二进制文件篇
源代码到可执行文件经过的步骤:
(1)预处理(preprocess) -E 可单独执行预处理
(2)编译(compile) -S
(3)汇编(assemble) -c
(4)链接(link)
- 预处理:主要是处理源代码中以'#'开头的预处理指令,eg:'#include'
- 编译:读入以某种语言(源语言 )编写的程序,输出目标语言编写的程序。该阶段将预处理文件进行一系列的词法分析,语法分析,语义分析以及优化,最终生成汇编代码。(实际在GCC的实现中,编译与预处理已经合并处理)且由于GCC的优化策略,生成汇编代码中函数printf()被替换成了puts(),因为在printf()只有单一参数时,与puts十分类似且性能较高。
gcc -Wall -g -o test(目标文件) test.c(源文件)
[-Wall:编译过程中会输出警告信息(warning)]
[-g:编译器会收集调试(debug)信息]
[-o:将编译完成后的可执行文件以指定的名称输出到指定的文件夹下]
[-32:编译32位程序]
- 汇编: 汇编器根据汇编指令和机器指令的对照表进行编译,将.s汇编成目标文件.o,此时的.o文件是可重定位文件,可以使用objdump命令来查看其内容。
- 链接:将目标文件及其依赖库进行链接生成可执行文件。'static'即可指定只用静态链接
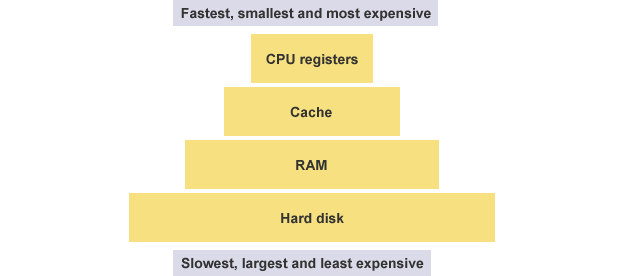
形象地理解寄存器,内存,辅存
1.寄存器:寄存器就是衣服上的口袋,只有那么几个,只装最常用或者马上用的东西。
最频繁读写的数据(比如循环变量)都会放在寄存器里面。CPU优先读写寄存器,再由寄存器跟内存交换数据
2.内存:内存是背包,有时候拿点东西放到口袋里,有时候从口袋里拿出点东西放到背包里
3.辅存:辅存就是你家的抽屉,可以放很多东西,但是存取不方便
CPU register:CPU寄存器
Cache:缓存
RAM:内存
Hard Disk:硬盘
详细了解寄存器
早期的X86有8个寄存器,而且每个都有不同的用途,现在的寄存器已经有100多个了,都变成了通用寄存器,不特别指定用途了,但是早期寄存器的名字都被保存了下来:
- EAX
- EBX
- ECX
- EDX
- EDI
- ESI
- EBP
- ESP
EAX(累加器):默认保存着加法乘法结果函数返回值
ESI/EDI(源/目标索引寄存器):通常用于字符串操作,ESI保存着源字符串的首地址,EDI保护着目标字符串的首地址
ESP:扩展栈指针寄存器,指向当前栈顶即保存着当前栈顶的地址
EBP(扩展基址指针寄存器):指向当前栈底即保存着当前栈底的地址。
EIP(指令指针寄存器):该寄存器存放着将要执行的代码的地址,当一个程序开始运行时系统自动将EIP清零,每读取一条指令,EIP自动增加取入CPU的字节数,在控制程序流程时,控制EIP寄存器的值显得尤为关键,决定着是否可以驰骋内存。
还有个跟运算息息相关的EFLAGS标志寄存器,这里面装着很多标志位,标志着运算状态等信息
上面8个寄存器种,前面7个都是通用的。ESP寄存器用于保存当前的Stack地址,即特殊用途
小tips:通常的64位技术是相对32位技术而言的,这个位数指的是CPU GPRs(General-Purpose register通用寄存器)的数据宽度为64位,而32位CPU的通用寄存器数据宽度为32位
64位相对于32位有更大的寻址能力,最大支持到16GB内存,而32位只支持到4GB内存
ELF文件类型
1.ELF文件分为3类:
(1).exec 可执行文件
经过链接的,可执行的目标文件,通常也被称为程序
(2).rel 可重定位文件:由源文件编译而成尚未链接的目标文件,通常以(.o)作为扩展名。用于与其他目标文件进行链接以构成可执行文件或动态链接库
由源文件编译而成且尚未链接的目标文件,通常以'.o'作为扩展名,用于与其他目标文件进行链接构成可执行文件或动态链接库,通常是一段位置独立的代码
(3).dyn 共享目标文件
动态链接库文件。用于在链接过程中与其他动态链接库或可重定位文件一起构建新的目标文件,或者在可执行文件加载时,链接到进程中作为运行代码的一部分
- 总结:源文件---->预处理---->编译---->汇编---->链接
.rel
ELF文件结构
审视一个目标文件的两个视角:
- 链接视角:以‘节’来进行划分
- 运行视角:以‘段’来进行划分
链接视角: - 代码节(.text):用于保存可执行的机器指令
- 数据节(.data):用于保存已初始化的全局变量和局部静态变量
- BSS节(.bss):用于保存未初始化的全局变量和局部静态变量
将程序指令和程序数据分开存放有许多好处
当程序被加载,数据和指令分别被映射到不同的虚拟区域:
由于数据区域对于进程来说是可读写的,而指令区域对于进程来说是只读的,所以这两个虚存区域可以被设置成可读写和只读,防止程序的指令被改写和利用
ELF文件头:
位于目标文件最开始的位置,包含描述整个文件的一些基本信息(ELF文件类型,版本/ABI版本,目标机器,程序入口,段表和节表的位置和长度等)
魔术字符的作用:当文件被映射到内存时,可以通过搜索该字符确定映射地址,在dump时非常有用
- 何为dump:
From zhihu:
作为动词:一般指将数据导出,转存成文件或静态形式。比如可以理解成:把内存某一时刻的内容转换成文件
作为名词:一般特指上述过程中所用得到的文件或静态形式
节头表
一个目标文件包含许多节(代码节,数据节,BSS节),这个节的信息保存在节头表中,表的每一项都是一个Elf64_Shdr结构体(也被称为节描述符),记录了节的名字,长度,偏移,读写权限等信息。
节头表对于程序运行不是必须的,因为它与程序布局无关,是程序头表的任务,所以常有程序去除节头表,以增加反编译器的分析难度。
静态链接
两个或多个不同的目标文件通过链接(linking)组成一个可执行文件。根据发生时间不同,分为编译时链接,加载时链接,运行时链接
动态链接
随着系统中可执行文件的增加,静态链接带来的磁盘和空间浪费问题愈发严重。例如大部分可执行文件都需要glibc,那么在静态链接时就要把libc.a和编写的代码链接进去,单个libc.a文件的大小为5M左右,那么1000个就是5G。
如果不把系统库与自己编写的代码链接到一个可执行文件,而是分割成两个独立的,模块,等到程序真正运行时再把这两个模块进行链接,就可以节省硬盘空间,并且内存中的一个系统库可以被多个程序使用,还节省了物理内存空间
大端与小端
小端:小端就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端(低低高高)
低地址—————>高地址
0x12 | 0x34 | 0x56 | 0x78
大端:大端就是低位字节排放在内存的高地址端,高位字节排放在内存的低地址端(低高低高)
低地址—————>高地址
0x78 | 0x56 | 0x34 | 0x12
大小端出现的原因
计算机系统以字节为单位,每个地址单元都对应着一个字节,一个字节为8bit。但对于位数大于8位的处理器,如16位与32位的处理器,由于寄存器的宽度大于一个字节,那么必然存在一个如何将多个字节安排的问题,因此导致了大端存储模式和小端存储模式的出现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号