
Sharding-JDBC的使用及原理
一、基本使用
pom(基于5.2.0)
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core</artifactId> <version>5.2.0</version> </dependency>
基本配置
private static DataSource ds0 = DataSourceUtil.createDataSource("127.0.0.1", "root", "123456", "test_split1"); private static final String GENERAL_DATABASE_HIT = "GENERAL-DATABASE-HIT"; private static final String GENERAL_TABLE_HIT = "GENERAL-TABLE-HIT"; public static void main(String[] args) throws SQLException { Map<String, DataSource> map = new HashMap<>(); map.put("ds0",ds0); ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); shardingRuleConfig.getShardingAlgorithms().put(GENERAL_DATABASE_HIT,new AlgorithmConfiguration(GENERAL_DATABASE_HIT,null)); shardingRuleConfig.getShardingAlgorithms().put(GENERAL_TABLE_HIT,new AlgorithmConfiguration(GENERAL_TABLE_HIT,null)); shardingRuleConfig.setDefaultDatabaseShardingStrategy(new HintShardingStrategyConfiguration(GENERAL_DATABASE_HIT)); // TODO 增加规则 ShardingTableRuleConfiguration jlDailyData = new ShardingTableRuleConfiguration("jl_daily_data", "ds$->{0..0}.jl_daily_data_$->{2021..2022}"); jlAdvertiserDailyData.setTableShardingStrategy(new HintShardingStrategyConfiguration(GENERAL_TABLE_HIT)); // 配置分片规则 shardingRuleConfig.getTables().add(jlDailyData); // 上下文 HintManager hintManager = HintManager.getInstance(); hintManager.addTableShardingValue("jl_daily_data", "2022"); Properties properties = new Properties(); properties.setProperty(ConfigurationPropertyKey.KERNEL_EXECUTOR_SIZE.getKey(), String.valueOf(10)); // 获取数据源对象 DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(map, Collections.singleton(shardingRuleConfig), properties); Connection connection = dataSource.getConnection(); Statement statement = connection.createStatement(); long start =System.currentTimeMillis(); statement.execute("SELECT cost, `click` , `show`, concat( `ctr`,'%') as ctr ,concat(convert(ctr,decimal(12,2)),'%') ctr1 FROM `jl_daily_data` where cost>0"); System.out.println((System.currentTimeMillis()-start)/1000); ResultSet resultSet = statement.getResultSet(); while (resultSet.next()) { //log.info("ss:{},{},{},{}", resultSet.getString("advertiserId"),resultSet.getString("cost1"),resultSet.getString("avgShowCost"), resultSet.getString("avgShowCost")); log.info("ss:{}", resultSet.getString("cost")); } }
1.1 ShardingRuleConfiguration 参数详解
public final class ShardingRuleConfiguration implements DatabaseRuleConfiguration, DistributedRuleConfiguration { // 分表规则 private Collection<ShardingTableRuleConfiguration> tables = new LinkedList(); // 自动分表 (5.0 新增特性,只给分片数,不管分片策略) private Collection<ShardingAutoTableRuleConfiguration> autoTables = new LinkedList(); // 绑定表 private Collection<String> bindingTableGroups = new LinkedList(); // 广播表 private Collection<String> broadcastTables = new LinkedList(); private ShardingStrategyConfiguration defaultDatabaseShardingStrategy; private ShardingStrategyConfiguration defaultTableShardingStrategy; private KeyGenerateStrategyConfiguration defaultKeyGenerateStrategy; private ShardingAuditStrategyConfiguration defaultAuditStrategy; private String defaultShardingColumn; // 分片策略 private Map<String, AlgorithmConfiguration> shardingAlgorithms = new LinkedHashMap(); // id策略 private Map<String, AlgorithmConfiguration> keyGenerators = new LinkedHashMap(); // 自动分片策略 private Map<String, AlgorithmConfiguration> auditors = new LinkedHashMap(); public ShardingRuleConfiguration() { } }
1.2 AlgorithmConfiguration 策略

ShardingAlgorithm (分片策略)
主要有 混合策略,上行文命中策略,表达式分片策略。
如果需要新增自定义策略,需要在resouce/META-INF/services/
新增文件 :
- 文件名:spi加载策略接口的类路径。
- 文件内存: 具体实现类的类路径。
二、原理
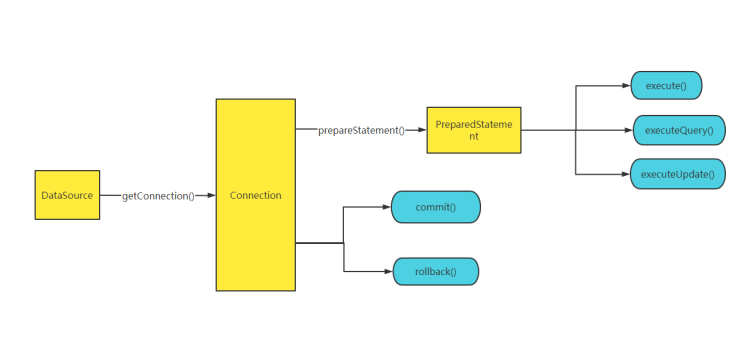
通俗来说:sharding-jdbc 是定位在jdbc层的代理框架。
主要通过ShardingSphereDataSourceFactory,生成静态代理ShardingDataSource;
在ShardingDataSource#getConnection ,生成静态代理ShardingSphereConnection;
在ShardingSphereConnection#prepareStatement,生成静态代理ShardingSpherePreparedStatement;
最终在ShardingSpherePreparedStatement#execute,完成真正的数据库创建连接,分库分表笛卡尔乘积,改写sql,合并结果集。
ShardingSpherePreparedStatement##execute()
@Override public boolean execute() throws SQLException { try { if (statementsCacheable && !statements.isEmpty()) { resetParameters(); return statements.iterator().next().execute(); } clearPrevious(); // 解析sql, QueryContext queryContext = createQueryContext(); trafficInstanceId = getInstanceIdAndSet(queryContext).orElse(null); if (null != trafficInstanceId) { JDBCExecutionUnit executionUnit = createTrafficExecutionUnit(trafficInstanceId, queryContext); return executor.getTrafficExecutor().execute(executionUnit, (statement, sql) -> ((PreparedStatement) statement).execute()); } deciderContext = decide(queryContext, metaDataContexts.getMetaData().getProps(), metaDataContexts.getMetaData().getDatabase(connection.getDatabaseName())); if (deciderContext.isUseSQLFederation()) { ResultSet resultSet = executeFederationQuery(queryContext); return null != resultSet; } // sql 路由,改写sql executionContext = createExecutionContext(queryContext); if (hasRawExecutionRule()) { // TODO process getStatement Collection<ExecuteResult> executeResults = executor.getRawExecutor().execute(createRawExecutionGroupContext(), executionContext.getQueryContext(), new RawSQLExecutorCallback(eventBusContext)); return executeResults.iterator().next() instanceof QueryResult; } ExecutionGroupContext<JDBCExecutionUnit> executionGroupContext = createExecutionGroupContext(); cacheStatements(executionGroupContext.getInputGroups()); // 执行sql return executor.getRegularExecutor().execute(executionGroupContext, executionContext.getQueryContext(), executionContext.getRouteContext().getRouteUnits(), createExecuteCallback()); } catch (SQLException ex) { handleExceptionInTransaction(connection, metaDataContexts); throw ex; } finally { clearBatch(); } }
@Override public ResultSet getResultSet() throws SQLException { if (null != currentResultSet) { return currentResultSet; } if (null != trafficInstanceId) { return executor.getTrafficExecutor().getResultSet(); } if (null != deciderContext && deciderContext.isUseSQLFederation()) { return executor.getFederationExecutor().getResultSet(); } if (executionContext.getSqlStatementContext() instanceof SelectStatementContext || executionContext.getSqlStatementContext().getSqlStatement() instanceof DALStatement) { List<ResultSet> resultSets = getResultSets(); // 合并结果集 MergedResult mergedResult = mergeQuery(getQueryResults(resultSets)); currentResultSet = new ShardingSphereResultSet(resultSets, mergedResult, this, executionContext); } return currentResultSet; }
2.1 生成路由
ShardingSpherePreparedStatement#createExecutionContext,有兴趣自看源码。
主要逻辑:
根据当前sql中的表,字段,匹配到的库,表,做笛卡尔乘积,生成相应个数的执行计划(每个执行计划,指向具体的库名,表名)。
遍历执行计划,对每个执行计划中的原始sql,进行替换,改写。
示例:
改写为: select * from jl_daily_data_2020, 数据对应d0库。
分页查询的优化:
select * from jl_daily_data limit 100,10
会被改写为 select * from jl_daily_data limit 110,会将所有的数据都查询出来,多余的数据会在代码中被舍弃。(使用sharding-jdbc 做深翻页时,查询的条数会非常大,影响性能。考虑,深度翻页,增加条件查询,减少查询的条数)
2.2 执行查询
遍历执行计划,将每个执行计划执行得到的 ResultSet,包裹为QueryResult(简称数据分片),并缓存在List<QueryResult>中。并将List<QueryResult> 封装在ShardingResultSet (内部包含不同逻辑的MergedResult)中,通过代理next()方法,根据相应的规则取分片的数据。
对执行的优化:
- 如果只有一个执行计划,会同步执行。
- 如果有两个及以上的执行计划,第一个会同步执行,后面的会在线程池中并发执行。
2.3 合并结果集
合并结果不支持having,多重聚合(即集合函数中,还有其他函数)。
2.3.1 简单sql
不包含,group by order by 的sql。
顺序取每个分片数据。
2.3.2 order by,gorup by
情况1:在只有order by 的情况下;
在此情况,会将List<QueryResult> ,每个QueryResult 的第一行数据做比较,放入OrderByStreamMergedResult(内部基于 最大堆/最小堆),依次取数。
情况2:group by 和order by的字段相同时,如果sql中只有group by,会在改写sql阶段在 sql 末尾加上 相同字段的 order by;
在此情况,会将List<QueryResult> ,每个QueryResult 的第一行数据做比较,放入GroupByStreamMergedResult(内部包含了OrderByStreamMergedResult),每次next(),都会遍历所有数据分片,目的是为聚合函数。
情况3:group by 和order by的字段不相同时;
在此情况,会将List<QueryResult>, 所有数据封装在GroupByMemoryMergedResult中,在内存中计算聚合后再排序(List.sort 快排,归并)(数据较多时,考虑性能问题)。
2.3.3 limit
在当前所有的数据分片,跳过偏移的行数。(在内存中模拟Mysql 查询limit n,m 舍弃前n行过程)。
参考
https://shardingsphere.apache.org/document/legacy/4.x/document/en/manual/sharding-jdbc/
https://shardingsphere.apache.org/document/legacy/3.x/document/cn/overview/
(文档都是3.x 4.x 版本的, 目前最版是5.2.0)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号