Linux内核笔记(三)内核编程语言和环境
学习概要:
Linux内核使用的编程语言、目标文件格式、编译环境、内联汇编、语句表达式、寄存器变量、内联函数 c和汇编函数之间的相互调用机制Makefile文件的使用方法。
as86汇编语言语法
汇编器专门来把程序编译成含机器码的二进制程序或目标文件。汇编器会把输入的一个汇编语言程序(例如srcfile)编译成目标文件。汇编的命令行基本格式是
as[选项] -o objfile srcfile
其中objfile是as编译输出的目标文件名称,srcfile.s是as的输入汇编语言程序名称。如果没有使用输出文件名,那么as会编译输出名称为a.out的默认目标文件选项用来控制编译过程以产生指定格式和设置的目标文件。输入的汇编语言程序srcfile是一个文本文件。该文件内容必须是有换行字符结尾的一系列文本行组成。虽然GNU as可使用分号在一行上包含多个语句,但通常在编制汇编语言程序时每行指包含一条语句。
语句可以是只包含空格、制表符和换行符的空行,也可以是赋值语句(或定义语句)、伪操作符语句和机器指令语句。例如BOOTSEG = 0X07C0
- 伪操作符语句都是汇编器使用的指示符,它通常并不会产生任何代码。它有伪操作码和0个或多个操作数组成。每个操作码都是由一个点字符'.'开始。
点字符本身是一个特殊的符号,它表示编译过程中的位置计数器。其值是点符号出现处机器指令第1个字节的地址。 - 机器指令语句是可执行机器指令的助记符,它由操作码和0个或多个操作数构成。另外任何语句之前都可以有标号。标号是由一个标识符后跟一个冒号:组成。在编译过程,当汇编器遇到一个标号,那么当前位置计数器的值就会赋值给这个标号。
- 一条汇编语句通常由标号(可选)、指令助记符(指令名)和操作数三个字段组成,标号位于一条指令的第一个字段。它代表其所在位置的地址,通常指明一个跳转指令的的目标位置。最好还可以跟随用注释符开始的注释部分。
- 汇编器编译产生的目标文件objfile通常起码包含三个段或区
- .text:正文段(代码段,是一个已初始化过的段)通常其中包含程序的执行代码或只读代码(.bss)
- .data:数据段 :其中包含可读/写的数据。而未初始化数据段是一个未初始化的段。通常汇编器产生的输出目标文件不会为该段保留空间,但在目标文件链接成执行程序被加载时操作系统会把该段的内容全部初始化为0.
as86
.bass:未初始化数据段
as86汇编语言程序
一个简单的框架实例boot.s来说明as86汇编程序的结构以及程序中语句的语法,然后给出编译链接和运行方法,最后再分别列出as86和ld86的使用方法和编制选项。
1 !
2 !boot.s -- bootsect.s的框架程序。用代码0x07替换串msg1中1字符,然后在屏幕第一行上显示。
3 !
4 .globl begtext,begdata,begbss,endtext,enddata,endbss !全局标识符,供ld86链接使用
5 .text !正文段:
6 begtext:
7 .data ! 数据段;
8 begdata
9 .bss !未初始化数据段
10 begbss:
11 .text !正文段
12 BOOTSEG = 0X07c0 !BIOS加载bootsect代码的原始段地址;
13
14 entry start !告知链接程序,程序从start标号处开始执行。
15 start:
16 jmpi go,BOOTSEG !段间跳转。INITSET指出跳转段地址,标号go是偏移地址。
17 go: mov ax,cs !段寄存器cs值-->ax,用于初始化数据段ds和es。
18 mov ds,ax
19 mov ex,ax
20 mov [msg1+17],ah !0x07-->替换字符串中1个点符号,喇叭就会响一声
21 mov cx,#20 !共显示20个字符,包含回车换行符
22 mov dx,#0x1004 !共显示在屏幕第17行、第5列处。
23 mov bx,#0x000c !字符显示属性(红色)
24 mov bp,#msg1 !指向要显示的字符串(中断调用请求)
25 mov ax,#0x1301 !写字符串并移动光标到串结尾处。
26 int 0x10 !BIOS中断调用0x10,功能0x13,子功能01.
27 loop1: jmp loop1 !死循环
28msg1:.ascii "Loading System..."!调用BIOS中断显示的信息。共20个ASCII码字符
29 .byte 13,10
30 .org 510 !表示以后语句从地址510(0x1FE)开始存放。
31 .word 0XAA55 !有效引导扇区标志,供BIOS加载引导扇区使用
32 .text
33 endtext
34 .data
35 enddata
36 .bss
37 endbss:
该程序是一个简单的引导扇区启动程序。编译链接产生的执行程序可以放入软盘第1个扇区直接用来引导计算机启动。启动后会在屏幕第17行、第五列处显示出红色字符串"Loading system ..",并且光标下移一行。然后程序就在27行上死循环。
第4行上的'.globl'是汇编指示符(或称汇编伪指令、伪操作符)。汇编指示符均以一个字符'.'开始,并且不会在编译时产生任何代码。汇编指示符由一个伪操作码,后跟0个或多个操作数组成。第4行上的'glogl'是一个伪操作码,而其后面的标号'begtext,begdata,begbss'等标号就是它的操作数。标号是后面带冒号的标志符,例如第6行上的'begtext:'。但是在引用一标号时无须带冒号。
第12行定义了一个赋值语句"BOOTSEG = 0x7c0"。等号'='(或符号'EQYU')用于定义标识符BOOTSEG所代表的值,因此这个标识符可称为符号常量。这个值与C语言中的写法一样,可以使用十进制、八进制、十六进制。
第14行上的标识符'entry'是保留关键字,用于迫使链接器ld86
在生成的可执行文件中包括进其后指定的标号'start'。通常在链接多个目标文件生成一个可执行文件时应该在其中一个汇编程序中用关键词指定一个入口标号,以便于调试。
第16行上是一个段间(Inter-segment)远跳转语句,就跳转到下一条指令。由于当BIOS把程序加载到物理内存0x7c00处并跳转到该处时,所有段寄存器(包括CS)默认值均为0,即此时CS:IP = 0X0000:0X7c00。因此这里使用段间跳转语句就是为了给CS赋段值0x7c0。该语句执行后CS:IP=0X07C0:0X0005。随后的两条语句分别给DS和ES段寄存器赋值,让它们都指向0x7c0。这样便于对程序中的数据(字符串)进行寻址。
第20行上的MOV指令用于把ah寄存器中0x7c0段值的高字节(0x07)存放到内存中字符串msg1最后一个'.'位置处。这个字符将导致BIOS中断在显示字符串时鸣叫一声。
! 直接寄存器寻址。跳转到bx值指定的地址处,即把bx的值拷贝到IP中。
mov bx,ax
jmp bx
! 间接寄存器寻址。bx值指定内存位置处的内容作为跳转的地址。
mov [bx],ax
jmp [bx]
! 把立即数1234放到ax中,把msg1地址值放到ax中。
mov ax,#1234
mov ax,#msg1
! 绝对寻址。把内存地址1234(msg1)处的内容放入ax中。
mov ax,1234
mov ax,msg1
mov ax,[msg1]
! 索引地址。把第二个操作数所指内存位置处的值放入ax中。
mov ax,msg1[bx]
mov ax, msg1[bx*4+si]
第21--25行的语句分别用于把立即数放到相对应的寄存器中。**把立即数前一定要加'#',否则将作为内存地址使用而使语句变成绝对寻址语句,**,例如,把一个标号(例如msg1)的地址值放入寄存器中时也一定要在前面加'#',否则会变成把msg1地址处的内容放到寄存器中!
第26行是BIOS屏幕显示中断调用int0x10。这里其功能19、子功能。1.该中断的作用是把一字符串(msg1)写到屏幕指定位置处。寄存器cx中是字符串长度值,dx中是显示位置值,bx中是显示使用的字符属性,es:bp指向字符串。
第27行是一个跳转语句,跳转到当前指令处。因此这是一个死循环语句。这里采用死循环语句是为了让显示的内容能够停留在屏幕上而不被删除。死循环语句是调试汇编程序时常用的方法。
第28--29行定义了字符串msg1。定义字符串需要使用伪操作符'.ascii',并且需要使用双引号括住字符串。伪操作符'.asciiz'还会自动在字符串后添加一个NULL(0)字符。另外,第29行上定义了回车和换行(13,10)两个字符。定义字符需要使用伪操作符'.byte',并且需要使用单引号把字符括住。
3.1.3as汇编语言程序的编译和链接
[/root]# as86 -0 -a -o boot.o boot.s //编译。生成与as部分兼容的目标文件。
[/root]# ld86 -0 -s -o boot boot.o //链接。去掉符号信息。
[/root]# ls -l boot*
-rwx--x--x 1 root root
-rw------- 1 root root
-rw------- 1 root root
[/root]# dd bs=32 if=boot of=/dev/fd0 skip =1//写入磁盘或Image盘文件中。
16+0 records in
16+0 records out
其中第1条命令利用as86汇编器对boot.s程序进行编译,生成boot.o目标文件。第二条命令使用链接器ld86对目标文件执行链接操作,最后生成MINIX结构的可执行文件boot。其中选项'-0'用于生成8086的16位目标程序;'-a'用于指定生成与GNU as 和ld 部分兼容的代码。'-s'选项用于告诉链接器要去除最后生成的可执行文件中的符号信息。'-o'指定生成的可执行文件名称。
3.1.4as86和ld使用方法和选项
as86和ld86的使用方法和选项如下:
as的使用方法和选项:
as [-03agjuw] [-b [bin]] [-lm [list] [-n name] [-o objfile] [-s sym]] srcfile
默认设置(除了以下默认值以外,其他选项默认为关闭或无;若没有明确说明a标志,则不会有输出):
-3 使用80386的32位输出;
list 在标准输出上显示;
name 源文件的基本名称(即不包括'.'后的扩展名);
各选项含义
-0 使用16比特代码段;
-3 使用32比特代码段;
-a 开启与GNU as、ld的部分兼容性选项;
-b 产生二进制文件,后面可以分文件名;
-g 在目标文件中仅存入全局符号;
-j 使用所有跳转语句均为长跳转;
-l 产生列表文件,后面可以跟随列表文件名;
-m 在列表中扩展宏定义;
-n 后面跟随模块名称(取代源文件名称放入目标文件中);
-o 产生目标文件,后跟目标文件名(objfile);
-s 产生符号文件,后跟符号文件名;
-u 将未定义符号作为输入的未指定段的符号;
-w 不显示警告信息;
ld连接器的使用语法和选项:
对于生成Minix a.out格式的版本:
ld [-03Mims[-]] [-T textaddr] [-llib_extension] [-o outfile] infile...
对于生成GNU-Minix的a.out格式的版本:
ld [-03Mimrs[-]] [-T textaddr] [-llib_extension] [-o outfile] infile...
默认设置(除了以下默认值以外,其他选项默认为关闭或无):
-03 32位输出;
outfile a.out格式输出;
-0 产生具有16比特魔数的头结构,并且对-lx选项使用i86子目录;
-3 产生具有32比特魔数的头结构,并且对-lx选项使用i386子目录;
-M 在标准输出设备上显示已链接的符号;
-T 后面跟随正文基地址(使用合适于strtoul的格式);
-i 分离的指令与数据段(I&D)输出;
-lx 将库/local/lib/subdir/libx.a加入链接的文件列表中;
-m 在标准输出设备上显示已链接的模块;
-o 指定输出文件名,后跟输出文件名;
-r 产生适合于进一步重定位的输出;
-s 在目标文件中删除所有符号。
3.2 GNU as汇编
as汇编器仅用于编译内核中的boot/bootsect.s引导扇区程序和实模式下的设置程序boot/setup.s。内核中其余所有汇编语言程序(包括C语言产生的汇编程序)均使用gas来编译,并与C语言程序编译产生的模块链接。
在编译C语言程序时,GNU gcc编译器会首先输出一个作为中间结果的as汇编语言文件,然后gcc会调用as汇编器把这个临时汇编语言程序编译成目标文件。即实际上as汇编器最初是专门用于汇编gcc产生的中间汇编语言程序的,而非作为一个独立的汇编器使用。
3.2.1编译as汇编语言程序
使用as汇编器编译一个as汇编语言程序的基本命令行格式如下所示:
as [选项] [-o objfile] [srcfile.s...]
其中objfile是as编译输出的目标文件名,srcfile.s是as的输入汇编语言程序名。如果没有使用输出文件名,那么as会编译输出名称为a.out的默认目标文件。在as程序名之后,命令行上可包含编译选项和文件名。所有选项可随意放置,但是文件名的放置次序编译结果密切相关。
一个程序的源程序可以被放置在一个或多个文件中,程序的源代码是如何分割放置在几个文件中并不会改变程序的语义。程序的源代码是所有这些文件按次序的组合结果。每次运行as编译器,它只编译一个源程序。
3.2.2as汇编语法
as汇编器使用AT&T系统V的汇编语法与Intel的区别:
-
AT&T语法中立即操作数前面要加一个字符'$';寄存器操作数前要加字符百分号'%';绝对跳转/调用(相对于程序计算器有关的跳转/调用)操作数前面要加'*'号。而Intel汇编语法均没有这些限制。
-
AT&T语法与Intel语法使用的源和目的操作数次序正好相反。AT&T的源和目的操作数是从左到右 '源,目的'。例如Intel的语句'add eax,4'对应AT&T的'addl $4,%eax'。
-
AT&T语法中内存操作数的长度(宽度)由操作码最后一个字符来确定。操作码后缀'b'、'w'、和'l'分别指示内存引用宽度为8位字节(byte)、16位字(word)、32位长字(long)。Intel语法则通过在内存操作数前使用前缀'byte ptr'、'word ptr'和'dword ptr'来达到同样目的。因此,Intel的语句'mov al,byte ptr foo'对应于AT&T的语句'movb $foo,%al'。
-
AT&T语法中立即形式的远跳转和远调用为'ljmp/lcall $section,$offset',而Intel的是'jmp/call far section:offset'。同样,AT&T语法中远返指令’lret $stack-adjust'对应Intel的'ret far stack-adjust'
*AT&T汇编器不提供多代码段程序的支持,UNIX类操作系统要求所有代码在一个段中。
3.2.2.1汇编程序处理
as汇编器具有对汇编语言程序内置的简单预处理功能。该预处理功能会调整并删除多余的空格字符和制表符;删除所有注释语句并且使用单个空格或一些换行符替换它们;把字符常数转换成对应的数值。但是预处理功能不会对宏定义进行处理,也没有处理包含文件的功能。如果需要这方面的功能,那么可以让汇编语言程序使用大写的后缀'.S'让as使用gcc的CPP预处理功能。
由于as汇编语言程序除了使用C语言注释语句(即'/'和'/')以外,还使用'#'作为单行注释开始字符,因此若在汇编之前不对程序执行预处理,那么程序中包含的所有以'#'开始的指示符或命令均被当作注释部分。
3.2.2.2符号、语句和常数
符号(Symbol)是由字符组成的标识符,组成符号的有效字符取决于大小写字符集、数字和三个字符'_.$'。符号不允许数字字符开始,并且大小写含义不同。在as汇编程序中符号长度没有限制,并且符号中所有字符都是有效的。符号使用其他字符(';')作为结束。文件最后语句必须以换行符作为结束处。
语句(Statement)以换行符或者行分割符(";")作为结束。文件最后语句必须以换行符作为结束。若在一行的最后使用反斜杠字符''(在换行符前),那么就可以让一条语句使用多行。当as读取到反斜杠加换行符时,就会忽略掉这两个字符。
语句由零个或多个标号(Label)开始,后面可以跟随一个确定语句类型的关键符号。标号由符号后面跟随一个冒号(":")构成。关键符号确定了语句余下部分的语义。如果该关键符号以一个'.'开始,那么当前语句就是一个汇编命令(或称为伪指令、指示符)。如果关键符号以一个字母开始,那么当前语句就是一条汇编语言指令语句。因此一条语句的通用格式为:
标号: 汇编指令 注释部分 (可选)
或
标号: 指令助记符 操作数1,操作数2 注释部分(可选)
常数是一个数字,可分为字符常数和数字常数两类。字符常数还可分为字符串和单个字符;而数字常数可分为整数、大数和浮点数。
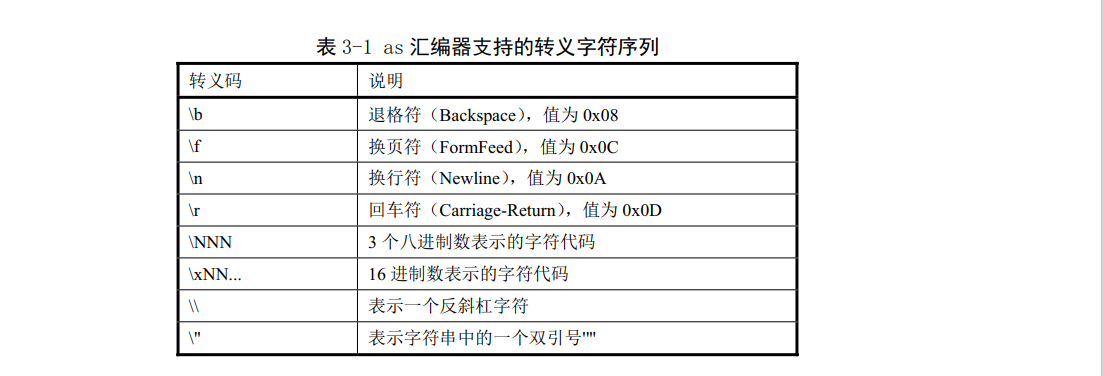
字符串必须用双引号括住,并且其中可以使用反斜杠''来转义包含特殊字符。例如'\'表示一个反斜杠字符。其中第一个反斜杠是转义指示符,说明把第2个字符看作一个普通反斜杠字符。常用转义字符序列,反斜杠若是其他字符,那么该反斜杠将不起作用并且as汇编器将会发出警告信息。
汇编程序中使用单个字符常数时可以写成在该字符前面加一个单引号,例如"'A"表示值65、"'C"表示值67.表3-1中的转义码也同样可以用于单个字符常数。例如"'\"表示是一个普通反斜杠字符常数。
整数数字常数有4中表示方法,即使用'0b'或者'0B'开始的二进制数('0-1'):以'0'开始的八进制数('0-7');以非‘0’数字开始的十进制数('0-9')和使用‘0x’或‘0X’开头的十六进制数('0-9a-fa-F')。若要表示负数,只需要前面添加‘-’。
大数(Bignum)是位数超过32位二进制位的数,其表示方法与整数的相同。汇编程序中对浮点常数的表示方法与C语言中的基本一样。由于内核代码中几乎不用浮点数。
3.2.3指令语句、操作数和寻址
指令(Instructions)是CPU执行的操作,通常指令也称作操作码(Opcode);操作数(Operand)是指令操作的对象;
而地址(Address)是指定数据在内存中的位置。指令语句是程序运行时刻执行的一条语句,它通常包含4个组成部分
-
标号(可选)
-
操作码(指令助记符)
-
注释
一条指令语句可以含有0个或最多3个用逗号分开的操作数。对于具有两个操作数的指令语句,第1个是源操作数,第2个是目的操作数,即指令操作结果保存在第2个操作数中。
操作数可以是立即数(即值是常数值的表达式)、寄存器(值在CPU的寄存器中)或(值在内存中)。一个间接操作数(Indirect operand)含有实际操作数值得地址值。AT&T语法通过在操作数前加一个'*'字符来指定一个间接操作数。只有跳转/调用指令才能使用间接操作数。见下面对跳转指令的说明。 -
立即操作数前需要加一个'$'字符前缀
-
寄存器名前需要加一个'%'字符前缀
-
内存操作数有变量名或者含有变量地址的一个寄存器指定。变量名隐含指出了变量的地址,并指示CPU引用该地址处内存的内容。
3.2.3.1指令操作码的命名
AT&T语法中指令操作码名称(即指令助记符)最后一个字符用来指明操作数的宽度。字符‘b’、‘w’和‘l’分别指定byte、word和long类型的操作数。如果指令名称没有带这样的字符后缀,并且指令语句中不含内存操作数,那么as就会根据目的寄存器操作数尝试确定操作数宽度。例如指令语句'mov %ax,%bx'等同于'movw %ax,%bx'。同时,语句'mov $1,%bx'等同于'movw $1,%bx'。
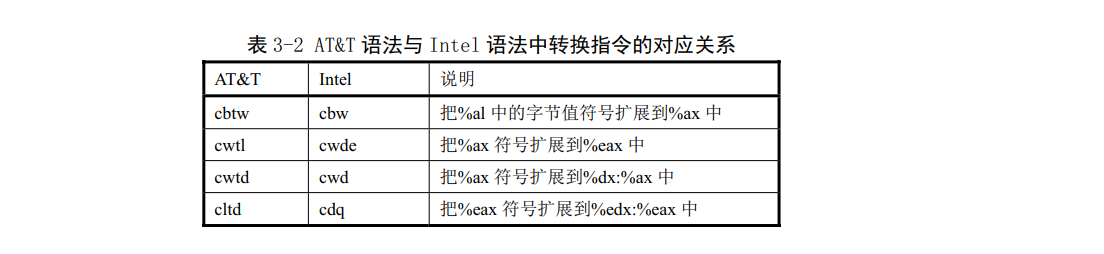
AT&T与Intel语法中几乎所有指令操作码的名称都相同,但仍有几个例外。符号扩展和零扩展指令都需要2个宽度来指令,即需要为源和目的操作数指明宽度。AT&T语法中是通过使用两个操作码后缀来做到。AT&T语法中符号扩展和零扩展的基本操作码名称分别是'movs...'和movz...,Intel中分别是'movsx'和'movzx'。两个后缀就附在操作码基本名上。例如"使用符号扩展从%al到%edx"的AT&T语句是'movsbl %al,%edx',即从byte到long是bl、从byte到word是bw、从word到long是wl。AT&T语法与Intel语法中转换指令的对应关系见表3-2所示
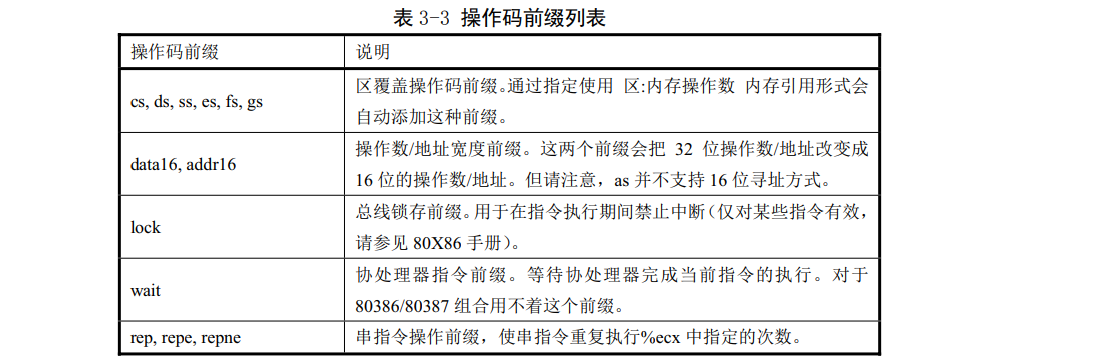
3.2.3.2指令操作码前缀
操作码前缀用于修饰随后的操作码。它们用于重复字符串指令、提供区覆盖、执行总线锁定操作、或指定操作数和地址宽度。通常操作码前缀可作为一条没有操作数的指令独占一行并且必须直接位于所影响指令之前,但是最好与它修饰的指令放在同一行上。例如,串扫描指令'scas'使用前缀执行重复操作:
repne scas %es:(%edi),%al
操作码前缀有表3-3中列出的一些。
3.2.3.3内存引用
Intel语法的间接内存引用形式:
section:[base+index*scale+disp]
对应于如下AT&T语法形式:
section:disp(base,index,scale)
其中base和index是可选的32位基寄存器和索引寄存器,disp是可选的偏移值。scale是比例因子,取值范围是1、2、4、8。(分别是2的0次方,2的1次方,2的2次方、2的3次方)。scale其乘上索引index用来计算操作数地址。如果没有指定scale,则scale取默认值1。section为内存操作数指定可选的段寄存器,并且会覆盖操作数使用的当前默认段寄存器。请注意,如果指定的段覆盖寄存器与默认操作的段寄存器相同,则as就不会为汇编的指令再输出相同的段前缀。以下是几个AT&T和Intel语法形式的内存引用例子:
movl var,%eax #把内存地址var处的内容放入寄存器%eax中。
movl %cs:var,%eax #把代码段中内存地址var处的内容放入%eax中。
movb $0x0a,%es:(%ebx)#把字节值0x0a保存到es段的%ebx指定的偏移处。
movl %var,%eax #把var的地址放入%eax中。
movl array(%esi),%eax #把array+%esi确定的内存地址处的内容放入%eax中。
movl (%ebx,%esi,4),%eax #把%ebx+%esi*4确定的内存地址处的内容放入%eax中
movl array(%ebx,%esi,4),%eax #把array+%ebx+%esi*4确定的内存地址处的内容放入%eax中。
movl -4(%ebp),%eax #把%ebp-4内存地址处的内容放入%eax中,使用默认段%ss
movl foo(,%eax,4),%eax #把内存地址foo+eax*4处内容放入%eax中,使用默认段%ds。
3.2.3.4跳转指令
跳转指令用于把执行点转移到程序另一个位置继续执行下去。这些跳转的目的位置通常使用一个标号来表示。在生成目标代码文件时,汇编器会确定所有带标号的指令的地址,并且把跳转到的指令的地址编码到跳转指令中。跳转指令可以分为无条件跳转和条件跳转两大类。跳转指令将依赖于执行指令时标志寄存器中某个相关标志的状态来确定是否进行跳转,而无条件跳转则不依赖于这些标志。
JMP是无跳转指令,并可分为直接(direct)跳转和间接(indirect)跳转两类,而条件跳转指令只有直接跳转的形式。对于直接跳转指令,跳转到的目标指令的地址作为跳转指令的一部分直接编码进跳转指令中;对于间接跳转指令,跳转的目的位置取自于某个寄存器或某个内存位置中。直接跳转语句的写法是给出跳转目标处的标号;间接跳转语句的写法是必须使用一个星字符'*'作为操作指示符的前缀字符,并且该操作指示符使用movl指令相同的语法。下面是直接和间接跳转的几个例子
jmp NewLoc #直接跳转。无条件直接跳转到标号NewLoc处执行。
jmp *%eax #间接跳转。寄存器%eax的值是跳转的目标位置。
jmp *(%eax) #间接跳转。从%eax指明的地址处读取跳转的目标位置。
同样,与指令计数器PC无关的间接调用的操作数也必须有一个''作为前缀字符。若没有使用''字符,那么as汇编器就会选择与指令计数PC的相关的跳转标号。还有,其他任何具有内存操作数的指令都必须使用操作码后缀('b','w'或'l')指明操作数的大小(byte、word或long)。
3.2.4区与重定位
区(Section)(也称为段、节或部分)用于表示一个地址范围,操作系统将会以相同的方式对待和处理在该地址范围中的数据信息。例如,可以有一个"只读"的区,我们只能从该区中读取数据而不能写入。区的概念主要用来表示编译生成的目标文件(或可执行程序)中的不同的信息区域,例如目标文件中的正文区或数据区。若要正确理解和编制一个as汇编语言程序,我们就需要了解as产生的输出目标文件的格式安排。
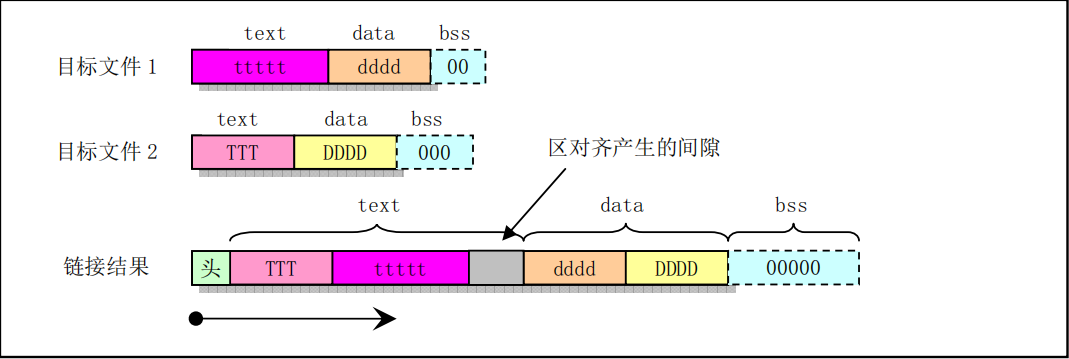
链接器ld会把输入的目标文件的内容按照一定规律组合成一个可执行程序。当as汇编器输出一个目标文件时,该目标文件中的代码被默认设置成从0开始。此后ld将会在链接过程中为不同目标文件中的各个部分分配不同的最终地址位置。ld会把程序中的字节块移动到程序运行时的地址处。这些块时作为固定单元进行移动的。它们的长度以及字节次序都不会被改变。这样的固定单元就被称作是区(或段、部分)。而为区分配运行时刻的地址的操作就被称为重定位(Reclocation)操作,其中包括调整目标文件中记录的地址,从而让它们对应到恰当的运行时刻地址上。
as汇编器输出产生的目标文件中至少具有3个区,分别被称为正文(text)、数据(data)和bss区。每个区都可能是空的。如果没有使用汇编指令把输出放置在'.text'或'.data'区中,这些区会仍然存在,但内容是空的。在一个目标文件中,其text区从地址0开始,随后就是data区,再后面是bss区。
当一个区被重定位时,为了让链接器ld知道哪些数据会发生变化以及如何修改这些数据,as汇编器也会往目标文件中写入所需要的重定位信息。为了执行重定位操作,在每次涉及目标文件中的一个地址时,ld必须知道:
* 目标文件中对一个地址的引用是从什么地方算起的?
* 该引用的字节长度是多少?
* 该地址引用的是哪个区?(地址)-(区的开始地址)的值等于多少?
* 对地址的引用与程序计数器PC(Program-Counter)相关吗?
实际上,as使用的所有地址都可表示为:(区)+(区中偏移)。另外,as计算的大多数表达式都有这种与区相关的特性,在下面说明中,我们使用记号"{secname N}"来表示区secname中偏移N。
除了text、data和bss区,我们还需要了解绝对地址区(absolute区)。当链接器把各个目标文件组合在一起,absolute区中的地址将始终不变。例如,ld会把地址{absolute 0} "重定位"到运行时刻地0处。尽管链接器在链接后绝不会把两个目标文件中的data区安排成重叠地址处,但是目标文件中的absolute区必会重叠而覆盖。
另外还有一种名为"未定义的区(Undefined section)"在汇编时不能确定所在区的任何地址都被设置成{undefined U},其中U将会在以后填上。因为数值总是有定义的,所以出现未定义地址的唯一途径仅涉及未定义的符号。对一个称为公共块(common block)的引用就是这样一种符号:在汇编时它的值未知,因此它在undefined区中。
类似地,区名也用于描述已链接程序中区的组。链接器ld会把程序所有目标文件中的text区放在相邻的地址处。我们习惯上所说的程序的text区实际上是指其所有目标文件text区组合构成的整个地址区域。对程序中data和bss区的理解也同样如此。
3.2.4.1链接器涉及的区
链接器ld只涉及如下4类区
- text区、data区 -- 这两个区用于保存程序。as和ld会分别独立而同等地对待它们。对其中text区的描述也同样适合data区。然而当程序在运行时,则通常text区是不会改变的。text区通常会被进程共享,其中含有指令代码和常数等内容。程序运行时data区的内容通常是会变化的。例如,C变量一般就存放在data区中。
- bss区 --在程序开始运行时这个区中含有0值字节。该区用于存放未初始化的变量或作为公共变量存储空间。虽然程序每个目标文件bss区的长度信息很重要,但是由于该区中存放的是0值字节,因此无须再目标文件中保存bss区。设置bss区的目的就是为了从目标文件中明确地排除0值字节。
- absolute区 --该区的低地址0总是"重定位"到运行时刻地址0处。如果你不想让ld在重定位操作时改变你所引用的地址,那么就使用这个区。从这种观点来看,我们可以把绝对地址称作是"不可重定位的:"在重定位操作期间它们不会改变。
- undefined区 --对不在先前所述各个区对象的地址引用都属于本区。
3.2.4.2子区
汇编取得的字节数据通常位于text或data区中。有时候在汇编源程序某个区中可能分布着一些不相邻的数据组,但是你可以会想让它们在汇编后聚集在一起存放。as汇编器允许你利用子区(subsection)来到达这个目的。在每个区中,可以有编号为0--8192的子区存在。编制在同一个子区中的对象会在目标文件中与该子区中其他对象放在一起。在这种情况下,编译器就可以在每个会输出的代码区之前用'.text 0 '子区,并且在魅族会输出的常数之前使用'.text 1 子区'。
使用子区是可选的。如果没有使用子区,那么所有对象都会放在子区0中。子区会以其从小到大的编号顺序出现在目标文件中,但是目标文件中并不包含表示子区的任何信息。处理目标文件的ld以及其他程序并不会看到子区的踪迹,它们只会看到由所有text子区组成的text区;由所有data子区组成的data区。为了指定随后的的语句被汇编到哪个子区中,可在'.text'表达式或'.data表达式'中使用数值参数。表达式结果应该是绝对值。如果只指定了'.text',那么就会默认使用'.text0'。同样地,'.data'表示使用'.data 0'。每个区都有一个位置计数器(Location Counter),它会对每个汇编进该区的字节进行计数。由于子区仅供as汇编器使用方便而设置的,因此并不存在子区计数器。虽然没有什么直接操作一个位置计数器的方法,但是汇编命令'.align'可以改变其值,并且任何标号定义都会取用位置计数器的当前值。正在执行语句汇编处理的区的位置计数器被称为当前活动计数器。
3.2.4.3bss区
bss区用于存储局部公共变量。你可以在bss区中分配空间,但是在程序运行之前不能再其中放置数据。因为当程序刚开始执行时,bss区中所有字节内容都将被清零。'.lcomm'汇编命令用于在bss区中定义一个符号;'.comm'可用于在bss区中声明一个公共符号。
3.2.5符号
在程序编译和链接过程中,符号(Sysmbol)是一个比较重要的概念。程序员使用符号来命名对象,链接器使用符号进行链接操作,而调试器利用符号进行调试。
标号(Label)后面紧跟随一个冒号的符号。此时该符号代表活动位置计数器的当前值,并且,例如,可作为指令的操作数使用。我们可以使用等号'='给一个符号赋予任意数值。
符号名一个字母或'._'字符之一开始。局部符号用于协助编译器和程序员临时使用名称。在一个程序中共有10个局部符号('0'....'9')可供重复使用。为了定义一个局部符号,只要写出形如'N:'的标号(其中N代表任何数字)。若是引用前面最近定义的这个符号,需要写成'Nb';若需引用下一个定义的局部标号,则需要写成'Nf'。其中'b'意思是向后(backwards),'f'表示向前(forwards)。局部标号在使用方面没有限制,到那时在任何时候我们只能向前/向后引用最远10个局部标号。
3.2.5.1特殊点符号
特殊符号'.'表示as汇编的当前地址。因此表达式'mylab:.long.'就会把mylab定义包含它自己所处的地址值。给'.'赋值就如同汇编命令'.org'的作用。因此表达式'.=.+4'与'.space4'完全相同。
3.2.5.2符号属性
除了名字以外,每个符号都有值"值"和"类型"属性。根据输出的格式不同,符号也可以具有辅助属性。如果不定义就使用一个符号,as就会假设其所有属性均为0.这指示该符号是一个外部定义的符号。
符号的值通常是32位的。对于标出text、data、bss或absolute区中一个位置的符号,其值是从区开始到标号处的地址值。对于text、data和bss区,一个符号的值通常会在链接过程中由于ld改变区的基地址而变化,absolute区中符号的值不会改变。这也是为何称它们是绝对符号的原因。
ld会对未定义符号的值进行特殊处理。如果未定义符号的值是0,则表示该符号在本汇编源程序中没有定义,ld会尝试根据其他链接的文件来确定它的值。在程序使用了一个符号但没有对符号进行定义,就会产生这样的符号。若未定义符号的值不为0,那么该符号值就表示是.comm公共声明的需要保留的公共存储空间字节长度。符号指向该存储空间的第一个地址处。
符号的类型属性含有用于链接器或调试器的重定位信息、指示符号是外部的标志以及一些其他可选信息。对于a.out格式的目标文件,符号的类型存放在一个8位字段中(n_type字节)。
as汇编指令
汇编指令是指示汇编器操作方式的伪指令。汇编命令用于要求汇编器为变量分配空间、确定程序开始地址、指定当前汇编的区、修改位置计数器值等。所有汇编指令的名称都以'.'开始,其余都是字符,并且大小写无关。但是通常都使用小写字符。
3.2.6.1 .align abs-expr1,abs-expr2,abs-expr3
.align是存储对齐汇编命令,用于在当前子区中把位置计数器设置(增加)到下一个指定存储边界处。第1个绝对值表达式abs-expr1(absolute expression)指定要求的边界对齐值。对于使用a.out格式目标文件的80x86系统,该表达式值式位置计数器值增加后其二进制值最右面0值位的个数,即是2的次方值。例如,'.align3'表示把位置计数器值增加到8的倍数上。如果位置计数器值本身就是8的倍数,那么就无需改变。但是对于使用ELF格式的80X86系统,该表达式值就是要求对齐的字节数。例如'.align 8'就是把位置计数器值增加到8的倍数上。
第2个表达式给出用于对齐而填充的字节值。该表达式与其前面的逗号可以省略。若省略,则填充字节值是0。第3个可选表达式abs-expr3用于指示对齐操作允许填充跳过的最大字节数。如果对齐操作要求跳过的字节数大于这个最大值,那么该对齐操作就被取消。若想省略第2个参数,可以在第1和第3个参数之间使用两个逗号。
3.2.6.2 .ascii "string"
从位置计数器所值当前位置位字符串分配空间并存储字符串。可使用逗号分开出多个字符串。例如,'.ascii "Hello world!","My assembler"'。该汇编命令会让as把这些字符串汇编在连续的地址位置处,每个字符串后面不会自动添加0(NULL)字节。
3.2.6.3 .asciz "string"
该命令与‘.ascii’类似,但是每个字符串后面会自动添加NULL字符。
3.2.6.4 .byte expressions
该汇编命令定义0个或多个够好分开的字节值。每个表达式的值是一个字节。
3.2.6.5 .common symbol,length
在bss区中声明要给命名的公共区域。在ld链接过程中,某个目标文件中的一个公共符号会与其他目标文件中同名的公共符号合并。如果ld没有找到一个符号的定义,而只是一个或多个公共符号,那么ld就会分配指定长度length字节的未初始化内存。length必须是一个绝对值表达式。如果ld找到多个长度不同但同名的公共符号,ld就会分配长度最大的空间。
3.2.6.6 .data subsection
该汇编指令通知as把随后的语句汇编到编号为subsection的data子区中。如果省略编号,则默认使用编号0.编号必须是绝对值表达式。
3.2.6.7 .desc symbol,abs-expr
用绝对表达式的值设置符号symbol的描述字段n_desc的16位值。仅用于a.out格式的目标文件。
3.2.6.8 .filrepeat,size,value
该汇编命令会产生数个(repeat个)大小为size字节的重复拷贝。大小值可以为0或某个值,但是若size大于8,则限定为8.每个重复字节内容取自一个8字节数。高4字节为0,低4字节是数值value。这3个参数值都是绝对值,size和value是可选的。如果第2个逗号和value省略,value默认为0值;如果后面两个参数都省略的话,则size默认为1。
3.2.6.9 .global symbol (或者.globl symbol)
该汇编命令会使得链接器ld能看见符号symbol如果在我们的目标中定义了符号symbol,那么它的值将能被链接过程中的其他目标文件使用。若目标文件中没有定义该符号,那么它的属性将从链接过程中其他目标文件的同名符号中获得。这是通过设置符号symbol类型字段中的外部位N_EXT来做到的。
3.2.6.10 .int expressions
该汇编命令在某个区中设置0个或多个整数值(80386系统为4字节,同.long)。每个用逗号分开的表达式的值就是运行时刻的值。例如.int 1234 ,567,0x89AB
3.2.6.11 .lcomm symbol,length
为符号symbol指定的局部公共区域保留长度为length字节的空间。所在的区和符号symbol的值是新的局部公共块的值。分配的地址在bss区中,因此在运行时刻这些字节值被清零。由于符号symbol没有被声明为全局的,因此链接器ld看不见
3.2.6.12 .long expressions
含义与.int相同
3.2.6.13 .octa bignums
这个汇编指令指定0个或多个用逗号分开的16字节大数(.byte,.work,.long,.quad,.octa)分别对应(1、2、4、8和16字节数)
3.2.6.14 .org new_lc,fill
这个汇编命令会把当前区的位置计数器设置为new_lc。new_lc是一个绝对值(表达式),或者是具有相同区作为子区的表达式,也即不能使用.org跨越各区。如果new_lc的区不对,那么.org就不会起作用。请注意,位置计数器是基于区的,即以每个区作为计数起点。
当位置计数器值增长时,所跳跃的字节将被填入值fill。该值必须是绝对值。如果省略了逗号和fill,则fill默认为0值。
3.2.6.15 .quad bignums
这个汇编命令指定00个或多个逗号分开的8字节大数bignum。如果大数放不进8字节中,则取低8个字节。
3.2.6.16 .short expressions(同.word expressions)
这个汇编命令指定0个或多个用逗号分开的8字节大数bignum。如果大数放不进8个字节中,则取低8个字节。
3.2.6.17 .space size,fill
该汇编命令产生size个字节,每个字节填fill。这个参数均为绝对值。如果省略了逗号和fill,那么fill的默认值就是0。
3.2.6.18 .string "string"
定义一个或多个用逗号分开的字符串。在字符串中可以使用转义字符。每个字符串都自动附加一个NULL字符结尾。例如,.string "\n\nStarting","other strings"。
3.2.6.19 .text subsection
通知as把随后的语句汇编进编号为subsection的子区中。如果省略了编号subsection,则使用默认编号值0。
3.2.6.20 .word expressions
对应32位机器,该汇编命令含义与.short相同。
3.2.7编写16位代码
虽然as通常用来编写纯32位的80X86代码,但是1995年后它对编写运行于实模式或16位保护模式的代码也提供有限的支持。为了让as汇编时产生16位代码,需要在运行16位模式的指令语句之前添加汇编命'.code16',并且使用汇编命令'.code32'让as汇编器切换回32位代码汇编方式。
as不区分16位和32位汇编语句,在16位和32位模式下每条指令的功能完全一样而与模式无关。as总是为汇编语句产生32位的指令代码而不管指令将运行在16位还是32位模式下。如果使用汇编命令'.code16'让as处于16位模式下,那么as会自动为所有指令加上一个必要的操作数宽度前缀而让指令运行在16位模式。请注意,因为as为所有指令添加了额外的地址和操作数宽度前缀,所以汇编产生的代码长度和性能上将会受到影响。
由于在1991年开发Linux内核0.11时as汇编器还不支持16位代码,因此在编写和汇编0.11内核实模式下的引导启动代码和初始化汇编程序时使用前面介绍的as汇编器。
3.2.8AS汇编器命令行选项
- -a开启程序列表
- -f快速操作
- -o指定输出的目标文件名
- -R组合数据区和代码区
- -W取消警告信息
3.3C语言程序
3.3.1C程序编译和链接
使用gcc汇编器编译C语言程序时通常会经过四个处理阶段,即预处理阶段、编译阶段、汇编阶段和链接阶段。
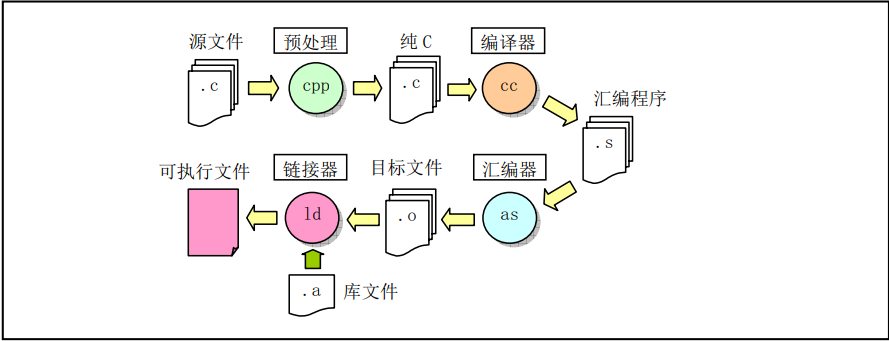
在前处理阶段中,gcc会把C程序传递给C前处理器CPP,对C语言程序中指示符和宏进行替换处理,输出纯C语言代码;在编译阶段,gcc把C语言程序编译生成对应的与机器相关的as汇编语言代码;在汇编阶段,as汇编器会把汇编代码转换成机器指令,并以特定二进制格式输出保存在目标文件中;最后GNUld链接器把程序的相关目标文件组合链接在一起,生成程序的可执行映像文件。调用gcc的命令格式与编译汇编语言的格式类似:
gcc [选项] [-o outfile] infile
其中infile是输入的C语言文件;outfile是编译产生的输出文件。对于某次编译过程,并非一定要全部执行这四个阶段,使用命令行选项可以令gcc编译过程在某个处理阶段后就停止执行。例如,使用'-S'选项可以让gcc在输出了C程序对应的汇编语言之后就停止运行;使用'-c'选项可以让gcc只生成目标文件而不执行链接处理,见如下所下。
gcc -o hello hello.c //编译hello.c程序,生成执行文件hello。
gcc -S hello.s hello.c //编译hello.c程序,生成对应汇编程序hello.s
gcc -c -o hello.o hello.c //编译hello.c程序,生成对应目标文件hello.o而不链接。
在编译像Linux内核这样的包含很多源程序文件的大型程序时,通常使用make工具软件对整个程序的编译过程进行自动管理。
3.3.2
本节介绍内核C语言程序中接触到的嵌入汇编(内联汇编)语句。由于我们通常编制C程序过程中一般很少用到嵌入式汇编代码,因此这里有必要对其基本格式和使用方法进行说明。具有输入和输出参数的嵌入汇编语句的基本格式为:
asm("汇编语句"
:输出寄存器
:输入寄存器
:会被修改的寄存器
);
除第一行以外,后面带冒号的行若不使用就都可以省略。其中,"asm"是内联汇编语句关键词;"汇编语句"是你写汇编指令的地方;"输出寄存器"表示当这段嵌入汇编执行完之后,哪些寄存器用于存放输出数据。此地,这些寄存器分别对应一C语言表达式值或一个内存地址;"输入寄存器"表示在开始执行汇编代码时,这里指定的一些寄存器中应存放的输入值,它们也分别对应着一C变量或常数值。"会被修改的寄存器"表示你已对其中列出的寄存器中的值进行了改动,gcc编译器不能再依赖于它原先对这些寄存器加载的值。如果必要的话,gcc需要重新加载这些寄存器。因为我们需要把那些没有在输出/输入寄存器部分列出,但是在汇编语句中明确使用到或隐含使用到的寄存器名列在这个部分中。
/kernel/traps.c文件中第22行开始的一段代码作为例子来详细解说。为了能看得更清楚一些,我们对这段代码进行重新排列和编号。
#define get_seg_byte(seg,addr)
({
\
register char __res;\ //定义了一个寄存器变量__res。
__asm__("push %%fs;\ //首先保存fs寄存器原值(段选择符)
mov %%ax,%%fs;\ //然后用seg设置fs
movb %%fs:%2,%%al;\ //seg::addr处1字节内容到a1寄存器中。
pop %%fs"\ //恢复fs寄存器原内容
:"=a"(__res) //输出寄存器列表
:"0"(seg),"m"(*(addr)) //输入寄存器列表
")
__res;s})
10行代码定义了一个嵌入汇编语言宏函数。通常使用汇编语句最方便的方式把它们放在一个宏内。用圆括号括住的组合语句(花括号中的语句):"({})"可以作为表达式使用,其中最后一行上的变量__res(第10行)是该表达式的输出值。
因为宏语句需要定义在一行上,因此这里使用反斜杠''将这些语句连城一行。这条宏定义将被替换到程序中引用该宏名称的地方。第一行定义了宏的名称,也即是宏函数名称get_seg_byte(seg,addr)。第3行定义了一个寄存器变量__res。该变量将被保存在一个寄存器中,以便于快速访问和操作。如果想指定寄存器(例如eax),那么我们可以把该局写成"register char __res asm("ax");",其中"asm"也可以写成"asm"。第4行上的"asm"表示嵌入汇编语句的开始。从第4行到第7行的4条语句是AT&T格式的汇编语句。另外,为了让gcc编译产生的汇编语言程序中寄存器名称前有一个百分号"%",在嵌入汇编语句寄存器名称之前就必须写上两个百分号"%%"。
第8行即是输出寄存器,这句的含义是在这段代码运行结束后将eax所代表的寄存器的值放入__res变量中,作为本函数的输出值,"=a"中的"a"称为加载代码,"="表示这是输出寄存器,并且其中的值将被输出值替代。第9行表示在这段代码开始运行时将seg放到eax寄存器中,"0"表示使用与上面同个位置的输出相同的寄存器。而((addr))表示一个内存偏移地址值。为了在上面汇编语句中使用该地址值,嵌入汇编程序规定把输出和输入寄存器统一按顺序编号,顺序是从输出寄存器序列从左到右从上到下以"%0"开始,分别记为%0、%1、...%9。因此,输出寄存器的编号是%0(这里只有一个输出寄存器),输入寄存器前一部分("0"(seg))的编号%1,而后部分的编号是%2。上面第6行上的%2即代表((addr))这个内存偏移量。
现在我们来研究4-7行上的代码的作用。第一句将fs段寄存器的内容入栈;第二句将eax中的段值赋给fs段寄存器;第三句是把fs:(*(addr))所指定的字节放入al寄存器中。当执行完汇编语句后是,输出寄存器eax的值将被放入__res,作为该宏函数(块结构表达式)的返回值。
通过上面分析,我们指定,宏名称中的seg代表一指定的内存值,而addr表示一内存偏移地址量。
asm("cld\n\t"
"rep\n\t"
"stol"
:/*没有输出寄存器*/
:/"c"(count-1),"a"(fill_value),"D"(dest)
:"%ecx","%edi"
);
1-3行这三句是通常的汇编语句,用以清方向位,重复保存值。 其中两行中的字符"\n\t"是用于gcc预处理输出程序列表时能排的整齐而设置的,字符的含义与C语言中的相同。即gcc的运作方式是先产生与C程序对应的汇编程序,然后调用汇编器对其进行编译产生目标代码,如果在写程序和调试程序时想看看C对应的汇编程序,那么就需要得到预处理程序输出的汇编程序结果(这在编写和调试高效的代码时常用的做法)。为了预处理输出的汇编程序格式整齐,就可以使用"\n\t"这两个格式符号。
第4行说明这段嵌入汇编程序没有用到输出寄存器。第5行的含义是:将count-1的值加载到ecx寄存器中(加载代码是C),fill_value加载到eax中,dest放到edi中。为什么要让gcc编译程序取做这样的寄存器值的加载,而不让我们自己做呢?因为gcc在它进行寄存器分配时可以进行某些优化工作。例如fill_value值可能已经在eax中。如果是在一个循环语句中的话,gcc就可能在整个循环操作中保留eax,这样就可以在每次循环中少用一个movl语句。
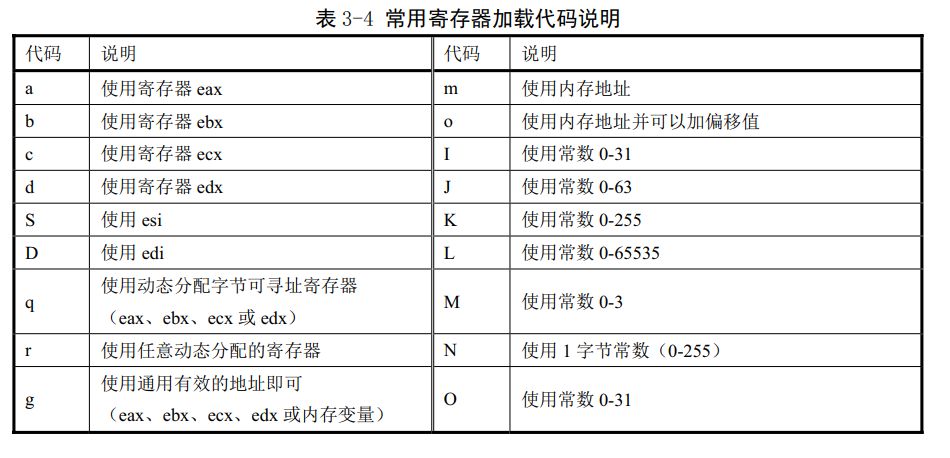
最后一行的作用是告诉gcc这些寄存器中的值已经改变了。在gcc知道你拿这些什么后,能够对gcc的优化操作有所帮助。表3-4中是一些可能用到的寄存器加载代码及其具体的含义。

下面的例子不是让你指定哪个变量使用哪个寄存器,而是让gcc为你选择
asm("leal(%1,%1,4),%0"
:"=r"(y)
:"0"(x));
)
指令"leal"用于计算有效地址,但这里用它进行一些简单计算。第1条汇编语句"leal(r1,r2,4),r3"语句表示r1+r2*4->r3。这个例子可以非常快地将x乘5。其中"%0"、"%1"是指gcc自动分配的寄存器。这里"%1"代表输入值x要放入的寄存器,"%0"表示输出值寄存器。输出寄存器代码前一定要加等于号。如果输入寄存器的代码是0或为空时,则说明使用与相应输出一样的寄存器。所以,如果gcc将r指定位eax的话,那么上面汇编语句的含义即为:
"leal (eax,eax,4),eax"
注意:在执行代码时,如果不希望汇编语句被GCC优化而作修改,就需要在asm符号后面添加关键词volatile,见下面所示。这两种声明的区别在于程序兼容性方面。建议使用后一种声明方式。
asm volatile(........);
或这更详细的说明为
__asm__ __volatile__(.....);
** 关键词volatile也可以放在函数名前来修饰函数,用来通知gcc编译器该函数不会返回。**这样就可以让gcc产生更好一些的代码。另外,对于不会返回的函数,这个关键词也可以避免gcc产生假警告信息。例如mm/memory.c中的如下语句说明函数do_exit()和oom()不会再返回到调用者代码中:
volatile void do_exit(long code);
static inline volatile void oom(void)
{
printk("out of memory\n\r");
do_exit(SIGSEGV);
}
这段代码是从include/string.h文件中文件中摘取的,是strcmp()字符串比较函数的一种实现。同样,其中每行中的"\n\t"是用于gcc预处理程序输出列表好看而设置的。
////字符串1与字符串2的前count字符进行比较
//参数:cs - 字符串1,ct -字符串2,count -比较的字符数。
// %0 - eax(__res)返回值, %1 - edi(cs)串1指针,%2 - esi(ct)串2指针,%3 - ecx(count)。
// 返回:如果串1>串2,则返回1;串1 = 串2,则返回0;串1<串2,则返回-1
extern inline int strncmp(const char* cs,const char char* ct,init count)
{
register int __res; //__res是寄存器变量
__asm__("cld\n //清方向位
"1:\tdecl %3\n\t" //count--。
"js zf\n\t" // 如果count<0,则向前跳转到标号2。
"lodsb\n\t" //取串2的字符ds:[esi]->a1,并且esi++
"scasb\n\t" //比较a1与串1的字符es:[edi],并且edi++
"jne 3f\n\t" //如果不相等,则向前跳转到标号3。
"testb %%al,%%al\n\t" //该字符是NULL字符吗?
"jne 1b\n" //不是,则向后跳转到标号1,继续比较。
"2:\txorl %%eax,%%eax\n\t"//NULL字符,则eax清零(返回值)。
"jmp 4f\n"//向前跳转到标号4,结束。
"3:\tmovl $1,%%eax\n\t" //eax中置1
"jl 4f\n\t"//如果前面比较中串2字符<串1字符,则返回1,结束。
"neg1 %%eax\n" //否则eax = -eax,返回负值,结束。
"4:"
:"=a"(__res):"D".(cs),"S" (ct),"c"(count):"si","di","cx")
return __res; //返回比较结果。
}
3.3.3圆括号中的组合语句
花括号对"{...}"用于把变量声明和语句组合成一个复合语句(组合语句)或一个语句块,这样在语义上这些语句就等同于一条语句。组合语句的右花括号后面不需要使用分号。圆括号中的组合语句,即形如"({....})"的语句,可以在GNU C中用作一个表达式使用。这样就可以在表达式中使用loop、switch语句和局部变量,因此这种形式的语句通常称为语句表达式。语句表达式具有如下示例的形式:
({
int y = foo();int z;
if(y>0) z = y;
else z = -y
3+z;
})
其中组合语句中最后一条语句必须市后面跟随一个分号的表达式。这个表达式("3+z")的值即用作整个圆括号括住语句的值。如果最后一条语句不是表达式,那么整个语句表达式就具有void类型,因此没有值。另外,这种表达式中语句声明的任何局部变量都会在整个语句结束后失效。这个示例语句可以像如下形式的赋值语句来使用:
res = x + ({略...})+b
当然,人们通常不会像上面这样写语句,这种语句表达式通常都用来定义宏。例如内核源代码init/main.c程序中读取CMOS时钟信息的宏定义:
#define CMOS_READ(addr)({{
\最后反斜杠起连接两行语句的作用
outb_p(0x80|addr,0x70)\ //首先向I/O端口0x70输出欲3读取的位置addr。
intb_p(0x71);\ //然后从端口0x71读入该位置处的值作为返回值。
})
再看一个include/asm/io.h头文件中的读I/O端口port的宏定义,其中最后变量_v的值就是inb()的返回值。
#define inb(port)({\
unsigned char_v;\
__asm__volatile("inb %%dx,%%al":"=a"(_v):"d"(port);\
_v;\
})
3.3.4寄存器变量
GNU对C语言的另一个扩充是允许我们把一些变量值放到CPU寄存器中,即所谓寄存器变量。这样CPU就不用经常花费较长时间访问内存去取值。寄存器变量可以分为2种:全局变量寄存器变量和局部寄存器变量。全局寄存器变量会在程序的整个运行过程种保留寄存器专门用于几个全局变量。相反,局部寄存器不会保留指定的寄存器,而仅在内嵌asm汇编语句种作为输入或输出操作数时使用专门的寄存器。gcc编译器的数据流分析功能本身有能力确定指定的寄存器何时含有正在使用的值,何时可派其他用场。当gcc数据流分析功能认为存储在某个局部寄存器变量值无用时就可能会删除之,并且对局部寄存器变量的引用也可能被删除、移动或简化。因此,若不想让gcc作这些优化改动,最好在asm语句种加上volatitle关键词。
如果想在嵌入汇编语句中把汇编指令的输出直接写到指定的寄存器中,那么此时使用局部寄存器变量就很方便。由于Linux内核中通常只使用局部寄存器变量,因此这里我们只对局部寄存器变量的使用方法进行讨论。在GNU C程序中我们可以在函数中用如下形式定义一个局部寄存器变量:
register int res __asm__("ax")
这里ax是变量res所希望使用的寄存器。定义这样一个寄存器变量并不会专门保留这个寄存器不派其他用途。在程序编译过程中,当gcc数据流控制去欸的那个变量的值已经不用时就可能将该寄存器派作其他用途,而且对它的引用可能会被删除、移动或被简化。另外,gcc并不保证编译出的代码会把变量一致放在指定的寄存器中。因此在嵌入汇编指令的部分最好不要明确地引用该寄存器并且假设该寄存器肯定引用的是该变量值。然而把该变量用作为asm的操作数还是能够保证指定的寄存器被用作该操作数。
3.3.5内联函数
在程序中,通过把一个函数声明为内联(inline)函数,就可以让gcc把函数的代码集成到调用该函数的代码中去。这样处理可以去掉函数调用时进入/退出时间开销,从而肯定能够加快执行速度。因此把一个函数声明为内联函数的主要目的就是能够尽量快速的执行函数体。另外,如果内联函数中有常数值,那么在编译期间gcc就可能用它进行一些简化操作,因此并非所有内联函数的代码都会被嵌入进去。内联函数方法对程序代码的长度影响并不明显。使用内联函数的程序编译产生的目标代码可能会长一些也可能会短一些,这需要根据具体情况来定。
内联函数嵌入调用者代码中的操作是一种优化操作,因此只有进行优化编译才会执行代码嵌入处理。若编译过程中没有使用优化选项"-O",那么内联函数的程序编译产生的目标代码可能会长一些也可能会短一些,这需要根据具体情况来定。
内联函数嵌入调用者代码中的操作是一个优化操作,因此只有进行优化编译时才会执行代码嵌入处理。。若编译过程中没有使用优化选项"-O",那么内联函数的代码就不会被真正地嵌入到调用这代码中,而是只作为普通函数调用来处理。把一个函数声明为内联函数的方法是在函数声明中使用关键词"inline",例如内核文件/fs/inode.c的如下函数:
inline int inc(int *a)
{
(*a)++;
}
函数中的某些语句用法可能会使得内联函数的替换操作无法正常进行,或者不适合进行替换操作。例如使用了可变参数、内存分配函数mallocca()、可变长度数据类型变量、非局部goto语句、以及递归函数。编译时可以使用选项 -Winline 让gcc对标志成inline但不能被替换的函数给出警告信息以及不能替换的原因。
当在一个函数定义中既使用inline关键词、又使用static关键词,即像下面文件fs/inode.c中的内联函数定义一样,那么如果所有对该内联函数的调用都被替换而集成在调用者代码中,并且程序中没有引用过该内联函数的地址,则该内联函数自身的汇编代码就不会被引用过。在这种情况下,除非我们在编译过程中使用选项 -fkeep-inline-functions,否则gcc就不会再为该内联函数定义之前的调用语句。是不会被替换集成的,并且也都不能是递归定义的函数。如果存在一个不能被替换集成的调用,那么内联函数就会像平常一样被编译成汇编代码。因为对内联函数地址的引用时不能被替换的。
static inline void wait_on_inode(struct m_inode* inode)
{
cli();
while(inode->i_lock)
sleep_on(&inode->i_wait)
sti();
}
请注意,内联函数功能已经被包括在ISO标准C99中,但是该标准定义的内联函数与gcc定义的有较大区别。ISO标准C99的内联函数语义定义等同于这里使用组合关键词inline和static的定义,即"省略"了关键词static。若在程序需要使用C99标准的语义,那么就需要使用编译选项 -std=gnu99。不过为了兼容起见,在这中情况下还是最好使用inline和static组合。以后gcc将最终默认使用C99的定义,在希望仍然使用这里定义的语义,就需要使用选项 -std=gnu89来指定。
若一个内联函数的定义没有使用关键词static,那么gcc就会假设其他程序文件中也对这个函数有调用。因为一个全局符号只能被定义一次,所以该函数就不能再在其他源文件中进行定义。因此这里对内联函数的调用就不能被替换集成。因此,一个非静态的内联函数总是会被编译出自己的汇编代码来。在这方面,ISO标准C99对不使用static关键词的内联函数定义等同于这里使用static关键词的定义。
如果在定义一个函数时同时指定了inline和extren关键词,那么该函数定义仅用于内联集成,并且在任何情况下都不会单独产生该函数自身的汇编代码,即使明确了引用了该函数的地址也不会产生。这样的一个地址会变成一个外部引用,就好像你仅仅声明了函数而没有定义函数一样。
关键词inLine和extern组合在一起的作用几乎类同一个宏定义。使用这种组合方式就是把带有组合关键词的一个函数定义放在.头文件中,并且不含关键词的另一个相同函数定义放在一个库文件中。此时头文件中的定义会让绝大多数对函数的调用被替换嵌入。如果还没有被替换的对该函数的调用,那么就会使用(引用)程序文件中或库中的拷贝。
Linux 0.1x内核源代码中文件 include/string.h、lib/strings.c就是这种使用方式的一个例子。例如string.h定义了如下函数:
//将字符串(src)拷贝到另一个字符串(dest),直到遇到NULL字符后停止。
//参数dest - 目的字符串指针,src - 源字符串指针 %0 -esi(src),%1 -edi(dest)
extern inline char * strcpy(char* dest,const char *src)
{
__asm__(
"cld\n" //清方向位。
"1:\tlodsb\n\t" //加载DS:[esi]处1字节->al,并更新esi。
"stosb\n\t" //存储字节al->ES:[edi],并更新edi
"testb %%al,%%al\n\t" //刚存储的字节是0?
"jne 1b" //不是则向后跳转到标号1处,否则结束。
::"S"(src),"D"(dest):"si","di","ax");
return dest //返回目的字符串指针。
}
而在内核函数库目录中,lib/string.c文件把关键词inline和extern都定义为空,见如下所示。因此实际上就在内核函数库中又包含了string.h文件所有这类函数的一个拷贝,即又对这些函数重新定义了一次,并且"消除"了两个关键词的作用。
#define extern //定义为空
#define inline //定义为空
#define LIBRARY
#include <string.h>
此时库函数重新定义的上述strcpy()函数变成如下形式:
char * strcpy(char* dest,const char *src)
{
__asm__("cld\n" //清方向位置
"1:\tlodsb\n\t"//加载DS:[esi]处1字节->a1,并更新esi
"stosb\n\t"//存储字节al->ES:[edi],并更新edi
"testb %%al,%%al\n\t"//刚存储的字节是0?
"jne 1b" //不是则向后跳转到标号1处,否则结束
::"S"(src),"D"(dest):"si","di","ax");
return dest//返回目的字符串指针
}
3.4C与汇编程序的相互调用
为了提高代码执行效率,内核源代码中有地方直接使用了汇编语言编制。这就会涉及到在两种语言编制的程序之间相互调用问题。本节首先说明C语言函数的调用机制,然后使用两者函数之间的调用方法。
3.4.1C函数调用机制
在Linux内核程序boot/head.s执行完基本初始化操作之后,就会跳转去执行init/main.c程序。那么head.s程序是如何把执行控制转交给init/main.c程序的呢?即汇编程序是如何调用执行C语言程序的?这里我们首先描述一下C函数的调用机制、控制权传递方式,然后说明head.d程序跳转到C程序的方法。
函数调用操作包括从一块代码到另一块代码之间的双向数据传递和执行控制转移。数据传递通过函数参数和返回值来进行。另外,我们还需要在进入函数时为函数的局部变量分配存储空间,并且在退出函数时收回这部分空间。Intel80x86CPU为控制传递提供了简单的指令,而数据的传递和局部变量存储空间的分配与回收则通过栈操作来实现。
3.4.1.1栈帧结构和控制转移权方式
大多数CPU上的程序实现使用栈来支持函数调用操作。栈被用来传递函数参数、存储返回信息、临时保存寄存器原有值以备恢复以及存储局部数据。单个函数调用操作所使用的栈部分被称为栈帧(Stack frame)结构,栈帧结构的两端由两个指针来指定。寄存器ebp通常用作帧指针(frame pointer),而esp则用作栈指针(stack pointer)。在函数执行过程中,栈指针esp会随着数据的入栈和出栈而移动,因此函数中对大部分数据的访问都基于帧指针ebp进行。
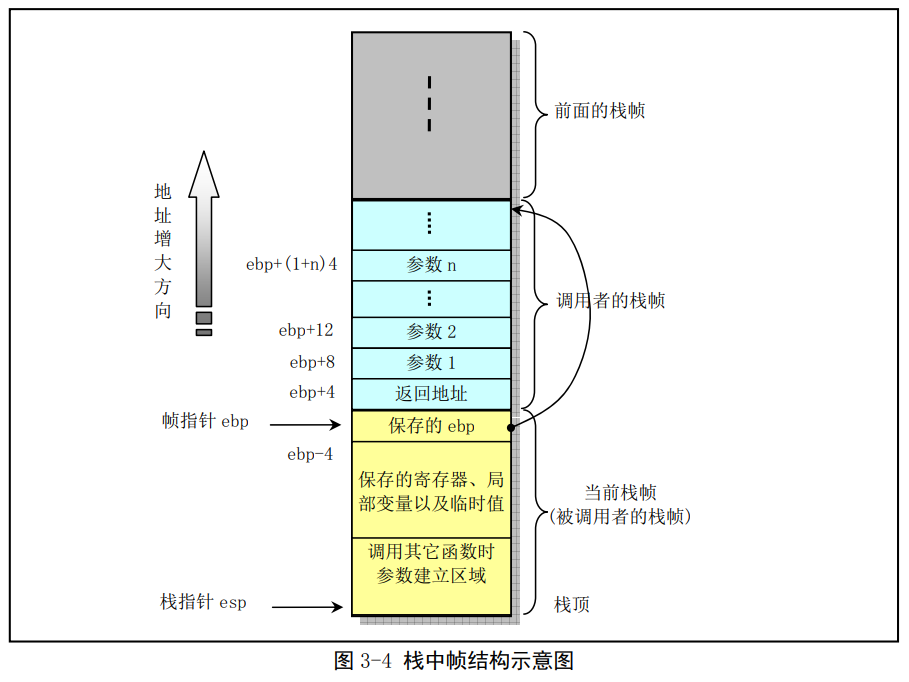
对于函数A调用函数B的情况,传递给B的参数包含在A的栈帧中。当A调用B时,函数A的返回地址(调用返回后继续执行的指令地址)被压入栈中,栈中该位置也明确指明了A栈的结束处。而B的栈帧则从随后的栈部分开始,即图中保存帧指针(ebp)的地方开始。再随后则用于存放任何保存的寄存器值以及函数的临时值。
B函数同样也使用栈来保存不能放寄存器中的局部变量值。例如由于通常CPU的寄存器数量有限而不能够存放函数的所有局部数据,或者有些局部变量是数组或结构,因此必须使用数组或结构引用来访问。还有就是C语言的地址操作符'&'被应用到一个局部变量上时,我们就需要为该变量生成一个地址,即为变量的地址指针分配一空间。最后,B函数会使用栈来保存调用任何其它函数的参数。
栈是往低(小)地址方向扩展的,而esp指向当前栈顶处的元素。通过使用push和pop指令我们可以把数据压入栈中或从栈中弹出。对于没有指定初始值的数据所需要的存储空间,我们可以通过帧指针递减适当的值来做到。类似的,通过增加栈指针值我们可以回收栈中已分配的空间。
指令CALL和Ret用于处理函数调用和返回操作。调用指令CALL的作用是把返回地址压入栈中并且跳转到被调用函数开始处执行。返回地址是程序中紧随调用CALL后面一条指令的地址。因此当被调用函数返回时就会从该位置继续执行。返回RET指令用于弹出栈顶处的地址并跳转到该地址处。在使用该指令之前,应该先正确处理栈中内容,使得当前栈指针所指位置内容正是先前CALL指令保存的返回地址。
另外,若返回值是一个整数或一个指针,那么寄存器eax将被默认用来传递返回值。
尽管某一时刻只有一个函数在执行,但我们还是需要确定在一个函数(调用者)调用其他函数(被函数者)时,被调用者不会修改或覆盖调用者今后用到的寄存器内容。因此IntelCPU采用了所有函数必须遵守的寄存器用法统一惯例。该惯例指明,寄存器eax、edx、和ecx的内容必须由调用者自己负责保存。当函数B被A调用时,函数B可以在不用保存这些寄存器内容的情况下任意使用它们而不会毁坏函数A所需要的任何数据。另外,寄存器ebx、esi和edi的内容则必须由被调用者B来保护。当被调用者需要使用这些寄存器中的任何一个时,必须首先在栈中保存其内容,并在退出时恢复这些这些寄存器的内容。因为调用者A(或者一些更高的函数)并不负责保存这些寄存器内容,但可能在以后的操作中还需要用到原先的值。还有寄存器ebp和esp也必须遵守第二个惯例用法。
3.4.1.2函数调用举例
作为一个例子,我们来观察下面C程序exch.c中函数调用的处理过程。该程序交换两个变量中的值,并返回它们的差值。
void swap(int* a,int* b)
{
int c;
c = *a;
*a = *b;
*b = c;
}
int main()
{
int a,b;
a = 16;
b = 32;
swap(&a,&b);
return(a-b);
}
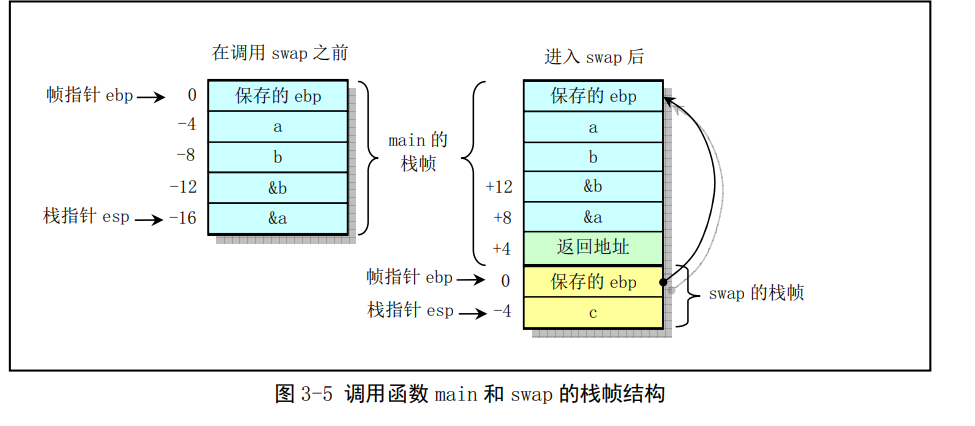
其中函数swap()用于交换两个变量的值。C程序的主程序main()也是一个函数(将在下面说明),它在调用swap()之后返回交换的结果。这两个函数的栈帧结构见图。可以看出,函数swap()从调用者(main())的栈帧中获取其参数。图中的位置信息相对于寄存器ebp中的帧指针。栈帧左边的数字指出了相对于帧指针的地址偏移值。在像gdb这样的调试器中,这些数值都用2的补码表示。例如'-4'被表示成'0xFFFFFFFC','-12'会被表示成'0xFFFFFFF4'
调用者main()的栈帧结构中包括局部变量a和b的存储空间,相对于帧指针位于-4和-8偏移处。由于我们需要为这两个局部变量生成地址,因此它们必须保存在栈中而非简单地存放在寄存器中。
.text
_swap
pushl %ebp #保存原ebp值,设置当前函数的帧指针。
movl %esp,%ebp
subl $4,%esp #为局部变量c在栈内分配空间
movl 8(%ebp),%eax #取函数第1个参数,该参数是一个整数类型值的指针。
movl (%eax),%ecx #取该指针所指位置的内容,并保存到局部变量c中。
movl (%ecx),-4(%ebp)
movl 8(%ebp),%eax #再次取第1个参数,然后取第2个参数
movl 12(%ebp),%edx
movl(%edx),%ecx
movl %ecx,(%eax)
movl 12(%ebp),%eax #再取第2个参数。
movl -4(%ebp),%ecx #然后把局部变量c中的内容放到这个指针所指位置处。
movl %ecx,(%eax)
leave $恢复原ebp、esp值(即movl %ebp,%esp;popl %ebp)
ret
_main
pushl %ebp #保存原ebp值,设置当前函数的帧指针
movl %esp,%ebp
subl $8,%esp #为整型局部变量a和b在栈中分配空间
movl $16,-4(%ebp)
movl $32,-8(%ebp)
leal -8(%ebp),%eax #外调用swap()函数作准备,取局部变量b的地址。
pushl %eax #作为调用的参数并压入栈中。即先压入第2个参数。
call _swap #调用函数swap()
movl -4(%ebp),%eax #取第1个局部变量a的值,减去第2个变量b的值
movl -8(%ebp),%eax
leave #恢复原ebp、esp值(即movl %ebp,%esp;popl %ebp;)
ret
这两个函数均可以划分成三个部分:"设置",初始化栈帧结构;"主题",执行函数的实际计算操作;"结束",恢复栈状态并从函数中返回。对于swap()函数,其设置部分代码是3--5行。前两行用来设置保存调用者的帧指针和设置本函数的的栈帧指针,第5行通过把栈指针esp下移4字节为局部变量c分配空间。第6--15行是swap函数的主题部分。第6--8用于取调用者的第一个参数&a,并以该参数作为地址取所有内容到ecx寄存器中,然后保存到为局部变量分配的空间中(-4(%ebp)。)第9--12行用于取第2个参数&b,并以该参数值作为地址取其内容放到第1个参数指定的地址处。第13--15行把保存在临时局部变量c中的值存放到第2个参数指定的地址处。最后16--17行是函数结束部分。leave指令用于处理栈内容以准备返回,它的作用等价于下面两个指令
movl %ebp,%esp #恢复原esp的值(指向栈帧开始处)
popl %ebp #恢复原ebp的值(通常是调用者的帧指针)。
这部分代码恢复了在进入swap()函数时寄存器esp和ebp的原有值,并执行返回指令ret。
第19--21行时main()函数的设置部分,在保存和重新设置帧指针后,main()为局部变量a和b在栈中分配了空间。第22-23行为这两个局部变量赋值。从24-28行可以看出main()中是如何调用swap()函数的。其中首先使用leal指令(取有效地址)获得变量b和a的地址并分别压入栈中,然后调用swap()函数。变量地址压入栈中的顺序正好与函数申明的参数顺序相反。即函数最后一个参数首先压入栈中,而函数的第1个参数则是最后一个在调用函数指令callz之前压入栈中。第29--30两行将两个已经交换过的数字相减,并放在eax寄存器中作为返回值。
从以上分析可知,C语言在调用函数时是在堆栈上临时存放被调函数参数的值,即C语言是传值类语言,没有直接的方法可用来在被调用函数中修改调用者变量的值。因此为了达到修改的目的就需要向函数传递变量的指针(即变量的地址)。
3.4.1.3main()也是一个函数
上面这段汇编程序是gcc 1.40编译产生的,可以看出其中有几行多余的代码。可见当时的gcc编译器还不能产生最高效率的代码,这也是为什么某些关键代码需要直接使用汇编语言编制的原因。另外,上面提到c程序的主程序main()也是一个函数。这是因为在编译链接时它将会作为ctr0.s汇编程序的函数被调用。crt0.s是一个桩(stub)程序,名称中的"crt"是"C run-time"的缩写。该程序的目标文件将被链接在每个用户执行程序的开始部分,主要用于设置一些初始化全局变量等。Linux0.11中crt0.s汇编程序中见如下所示。其中建立并初始化全局变量_environ供程序中其它模块使用。
.text
.global _environ #声明全局变量 _environ(对应C程序中的environ变量)
__entry #代码入口标号
movl 8(%esp),%eax#取程序的环境变量指针envp并保存在__environ中。
movl %eax,_environ #envp是execve函数在加载执行文件时设置的。
call _main #调用我们的主程序。其返回状态值在eax寄存器中。
pushl %eax #压入返回值为exit()函数的参数并调用该函数。
call _exit
jmp lb
.data
_environ #定义变量_environ,为其分配一个长字空间
.long 0
通常使用gcc编译链接生成执行文件时,gcc会自动把该文件的代码作为第一个模块链接在可执行程序中。在编译时使用显示详细信息选项'-v'就可以明显地看出这个链接操作过程:
[/usr/root]# gcc -v -o exch exch.s
gcc version 1.40
/usr/local/lib/gcc-as -o exch.o exch.s
/usr/local/lib/gcc-ld -o exch /usr/local/lib/crt0.o exch.o /usr/local/lib/gnulib -lc
/usr/local/lib/gnulib
[/usr/root]#
因此在通常的编译过程中我们无需特别指定stub模块crt0.o,但是若想从上面给出的汇编程序手工使用ld(gld)从exch.o模块俩链接产生可执行文件exch,那么我们就需要在命令行上特别指明crt0.o这个模块,并且链接的顺序应该是crt0.o所有程序模块、库文件。"
为了使用ELF格式的目标文件以建立共享库模块文件,现在的gcc编译器(2.x)已经把这个crt0扩展成几个模块:crt1.o、crti.o、crtbegin.o、cretend.o和crtn.o这些模块的链接顺序为"crtl.o、crti.o、crtbegin.o(crtbeginS.o)"、所有程序模块、crtend.o(crtendS.o)、crtn.o、库模块文件"。gcc的配置文件specfile指定了这种链接顺序。其中ctrl.o、crti.o和crtn.o由C库提供,是C程序的"启动"模块;crtbegin.o和crtend.o是C++语言的启动模块,由编译器gcc提供;而ctrl.o则与crt0.o的作用类似,主要用于调用main()之前做一些初始化工作,全局符号__start就定义在这个模块中。
crtbegin.o和crtend.o主要用于C++语言在.ctors和.dtors区中执行全局构造器(constructor)和析构器(destructor)函数。crtbeginS.o和crtendS.o的作用与前两者类似,但用于创建共享模块中。crti.o用于在.init区中执行初始化函数init()。.init区中包含进程的初始化代码,即当前程序开始执行时,系统在调用main()之前先执行.init中的代码。crtn.o则用于在.fini区中执行进程终止退出处理函数fini()函数,即当程序正常退出时(main()返回之后),系统会安排执行.fini中的代码。
boot/head.s程序中第136--140行就是用于为跳转到init/main.c中的main()函数作准备工作。第139行上的指令在栈中压入了返回地址,而第140行则压入了main()函数代码的地址。当head.s最后在第218行上执行ret指令时就会弹出main()的地址,并把控制权转移到init/main.c程序中。
3.4.2在汇编程序中调用C函数
在汇编程序中调用一个C函数时,程序需要首先按照逆向顺序把函数参数压入栈中,即函数最后(最右边的)一个参数先入栈,而最左边的第1个参数在最后调用指令之前入栈,见图3-6所示。然后执行CALL指令去执行被调用的函数。在调用函数返回后,程序需要再把先前压入栈中的参数清楚掉。
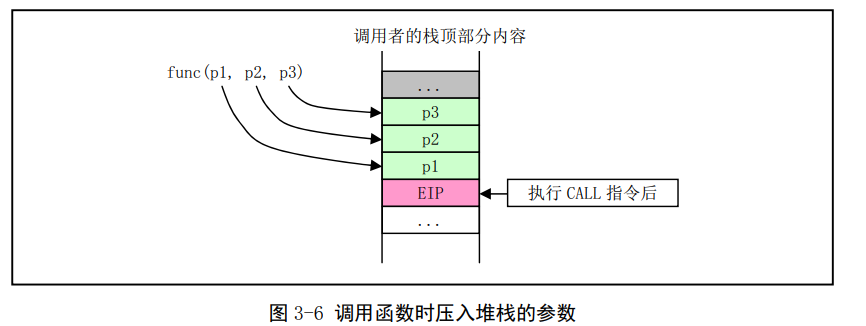
在执行CALL指令时,CPU会把CALL指令下一条指令的地址压入栈中(见图中EIP)。如果调用还涉及到代码特权级变化,那么CPU还会进行堆栈切换,并且把当前堆栈指针、段描述符和调用参数压入新堆栈中。由于Linux内核中只使用中断门和陷阱门方式处理特权级别变化时的调用情况,并没有使用CALL指令来处理特权变化的情况,因此这里对特权级别变化时的CALL指令使用方式不再进行说明。
汇编中调用C函数比较"自由"。只要是在栈中适当位置的内容就可以作为参数供C函数使用。这里仍然以图3-6中具有3个参数的函数调用为例,如果我们没有专门为调用函数func压入参数就直接调用它的话,那么func()函数仍然会把EIP位置以上的栈中其他内容作为自己的参数使用。如果我们为调用func()仅仅明确地压入了第1、第2个参数,那么func()函数的第3个参数p3就会直接使用p2前的栈中内容。在Linux0.1x内核代码中国就有几处使用了这种方式。例如在kernel/system_call.s汇编程序中第217行上调用copy_process()函数(kernel/fork.c中第68行)的情况。在汇编程序函数__sys_fork中虽然把5个参数压入栈中,但是copy_process()却共带有多达17个参数,见下面所示:
//kernel/system_call.s汇编程序_sys_fork部分
212 push%gs
213 pushl %esi
214 pushl %edi
215 pushl %ebp
216 pushl %eax
217 call _copy_process #调用C函数copy_process()(kernel/fork.c,68)
218 addl $20,%esp #丢弃这里所有压栈内容。
219 ret
//kernel/fork.c程序
68 int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,long ebx,long ecx,long edx,long fs, long es,long ds,long eip,long cs,long eflags,long esp,long ss)
我们知道参数越是最后入栈,它越是靠近C函数参数左侧。因此实际上调用copy_process()函数之前入栈5个寄存器值就是copy_process()函数的最左面的5个参数。按顺序它们分别对应为入栈的eax(nr)、ebp、edi、esi和寄存器gs的值。而随后的其余参数实际上直接对应堆栈上已有的内容。这些内容是进入系统调用中断处理过程开始,直到调用本系统调用处理过程时逐步入栈的各寄存器的值。
参数none是system_call.s程序第94行上利用地址跳转表sys_call_table调用_sys_fork时的下一条指令的返回地址。随后的参数是刚进入system_call时在83-88行压入栈的寄存器ebx、ecx、edx和段寄存器fs、es、ds。最后5个参数是CPU执行中断指令压入返回地址eip和cs、标志寄存器eflags、用户栈地址esp和ss。因为系统调用涉及到程序特权级别变化,所以CPU会把标志寄存器值和用户栈地址也压入了堆栈。在调用C函数copy_process()返回后,_sys_fork也只把自己压入5个参数丢掉,栈中其他还均保存着。其它采用上述用法的函数还有kernel/signal.c中的do_signal()、fs/exec.c中的do_execve(),请自己分析。
另外,我们说汇编程序调用C函数比较自由的另一个原因是我们可以根本不用CALL指令而采用JMP指令同样到达调用函数的目的。方法是在参数入栈后人工把下一条要执行的指令地址压入栈中,然后直接使用JMP指令跳转到被调用函数开始地址处去执行函数。此后当函数执行完成时就会执行RET指令把我们人工压入栈中的下一条指令地址弹出,作为函数返回的地址。Linux内核中也有多处用到了这种函数调用方法,例如kernel/asm.s程序第62行调用执行了trap.c中的do_int3()函数的情况。
3.4.3在程序中调用汇编函数
从C程序调用汇编程序函数的方法与汇编程序中调用C函数的原理相同,但Linux内核程序中不常使用。调用方法的着重点仍然是对函数参数在栈中位置的确定上。当然,如果调用的汇编语言程序比较短,那么就可以直接在C程序中使用上面的介绍测内联汇编语句来实现。以下我们以一个示例来说明编制这类程序的方法。包含两个函数的汇编程序callees.s见如下所示。
/*
本汇编程序利用系统调用sys_write()实现显示函数 int mywrite(int fd,char* buf,int count)函数 int myadd(int a,int b,int* res)用于执行a+b=res运算。若函数返回0,则说明溢出。
注意:如果在现在的Linux系统(例如RedHat 9)下编译,则请去掉函数名的下划线'_'
*/
SYSWRITE = 4 #sys_write()系统调用号
.global _mywrite, _myadd
.text
_mywrite
pushl %ebp
movl %esp,%ebp
pushl %ebp
movl 8(%ebp),%ebx #取调用者第1个参数:文件描述符fd
movl 12(%ebp),%ecx #取第2个参数:缓冲区指针
movl 16(%ebp),%edx #取第三个参数:显示字符数。
movl $SYSWRITE,%eax #%eax中放入系统调用号4
int $0x80 #执行系统调用
popl %ebx
movl %ebp,%esp
popl %ebp
ret
_myadd
pushl %ebp
movl %esp,%ebp
movl 8(%ebp),%eax #取第1个参数a。
movl 12(%ebp),%edx #取第2个参数b。
xorl %ecx,%ecx #%ecx为0表示计算溢出。
addl %eax,%edx #执行加法运算
jo lf #若溢出则跳转
movl 16(%ebp),%eax #取第3个参数的指针
movl %edx,(%eax) #把计算结果放入指针所指位置处
incl %ecx #没有发生溢出,于是设置无溢出返回值
movl %ecx,%eax #%eax中是函数返回值
movl %ebp,%esp
popl %ebp
ret
该汇编文件中的第1个参数mywrite()利用系统中断0x80系统调用sys_write(int fd,char* buf,int count)实现在屏幕上显示信息。对应的系统调用功能号是4(参见include/unistd.h),三个参数分别为文件描述符、显示缓冲区指针和显示字符数。在执行int 0x80之前,寄存器%eax中需要放入调用功能号(4),寄存器%ebx、%ecx和%edx要按调用规定分别存放fd、buf和count。函数mywrite()的调用参数个数与sys_write()完全一样。
第2个函数myadd(int a,int b,int *res)执行加法运算。其中参数res是运算的结果。函数返回值用于判断是否发生溢出。如果返回值为0表示计算已发生溢出,结果不可用。否则计算结果将通过参数res返回给调用者。
注意:如果在现在Linux系统(例如RedHat 9)下编译callee.s程序,则请去掉函数名前的下划线'_'。调用这两个函数的C程序cller.c见如下所示
/*
调用汇编函数mywrite(fd,buf,count)显示信息;调用myadd(a,b,result)执行加法运算。如果myadd()返回0,则表示加函数发生溢出。首先显示开始计算信息,然后显示运算结果。
*/
int main()
{
char buf[1024];
int a, b,res;
char* mystr="Calculating....\n"
char* emsg = "Error in adding\n"
a = 5;
b = 10;
mywrite(1,mystr,strlen(mystr));
if(myadd(a,b,&res))
{
sprintf(buf,"The result is %d \n",res)
}
else
{
mywrite(1,emsg,strlen(emsg));
}
return 0 ;
}
该函数首先利用汇编函数利用mywrite()在屏幕上显示开始计算的信息"Calculating....",然后调用加法计算汇编函数myadd()对a和b两个数进行运算,并在第3个参数res中返回计算结果。最后再利用mywrite()函数把格式化过的结果信息字符串显示在屏幕上。如果函数myadd()返回0,则表示加函数发生溢出,计算结果无效。这两个文件的编译和运行结果
[/usr/root]# as -0 callee.o callee.s
[/usr/root]# gcc -o caller caller.c callee.o
[/usr/root]# ./caller
Calculating...
The result is 15
[/usr/root]#
3.5Linux0.11目标文件格式
为了生成内核代码文件,Linux0.11使用了两种编译器。第一种是汇编编译器as86和相对应的链接程序(或称为链接器)ld86。它们专门用于编译和链接运行在实地址模式下的16位内核引导扇区程序bootsect.s和设置程序setup.s第二种是GNU的汇编器as(gas)和C语言编译器gcc以及相对应的链接程序gld。编译器用于为源程序文件产生对应的二进制代码和数据目标文件。链接程序用于对相关的所有目标文件进行组合处理,形成一个可被内核加载执行的目标文件,即可执行文件。
本节首先简单说明编译器产生的目标文件结构,然后描述链接器如何把需要链接在一起的目标文件模块组合在一起,以生成二进制可执行映像文件或一个大的模块文件。最后说明Linux0.11内核二进制代码文件Image的生成原理和过程。这里给出了Linux0.11内核所支持的a.out目标文件格式的信息。as86和ld86生成的MINIX专门的目标文件格式,我们将涉及这种格式的内核创建工具一章中给出。
为了便于描述,这里把编译器生成的目标文件称为目标模块文件(简称模块文件),而把链接程序输出产生的可执行目标文件称为可执行文件。并且它们都统称为目标文件。
3.5.1目标文件格式
在Linux0.11系统中,GNU gcc或 gas编译输出的目标模块文件和链接程序所生成的可执行文件使用了UNIX传统的a.out格式。这是一种被称为汇编或链接输出(Assembly& linker editor output)的目标文件格式。对于具有内存分页机制的系统来说,这是一种简单有效的目标文件个是。a.out文件有一个文件头和随后的代码区(Text section ,也称为正文段)、已初始化数据区(Data section,也称为数据段)、重定位信息区、符号表以及符号名字符串构成,见下图其中代码区和数据区通常也分别称为正文段(代码段)和数据段。
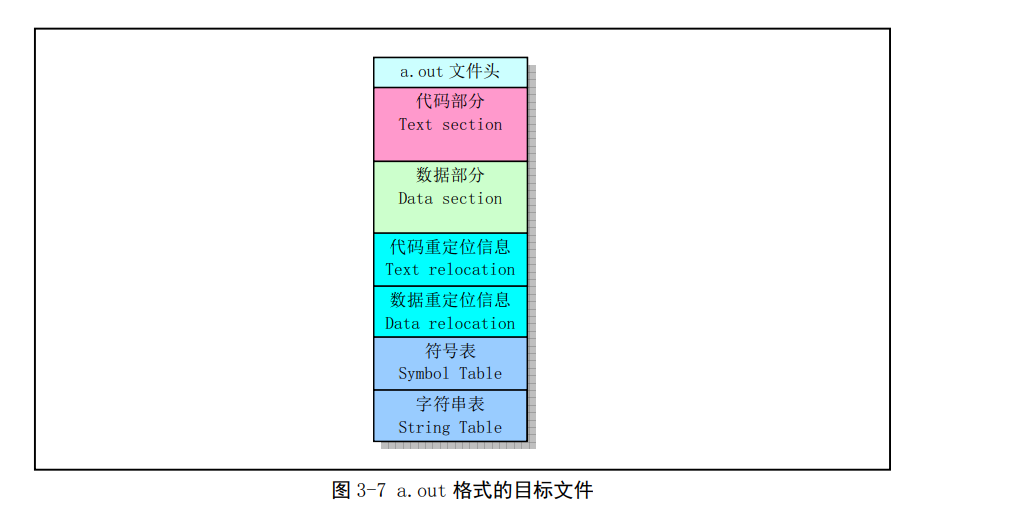
a.out格式7个区的基本定义和用途是:
- 执行头文件(exec header)。执行文件头部分。该部分含有一些参数(exec结构),是有关目标文件的整体结构信息。例如代码和数据区的长度、未初始化数据区的长度、对应源程序文件名以及目标文件创建时间等。内核使用这些参数把执行文件加载到内存中并执行,而链接程序(ld)使用这些参数将一些模块文件组合成一个可执行文件。这是目标文件唯一必要的组成部分。
- 代码区(text segment)。由编译器或汇编器生成的二进制指令代码和数据信息,含有程序执行时被加载到内存中的指令代码和相关数据。可以以只读形式被加载。
- 数据区(data segment)。由编译器或汇编器生成的二进制指令代码和数据信息,这些部分含有已经初始化过的数据,总是被加载到可读写的内存中。
- 代码重定位(text relocations)。这部分含有供链接程序使用的记录数据。在组合目标模块文件时用于定位代码段中的指针或地址。当链接程序需要改变目标代码的地址时就需要修正和维护这些地方。
- 数据重定位(data relocations)。类似于代码重定位部分的作用,但是用于数据段中指针的重定位。
- 符号表部分(sysmbol table)。这部分同样含有供链接程序使用的记录数据。这些数据保存着模块文件中定义的全局符号以及需要从其它模块文件中输入的符号,或者由链接器定义的符号,用于在模块文件之间对命名的变量和函数(符号)进行交叉引用。
- 字符串表部分(string table)。该部分有与符号相对应的字符串。用于调试程序调试目标代码,与链接过程无关。这些信息可包含源程序代码和行号、局部符号以及数据结构描述信息等。
对于一个指定的目标文件并非一定包含所有以上信息。由于Linux0.11系统使用了IntelCPU的内存管理功能,因此它会为每个执行程序单独分配一个64MB的地址空间(逻辑地址空间)使用。在这种情况下因为链接器已经把执行文件处理成一个固定地址开始运行,所以相关的可执行文件中就不再需要重定位信息。
3.5.5System.map文件
当运行GNU链接器gld(ld)时若使用了‘-M’选项,或者使用nm命令,则会在标准输出设备(通常是屏幕)上打印出链接映像(link map)信息,即是指由链接程序产生的目标程序内存地址映像信息。其中列出了程序段装入到内存中的位置信息。具体来讲有如下信息:
- 目标文件及符号信息映射到内存中的位置:
- 公共符号如何放置;
- 链接中包含的所有文件成员及其引用的符号。
通常我们会把发送到标准输出设备的链接映像信息重定向到一个文件中(例如System.map)。在编译内核时,linux/Makefile文件产生的System.map文件就用于存放内核符号表信息。符号表是所有内核符号及其对应地址的一个列表,当然包括上面说明的_etext、_edata和_end等符号的地址信息。随着每次内核的编译,就会产生一个新的对应System.map文件。当内核运行出错时,通过System.map文件中的符号表解析,就可以查到一个地址值对应的变量名,或反之。
利用System.map符号表文件,在内核或相关程序出错时,就可以获得我们比较容易识别的信息。符号表的样例子如下所示:
c03441a0 B dmi_broken
c03441a4 B is_sony_vaio_laptop
c03441c0 b dmi_ident
c0344200 b pci_bios_present
c0344204 b pirq_table
3.6Make程序和Makefile文件
Makefile(makefile)文件是make工具程序的配置文件。Make工具程序的主要用途是能自动地决定一个含有很多源程序文件的大型程序中哪个文件需要被重新编译。Makefile的使用比较复杂,这里只是根据上面的Makefile文件作简单的介绍。
为了使用make程序,你就需要Makefile文件来告诉make要做什么工作。通常,Makefile文件会告诉make如何编译和链接一个文件。当明确指出时,Makefile还可以告诉make运行各种命令(例如,作为清理操作而删除某些文件)。
make的执行过程分为两个不同的阶段。在第一个阶段,它读取所有的Makefile文件以及包含的makefile文件等,记录所有的变量及其值、隐式的或显示的规则,并构造出所有目标对象及其先决条件的一幅全景图。在第二阶段期间,make就使用这些内容结构来确定哪个目标对象需要被重建,并且使用相应的规则来操作。
当make重新编译程序时,每个修改过的C代码文件必须被重新编译。如果一个头文件被修改过了,那么为了确保正确,每一个包含该头文件的C代码程序都将被重新编译。每次编译操作都产生一个与源程序对应的目标文件。最终,如果任何源代码文件被编译过了,那么所欲的目标文件不管是刚编译完的还是以前就编译好的必须连接在一起以生成的可执行文件文件。
简单的Makefile文件含有一些规则,这些规则具有如下的形式:
目标(target)...:先决条件(prerequisites)...
命令(command)
....
....
其中'目标'对象通常是程序生成的一个文件的名称;例如是一个可执行文件或目标文件。目标也可以是所要采取活动的名字,比如‘清楚’‘(clean)’‘先决条件’是一个或多个文件名,是用作产生目标的输入条件。通常一个目标依赖几个文件。而'命令'是make需要执行的操作。一个规则可以有多个命令,每一个命令自成一行。请注意,你需要在每个命令行之前键入一个制表符!这是粗心这常常忽略的地方。
如果一个先决条件通过目录搜寻而在另外一个目录中被找到,这并不会改变规则的命令;它们将被如期执行。因此,你必须小心地设置命令,使得命令能够在make发现先决条件的目录中找到需要的先决条件。这就需要通过使用自动变量来做到。自动变量是一种在命令行上根据情况能被自动替换的变量。自动变量的值是基于目标对象及其先决条件而在命令行执行前的设置。例如,’$^‘的值表示规则的所有先决条件,包含它们所处目录的名称;’$<‘的值表示规则中的第一个先决条件;’$@’表示目标对象;另外还有一些自动变量这里就不提了。
有时,先决条件还常包含头文件,而这些头文件并不愿在命令中说明。此时自动变量‘$<’正是一个先决条件。例如
foo.o:foo.c def.h hack.h
cc -c $(CFLAGS) $< -o $@
其中的'$<'就会被自动地替换成foo.c,$@则会被替换为foo.o
为了让make能使用习惯用法来更新一个目标对象,你可以不指定命令,写一个不带命令的规则或者不写规则。此时make程序将会根据源程序文件的类型(程序的后缀)来判断要使用哪个隐式规则。
后缀规则是为make程序定义隐式规则的老式方法(现在这种规则已经不用了,取而代之的是使用更通用更清晰的模式匹配规则)。下面规则就是一种双后缀规则。双后缀规则是用一对后缀定义的:源后缀和目标后缀。相应的隐式先决条件是通过使用文件名中的源后缀替换目标后缀后得到。因此,此时下面的‘$<’值是‘.c’文件名。而正条make规则的含义是将'.c'程序编译成'*.s'代码。
.c.s:
$(CC)$(CFLAGS)\
-nostdinc -Iinclude -S -o $*.s $
通常命令是属于一个具有先决条件的规则,并在任何先决条件改变时用于生成一个目标(target)文件。然而,为目标而指定命令的也不一定要有先决条件。例如,与目标'clean'相关的含有删除(delete)命令的规则并不需要有先决条件。此时,一个规则说明了如何以及何时来重新制作某些文件,而这些文件是特定规则的目标。make根据先决条件来执行命令以及创建或更新目标。一个规则也可以说明如何及何时执行一个操作。
一个Makefile文件也可以含有除规则以外的其他文字,但是一个简单的Makefile文件只需要含有适当的规则。规则可能看上去要比上面示出的模板复杂得多,但基本上都是符合的。
Makefile文件最后生成的依赖关系是用于让make来确定是否需要重建一个目标对象。比如当某个头文件被改动后,make就通过这些依赖关系,重新编译与该头文件相关的所有‘*.c’文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号