
MySQL学习(七)---->事务和锁
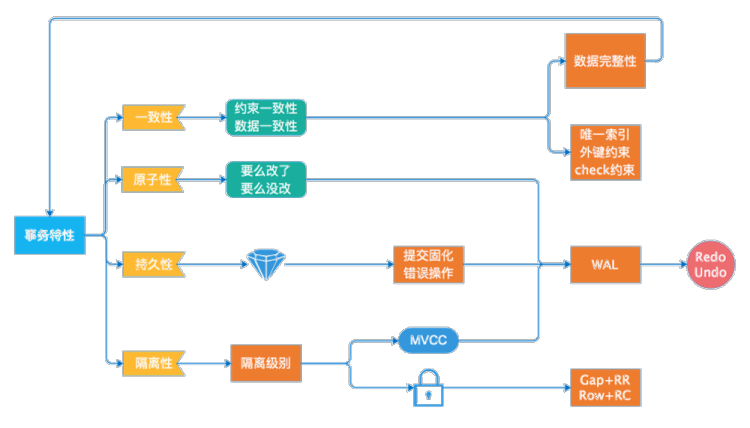
事务特性(ACID):
一个逻辑工作单元要成为事务,在关系型数据库管理系统中,必须满足 4 个特性,即所谓的 ACID:原子性、一致性、隔离性和持久性。
一致性:事务开始之前和事务结束之后,数据库的完整性限制未被破坏。
原子性:事务的所有操作,要么全部完成,要么全部不完成,不会结束在某个中间环节。
持久性:事务完成之后,事务所做的修改进行持久化保存,不会丢失。
隔离性:当多个事务并发访问数据库中的同一数据时,所表现出来的相互关系。
ACID 及它们之间的关系如下图所示,比如 4 个特性中有 3 个与 WAL 有关系,都需要通过 Redo、Undo 日志来保证等。
一致性
首先来看一致性,一致性其实包括两部分内容,分别是约束一致性和数据一致性。
- 约束一致性:大家应该很容易想到数据库中创建表结构时所指定的外键、Check、唯一索引等约束。可惜在 MySQL 中,是不支持 Check 的,只支持另外两种,所以约束一致性就非常容易理解了。
- 数据一致性:是一个综合性的规定,或者说是一个把握全局的规定。因为它是由原子性、持久性、隔离性共同保证的结果,而不是单单依赖于某一种技术。
原子性
接下来看原子性,原子性就是前面提到的两个“要么”,即要么改了,要么没改。也就是说用户感受不到一个正在改的状态。MySQL 是通过 WAL(Write Ahead Log)技术来实现这种效果的。
可能你想问,原子性和 WAL 到底有什么关系呢?其实关系非常大。举例来讲,如果事务提交了,那改了的数据就生效了,如果此时 Buffer Pool 的脏页没有刷盘,如何来保证改了的数据生效呢?就需要使用 Redo 日志恢复出来的数据。而如果事务没有提交,且 Buffer Pool 的脏页被刷盘了,那这个本不应该存在的数据如何消失呢?就需要通过 Undo 来实现了,Undo 又是通过 Redo 来保证的,所以最终原子性的保证还是靠 Redo 的 WAL 机制实现的。
持久性
再来看持久性。所谓持久性,就是指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,接下来的操作或故障不应该对其有任何影响。前面已经讲到,事务的原子性可以保证一个事务要么全执行,要么全不执行的特性,这可以从逻辑上保证用户看不到中间的状态。但持久性是如何保证的呢?一旦事务提交,通过原子性,即便是遇到宕机,也可以从逻辑上将数据找回来后再次写入物理存储空间,这样就从逻辑和物理两个方面保证了数据不会丢失,即保证了数据库的持久性。
隔离性
最后看下隔离性。所谓隔离性,指的是一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对其他的并发事务是隔离的。锁和多版本控制就符合隔离性。
WAL
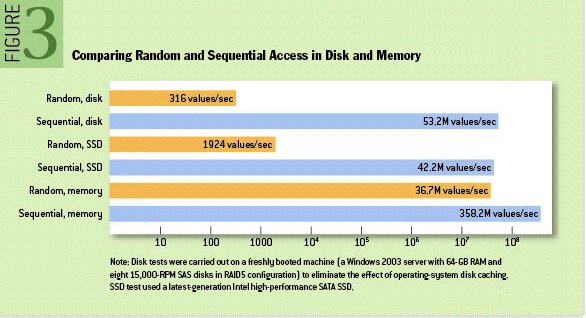
从上图可以看出两点:
- 内存的读写速度比磁盘读写高出几个数量级。
- 顺序读写比随机读写高很多
WAL原理
- 通过cache合并多条写操作为一条,减少IO次数
- 日志顺序追加性能远高于数据随机写.
- 随机内存处理性能远高于数据随机处理.
原子性背后的技术
先来看看原子性,每一个写事务,都会修改 Buffer Pool,从而产生相应的 Redo 日志,这些日志信息会被记录到 ib_logfiles 文件中。因为 Redo 日志是遵循 Write Ahead Log 的方式写的,所以事务是顺序被记录的。
在 MySQL 中,任何 Buffer Pool 中的页被刷到磁盘之前,都会先写入到日志文件中,这样做有两方面的保证。
- 如果 Buffer Pool 中的这个页没有刷成功,此时数据库挂了,那在数据库再次启动之后,可以通过 Redo 日志将其恢复出来,以保证脏页写下去的数据不会丢失,所以必须要保证 Redo 先写。
- 因为 Buffer Pool 的空间是有限的,要载入新页时,需要从 LRU 链表中淘汰一些页,而这些页必须要刷盘之后,才可以重新使用,那这时的刷盘,就需要保证对应的 LSN 的日志也要提前写到 ib_logfiles 中,如果没有写的话,恰巧这个事务又没有提交,数据库挂了,在数据库启动之后,这个事务就没法回滚了。所以如果不写日志的话,这些数据对应的回滚日志可能就不存在,导致未提交的事务回滚不了,从而不能保证原子性,所以原子性就是通过 WAL 来保证的。
持久性背后的技术
再来看持久性,如下图所示,一个“提交”动作触发的操作有:binlog 落地、发送 binlog、存储引擎提交、flush_logs, check_point、事务提交标记等。这些都是数据库保证其数据完整性、持久性的手段。
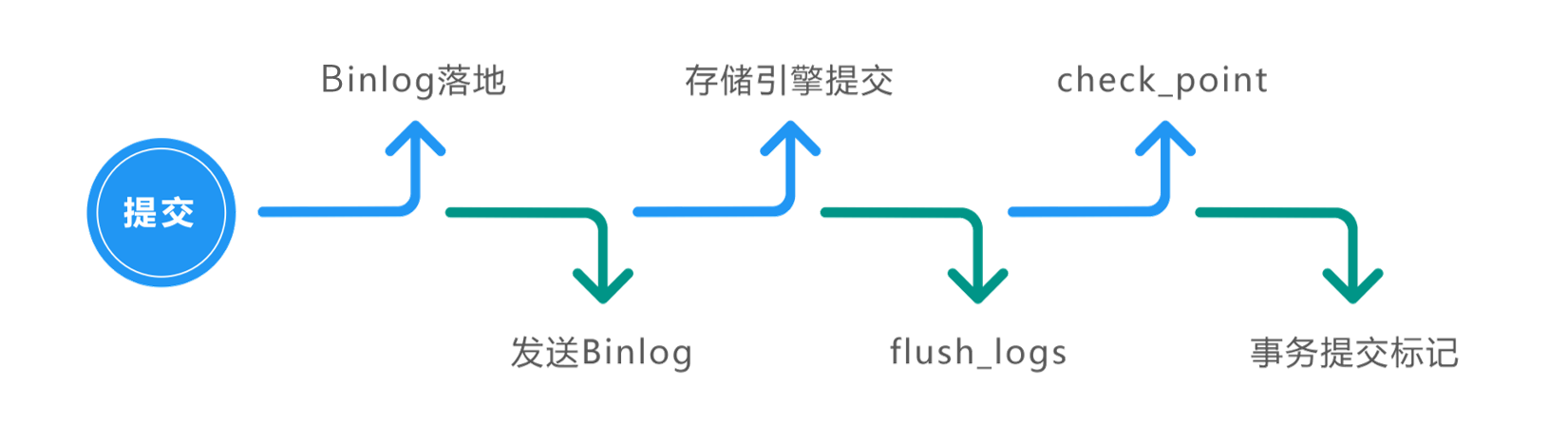
那这些操作如何做到持久性呢?前面讲过,通过原子性可以保证逻辑上的持久性,通过存储引擎的数据刷盘可以保证物理上的持久性。这个过程与前面提到的 Redo 日志、事务状态、数据库恢复、参数 innodb_flush_log_at_trx_commit 有关,还与 binlog 有关。这里多提一句,在数据库恢复时,如果发现某事务的状态为 Prepare,则会在 binlog 中找到对应的事务并将其在数据库中重新执行一遍,来保证数据库的持久性。
隔离性背后的技术
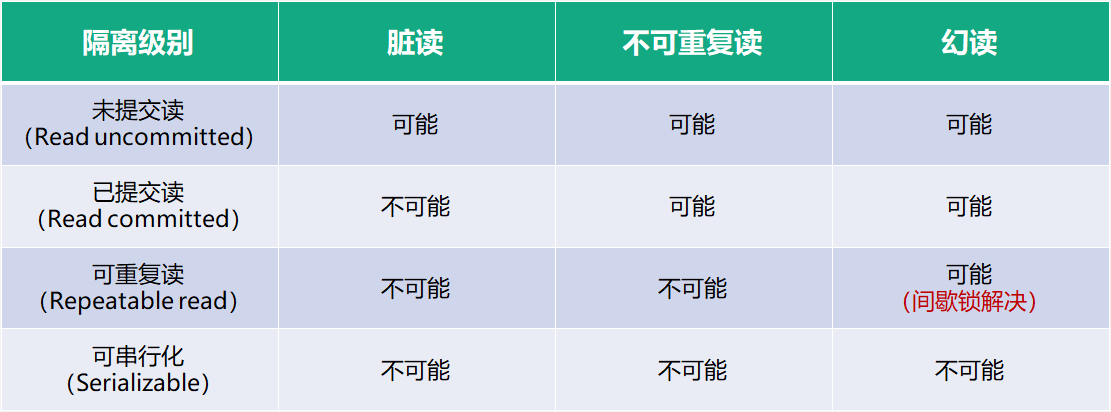
接下来看隔离性,InnoDB 支持的隔离性有 4 种,隔离性从低到高分别为:读未提交、读提交、可重复读、可串行化。
读未提交(RU,Read Uncommitted : 它能读到一个事务的中间过程,违背了 ACID 特性,存在脏读的问题,所以基本不会用到,可以忽略。
读提交(RC,Read Committed): 它表示如果其他事务已经提交,那么我们就可以看到,这也是一种最普遍适用的级别。但由于一些历史原因,可能 RC 在生产环境中用的并不多。
可重复读(RR,Repeatable Read): 是目前被使用得最多的一种级别。其特点是有 Gap 锁、目前还是默认的级别、在这种级别下会经常发生死锁、低并发等问题。
可串行化 : 这种实现方式,其实已经并不是多版本了,又回到了单版本的状态,因为它所有的实现都是通过锁来实现的。
MVCC 实现原理
MySQL InnoDB 存储引擎,实现的是基于多版本的并发控制协议——MVCC,而不是基于锁的并发控制。
MVCC 最大的好处是读不加锁,读写不冲突。在读多写少的 OLTP(On-Line Transaction Processing)应用中,读写不冲突是非常重要的,极大的提高了系统的并发性能,这也是为什么现阶段几乎所有的 RDBMS(Relational Database Management System),都支持 MVCC 的原因。
快照读与当前读
在 MVCC 并发控制中,读操作可以分为两类: 快照读(Snapshot Read)与当前读 (Current Read)。
快照读:读取的是记录的可见版本(有可能是历史版本),不用加锁。
当前读:读取的是记录的最新版本,并且当前读返回的记录,都会加锁,保证其他事务不会再并发修改这条记录。
注意:MVCC 只在 Read Commited 和 Repeatable Read 两种隔离级别下工作。
如何区分快照读和当前读呢? 可以简单的理解为:
快照读:简单的 select 操作,属于快照读,不需要加锁。 (特殊的select ... lock in share mode/for update)
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
并发事务问题及解决方案
上文讲述了 MVCC 的原理及其实现。那么随着数据库并发事务处理能力的大大增强,数据库资源的利用率也会大大提高,从而提高了数据库系统的事务吞吐量,可以支持更多的用户并发访问。但并发事务处理也会带来一些问题,如:脏读、不可重复读、幻读。下面一一解释其含义。
脏读
一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象的叫作"脏读"(Dirty Reads)。
不可重复读
一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫作“ 不可重复读”(Non-Repeatable Reads)。
幻读
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”(Phantom Reads)。
解决方案
产生的这些问题,MySQL 数据库是通过事务隔离级别来解决的,这里再进行简单的说明。
在上文讲 MySQL 事务特性的隔离性的时候就已经详细地讲解了事务的四种隔离级别。这里要求大家能够记住这种关系的矩阵表;记住各种事务隔离级别及各自都解决了什么问题,如下图所示。
mysql的文件体系:
该层负责将数据库的数据和日志存储在文件系统之上,并完成与存储引擎的交互,是文件的物理存储层。主要包含日志文件,数据文件,配置文件,pid 文件,socket文件等。
- 日志文件
- 错误日志(Error log )
默认开启,show variables like '%log_error%'。
- 通用查询日志(General query log )
记录一般查询语句,show variables like '%ogeneral%;
- 二进制日志( binary log )
记录了对MySQL数据库执行的更改操作,并且记录了语句的发生时间、执行时长;但是它不记录select.show 等不修改数据库的sql。主要用于数据库恢复和主从复制。
show variables like '%log_bin%; 是否开启
show variables like '%binlog%'; 参数查看
show binary logs; 查看日志文件
- 慢查询日志(Slow query log )
记录所有执行时间超时的查询sql,默认是10秒。
show variables like '%slow_query%";是否开启
show variables like '%long_query_time%';//时长
- 配置文件
用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等。
- 数据文件
- db.opt 文件:记录这个库的默认使用的字符集和校验规则。
- frm文件:存储与表相关的元数据( meta )信息,包括表结构的定义信息等,每一张表都会有一个frm文件。
- MYD文件:MyISAM存储引擎专用,存放MyISAM表的数据( data),每一张表都会有一个.MYD文件。
- MYI文件:MylSAM存储引擎专用,存放MyISAM表的索引相关信息,每一张MyISAM表对应一个.MYI文件。
- ibd文件和IBDATA文件∶存放InnoDB的数据文件(包括索引)。InnoDB存储引擎有两种表空间方式:独享表空间和共享表空间。独享表空间使用.ibd文件来存放数据,且每一张 InnoDB表对应一个.ibd文件。共享表空间使用.ibdata文件,所有表共同使用一个(或多个,自行配置) .ibdata文件。
- ibdata1文件:系统表空间数据文件,存储表元数据、Undo日志等。
- ib_logfileo、ib_logfile1文件:Redo log日志文件。
- pid文件
pid 文件是mysqld应用程序在Unix/Linux环境下的一个进程文件,和许多其他Unix/Linux服务端程序一样,它存放着自己的进程id。
- socket文件
socket文件也是在Unix/Linux环境下才有的,用户在Unix/Linux环境下客户端连接可以不通过TCP/IP网络而直接使用Unix Socket来连接MySQL。
undo
Undo Log介绍
- Undo :意为撤销或取消,以撤销操作为目的,返回指定某个状态的操作。
- Undo Log :数据库事务开始之前,会将要修改的记录存放到Undo日志里,当事务回滚时或者数据库崩溃时,可以利用Undo日志,撤销未提交事务对数据库产生的影响。
- Undo Log产生和销毁:Undo Log在事务开始前产生;事务在提交时,并不会立刻删除undo log , innodb会将该事务对应的undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理。Undo Log属于逻辑日志,记录一个变化过程。例如执行一个delete , undolog会记录一个insert ;执行一个update,undolog会记录一个相反的update。
- Undo Log存储 : undo log采用段的方式管理和记录。在innodb数据文件中包含一种rollback segment回滚段,内部包含1024个undo log segment。可以通过下面一组参数来控制Undo log存储。
show variables like '%innodb_undo%;
Undo Log作用
- 实现事务的原子性
Undo Log是为了实现事务的原子性而出现的产物。事务处理过程中,如果出现了错误或者用户执行了ROLLBACK语句,MySQL可以利用Undo Log 中的备份将数据恢复到事务开始之前的状态。
- 实现多版本并发控制(MVCC )
Undo Log在MysQL InnoDB存储引擎中用来实现多版本并发控制。事务未提交之前,Undo Log保存了未提交之前的版本数据,Undo Log 中的数据可作为数据旧版本快照供其他并发事务进行快照读。
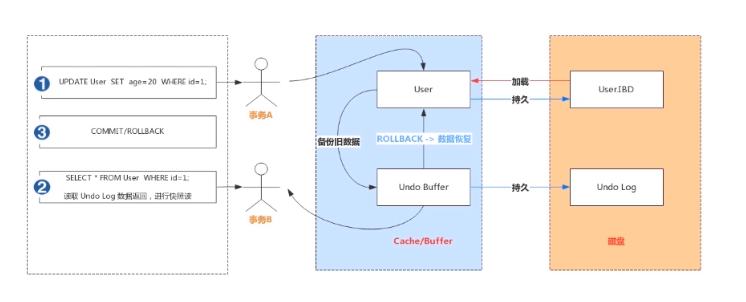
redo
Redo Log介绍
Redo:顾名思义就是重做。以恢复操作为目的,在数据库发生意外时重现操作。
Redo Log:指事务中修改的任何数据,将最新的数据备份存储的位置( Redo Log ),被称为重做日志。Redo Log的生成和释放∶随着事务操作的执行,就会生成Redo Log,在事务提交时会将产生Redo Log写入Log Buffer,并不是随着事务的提交就立刻写入磁盘文件。等事务操作的脏页写入到磁盘之后,Redo Log的使命也就完成了,Redo Log占用的空间就可以重用(被覆盖写入)。
Redo Log工作原理
Redo Log是为了实现事务的持久性而出现的产物。防止在发生故障的时间点,尚有脏页未写入表的IBD文件中,在重启MysQL服务的时候,根据Redo Log进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。(减少IO,顺序写入)
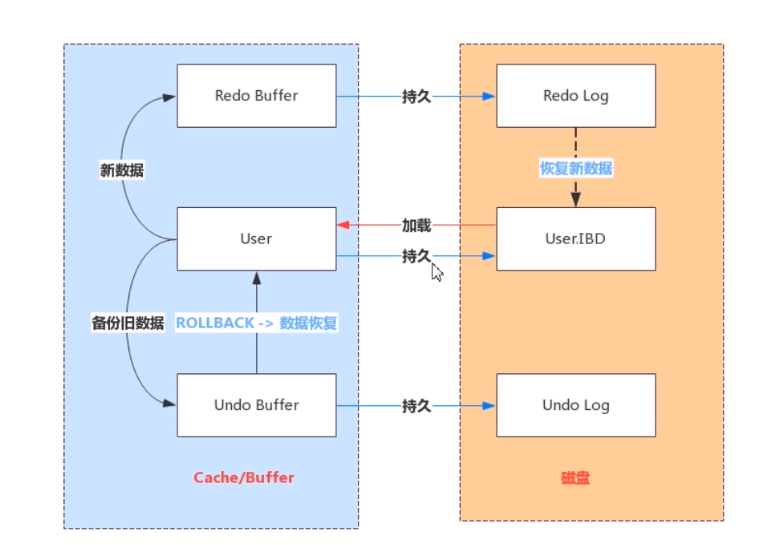
Redo Log写入机制
Redo Log文件内容是以顺序循环的方式写入文件,写满时则回溯到第一个文件,进行覆盖写。
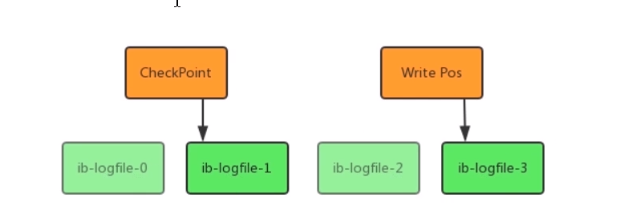
如图所示:
- write pos:是当前记录的位置,一边写一边后移,写到最后一个文件末尾后就回到0号文件开头;
- checkpoint:是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
write pos和checkpoint之间还空着的部分,可以用来记录新的操作。如果write pos追上checkpoint ,表示写满,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint推进一下。
Redo Log相关配置参数
每个InnoDB存储引擎至少有1个重做日志文件组( group ),每个文件组至少有2个重做日志文件,默认为ib_logfile0和ib_logfile1。可以通过下面一组参数控制Redo Log存储︰
show variab1es 1ike '%innodb_log%';
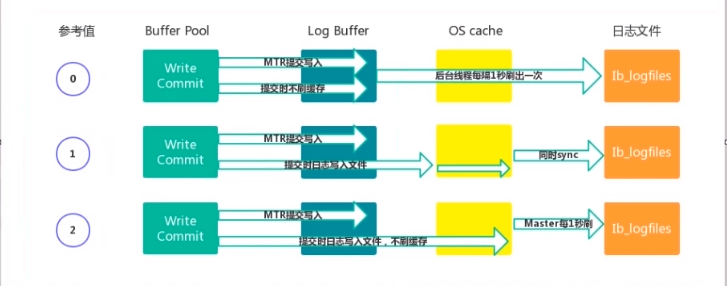
Redo Buffer持久化到Redo Log的策略,可通过innodb_flush_log_at_trx_commit 设置:
- 0 每秒提交Redo buffer ->os cache -> flush cache to disk,可能丢失一秒内的事务数据。由后台
Master线程每隔1秒执行一次操作。
- 1(默认值):每次事务提交执行Redo Buffer -> os cache -> flush cache to disk,最安全,性能最差的方式。
- 2 每次事务提交执行Redo Buffer -> OS cache,然后由后台Master线程再每隔1秒执行OS cache ->flush cache to disk 的操作。
一般建议选择取值2,因为MySQL挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数据。
binlog
Binlog记录模式
Redo Log是属于InnoDB引擎所特有的日志,而MysQL Server也有自己的日志,即Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
- 主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
- 数据恢复︰通过mysqlbinlog工具来恢复数据。
Binlog文件名默认为"主机名_binlog-序列号"格式,例如oak_binlog-000001,也可以在配置文件中指定名称。文件记录模式有STATEMENT、ROW和MIXED三种,具体含义如下。
- Row ( row-based replication,RBR )∶日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
优点︰能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。
缺点 : 批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。
- STATMENT ( statement-based replication, SBR ) :每一条被修改数据的SQL都会记录到master的
Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。
优点∶日志量小,减少磁盘IO,提升存储和恢复速度
缺点︰在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。
- MIXED ( mixed-based replication, MBR )∶以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog ,MySQL会根据执行的SQL语句选择写入模式。
Binlog文件结构
MySQL的binlog文件中记录的是对数据库的各种修改操作,用来表示修改操作的数据结构是Log event。不同的修改操作对应的不同的log event。比较常用的log event有 : Query event、Row event、Xid event等。binlog文件的内容就是各种Log event的集合。
Binlog文件中Log event结构如下图所示∶
Binlog写入机制
- 根据记录模式和操作触发event事件生成log event (事件触发执行机制)。
- 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区
Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache ,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
- 事务在提交阶段会将产生的log event写入到外部binlog文件中。
不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在binlog文件中是连续的,中间不会插入其他事务的log event。binlog是引擎插件上层的功能,事务提交第一个就会调用binlog功能接口,然后再调用其他存储引擎的功能接口。因此先写binlog,然后再执行innodb的redolog/undo和脏页刷新操作

Binlog写入机制
- 根据记录模式和操作触发event事件生成log event (事件触发执行机制)。
- 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区
Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache ,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
- 事务在提交阶段会将产生的log event写入到外部binlog文件中。
不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在binlog文件中是连续的,中间不会插入其他事务的log event。binlog是引擎插件上层的功能,事务提交第一个就会调用binlog功能接口,然后再调用其他存储引擎的功能接口。因此先写binlog,然后再执行innodb的redolog/undo和脏页刷新操作
Binlog状态查看
show variables like '%log_bin%';
- 开启Binlog功能
set GLOBAL log_bin=mysqllogbin;
- 使用show binlog events命令
show binary logs ; //等价于show master logs ; show master status; show binlog events; show binlog events in 'binlog.000460'
- 使用mysqlbinlog命令
mysq1binlog "文件名" mysqlbin1og "文件名" > "test.sql"
- 使用binlog 恢复数据
/按指定时间恢复 mysqlbinlog --start-datetime="2021-01-01 18:00:00" --stop-datetime="2021-01-02 00:00:00" binlog.000460 | mysql -uroot -p /按事件位置号恢复 mysqlbinlog --start-position=555 --stop-position=1487 binlog.000463 | mysql -uroot -p123456
备注:mysqldump∶定期全部备份数据库数据。mysqlbinlog可以做增量备份和恢复操作。
- 删除Binlog文件
purge binary logs to 'binlog.000460'; //删除制定文件 purge binary logs before '2021-01-02 00:00:00' ; //删除指定时间前 reset master; //清除所以文件 show VARIABLES like '%expire_logs_days%'; //可通过设置自动清理文件 0表示不启用
- Redo Log和BinLog区别
- Redo Log是属于InnoDB引擎功能,Binlog是属于MySQL Server自带功能,并且是以二进制文件记录。
- Redo Log属于物理日志,记录该数据页更新状态内容,Binlog是逻辑日志,记录更新过程。
- Redo Log日志是循环写,日志空间大小是固定,Binlog是追加写入,写完一个写下一个,不会覆盖使用
- Redo Log作为服务器异常宕机后事务数据自动恢复使用,Binlog可以作为主从复制和数据恢复使用。Binlog没有自动crash-safe的能力。
如何设置事务的隔离级别
我们可以通过下边的语句修改事务的隔离级别:
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level; ## GLOBAL ##查看当前数据库的事务隔离级别 SHOW VARIABLES LIKE 'transaction_isolation'; ##存在不同版本变量名不同的问题 SHOW VARIABLES LIKE '%isolation'; select @@tx_isolation; select @@transaction_isolation; ##设置read uncommitted级别: set session transaction isolation level read uncommitted; ##设置read committed级别: set session transaction isolation level read committed; ##设置repeatable read级别: set session transaction isolation level repeatable read; ##设置serializable级别: set session transaction isolation level serializable;
MYSQL中的锁
MySQL 锁分类
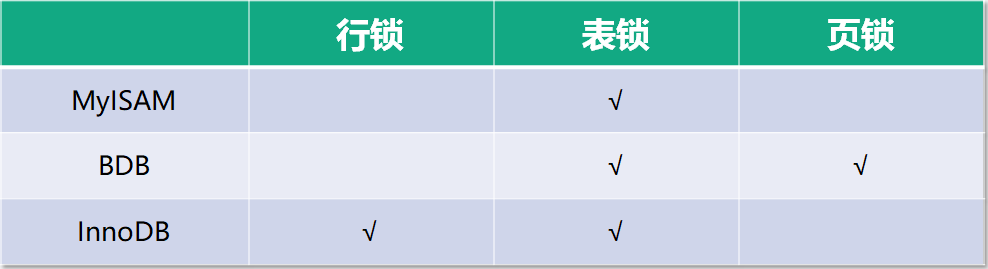
在 MySQL 中有三种级别的锁:页级锁、表级锁、行级锁。
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。 会发生在:MyISAM、memory、InnoDB、BDB 等存储引擎中。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。会发生在:InnoDB 存储引擎。
- 页级锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。会发生在:BDB 存储引擎。
InnoDB 中的锁
在 MySQL InnoDB 存储引擎中,锁分为行锁和表锁。其中行锁包括两种锁。
- 共享锁(S):多个事务可以一起读,共享锁之间不互斥,共享锁会阻塞排它锁。
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
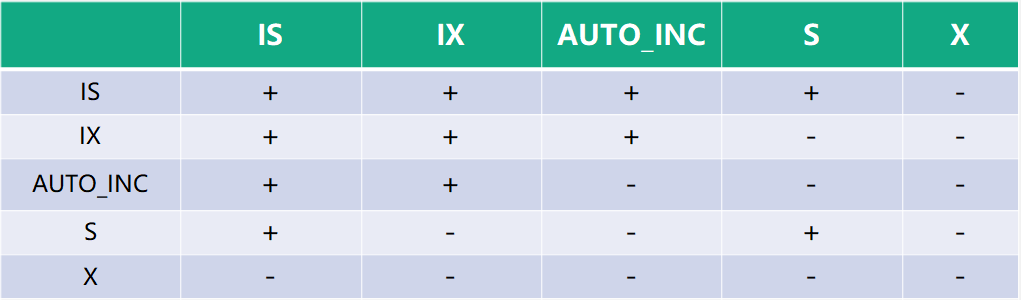
另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB 还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。表锁又分为三种。
- 意向共享锁(IS):事务计划给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
- 自增锁(AUTO-INC Locks):特殊表锁,自增长计数器通过该“锁”来获得子增长计数器最大的计数值。
在加行锁之前必须先获得表级意向锁,否则等待 innodb_lock_wait_timeout 超时后根据innodb_rollback_on_timeout 决定是否回滚事务。
InnoDB 锁关系矩阵如下图所示,其中:+ 表示兼容,- 表示不兼容
InnoDB 行锁
InnoDB 行锁是通过对索引数据页上的记录(record)加锁实现的。主要实现算法有 3 种:Record Lock、Gap Lock 和 Next-key Lock。
- Record Lock 锁:单个行记录的锁(锁数据,不锁 Gap)。
- Gap Lock 锁:间隙锁,锁定一个范围,不包括记录本身(不锁数据,仅仅锁数据前面的Gap)。
- Next-key Lock 锁:同时锁住数据,并且锁住数据前面的 Gap。
排查 InnoDB 锁问题
排查 InnoDB 锁问题通常有 2 种方法。
打开 innodb_lock_monitor 表,注意使用后记得关闭,否则会影响性能。
在 MySQL 5.5 版本之后,可以通过查看 information_schema 库下面的 innodb_locks、innodb_lock_waits、innodb_trx 三个视图排查 InnoDB 的锁问题。
InnoDB 加锁行为
下面举一些例子分析 InnoDB 不同索引的加锁行为。分析锁时需要跟隔离级别联系起来,我们以 RR 为例,主要是从四个场景分析。
- 主键 + RR。
- 唯一键 + RR。
- 非唯一键 + RR。
- 无索引 + RR。
下面讲解第一种情况:主键 + RR,如下图所示。
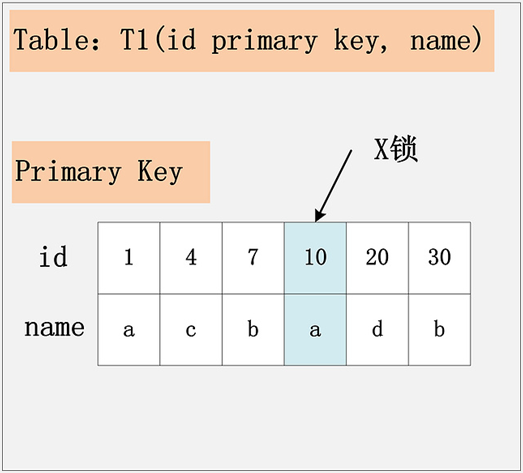
假设条件是:
- update t1 set name=‘XX’ where id=10。
- id 为主键索引。
加锁行为:仅在 id=10 的主键索引记录上加 X锁。
第二种情况:唯一键 + RR,如下图所示。
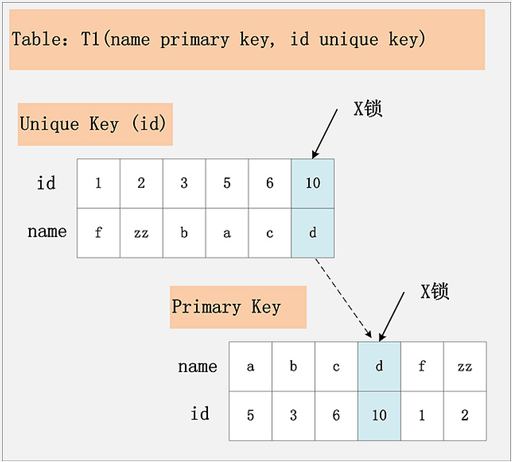
假设条件是:
- update t1 set name=‘XX’ where id=10。
- id 为唯一索引。
加锁行为:
先在唯一索引 id 上加 id=10 的 X 锁。
再在 id=10 的主键索引记录上加 X 锁,若 id=10 记录不存在,那么加间隙锁。
第三种情况:非唯一键 + RR,如下图所示。
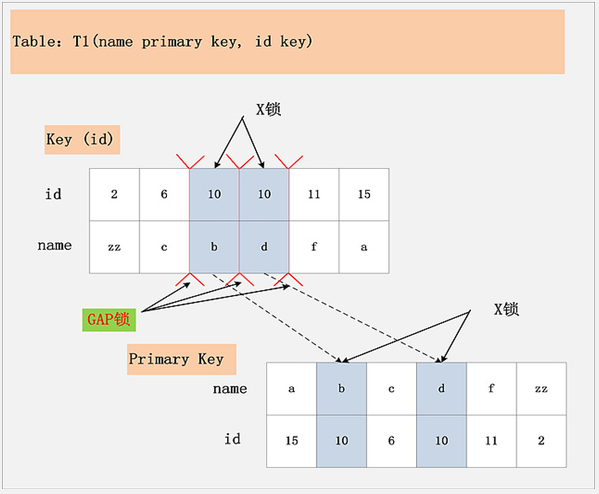
假设条件是:
- update t1 set name=‘XX’ where id=10。
- id 为非唯一索引。
加锁行为:
先通过 id=10 在 key(id) 上定位到第一个满足的记录,对该记录加 X 锁,而且要在 (6,c)~(10,b) 之间加上 Gap lock,为了防止幻读。然后在主键索引 name 上加对应记录的X 锁;
再通过 id=10 在 key(id) 上定位到第二个满足的记录,对该记录加 X 锁,而且要在(10,b)~(10,d)之间加上 Gap lock,为了防止幻读。然后在主键索引 name 上加对应记录的X 锁;
最后直到 id=11 发现没有满足的记录了,此时不需要加 X 锁,但要再加一个 Gap lock: (10,d)~(11,f)。
第四种情况:无索引 + RR,如下图所示。
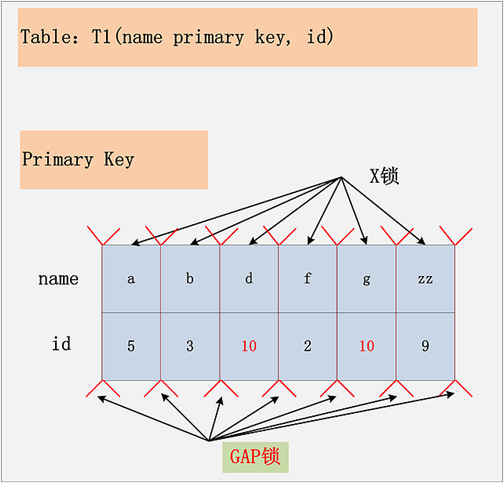
假设条件是:
- update t1 set name=‘XX’ where id=10。
- id 列无索引。
加锁行为:
表里所有行和间隙均加 X 锁。
上面我们有提到分析锁问题的三个视图,在实际的使用中,可以在数据库发生阻塞的时候,将这三个视图( innodb_locks、innodb_lock_waits、innodb_trx )做联合查询来帮助获取详细的锁信息,帮助快速定位找出造成死锁的元凶和被害者,以及具体的事务。
InnoDB 死锁
在 MySQL 中死锁不会发生在 MyISAM 存储引擎中,但会发生在 InnoDB 存储引擎中,因为 InnoDB 是逐行加锁的,极容易产生死锁。那么死锁产生的四个条件是什么呢?
- 互斥条件:一个资源每次只能被一个进程使用;
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
- 不剥夺条件:进程已获得的资源,在没使用完之前,不能强行剥夺;
- 循环等待条件:多个进程之间形成的一种互相循环等待资源的关系。
在发生死锁时,InnoDB 存储引擎会自动检测,并且会自动回滚代价较小的事务来解决死锁问题。但很多时候一旦发生死锁,InnoDB 存储引擎的处理的效率是很低下的或者有时候根本解决不了问题,需要人为手动去解决。
既然死锁问题会导致严重的后果,那么在开发或者使用数据库的过程中,如何避免死锁的产生呢?这里给出一些参考:
- 加锁顺序一致;
- 尽量基于 primary 或 unique key 更新数据。
- 单次操作数据量不宜过多,涉及表尽量少。
- 避免索引设置不当导致的 锁定资源过多。
- 相关工具:pt-deadlock-logger。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号