

介绍:
kafka是高性能的消息中间件,利用zookeeper做分布式协调,实现集群化扩展
关键词:topic,partition,replication,offset
安装使用:
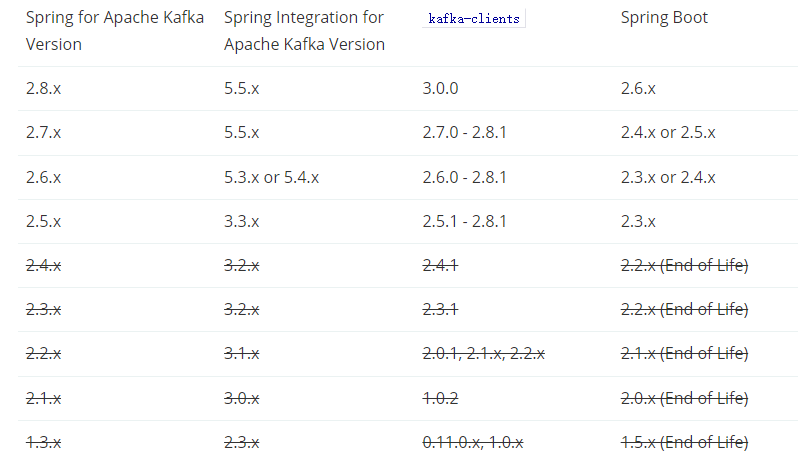
下载安装包但是一定要注意版本问题不然springboot代码没有反应,kafka-clients为kafka的broker版本号:https://spring.io/projects/spring-kafka
低版本使用zookeeper做存储,高版本使用自身做存储metadata,命令有所差异。
启动zookeeper命令:
bin/zookeeper-server-start.sh <-daemon 非交互式启动> config/zookeeper.properties
修改server.properties配置,复制多个配置文件:
#是否允许删除topic,默认false不能手动删除 delete.topic.enable=true #当前机器在集群中的唯一标识,和zookeeper的myid性质一样 broker.id=0 #当前kafka服务侦听的地址和端口,端口默认是9092 listeners = PLAINTEXT://192.168.100.21:9092 #这个是borker进行网络处理的线程数 num.network.threads=3 #这个是borker进行I/O处理的线程数 num.io.threads=8 #发送缓冲区buffer大小,数据不是一下子就发送的,先会存储到缓冲区到达一定的大小后在发送,能提高性能 socket.send.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘 socket.receive.buffer.bytes=102400 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小 socket.request.max.bytes=104857600 #消息日志存放的路径 log.dirs=/opt/module/kafka_2.11-1.1.0/logs #默认的分区数,一个topic默认1个分区数 num.partitions=1 #每个数据目录用来日志恢复的线程数目 num.recovery.threads.per.data.dir=1 #默认消息的最大持久化时间,168小时,7天 log.retention.hours=168 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件 log.segment.bytes=1073741824 #每隔300000毫秒去检查上面配置的log失效时间 log.retention.check.interval.ms=300000 #是否启用log压缩,一般不用启用,启用的话可以提高性能 log.cleaner.enable=false #设置zookeeper的连接端口 zookeeper.connect=node21:2181,node22:2181,node23:2181 #设置zookeeper的连接超时时间 zookeeper.connection.timeout.ms=6000
listeners=PLAINTEXT://192.168.121.132:9092 (--暴露服务,否则连接超时)
broker.id=2
(以下同一个机器需要修改):
port=9094
log.dirs=/tmp/kafka-logs-2
启动kafka命令:
bin/kafka-server-start.sh <-daemon 非交互式启动> config/server.properties
停止命令:
bin/kafka-server-stop.sh config/server.properties
创建低版本topic:(replication-factor副本值):
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic-name
查询topic详情:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic topic-name
查询所有topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181
修改topic参数配置:
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic_name --parti-tions count
删除topic:
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_name
高版本:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic-name
创建生产者:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-name
创建消费者(有非必须参数,分区与consumer之间的关系:一个分区不能分给两个consumer,但是两个分区可以分给一个consumer):
bin/kafka-console-consumer.sh --bootstrap-server localhost:2181 --topic topic-name --from-beginning --group testgroup
查询组:
springboot中使用kafka的配置:
1 #kafka集群配置 2 spring.kafka.bootstrap-servers=192.168.121.132:9092 3 #重试次数 4 spring.kafka.producer.retries=0 5 #应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0,1,all/-1) 6 spring.kafka.producer.acks=0 7 #批量大小 8 spring.kafka.producer.batch-size=16384 9 #提交延时 10 spring.kafka.producer.properties.linger.ms=0 11 #当生产端积累的消息达到batch-size或者接收信息linger.ms后,生产者就会将消息提交个kafka 12 #linger.ms为0表示每接收到一条信息就会提交给kafka,这时候batch-size其实就没有用了 13 #生产端缓冲区大小 14 spring.kafka.producer.buffer-memory=33554432 15 #kafka提供的序列化和反序列化类 16 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer 17 spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer 18 19 ###############消费者配置########## 20 #默认的消费组id(同一消息,可以被不同组重复使用) 21 spring.kafka.consumer.properties.group.id=defaultConsumerGroup 22 #是否自动提交offset 23 spring.kafka.consumer.enable-auto-commit=true 24 #提交offset延时(接收到信息后多久提交offset) 25 spring.kafka.consumer.auto-commit-interval=1000 26 #earliest:获取上一次消费的offset继续消费或者从头开始消费(重复消费)28 #latest:获取上一次消费的offset继续消费或者最新的offset消费(丢失消费) 29 #none:必须要有上次消费的offset,否则报错 30 spring.kafka.consumer.auto-offset-reset=latest 31 #消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作) 32 spring.kafka.consumer.properties.session.timeout.ms=120000 33 #消费请求超时时间 34 spring.kafka.consumer.properties.request.timeout.ms=180000 35 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer 36 spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer 37 #消费端监听的topic不存在时,项目启动会报错 38 spring.kafka.listener.missing-topics-fatal=false
消费者:
@Component @Slf4j public class KafkaCustomerService { @KafkaListener(topics = "hello-world") //定义此消费者接收topic为“hello-world”的消息,监听服务器上的kafka是否有相关的消息发过来 //record变量代表消息本身,可以通过ConsumerRecord<?,?>类型的record变量来打印接收的消息的各种信息 public void listen (ConsumerRecord<?, ?> record) throws Exception { System.out.printf("topic = %s, offset = %d, value = %s \n", record.topic(), record.offset(), record.value()); } }
生产者:
@Service @Slf4j public class KafkaProductService { @Autowired KafkaTemplate kafkaTemplate; private void sendMsg(){ kafkaTemplate.send("hello-world","welcom to kafka"); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号