JDK8以上提高开发效率
1 接口的默认方法和静态方法
1.1 接口中可以定义默认方法和静态方法。
- 默认方法使用default修饰,静态方法和默认方法可以多个;
- 静态方法通过接口直接调用,默认方法通过接口实现类调用
- 默认方法可以重写
public interface InterfaceTest {
default String defaultMethod(){
return "InterfaceTest defaultMethod";
}
static String staticMethod(){
return "InterfaceTest staticMethod";
}
}
public class InterfaceMain {
public static void main(String[] args) {
//接口中的默认方法必须通过接口实现类调用
InterfaceTestImpl impl = new InterfaceTestImpl();
System.out.println(impl.defaultMethod());
// 接口中的静态方法可以直接通过接口调用
System.out.println(InterfaceTest.staticMethod());
}
}
接口中默认方法可以重写
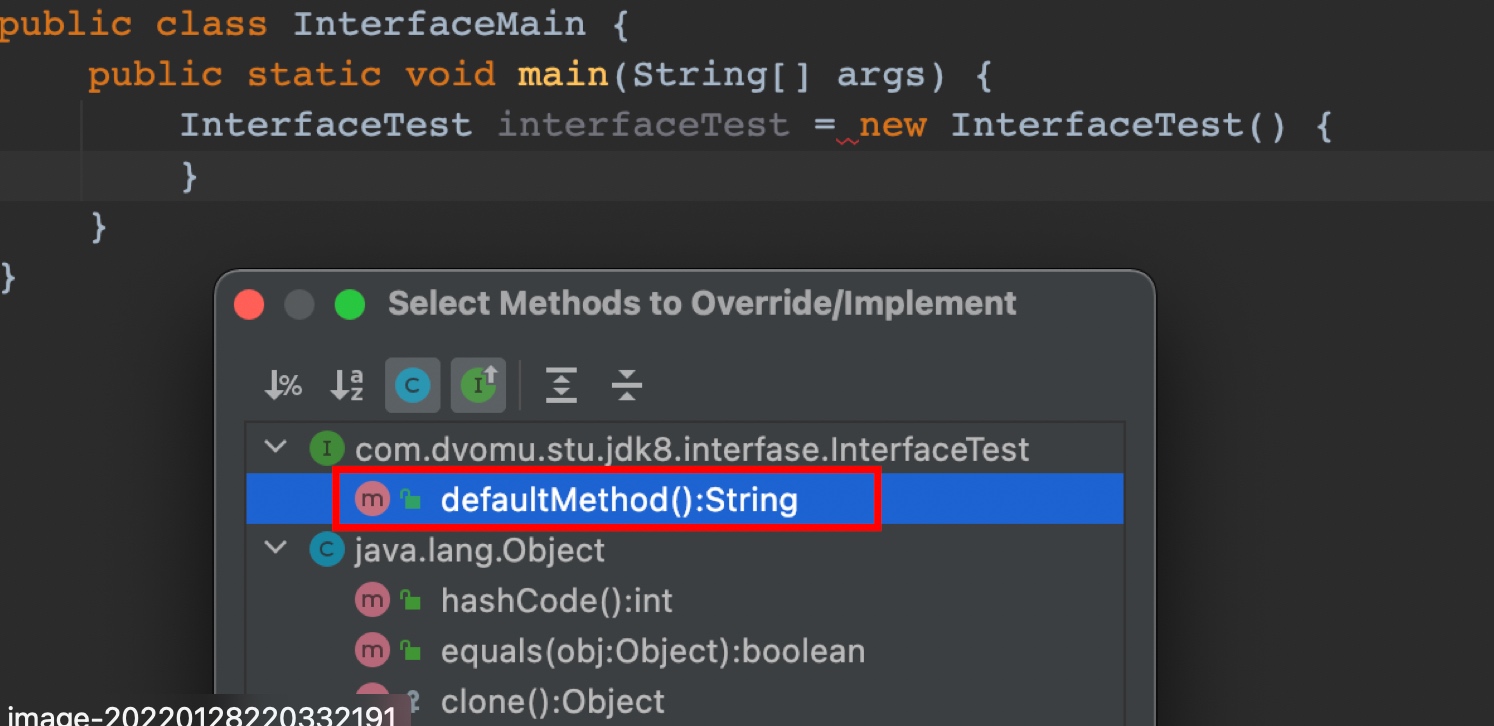
1.2 如果子类继承父类和实现接口中方法重名,采用类优先原则 调用父类方法
public class Inter {
public String defaultMethod(){
return "Inter defaultMethod";
}
}
public interface InterfaceTest {
default String defaultMethod(){
return "InterfaceTest defaultMethod";
}
}
public class InterfaceMain extends Inter implements InterfaceTest{
public static void main(String[] args) {
InterfaceMain i = new InterfaceMain();
System.out.println(i.defaultMethod());
}
}
输入结果:Inter defaultMethod

2 Lambda表达式
2.1 Lambda基础格式
(参数列表)->{
方法体
}
- 没有参数的Lambda表达式,方法体只有一个可以省略return
()-> new Student(); - 只有一个参数的Lambda表达式
x->{
System.out.prontle(x);
return x;
}
- 有多个参数的Lambda表达式
(int x,int y)->{
System.out.prontle(x);
System.out.prontle(y);
return x+y;
}
上述写法可以简化,参数列表中的参数的数据类型JVM可以根据上下文进行推断,所以可以不定义类型
(x,y)->{
System.out.prontle(x);
System.out.prontle(y);
return x+y;
}
- 一个参数和仅一条语句的Lambda表达式
x -> 3+x; - 多个参数和鲸一条语句的Lambda表达式
(x+y)->x+y;
2.2 Lambda使用案例
- Lambda简化匿名内部类写法
Runnable runnable1 = new Runnable() {
@Override
public void run() {
System.out.println("hello Lambda");
}
};
//Lambda简化匿名内部类写法
Runnable runnable2 = ()-> System.out.println("hello Lambda");
2. Lambda对数组排序
String[] arr = new String[]{"c","b","a"};
//原写法
Arrays.sort(arr, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
//Lambda简化写法1
Arrays.sort(arr,(o1,o2)->(o1.compareTo(o2)));
//Lambda简化写法2,再次简化
Arrays.sort(arr, String::compareTo);
3 函数式接口
Java8为了让现有的函数更加友好的使用Lambda表达式,引入了函数式接口。函数式接口仅有一个抽象方法,如果声明多个抽象方法则会报错,但默认方法和静态方法在此接口中可以有多个。
3.1 函数式接口声明和使用
自定义函数接口需要在接口上加@FunctionalInterface
//函数式接口定义
@FunctionalInterface
public interface MyInterface {
void excute();
}
//函数式接口调用
public static void demo(MyInterface myInterface) {
myInterface.excute();
}
public static void main(String[] args) {
demo(() -> System.out.println("函数式接口调用"));
}
3.2 常见应用
在Java8类库设计中,已经引入了几个函数式接口:Predicate、Consumer、Function、Supplier
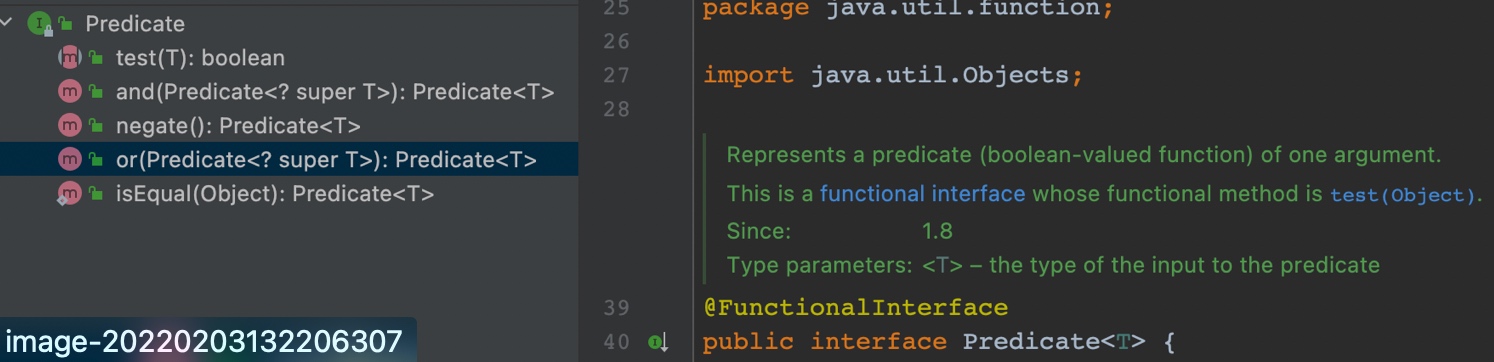
3.2.1 Predicate
Predicate属于java.util.function包下,用于进行判断操作,内部顶一个抽象方法test、三个默认方法and、negate、or、一个静态方法isEqual。
3.2.2 Consumer
Comsumer,用于==获取数据的操作==。内部定义了一个抽象方法accept,一个默认方法andThen。

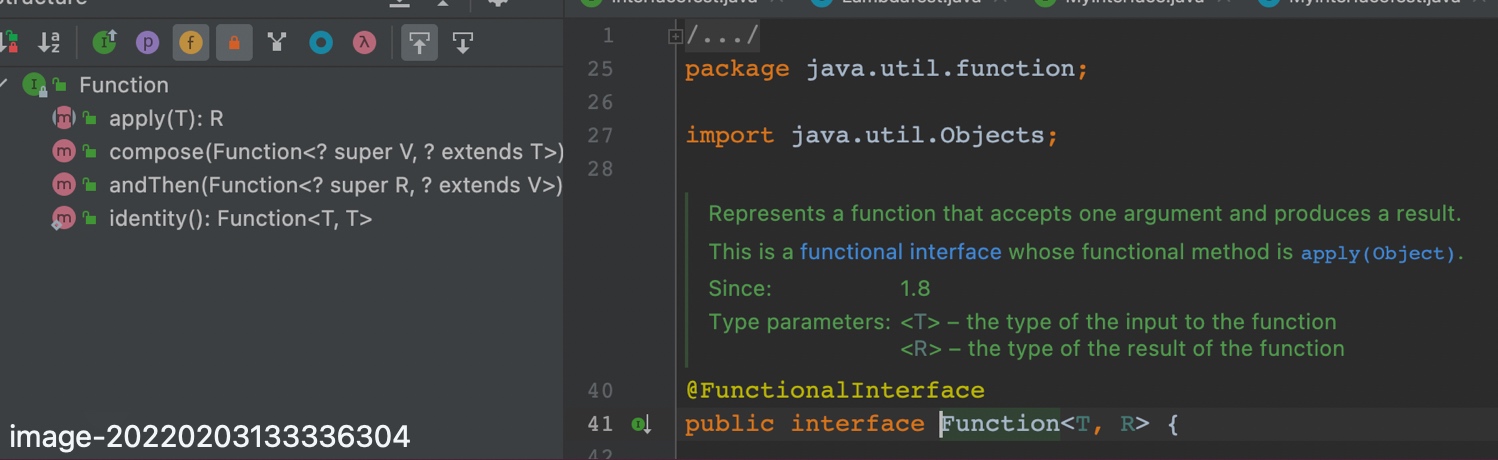
3.2.3 Function
Function主要用于==进行类型转换的操作==。内部提供一个抽象方法apply、两个默认方法compose、andThen、一个静态方法identity。
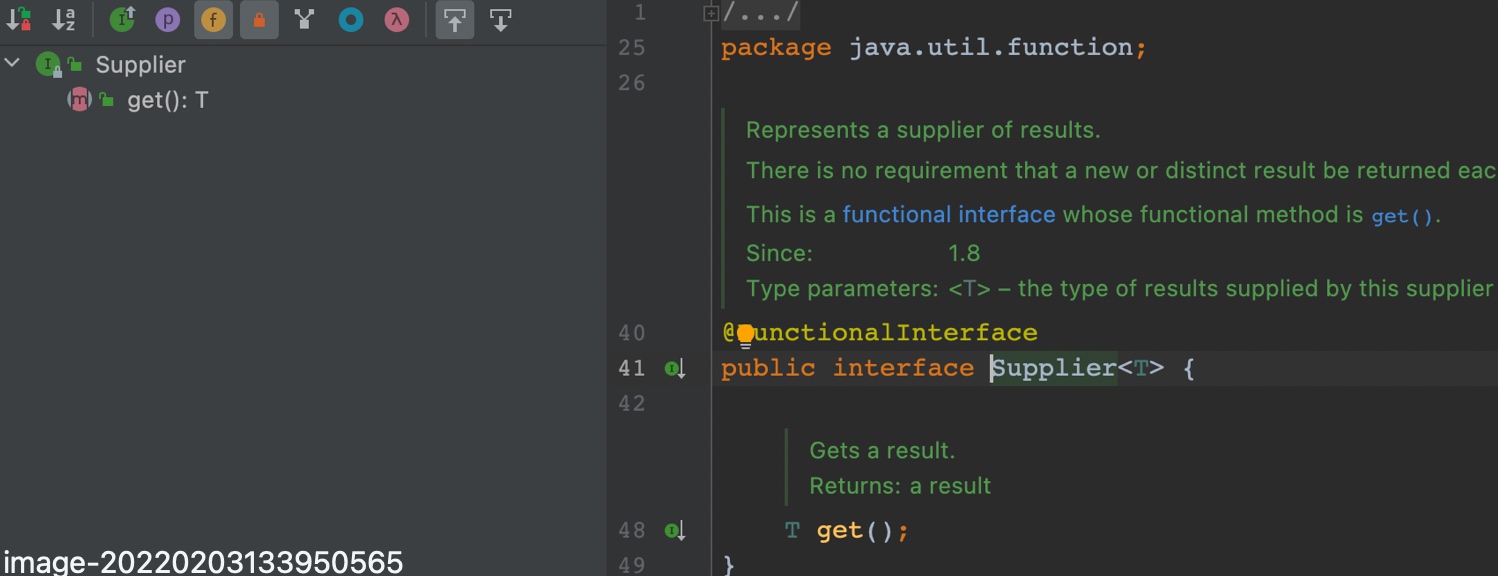
3.2.4 Supplier
Supplier也是用来==获取值操作==,内部只有一个抽象方法get。与Consumer 的 accept方法不同于 Consumer 的 accept没有返回值,supplier中的get方法有返回值。
4 类型检查&推断
自动类型推断:在Java8中可以省略Lambda表达式的所有参数类型,在编译的时根据Lambda表达式的上下文信息推断出参数的正确类型,这就是所谓的类型推断。
5 方法引用
方法引用更进一步的优化了Lambda的使用。它让代码感觉更加的自然。我们可以直接使用::来简化Lambda表达式的使用。其语法如下:类名或实例名::属性
List<Student> students = new ArrayList<>();
students.add(new Student(2,"张三","N"));
students.add(new Student(1,"李四","V"));
students.add(new Student(3,"万维","V"));
students.sort(Comparator.comparing(Student::getId));
6 Stream流
Stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或IO等。在stream中的操作每一次都会产生新的流,内部不会像普通集合操作一样立刻获取值,而是惰性取值,只有等到用户真正需要结果的时候才会执行。
**案例1:**获取年龄小于20岁学生,并且年龄从小到大排序,只取姓名
List<Student> students = new ArrayList();
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19));
students.add(new Student(2,"赵六","N",17));
students.add(new Student(4,"王五","V",22));
students.add(new Student(3,"李四","V",23));
}
/**
* 获取年龄小于20岁学生,并且年龄从小到大排序,只取姓名
* 期望:赵六 张三
*/
@Test
public void filter20AndSort(){
List<String> list = students.stream()
.filter(s -> s.getAge() < 20) //获取年龄小于20岁学生
.sorted(Comparator.comparing(Student::getAge)) //按年龄排序
.map(Student::getName)//取姓名
.collect(Collectors.toList()); //收集成list
System.out.println(list);
}
6.1 流操作详解
6.1.1 筛选
- filter( ) 筛选符合条件的数据
获取及格学生名单
List<Student> students = new ArrayList();
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19,false));
students.add(new Student(2,"赵六","N",17,true));
students.add(new Student(4,"王五","V",22,true));
students.add(new Student(3,"李四","V",23,false));
}
/**
* 获取及格学生名单
*/
@Test
public void filterIspass(){
List<Student> passStudents = students.stream()
.filter(Student::isIspass)
.collect(Collectors.toList());
System.out.println(passStudents);
}
- distinct( )去重
底层通过LinkHashSize实现。注意:对象去重需重写equals和hashcode方法
@Test
public void distinct(){
List<Integer> list = Arrays.asList(1,2,3,2,6,1,4,5);
List<Integer> result = list.stream().distinct().collect(Collectors.toList());
System.out.println(result);
}
6.1.2 切片
- limit ( ) 返回一个不超过给定长度的流。从前往后
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19,false));
students.add(new Student(2,"赵六","N",17,true));
students.add(new Student(4,"王五","V",22,true));
students.add(new Student(3,"李四","V",23,false));
}
//取第一条数据
@Test
public void limt(){
List<Student> result = students.stream().limit(1).collect(Collectors.toList());
System.out.println(result);
}
- skip( ) 跳过给定数量 取剩余的数据
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19,false));
students.add(new Student(2,"赵六","N",17,true));
students.add(new Student(4,"王五","V",22,true));
students.add(new Student(3,"李四","V",23,false));
}
@Test
public void skip(){
//取最后一条数据
List<Student> result = students.stream().skip(3).collect(Collectors.toList());
System.out.println(result);
}
skip与limit结合使用
跳过前2条取1条数据
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19,false));
students.add(new Student(2,"赵六","N",17,true));
students.add(new Student(4,"王五","V",22,true));
students.add(new Student(3,"李四","V",23,false));
students.add(new Student(3,"韩七","V",25,false));
}
@Test
public void limtAndSkip(){
List<Student> result = students.stream().skip(2).limit(1).collect(Collectors.toList());
System.out.println(result);
}
6.1.3 映射
在对集合进行操作的时候,我们经常会从某些对象中选择性的提取某些元素的值。可以使用map( )进行映射
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19,false));
students.add(new Student(2,"赵六","N",17,true));
students.add(new Student(4,"王五","V",22,true));
students.add(new Student(3,"李四","V",23,false));
}
@Test
public void map(){
List<String> result = students.stream()
.map(Student::getName) //只取集合中的姓名值
.collect(Collectors.toList());
System.out.println(result);
}
案例:将集合类型转换并求和
@Test
public void map2(){
List<String> list = Arrays.asList("1","2","3","2","6");
int result = list.stream()
.mapToInt(s->Integer.parseInt(s))//类型转换
.sum(); //求和
System.out.println(result);
}
6.1.4 匹配
用于判断集合中某些元素是否匹配对应的条件,如果有的话,再进行后续的操作。如anyMatch、allMatch等,对应&& 和|| ||运算符。
- anyMatch( ) 只要有1条数据满足条件即返回TRUE 否则返回FALSE
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19,false));
students.add(new Student(2,"赵六","N",22,true));
students.add(new Student(4,"王五","V",22,true));
students.add(new Student(3,"李四","V",23,false));
}
@Test
public void anyMath(){
if(students.stream().anyMatch(s->s.getAge()==22)){
System.out.println("集合中有22岁的学生");
}
}
- allMatch( ) 当所有数据满足条件后返回TRUE 否则返回FALSE。
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19,false));
students.add(new Student(2,"赵六","N",22,true));
students.add(new Student(4,"王五","V",22,true));
students.add(new Student(3,"李四","V",23,false));
}
@Test
public void allMath(){
if(students.stream().allMatch(Student::isIspass)){
System.out.println("所有学生及格");
}else{
System.out.println("还有学生不及格");
}
}
6.1.5 查找
- findAny( ) 随机查找符合条件的数据,找到返回该数据(并行流情况下才会随机返回)
@BeforeEach
public void init(){
students.add(new Student(1,"张三","N",19,false));
students.add(new Student(2,"赵六","N",22,true));
students.add(new Student(4,"王五","V",22,true));
students.add(new Student(3,"李四","V",23,false));
}
@Test
public void findAny(){
Optional<Student> optional = students.stream().filter(s -> s.getAge() > 10).findAny();
if(optional.isPresent()){
Student student = optional.get();
System.out.println(student);
}
}
- findFirst( ) 返回第一个符合条件的数据
6.1.6 聚合
- reduce()累加。参数一表示初始值*(累加后会再次加上初始的值)*。
public void reduce(){
List<Integer> list = Arrays.asList(1,2,3,4,5);
// Integer sum = list.stream().reduce(0, (a, b) -> a + b);
// Integer sum = list.stream().reduce(0, Integer::sum);
System.out.println(sum);
Optional<Integer> optional = list.stream().reduce(Integer::sum);
if(optional.isPresent()){
System.out.println(optional.get());
}
}
- max( ) 取出数据中最大的值
@Test
public void max(){
List<Integer> list = Arrays.asList(1,2,3,4,5);
// Optional<Integer> optional = list.stream().reduce(Integer::max);
Optional<Integer> optional = list.stream().max(Integer::compareTo);
if(optional.isPresent()){
System.out.println(optional.get());
}
}
- min( )最小值。使用同max
6.1.7 构建流
- 基于数组创建
public void create(){
//1.通过of方法创建
Streamstream = Stream.of(1, 2, 3);
//2.通过数组stream方法创建,底层实现相同
IntStream stream1 = Arrays.stream(new int[]{1, 2, 3});
} - 基于文件创建
6.1.8 收集器
- collect( ) 可以收集流中的数据到集合或者数组中
public void collect(){
//1.通过of方法创建
Stream<Integer> stream = Stream.of(1, 2, 3);
List<Integer> list = stream.collect(Collectors.toList());
}
- 分组/分区/拼接
分组:groupingBy( )
通过Collectors.groupingBy( )完成。分组可以分多个
@BeforeEach
public void init() {
students.add(new Student(1, "张三", "N", 19, false));
students.add(new Student(2, "赵六", "N", 22, true));
students.add(new Student(4, "王五", "V", 22, true));
students.add(new Student(3, "李四", "V", 23, false));
}
@Test
public void groupingBy() {
//按性别分组
Map<String, List<Student>> map = students.stream()
.collect(Collectors.groupingBy(Student::getSex));
}
分区:partitioningBy( )
分组通过Collectors.partitioningBy( )完成。分区只能分2个。根据返回值是否为TRUE,把集合分为2个列表,一个TRUE列表,一个FALSE列表。
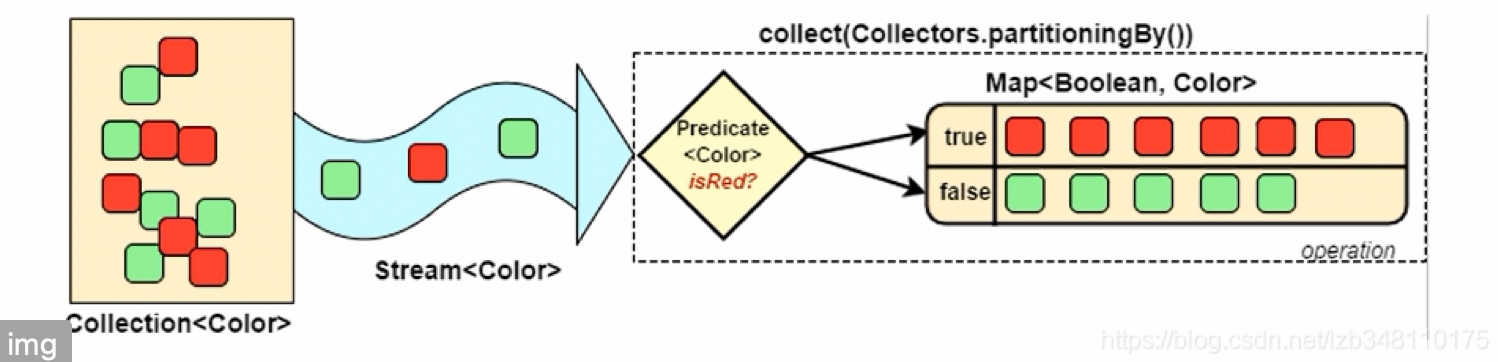
@BeforeEach
public void init() {
students.add(new Student(1, "张三", "N", 19, false));
students.add(new Student(2, "赵六", "N", 22, true));
students.add(new Student(4, "王五", "V", 22, true));
students.add(new Student(3, "李四", "V", 23, false));
}
@Test
public void partitioningBy() {
Map<Boolean, List<Student>> map = students.stream()
.collect(Collectors.partitioningBy(s -> s.getSex().endsWith("N")));
System.out.println(map);
//{
// false=[Student(id=4, name=王五, sex=V, age=22, ispass=true), Student(id=3, name=李四, sex=V, age=23, ispass=false)],
// true=[Student(id=1, name=张三, sex=N, age=19, ispass=false), Student(id=2, name=赵六, sex=N, age=22, ispass=true)]
// }
}
拼接:joining( )
Collectors.joining() 会根据指定的连接符,将所有元素连接成一个字符串。
@BeforeEach
public void init() {
students.add(new Student(1, "张三", "N", 19, false));
students.add(new Student(2, "赵六", "N", 22, true));
students.add(new Student(4, "王五", "V", 22, true));
students.add(new Student(3, "李四", "V", 23, false));
}
@Test
public void joining() {
String names = students.stream()
.map(Student::getName)
.collect(Collectors.joining());
System.out.println(names);//张三赵六王五李四
}
6.2 数据并行化
parallelStream( )替换stream( )
6.2.1 并行和并发
并行:多个任务在同一时间点发生,并由不同的CPU进行处理,互相不抢占资源。
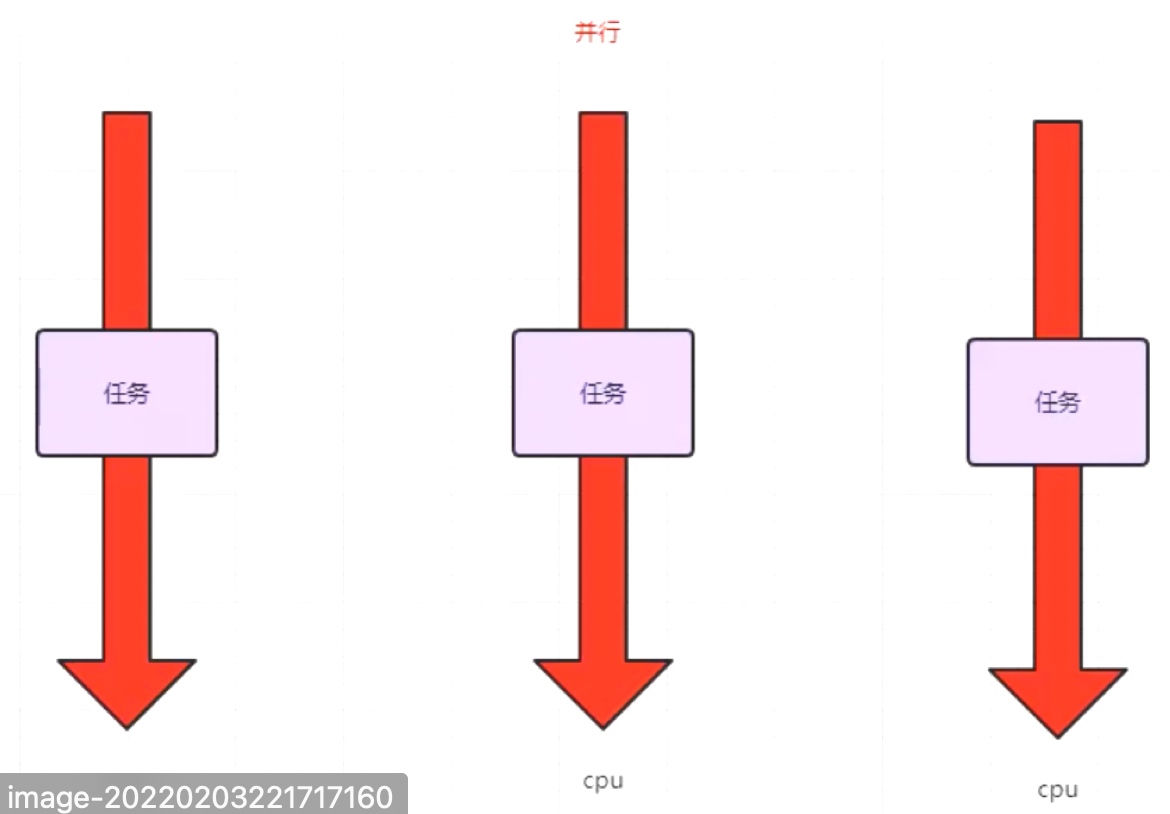
并发:多个任务在同一时间内同时发生,但由同一个CPU处理,互相抢夺资源。

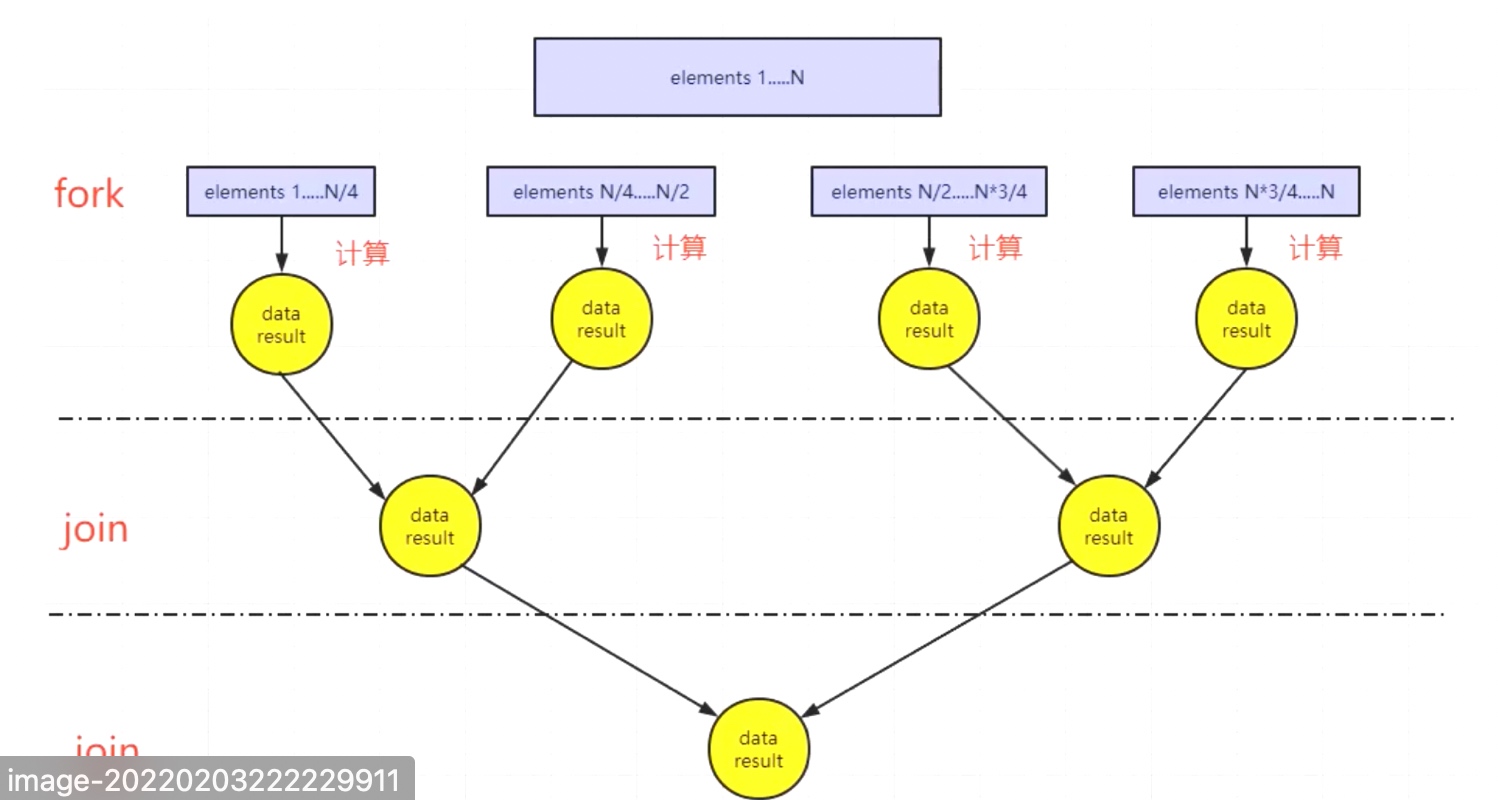
6.2.2 并行流原理介绍
对于并行流,其在底层中,是沿用Java7提供的fork\join分解合并框架进行实现。fork根据==CPU可用核数==进行数据分块,join对各个fork进行合并,实现过程如下图。
假如现在的操作是运行一台4核机器上
7 异步编程CompleTableFuture
completableFuture是Java1.8提供的一个新类,其实现了Future与completionStage两个接口。提供了诸多API扩展功能,可以通过stream形式简化异步编程的复杂度,同时提供通过回调方式处理计算结果。
7.1 创建异步任务
在completableFuture中提供了四个静态方法用于创建异步任务:
runAsync(Runnable runnable) //不带返回值,默认使用守护进程线程池,不推荐
runAsync(Runnable runnable,Executor executor)//无返回值,自定义线程池
supplyAsync(Supplier<U> supplier)//有返回值,默认使用守护进程线程池,不推荐
supplyAsync(Supplier<U> supplier,Executor executor)//有回值,自定义线程池

 浙公网安备 33010602011771号
浙公网安备 33010602011771号