

下载mysql官网数据库模板:https://dev.mysql.com/doc/index-other.html

解压导入到数据库中

官网查询执行计划地址: https://dev.mysql.com/doc/refman/5.5/en/explain-output.html
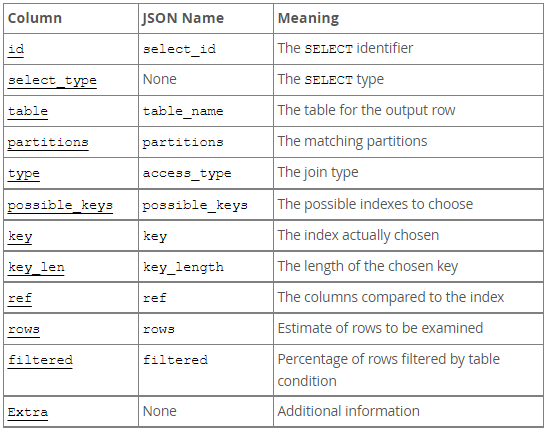
EXPLAIN输出列说明:
id:为每个查询子句的标识符,为一组数字,表示查询中执行select子句或者操作表的顺序
1)如果id相同,那么执行顺序从上到下
explain SELECT * FROM customer a join address b ON a.address_id = b.address_id;
2)如果id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
explain SELECT * FROM customer a WHERE a.address_id = (SELECT b.address_id from address b WHERE b.address_id =100);
3)id相同和不同的,同时存在:相同的可以认为是一组,从上往下顺序执行,在所有组中,id值越大,优先级越高,越先执行
explain SELECT * FROM customer a JOIN address c ON a.address_id = c.address_id WHERE a.address_id = (SELECT b.address_id from address b WHERE b.address_id =100);
select_type:为每个查询子句类型
1)SIMPLE 简单查询表
explain SELECT * FROM customer;
2)primary:查询中若包含任何复杂的子查询,最外层查询则被标记为Primary,如以下语句a表
EXPLAIN SELECT a.* FROM customer a WHERE a.address_id = ( SELECT b.address_id FROM address b WHERE b.address_id = 100 ) ;
3)union:若第二个select出现在union之后,则被标记为union,如以下语句b表
EXPLAIN SELECT a.first_name FROM customer a WHERE a.address_id = 100 UNION SELECT a.first_name FROM customer a WHERE a.address_id = 101;
4)subquery:在select或者where列表中包含子查询,如以下语句b表
EXPLAIN SELECT a.* FROM customer a WHERE a.address_id = ( SELECT b.address_id FROM address b WHERE b.address_id = 100 ) ;
5)MATERIALIZED:子查询物化,当表出现在非相关子查询中并且需要进行物化时会出现MATERIALIZED关键词
EXPLAIN SELECT a.* FROM customer a WHERE a.first_name IN ( SELECT DISTINCT b.first_name FROM customer b ) ;
6)UNION RESULT:为union查询完成之后的结果集
EXPLAIN SELECT a.first_name FROM customer a WHERE a.address_id = 100 UNION SELECT a.first_name FROM customer a WHERE a.address_id = 101;
7)DERIVED:from子句中出现的子查询,也叫做派生类
EXPLAIN SELECT c.* FROM (SELECT a.first_name FROM customer a WHERE a.address_id = 100 UNION SELECT b.first_name FROM customer b WHERE b.address_id = 101 ) c;
8)DEPENDENT SUBQUERY:子查询b受a表影响
EXPLAIN SELECT (SELECT b.first_name FROM customer b WHERE b.first_name=a.first_name) FROM customer a;
9)DEPENDENT UNION:子表b查询结果受a表影响,且在union后面
EXPLAIN SELECT (SELECT c.first_name FROM customer c WHERE c.customer_id =1 UNION SELECT b.first_name FROM customer b WHERE b.first_name=a.first_name) FROM customer a;
10)UNCACHEABLE SUBQUERY:表示子查询不可被物化需要逐次运行
EXPLAIN select * from customer where customer_id = (select customer_id from customer where customer_id=@@sort_buffer_size);
11)UNCACHEABLE UNION: 子查询中出现UNION并且不可被缓存在UNION 后的 SELECT 语句出现此关键词
EXPLAIN select * from customer where customer_id IN (select customer_id from customer WHERE customer_id=1 UNION select customer_id from customer where customer_id=@@sort_buffer_size);
12)DEPENDENT DERIVED:衍生表受外部影响,未复现。
table:为对应行正在访问哪一个表,表名或者别名,可能是临时表或者union合并结果集或衍生表
partitions:分区表名
type:查询数据方式,是全表查询还是索引查询检索
效率从最好到最坏依次是:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > all
1)all:全表扫描,一般情况下出现这样的sql语句而且数据量比较大的话那么就需要进行优化。
EXPLAIN SELECT * FROM customer;
2)index:全索引扫描,这个比all效率要好,主要有两种情况可以使用:一种是当前sql是覆盖索引查询,第二种是进行索引排序
EXPLAIN SELECT customer_id FROM customer;
3)range:利用索引进行范围查询。避免全表扫描,操作符: =, <>, >, >=, <, <=, IS NULL, BETWEEN, LIKE, or IN()
EXPLAIN SELECT customer_id FROM customer where customer_id>100 and customer_id <120;
4)index_subquery:利用索引来关联子查询,不再扫描全表
5)unique_subquery:该连接类型类似与index_subquery,使用的是唯一索引
6)index_merge:在查询过程中需要多个索引组合使用,没有模拟出来
7)ref_or_null:对于某个字段即需要关联条件,也需要null值的情况下
8)fulltext:使用了全文索引
9)ref:利用非唯一索引进行范围查询查询
EXPLAIN SELECT * FROM film WHERE title in (SELECT title FROM film WHERE title like 'a%');
10)eq_ref:使用唯一索引进行范围查询数据
EXPLAIN SELECT * FROM customer WHERE customer_id in (SELECT customer_id FROM customer);
11)const:查询条件使用索引,且是常量值
EXPLAIN SELECT * FROM customer WHERE customer_id=100;
12)system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现
possible_keys : 可能使用的索引,当前表中所建立的索引
key:实际使用的索引,如果未使用则显示为null
key_len : 当前索引所使用的的字节数
ref:显示索引的哪一列被使用了,或可能是一个常数
rows:大致估算出找出所需记录需要读取的行数,此参数很重要,直接反应的sql找了多少数据,在完成目的的情况下越少越好
filtered:查询数据与需要查询的结果比值
extra:显示额外信息
1)using filesort:说明未使用索引排序,在内存中使用排序算法进行排序
2)using temporary:建立临时表来保存中间结果,查询完成后把临时表删除
3)using index:表示当前的查询使用覆盖索引,
4)using where:表示使用了索引,但是回表了
5)using join buffer(hash join):表示查询结果在内存中创建hash临时表
6)Impossible where:where语句的结果总是false
EXPLAIN SELECT a.* FROM film a WHERE 1 !=1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号