Etcd中Raft joint consensus的实现
2021-06-12 15:02 DoPeter 阅读(887) 评论(0) 收藏 举报Joint consensus

分为2个阶段,first switches to a transitional configuration we call joint consensus; once the joint consensus has been committed, the system then transitions to the new configuration. The joint consensus combines both the old and new configurations.
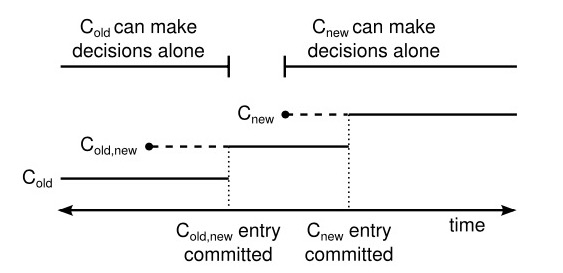
这样就非常直观,在joint consensus的配置中,包含了新老节点的配置,如果有节点变更,并进入了 joint consesus阶段,在日志复制的大多数同意策略中,达成一致就需要新老节点中都有节点出来同意。在 joint consensus 状态中,同意节点变更的应用也是需要大多数同意的,因为是基于日志复制来分发。
Raft log replication flow
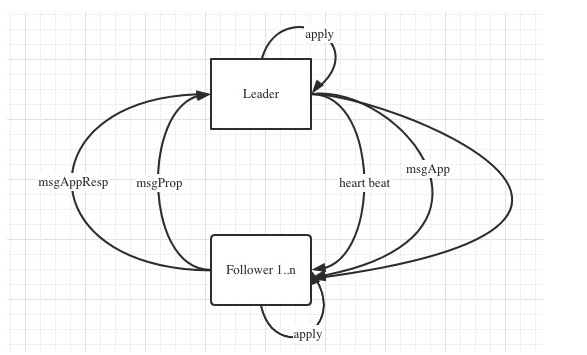
上图是etcd中raft提交的一个简约流程,没有标注顺序是因为都在自旋。
很有意思的是,我理解joint consensus的实现类似于log replication的应用,将joint consensus中带有的成员变更信息作为日志的内容通过log replication来应用到每个raft节点成员中。所以可以说,joint consensus是基于raft log replication。
如果将raft算法模块看作整体,说是自举其实也能部分说通,因为它改变了自身的成员信息,影响了raft将消息同步到谁的策略。
说是log replication的应用也是可以的,将raft算法模块白盒化,log replication算作一个子模块,joint consensus算作一个。
说本身就是raft算法模块,不将joint consensus看作是新增的部分,也是可行的。
Impl in Etcd
开始和结束joint consensus 的 message type 是定义在 pb中的。
const (
EntryNormal EntryType = 0
EntryConfChange EntryType = 1
EntryConfChangeV2 EntryType = 2
)
joint consensus的过程,首先是通过propose将EntryConfChange传入到raft算法模块内部,在leader应用了更改后,同样发送EntryConfChange消息到其他节点,大多数同意后,follower&learner才开始apply节点变更,并且leader 在 apply时发送EntryConfChangeV2结束节点变更的消息。
Structure of join consensus
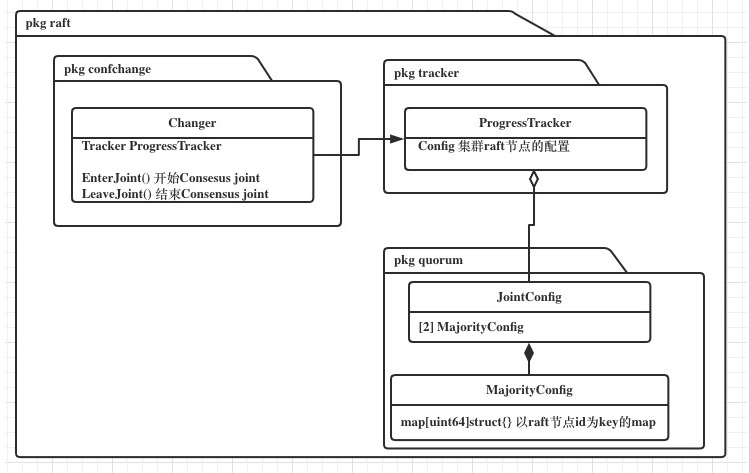
在Confchange中封装了joint consensus的阶段变更逻辑。
JointConfig是由2个MajorityConfig的map组成,一个对应变更节点集合,一个对应老节点集合。
由上图的引用关系最终在Confchange中来组装逻辑。
Confchange中将变更节点集合表示为 incoming,老节点集合表示为 outgoing。
func incoming(voters quorum.JointConfig) quorum.MajorityConfig { return voters[0] }
func outgoing(voters quorum.JointConfig) quorum.MajorityConfig { return voters[1] }
func outgoingPtr(voters *quorum.JointConfig) *quorum.MajorityConfig { return &voters[1] }
节点未发生变更时,节点信息存储在JointConfig[0] ,即incoming的指向的集合中。
当EnterJoint时,将老节点拷贝至outgoing中,变更节点拷贝至incoming中。
LeaveJoint时,删除下线的节点,合并在线的节点并合并至incoming中,完成节点变更过程。
Logic flow of joint consensus
Proposal trigger
在EtcdServer中不论是AddMember()还是RemoveMembe()以及其他2个会修改Member成员的方法,都会触发
configure()函数
// configure sends a configuration change through consensus and
// then waits for it to be applied to the server. It
// will block until the change is performed or there is an error.
func (s *EtcdServer) configure(ctx context.Context, cc raftpb.ConfChange) ([]*membership.Member, error) {
lg := s.Logger()
cc.ID = s.reqIDGen.Next()
ch := s.w.Register(cc.ID)
start := time.Now()
if err := s.r.ProposeConfChange(ctx, cc); err != nil {
s.w.Trigger(cc.ID, nil)
return nil, err
}
select {
case x := <-ch:
if x == nil {
lg.Panic("failed to configure")
}
resp := x.(*confChangeResponse)
lg.Info(
"applied a configuration change through raft",
zap.String("local-member-id", s.ID().String()),
zap.String("raft-conf-change", cc.Type.String()),
zap.String("raft-conf-change-node-id", types.ID(cc.NodeID).String()),
)
return resp.membs, resp.err
case <-ctx.Done():
s.w.Trigger(cc.ID, nil) // GC wait
return nil, s.parseProposeCtxErr(ctx.Err(), start)
case <-s.stopping:
return nil, ErrStopped
}
}
s.r.ProposeConfChange(ctx, cc) 会将Config Change向Raft中 propose。
这段里面还有个有趣的逻辑,利用了一个channel等待操作完成再返回结果,和读一致性的实现异曲同工。
//向channel池中注册一个需要等待的channel
ch := s.w.Register(cc.ID)
//发送信号进该channel
s.w.Trigger(cc.ID, nil)
select {
//等待该channel返回信号
case x := <-ch:
if x == nil {
lg.Panic("failed to configure")
}
...
}
Proposal logic of Leader
Leader收到Proposal后,会进行如下处理:
e := &m.Entries[i]
var cc pb.ConfChangeI
if e.Type == pb.EntryConfChange {
var ccc pb.ConfChange
if err := ccc.Unmarshal(e.Data); err != nil {
panic(err)
}
cc = ccc
} else if e.Type == pb.EntryConfChangeV2 {
var ccc pb.ConfChangeV2
if err := ccc.Unmarshal(e.Data); err != nil {
panic(err)
}
cc = ccc
}
if cc != nil {
alreadyPending := r.pendingConfIndex > r.raftLog.applied
alreadyJoint := len(r.prs.Config.Voters[1]) > 0
wantsLeaveJoint := len(cc.AsV2().Changes) == 0
var refused string
if alreadyPending {
refused = fmt.Sprintf("possible unapplied conf change at index %d (applied to %d)", r.pendingConfIndex, r.raftLog.applied)
} else if alreadyJoint && !wantsLeaveJoint {
refused = "must transition out of joint config first"
} else if !alreadyJoint && wantsLeaveJoint {
refused = "not in joint state; refusing empty conf change"
}
if refused != "" {
r.logger.Infof("%x ignoring conf change %v at config %s: %s", r.id, cc, r.prs.Config, refused)
m.Entries[i] = pb.Entry{Type: pb.EntryNormal}
} else {
r.pendingConfIndex = r.raftLog.lastIndex() + uint64(i) + 1
}
}
如果发现当前是在joint consensus过程中,拒绝变更,直接将message type 变成普通的entry。
处理完毕后,会等待将该消息分发。
Logic of apply
当大多数节点commit后,就会Ready至EtcdServer,然后开始apply config的过程,同apply log的过程是相同的。
自旋Ready从raft module 到 EtcdServer的过程在上一篇日志复制中已经描述过。
直接看raft module 中的代码。
apply分为2步,第1步是EtcdServer apply raft log的逻辑,第2步是raft 胶水 advance()的逻辑。
在joint consensus中就是首先应用节点配置,然后在advance中结束 joint consensus。
apply config
func (r *raft) applyConfChange(cc pb.ConfChangeV2) pb.ConfState {
cfg, prs, err := func() (tracker.Config, tracker.ProgressMap, error) {
changer := confchange.Changer{
Tracker: r.prs,
LastIndex: r.raftLog.lastIndex(),
}
if cc.LeaveJoint() {
return changer.LeaveJoint()
} else if autoLeave, ok := cc.EnterJoint(); ok {
return changer.EnterJoint(autoLeave, cc.Changes...)
}
return changer.Simple(cc.Changes...)
}()
if err != nil {
// TODO(tbg): return the error to the caller.
panic(err)
}
return r.switchToConfig(cfg, prs)
}
逻辑的解释在上面介绍Changer中。
joint consensus completely
func (r *raft) advance(rd Ready) {
r.reduceUncommittedSize(rd.CommittedEntries)
// If entries were applied (or a snapshot), update our cursor for
// the next Ready. Note that if the current HardState contains a
// new Commit index, this does not mean that we're also applying
// all of the new entries due to commit pagination by size.
if newApplied := rd.appliedCursor(); newApplied > 0 {
oldApplied := r.raftLog.applied
r.raftLog.appliedTo(newApplied)
if r.prs.Config.AutoLeave && oldApplied <= r.pendingConfIndex && newApplied >= r.pendingConfIndex && r.state == StateLeader {
// If the current (and most recent, at least for this leader's term)
// configuration should be auto-left, initiate that now. We use a
// nil Data which unmarshals into an empty ConfChangeV2 and has the
// benefit that appendEntry can never refuse it based on its size
// (which registers as zero).
ent := pb.Entry{
Type: pb.EntryConfChangeV2,
Data: nil,
}
// There's no way in which this proposal should be able to be rejected.
if !r.appendEntry(ent) {
panic("refused un-refusable auto-leaving ConfChangeV2")
}
r.pendingConfIndex = r.raftLog.lastIndex()
r.logger.Infof("initiating automatic transition out of joint configuration %s", r.prs.Config)
}
}
if len(rd.Entries) > 0 {
e := rd.Entries[len(rd.Entries)-1]
r.raftLog.stableTo(e.Index, e.Term)
}
if !IsEmptySnap(rd.Snapshot) {
r.raftLog.stableSnapTo(rd.Snapshot.Metadata.Index)
}
}
如果是Leader并且正在joint consensus过程中,将EntryConfChangeV2加入自己的日志中,通过Ready的自旋进行分发。
同样是日志复制的过程来结束joint consensus。
Summary
整个过程的逻辑还未用场景来做一些推导,等把读一致性写完,同大多数复制来一起验证一次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号