Redis集群原理及搭建(Twemproxy、Predixy代理搭建、Redis Cluster集群)
1 引言
网上很多文章会把集群和主从复制混为一谈,其实这两者是存在本质差异的,各自解决的问题不同。Redis在单机/单节点/单实例存在的风险:单点故障、容量有限、并发压力问题。Redis主从复制配合Sentinel故障监控和转移主要解决的是单点故障和并发压力,并没有解决服务器内存有限问题。
注意:内存不是单纯的砸钱的问题,当服务器内存过大后对持久化和主从切换都是比较费时间的。所以,通常Redis服务器内存不会设置的太大。通过Redis集群扩容收容来解决内存有限问题。
本文主要针对Redis服务器容量有限问题进行集群模型推导,并通过主流代理和官方Redis Cluster实现Redis集群。
2 集群模型推导
2.1 AKF服务拆分
X抽拆分
当我们业务的访问上升后,单台Redis承载不了访问压力时,通常会进行横向扩容即如下图所示,通过横向的全量、镜像部署多个副本节点分担读请求,实现读写分离/主备,从而提高Redis的访问性能。

Y轴拆分
通过X轴横向拆分解决了并发读的问题,如果某些功能被频繁访问,涉及到的数据频繁读写,这是可以将这部分独立出来,按不同的业务将数据拆分。如下图

Z轴拆分
在上面的AFK原则X-Y拆分之后,对服务器做了主从主备复制,然后做了业务拆分,不同的Redis负责不同的业务请求,这时候随着业务的发展,可能会存在某些业务访问量要明显高于其他业务,例如对于Y轴上一个Redis,它负责某一样业务,但是这个业务的数据访问巨大,那就只好对数据请求进行AFK的Z轴拆分。先分析下数据请求的情况,然后根据访问来源,分为北京的、上海的这样不同的Redis虽然是负责不同的数据,但是负责的业务是一样的。AFK拆分图示:
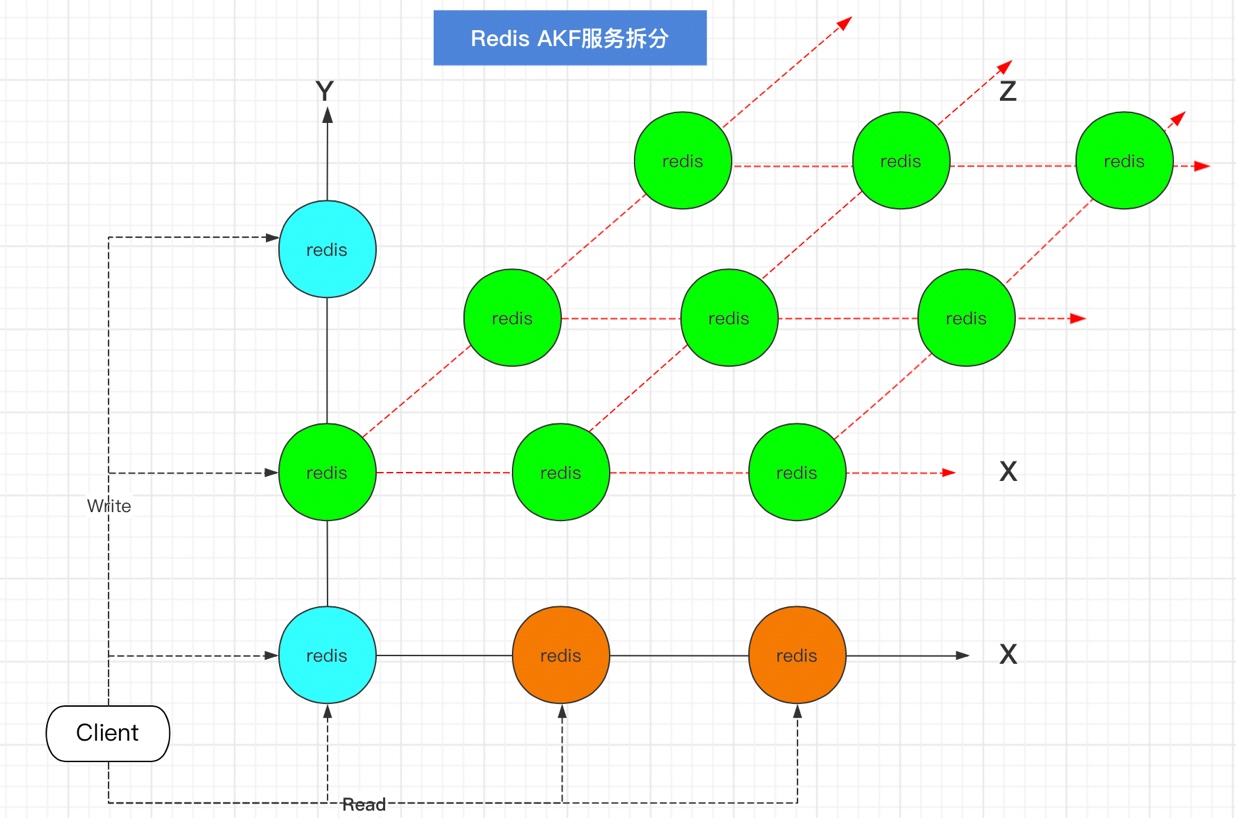
AFK总结
X轴拆分:水平复制,就是单体系统多运行几个实例,做集群加负载均衡的模式,主主、主备、主从。
Y轴拆分:基于不同的业务拆分。
Z轴拆分:基于数据拆分。
没有最好的架构,只有更适合的架构。不要为了技术而技术!
2.2 集群数据存取
2.2.1 数据分类存取
数据分类存储即将数据按逻辑业务拆分存储到不同的Redis服务器中,适用于业务之间数据交集不多。具体图示如下:
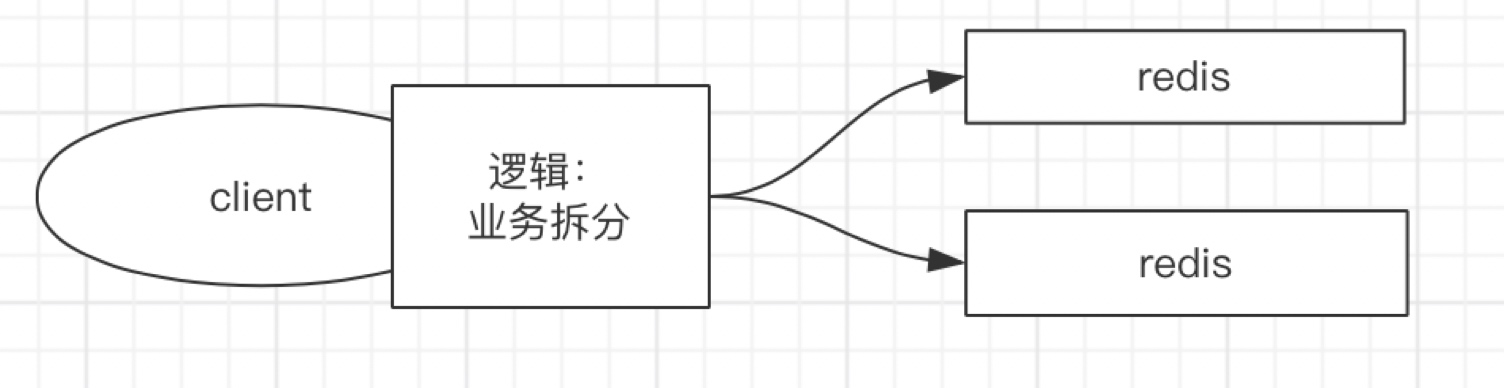
分类储存前提是数据可以进行拆分,如果数据不能拆分这种模式就不适用了。
2.2.2 Sharding分片存取
当数据不能按业务拆分,可以使用分片存储。如果将某条数据存储到Redis后,查询的时候希望可以直接去这台数据库查询,通常可以把数据的固定值通过一定的算法进行计算后再存储,当取的时候同样通过该值计算后再去查指定的Redis,常用的方式如下:
- Modula(Hash+取模)
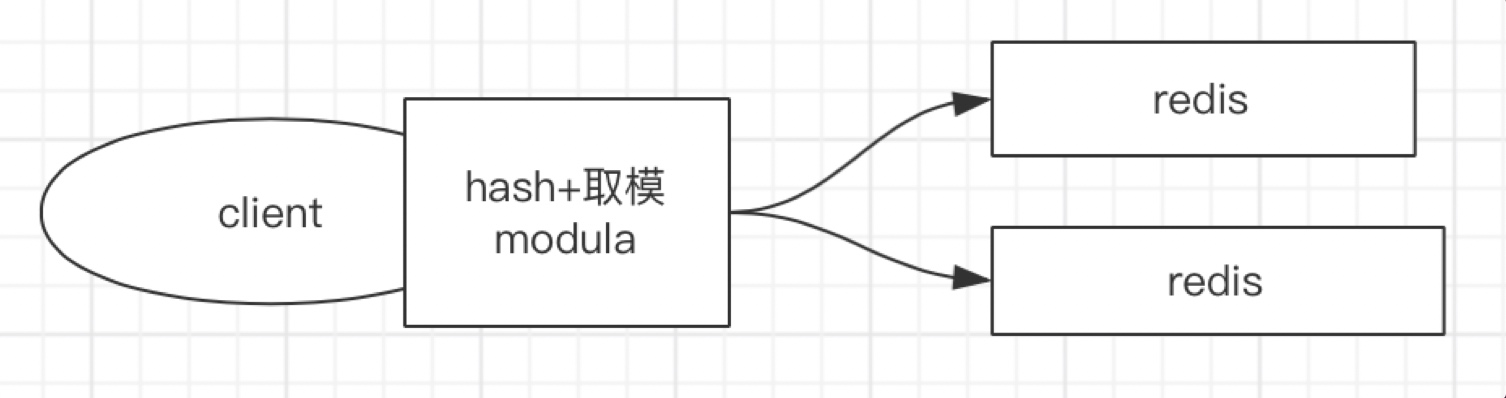
缺点:取模的数须固定,即服务器台数需固定,否则会存在数据查不到的情况。比如,原有2台服务器,用户A的id通过Hash计算后与2取模,结算结果存在node1中。当服务器扩展到3台后,用户A的id通过Hash计算后需要与3取模,计算结果可能就不在node1上了。所以,这种模式会影响分布式下的扩展性。
2. Random(随机存储)

即随机将数据存储到某台Redis中,但是缺点也很明显,数据随机存储后,取数据就不方便了。但是,这种模式有一些特定的场景是可以使用的,比如消息队列。
3. Kemata(一致性哈希)
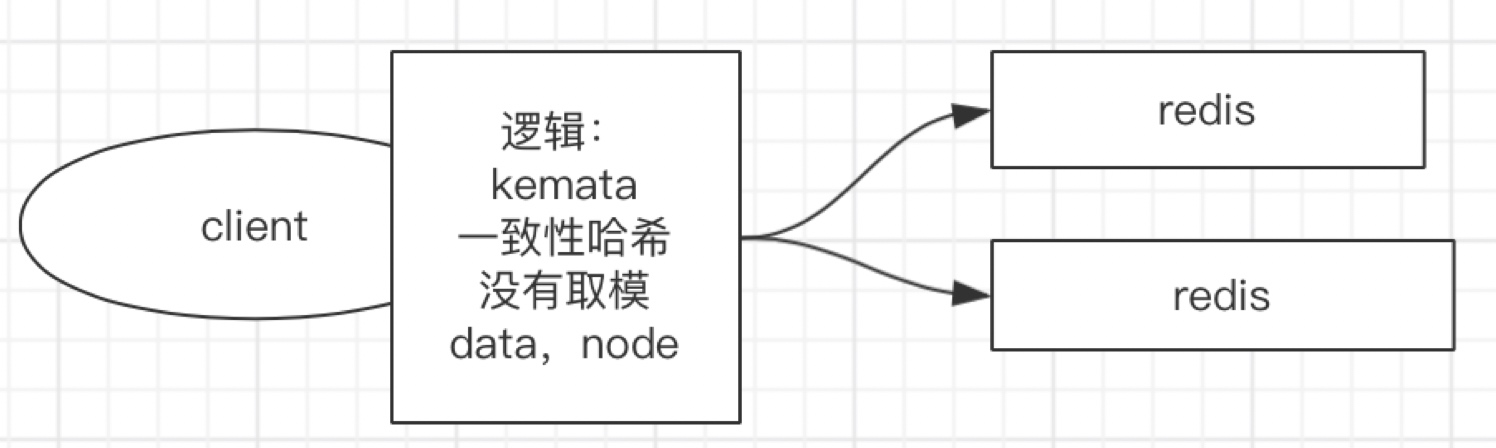
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^ 32-1取模。
第一步:将服务器的固定值(IP或主机名,建议主机名)Hash计算后对2^ 32-1取模,得到0到2^ 32的值,对应到Hash环上,如下图:
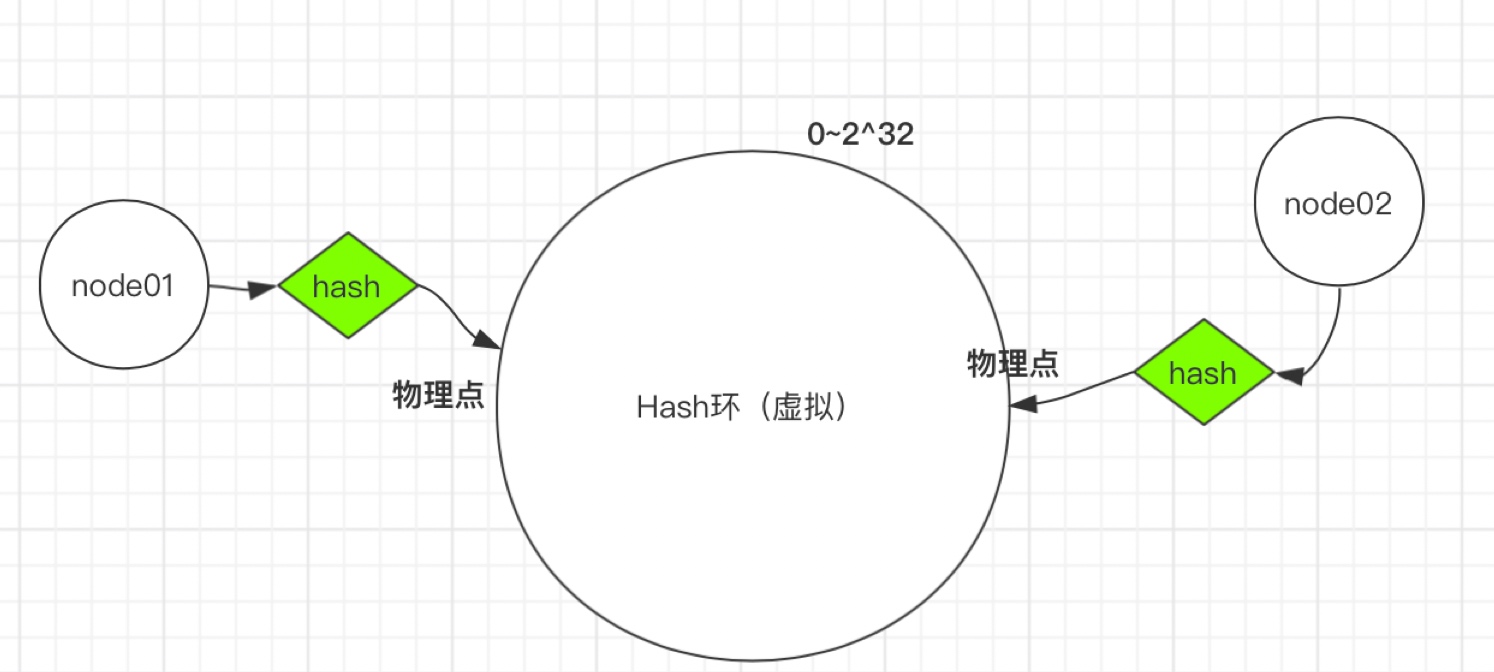
第二步:将需要存储的数据,按第一步相同的Hash计算,同样对2^ 32-1取模,得到0到2^ 32的值同样对应到虚拟Hash环上。将数据从所在位置顺时针找第一台遇到的服务器节点,这个节点就是该key存储的服务器。
例如我们有k1、k2两个key,经过哈希计算后,在环空间上的位置如下:k1存储在node1,k2存储在node2。
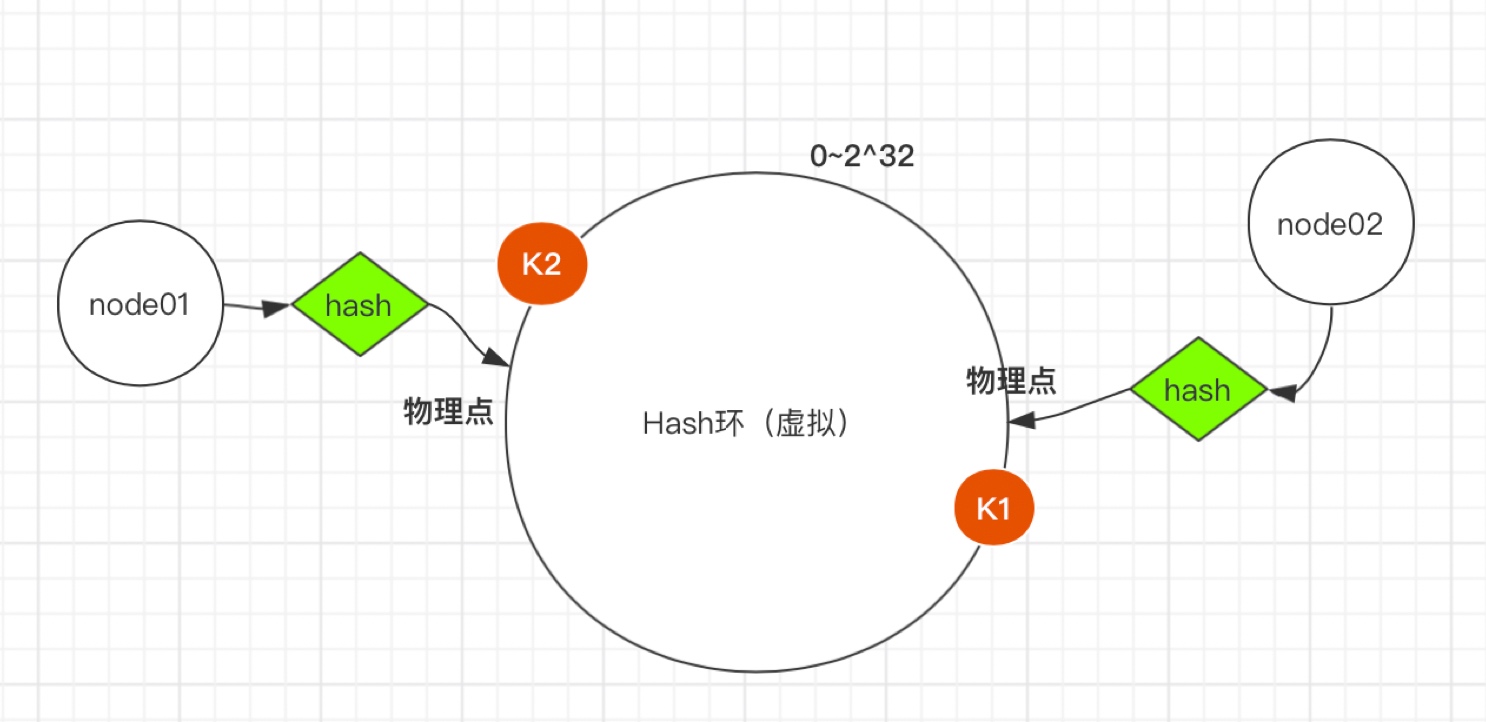
一致性hash算法主要应用于分布式存储系统中,可以有效地解决分布式存储结构下普通余数Hash算法带来的伸缩性差的问题,可以保证在动态增加和删除节点的情况下尽量有多的请求命中原来的机器节点。
-
优点:对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
-
缺点:一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题(被缓存的对象大部分集中缓存在某一台服务器上)。为了解决数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。多个虚拟节点可以减少数据的倾斜。
Redis 集群没有使用一致性hash, 而是在第一种Hash+取模的基础上引入了哈希槽slots的概念。接下来我们分析下Redis的实现。
- Redis集群的分片存取
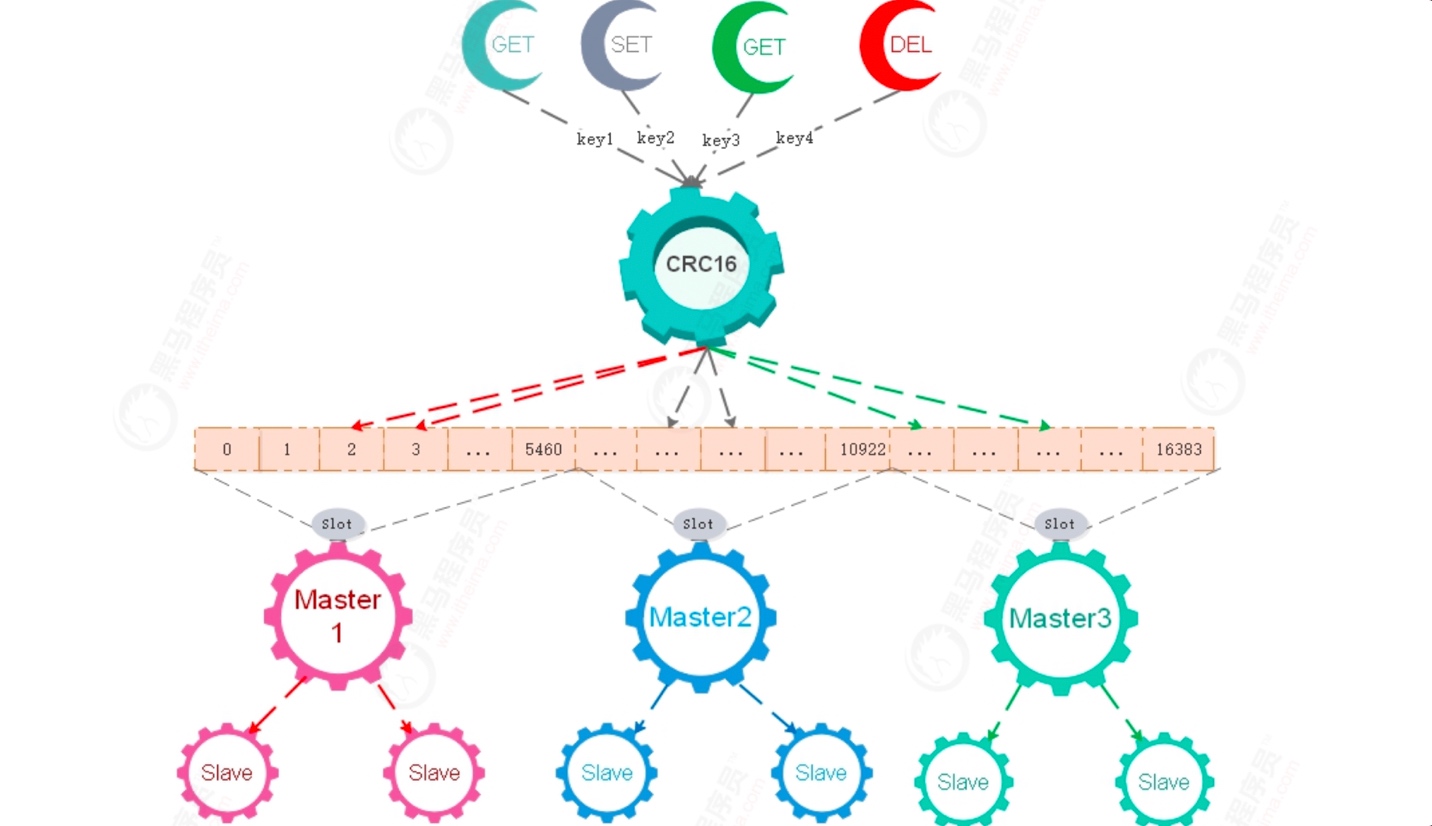
- Redis Cluster 特性之一是引入了槽的概念。一个redis集群包含 16384 个哈希槽。
- 集群时,会将16384个哈希槽分别分配给每个Master节点,每个Master节点占16384个哈希槽中的一部分。
- 执行GET/SET/DEL时,都会根据key进行操作,Redis通过CRC16算法对key进行计算得到该key所属Redis节点。
- 根据key去指定Redis节点操作数据。
2.3 集群访问
当客户端连接Redis集群时,如果直接连server端造成的压力很大,如下图,4个人客户端连接2台Redis,每台Redis都需要和所有客户端连接。

因此,我们首先考虑的是同代理减少服务端连接,如下图
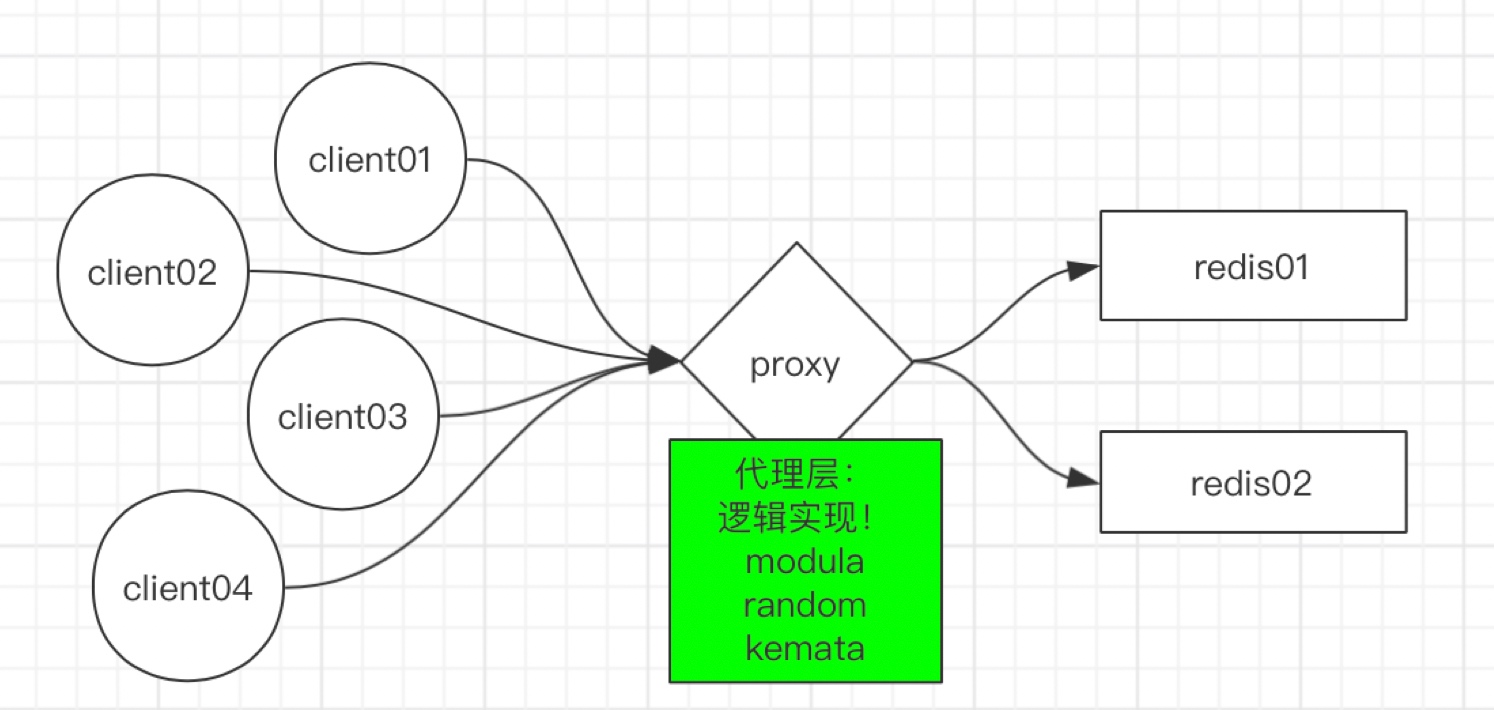
通过代理确实可以解决服务端连接问题,但是proxy服务的单点问题就暴露了,为了解决单点问题,我们把架构调整如下:

如上图,通过LVS+KeepAlived实现proxy的高用,从而解决了这一系列问题(具体架构详解可以参考另一篇文章《LVS+KeepAlived高可用部署架构》)。接下来我们讲解下Redis集群的具体搭建,proxy和Redis Cluster。
3 Redis集群搭建
无论是为了解决redis的高可用问题、还是为了可扩展性、或者是为了维护方便,用一款redis代理都是上佳的选择。在github上有众多开源的redis代理,本章中主要针对Twemproxy、Predixyr进行搭建Redis集群。
3.1 Twemproxy
Twemproxy是Twitter维护的(缓存)代理系统,代理Memcached的ASCII协议和Redis协议。它是单线程程序,使用c语言编写,运行起来非常快。它是采用Apache2.0 license的开源软件。 Twemproxy支持自动分区,如果其代理的其中一个Redis节点不可用时,会自动将该节点排除(这将改变原来的keys-instances的映射关系,所以你应该仅在把Redis当缓存时使用Twemproxy)。
Twemproxy本身不存在单点问题,因为你可以启动多个Twemproxy实例,然后让你的客户端去连接任意一个Twemproxy实例。
Twemproxy是Redis客户端和服务器端的一个中间层,由它来处理分区功能应该不算复杂,并且应该算比较可靠的。
3.1.1 Twemproxy安装
官网地址:GItHub
# 下载安装包
wget https://github.com/twitter/twemproxy/releases/download/0.5.0/twemproxy-0.5.0.tar.gz
tar xf twemproxy-0.5.0.tar.gz
# twemproxy运行需要automake和 libtool
yum install automake libtool -y
cd twemproxy
autoreconf -fvi
./configure
make
# 复制配置文件及加入系统命令
cp scripts/nutcracker.init /etc/init.d/twemproxy
chmod +x /etc/init.d/twemproxy
mkdir /etc/nutcracker
cp conf/* /etc/nutcracker/
cp src/nutcracker /usr/bin/
cd /etc/nutcracker/
# 修改配置文件
cp nutcracker.yml nutcracker.yml.bak
修改后配置,按需修改,这里使用的是本机2台Redis测试
alpha:
listen: 127.0.0.1:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- 127.0.0.1:6379:1
- 127.0.0.1:6380:1
3.1.2 手动启动2个Redis实例
创建2个Redis目录 6379 6380 分别进入2个目录执行启动命令

启动Redis
# 进入6379文件夹
redis-server --port 6379
# 进入6380文件夹
redis-server --port 6380
查看

启动twemproxy
server twemproxy start
3.1.3 验证
连接twemproxy代理的Redis,注意此处端口使用twemproxy端口号
redis-cli -p 22121

通过在22121端口中set数据,最终会按设置的规则分布在6379和63802台Redis服务器。
22121代理:
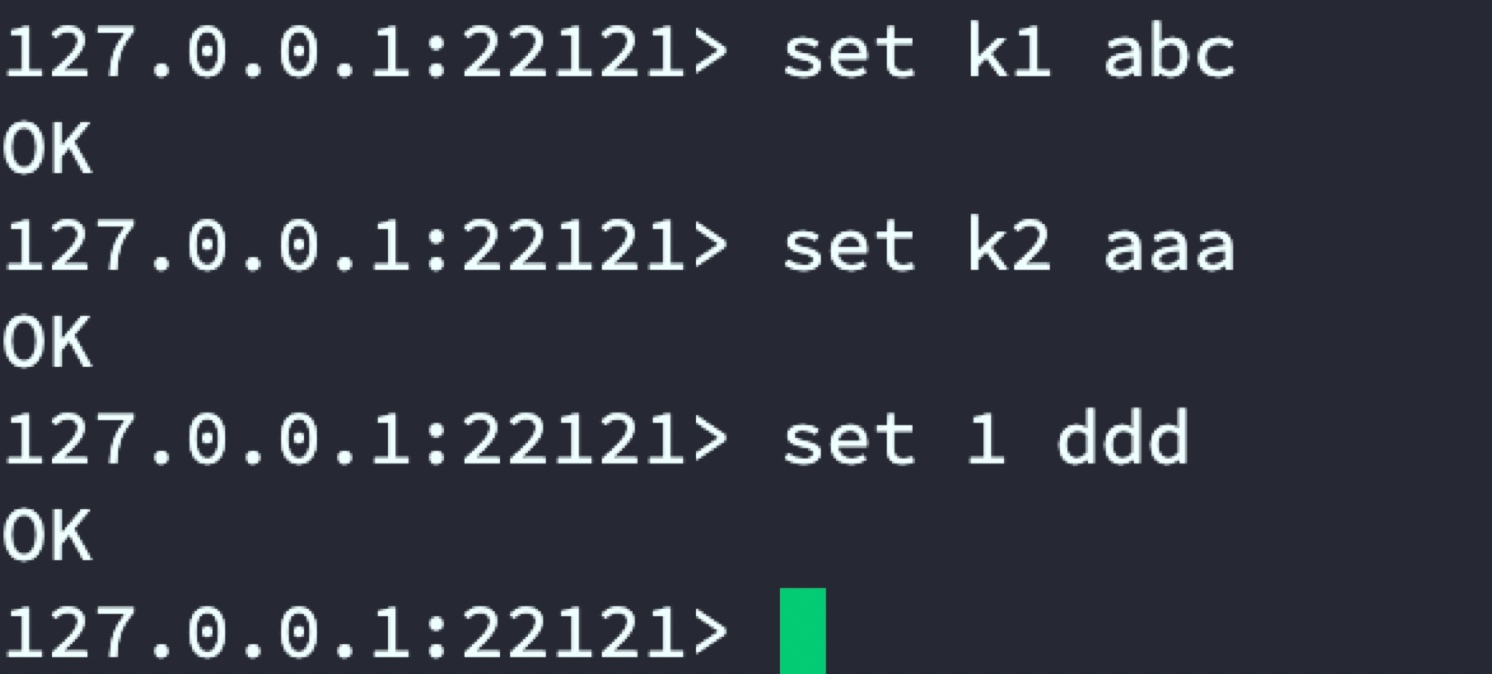
6379

6380
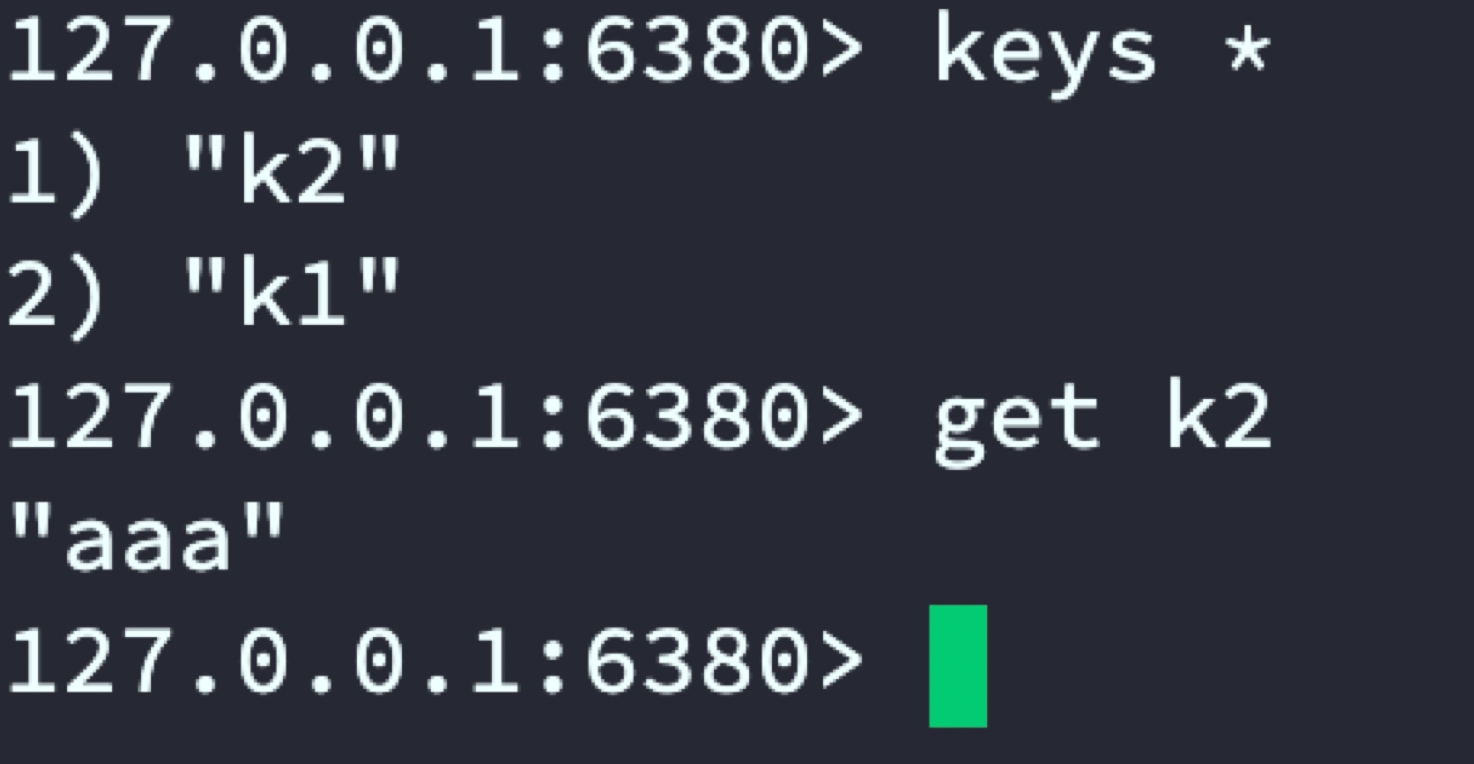
到此已实现通过twemproxy代理2台Redis服务器进行数据分布储存,后续用户存取只用连接代理服务器即可,从而解决单台Redis内存有限问题。
使用twemproxy代理Redis进行数据分治后会存在的问题:代理层不支持查询全部数据,不支持事务。
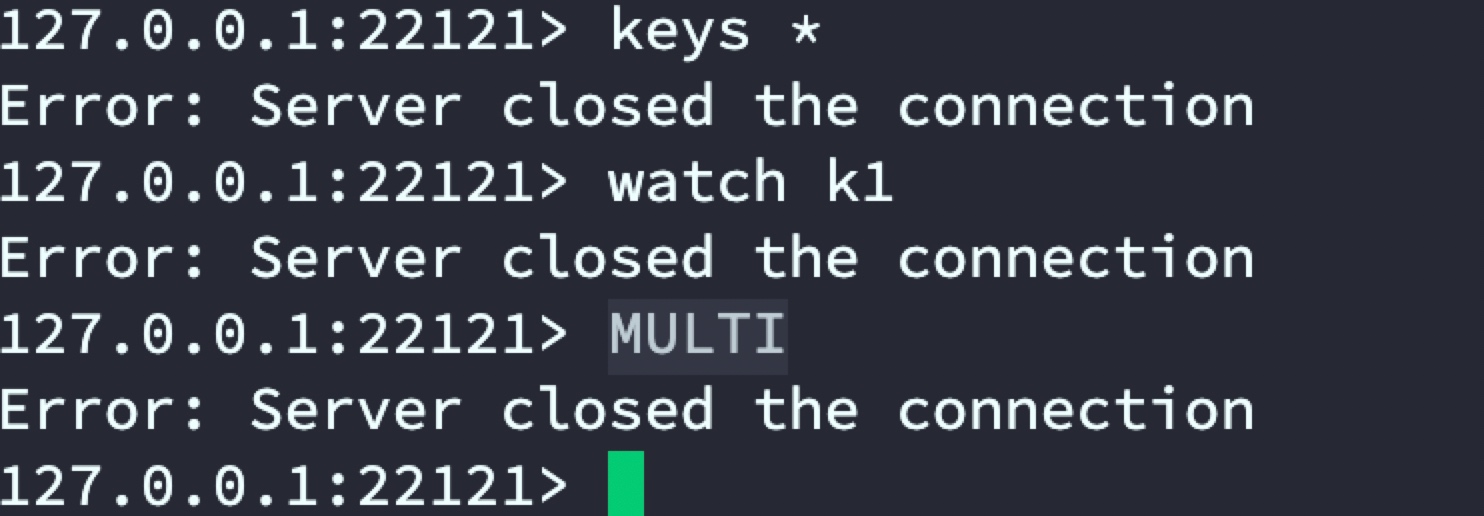
3.2 Predixy
Predixy是一款redis代理的开源程序,支持一套master-slave事务,支持redis单机,多机,集群的代理,对于客户端是感应不到的。 要求是c++11编译。
常用Redis代理对比
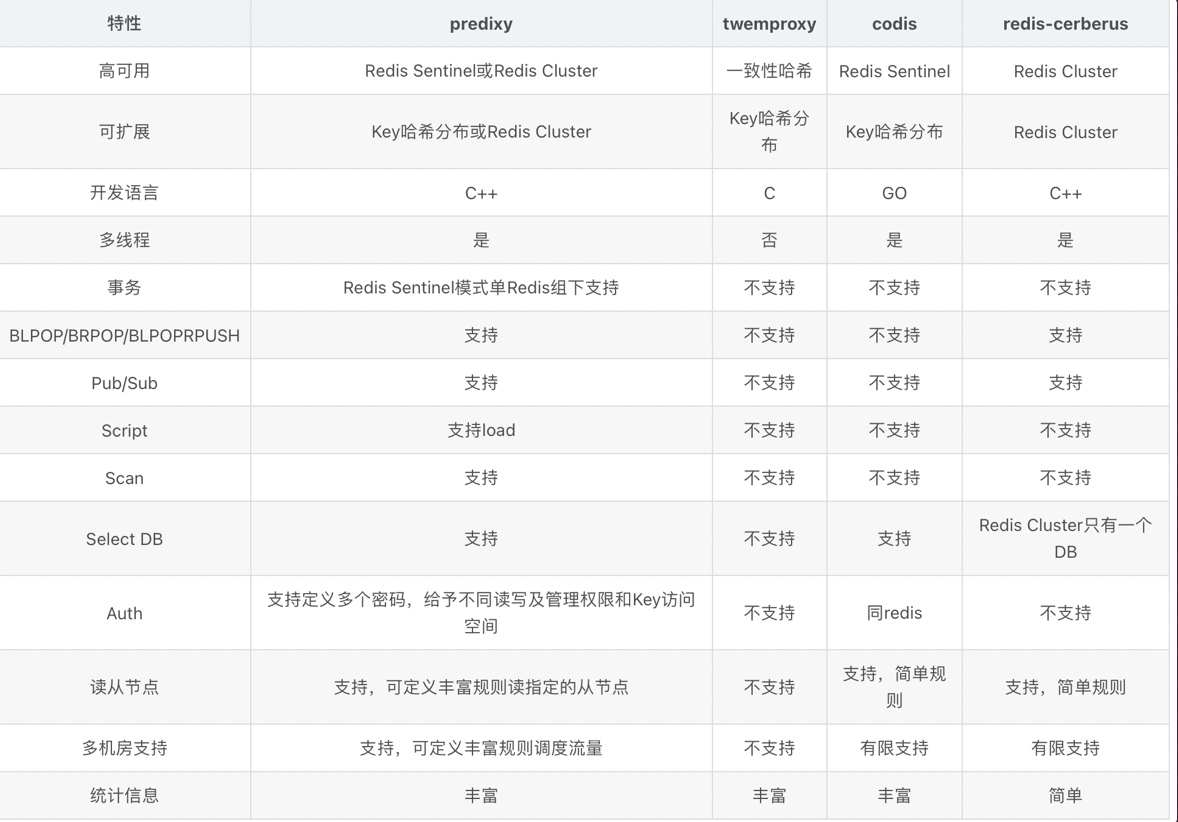
接下来演示Predixy代理搭建。
3.2.1 安装
官方下载地址:GItHub
wget https://github.com/joyieldInc/predixy/releases/download/1.0.5/predixy-1.0.5-bin-amd64-linux.tar.gz
tar xf predixy-1.0.5-bin-amd64-linux.tar.gz
3.2.2 配置
修改predixy.conf
vi predixy-1.0.5/conf/predixy.conf
打开绑定端口

打开sentinel配置

修改sentinel配置
vi predixy-1.0.5/conf/sentinel.conf
内容如下
SentinelServerPool {
Databases 16
Hash crc16
HashTag "{}"
Distribution modula
MasterReadPriority 60
StaticSlaveReadPriority 50
DynamicSlaveReadPriority 50
RefreshInterval 1
ServerTimeout 1
ServerFailureLimit 10
ServerRetryTimeout 1
KeepAlive 120
# 哨兵IP就端口
Sentinels {
+ 127.0.0.1:8001
+ 127.0.0.1:8002
+ 127.0.0.1:8003
}
# 分组
Group beijin {
}
Group shanghai {
}
}
3.2.3 启动sentinel集群
集群拓扑图
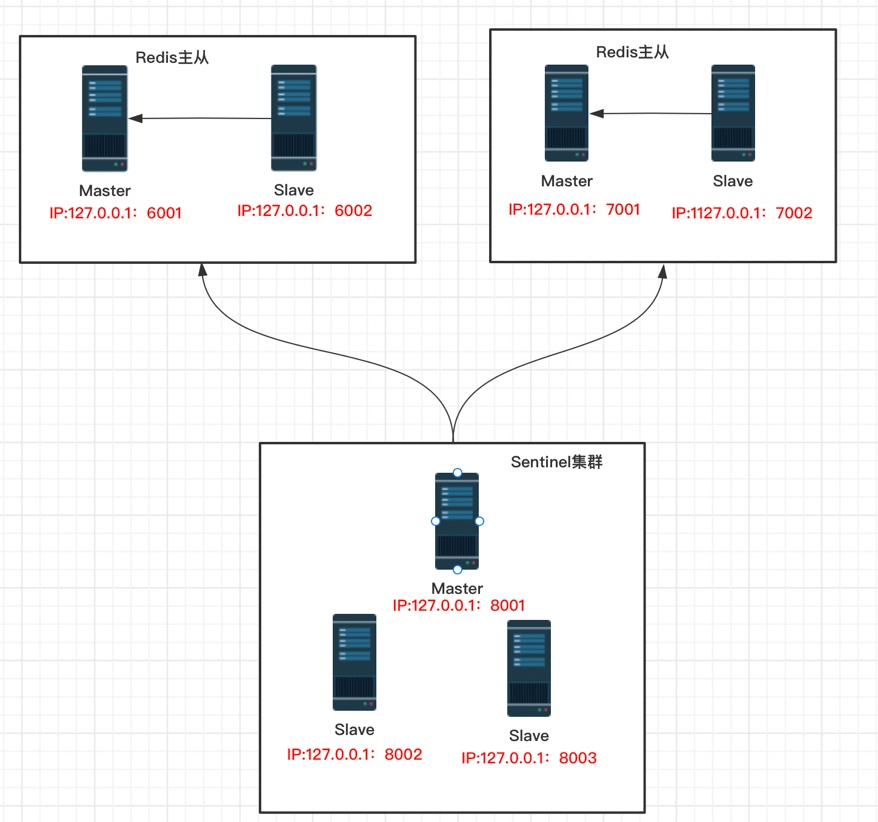
说明:通过sentinel集群端口为:8001、8002、8003 监控2套Redis主从beijin和shanghai。
Redis主从一:beijin Master端口为6001,Slave 6002;
Redis主从一: shanghai Master端口为7001,Slave端口7002;
sentinel配置
beijin和shanghai为Redis主从分组,对应predixy.conf中的Grpoup
8001:
port 8001
sentinel monitor beijin 127.0.0.1 6001 2
sentinel monitor shanghai 127.0.0.1 7001 2
8002:
port 8002
sentinel monitor beijin 127.0.0.1 6001 2
sentinel monitor shanghai 127.0.0.1 7001 2
8003:
port 8003
sentinel monitor beijin 127.0.0.1 6001 2
sentinel monitor shanghai 127.0.0.1 7001 2
配置文件列表

启动3台sentinel
redis-server 8001.conf --sentinel
redis-server 8002.conf --sentinel
redis-server 8003.conf --sentinel
查看启动状态

3.2.4 启动2套Redis主从
mkdir 6001
mkdir 6002
mkdir 7001
mkdir 7002
分别进入4个文件夹启动对应Redis
# 6001文件夹
redis-server --port 6001
# 6002文件夹
redis-server --port 6002 --replicaof 127.0.0.1 6001
# 7001文件夹
redis-server --port 7001
# 7002文件夹
redis-server --port 7002 --replicaof 127.0.0.1 7001
查看启动进程

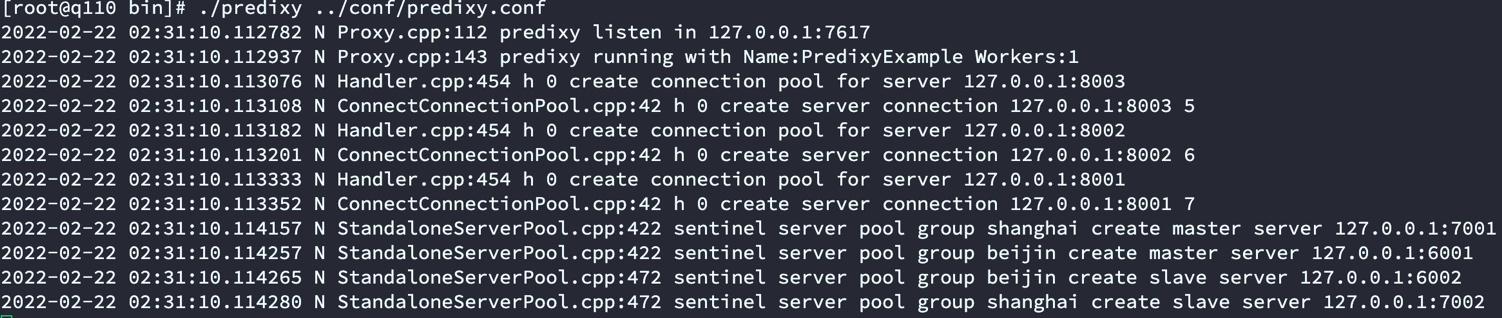
启动predixy
cd predixy-1.0.5/bin/
./predixy ../conf/predixy.conf
启动日志
3.2.5 验证
- 验证数据存取
客户端通过7617端口连接predixy代理,进而操作集群。
redis-cli -p 7617
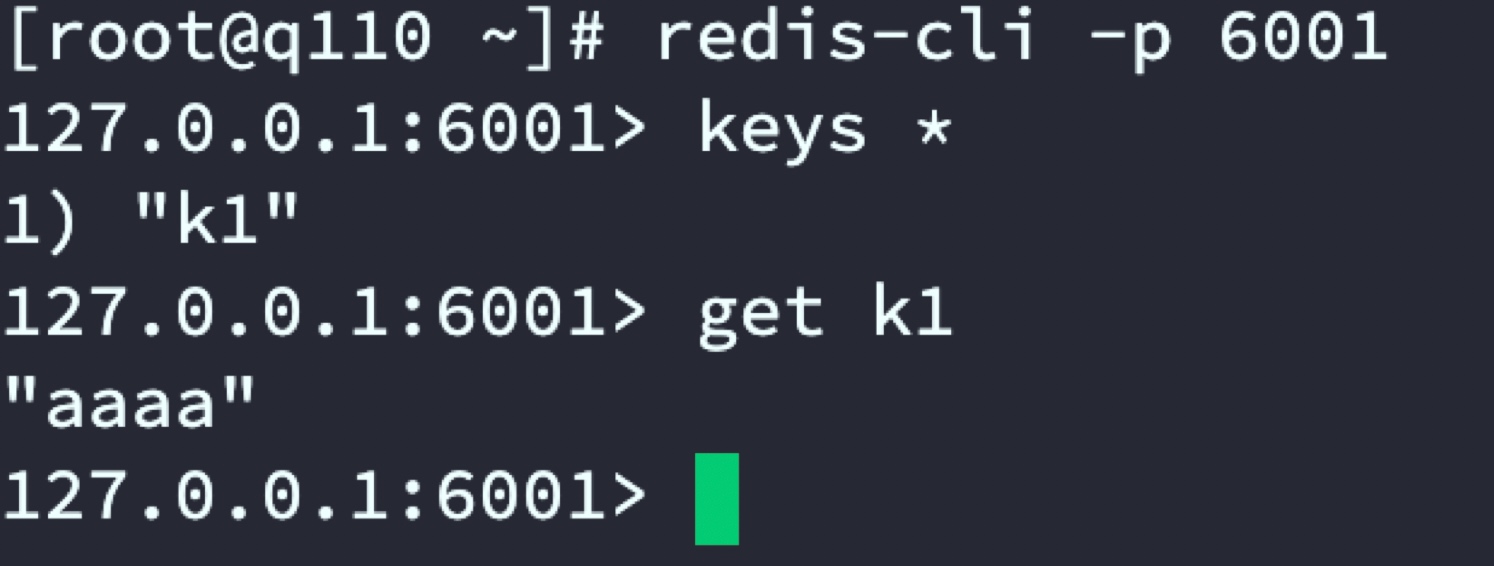
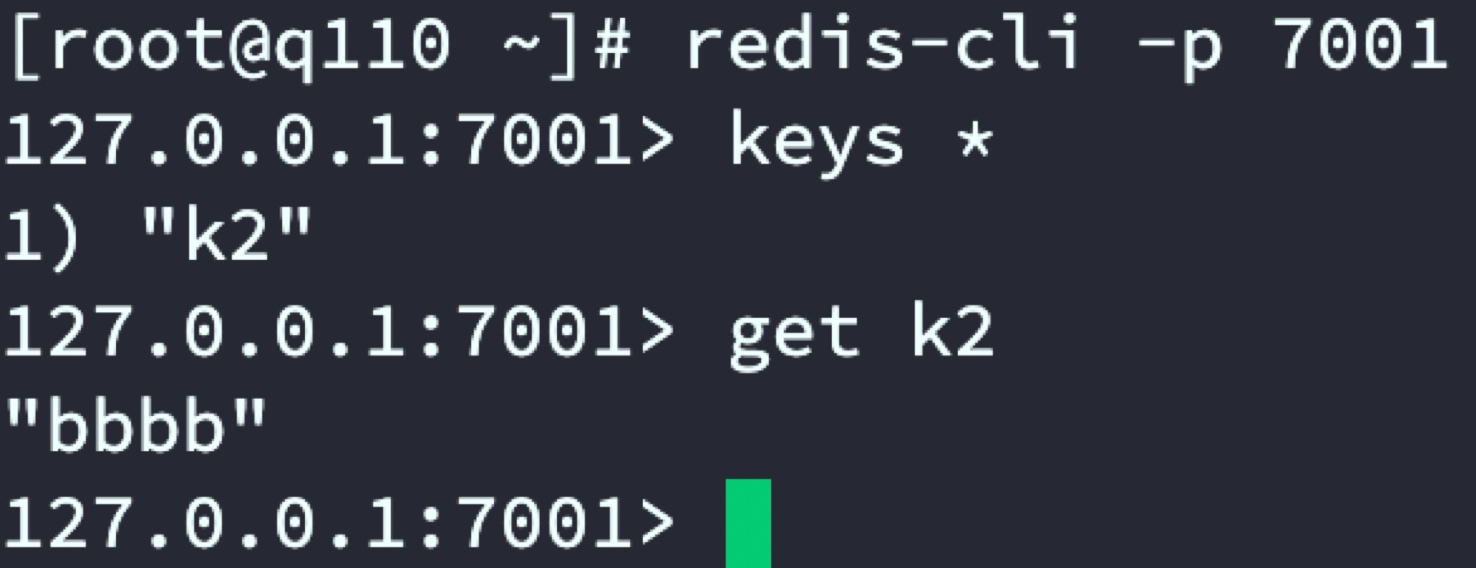
通过代理服务器set k1和k2 数据,分别在2套Redis集群中查看数据分布
代理服务器

Redis主从一:beijin
Redis主从二:shanghai
- 验证通过代理服务器将数据存储到指定的Redis集群
代理服务器指定将k3和k4存储到代号beijin的Redis主从,将k5和k6存储到代号shanghai主从中
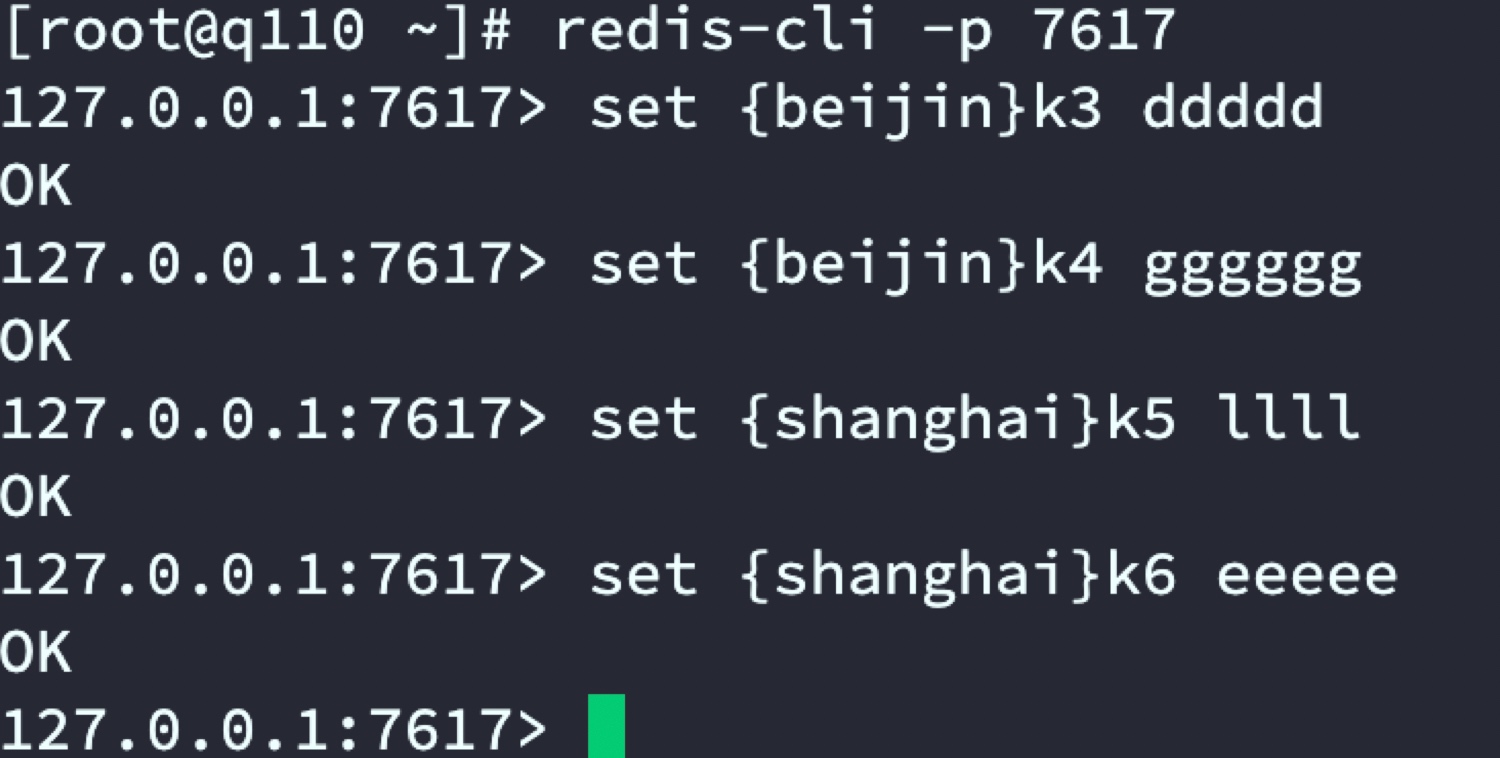
beijin主从
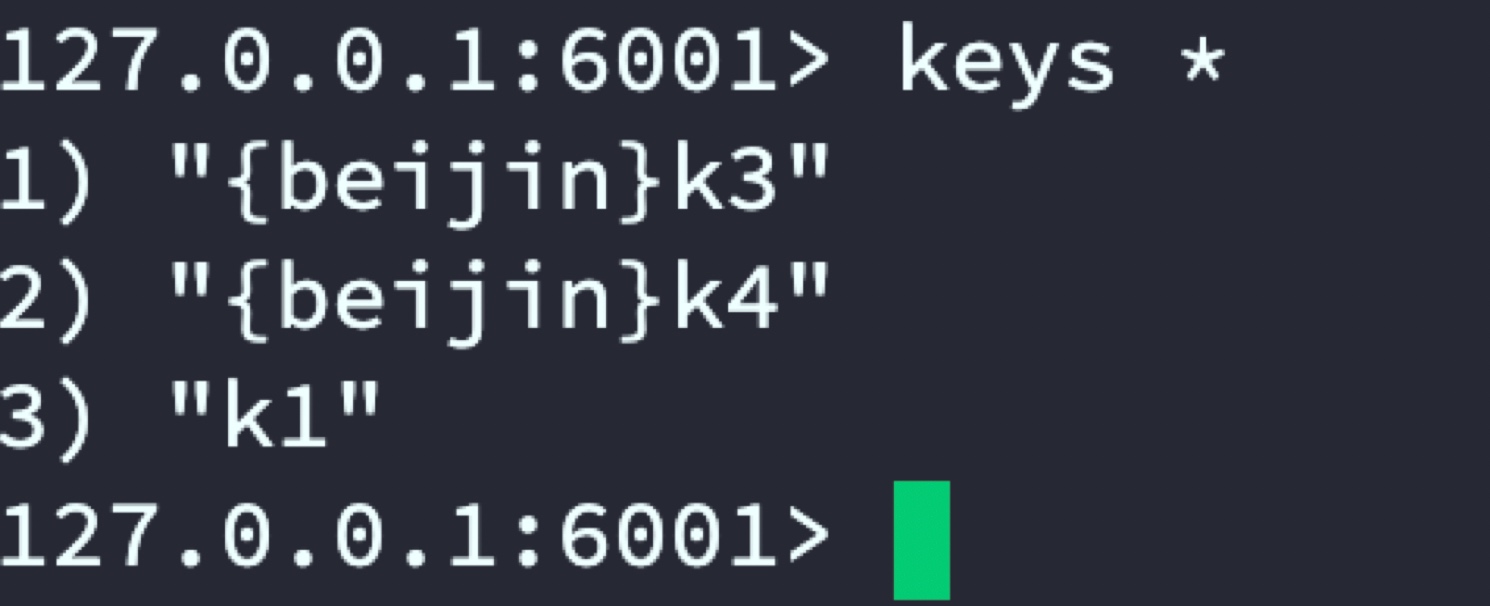
shanghai主从

- 验证集群事务

发现当存在2套Redis组集群时predixy依旧不支持事务,predixy只支持单组集群下的事务。
停止predixy修改predixy.conf
vi predixy-1.0.5/conf/sentinel.conf
修改后配置

重新启动predixy并验证
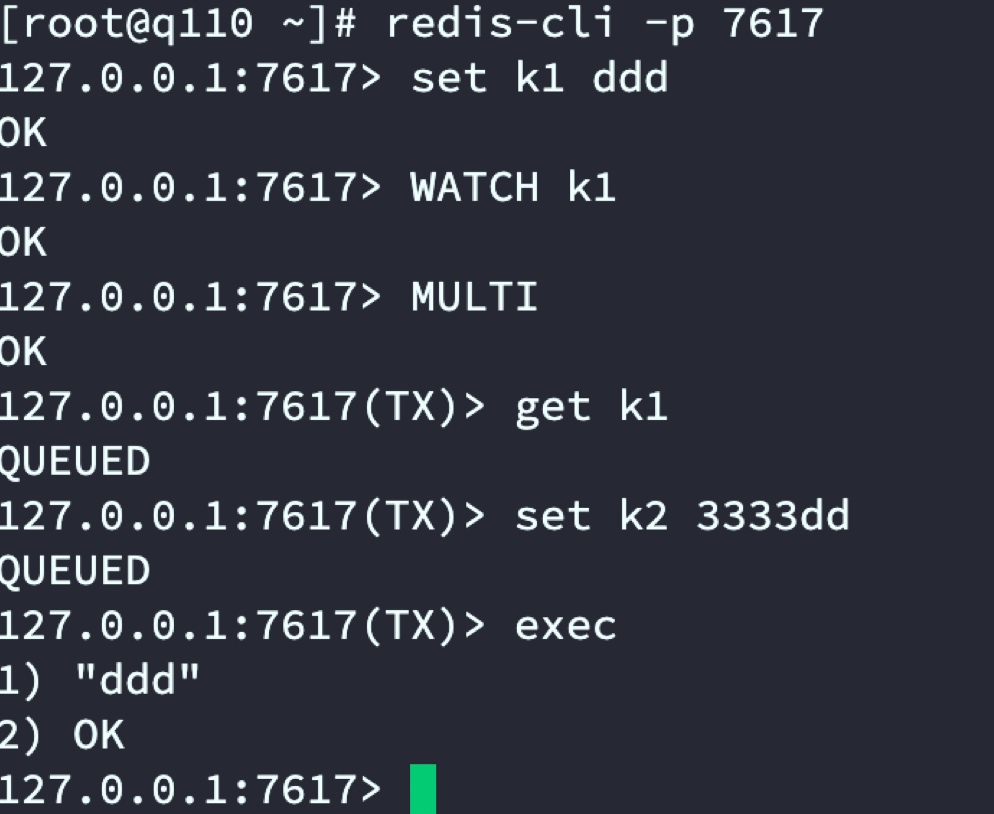
通过测试发现单组集群predixy是可以支持事务的,接下来演示Redis Cluster集群模式
3.3 Redis Cluster集群搭建
3.3.1 使用官方提供的脚本搭建Redis Cluster集群
- 修改配置
# 进入Redis源码目录
cd redis-6.2.6/utils/create-cluster
vi create-cluster
修改nodes节点数量和replicas副本数量,我这使用3组 每组1主1从测试,修改后的结果

2. 启动集群
# 启动集群
./create-cluster start
# 分哈希槽
./create-cluster create
如下截图,已经将16384个slots分给3台master,并且反馈了每台master对应分得的slots编号及数量
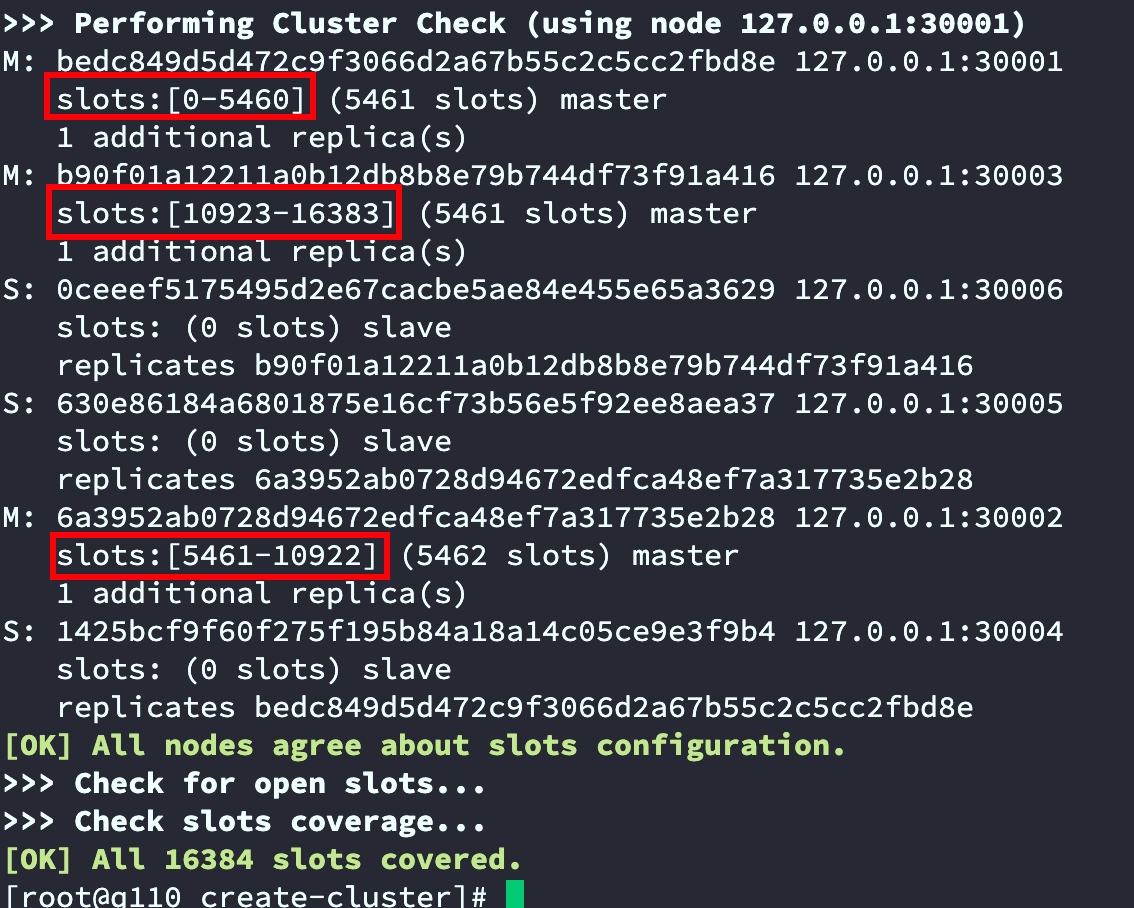
3.3.2 手动创建集群并分配哈希槽
目前是Redis cluster 自动帮我们设置的集群信息以及分配的哈希槽,也可以手动创建和设置
手动创建集群并分配哈希槽
# 停止集群
./create-cluster stop
# 清理已分配的哈希槽信息
./create-cluster clean
# 创建集群 --cluster-replicas 1 即 1主1从
redis-cli --cluster create 127.0.0.1:30001 127.0.0.1:30002 127.0.0.1:30003 127.0.0.1:30004 127.0.0.1:30005 127.0.0.1:30006 --cluster-replicas 1
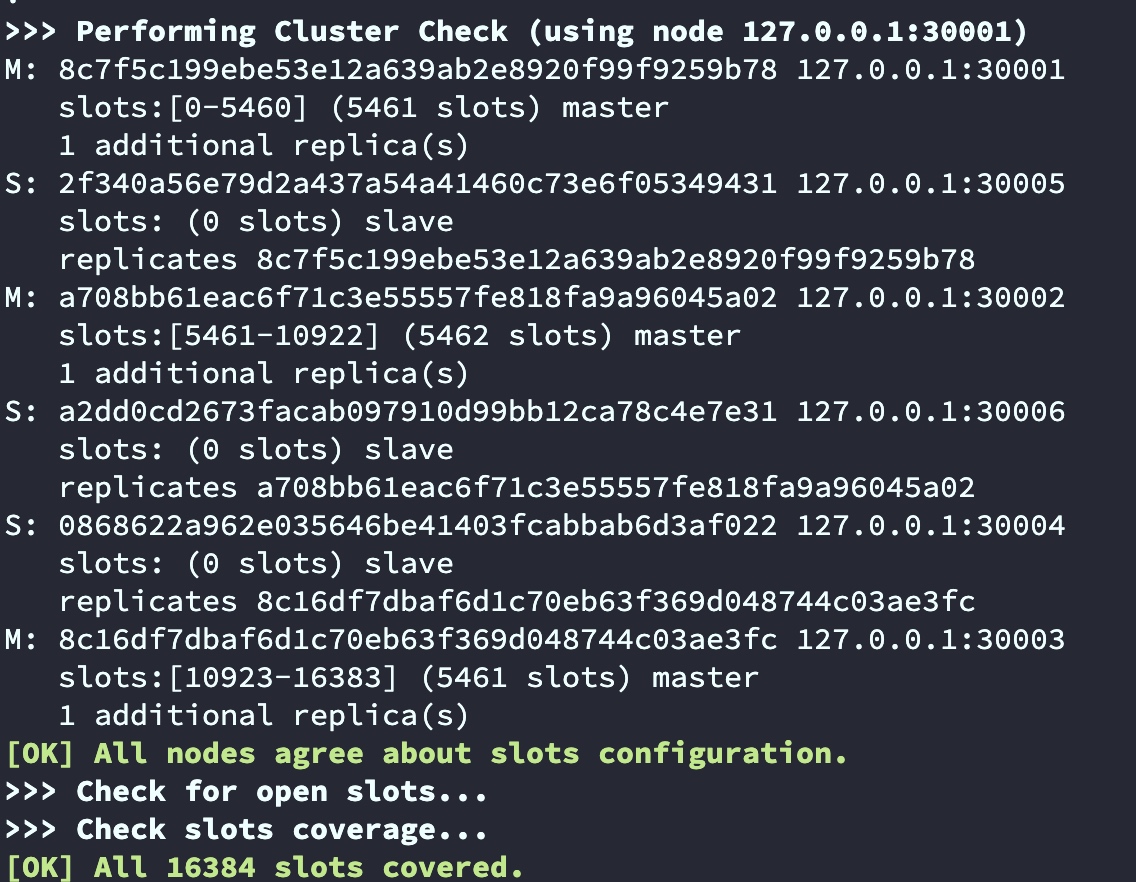
手动设置的集群哈希槽分配情况
| 节点 | 哈希槽 | 数量 |
|---|---|---|
| 30001 | 0-5460 | 5461 |
| 30002 | 5461-10922 | 5462 |
| 30003 | 10923-16383 | 5461 |
假设我们需要将30001节点的槽移动1000个到30003
# 连接Redis集群 随便集群中的哪个节点都可以
[root@q110 create-cluster]# redis-cli --cluster reshard 127.0.0.1:30001
>>> Performing Cluster Check (using node 127.0.0.1:30001)
M: 8c7f5c199ebe53e12a639ab2e8920f99f9259b78 127.0.0.1:30001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 2f340a56e79d2a437a54a41460c73e6f05349431 127.0.0.1:30005
slots: (0 slots) slave
replicates 8c7f5c199ebe53e12a639ab2e8920f99f9259b78
M: a708bb61eac6f71c3e55557fe818fa9a96045a02 127.0.0.1:30002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: a2dd0cd2673facab097910d99bb12ca78c4e7e31 127.0.0.1:30006
slots: (0 slots) slave
replicates a708bb61eac6f71c3e55557fe818fa9a96045a02
S: 0868622a962e035646be41403fcabbab6d3af022 127.0.0.1:30004
slots: (0 slots) slave
replicates 8c16df7dbaf6d1c70eb63f369d048744c03ae3fc
M: 8c16df7dbaf6d1c70eb63f369d048744c03ae3fc 127.0.0.1:30003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# 需要移动的槽数量1000
How many slots do you want to move (from 1 to 16384)? 1000
# 分配给谁节点ID?
What is the receiving node ID? 8c16df7dbaf6d1c70eb63f369d048744c03ae3fc
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
# 从哪个节点取出
Source node #1: 8c7f5c199ebe53e12a639ab2e8920f99f9259b78
# 结束
Source node #2: done
查看节点信息
redis-cli --cluster info 127.0.0.1:30001
redis-cli --cluster check 127.0.0.1:30001
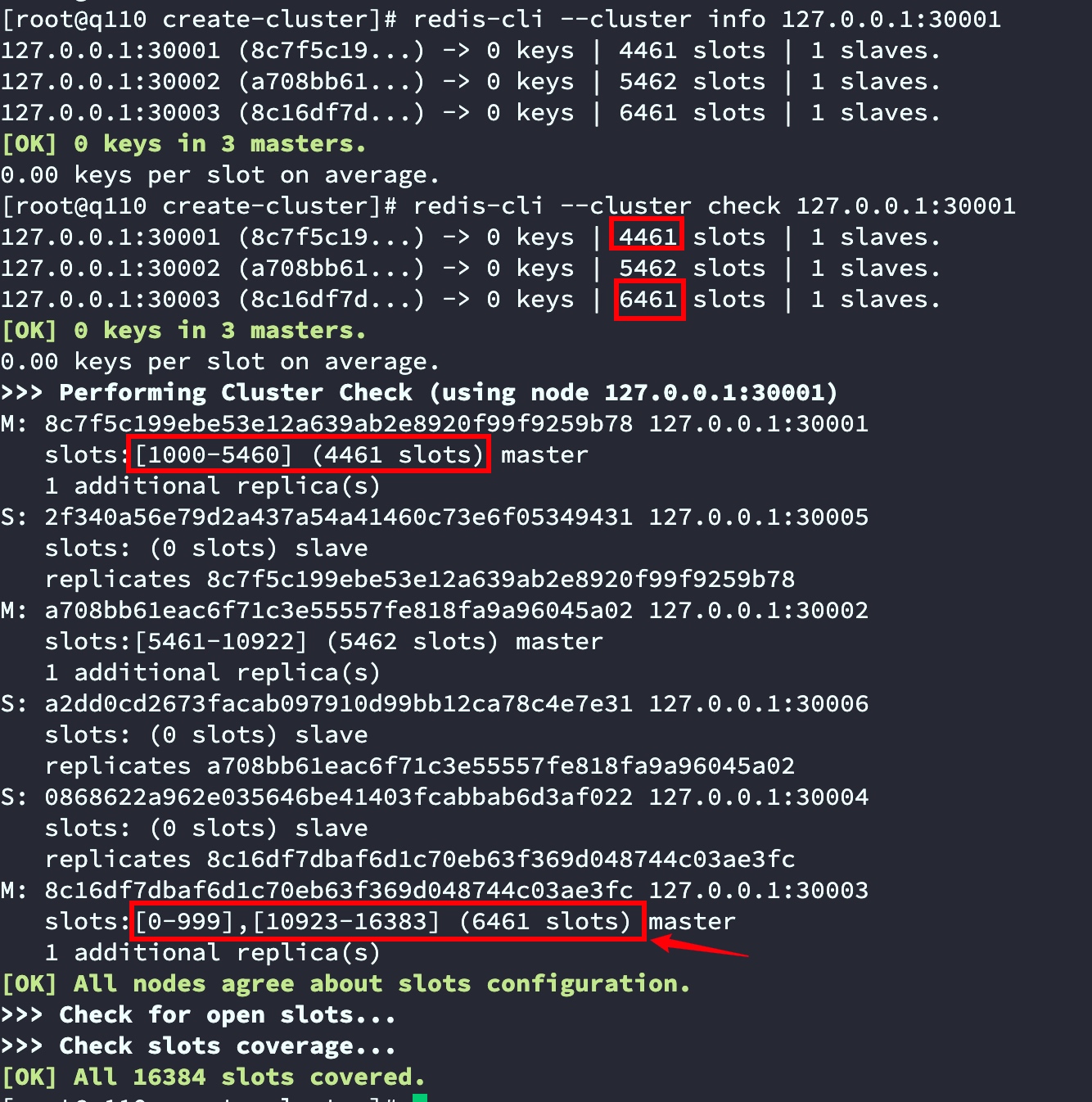
截图中可以看出30001节点0-999共1000个槽已经移动到了30003
3.3.3 测试集群
测试数据存取
如下图,我们使用Redis-cli -p 30001连接后set k1 xxx会报错,提示set k1 需要到30003节点操作。通过redis-cli -c -p 30001连接Redis Cluster集群后 set k1 xxx会自动跳转到30003节点。
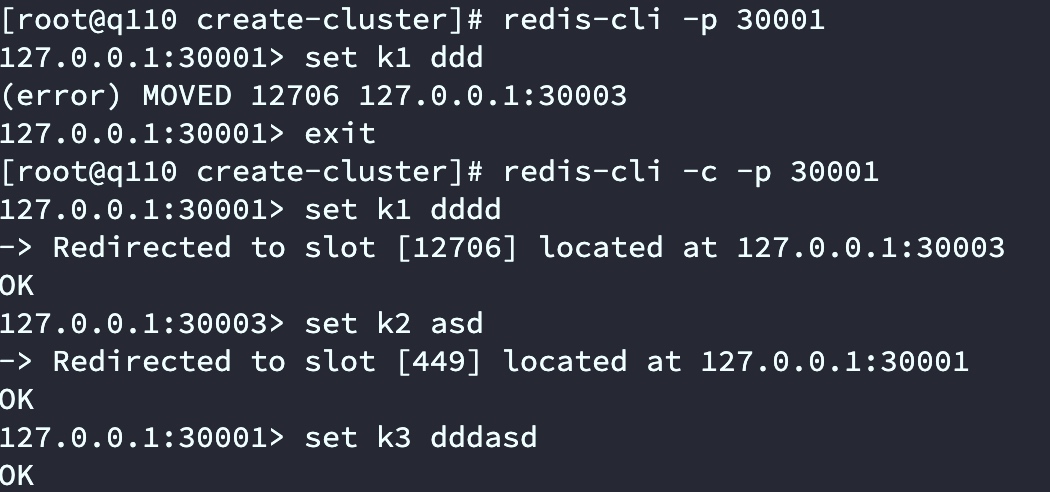
上面的截图具体原因是Redis Cluster moved重定向问题:

客户端向Redis Cluster的任意节点发送命令,接收命令的节点会根据CRC16规则进行hash运算与16384取余,计算自己的槽和对应节点;如果保存数据的槽被分配给当前节点,则去槽中执行命令,并把命令执行结果返回给客户端;如果保存数据的槽不在当前节点的管理范围内,则向客户端返回moved重定向异常;客户端接收到节点返回的结果,如果是moved异常,则从moved异常中获取目标节点的信息;客户端向目标节点发送命令,获取命令执行结果。
测试事务
127.0.0.1:30003> set k2 kkd
-> Redirected to slot [449] located at 127.0.0.1:30001
OK
127.0.0.1:30001> WATCH k1
-> Redirected to slot [12706] located at 127.0.0.1:30003
OK
127.0.0.1:30003> MULTI
OK
127.0.0.1:30003(TX)> set k2 asd
-> Redirected to slot [449] located at 127.0.0.1:30001
OK
127.0.0.1:30001> exec
(error) ERR EXEC without MULTI
报错了,原因是事务在30003节点开启,事务中我们set k2 跳转到了30001 然后提交事务在30001提交。这种情况Redis cluster 自身是不支持的,可以通过认为处理,类似Predixy代理的处理方式,在key前面加上固定的字符,比如下面的测试
127.0.0.1:30002> set {beijin}k2 jjjjd
OK
127.0.0.1:30002> set {beijin}k1 jjjjd
OK
127.0.0.1:30002> MULTI
OK
127.0.0.1:30002(TX)> set {beijin}k2 lajdjddda
QUEUED
127.0.0.1:30002(TX)> exec
1) OK
127.0.0.1:30002>
至此Redis集群模式已经结束,但是实际工作中很多时候都是通过docker创建和管理集群,下一篇讲解Docker搭建Redis集群及扩容收容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号