Etcd中Raft log replication的实现
2021-05-15 20:19 DoPeter 阅读(595) 评论(0) 收藏 举报Raft state of log

commitIndex : A log entry is committed once the leader that created the entry has replicated it on a majority of the servers.
在大多数服务器上复制了该条日志,则该条日志的index可以被认为是commited
lastApplied : 上一个被状态机应用的index
这2个属性都被标注了 volatile
Impl in Etcd
日志复制分为了2个阶段的过程,commit和apply,commit是raft状态机间相互确认日志同步的过程,apply是应用处理好相关日志并通知raft状态机已被应用的过程
apply的过程较为抽象,由应用来决定业务上需要apply的过程,实际上是应用commited的日志的应用逻辑,在完成逻辑后,只是向raft状态机标记日志被应用方处理了
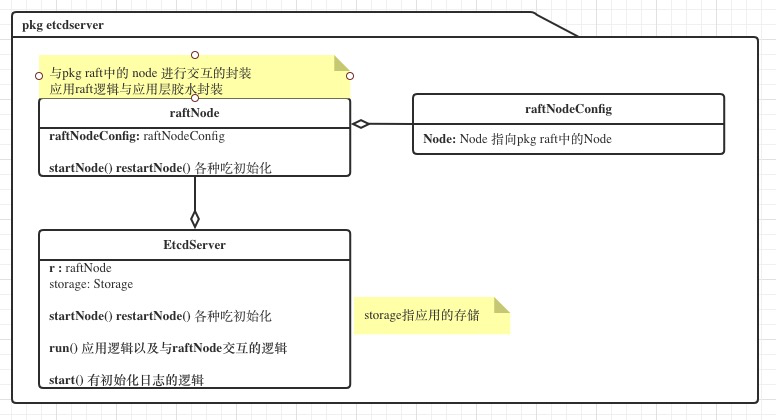
Structure

主要由2个包组成,
pkg raft 是raft算法的具体实现
pkg etcdserver作为使用raft算法的应用,包含具体的应用逻辑与交互胶水
pkg raft

pkg etcdserver
remote request sequential flow

raft msg handle sequential flow
就是试试mermaid,还蛮好用的
Flow
Commit flow
proposal
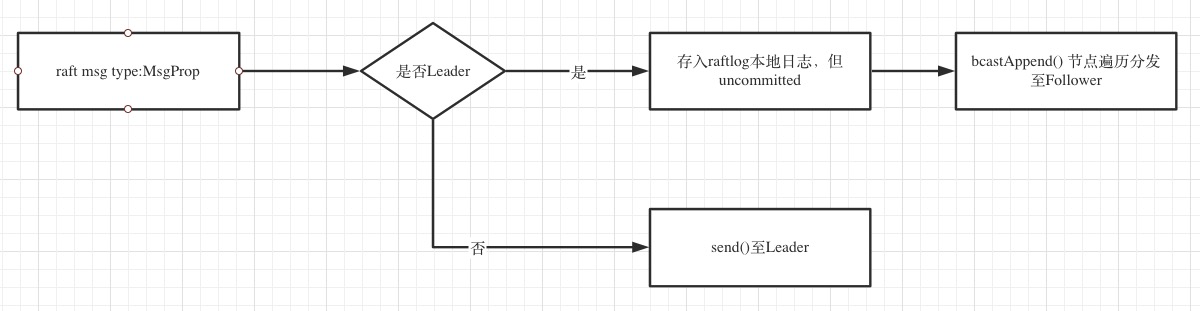
follower accept proposal

leader commit proposal
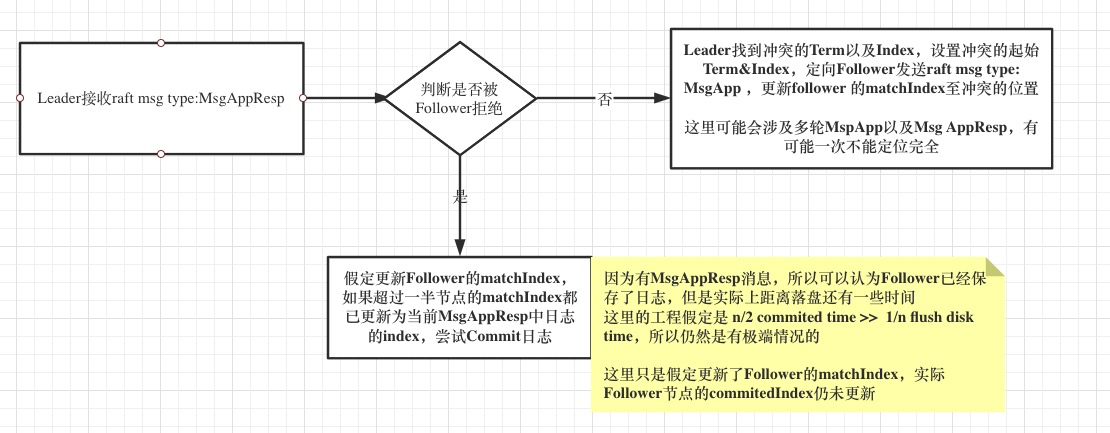

除开SnapShot以及重启节点的特殊逻辑,正常启动一个Node,在Storage中实际上存储了uncommited&commited的日志,并且在启动时设置了commitedIndex就是日志的最大长度,某些极端情况下,日志会有不同,所以在Follower accept proposal的过程中,会有检测冲突的过程,以及Leader强制Follower跟随自己的日志
apply flow
每个节点都会有自己的applied index,并不需要同步。
流程见 raft msg handle sequential flow
这一步 Node(pkg raft): call ready(), collect entries from raft log & msgs needs handle ,会生成 Ready 数据,里面包含untable entries,以及 committed entries。其中Entries字段实际上是包含了 raftlog中 unstable 的日志,里面含有uncommitted&committed的日志,因为没有被标记成applied,所以是 unstable的。
Ready通过channel数据传输至 EtcdServer后,在这里应用层的逻辑就会执行,存储,应用,之后mark 日志为 applied,并且将unstable中applied的日志清除掉。
Summary
缺失了snapshot,log compact ,leader change , config change , read linear的流程。
在交互上还未去确认的地方,是否applied过后的日志才被etcd承认,按照目前的流程,其实commit过后的,虽然有可能会丢失,但也可以被承认如果是乐观看待的话。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号