Oracle打怪升级之路一【Oracle基础、Oracle查询】
前言
背景:2021年马上结束了,在年尾由于工作原因接触到一个政府单位比较传统型的项目,数据库用的是Oracle。需要做的事情其实很简单,首先从大约2000多张表中将表结构及数据导入一个共享库中,其次是将共享库的数据进行清理落到业务库里面。表不算多,但是表里面的数据量还蛮大的,开始是打算进行OGG同步,但由于数据保密的原因,机关单位不向外直接提供,只能导表结构及脱敏数据,于是进行dmp备份导入,再用存储过程进行数据落地。在处理过程中发现Oracle常用的知识点基本都有涉及,于是决定写下这篇博文。
整篇文章主要分为4大部分
- Oracle 基础
- Oracle 查询
- Oracle 对象
- Oracle 编程
当然,后续工作中有相应的知识点或者新的内容,再将轮子不断完善。
Oracle基础
Oracle简介
(一) 什么是Oracle
ORACLE 数据库系统是美国 ORACLE 公司(甲骨文)提供的以分布式数据库为核心的一组软件产品,是目前最流行的客户/服务器(CLIENT/SERVER)或
B/S 体系结构的数据库之一。
ORACLE 通常应用于大型系统的数据库产品。
ORACLE 数据库是目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个
完备关系的产品;作为分布式数据库它实现了分布式处理功能。
ORACLE 数据库具有以下特点:
(1)支持多用户、大事务量的事务处理
(2)数据安全性和完整性控制
(3)支持分布式数据处理
(4)可移植性
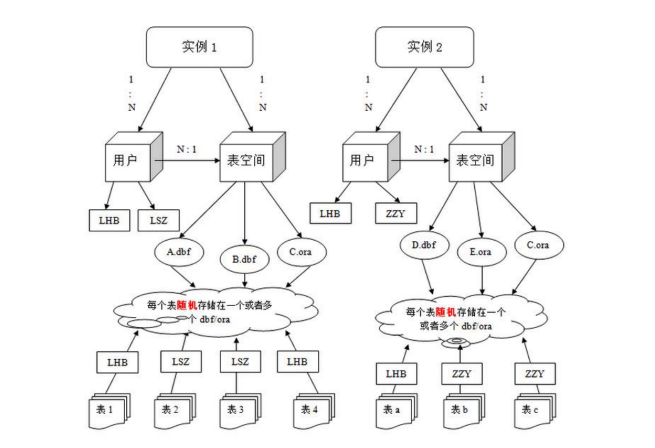
(二) Oracle体系结构
-
数据库
Oracle 数据库是数据的物理存储。这就包括(数据文件 ORA 或者 DBF、控制文件、联机日志、参数文件)。其实 Oracle 数据库的概念和其它数据库不一
样,这里的数据库是一个操作系统只有一个库。可以看作是 Oracle 就只有一个北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090大数据库。
-
实例
一个Oracle实例(Oracle Instance)有一系列的后台进程(Backguound Processes)和内存结构(Memory Structures)组成。一个数据库可以有 n 个实例。
-
数据文件(dbf)
数据文件是数据库的物理存储单位。数据库的数据是存储在表空间中的,真正是在某一个或者多个数据文件中。而一个表空间可以由一个或多个数据文件组成,一个数据文件只能属于一个表空间。一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数据文件,只能删除其所属于的表空间才行。
-
表空间
表空间是 Oracle 对物理数据库上相关数据文件(ORA 或者 DBF 文件)的逻辑映射。一个数据库在逻辑上被划分成一到若干个表空间,每个表空间包含了在
逻辑上相关联的一组结构。每个数据库至少有一个表空间(称之为 system 表空间)。
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。

注:表的数据,是有用户放入某一个表空间的,而这个表空间会随机把这些表数据放到一个或者多个数据文件中。
由于 oracle 的数据库不是普通的概念,oracle 是有用户和表空间对数据进行管理和存放的。但是表不是有表空间去查询的,而是由用户去查的。因为不同用
户可以在同一个表空间建立同一个名字的表!这里区分就是用户了!

-
用户
用户是在表空间下建立的。用户登陆后只能看到和操作自己的表, ORACLE的用户与 MYSQL 的数据库类似,每建立一个应用需要创建一个用户。
Oracle安装配置
关于搭建这一部分,详细的流程就不一一列举了,网上一查一大堆的资料,整体来说还是非常简单的。而且一般来说在公司会有专门的DBA或者系统集成人员来做这部分工作,后续如果实际中工作有需要自己做这一块,我再将这部分补充完整。
Oracle 表的基础操作
-
查看当前数据库实例名称
select instance_name from v$instance; -
常用的数据字典信息查询(数据字典视图包含静态数据字典视图和动态性能视图,其中静态的数据字典视图又分为三类,以不同前缀相互区分)
- DBA_*** 该视图包含数据库整个对象信息,只能由数据库管理员查看
- ALL_*** 包含某个用户所能看到的全部数据库信息
- USER_*** 包含当前用户访问的数据库对象信息
-- 通过数据字典视图dba_objects查看某个用户的数据库对象信息,对于另外两类视图也是类似做法 select owner,object_name,created from from dba_objects where owner='HX_ZS'; -- 查看当前用户所拥有的表 select table_name from user_tables; -- 查看当前用户所拥有的表名和类型 select * from user_catalog; -
动态性能视图查询,动态性能视图只存在于运行的数据库中,只有数据库管理员可以查询,以v$为前缀。
- v$controlfile包含了控制文件存储目录和文件名信息
- v$datafile包含了数据库文件信息
- v$fixed_table视图包含了当前所有动态性能视图
- v$datafile包含了当前所有动态性能视图
-- 查询所有和日志文件相关的动态性能视图 select * from v$fixed_table where name like 'V$LOG%'; -- 查看当前正在使用的重做日志组,current说明正在使用 select group#,members,archived,status from v$log; -- 查看重做日志文件信息 select * from v$logfile; -- 查看实例信息 select instance_name,host_name,version,startup_time,logins from v$instance; -- 查看数据库信息 select name,created,log_mode from v$database; -
查看表空间名称
select tablespace_name,file_id,bytes,file_name from dba_data_files; -
创建表空间
create tablespace waterboss datafile '/u01/oradata/swgx/waterboss.dbf' size 100m autoextend on next 10m;解释:
waterboss 为表空间名称
datafile 用于设置物理文件名称
size 用于设置表空间的初始大小
autoextend on 用于设置自动增长,如果存储量超过初始大小,则开始自动扩容
next 用于设置扩容的空间大小
-
创建用户 表空间和用户之间的关系是多对多
create user wateruser identified by wateruser default tablespace waterboss;解释:
wateruser 为创建的用户名
identified by 用于设置用户的密码
default tablesapce 用于指定默认表空间名称
-
用户赋权,给用户赋予DBA权限后即可登录
grant dba to wateruser; -
数据类型
-
字符型
(1)CHAR : 固定长度的字符类型,最多存储 2000 个字节
(2)VARCHAR2 :可变长度的字符类型,最多存储 4000 个字节
(3)LONG : 大文本类型。最大可以存储 2 个 G -
数值型
NUMBER : 数值类型
NUMBER(5) 最大可以存的数为 99999
NUMBER(5,2) 最大可以存的数为 999.99
-
日期型
(1)DATE:日期时间型,精确到秒
(2)TIMESTAMP:精确到秒的小数点后 9 位
-
二进制(大数据类型)
(1)CLOB : 存储字符,最大可以存 4 个 G
(2)BLOB:存储图像、声音、视频等二进制数据,最多可以存 4 个 G
-
-
创建表
-- 语法 CREATE TABLE 表名称( 字段名 类型(长度) primary key, 字段名 类型(长度), ....... ); -
修改表
增加字段语法
-- 语法 ALTER TABLE 表名称 ADD( 列名 1 类型 [DEFAULT 默认值], 列名 1 类型 [DEFAULT 默认值] ... ) -- 语句 ALTER TABLE T_OWNERS ADD( REMARK VARCHAR2(20), OUTDATE DATE )修改字段语法
-- 语法 ALTER TABLE 表名称 MODIFY( 列名 1 类型 [DEFAULT 默认值], 列名 1 类型[DEFAULT 默认值] ... ) -- 语句 ALTER TABLE T_OWNERS MODIFY( REMARK CHAR(20), OUTDATE TIMESTAMP )修改字段名语法
ALTER TABLE T_OWNERS RENAME COLUMN OUTDATE TO EXITDATE删除字段名
-- 删除一个字段 ALTER TABLE 表名称 DROP COLUMN 列名 -- 删除多个字段 ALTER TABLE 表名称 DROP (列名 1,列名 2...) -- 语句 ALTER TABLE T_OWNERS DROP COLUMN REMARK -
删除表
DROP TABLE 表名称 -
基础的增删改查我就不一一去列举语法了,这里提一下truncat 与 delete 表数据删除差异
-- DELETE,执行 DELETE 后一定要再执行 COMMIT 提交事务 DELETE FROM 表名 WHERE 删除条件; -- TRUNCATE 语法 TRUNCATE TABLE 表名称二者差异:
- delete 删除的数据可以 rollback
- delete 删除可能产生碎片,并且不释放空间
- truncate 是先摧毁表结构,再重构表结构
Oracle 数据的导入导出
当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(硬件故障、软件故障、网络故障、进程故障和系统故障)影响数据库系统的操作,影响数据库中数据的正确性,甚至破坏数据库,使数据库中全部或部分数据丢失。因此当发生上述故障后,希望能重构这个完整的数据库该处理称为数据库恢复,而要进行数据库的恢复必须要有数据库的备份工作。
前提条件,切换至Oracle下并登陆
# Linux 切换oracle用户 并登陆
$: su -l oracle
$: sqlplus 用户名/密码 as sysdba
(一) 整库导入导出
$: exp system/wateruser full=y
解释:添加参数 full=y 就是整库导出,执行命令后会在当前目录下生成一个叫 EXPDAT.DMP,此文件为备份文件。
如果想指定备份文件的名称,则添加 file 参数即可,命令如下
$: exp system/wateruser file=文件名 full=y
整库导入命令
$: imp system/wateruser full=y
此命令如果不指定 file 参数,则默认用备份文件 EXPDAT.DMP 进行导入如果指定 file 参数,则按照 file 指定的备份文件进行恢复
$: imp system/wateruser full=y file=water.dmp
(二) 按用户导出与导入
按用户导出
$: exp system/wateruser owner=wateruser file=wateruser.dmp
按用户导入
$: imp system/wateruser file=wateruser.dmp fromuser=wateruser
(三) 按表导出与导入
按表导出,用 tables 参数指定需要导出的表,如果有多个表用逗号分割即可
$: exp wateruser/wateruser file=a.dmp tables=t_account,a_area
按表导入
$: imp wateruser/wateruser file=a.dmp tables=t_account,a_area
Oracle查询
以下案例的SQL脚本及测试数据,可关注博主后私信获取。原创不易,谢谢支持。
单表查询
简单条件查询
精确查询
需求:查询水表编号为 30408 的业主记录
查询语句:
select * from T_OWNERS where watermeter='30408'
模糊查询
需求:查询业主名称包含“刘”的业主记录
查询语句:
select * from t_owners where name like '%刘%'
and运算符
需求:查询业主名称包含“刘”的并且门牌号包含 5 的业主记录
查询语句:
select * from t_owners where name like '%刘%' and housenumber like '%5%'
or 运算符
需求:查询业主名称包含“刘”的或者门牌号包含 5 的业主记录
查询语句:
select * from t_owners where name like '%刘%' or housenumber like '%5%'
and 与 or 运算符混合使用
需求:查询业主名称包含“刘”的或者门牌号包含 5 的业主记录,并且地址编号 为 3 的记录。
select * from t_owners where (name like '%刘%' or housenumber like '%5%') and addressid=3
因为 and 的优先级比 or 大,所以我们需要用 ( ) 来改变优先级。
范围查询
需求:查询台账记录中用水字数大于等于 10000,并且小于等于 20000 的记录
我们可以用>= 和<=来实现,查询语句
select * from T_ACCOUNT where usenum>=10000 and usenum<=20000
我们也可以用 between .. and ..来实现
select * from T_ACCOUNT where usenum between 10000 and 20000
空值查询
需求:查询 T_PRICETABLE 表中 MAXNUM 为空的记录
语句:
select * from T_PRICETABLE t where maxnum is null
需求:查询 T_PRICETABLE 表中 MAXNUM 不为空的记录
查询语句
select * from T_PRICETABLE t where maxnum is not null
去掉重复记录
需求:查询业主表中的地址 ID,不重复显示
语句:
select distinct addressid from T_OWNERS
排序查询
升序查询
需求:对 T_ACCOUNT 表按使用量进行升序排序
语句:
select * from T_ACCOUNT order by usenum
降序排序
需求:对 T_ACCOUNT 表按使用量进行降序排序
语句:
select * from T_ACCOUNT order by usenum desc
基于伪列的查询
在 Oracle 的表的使用过程中,实际表中还有一些附加的列,称为伪列。伪列就 像表中的列一样,但是在表中并不存储。伪列只能查询,不能进行增删改操作。 接下来学习两个伪列:ROWID 和 ROWNUM。
ROWID
表中的每一行在数据文件中都有一个物理地址,ROWID 伪列返回的就是该行的 物理地址。使用 ROWID 可以快速的定位表中的某一行。ROWID 值可以唯一的标识表中的一行。由于 ROWID 返回的是该行的物理地址,因此使用 ROWID 可以显示行是如何存储的。
select rowID,t.* from T_AREA t;
我们可以通过指定 ROWID 来查询记录
select rowID,t.* from T_AREA t where ROWID='AAAM1uAAGAAAAD8AAC';
ROWNUM
在查询的结果集中,ROWNUM 为结果集中每一行标识一个行号,第一行返回 1, 第二行返回 2,以此类推。
通过 ROWNUM 伪列可以限制查询结果集中返回的行数。可用作分页查询
查询语句
select rownum,t.* from T_OWNERTYPE t
聚合统计
ORACLE 的聚合统计是通过分组函数来实现的,与 MYSQL 一致。
聚合函数
求和 SUM
需求:统计 2012 年所有用户的用水量总和
select sum(usenum) from t_account where year='2012'
求平均值 AVG
需求:统计 2012 年所有用水量(字数)的平均值
select avg(usenum) from T_ACCOUNT where year='2012'
求最大值 MAX
需求:统计 2012 年最高用水量(字数)
select max(usenum) from T_ACCOUNT where year='2012'
求最小值 MIN
需求:统计 2012 年最低用水量(字数)
select min(usenum) from T_ACCOUNT where year='2012'
统计个数
需求:统计业主类型 ID 为 1 的业主数量
select count(*) from T_OWNERS t where ownertypeid=1
分组聚合
需求:按区域分组统计水费合计数
查询语句
select areaid,sum(money) from t_account group by areaid
分组后条件查询having
需求:查询水费合计大于 16900 的区域及水费合计
查询语句
select areaid,sum(money) from t_account group by areaid having sum(money)>169000
连接查询
多表内连接查询
需求:查询显示业主编号,业主名称,业主类型名称
查询语句
select o.id 业主编号,o.name 业主名称,ot.name 业主类型 from T_OWNERS o,T_OWNERTYPE ot where o.ownertypeid=ot.id
需求:查询显示业主编号,业主名称、地址和业主类型
查询语句
select o.id 业主编号,o.name 业主名称,ad.name 地址, ot.name 业主类型 from T_OWNERS o,T_OWNERTYPE ot,T_ADDRESS ad where o.ownertypeid=ot.id and o.addressid=ad.id
需求:查询显示业主编号、业主名称、地址、所属区域、业主分类
查询语句
select o.id 业主编号,o.name 业主名称,ar.name 区域, ad.name 地 址, ot.name 业主类型
from T_OWNERS o ,T_OWNERTYPE ot,T_ADDRESS ad,T_AREA ar
where o.ownertypeid=ot.id and
o.addressid=ad.id and
ad.areaid=ar.id
需求:查询显示业主编号、业主名称、地址、所属区域、收费员、业主分类
查询语句
select ow.id 业主编号,ow.name 业主名称,ad.name 地址, ar.name 所属区域,op.name 收费员, ot.name 业主类型
from
T_OWNERS ow,T_OWNERTYPE ot,T_ADDRESS ad , T_AREA ar,T_OPERATOR op
where ow.ownertypeid=ot.id
and ow.addressid=ad.id
and ad.areaid=ar.id
and ad.operatorid=op.id
左外连接查询
需求:查询业主的账务记录,显示业主编号、名称、年、月、金额。如果此业主没有账务记录也要列出姓名。
查询语句
-- SQL1999 标准的语法
SELECT ow.id,ow.name,ac.year ,ac.month,ac.money FROM T_OWNERS ow left join T_ACCOUNT ac on ow.id=ac.owneruuid
-- ORACLE 提供的语法
SELECT ow.id,ow.name,ac.year ,ac.month,ac.money FROM T_OWNERS ow,T_ACCOUNT ac WHERE ow.id=ac.owneruuid(+)
如果是左外连接,就在右表所在的条件一端填上(+)
右外连接查询
需求:查询业主的账务记录,显示业主编号、名称、年、月、金额。如果账务记录没有对应的业主信息,也要列出记录。
-- SQL1999 标准的语句
select ow.id,ow.name,ac.year,ac.month,ac.money from T_OWNERS ow right join T_ACCOUNT ac on ow.id=ac.owneruuid
-- ORACLE 提供的语法
select ow.id,ow.name,ac.year,ac.month,ac.money from T_OWNERS ow , T_ACCOUNT ac where ow.id(+) =ac.owneruuid
子查询
where 子句中的子查询
-
单行子查询
-
只返回一条记录
-
单行操作符
-

需求:查询 2012 年 1 月用水量大于平均值的台账记录
查询语句:
select * from T_ACCOUNT where year='2012' and month='01'
and usenum> ( select avg(usenum) from T_ACCOUNT where year='2012' and month='01' )
-
多行子查询
-
返回多条记录
-
多行操作符
-
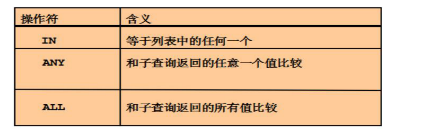
in运算符
需求:查询地址编号为 1 、3、4 的业主记录
分析:如果我们用 or 运算符编写,SQL 非常繁琐,所以我们用 in 来进行查询
查询语句
select * from T_OWNERS where addressid in ( 1,3,4 )
需求:查询地址含有“花园”的业主的信息
查询语句
select * from T_OWNERS where addressid in ( select id from t_address where name like '%花园%' )
需求:查询地址不含有“花园”的业主的信息
查询语句
select * from T_OWNERS where addressid not in ( select id from t_address where name like '%花园%' )
from 子句中的子查询
from 子句的子查询为多行子查询
需求:查询显示业主编号,业主名称,业主类型名称,条件为业主类型为”居民”, 使用子查询实现。
查询语句
select * from (
select o.id 业主编号,o.name 业主名称,ot.name 业主类型
from T_OWNERS o,T_OWNERTYPE ot
where o.ownertypeid=ot.id )
where 业主类型='居民';
select 子句中的子查询
select 子句的子查询必须为单行子查询
需求:列出业主信息,包括 ID,名称,所属地址
查询语句
select id,name, (select name from t_address where id=addressid) addressname from t_owners;
需求:列出业主信息,包括 ID,名称,所属地址,所属区域
查询语句
select id, name, ( select name from t_address where id=addressid ) addressname,
( select (select name from t_area where id=areaid ) from t_address where id = addressid ) adrename
from t_owners;
分页查询
简单分页
需求:分页查询台账表 T_ACCOUNT,每页 10 条记录
分析:我们在 ORACLE 进行分页查询,需要用到伪列 ROWNUM 和嵌套查询
我们首先显示前 10 条记录,查询语句:
select rownum,t.* from T_ACCOUNT t where rownum<=10
那么我们显示第 11 条到第 20 条的记录呢?编写语句:
select rownum,t.* from T_ACCOUNT t where rownum>10 and rownum<=20
查询结果为空
嗯?怎么没有结果?
这是因为 rownum 是在查询语句扫描每条记录时产生的,所以不能使用“大于”
符号,只能使用“小于”或“小于等于” ,只用“等于”也不行。
那怎么办呢?我们可以使用子查询来实现
select * from (select rownum r,t.* from T_ACCOUNT t where rownum<=20) where r>10
基于排序的分页
需求:分页查询台账表 T_ACCOUNT,每页 10 条记录,按使用字数降序排序。
我们查询第 2 页数据,如果基于上边的语句添加排序,查询语句如下
select * from (select rownum r,t.* from (select * from T_ACCOUNT order by usenum desc) t where rownum<=20 ) where r>10
单行函数查询
字符函数
| 函数 | 说明 |
|---|---|
| ASCII | 返回对应字符的十进制值 |
| CHR | 给出十进制返回字符 |
| CONCAT | 拼接两个字符串,与 |
| INITCAT | 将字符串的第一个字母变为大写 |
| INSTR | 找出某个字符串的位置 |
| INSTRB | 找出某个字符串的位置和字节数 |
| LENGTH | 以字符给出字符串的长度 |
| LENGTHB | 以字节给出字符串的长度 |
| LOWER | 将字符串转换成小写 |
| LPAD | 使用指定的字符在字符的左边填充 |
| LTRIM | 在左边裁剪掉指定的字符 |
| RPAD | 使用指定的字符在字符的右边填充 |
| RTRIM | 在右边裁剪掉指定的字符 |
| REPLACE | 执行字符串搜索和替换 |
| SUBSTR | 取字符串的子串 |
| SUBSTRB | 取字符串的子串(以字节) |
| SOUNDEX | 返回一个同音字符串 |
| TRANSLATE | 执行字符串搜索和替换 |
| TRIM | 裁剪掉前面或后面的字符串 |
| UPPER | 将字符串变为大写 |
常用字符函数:
字符串长度 LENGTH
select length('ABCD') from dual;
字符串的子串 SUBSTR
select substr('ABCD',2,2) from dual;
字符串拼接 CONCAT
select concat('ABC','D') from dual;
我们也可以用|| 对字符串进行拼接
select 'ABC'||'D' from dual;
数值函数
| 函数 | 说明 |
|---|---|
| ABS(value) | 绝对值 |
| CEIL(value) | 大于或等于 value 的最小整数 |
| COS(value) | 余弦 |
| COSH(value) | 反余弦 |
| EXP(value) | e 的 value 次幂 |
| FLOOR(value) | 小于或等于 value 的最大整数 |
| LN(value) | value 的自然对数 |
| LOG(value) | value 的以 10 为底的对数 |
| MOD(value,divisor) | 求模 |
| POWER(value,exponent) | value 的 exponent 次幂 |
| ROUND(value,precision) | 按 precision 精度 4 舍 5 入 |
| SIGN(value) | value 为正返回 1;为负返回-1;为 0 返回 0. |
| SIN(value) | 余弦 |
| SINH(value) | 反余弦 |
| SQRT(value) | value 的平方根 |
| TAN(value) | 正切 |
| TANH(value) | 反正切 |
| TRUNC(value,按 precision) | 按照 precision 截取 value |
| VSIZE(value) | 返回 value 在 ORACLE 的存储空间大小 |
常用数值函数讲解
四舍五入函数 ROUND
-- 不保留小数,四舍五入
select round(100.567) from dual;
-- 保留小数四舍五入
select round(100.567,2) from dual;
截取函数 TRUNC
select trunc(100.567) from dual
select trunc(100.567,2) from dual
取模 MOD
select mod(10,3) from dual
日期函数
| 函数 | 描述 |
|---|---|
| ADD_MONTHS | 在日期 date 上增加 count 个月 |
| GREATEST(date1,date2,. . .) | 从日期列表中选出最晚的日期 |
| LAST_DAY( date ) | 返回日期 date 所在月的最后一天 |
| LEAST( date1, date2, . . .) | 从日期列表中选出最早的日期 |
| MONTHS_BETWEEN(date2, date1) | 给出 Date2 - date1 的月数(可以是小数) |
| NEXT_DAY( date,’day’) | 给出日期 date 之后下一天的日期,这里的 day 为星期, 如: MONDAY,Tuesday 等。 |
| NEW_TIME(date,’this’,’other’) | 给出在 this 时区=Other 时区的日期和时间 |
| ROUND(date,’format’) | 未指定 format 时,如果日期中的时间在中午之前,则 将日期中的时间截断为 12 A.M.(午夜,一天的开始),否 则进到第二天。时间截断为 12 A.M.(午夜,一天的开始),否则进到第二天。 |
| TRUNC(date,’format’) | 未指定 format 时,将日期截为 12 A.M.( 午夜,一天的开始)。 |
我们用 sysdate 这个系统变量来获取当前日期和时间
select sysdate from dual;
常用日期函数讲解:
加月函数 ADD_MONTHS :在当前日期基础上加指定的月
select add_months(sysdate,2) from dual;
求所在月最后一天 LAST_DAY
select last_day(sysdate) from dual;
日期截取 TRUNC
select TRUNC(sysdate) from dual;
select TRUNC(sysdate,'yyyy') from dual
select TRUNC(sysdate,'mm') from dual
转换函数
| 函数 | 描述 |
|---|---|
| CHARTOROWID | 将 字符转换到 rowid 类型 |
| CONVERT | 转换一个字符节到另外一个字符节 |
| HEXTORAW | 转换十六进制到 raw 类型 |
| RAWTOHEX | 转换 raw 到十六进制 |
| ROWIDTOCHAR | 转换 ROWID 到字符 |
| TO_CHAR | 转换日期格式到字符串 |
| TO_DATE | 按照指定的格式将字符串转换到日期型 |
| TO_MULTIBYTE | 把单字节字符转换到多字节 |
| TO_NUMBER | 将数字字串转换到数字 |
| TO_SINGLE_BYTE | 转换多字节到单字节 |
常用转换函数
数字转字符串
select TO_CHAR(1024) from dual
日期转字符串 TO_CHAR
select TO_CHAR(sysdate,'yyyy-mm-dd') from dual;
select TO_CHAR(sysdate,'yyyy-mm-dd hh:mi:ss') from dual;
字符串转日期 TO_DATE
select TO_DATE('2017-01-01','yyyy-mm-dd') from dual;
字符串转数字 TO_NUMBER
select to_number('100') from dual;
其他函数
空值处理函数 NVL
语法: NVL(检测的值,如果为 null 的值);
select NVL(NULL,0) from dual;
-- 需求:显示价格表中业主类型 ID 为 1 的价格记录,如果上限值为 NULL,则显示 9999999
select PRICE,MINNUM,NVL(MAXNUM,9999999) from T_PRICETABLE where OWNERTYPEID=1;
空值处理函数 NVL2
语法: NVL2(检测的值,如果不为 null 的值,如果为 null 的值);
-- 需求:显示价格表中业主类型 ID 为 1 的价格记录,如果上限值为 NULL,显示“不限”
select PRICE,MINNUM,NVL2(MAXNUM,to_char(MAXNUM) , '不限') from T_PRICETABLE where OWNERTYPEID=1;
条件取值 decode
语法: decode(条件,值 1,翻译值 1,值 2,翻译值 2,...值 n,翻译值 n,缺省值) 【功能】根据条件返回相应值
select name,decode(ownertypeid,
1,'居民',
2,'行政事业单位',
3,'商业') as 类型 from T_OWNERS
上边的语句也可以用 case when then 语句来实现
select name ,(case ownertypeid
when 1 then '居民'
when 2 then '行政事业单位'
when 3 then '商业'
else '其它'
end ) from T_OWNERS;
-- 另外一种写法
select name,(case when ownertypeid= 1 then '居民'
when ownertypeid= 2 then '行政事业'
when ownertypeid= 3 then '商业'
end ) from T_OWNERS
行列转换
需求:按月份统计 2012 年各个地区的水费,如下图
select (select name from T_AREA where id = areaid) 区域,
sum(case when month = '01' then money else 0 end) 一月,
sum(case when month = '02' then money else 0 end) 二月,
sum(case when month = '03' then money else 0 end) 三月,
sum(case when month = '04' then money else 0 end) 四月,
sum(case when month = '05' then money else 0 end) 五月,
sum(case when month = '06' then money else 0 end) 六月,
sum(case when month = '07' then money else 0 end) 七月,
sum(case when month = '08' then money else 0 end) 八月,
sum(case when month = '09' then money else 0 end) 九月,
sum(case when month = '10' then money else 0 end) 十月,
sum(case when month = '11' then money else 0 end) 十一月,
sum(case when month = '12' then money else 0 end) 十二月
from T_ACCOUNT
where year = '2012'
group by areaid;
需求:按季度统计 2012 年各个地区的水费
select (select name from T_AREA where id = areaid) 区域,
sum(case when month >= '01' and month <= '03' then money else 0 end) 第一季度,
sum(case when month >= '04' and month <= '06' then money else 0 end) 第二季度,
sum(case when month >= '07' and month <= '09' then money else 0 end) 第三季度,
sum(case when month >= '10' and month <= '12' then money else 0 end) 第四季度
from T_ACCOUNT
where year = '2012'
group by areaid;
分析函数
以下三个分析函数可以用于排名使用。
RANK 相同的值排名相同,排名跳跃
需求:对 T_ACCOUNT 表的 usenum 字段进行排序,相同的值排名相同,排名跳北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090
跃
select rank() over(order by usenum desc ),usenum from T_ACCOUNT;
DENSE_RANK 相同的值排名相同,排名连续
需求:对 T_ACCOUNT 表的 usenum 字段进行排序,相同的值排名相同,排名连续
select dense_rank() over(order by usenum desc ),usenum from T_ACCOUNT;
ROW_NUMBER 返回连续的排名,无论值是否相等
需求:对 T_ACCOUNT 表的 usenum 字段进行排序,返回连续的排名,无论值是否相等
select row_number() over(order by usenum desc ),usenum from T_ACCOUNT
用 row_number()分析函数实现的分页查询相对三层嵌套子查询要简单的多
select *
from (select row_number() over (order by usenum desc ) rownumber, usenum from T_ACCOUNT)
where rownumber > 10
and rownumber <= 20
集合运算
集合运算,集合运算就是将两个或者多个结果集组合成为一个结果集。
集合运算包括:
- UNION ALL(并集),返回各个查询的所有记录,包括重复记录
- UNION(并集),返回各个查询的所有记录,不包括重复记录
- INTERSECT(交集),返回两个查询共有的记录
- MINUS(差集),返回第一个查询检索出的记录减去第二个查询检索出的记录之后剩余的记录

并集运算
UNION ALL 不去掉重复记录
select *
from t_owners
where id <= 7
union all
select *
from t_owners
where id >= 5
UNION 去掉重复记录
select * from t_owners where id<=7
union
select * from t_owners where id>=5
交集运算
select * from t_owners where id<=7
intersect
select * from t_owners where id>=5
差集运算
select * from t_owners where id<=7
minus
select * from t_owners where id>=5
如果我们用 minus 运算符来实现分页,语句如下
select rownum,t.* from T_ACCOUNT t where rownum<=20
minus
select rownum,t.* from T_ACCOUNT t where rownum<=10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号