

Spring Cloud Stream 知识整理
转自 https://www.baidu.com/link?url=fqkjjbRyylLj4mFPZalxkjgV2uespWPX6d3G4tylH-5M3gJP2iC2dIhy77QbcOzQMDwd2mjdo6SJeFNiuOJDmK&wd=&eqid=a9ae41c90001f45c000000065a4598d6
Spring Cloud Stream 知识整理
概念 使用方法
概念
1. 发布/订阅
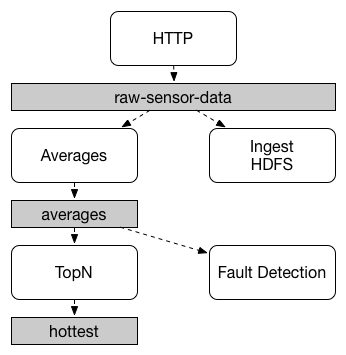
简单的讲就是一种生产者,消费者模式。发布者是生产,将输出发布到数据中心,订阅者是消费者,订阅自己感兴趣的数据。当有数据到达数据中心时,就把数据发送给对应的订阅者。
2. 消费组
直观的理解就是一群消费者一起处理消息。需要注意的是:每个发送到消费组的数据,仅由消费组中的一个消费者处理。
3. 分区
类比于消费组,分区是将数据分区。举例:某应用有多个实例,都绑定到同一个数据中心,也就是不同实例都将数据发布到同一个数据中心。分区就是将数据中心的数据再细分成不同的区。为什么需要分区?因为即使是同一个应用,不同实例发布的数据类型可能不同,也希望这些数据由不同的消费者处理。这就需要,消费者可以仅订阅一个数据中心的部分数据。这就需要分区这个东西了。
Spring Cloud Stream简介
1. 应用模型
Spring Cloud Stream应用由第三方的中间件组成。应用间的通信通过输入通道(input channel)和输出通道(output channel)完成。这些通道是有Spring Cloud Stream 注入的。而通道与外部的代理(可以理解为上文所说的数据中心)的连接又是通过Binder实现的。
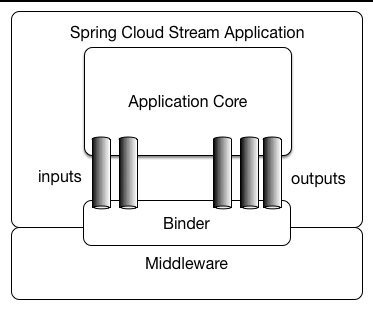
上图就是Spring Cloud Stream的应用模型。
1.1 可独立运行的jar
Spring Cloud Stream应用可以直接在IDE运行。这样会很方便测试。但在生产环境下,这是不适合的。Spring Boot为maven和Gradle提供了打包成可运行jar的工具,你可以使用这个工具将Spring Cloud Stream应用打包。
2. 抽象的Binder
Binder可以理解为提供了Middleware操作方法的类。Spring Cloud 提供了Binder抽象接口以及KafKa和Rabbit MQ的Binder的实现。
使用Spring Cloud Stream
1. 快速开始
这里先放出前面的应用模型图
下面例子使用的Middleware是Kafka,版本是kafka_2.11-1.0.0。Kafka使用的是默认配置,也就是从Kafka官网下载好后直接打开,不更改任何配置。
关于pom.xml中依赖的项目的版本问题,最好不该成别的版本,因为很大可能导致版本冲突。
1.1 pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.8.RELEASE</version>
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-dependencies</artifactId>
<version>Ditmars.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<exclusions>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<groupId>ch.qos.logback</groupId>
<