聊聊数据库~3.SQL基础篇
上篇回顾:聊聊数据库~SQL环境篇
扩展:为用户添加新数据库的权限
PS:先使用root创建数据库,然后再授权grant all privileges on 数据库.* to 用户名@"%" identified by "密码";并刷新flush privileges;
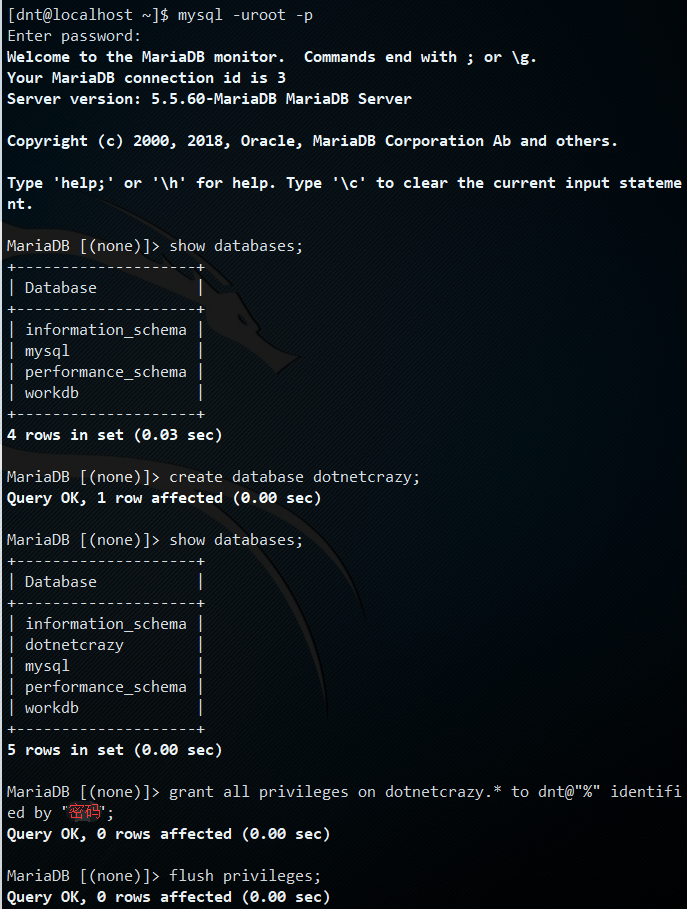
查看权限:show grants for dnt;
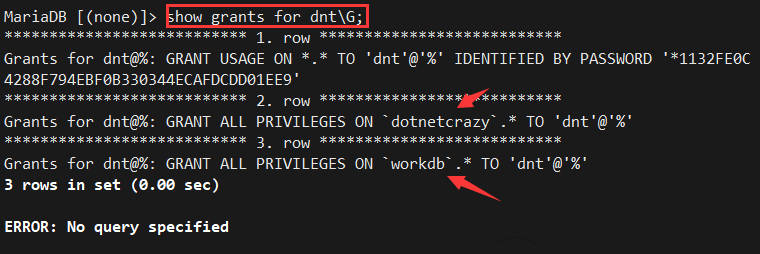
效果:
1.3.MySQL部署
之前有园友说,为啥不顺便说说UbuntuServer的部署呢?呃。。。一般来说公司服务器都是CentOS的占大多数,然后UbuntuServer更多的是个人云服务比较多(推荐初创公司使用),毕竟它们两个系统追求的不太一样,一个是追求稳(部署麻烦),一个是追求软件尽量新的情况下稳定(更新太快)
那么长话短说,步入正轨:
1.Ubuntu最常见的包问题
Ubuntu不得不说的就是这个apt出问题的处理 :(换源就不说了/etc/apt/sources.list)
# 一般删除这几个锁文件,然后再重新配置下就可以了
sudo rm /var/lib/dpkg/lock
sudo rm /var/lib/dpkg/lock-frontend
sudo rm /var/lib/apt/lists/lock
sudo rm /var/cache/apt/archives/lock
# 简写(千万注意空格,不然你就是rm -rf / + 跑路了)
# sudo rm /var/lib/apt/lists/lock /var/cache/apt/archives/lock /var/lib/dpkg/lock /var/lib/dpkg/lock-frontend
# 重新配置下
sudo dpkg --configure -a
2.安装注意(Ubuntu的特点就是使用起来简单)
Ubuntu推荐使用MySQL(毕竟同是5.x用起来基本上差不多,安装过程和之前说的CentOS 下 MariaDB差不多,所有命令前加个sudo)
1.安装比较简单:sudo apt install mysql-server -y
2.允许远程连接:注释掉 bind-address=127.0.0.1(/etc/mysql/mysql.conf.d/mysqld.cnf)
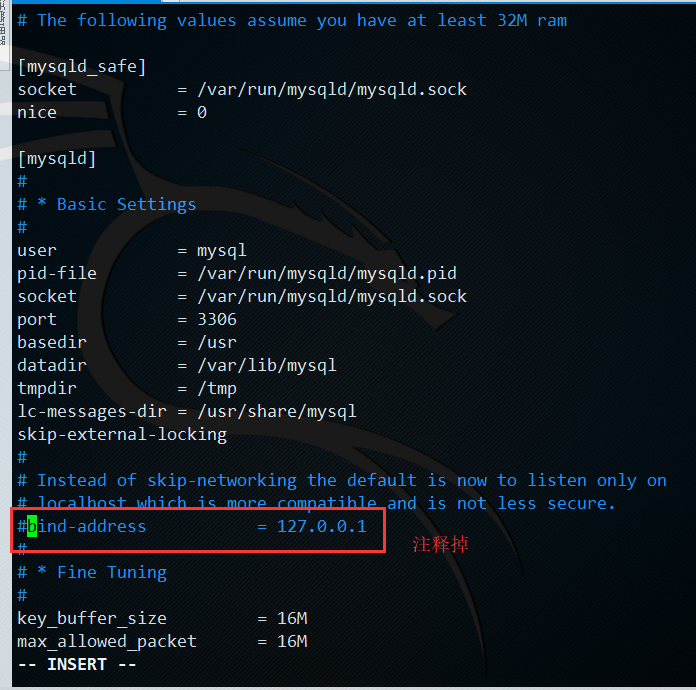
PS:常用配置(/etc/mysql/mysql.conf.d/mysqld.cnf)
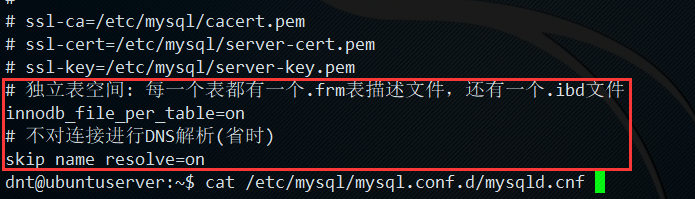
3.关于为什么是这个路径的说明:sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
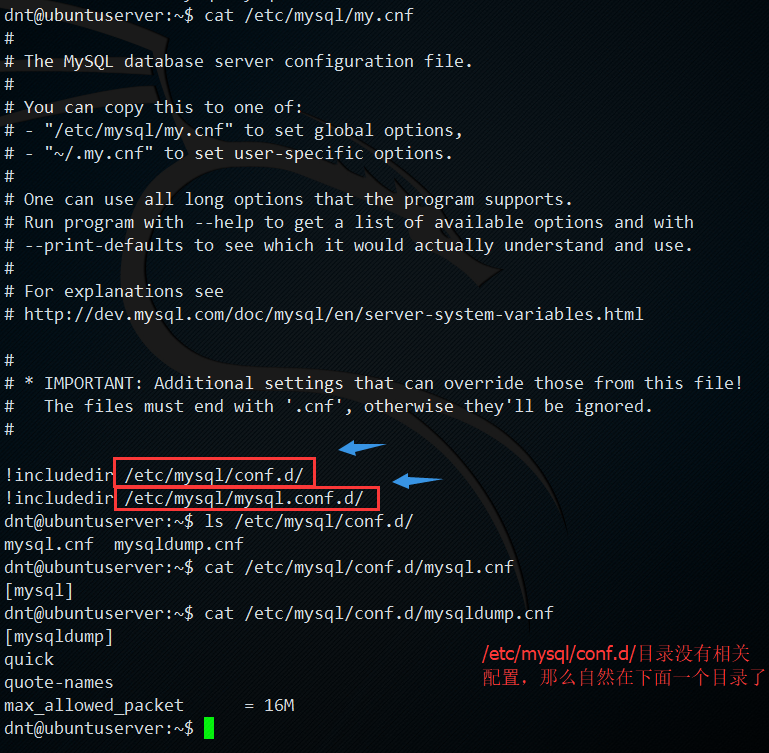
4.所有配置修改都需要重新启动下:sudo systemctl restart mysql

5.第一次初始化和MariaDB不太一样:sudo mysql_secure_installation(其他一路y即可)
需要选下你设置root密码的复杂度:(一般1就可以了,就算设置再复杂,入了系统也是虚的)

PS:可以看看拓展文章:Ubuntu16安装mysql5.7未提示输入密码,安装后修改mysql默认密码 和 【不推荐】修改mysql密码策略
6.然后输入密码你就可以登录了sudo mysql -uroot -p(PS:你直接sudo mysql也可以直接登录)
这边我就不像上节课一步步演示了,直接授权和创建一步走了grant all privileges on 数据库.* to "用户名"@"%" identified by "复杂密码";
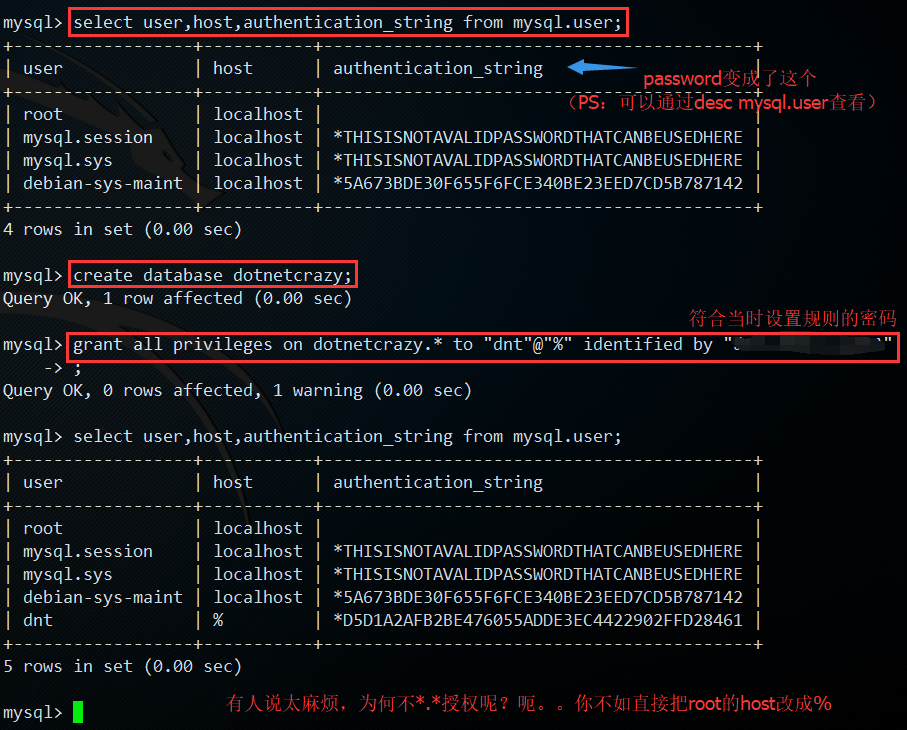
7.记得flush privileges;刷新一下系统表
PS:数据文件一般都是放在/var/lib/mysql中
课后拓展:
浅析MySQL 8忘记密码处理方式
https://www.cnblogs.com/wangjiming/p/10363357.html
MySQL5.6更改datadir数据存储目录
https://www.cnblogs.com/ding2016/p/7644675.html
1.4.基础(MySQL and SQLServer)
脚本示例:https://github.com/lotapp/BaseCode/tree/master/database/SQL
PS:在MySQL中运行SQL脚本:mysql < script.sql
后面代码优先使用通用SQL(MySQL和SQLServer(MSSQL)通用的SQL语句),逆天好几年没用SQLServer了(几年前讲过MSSQL),这边就一带而过(欢迎纠错)
PS:后面MariaDB我也直接说成MySQL了(有区别的地方我会说下,毕竟也是MySQL的分支,相似度还是很大的)
1.概念
1.1.传统概念
来说说传统概念:
- 关系型数据库中的关系:表(行、列)
- 设计范式:
- 第1范式:字段是原子性的
- 第2范式:每个表需要一个主键
- 第3范式:任何表都不应该有依赖于其他非主键表的字段
- DDL:数据定义语言(Data Defination Language)
create、drop、alter
- DML:数据操作语言(Data Manipulation Language)
insert、delete、update、select
- DCL:数据库控制语言(Data Control Language)
grant(授权)、revoke(回收)
PS:CURD(定义了用于处理数据的基本原子操作):创建(Create)更新(Update)读取(Retrieve)删除(Delete)操作
1.2.常见组件
关系型数据库常见组件:
- 数据库:database
- 表:table
- 行:row
- 列:column
- 索引:index
- 视图:view
- PS:如果有
数据库迁移的需求则不建议使用 - PS:MySQL的视图功能不是特别完素,尽量不使用
- PS:如果有
- 存储过程:procedure
- 存储函数:function
- 触发器:trigger
- 事件调度器:event、scheduler
- 用户:user
- 权限:privilege
PS:MySQL常见的文件类型:
- 数据:数据文件、索引文件
- 日记:错误日志、查询日志、慢查询日志、二进制日志、(重做日志、撤销日志、中继日志)
2.MySQL标准存储引擎
2.1.MySQL
先说说MySQL标准存储引擎(表类型):
MyISAM:只支持表级锁,不支持事务InnoDB:支持事务、间隙锁、行锁等等
2.2.MariaDB
首先是插件式存储引擎(表类型)的改进和扩充 PS:其实也就是支持更多的存储引擎(包括自定义的)
MariaDB对标准存储引擎进行了改造升级:
MyISAM==>Aria:支持崩溃后的恢复InnoDB==>XtraDB:优化存储性能
还进行了很多扩展并开发了新的功能(也提供了很多测试工具),比如添加一些NoSQL的功能(SQLServer也扩展了NoSQL)
3.创建、删除(数据库 | 表)
字段类型(含异同)
官方文档:
https://mariadb.com/kb/en/library/data-typeshttps://dev.mysql.com/doc/refman/5.7/en/data-types.html
以MariaDB为例,简单列举下常用类型:(倾体说明和MySQL不一样)
- 字符型:
- 定长字符型:
char():不区分字符大小写类型的字符串,max:255个字符- binary():区分字符大小写类型的二进制字符串
- 变长字符型:
varchar(): 不区分字符大小写类型的字符串- max:65535(2^16 - 1)个字节(
utf8编码下最多支持21843个字符) - 可以理解为
SQLServer的nvarchar
- max:65535(2^16 - 1)个字节(
- varbinary():区分字符的大小写类型的二进制字符串
- 对象存储:
text:不区分字符大小写的不限长字符串- 最大长度为65,535(2^16 - 1)个字符
- 如果值包含多字节字符,则有效最大长度减少
- blob:区分字符大小写的不限长二进制字符串
- 内建类型:(不推荐使用)
- enum:单选字符串数据类型,适合表单中的
单选值 - set:多选字符串数据类型,适合表单的
多选值 - PS:
MySQL系独有,SQLServer没有
- enum:单选字符串数据类型,适合表单中的
- 定长字符型:
- 数值型:
- 精确数值型:
- 整型:int
- bool:布尔类型(MySQL没有)
- PS:
SQLServer是bit - 相当于
MySQL的tinyint(1)
- PS:
tinyint:微小整型(1字节,8位)[-2^7, 2^7)(-128 ~ 127)- 无符号:
[0, 2^8)(0 ~ 255)
- smallint(2bytes,16bit):小整型
- 无符号:
0 ~ 65535
- 无符号:
- mediumint(3bytes,24位):中等整型
PS:SQLServer中没这个类型
int(4bytes,32bit)[-2^31, 2^31),[-2147483648,2147483648)- 无符号:
[0, 2^32),[0,4294967296)
bigint(8bytes,64bit)[-2^63, 2^63)- 无符号:
[0, 2^64)
- bool:布尔类型(MySQL没有)
- 整型:int
- 浮点类型:
- float:单精度浮点数(4字节)
double:双精度浮点数(8字节)- PS:
SQLServer的float类型相当于MySQL的double
- PS:
decimal:精确小数类型(比double更精确)- 钱相关用的比较多:
decimal(位数,小数点位数) - eg:
decimal(2,1)=>x.x
- 钱相关用的比较多:
- 精确数值型:
- 日期和时间类型:(和
MySQL一样)- date:日期(3bytes)
- time:时间(3bytes)
- year:年
- eg:
year(2):00~99(1bytes) - eg:
year(4):0000~9999(1bytes) - PS:
SQLServer没有这个类型
- eg:
datetime:既有时间又有日期(8bytes)timestamp:时间戳(4bytes)【精度更高】
- 修饰符:
- 所有类型都适用:
- 是否为null:
null|not null - 默认值:
default xxx_value - 主 键:
primary key - 唯一键:
unique key
- 是否为null:
- 数值类型适用:
- 无符号:
unsigned(MySQL系独有) - 自增长:
auto_increment(一般只用于整型,MSSQL是identity)- 获取ID:
last_insert_id()
- 获取ID:
- 无符号:
- PS:多列设置:
- 主键:
primary key(xx,...) - 唯一键:
unique key(xx,...) - 索引:
index index_name (xx,...)
- 主键:
- 所有类型都适用:
PS:现在新版本数据库兼容了SQLServer的nvarchar写法(执行成功后数据类型变成varchar)【不推荐使用】
课后拓展:
MySQL:char、varchar、text的区别
https://dev.mysql.com/doc/refman/5.7/en/char.html
https://blog.csdn.net/brycegao321/article/details/78038272
3.1.MySQL
知识点概括:
- 创建数据库:
create database [if not exists] db_name;
- 删除数据库:
drop database [if exists] db_name;
- 创建表:
create table [if not exists] tb_name(列名1,数据类型 修饰符,列名2,数据类型 修饰符);
- 删除表:
drop table [if exists] db_name.tb_name;
- 修改表:
- 字段
- 添加字段:add
alter table tb_name add 列名 数据类型 修饰符 [first | after 列名];- PS:SQLServer没有
[first | after 列名]
- 修改字段:alter、change、modify
- 修改字段名:
alter table tb_name change 旧列名 新列名 类型 类型修饰符 - 修改字段类型:
alter table tb_name modify 列名 类型 类型修饰符 - 添加默认值:
alter table tb_name alter 列名 set default df_value
- 修改字段名:
- 删除字段:drop
alter table tb_name drop 字段名
- 添加字段:add
- 索引
- 添加索引:add(常用:
create index index_name on tb_name(列名,...);)alter table tb_name add index [ix_name] (列名,...);- 添加唯一键:
alter table tb_name add unique [uq_name] (列名,列名2...); - PS:不指定索引名字,默认就是第一个字段名
- 删除索引:drop(常用:
drop index index_name on tb_name)alter table tb_name drop index index_name;- 删除唯一键:
alter table tb_name drop index uq_name; - PS:唯一键的索引名就是第一个列名
- PS:一般在经常用做查询条件的列设置索引
- 添加索引:add(常用:
- 表选项
- 可以参考这篇文章:
https://www.cnblogs.com/huangxm/p/5736807.html
- 可以参考这篇文章:
- 字段
SQL Model:定义MySQL对约束的响应行为:- 会话修改:
- mysql>
set [session] sql_model='xx_mode' - mysql>
set @@session.sql_mode='xx_mode' - PS:只在当前会话生效
- mysql>
- 全局修改:需要有权限,并且不会立即生效,对以后新建的会话生效(从全局继承的)
- mysql>
set global sql_mode='xx_mode' - mysql>
set @@global.sql_mode='xx_mode' - PS:MySQL重启后失效
- mysql>
- 配置修改:永远生效:
- eg:
vi /etc/my.cnf,在[mysqld]下添加sql_mode='xx',然后重启数据库 - PS:从MySQL8开始,可通过
set persist命令将全局变量的修改持久化到配置文件中- 持久化到
/var/lib/mysql/mysqld-auto.cnf配置文件中 - eg:
set persist log_timestamps='SYSTEM';(需要root权限)
- 持久化到
- eg:
- 常用mode:(阿里服务器默认是:
strict_trans_tables)traditional:使用传统模型,不允许对非法值做插入操作strict_trans_tables:对所有支持事物类型的表做严格约束strict_all_tables:对所有表做严格约束- 查询当前设置:
select @@sql_mode
- 详情可以查看我之前写的文章:https://www.cnblogs.com/dotnetcrazy/p/10374091.html
- 会话修改:
3.1.1.创建、删除数据库
-- 如果存在就删除数据库
drop database if exists dotnetcrazy;
-- 创建数据库
create database if not exists dotnetcrazy;
3.1.2.创建、删除表
-- 如果存在就删除表
drop table if exists dotnetcrazy.users;
-- mysql> help create table(低版本的默认值不支持函数)
-- 创建表 create table users(字段名 类型 修饰符,...)
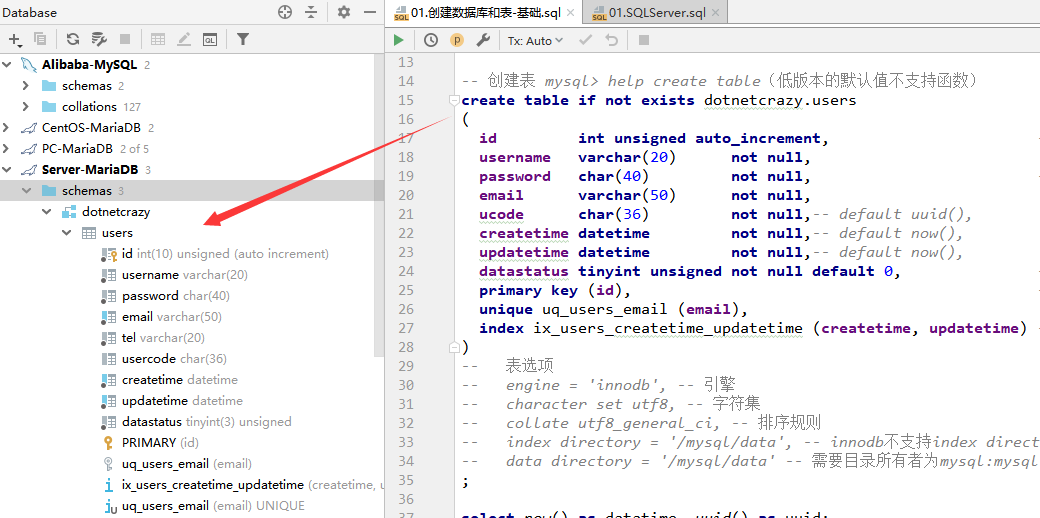
create table if not exists dotnetcrazy.users
(
id int unsigned auto_increment, -- 主键,自增长【获取ID:last_insert_id()】
username varchar(20) not null,
password char(40) not null, -- sha1:40
email varchar(50) not null,
ucode char(36) not null,-- default uuid(), -- uuid
createtime datetime not null,-- default now(),
updatetime datetime not null,-- default now(),
datastatus tinyint not null default 0, -- 默认值为0
primary key (id), -- 主键可多列
unique uq_users_email (email),
index ix_users_createtime_updatetime (createtime, updatetime) -- 索引,不指定名字默认就是字段名
)
-- 表选项
-- engine = 'innodb', -- 引擎
-- character set utf8, -- 字符集
-- collate utf8_general_ci, -- 排序规则
;
3.1.3.修改表
-- 修改表 mysql> help alter table
-- 3.1.添加一列 alter table tb_name add 列名 数据类型 修饰符 [first | after 列名]
alter table dotnetcrazy.users
add uid bigint not null unique first; -- MSSQL没有[first | after 列名]
-- 在email后面添加手机号码列
-- 手机号不会用来做数学运算,varchar可以模糊查询(eg:like ‘138%’)
-- 牵扯到国家代号时,可能出现+、-、()等字符,eg:+86
alter table dotnetcrazy.users
add tel varchar(20) not null after email;
-- 3.2.删除一列 alter table tb_name drop 字段名
alter table dotnetcrazy.users
drop uid;
-- 3.3.添加索引 alter table tb_name add index [ix_name] (列名,...)
alter table dotnetcrazy.users
add index ix_users_ucode (ucode); -- 不指定名字默认就是字段名
-- add index (ucode, tel); -- 不指定索引名字,默认就是第一个字段名
-- 添加唯一键 alter table tb_name add unique [uq_name] (列名,列名2...)
alter table dotnetcrazy.users
add unique uq_users_tel_ucode (tel, ucode);
-- add unique (tel, ucode);-- 不指定索引名字,默认就是第一个字段名
-- 3.4.删除索引 alter table tb_name drop index ix_name
alter table dotnetcrazy.users
drop index ix_users_ucode;
-- 删除索引(唯一键) alter table tb_name drop index uq_name
alter table dotnetcrazy.users
drop index uq_users_tel_ucode;
-- drop index tel; -- 唯一键的索引名就是第一个列名
-- 3.5.修改字段
-- 1.修改字段名:`alter table tb_name change 旧列名 新列名 类型 类型修饰符`
-- 此时一定要重新指定该列的类型和修饰符
alter table dotnetcrazy.users
change ucode usercode char(36); -- default uuid();
-- 2.修改字段类型
alter table dotnetcrazy.users
modify username varchar(25) not null;
-- 3.添加默认值:`alter table tb_name alter 列名 set default df_value`
alter table dotnetcrazy.users
alter password set default '7c4a8d09ca3762af61e59520943dc26494f8941b';
3.2.SQLServer
示例服务器:SQLServer 2014
3.2.1.创建、删除数据库
use master
--存在就删除
if exists(select *
from sysdatabases
where Name = N'dotnetcrazy')
begin
drop database dotnetcrazy
end
--创建数据库(简化版:create database dotnetcrazy)
create database dotnetcrazy
on primary --数据库文件,主文件组
(
name ='dotnetcrazy_Data', --逻辑名
size =10 mb, --初始大小
filegrowth =10%, --文件增长
maxsize =1024 mb, --最大值
filename =N'D:\Works\SQL\dotnetcrazy_data.mdf'--存放路径(包含文件后缀名)
)
log on --日记
(
name ='dotnetcrazy_Log',
size =5 mb,
filegrowth =5%,
filename =N'D:\Works\SQL\dotnetcrazy_log.ldf'
);
-- 切换数据库
use dotnetcrazy;
3.2.2.创建、删除表
--存在就删除表
if exists(select *
from sysobjects
where name = N'users')
begin
drop table users
end
-- dotnetcrazy.dbo.users
create table users
(
id int identity, -- 主键,自增长
username nvarchar(20) not null,
email varchar(50) not null,
password char(40) not null, -- sha1
ucode char(36) not null default newid(), -- guid
createtime datetime not null default getdate(),
updatetime datetime not null default getdate(),
datastatus tinyint not null default 0, -- 默认值为0
primary key (id), -- 主键可多列
unique (email),
index ix_users_createtime_updatetime (createtime, updatetime) -- 索引
);
3.1.3.修改表
-- 3.1.添加一列 alter table tb_name add 列名 数据类型 修饰符
-- 在email后面添加手机号码列
alter table users
add tel varchar(20) not null;
-- 3.1.1.添加含唯一键的列
-- 先添加列
alter table users
add uid bigint not null
-- 再添加约束 alter table tb_name add constraint uq_name
alter table users
add constraint uq_users_uid unique (uid); -- 自定义名称
-- 3.1.2.定义和约束一步走(系统设置名字)
-- alter table users
-- add uid bigint not null unique; -- 默认名称
-- 3.2.含唯一键的列
-- 3.2.1.删除约束 alter table tb_name drop constraint uq_name
if exists(select *
from sysobjects
where name = 'uq_users_uid')
alter table users
drop constraint uq_users_uid;
-- 3.2.2.删除列 alter table tb_name drop column 字段名
alter table users
drop column uid;
-- 3.3.修改字段
-- 3.3.1.修改列名:exec sp_rename '表名.旧列名','新列名';
exec sp_rename 'users.ucode', 'usercode';
-- 3.3.2.修改字段类型
alter table users
alter column username varchar(25) not null;
-- 3.3.3.添加默认值:`alter table tb_name alter 列名 set default df_value`
alter table users
add default '7c4a8d09ca3762af61e59520943dc26494f8941b' for password;
知识回顾:
课后拓展:
SQLServer突破内存限制:
https://www.cnblogs.com/zkweb/p/6137423.html
官方demo:
https://www.microsoft.com/en-us/sql-server/developer-get-started/python/ubuntu
官方文档:
https://docs.microsoft.com/zh-cn/sql/linux/sql-server-linux-overview?view=sql-server-2017
PS:SQL Server默认端口为TCP 1433
3.3.区别
简单列举下上面的区别(欢迎补充):
- MySQL自增长是
auto_increment,MSSQL是identity - MySQL可以设置无符号
unsigned,MSSQL不可以直接设置无符号整型,需要通过约束之类的来限制 alter table的时候,MSSQL没有[first | after 列名],而且语法差别也挺大
4.增删改查(CURD)
4.1.MySQL
select语句执行流程:
from 表[inner|left|right] join 表 on 条件where 条件- 对select的结果进行过滤
group by 字段- 根据指定条件把查询结果进行
分组,以用做聚合运算
- 根据指定条件把查询结果进行
having 条件- 对分组聚合运算(
group by)后的结果进行过滤
- 对分组聚合运算(
order by 字段 [asc|desc]- 根据指定字段对查询结果进行排序(默认升序
asc)
- 根据指定字段对查询结果进行排序(默认升序
select 字段limit [偏移量,]显示数量- 显示多少条数据 | 分页显示
增删改
-- 4.1.插入 help insert
-- 自增长主键和默认值的字段可以不写
insert into dotnetcrazy.users(username, password, email, tel, usercode, createtime, updatetime, datastatus)
values ('dnt', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'dnt@qq.com', '18738002038', uuid(), now(), now(), 1);
-- 批量插入
insert into dotnetcrazy.users(username, password, email, tel, usercode, createtime, updatetime, datastatus)
values('xxx', '7c4a8d09ca3762af61e59520943dc26494f8942b', 'xxx@qq.com', '13738002038', uuid(), now(), now(), 0),('mmd', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'mmd@qq.com', '13718002038', uuid(), now(), now(), 1),('小张', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'zhang@qq.com', '13728002038', uuid(), now(), now(), 1);
-- 4.2.修改 help update
update dotnetcrazy.users
set datastatus=99,
updatetime = now()
where username = 'mmd'; -- 一定要有where条件!开发中一般都是先写where条件再写update
-- 4.3.删除
-- 删除数据(自增长不重置)help delete;
delete
from dotnetcrazy.users
where datastatus = 0;
-- 删除全部数据(自增长重置)help truncate;
truncate table dotnetcrazy.users;
查询
-- 数据构造见附录
-- 4.4.查询 help select
-- 查询来源url(去重后)
select distinct url
from file_records;
-- 查询来源url(分组方式)
select url
from file_records
group by url;
-- 分别统计一下url出现的次数(分组+聚合)
-- 分组一般都和聚合函数一起使用
select url, count(*) as count
from file_records
group by url;
-- 分别统计一下url出现的次数,已经删除的文件不算进去
select url, count(*) as count
from file_records
group by url
having count > 3; -- 在group by的结果上筛选
-- 分别统计一下url出现的次数并查出对应的id
select group_concat(id) as ids, url
from file_records
group by url;
-- 内连接查询 innet join tb_name on 关联条件
select file_records.id,
users.id as uid,
users.username,
users.email,
file_records.file_name,
file_records.md5,
inet_ntoa(file_records.ip) as ip,
file_records.url
from users
inner join file_records on file_records.user_id = users.id -- 连接条件
where users.datastatus = 1
and file_records.datastatus = 1
order by file_records.file_name desc; -- 文件名降序排序
-- MySQL没有`select top n`语法,可以使用 limit来实现,eg:top 5
select *
from file_records
limit 5; -- limit 0,5
-- 分页查询
-- page:1,count=5 ==> 0,5 ==> (1-1)*5,5
-- page:2,count=5 ==> 5,5 ==> (2-1)*5,5
-- page:3,count=5 ==> 10,5 ==> (3-1)*5,5
-- 推理:limit (page-1)*count,count
select file_records.id,
users.id as uid,
users.username,
users.email,
file_records.file_name,
file_records.md5,
inet_ntoa(file_records.ip) as ip,
file_records.url
from file_records
inner join users on file_records.user_id = users.id
limit 0,5;
-- limit后面跟表达式就会报错
select file_records.id,
users.id as uid,
users.username,
users.email,
file_records.file_name,
file_records.md5,
inet_ntoa(file_records.ip) as ip,
file_records.url
from file_records
inner join users on file_records.user_id = users.id
limit 5,5;
-- limit (2-1)*5,5; -- limit错误写法
-- limit要放在最后
select file_records.id,
users.id as uid,
users.username,
users.email,
file_records.file_name,
file_records.md5,
inet_ntoa(file_records.ip) as ip,
file_records.url
from file_records
inner join users on file_records.user_id = users.id
order by username desc, file_name desc
limit 10,5; -- 先order by排完序,然后再取第三页的5个数据
-- 查找一下从来没上传过文件的用户
-- right join:以右边表(users)为基准连接
select file_records.id as fid,
users.id as uid,
users.username,
users.email,
file_records.file_name,
file_records.md5,
inet_ntoa(file_records.ip) as ip,
file_records.url
from file_records
right join users on file_records.user_id = users.id
where users.datastatus = 1
and file_records.id is null
order by username desc, file_name desc;
-- 自连接案例:
-- 二级联动 p:province,c:city,a:area
-- 前端一般都会显示省级信息,用户选择后可以获得对应的二三级信息
select c.name, a.name
from city_infos as c
inner join city_infos as a on a.pcode = c.code
where c.pcode = '320000'; -- pcode设置为索引
-- 通过省名称查询
select p.name, c.name, a.name
from city_infos as c
inner join city_infos as p on c.pcode = p.code
inner join city_infos as a on a.pcode = c.code
where p.name = '江苏省';
视图
-- 简单提一下视图:
-- 创建视图
create view view_userinfo as
select id, username, password, email, tel, datastatus
from dotnetcrazy.users;
-- 查询视图
select id, username, password, email, tel, datastatus
from dotnetcrazy.view_userinfo;
-- 删除视图
drop view if exists view_userinfo;
附录:
知识点:
-- 把ip转换成int
select inet_aton('43.226.128.3'); -- inet6_aton()
-- 把int转换成ip
select inet_ntoa('736264195'); -- inet6_ntoa() ipv6
-- 将多个字符串连接成一个字符串
select concat(user_id, ',', file_name, ',', ip, ',', url) as concat_str
from file_records;
-- 将多个字符串连接成一个字符串+可以一次性指定分隔符
select concat_ws(',', user_id, file_name, ip, url) as concat_str
from file_records;
-- 在有group by的查询语句中,select指定的字段要么就包含在group by语句的后面,作为分组的依据,要么就包含在聚合函数中
-- group_concat():将group by产生的同一个分组中的值连接起来,返回一个字符串结果
select group_concat(file_name) as file_name, url, count(*)
from file_records
group by url;
-- having一般对group by的结果进行筛选,where是对原表进行筛选
select group_concat(file_name) as file_name, group_concat(url) as url, count(*) as count
from file_records
group by url
having count >= 3;
-- 四舍五入到指定位数
select round(3.12345, 4);
-- 存小数数据为了不损伤精读一般都是转成整数,eg:3.1415 ==> 整数:31415,倍数:10000
数据构造:
city_data.sql:https://github.com/lotapp/BaseCode/blob/master/database/SQL/city2017.sql
-- 编号,文件名,文件MD5,Meta(媒体类型),当前用户,请求IP,来源地址,请求时间,数据状态
drop table if exists file_records;
create table if not exists file_records
(
id int unsigned auto_increment primary key,
file_name varchar(100) not null,
md5 char(32) not null,
meta_type tinyint unsigned not null default 1,
user_id int unsigned not null,
ip int unsigned not null,
url varchar(200) not null default '/',
createtime datetime not null, -- default now(),
datastatus tinyint not null default 0
);
-- 可以插入2~3次(方便下面演示)
insert into file_records(file_name, md5, meta_type, user_id, ip, url, createtime, datastatus)
values ('2.zip', '3aa2db9c1c058f25ba577518b018ed5b', 2, 1, inet_aton('43.226.128.3'), 'http://baidu.com', now(), 1),
('3.rar', '6f401841afd127018dad402d17542b2c', 3, 3, inet_aton('43.224.12.3'), 'http://qq.com', now(), 1),
('7.jpg', 'fe5df232cafa4c4e0f1a0294418e5660', 4, 5, inet_aton('58.83.17.3'), 'http://360.cn', now(), 1),
('9.png', '7afbb1602613ec52b265d7a54ad27330', 5, 4, inet_aton('103.3.152.3'), 'http://cnblogs.com', now(), 1),
('1.gif', 'b5e9b4f86ce43ca65bd79c894c4a924c', 6, 3, inet_aton('114.28.0.3'), 'http://qq.com', now(), 1),
('大马.jsp', 'abbed9dcc76a02f08539b4d852bd26ba', 9, 4, inet_aton('220.181.108.178'), 'http://baidu.com', now(),
99);
4.2.SQLServer
select语句执行流程:
from 表join类型 join 表 on 条件where 条件- 对select的结果进行过滤
group by 字段- 根据指定条件把查询结果进行
分组,以用做聚合运算
- 根据指定条件把查询结果进行
having 条件- 对分组聚合运算(
group by)后的结果进行过滤
- 对分组聚合运算(
select distinct 字段order by 字段 [asc|desc]- 根据指定字段对查询结果进行排序(默认升序
asc)
- 根据指定字段对查询结果进行排序(默认升序
top 多少行- 类比
limit
- 类比
增删改
-- 4.1.插入 help insert
-- 自增长主键和默认值的字段可以不写
insert into dotnetcrazy.dbo.users(username, password, email, tel, usercode, createtime, updatetime, datastatus)
values ('dnt', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'dnt@qq.com', '18738002038', newid(), getdate(), getdate(),
1);
-- 批量插入 SQLServer一次批量插入最多1000行左右
insert into dotnetcrazy.dbo.users(username, password, email, tel, usercode, createtime, updatetime, datastatus)
values ('xxx', '7c4a8d09ca3762af61e59520943dc26494f8942b', 'xxx@qq.com', '13738002038', newid(), getdate(), getdate(), 0),
('mmd', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'mmd@qq.com', '13738002038', newid(), getdate(), getdate(), 1),
('小明', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'xiaoming@qq.com', '13718002038', newid(), getdate(), getdate(), 1),
('小张', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'zhang@qq.com', '13728002038', newid(), getdate(), getdate(), 1),
('小潘', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'pan@qq.com', '13748002038', newid(), getdate(), getdate(), 1),
('小周', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'zhou@qq.com', '13758002038', newid(), getdate(), getdate(), 1),
('小罗', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'luo@qq.com', '13768002038', newid(), getdate(), getdate(), 1);
-- 4.2.修改 help update
update dotnetcrazy.dbo.users
set datastatus=99,
updatetime = getdate()
where username = 'mmd'; -- 一定要有where条件!开发中一般都是先写where条件再写update
-- 4.3.删除
-- 删除数据(自增长不重置)help delete;
delete
from dotnetcrazy.dbo.users
where datastatus = 0;
-- 删除全部数据(自增长重置)help truncate;
truncate table dotnetcrazy.dbo.users;
查询
-- 查询来源url(去重后)
select distinct url
from file_records;
-- 查询来源url(分组方式)
select url
from file_records
group by url;
-- 分别统计一下url出现的次数(分组+聚合)
-- 分组一般都和聚合函数一起使用
select url, count(*) as count
from file_records
group by url;
-- 分别统计一下url出现的次数,已经删除的文件不算进去
select url, count(*) as count
from file_records
group by url
having count(*) > 3; -- 在group by的结果上筛选,★写成count就不行了★
-- 分别统计一下url出现的次数并查出对应的id
-- SQLServer2017新增string_agg
select ids =(select stuff((select ',' + cast(id as varchar(20)) from file_records as f
where f.url = file_records.url for xml path ('')), 1, 1, '')),url from file_records
group by url;
-- 内连接查询 innet join tb_name on 关联条件
select file_records.id,
users.id as uid,
users.username,
users.email,
file_records.file_name,
file_records.md5,
file_records.ip,
file_records.url
from users
inner join file_records on file_records.user_id = users.id -- 连接条件
where users.datastatus = 1
and file_records.datastatus = 1
order by file_records.file_name desc; -- 文件名降序排序
-- 显示前5个数据
select top 5 * from file_records;
-- 分页查询 第3页,每页5条
select *
from (select row_number() over (order by username desc, file_name desc) as id,
file_records.id as fid,
users.id as uid,
users.username,
users.email,
file_records.file_name,
file_records.md5,
file_records.ip,
file_records.url
from file_records
inner join users on file_records.user_id = users.id) as temp
where id > (3 - 1) * 5 and id <= 3 * 5;
-- 简单提一下视图:
-- 存在就删除
if exists(select *
from sysobjects
where name = N'view_userinfo')
begin
drop view view_userinfo
end
-- 创建视图
create view view_userinfo as
select id, username, password, email, tel, datastatus
from users;
-- 查询视图
select id, username, password, email, tel, datastatus
from view_userinfo;
附录
知识点:
select getdate() as datatime, newid() as uuid;
-- 类似于concat的效果
select cast(id as varchar(20)) + ','
from file_records for xml path ('');
-- 移除多余的字符
-- STUFF(<character_expression>,<开始>,<长度>,<character_expression>)
-- 将字符串插入到另一个字符串中。它会删除开始位置第一个字符串中的指定长度的字符,然后将第二个字符串插入到开始位置的第一个字符串中
select stuff((select ',' + cast(id as varchar(20))
from file_records for xml path ('')), 1, 1, '');
数据构造:
--存在就删除表
if exists(select *
from sysobjects
where name = N'file_records')
begin
drop table file_records
end
-- 因为SQLServer的int没有unsigned,所以推荐使用bigint
create table file_records
(
id bigint identity (1,1) primary key,
file_name varchar(100) not null,
md5 char(32) not null,
meta_type tinyint not null default 1,
user_id int not null,
ip bigint not null, -- 在程序中自行转换
url varchar(200) not null default '/',
createtime datetime not null default getdate(),
datastatus tinyint not null default 0
);
-- 可以插入3次(方便下面演示)
insert into file_records(file_name, md5, meta_type, user_id, ip, url, createtime, datastatus)
values ('2.zip', '3aa2db9c1c058f25ba577518b018ed5b', 2, 1, 736264195, 'http://baidu.com', getdate(), 1),
('3.rar', '6f401841afd127018dad402d17542b2c', 3, 3, 736103427, 'http://qq.com', getdate(), 1),
('7.jpg', 'fe5df232cafa4c4e0f1a0294418e5660', 4, 5, 978522371, 'http://360.cn', getdate(), 1),
('9.png', '7afbb1602613ec52b265d7a54ad27330', 5, 4, 1728288771, 'http://cnblogs.com', getdate(), 1),
('1.gif', 'b5e9b4f86ce43ca65bd79c894c4a924c', 6, 3, 1914437635, 'http://qq.com', getdate(), 1),
('大马.jsp', 'abbed9dcc76a02f08539b4d852bd26ba', 9, 4, 3702877362, 'http://baidu.com', getdate(), 99);
5.MySQL命令扩展:
- 命令帮助:
MySQL>help 命令- PS:版本查询:
select version();
- PS:版本查询:
- 查看字符集:
show character set;- utf8:使用1~3bytes来表示一个Unicode字符(常用)
- utf8mb4:使用1~4bytes来表示一个Unicode字符(
Emoji表情or不常用汉字)
- 排序规则:
show collation;- eg:
show collation where Collation like "%utf8%";
- eg:
- 查看引擎:
show engines;InnoDB是默认存储引擎
- 查看所有数据库:
show databases; - 切换数据库:
use db_name; - 查看所有表:
show tables; - 显示表状态:
show table status;- eg:
show table status like 'users';
- eg:
- 显示表结构:
desc tb_name; - 查看创建表时的SQL:
show create table tb_name; - 显示表的索引:
show indexes from tb_name - 查看mysql数据文件目录
show variables like '%dataDir%'; - 查询当前会话的连接号:
select connection_id();
PS:\G可以竖排显示:show table status like 'users'\G
最后YY几句:
- 没使用
Linux之前,我认为C#是最优美、性价比最高、最简单的语言,之后发现Python才是最简单的语言,C#只能是最优美、性价比最高的语言- 现在准备接触Golang,最终评价先待定吧
- 刚接触MySQL发现SQLServer真的很方便,研究MySQL越深越发现==>平心而讲:
- 对应开发人员来说,
MySQL真的比SQLServer方便 - 对于运维人员来说,
SQLServer真的太方便了 - PS:中小企业如果没有专门运维人员,还是推荐
SQLServer,如果有运维人员或者团队有点Linux运维功底的还是选择MySQL吧
- 对应开发人员来说,
送大家一句话:思维局限在一个维度里,认知就会发生偏移,希望大家能够勇于尝试和突破~
因为时间问题之后的SQL案例就不对比演示了,直接全部MySQL走起(之后只能说尽量加上SQLServer版的演示)
下节预估:查询优化
课外拓展:
MySQL在线IDE:phpMyAdmin
https://www.phpmyadmin.net/downloads/
MySQL最火工具:Navicat Premium
https://www.cnblogs.com/dotnetcrazy/p/9711198.html
MySQL最佳工具:dbForge Studio for MySQL
https://www.devart.com/dbforge/mysql/studio/download.html
【跨平台】SQLServer工具:SqlOps
https://www.cnblogs.com/dunitian/p/8045081.html
https://github.com/Microsoft/azuredatastudio/releases
【跨平台】都支持:JetBrains DataGrip 【推荐】
https://www.cnblogs.com/dotnetcrazy/p/9711763.html
MariaDB数据类型
https://www.w3cschool.cn/mariadb/mariadb_data_types.html
MySQL 数据类型
https://www.w3cschool.cn/mysql/mysql-data-types.html
(MariaDB)MySQL数据类型详解和存储机制
https://www.cnblogs.com/f-ck-need-u/archive/2017/10/25/7729251.html
Sql Server中的数据类型和Mysql中的数据类型的对应关系
https://blog.csdn.net/lilong329329/article/details/78899477
ALTER TABLE和CREATE INDEX的区别
https://blog.csdn.net/qq_34578253/article/details/72236808
1. create index必须提供索引名,对于alter table,如果你不提供索引名称,MySQL会自动创建索引名称(默认为第一个列名)
2. create index一个语句一次只能建立一个索引,alter table可以在一个语句建立多个,如:
- `ALTER TABLE HeadOfState ADD PRIMARY KEY (ID), ADD INDEX (LastName,FirstName);`
3. 只有alter table才能创建主键

 浙公网安备 33010602011771号
浙公网安备 33010602011771号