
Linux-----进程调度器介绍
调度器
进程调度器是操作系统内核中的一个重要组件,负责管理和分配CPU时间给不同的进程。其主要任务是决定哪个进程应该在CPU上运行,并在多任务操作系统中确保公平性、高效性和响应性。
-
调度策略:进程调度器通常使用一种调度策略来选择下一个运行的进程。最常见的调度策略是时间片轮转(Round Robin)、优先级调度、高级调度(CFS)
-
进程状态:调度器必须管理这些状态并根据进程的状态和优先级来做出调度决策。
-
上下文切换:当调度器选择一个新进程运行时,它需要进行上下文,将当前运行进程的上下文(寄存器、程序计算器等)保存起来并加载到新进程的上下文,以便它可以在CPU上继续执行。
-
调度队列:调度器通常维护一个就绪队列,其中包含了等待运行的进程。调度器从这个队列中选择下一个运行的进程。
-
多核支持:在多核处理器系统中,调度器需要决定哪个进程在哪个CPU核心上运行,以充分利用所有可用的核心。
-
实时性:在实时操作系统中,调度器必须确保实时任务能够按时执行,而不受其他非实时任务的干扰。
-
公平性:调度器应该公平地分配CPU时间片,以便每个进程都有机会执行,而不会被长时间占用CPU资源。
-
性能优化:高效的调度算法可以减少上下文切换的开销,提高系统性能。
进程调度的机制
操作系统通过中断机制实现了进程切换的调度。中断是一种硬件或软件触发的事件,它可以中断当前正在执行的进程,将控制权转移到操作系统内核,然后根据调度算法选择下一个要执行的进程。
操作系统会设置一个定时器中断,该中断周期性地触发,例如每隔一段时间。当定时器中断发生时,CPU会立即停止当前进程的执行,将控制权切换到内核的中断处理程序中。
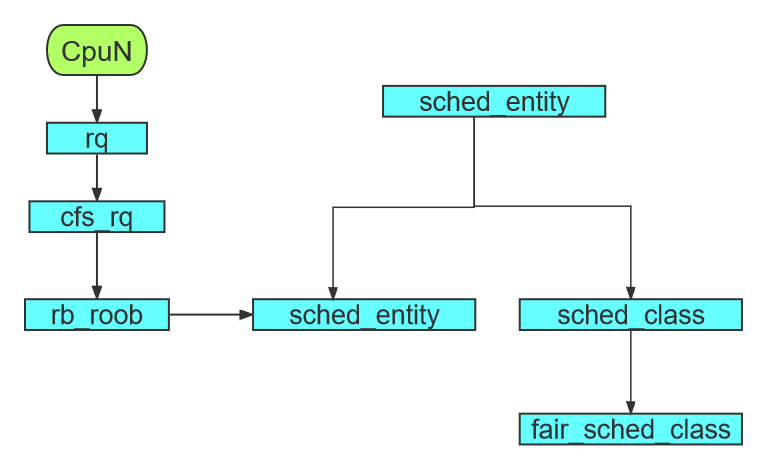
rq(Runqueue)运行队列
rq用于存储已经准备好并且可以被调度执行的进程。运行队列通常包含多个队列,每个队列代表一个不同的优先级或状态,例如就绪状态,阻塞状态等。在多任务操作系统种,内核会根据不同的调度策略将进程从一个队列移动到另一个队列,按照一定的优先级和调度算法来选择下一个要执行的进程。不同的调度器(如CFS、O(1)等可能使用不同的数据结构来管理运行队列)
cfs_rq
cfs_rq是Linux内核中Completely Fair Scheduler(CFS,完全公平调度器)。CFS是一种基于红黑树的调度算法,目标是在实现对系统中运行的进程分配CPU时间的公平性。最重要CFS
其中包括
-
struct load_weight:表示队列的权重,用于计算进程在队列中分配CPU时间的比列。
-
struct rb_root:这是一个红黑树的根,用于按照进程的虚拟运行时间(virtual runtime)排序任务。虚拟运行时间是CFS调度算法中的一个关键概念,用于确定下一个要执行的任务
-
u64 min_vruntime:表示队列中任务的最小虚拟运行时间,通常是红黑树中最左边节点的虚拟运行时间。
-
struct task_sturct *curr:指向当前正在运行的任务。
CFS通过不断更新新任务的虚拟运行时间来实现公平分配CPU时间,使得任务的执行时间比例接近其权重。这样,即使系统中有多个任务在运行,CFS也可以确保它们在相同时间内获得CPU时间片,从而实现了公平调度。
sched_entity
Linux内核中用于调度的实体,它是(Completely Fair Scheduler,CFS,完全公平调度器)的核心数据结构之一。CFS的目标就是对系统中运行的进程分配CPU时间的公平性。
主要成员和作用:
-
struct load_weight load:这个成员表示任务的权重,用于计算任务在队列中分配CPU时间的比例。CFS通过这个权重来尽量保证不同任务获得相等的CPU时间片。
-
struct rb_node run_node:
sched_entity结构以红黑树的形式组织在队列中,以根据虚拟运行时间(virtual runtime)排序任务。虚拟运行时间是CFS调度算法中的一个关键概念,用于确定下一个要执行的任务。 -
u64 vruntime:表示任务的虚拟运行时间,是一个64位无符号整数。虚拟运行时间决定了任务在队列中的位置,以及何时执行。较小虚拟运行时间的任务将更早地被调度执行。
-
struct sched_entity *parent:指向父调度实体,通常是进程的调度实体。这对于CFS中的多级调度非常重要,因为它允许在进程和线程之间共享虚拟运行时间。
sched_class
sched_class是用于实现不同调度策略的结构体,它定义了一组函数指针,用于管理进程的调度。
1.
struct sched_entity *(*pick_next_task)(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
这个函数会从运行队列rq中选择下一个任务,并返回sched_entity结构。
2.
void (*put_prev_task)(struct rq *rq, struct task_struct *prev, struct rq_flags *rf):
这个函数指针定义了在切换到下一个任务之前,如何处理当前任务。通常会执行一些清理工作,例如更新任务的状态。
3.
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued)
这个函数指针定义了当任务的时间片用完后,如何重新调度该任务。通常会更新任务的虚拟运行时间等信息。
4.
void (*task_fork)(struct task_struct *p)
这个函数指针定义了在新创建的任务上应用调度策略的操作。通常会为新任务初始化调度相关的数据结构。
5.
void (*set_cpus_allowed)(struct task_struct *p, const struct cpumask *newmask)
这个函数指针定义了如何设置任务的 CPU 亲和性,即确定任务可以在哪些 CPU 上运行。
6.
其他调度策略特定的函数:不同的调度策略可能会定义其他函数,用于实现特定的调度行为
CpuN
cpuN" 是一个用来指代特定CPU核心的术语,其中 "N" 代表一个数字,表示核心的标识符。在多核CPU系统中,每个CPU核心都有一个唯一的标识符,通常是从0开始的数字。例如,"cpu0" 表示第一个CPU核心,"cpu1" 表示第二个CPU核心,依此类推
在Linux系统中,可以使用类似 /proc/cpuinfo 或 top 命令来查看有关CPU核心的信息,其中包括它们的标识符(通常以 "processor" 字段表示)。
schedule函数的流程包括
schedule函数是Linux内核中用于进程调度的核心函数之一,它的流程涉及到多个步骤和函数调用。以下是schedule函数的主要流程:
1.进入schedule函数:当需要进行进程调度时,内核会进入schedule函数的执行。
2.准备就绪队列:首先,schedule函数会检查就绪队列中是否有可运行的进程。如果就绪队列为空,表示没有可运行的进程,那么调度器会继续执行空闲任务(idle task)。
3.选择下一个运行进程:如果就绪队列中有可运行的进程,调度器会选择下一个要运行的进程。这通常涉及到一个最优的进程,以满足调度策略(如CFS)。
4.切换进程上下文:一旦选择了下一个要运行的进程,调度器就会进行进程上下文切换。这包括保存当前进程的寄存器状态、堆栈、程序计数器等信息,然后加载下一个进程的寄存器状态,使其可以继续执行。
5.执行下一个进程:调度器会跳转到下一个进程的执行点,并让其继续执行官。这样,CPU的控制权就转移到了新选中的进程上。
6.进程运行:被选中的进程开始在CPU上运行,执行其相应的任务。
7.时间片耗尽检查:在进程运行时,调度器会定期检查进程的时间片是否已经耗尽。如果时间耗尽,说明当前进程已经运行了足够的时间,需要重新放入就绪队列,以便给其他进程运行的机会。
8.可能的切换点:在执行期间,可能会有一些切换点,如系统调用、中断处理、等待事件等。在这些切换点上,调度器会检查是否需要进行进程切换。
9.重复流程:这个流程会一直重复执行,以便不断地进行进程调度,确保每个就绪进程都有机会运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号