Redis解读(5):Redis深入理解及生产高可用
Redis单线程如何处理高并发
1.阻塞IO 与 非阻塞 IO
Java 在 JDK1.4 中引入 NIO,但是也有很多人在使用阻塞 IO,这两种 IO 有什么区别?
在阻塞模式下,如果你从数据流中读取不到指定大小的数据两,IO 就会阻塞。比如已知会有 10 个字节发送过来,但是我目前只收到 4 个,还剩六个,此时就会发生阻塞。如果是非阻塞模式,虽然此时只收到 4 个字节,但是读到 4 个字节就会立即返回,不会傻傻等着,等另外 6 个字节来的时候,再去继续读取。
所以阻塞 IO 性能低于 非阻塞 IO。
如果有一个 Web 服务器,使用阻塞 IO 来处理请求,那么每一个请求都需要开启一个新的线程;但是如果使用了非阻塞 IO,基本上一个小小线程池就够用了,因为不会发生阻塞,每一个线程都能够高效利用。
2.Redis 的线程模型
首先一点,Redis 是单线程。单线程如何解决高并发问题的?
实际上,能够处理高并发的单线程应用不仅仅是 Redis,除了 Redis 之外,还有 NodeJS、Nginx 等等也是单线程。
Redis 虽然是单线程,但是运行很快,主要有如下几方面原因:
- Redis 中的所有数据都是基于内存的,所有的计算也都是内存级别的计算,所以快。
- Redis 是单线程的,所以有一些时间复杂度高的指令,可能会导致 Redis 卡顿,例如 keys。
- Redis 在处理并发的客户端连接时,使用了非阻塞 IO。
- 在使用非阻塞 IO 时,有一个问题,就是线程如何知道剩下的数据来了?这里就涉及到一个新的概念叫做多路复用,本质上就是一个事件轮询 API。
- Redis 会给每一个客户端指令通过队列来排队进行顺序处理,Redis 做出响应时,也会有一个响应的队列。
Redis的通信协议
Redis 通信使用了文本协议,文本协议比较费流量,但是 Redis 作者认为数据库的瓶颈不在于网络流量,而在于内部逻辑,所以采用了这样一个费流量的文本协议。
这个文本协议叫做 Redis Serialization Protocol,简称 RESP
Redis 协议将传输的数据结构分为 5 种最小单元,单元结束时,加上回车换行符 \r\n。
- 单行字符串以 + 开始,例如 +javaboy.org\r\n
- 多行字符串以 $ 开始,后面加上字符串长度,例如 $11\r\njavaboy.org\r\n
- 整数值以: 开始,例如 :1024\r\n
- 错误消息以 - 开始
- 数组以 * 开始,后面加上数组长度
需要注意的是,如果是客户端连接服务端,只能使用第 5 种
1.准备工作
做两件事情:
为了方便客户端连接 Redis,我们关闭 Redis 种的保护模式(在 redis.conf 文件中)
protected-mode no
同时关闭密码:
# requirepass xxxx
配置完成后,重启Redis
2.实战
接下来,我们通过 Socket+RESP 来定义两个最最常见的命令 set 和 get
package org.taoguoguo.socket;
import java.io.IOException;
import java.net.Socket;
/**
* @author taoguoguo
* @description RedisClient
* @website https://www.cnblogs.com/doondo
* @create 2021-04-26 10:04
*/
public class RedisClient {
private Socket socket;
public RedisClient() {
try {
socket = new Socket("192.168.199.229",6379);
} catch (IOException e) {
e.printStackTrace();
System.out.println("Redis连接失败");
}
}
/**
* 执行 Redis 中的 set 命令 [set,key,value]
* @param key
* @param value
* @return
*/
public String set(String key, String value) throws IOException {
StringBuilder sb = new StringBuilder();
sb.append("*3")
.append("\r\n")
.append("$")
.append("set".length())
.append("\r\n")
.append("set")
.append("\r\n")
.append("$")
.append(key.getBytes().length)
.append("\r\n")
.append(key)
.append("\r\n")
.append("$")
.append(value.getBytes().length)
.append("\r\n")
.append(value)
.append("\r\n");
socket.getOutputStream().write(sb.toString().getBytes());
byte[] buf = new byte[1024];
socket.getInputStream().read(buf);
return new String(buf);
}
public String get(String key) throws IOException {
StringBuilder sb = new StringBuilder();
sb.append("*2")
.append("\r\n")
.append("$")
.append("get".length())
.append("\r\n")
.append("get")
.append("\r\n")
.append("$")
.append(key.getBytes().length)
.append("\r\n")
.append(key)
.append("\r\n");
socket.getOutputStream().write(sb.toString().getBytes());
byte[] buf = new byte[1024];
socket.getInputStream().read(buf);
return new String(buf);
}
public static void main(String[] args) throws IOException {
RedisClient redisClient = new RedisClient();
redisClient.set("k1", "v1");
String k1 = redisClient.get("k1");
System.out.println("k1的值: " + k1);
}
}
Redis持久化
Redis 是一个缓存工具,也叫做 NoSQL 数据库,既然是数据库,必然支持数据的持久化操作。在 Redis中,数据库持久化一共有两种方案:
-
快照方式
快照采用一次全量备份,快照采用内存数据二进制序列化的形式,在存储上非常的简促,非常省空间。
-
AOF 日志
AOF日志是连续的增量备份,AOF记录内存修改的指定的记录文本,日志在长期的记录过程中会变得越来越大,所以数据库重启时,如果需要加载AOF日志进行指令重放,时间就会比较漫长,因为原理是通过日志把你曾经执行过的命令挨个再执行一遍,所以耗费时间长,所以一般我们需要定期对AOF日志进行重写瘦身。
1.RDB快照
1.1 原理
redis 是一个单线程程序,那这个程序要同时负责多个客户端的并发读写操作,还有内存数据的读写。这么多指令同时做是如何执行的呢?可能互相之间会有影响,Redis是如何实现的呢?
Redis 使用操作系统的多进程机制来实现快照持久化:Redis 在持久化时,会调用 glibc 函数 fork 一个子进程,然后将快照持久化操作完全交给子进程去处理,而父进程则继续处理客户端请求。在这个过程中,子进程能够看到的内存中的数据在子进程产生的一瞬间就固定下来了,再也不会改变,也就是为什么 Redis 持久化叫做 快照。
1.2 具体配置
在 Redis 中,默认情况下,快照持久化的方式就是开启的。
默认情况下会产生一个 dump.rdb 文件,这个文件就是备份下来的文件。当 Redis 启动时,会自动的去加载这个 rdb 文件,从该文件中恢复数据。如果删除这个文件,重启 redis,之前 dump.rdb 中持久化的数据就丢失了。
具体的配置,在 redis.conf 文件中
#快照频率 You can set these explicitly by uncommenting the three following lines
#900秒内至少有1个键被更改进行快照
save 900 1
#300秒至少有10个键被更改进行快照
save 300 100
#60秒内至少有10000个键被更改进行快照
save 60 10000
#快照执行出错后,是否继续处理客户端的写命令
stop-writes-on-bgsave-error yes
# 是否对快照文件进行压缩
rdbcompression yes
# 表示生成的快照文件名
dbfilename dump.rdb
# 表示生成的快照文件位置
dir ./
1.3 备份流程
- 在 Redis 运行过程中,我们可以向 Redis 发送一条 save 命令来创建一个快照。但是需要注意,save 是一个阻塞命令,Redis 在收到 save 命令开始处理备份操作之后,在处理完成之前,将不再处理其他的请求。其他命令会被挂起,所以 save 使用的并不多。
- 我们一般可以使用 bgsave,bgsave 会 fork 一个子进程去处理备份的事情,不影响父进程处理客户端请求。
- 我们定义的备份规则,如果有规则满足,也会自动触发 bgsave。
- 另外,当我们执行 shutdown 命令时,也会触发 save 命令,备份工作完成后,Redis 才会关闭。
- 用 Redis 搭建主从复制时,在 从机连上主机之后,会自动发送一条 sync 同步命令,主机收到命令之后,首先执行 bgsave 对数据进行快照,然后才会给从机发送快照数据进行同步。
2.AOF日志
与快照持久化不同,AOF 持久化是将被执行的命令追加到 aof 文件末尾,在恢复时,只需要把记录下来的命令从头到尾执行一遍即可。
默认情况下,AOF 是没有开启的。我们需要手动开启
# 开启 aof 配置
appendonly yes
# AOF 文件名
appendfilename "appendonly.aof"
# 备份的时机,下面的配置表示每秒钟备份一次
appendfsync everysec
# 表示 aof 文件在压缩时,是否还继续进行同步操作
no-appendfsync-on-rewrite no
# 表示当目前 aof 文件大小超过上一次重写时的 aof 文件大小的百分之多少的时候,再次进行重写
auto-aof-rewrite-percentage 100
# 如果之前没有重写过,则以启动时的 aof 大小为依据,同时要求 aof 文件至少要大于 64M
auto-aof-rewrite-min-size 64mb
同时为了避免快照备份的影响,记得将快照备份关闭:
save ""
#save 900 1
#save 300 10
#save 60 10000
手动重写AOF文件
BGREWRITEAOF
#在满足AOF规则时,会自动重写 BGREWRITEAOF 命令
3.如何选择哪种快照方式
在实际生产环境中,根据数据量、应用对数据的安全要求、预算限制和业务场景等不同情况,会有各种各样的持久化策略;
- 如果 Redis 仅仅做缓存服务器,一般来说不必太过于太在乎两者数据,不是说做缓存一定不用这两者,可能也会用到
- 如果同时两种持久化方式RDB快照和AOF日志都开启了,当Redis重启时会优先载入AOF的文件来恢复原始的数据,因为在通常情况下,AOF的文件保存的数据集要比RDB文件保存的数据集要完整,RDB数据不完整时,服务器重启也只会优先找AOF文件。
- 那有小伙伴就疑惑了,那我直接用AOF得了。但 Redis 作者实际不推荐这种做法,因为RDB快照更适合用于备份数据库、快速重启等。
- 同时由于RDB文件通常用于后备用途,所以一般在从机上做RDB文件备份,并且通常15分钟备份一次即可。
- 使用AOF的好处是,最坏情况下也只会丢失大概一秒钟的数据,并且脚本简单,只需要load自己的AOF文件。但代价是带来了持续的IO,因为需要不停的去读写文件。AOF还有一个很大的劣势,就是在重写过程中产生的新数据和新文件,造成的阻塞几乎是不可避免的。所以如果硬盘许可时,应当尽量避免AOF的频率。应当结合设备性能和具体项目中的数据进行配置AOF文件大小,通常要设置几个G以上。
- 使用Redis主从结构也可以实现高性能、高可用。
Redis事务
正常来说,一个可以商用的数据库往往都有比较完善的事务支持,Redis 当然也不例外。相对于 关系型数据库中的事务模型,Redis 中的事务要简单很多。因为简单,所以 Redis 中的事务模型不太严格,所以我们不能像使用关系型数据库中的事务那样来使用 Redis。
在关系型数据库中,和事务相关的三个指令分别是:
- begin 开启事务
- commit 提交事务
- rollback 事务回滚
在 Redis 中,当然也有对应的指令:
- multi 开启事务
- exec 执行事务
- discard 放弃事务
1.原子性
Redis 中的事务并不能算作原子性。它仅仅具备隔离性,也就是说当前的事务可以不被其他事务打断
由于每一次事务操作涉及到的指令还是比较多的,为了提高执行效率,我们在使用客户端的时候,可以通过 pipeline 来优化指令的执行。
Redis 中还有一个 watch 指令,watch 可以用来监控一个 key,通过这种监控,我们可以确保在 exec之前,watch 的键的没有被修改过。相当于乐观锁,A用户操作这个键时,B用户不可修改该键,否则事务提交失败。
操作示例:
127.0.0.1:6379> FLUSHALL
OK
127.0.0.1:6379> clear
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> incr k1
QUEUED
127.0.0.1:6379(TX)> set k3 v3
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) OK
3) (error) ERR value is not an integer or out of range
4) OK
127.0.0.1:6379> keys *
1) "k2"
2) "k3"
3) "k1"
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379> get k3
"v3"
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set k4 v4
QUEUED
127.0.0.1:6379(TX)> DISCARD
OK
127.0.0.1:6379> keys *
1) "k2"
2) "k3"
3) "k1"
127.0.0.1:6379>
2.Java 实现
package trans;
import org.taoguoguo.redis.Redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
import java.util.List;
/**
* @author taoguoguo
* @description RedisTransaction
* @website https://www.cnblogs.com/doondo
* @create 2021-04-26 14:59
*/
public class RedisTransaction {
public static void main(String[] args) {
new Redis().execute(jedis -> {
new RedisTransaction().saveMoney(jedis, "taoguoguo", 1000);
});
}
public Integer saveMoney(Jedis jedis, String userId, Integer money) {
while (true) {
jedis.watch(userId);
int v = Integer.parseInt(jedis.get(userId)) + money;
Transaction tx = jedis.multi();
tx.set(userId, String.valueOf(v));
List<Object> exec = tx.exec();
if (exec != null) {
break;
}
}
return Integer.parseInt(jedis.get(userId));
}
}
Redis 主从同步
1.CAP
在分布式环境下,CAP 原理是一个非常基础的东西,所有的分布式存储系统,都只能在 CAP 中选择两项实现。
- c:consistent 一致性
- a:availability 可用性
- p:partition tolerance 分布式容忍性
在一个分布式系统中,这三个只能满足两个:在一个分布式系统中,P 肯定是要实现的,如果P都不实现那就不是分布式系统了。c 和 a 只能选择其中一个。大部分情况下,大多数网站架构选择了 ap,在某段时间内可能数据不一致,但会努力最终一致。
CAP场景:假设我现在两台Redis服务器,分别在长沙和株洲。我要保证可用性,那么如果长沙和株洲网络通信断了,那么数据就会有延迟同步,就不能保证数据的一致性。如果我们保证数据的一致性,长沙和株洲的网络通信断了,暂时不提供服务,等到网络恢复,启动服务数据还是一致的,所以三个只能满足两个。
在 Redis 中,实际上就是保证最终一致性。
Redis 中,当搭建了主从服务之后,如果主从之间的连接断开了,Redis 依然是可以操作的,相当于它满足可用性,但是此时主从两个节点中的数据会有差异,相当于牺牲了一致性。但是 Redis 保证最终一致,就是说当网络恢复的时候,从机会追赶主机,尽量保持数据一致。
2.主从复制
主从复制可以在一定程度上扩展 redis 性能,redis 的主从复制和关系型数据库的主从复制类似,从机能够精确的复制主机上的内容。实现了主从复制之后,一方面能够实现数据的读写分离,降低master的压力,另一方面也能实现数据的备份。
2.1配置方式
假设我有三个redis实例,地址分别如下:
192.168.199.228:6379
192.168.199.228:6380
192.168.199.228:6381
即同一台服务器上三个实例,配置方式如下:
- 将 redis.conf 文件更名为 redis6379.conf,方便我们区分,然后把 redis6379.conf 再复制两份,分别为 redis6380.conf 和 redis6381.conf。如下:
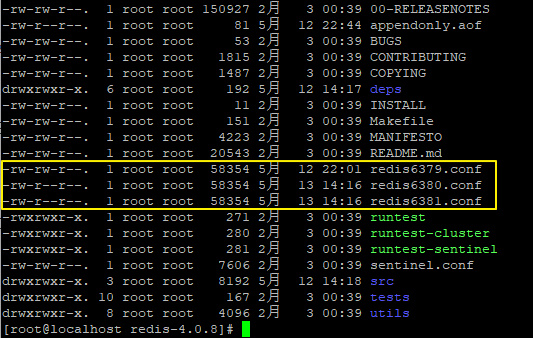
-
打开 redis6379.conf,将如下配置均加上 6379,(默认是6379的不用修改,如果不同机器也可以不用改),如下:
#如果是多机多节点 那不同ip 端口可以相同 就可以不用改 port 6379 pidfile /var/run/redis_6379.pid logfile "6379.log" dbfilename dump6379.rdb appendfilename "appendonly6379.aof" -
同理,分别打开 redis6380.conf 和 redis6381.conf 两个配置文件,将第二步涉及到 6379 的分别改为 6380 和 6381。
#1.编辑6380.conf vim 6380.conf #2.输入 / 查找符号,然后删除 输入替换正则进行全量替换 :%s/6379/6380/g #3.保存退出 :wq! #6481.conf同理修改 -
输入如下命令,启动三个redis实例:
[root@localhost redis-4.0.8]# redis-server redis6379.conf [root@localhost redis-4.0.8]# redis-server redis6380.conf [root@localhost redis-4.0.8]# redis-server redis6381.conf -
输入如下命令,分别进入三个实例的控制台:
[root@localhost redis-4.0.8]# redis-cli -p 6379 -a xxxxxx [root@localhost redis-4.0.8]# redis-cli -p 6380 -a xxxxxx [root@localhost redis-4.0.8]# redis-cli -p 6381 -a xxxxxx此时我就成功配置了三个redis实例了。
-
假设在这三个实例中,6379 是主机,即 master,6380 和 6381 是从机,即 slave,那么如何配置这种实例关系呢,很简单,分别在 6380 和 6381 上执行如下命令:
#在从机节点上分别 使用 SLAVEOF 附属主机 使用该命令,redis节点重启后,本身依旧为主机,不回作为从机附属 127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 OK 127.0.0.1:6381> SLAVEOF 127.0.0.1 6379 OK #要注意的是 虽然附属了 我们此时在主机设置数据,从机还是同步不到。为什么呢?因为我们的主机有密码,从机每次连接都需要密码,否则访问失败。且在生产环境上我们出于安全性考虑,也都是要设置密码的。修改从机的redis.conf文件,我这边以redis6380.conf为例子,6381节点同理。 #1.编辑对应节点配置文件 [root@192 redis-6.2.1]# vim redis6380.conf #2.配置主机认证密码 masterauth xxxxxx # If the master is password protected (using the "requirepass" configuration # directive below) it is possible to tell the replica to authenticate before # starting the replication synchronization process, otherwise the master will # refuse the replica request. masterauth 123456 #3.重启对应节点 然后重新附属主机 127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 OK #4.使用 infp replication 查看主从关系 127.0.0.1:6379> INFO replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=56,lag=1 slave1:ip=127.0.0.1,port=6381,state=online,offset=56,lag=0 master_replid:26ca818360d6510b717e471f3f0a6f5985b6225d master_replid2:0000000000000000000000000000000000000000 master_repl_offset:56 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:56我们可以看到 6379 是一个主机,上面挂了两个从机,两个从机的地址、端口等信息都展现出来了。如
果我们在 6380 上执行 INFO replication,显示信息如下127.0.0.1:6380> INFO replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:6 master_sync_in_progress:0 slave_repl_offset:630 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:26ca818360d6510b717e471f3f0a6f5985b6225d master_replid2:0000000000000000000000000000000000000000 master_repl_offset:630 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:630我们可以看到 6380 是一个从机,从机的信息以及它的主机的信息都展示出来了。
-
此时,我们在主机中存储一条数据,在从机中就可以 get 到这条数据了。
2.2主从复制注意点
-
如果主机已经运行了一段时间了,并且了已经存储了一些数据了,此时从机连上来,那么从机会将
主机上所有的数据进行备份,而不是从连接的那个时间点开始备份 -
使用
SLAVEOF IP Port进行主从配置,节点重启后,从机自身依旧是Master身份,不会自动附属主机,如果想要重启后自动附属主机形成主从关系,需要修改对应节点 redis.conf 文件中 replicaof <masterip> <masterport> 建立主从,配置如下:# # +------------------+ +---------------+ # | Master | ---> | Replica | # | (receive writes) | | (exact copy) | # +------------------+ +---------------+ # # 1) Redis replication is asynchronous, but you can configure a master to # stop accepting writes if it appears to be not connected with at least # a given number of replicas. # 2) Redis replicas are able to perform a partial resynchronization with the # master if the replication link is lost for a relatively small amount of # time. You may want to configure the replication backlog size (see the next # sections of this file) with a sensible value depending on your needs. # 3) Replication is automatic and does not need user intervention. After a # network partition replicas automatically try to reconnect to masters # and resynchronize with them. # # replicaof <masterip> <masterport> replicaof 127.0.0.1 6379 -
配置了主从复制之后,主机上可读可写,但是从机只能读取不能写入(可以通过修改redis.conf 中 slave-read-only 的值让从机也可以执行写操作),一般都是主机读写,从机可读,很少需求会用到从机写。
-
在整个主从结构运行过程中,如果主机不幸挂掉,重启之后,他依然是主机,主从复制操作也能够继续进行。
2.3主从复制原理
每一个 master 都有一个 replication ID,这是一个较大的伪随机字符串,标记了一个给定的数据集。每个 master 也持有一个偏移量,master 将自己产生的复制流发送给 slave 时,发送多少个字节的数据,自身的偏移量就会增加多少,目的是当有新的操作修改自己的数据集时,它可以以此更新 slave 的状态。复制偏移量即使在没有一个 slave 连接到 master 时,也会自增,所以基本上每一对给定的Replication ID, offset 都会标识一个 master 数据集的确切版本。当 slave 连接到 master 时,它们使用PSYNC 命令来发送它们记录的旧的 master replication ID 和它们至今为止处理的偏移量。通过这种方式,master 能够仅发送 slave 所需的增量部分。但是如果 master 的缓冲区中没有足够的命令积压缓冲记录,或者如果 slave 引用了不再知道的历史记录(replication ID),则会转而进行一个全量重同步:在这种情况下,slave 会得到一个完整的数据集副本,从头开始(参考redis官网)。
简单来说,就是以下几个步骤:
- slave 启动成功连接到 master 后会发送一个 sync 命令。
- Master 接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令。
- 在后台进程执行完毕之后,master 将传送整个数据文件到 slave,以完成一次完全同步。
- 全量复制:而 slave 服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master 继续将新的所有收集到的修改命令依次传给 slave,完成同步。
- 但是只要是重新连接 master,就会先来一次全量,后续增量同步(全量复制)将被自动执行
2.4 接力赛(薪火相传)
我们上面已经完成了基本的主从搭建,一主二仆,两个从机都是连接在一个主机上的,这样的连接方式对主机造成的压力比较大,如果一个主机连接很多从机的时候,它的同步可能延时非常高。所以还有另外一种结构,我们同步的时候可以从从机上去同步。比如让 6380 作为 6379 的从机去同步 7379 的数据,让 6381 作为 6380的从机 同步6380 的数据,依此类推往下接,这也是一种搭建思路。
主从复制的两种搭建结构:
- 一主二仆结构:

- 接力赛结构:

搭建方式很简单,在前文基础上,我们只需要修改 6381 的 master 即可,在 6381 实例上执行如下命令,让 6381 从 6380 实例上复制数据,如下:
127.0.0.1:6381> SLAVEOF 127.0.0.1 6380
OK
此时,我们再看 6379 的 slave,如下:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=0,lag=1
master_replid:4a38bbfa37586c29139b4ca1e04e8a9c88793651
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:0
只有一个 slave,就是 6380,我们再看 6380 的信息,如下:
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:70
slave_priority:100
slave_read_only:1
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=70,lag=0
master_replid:4a38bbfa37586c29139b4ca1e04e8a9c88793651
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:70
6380 此时的角色是一个从机,它的主机是 6379,但是 6380 自己也有一个从机,那就是 6381.此时我们的主从结构如下图:
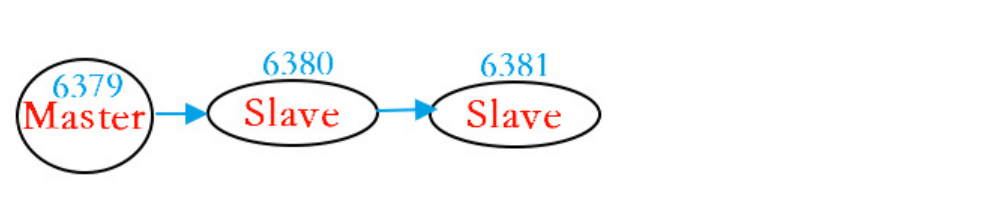
2.5 哨兵模式
我们一共介绍了两种主从模式了,但是这两种,不管是哪一种,都会存在这样一个问题,那就是当主机宕机时,就会发生群龙无首的情况,如果在主机宕机时,能够从从机中选出一个来充当主机,那么就不用我们每次去手动重启主机了,这就涉及到一个新的话题,那就是哨兵模式。
所谓的哨兵模式,其实并不复杂,我们还是在我们前面的基础上来搭建哨兵模式。假设现在我的master 是 6379,两个从机分别是 6380 和 6381,两个从机都是从 6379 上复制数据。先按照上文的步骤,我们配置好一主二仆,然后在 redis 目录下打开 sentinel.conf 文件,做如下配置:
#配置监控的主机
sentinel monitor mymaster 127.0.0.1 6379 1
#主机的访问密码
sentinel auth-pass mymaster 123456
其中 mymaster 是给要监控的主机取的名字,随意取,后面是主机地址,最后面的 2 表示有多少个sentinel 认为主机挂掉了,就进行切换(我这里只有一个,因此设置为1)。好了,配置完成后,输入如下命令启动哨兵:
redis-sentinel sentinel.conf
然后启动我们的一主二仆架构,启动成功后,关闭 master,观察哨兵窗口输出的日志,如下:
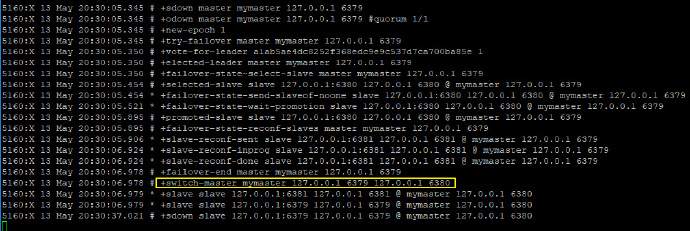
可以看到,6379 挂掉之后,redis 内部重新举行了选举,6380 重新上位。此时,如果 6379重启,也不再是主机角色了,只能屈身做一个 slave 了。
2.6 注意问题
由于所有的写操作都是先在 Master 上操作,然后同步更新到 Slave 上,所以从 Master 同步到 Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave 机器数量的增加也会使这个问题更加严重,因此后续我们还需要集群来进一步提升 redis 性能。
3.Jedis 操作哨兵模式
准备工作:
-
所有的实例均配置 masterauth (在 redis.conf 配置文件中)
-
所有实例均需要配置绑定地址:bind 192.168.91.128
另外,哨兵配置的时候,监控的 master 也不要直接写 127.0.0.1,按如下方式写:
sentinel monitor mymaster 192.168.91.128 6380 1
-
做好准备工作,然后启动三个 redis 实例,同时启动哨兵
public class Sentinel { public static void main(String[] args) { JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(10); config.setMaxWaitMillis(1000); String master = "mymaster"; Set<String> sentinels = new HashSet<>(); sentinels.add("192.168.91.128:26379"); JedisSentinelPool sentinelPool = new JedisSentinelPool(master, sentinels, config, "javaboy"); Jedis jedis = null; while (true) { try { jedis = sentinelPool.getResource(); String k1 = jedis.get("k1"); System.out.println(k1); } catch (Exception e) { e.printStackTrace(); } finally { if (jedis != null) { jedis.close(); } try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } } } } }在Jedis 客户端取值过程中,如果手动停掉一个Redis节点,那我们客户端是会短暂的报错的。等Redis选举完成后,客户端就可以正常的获取值了。
4.Spring Boot 操作哨兵模式
SpringBoot 操作哨兵模式和 Jedis 的前提条件相同,配置相比起来反而更简单。
配置 Redis 连接:
spring:
redis:
password: javaboy
timeout: 5000
sentinel:
master: mymaster
nodes: 192.168.91.128:26379
测试代码:
@SpringBootTest
class SentinelApplicationTests {
@Autowired
StringRedisTemplate redisTemplate;
@Test
void contextLoads() {
while (true) {
try {
String k1 = redisTemplate.opsForValue().get("k1");
System.out.println(k1);
} catch (Exception e) {
} finally {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
Redis 集群
集群原理
Redis 集群架构如下图:

Redis 集群运行原理如下:
- 所有的 Redis 节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的 fail 是通过集群中超过半数的节点检测失效时才生效
- 客户端与 Redis 节点直连,不需要中间 proxy 层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- Redis-cluster 把所有的物理节点映射到 [0-16383]slot 上,cluster (簇)负责维护 node<->slot<->value 。Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个key-value 时,Redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,Redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
怎么样投票
投票过程是集群中所有 master 参与,如果半数以上 master 节点与 master 节点通信超过 cluster-node-timeout 设置的时间,认为当前 master 节点挂掉。
怎么样判定节点不可用
- 如果集群任意 master 挂掉,且当前 master 没有 slave.集群进入 fail 状态,也可以理解成集群的 slot映射 [0-16383] 不完整时进入 fail 状态
- 如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态,当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
集群搭建
在之前上海老东家的时候,那时候用的还是低于 redis 3.x 的版本,搭建集群还需要使用 ruby 环境,redis 5.0后,将 ruby 整合进了redis-cli中,集群搭建进一步简化,下面就带大家搭建一个 三主三从 Redis 集群
-
在指定目录创建 redis-cluster 文件夹,并且将 在此文件夹下解压安装 redis
1. cd /home 2. mkdir redis-cluster 3. cd redis-cluster 4. tar -zxvf redis-6.2.1.tar.gz 5. cd redis-6.2.1 6. make 7. make install -
回到 redis-cluster 目录下,建立集群各个节点的配置文件夹 这里以7001 - 7006 为例子 ,并将刚刚安装好的 redis 中的配置文件拷贝至各个节点文件夹中
1. mkdir 700{1,2,3,4,5,6} 2. cp redis-6.2.1/redis.conf 7001/ cp redis-6.2.1/redis.conf 7002/ cp redis-6.2.1/redis.conf 7003/ cp redis-6.2.1/redis.conf 7004/ cp redis-6.2.1/redis.conf 7005/ cp redis-6.2.1/redis.conf 7006/ -
拷贝完成后修改各个节点文件夹中 redis.conf 配置,修改内容如下
port xxxx(修改为具体节点端口,7001就填7001,7002就填7002) #bind 127.0.0.1 (此处修改为具体节点所在的ip地址) #开启集群及配置对应节点配置文件 cluster-enabled yes cluster-config-file nodes-7001.conf (此处7001也修改为对应端口) #关闭访问保护 后台运行 protected no daemonize yes #开启密码 requirepass 123456 #开启主机授权密码(作为从机连接时使用) masterauth 123456 -
启动各节点 redis 服务
1.redis-server ../7001/redis.conf -h 192.168.0.105 -p 7001 -a 123456 2.redis-server ../7002/redis.conf -h 192.168.0.105 -p 7002 -a 123456 3.redis-server ../7003/redis.conf -h 192.168.0.105 -p 7003 -a 123456 4.redis-server ../7004/redis.conf -h 192.168.0.105 -p 7004 -a 123456 5.redis-server ../7005/redis.conf -h 192.168.0.105 -p 7005 -a 123456 6.redis-server ../7006/redis.conf -h 192.168.0.105 -p 7006 -a 123456 -
创建集群
#建立集群 并且集群副本为1(6个节点 三个主机三个从机) [root@localhost redis-6.2.1]# redis-cli --cluster create 192.168.0.105:7001 192.168.0.105:7002 192.168.0.105:7003 192.168.0.105:7004 192.168.0.105:7005 192.168.0.105:7006 --cluster-replicas 1 -a 123456 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.0.105:7005 to 192.168.0.105:7001 Adding replica 192.168.0.105:7006 to 192.168.0.105:7002 Adding replica 192.168.0.105:7004 to 192.168.0.105:7003 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: 9397d9050fc5db96ad3561c579307fbbdd534aff 192.168.0.105:7001 slots:[0-5460] (5461 slots) master M: 1d84e7ac4fce694d5cdc354cf447209caded41a7 192.168.0.105:7002 slots:[5461-10922] (5462 slots) master M: 32afb011852dc446464a3844aabe6c111f142ca6 192.168.0.105:7003 slots:[10923-16383] (5461 slots) master S: a928fd65a4ed5ca3d13c8af99934f2b105da155a 192.168.0.105:7004 replicates 1d84e7ac4fce694d5cdc354cf447209caded41a7 S: 46e3ccc1eac204d6a5182be65978a5caa7afabaf 192.168.0.105:7005 replicates 32afb011852dc446464a3844aabe6c111f142ca6 S: a8ee7daff2f82b9beb076ba5207012e54319061c 192.168.0.105:7006 replicates 9397d9050fc5db96ad3561c579307fbbdd534aff #是否采用上述配置方案 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join .. >>> Performing Cluster Check (using node 192.168.0.105:7001) M: 9397d9050fc5db96ad3561c579307fbbdd534aff 192.168.0.105:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 32afb011852dc446464a3844aabe6c111f142ca6 192.168.0.105:7003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: a8ee7daff2f82b9beb076ba5207012e54319061c 192.168.0.105:7006 slots: (0 slots) slave replicates 9397d9050fc5db96ad3561c579307fbbdd534aff S: 46e3ccc1eac204d6a5182be65978a5caa7afabaf 192.168.0.105:7005 slots: (0 slots) slave replicates 32afb011852dc446464a3844aabe6c111f142ca6 S: a928fd65a4ed5ca3d13c8af99934f2b105da155a 192.168.0.105:7004 slots: (0 slots) slave replicates 1d84e7ac4fce694d5cdc354cf447209caded41a7 M: 1d84e7ac4fce694d5cdc354cf447209caded41a7 192.168.0.105:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. -
集群创建成功后,测试连接并查看集群信息
root@localhost redis-6.2.1]# redis-cli -a 123456 -h 192.168.0.105 -p 7001 -c Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. #集群状态 OK 192.168.0.105:7001> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:1 cluster_stats_messages_ping_sent:85 cluster_stats_messages_pong_sent:91 cluster_stats_messages_sent:176 cluster_stats_messages_ping_received:86 cluster_stats_messages_pong_received:85 cluster_stats_messages_meet_received:5 cluster_stats_messages_received:176 #集群节点关系 及solt分配 可以看出 7001是当前主机 从机为 7006 192.168.0.105:7001> CLUSTER NODES 32afb011852dc446464a3844aabe6c111f142ca6 192.168.0.105:7003@17003 master - 0 1620025676591 3 connected 10923-16383 a8ee7daff2f82b9beb076ba5207012e54319061c 192.168.0.105:7006@17006 slave 9397d9050fc5db96ad3561c579307fbbdd534aff 0 1620025677000 1 connected 46e3ccc1eac204d6a5182be65978a5caa7afabaf 192.168.0.105:7005@17005 slave 32afb011852dc446464a3844aabe6c111f142ca6 0 1620025678602 3 connected 9397d9050fc5db96ad3561c579307fbbdd534aff 192.168.0.105:7001@17001 myself,master - 0 1620025677000 1 connected 0-5460 a928fd65a4ed5ca3d13c8af99934f2b105da155a 192.168.0.105:7004@17004 slave 1d84e7ac4fce694d5cdc354cf447209caded41a7 0 1620025677000 2 connected 1d84e7ac4fce694d5cdc354cf447209caded41a7 192.168.0.105:7002@17002 master - 0 1620025679608 2 connected 5461-10922
动态扩容增加节点
-
首先我们准备一个增加的节点,可以复制一个已经配置好的节点,替换其中的部分配置信息
1. cd /home/redis-cluster 2. cp -rf 7006 7007 3. vim 7007/redis.conf 4. 替换所有7006为7007 :%s/7006/7007/g #启动 7007 新增加的节点 redis-server ../7007/redis.conf -
将新增节点加入集群
#新增主机节点 7007 redis-cli --cluster add-node 192.168.0.105:7007 192.168.0.105:7001 -a 123456 -
查看集群节点信息,节点增加成功后没有分配槽的,没有分配到 slot 将不能存储数据,此时我们需要手动分配 slot
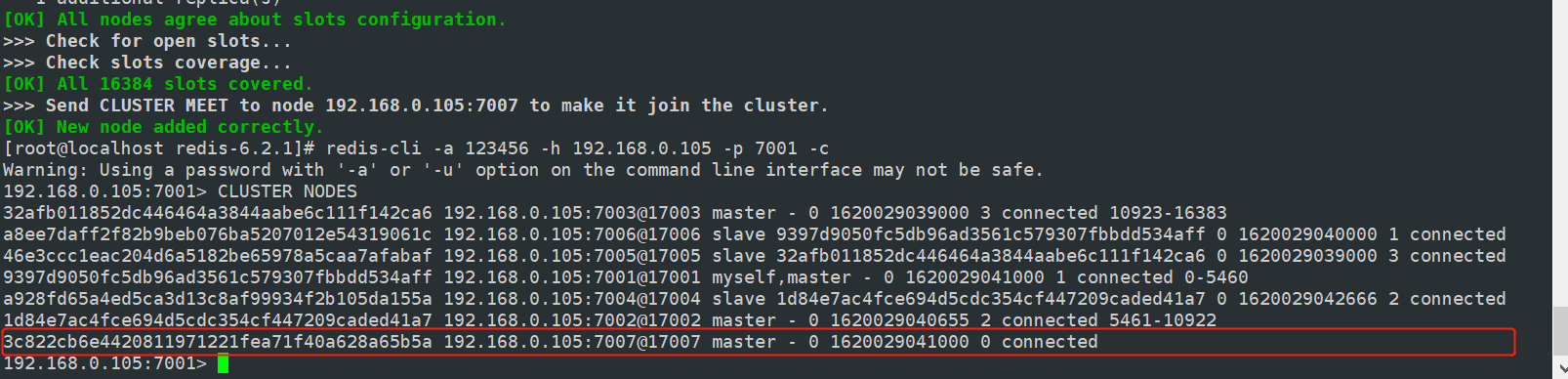
#手动分配槽
redis-cli --cluster reshard 192.168.0.105:7001 --cluster-from 32afb011852dc446464a3844aabe6c111f142ca6,9397d9050fc5db96ad3561c579307fbbdd534aff,1d84e7ac4fce694d5cdc354cf447209caded41a7 --cluster-to 3c822cb6e4420811971221fea71f40a628a65b5a --cluster-slots 4096 -a 123456

- 连接节点查看集群信息,及槽分配信息

-
我们发现我们已经成功的扩容了一个主机节点并且分配了槽,那按照我们之前的我们没有从机,我们如何给主机对应的扩容一个从机呢?
#新增从机机节点 7008 redis-cli --cluster add-node 192.168.0.105:7008 192.168.0.105:7001 --cluster-slave --cluster-master-id 3c822cb6e4420811971221fea71f40a628a65b5a -a 123456
Jedis 操作 RedisCluster
public class RedisCluster {
public static void main(String[] args) {
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.91.128", 7001));
nodes.add(new HostAndPort("192.168.91.128", 7002));
nodes.add(new HostAndPort("192.168.91.128", 7003));
nodes.add(new HostAndPort("192.168.91.128", 7004));
nodes.add(new HostAndPort("192.168.91.128", 7005));
nodes.add(new HostAndPort("192.168.91.128", 7006));
nodes.add(new HostAndPort("192.168.91.128", 7007));
JedisPoolConfig config = new JedisPoolConfig();
//连接池最大空闲数
config.setMaxIdle(300);
//最大连接数
config.setMaxTotal(1000);
//连接最大等待时间,如果是 -1 表示没有限制
config.setMaxWaitMillis(30000);
//在空闲时检查有效性
config.setTestOnBorrow(true);
JedisCluster cluster = new JedisCluster(nodes, 15000, 15000, 5,
"javaboy", config);
String set = cluster.set("k1", "v1");
System.out.println(set);
String k1 = cluster.get("k1");
System.out.println(k1);
}
}
Redis Stream
基本介绍
从 Redis5 开始,推出 Stream 功能。在 Stream 中,有一个消息链表,所有加入链表中的消息都会被串起来。每一条消息都有一个唯一的ID,还有对应的消息内容,所谓的消息内容,就是键值对。
一个 Stream 上可以有多个消费者,每一个消费者都有一个游标,这个游标根据消息的消费情况在链表上移动。多个消费者之间互相独立、互不影响。
基本命令
-
xadd 添加消息
#xadd key id string string * 代表服务器自动生成的ID; loadsysonfig、writemessage 任务名 dosomething 内容 192.168.0.105:7001> xadd job * loadsysonfig dosomething writemessage dosomething "1620035197992-0" -
xdel 删除消息
192.168.0.105:7001> xdel job 1620035197992-0 (integer) 1 -
xlen 消息个数
192.168.0.105:7001> XLEN job (integer) 1 -
xrange 获取消息列表
#返回所有消息 XRANGE job - + -
del 删除Stream
del job
消息消费
-
xread 读取消息
#从头部开始读取 xread count 1 streams job 0-0 #从尾部开始读取 xread count 1 streams job $
关于Stream消息消费 其实还有很多知识,通常我们会建立一个消费组,从消费组中消费消息。也可以把消息队列设计为阻塞队列,设置一个阻塞时长。这里给大家介绍的目的主要是让大家知道有这么个新特性,比如出去面试,提到这个自己知道不会让面试管觉得自己的知识面很狭窄。对于消息的处理,在不考虑复杂性的前提下,我们通常会采用专业的消息中间件处理。
Redis 过期策略
Redis 中所有的 key 都可以设置过期时间。Redis是把每一个设置过期时间的 key 放到一个独立的数据字典中,定时遍历这个字典来删除到期的 key。除了定时删除以外,还会使用一些惰性策略,客户端访问这个key 的时候,检查这个 key 的过期

 浙公网安备 33010602011771号
浙公网安备 33010602011771号