统计学习方法 学习笔记(六):序列最小最优化算法SMO
经过前三篇的学习笔记,对理论上的支持向量机算是稍微了解了,如何去求解前三篇学习笔记中的对偶问题呢?在这一篇学习笔记中将给出答案。
凸二次规划的对偶问题:
$$\min_{\alpha} \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_iy_iy_jK(x_i,x_j) - \sum_{i=1}^{N}\alpha_i$$
$$s.t. \sum_{i=1}^{N}\alpha_iy_i = 0$$
$$ 0 \leq \alpha_i \leq C, i=1,2,...,N$$
支持向量机的学习问题可以形式化为求解凸二次规划问题,这样的凸二次规划问题具有全局最优解,并且有许多最优化算法可以用于这一问题的求解。但是当训练样本容量很大时,这些算法往往变得非常低效,以致无法使用。所以,如何高效地实现支持向量机学习就成为一个重要的问题。
SMO算法是支持向量机学习的一种快速算法,其特点是不断地将原二次规划问题分解为只有两个变量的二次规划子问题,并对子问题进行解析求解,直到所有变量满足KKT条件为止。这样通过启发式的方法得到原二次规划问题的最优解。因为子问题有解析解,所以每次计算子问题都很快,虽然计算子问题次数很多,但在总体上还是高效的。所以,SMO算法两个大步骤:一,两个变量的二次规划的求解方法;二,两个变量的选择方法。
两个变量二次规划的求解方法:
不失一般性,假设选择的两个变量是$\alpha_1,\alpha_2$,其他变量$\alpha_i(i=3,4,...,N)$是固定的,于是SMO的最优化问题(上诉对偶问题)的子问题可以写成:
$$\min_{\alpha_1,\alpha_2} W(\alpha_1,\alpha_2) = \frac{1}{2}K_{11}\alpha_{1}^{2} + \frac{1}{2}K_{22}\alpha_{2}^{2} + y_1y_2K_{12}\alpha_1\alpha_2 - (\alpha_1 + \alpha_2) + y_1\alpha_1\sum_{i=3}^{N}y_i\alpha_iK_{i1} + y_2\alpha_2\sum_{i=3}^{N}y_i\alpha_iK_{i2}$$
$$s.t. \alpha_1y_1 + \alpha_2y_2 = - \sum_{i=3}^{N}y_i\alpha_i = \zeta$$
$$ 0 \leq \alpha_i \leq C , i=1,2$$
其中,$K_{ij} = K(x_i,x_j), i,j=1,2,...,N$,$\zeta$是常数,上述目标函数中省略了不含$\alpha_1,\alpha_2$的常数项。
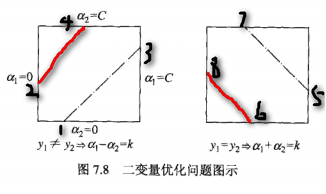
为了求解两个变量的二次规划问题,首先分析约束条件,然后在此约束条件下求极小。由于只有两个变量$(\alpha_1,\alpha_2)$,约束可以用二维空间中的图形表示,如上图。
不等式约束使得$(\alpha_1,\alpha_2)$在盒子[0,C]x[0,C]内,等式约束使$(\alpha_1,\alpha_2)$在平行于盒子[0,C]x[0,C]的对角线上。因此要求的目标函数在一条平行于对角线的线段上的最优值。这使两个变量的最优化问题成为实质上的单变量的最优化问题,不妨考虑为变量$\alpha_2$的最优化问题。
假设上述子问题的初始可行解为$\alpha_{1}^{old},\alpha_{2}^{old}$,最优解为$\alpha_{1}^{new},\alpha_{2}^{new}$,并且假设在沿着约束方向为经剪辑时$\alpha_2$的最优解为$\alpha_2^{new,unc}$,换句话说,$\alpha_2^{new,unc}$是仅仅满足两个约束条件中的一个等式约束条件。
由于$\alpha^new$需要满足不等式约束条件,所以最优值$\alpha^{new}$的取值范围必须满足条件:
$$L \leq \alpha_2^{new} \leq H$$
其中,$L$与$H$是$\alpha^{new}$所在的对角线端点的界。如果$y_1 \neq y_2$,则,在端点1,$\alpha_1$取0,在端点2,$\alpha_2$取$\alpha_2^{old} - \alpha_1^{old}$;在端点3,$\alpha_2$取$C+\alpha_2^{old}-\alpha_1^{old}$,在端点4,$\alpha_2$取$C$,所以:
$$L = max(0,\alpha_2^{old} - \alpha_1^{old}), H = min(C,C+\alpha_2^{old} - \alpha_1^{old})$$
如果$y_1 =y_2$,则,在端点5,$\alpha_2$取$\alpha_2^{old} + \alpha_1^{old} - C$,在端点6,取0;在端点7,取C,在端点8,取$\alpha_{2}^{old} + \alpha_{1}^{old}$。所以:
$$L = max(0,\alpha_2^{old}+\alpha_1^{old} - C), H = min(C,\alpha_2^{old} + \alpha_1^{old})$$
下面,首先求沿着约束方向未经剪辑即未考虑不等式约束时$\alpha_2$的最优解$\alpha_2^{new,unc}$;然后再求剪辑后$\alpha_2$的解$\alpha_2^{new}$:
(1)$\alpha_2^{new,unc}$


(2)经剪辑后$\alpha_2$的解:
$$\alpha_2^{new} = \begin{cases}
H, & \alpha_2^{new,unc}> H \\
\alpha_2^{nwe,unc},& L \leq \alpha_2^{new,unc} \leq H \\
L, & \alpha_2^{new,unc} < L
\end{cases}$$
由$\alpha_2^{new}$求得$\alpha_1^{new}$,因为$\alpha_1^{old}y_1 + \alpha_2^{old}y_2 = \alpha_1^{new}y_1 + \alpha_2^{new}y_2$:
$$\alpha_1^{new} = \alpha_1^{old} + y_1y_2(\alpha_2^{old} - \alpha_2^{new})$$
变量的选择方法:
SMO算法在每个子问题中选择两个变量优化,其中至少一个变量是违反KKT条件的。
第1个变量的选择:
SMO称选择第1个变量的过程为外层循环。外层循环在训练样本中选取违反KKT条件最严重的样本点,并将其对应的变量作为第1个变量。具体地,检验训练样本点$(x_i,y_i)$是否满足KKT条件,即:
$$\alpha_i = 0 \Leftrightarrow y_ig(x_i) \geq 1$$
$$ 0 < \alpha_i < C \Leftrightarrow y_ig(x_i) = 1$$
$$\alpha_i = C \Leftrightarrow y_ig(x_i) \geq 1$$
其中,$g(x_i) = \sum_{j=1}^{N}\alpha_jy_jK(x_i,x_j) + b.$
该检验是在$\varepsilon$范围内进行的。在检验过程中,外层循环首先遍历所有满足条件$0<\alpha_i<C$的样本点,即在间隔边界上的支持向量点,检验它们是否满足KKT条件。如果这些样本点都满足KKT条件,那么遍历整个训练集,检验它们是否满足KKT条件。
第2个变量的选择:
SMO称选择第2个变量的过程为内层循环。假设在外层循环中已经找到第一个变量$\alpha_i$,现在要在内层循环中找第二个变量$\alpha_2$。第二个变量选择的标准是希望能使$\alpha_2$有足够大的变化。
由$\alpha_2^{new}$的计算可知,$\alpha_2^{new}$是依赖于$|E_1 - E_2|$的,为了加快计算速度,一种简单的做法是选择$\alpha_2$,使其对应的$|E_1 - E_2|$最大。因为$\alpha_1$已定,$E_1$也确定了,如果$E_1$是正的,那么选择最小的$E_i$作为$E_2$;如果$E_1$是负的,那么选择最大的$E_i$作为$E_2$。为了节省计算时间,将所有$E_i$值保存在一个列表中。
在特殊情况下,如果内层循环通过以上方法选择的$\alpha_2$不能使目标函数有足够的下降,那么采用以下启发式规则继续选择$\alpha_2$。遍历在间隔边界上的支持向量点,依次将其对应的变量作为$\alpha_2$试用,直到目标函数有足够的下降。若找不到合适的$\alpha_2$,那么遍历训练数据集;若仍找不到合适的$\alpha_2$,则放弃第1个$\alpha_1$,再通过外层循环寻求另外的$\alpha_1$。
计算阈值$b$和差值$E_i$
在每次完成两个变量的优化后,都要重新计算阈值$b$。当$0<\alpha_1^{new}<C$时,由KKT条件$0<\alpha_i<C \Leftrightarrow y_ig(x_i) = 1$可知:
$$\sum_{i=1}^{N}\alpha_1y_iK_{i1} + b = y_1$$
于是,
$$b_1^{new} = y_1 - \sum_{i=3}^{N}\alpha_iy_iK_{i1} - \alpha_1^{new}y_1K_{11} - \alpha_2^{new}y_2K_{21}$$
由$E_1$的定义有:
$$E_1 = \sum_{i=3}^{N}\alpha_iy_iK_{i1} + \alpha_1^{old}y_1K_{11} + \alpha_2^{old}y_2K_{21} + b^{old} - y_1$$
所以:
$$y_1 - \sum_{i=3}^{N}\alpha_iy_iK_{i1} = - E_1 + \alpha_1^{old}y_1K_{11} + \alpha_2^{old}y_2K_{21} + b^{old}$$
所以:
$$b_1^{new} = - E_1 - y_1K_{11}(\alpha_1^{new} - \alpha_1^{old}) - y_2K_{21}(\alpha_2^{new} - \alpha_2^{old}) + b^{old}$$
同样,如果$0<\alpha_2^{new}<C$,那么:
$$b_2^{new} = - E_2 - y_1K_{12}(\alpha_1^{new} - \alpha_1^{old}) - y_2K_{22}(\alpha_2^{new} - \alpha_2^{old}) + b^{old}$$
如果$\alpha_1^{new},\alpha_2^{new}$同时满足条件$0<\alpha_i^{new}<C, i=1,2$,那么,$b_1^{new} = b_2^{new}$。如果$\alpha_1^{new},\alpha_2^{new}$是0或者C,那么$b_1^{new}$和$b_2^{new}$以及它们之间的数据都是符合KKT条件的阈值,这时选择它们的中点作为$b^{new}$。
在每次完成两个变量的优化之后,还必须更新对应的$E_i$值,并将它们保存在列表中,$E_i$值的更新要用到$b^{new}$值,以及所有支持向量对应的$\alpha_j$:
$$E_i^{new} = \sum_{S}y_j\alpha_jK(x_i,x_j) + b^{new} - y_i$$
其中,$S$是所有支持向量$x_j$的集合。
SMO算法:
输入:训练数据集$T = \{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}$,其中,$x_i \in \mathcal{X} = R^n, y_i \in \mathcal{Y}={-1,+1}, i=1,2,...,N$,精度$\varepsilon$;
输出:近似解$\hat{\alpha}$。
(1)取初值$\alpha^{(0)} = 0$,令$k = 0$;
(2)选取优化变量$\alpha_1^{k},\alpha_2^{k}$,解析求解两个变量的优化问题,求得最优解$\alpha_1^{(k+1)},\alpha_2^{(k+2)}$,更新$\alpha$为$\alpha^{(k+1)}$;
(3)若在精度$\varepsilon$范围内满足停机条件:
$$\sum_{i=1}^{N}\alpha_iy_i = 0$$
$$0 \leq \alpha_i \leq C, i=1,2,...,N$$
$$y_i \cdot g(x_i) = \left\{\begin{matrix}
\geq 1, &\{x_i|\alpha_i=0\} \\
= 1, &\{x_i|0<\alpha_i<C\} \\
\leq 1,&\{x_i|\alpha_i = C\}
\end{matrix}\right.$$
其中,
$$g(x_i) = \sum_{j=1}^{N}\alpha_jy_jK(x_j,x_i) + b$$
则转(4);否则令$k = k + 1$,转(2);
(4)取$\hat{\alpha} = \alpha^{(k+1)}$。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号