SqlServer-逻辑查询-ON与WHERE的天壤之别
在日常开发中,我们经常会通过SQL对数据库中的基础数据元素进行查询,通过对业务具有相关性的数据表进行关联组合,生成新的数据模型来达到我们将数据转换为业务信息的目的,但不掌握查询元素的逻辑处理次序就开始用SQL编程,在日常工作中很容易碰到令人费解的问题。
所以了解SQL执行的逻辑查询过程可以帮助我们更加自如的应用SQL查询,虽然SQL的逻辑查询的处理步骤看起来很低效,但SqlServer在实际的执行过程中数据库引擎会通过查询优化器来生成最有效的物理处理过程,查询的实际物理过程与逻辑处理过程有很大不同,但逻辑查询过程中的执行的步骤是通过逻辑步骤表述的方式让我们更容易理解SQL查询处理中的各个阶段。
闲话少说,下面我们开始一起讨论SQL查询的逻辑处理过程,假设我们正在开发一套当地的健康码小程序,我们的后台需要查询目前谁的健康码出示的次数,用来统计期间人员的出行频次,同时我们需要将出行次数少于2次的人员信息统计出来,那么就通过这个示例来解析一下逻辑查询的各个步骤。
首先,会创建一张人员表与健康码表,用来描述人员信息与健康码出示的次数,表结构如下:

我们分别为这两张表初始化如下数据:
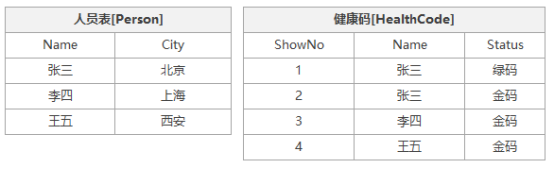
原谅我随意使用名称作为主键与我对表数据类型的选择,我知道这有些不妥,但我们只需要通过实力示例理解我所表达的业务就好,那么创建代码如下:
CREATE TABLE Person ( Name NVARCHAR(5) NOT NULL PRIMARY KEY, City NVARCHAR(10) NOT NULL ); INSERT INTO Person VALUES('张三','北京'); INSERT INTO Person VALUES('李四','上海'); INSERT INTO Person VALUES('王五','西安'); CREATE TABLE HealthCode ( ShowNo INT NOT NULL PRIMARY KEY, Name NVARCHAR(5) REFERENCES Person(Name), Status NVARCHAR(2) ); INSERT INTO HealthCode VALUES(1,'张三','绿码'); INSERT INTO HealthCode VALUES(2,'张三','金码'); INSERT INTO HealthCode VALUES(3,'李四','金码'); INSERT INTO HealthCode VALUES(4,'王五','金码');
接下来我们查询返回所有绿码和金码的人员出行次数,且出行次数少于2次的人员信息,并对返回结果按照出行次数进行由小到大的排序,查询代码与查询结果如下:
SELECT P.Name,P.City,COUNT(H.ShowNo) AS ShowCnt FROM Person AS P LEFT JOIN HealthCode AS H ON P.Name = H.Name WHERE H.Status IN ('金码','绿码') GROUP BY P.Name,P.City HAVING COUNT(H.ShowNo) < 2 ORDER BY ShowCnt
查询结果如下:
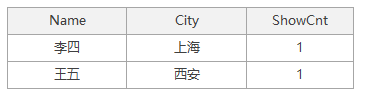
OK,看到这里想必我们就要开始根据该示例进行整体的逻辑查询处理过程的分析了,在开始分析之前,我想先简要介绍一下逻辑查询处理的步骤,在我们使用的大多数编程语言中,代码是按照由上至下、从左到右顺序执行,但在SQL中我们代码的编写是按顺序编写,但执行往往由FROM子句第一个被执行,每个子句的步骤执行完毕后会生成一张虚拟表,用作被下一个子句执行时使用。
由FROM开始,那其他关键字的先后执行的处理顺序是什么呢?简单起见,我们先看看我们最常用的关键字在SQL语句中的执行顺序,一张图让你了解逻辑查询的处理步骤:

从该图中我们可以看出,典型的SQL语句基本上为关键字+表达式的方式进行组成,我们可以从SQL中提取其中的关键字,并在图中对各个关键字在逻辑处理中的执行顺序以及过程进行了简要描述。
初步了解了语句整个逻辑查询的处理步骤后,如果没看懂或者思路很模糊也不必太担心,接下来我将根据我们的示例,对每一步具体的执行过程与中间产生的临时表的结构与过程,进行逐步的详细分解,本文的结尾,我会展示一个典型的问题用于大家思考,闲话少说,接下来我们来看看每一步的背后究竟是如何执行的。
第一步:执行FROM关键字
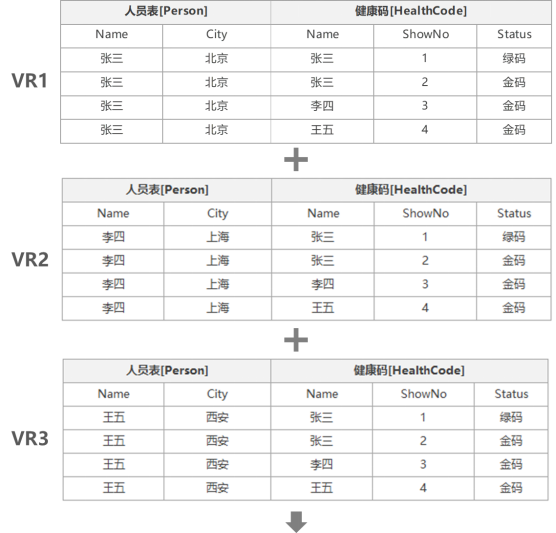
从示例SQL语句与上图描述的过程中,我们可以看到SQL语句执行的第一步为FROM,如果FROM为单表,则直接返回该表中的数据放入临时表VT1,用于下一步操作的数据源,若FROM为多表关联,会对FROM后面的表依次进行交叉联接[笛卡尔积],生成临时表VT1,根据我们的示例SQL为例,我们FROM关键字后描述了Person表与HealthCode的左外联接,那么第一步是将Person表的数据与HealthCode表的数据进行交叉联接。
先抛开左外联接的LEFT,因为他会在后面执行,为了让更多不同水平的人能看懂,接下来我会尽可能的用图的方式进行详细的描述,若您对该技术点已经特别熟悉,请直接跳过执行方式,看执行结果就好,具体执行方式如下:
1、将主表中的第一行与关联表中的所有行逐一关联,形成结果集VR1;

2、以此类推,将主表中的第二行与关联表中的所有行逐一关联VR2;

3、以此类推,将主表中的第二行与关联表中的所有行逐一关联VR3;

4、主表有多少行就重复多少次,将VR1-VRn的结果集合并形成FROM步骤的最终结果,将结果放入虚拟表VT1中,按照我们的示例我们将得到VT1中数据如下:
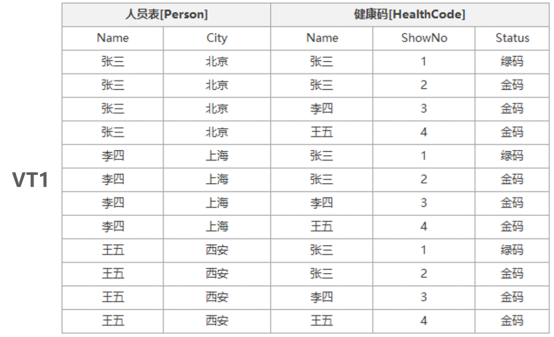
经过以上将Person与HealthCode表交叉联接后,FROM过程就执行完毕,并且生成一张虚拟表VT1,用于下一步骤的数据源。
第二步:执行ON筛选器
在上一步返回的虚拟表VT1中,对每一行数据进行ON筛选器中描述的条件表达式进行过滤,将表达式返回为TRUE或者换句话说满足表达式条件的数据,放入新生成的虚拟表VT2中,在我们示例中ON的表达式为:Person.Name = HealthCode.Name,详细图解过程如下:
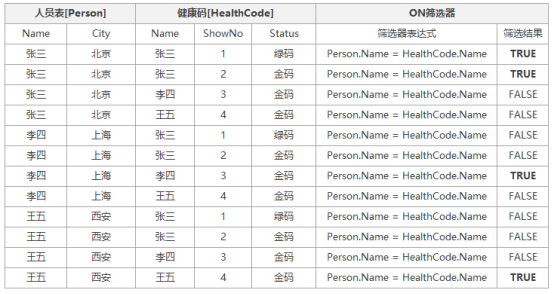
通过ON筛选器设置的逻辑表达式筛选后,结果为TRUE的值,放入虚拟表VT2中,用于下一步骤的数据源。VT2该虚拟表结构如下:
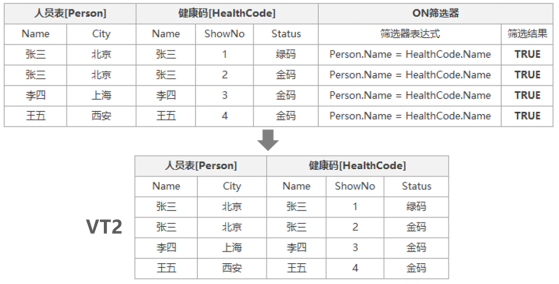
第三步:执行OUTER JOIN,补全主表缺失行
这一步操作只在当SQL中采用外联接时执行,用于将主表缺失的数据行补全,在未关联到的关联表数据列中补NULL,若想深入详细了解SQL表关联的知识请参考SQL的SqlServer系列关联查询部分的相关文章,因本示例主表与关联表在执行ON筛选器后,VT2中的Person.Name均包含主表Person.Name中的所有名称,所以该步骤不会补全缺失行,详细图解如下:
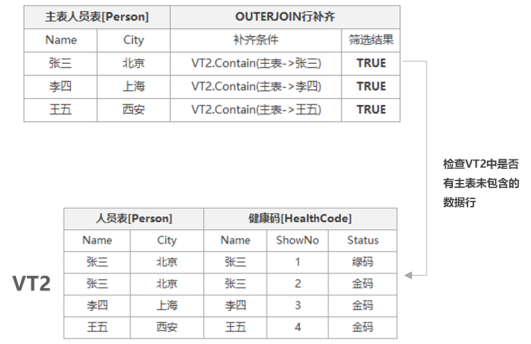
因VT2包含所有主表中的行数据未进行补全,所以VT2未产生任何变化,将结果生成虚拟表VT3,用于下一步操作的数据源。VT3结构如下:
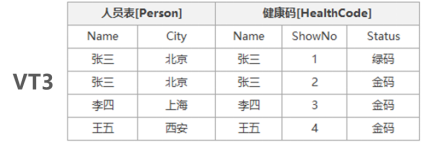
第四步:执行WHERE筛选器
该步骤对上一步返回的虚拟表VT3中的数据内容进行WHERE筛选器的过滤,通过WHERE设置的表达式对数据进行过滤,本示例的WHERE表达式为:WHERE H.Status IN ('金码','绿码'),该步骤图解与执行结果如下:
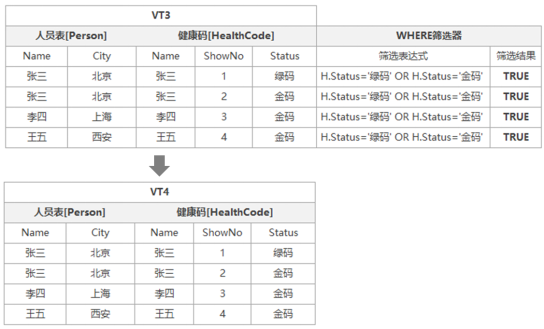
因为所有条件均满足WHERE筛选器的条件,所以VT3内容原封不动生成到虚拟表VT4,用于下一步骤的数据源。
第五步:执行GROUP BY分组
该步骤通过GROUP BY后面所描述的列明进行分组,在构建虚拟表的过程中,虚拟表中会包含分组列与上一步骤返回的数据两部分组成,生成虚拟表VT5,其中在VT5虚拟表中分组列用来描述VT4表中的数据应该数据哪个组,本示例中GROUP BY是以Person表中的Name字段进行分组,那么详细图示如下:
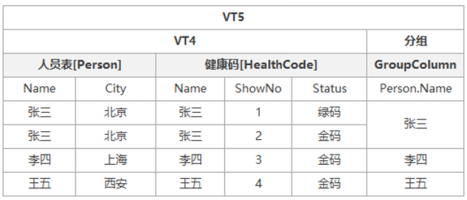
分组列用于描述每一行数据应该数据哪一个组,加入分组列描述的数据内容,生成虚拟表VT5,用于下一步骤的数据源。
第六步:执行HAVING筛选器
HAVING筛选器是专门与分组步骤搭配的筛选器,用于筛选分组后的结果内容,逻辑查询过程会根据该筛选器表达式在VT5分组虚拟表中加入对应的结果信息,用于执行实际的筛选判断,本示例的HAVING筛选器的条件为:HAVING COUNT(H.ShowNo) < 2,那么具体虚拟表的结构具体详细图示如下:
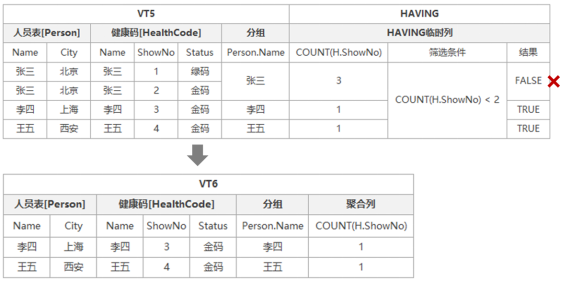
因HAVING统计的为COUNT(H.ShowNo) < 2,VT5中张三统计的数量为2,所以不满足该条件,张三这行数据被移除,同时生成新的虚拟表VT6,用于下一步骤的数据源。这里需要注意的是HAVING与分组是搭配使用,HAVING中的聚合函数默认会根据分组指定的内容进行计算。
第七步:执行SELECT构建查询列表
往往虚拟表中包含的列不一定全是我们需要看到的列,SELECT用于指定生成的虚拟表中应该有哪些列,用做下一步骤的数据源,同时我们可以在此步骤中对现有的列明通过AS关键字进行重命名,那么后续步骤中会使用新的列明进行相关操作。本示例中SELECT指定的列明包括Person表中的Name列,同时还包括了聚合列并对聚合列进行重新命名为ShowCnt,需要注意的是该聚合列是在HAVING阶段产生的,若SQL语句中没有HAVING条件,那么逻辑查询会根据SELECT 阶段中指定的聚合函数,计算出聚合列的值,本示例中包含HAVING阶段,那么包含该阶段的SELECT步骤具体的图示如下:
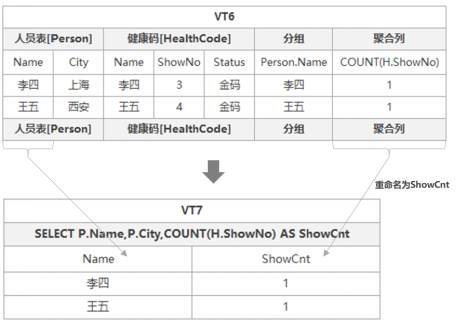
生成虚拟表VT7,用于下一步骤的数据源。
第八步:执行ORDER BY排序并返回结果集
因为本示例最后一步为排序,同时生成结果集返回客户端,我在此将这两步合并到一步进行讲解,需要注意的是,ORDER BY步骤返回的不是虚拟表,而是返回一个对象,SqlServer中将该对象成为游标,该对象包含了物理表中排序的顺序,而不是针对实际的表进行真实的排序,在C语言中该对象就好比一个指针数组,指针数组已经按照排序的规则指定了指针在数组中的具体索引位置,而在返回客户端的时候,是根据该指针数组中每个指针元素所指向行的地址获取改行数据,进行表拼装,返回客户端,具体图示如下:
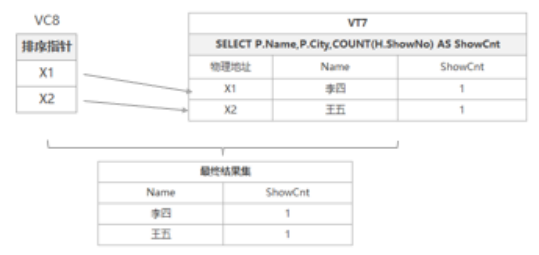
根据以上示例中SQL执行步骤的分解,我们了解了整个SQL执行过程中的顺序以及每个阶段数据是如何组织变化的,不管是做RDBMS还是大数据,理解SQL的用法都是非常必要,同时,这里需要提醒一下除非必须要排序,否则在日常SQL开发中,尽量不要使用ORDER BY,毕竟对大数量排序是非常占用资源成本的。
在本文开头我描述了了解逻辑查询过程的必要性,以及不了些该过程会为开发中的我们带来一定困扰,那我想写两个SQL语句,大家能否在评论区,告诉我这两个SQL语句的执行结果有什么差别?如果有差别原因是什么?
语句一:
SELECT P.Name,COUNT(H.ShowNo) AS ShowCnt FROM Person AS P LEFT JOIN HealthCode AS H ON P.Name = H.Name AND P.City = '西安' GROUP BY P.Name HAVING COUNT(H.ShowNo) < 2 ORDER BY ShowCnt;
语句二:
SELECT P.Name,COUNT(H.ShowNo) AS ShowCnt FROM Person AS P LEFT JOIN HealthCode AS H ON P.Name = H.Name WHERE P.City = '西安' GROUP BY P.Name HAVING COUNT(H.ShowNo) < 2 ORDER BY ShowCnt
能否告诉我一下区别到底在哪里?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号