SqlServer-数据旋转-知其然也指其所以然
在日常开发中,尤其是数据统计制作报表的时候,我们经常需要一种把行转换成列的技术,用于展示我们的统计结果,也许有人会说,我不能在设计表结构的时候就按照我想展示的结构进行设计么?虽然这也是一种办法,但日常的统计都是随着业务不断的运行,而逐步积累的动态数据,这时新的数据就会平凡导致表结构的修改。
例如:我们现在有一个需求,在数据库中存储每个人的名字、所掌握的专业技能与每项技能的熟练度,并且我想以一种简单的统计方式,看每个人的每项技能的熟练度,统计结果的要求如下:
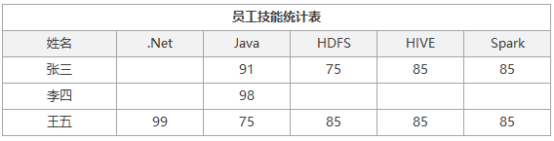
那么我们应该如何考虑设计数据库中的表结构?当然你可以就按照上面输出的结果格式设计表结构,但这种结构在后期随着业务的变化会过度愈来愈数据定义语言(DDL),试想一下后面再来一位赵六,并且赵六以上技能都会的同时还会Flink,我们势必要面对对表结构的修改,这将是我们的编程非常痛苦,所以我们通常会选择设计一张包含:姓名,专业与熟练度着三个列的表结构来存储基本信息,这样我们以后只需要对表中的数据进行增删改的操作即可满足要求,当然这在统计的时候也会自然变得稍微复杂一些,不过,当你权衡每种方法的利弊时,我选择两害相较取其轻。
闲话少叙,接下来就开始我们的正题“数据旋转”,前面说了数据旋转我们可以理解为一种把行转换成列的技术,结合我们上面的例子,我们基础数据的表结构设计如下:
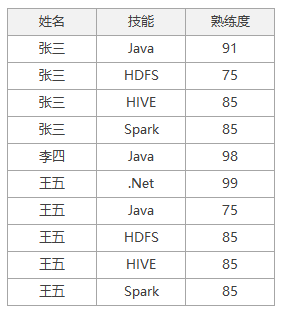
那么我们如何将原始的表结构转换为目标格式输出呢?从原始数据表结构到目标展示的表结构,我们可以看出,这就是一种典型的把行转换成列的需求,首先,我们先把原始表结构实现,具体语句如下:
CREATE TABLE skills ( name NVARCHAR(6), skills NVARCHAR(20), score int ) INSERT INTO skills VALUES('张三','Java',91); INSERT INTO skills VALUES('张三','HDFS',75); INSERT INTO skills VALUES('张三','HIVE',85); INSERT INTO skills VALUES('张三','Spark',85); INSERT INTO skills VALUES('李四','Java',98); INSERT INTO skills VALUES('王五','.Net',99); INSERT INTO skills VALUES('王五','Java',75); INSERT INTO skills VALUES('王五','HDFS',85); INSERT INTO skills VALUES('王五','HIVE',85); INSERT INTO skills VALUES('王五','Spark',85);
那么首先我们回想一下上一面《SqlServer-逻辑查询-ON与WHERE的天壤之别》中描述的查询逻辑处理的过程,这对于理解这个示例是非常有帮助的,我在前面讲到了SELECT阶段通常很多情景下会在SQL语句的最后一步执行,并且SELECT语句用于指定最终表都输出哪些列,那么我们在看下我们示例中要求输出的都有哪些列?输出结果中包含(姓名、.Net、Java、HDFS、HIVE、Spark),并且我们可以从问题和结果中看出,是把每个人的按照指定格式输出,脑子里面有没有瞬间想起分组?从以上我们可以得出通过SELECT可以控制输出列,通过分组可以按人员姓名统计分数。我们指导SQL在逻辑查询处理过程中,每一步后都会生成一张虚拟表,并且GOURP BY在SELECT之前执行,那么我们就先从分组开始。
第一步:先按名称执行分组
此步我们只考虑分组暂不考虑SELECT输出哪些内容与分组本身的一些特性包括聚合呀什么的,我们来看下如下语句,看看该语句在逻辑查询过程中是怎样的执行过程。
SELECT name FROM skills GROUP BY name
我们得到的执行结果如下:
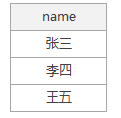
为了让该语句顺利执行,我在前面制定了SELECT name,输出name列,查询结果只是表象,其实在GROUPBY阶段生成的虚拟表结构如下:

第二步:通过SELECT指定输出列
从该虚拟表结构中我们可以看出,虚拟表中已经对name列加入了分组描述,那么下一步我们就可以通过指定SELECT指定输出哪些列来达到我们数据旋转的目的,因为为在分组中指定列不能直接通过SELECT输出,而需要结合聚合函数,我们可以将我们要输出的列包含在聚合函数中,并且在聚合函数中加入我们的CASE语句来达到我们行边列的效果,例如:
MAX(CASE WHEN skills = ‘Java’ THEN score END) AS Java
CASE的用法请关注后期SqlServer系列教程文章中详细了解,这里我只重点表述一下CASE表达式中如果没有写ELSE,则相当于默认写了个ELSE NULL,也就是说当判断到该项数据时,如果条件不满足会自动填充NULL,那么我们来看一下完整的SQL如下:
SELECT name, MAX(CASE WHEN skills = '.Net' THEN score END) AS [.Net], MAX(CASE WHEN skills = 'Java' THEN score END) AS Java, MAX(CASE WHEN skills = 'HDFS' THEN score END) AS HDFS, MAX(CASE WHEN skills = 'HIVE' THEN score END) AS HIVE, MAX(CASE WHEN skills = 'Spark' THEN score END) AS Spark FROM skills GROUP BY name
我们来具体按照逻辑查询处理过程分析一下,首先我们进行了分组,该步骤产生的虚拟表结构如下:

接下来我们通过SELECT制定了将所有技能输出为列,通过CASE语句控制该列具体展示的内容,这里细心且好学的朋友会有一个疑问,明明用的MAX聚合函数应该显示的内容都是每个分组中score列最大的值呀?这里我想说仔细看,我们CASE是现在聚合函数中的,也就是说它在聚合函数之前执行,我们通过下图来看一下具体的执行过程:
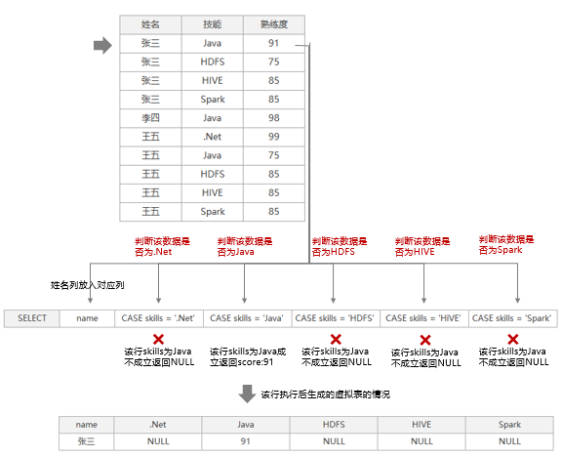
我们可以看到原始表的每一行数据都会经历一边上图的过程,原始表执行完最后一行数据,那么我们得到的中间虚拟结果表,内容如下:
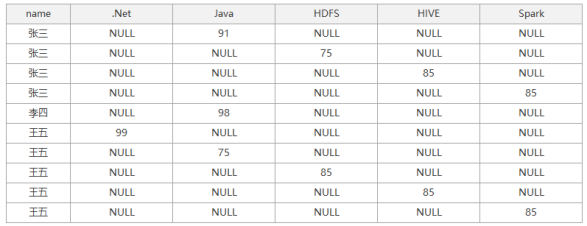
最后我们通过分组与聚合就能得到我们最终想要的结果,通过数据旋转完成了我们示例最终的展示要求。
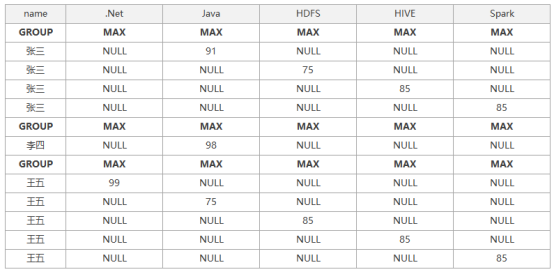
最后我想补充依据,以上是根据标准SQL进行的数据旋转,在SqlServer中加入了PIVOT(只适用于SqlServer2005以上版本),用来实现相同的数据旋转,但我觉的该用法还是很不直观,不易于理解,接下来我使用PIVOT进行该需求的实现,大家下来可以咱评论区补充一下对PIVOT的看法。
SELECT name, [.Net],Java,HDFS,HIVE,Spark FROM skills PIVOT(MAX(score) FOR skills IN([.Net],Java,HDFS,HIVE,Spark)) AS T
处理代码量降低了一点点之外,我并没有看到其他任何的优势,希望大家可以在评论区或者私下联系我,发表一下您对PIVOT这种用法的看法,创作不易,如果您觉得帮到了您,还请双击屏幕点个赞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号