

windows批处理学习(for和字符串)---03
【1】for命令简介
先把for循环与for命令类比一下,这样学习理解快。
for 循环语句,一般格式如下:
1 for (表达式1;表达式2;表达式3)
2 {
3 循环体;
4 }
1. 表达式1 一般为初始状态赋值表达式,给控制变量赋初值。
2. 表达式2 一般为关系表达式或逻辑表达式,为循环控制条件。
3. 表达式3 一般为每次执行循环体后向控制变量重新赋值的表达式(给控制变量增量或减量)。
4. 语句:循环体,一般为复合语句(即可能需要执行多条语句)。
举个实例:
1 for (int i=0; i < 100; ++i)
2 {
3 cout << i << endl;
4 }
for 命令,一般格式如下:
在cmd窗口中使用格式:
FOR %variable IN (set) DO command [command-parameters]
在批处理脚本中使用格式:
FOR %%variable IN (set) DO command [command-parameters]
1. 在cmd窗口中使用,变量名必须用单%引用(即:%variable);在批处理脚本中使用,变量名必须用双%引用(即:%%variable)。
2. for、in和do是for命令的三个关键字,缺一不可。
3. 关键字in之后,do之前的括号不能省略。
举个实例:新建一个文本文件,命名为fordemo,修改文件类型为bat,用Notepad++打开编辑内容为:
1 @echo off 2 for %%i in (1 2 3 4 5) do @echo %%i 3 pause>nul
执行结果:
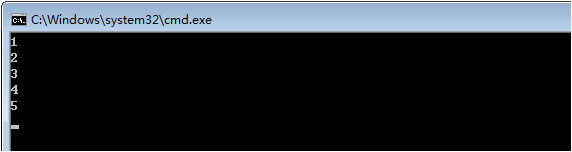
嗯哼,原来for命令就这么简单?嗨,同学,不要浮躁,保持冷静,更要理智。
下面,且看对上例语句的分析:
从命令组成结构由左向右剖析,除过关键字,依次分别为:
1. 变量名为i,i太简单,作为变量名不具备见名知意的特点。当我把i修改为item,如下内容:
1 @echo off 2 for %%item in (1 2 3 4 5) do @echo %%item 3 pause>nul
双击执行。不对呀!一扇而过?反正本人机器执行的确是。为什么会这样子的?
哦,原来如此:for命令的形式变量只能是26个字母中的任意一个。
代码先复原。不会吧?难道只能有26种形式变量名?这也太狭隘了吧!区分大小写不?验证一下,再把for之后,in之前的变量名i换成I(即大写字母I),如下内容:
1 @echo off 2 for %%I in (1 2 3 4 5) do @echo %%i 3 pause>nul
双击执行。我勒个去~ 执行结果竟然这样:

哦,原来如此:字母区分大小写(即就是 %%a 和 %%A 是两个不同的变量名)。
代码复原。那要这样的话,那我想修改为数字可否呢?尽管,我已经知道批处理脚本中%0~%9是特殊的10个形式变量,修改后如下内容:
1 @echo off 2 for %%0 in (1 2 3 4 5) do @echo %%0 3 pause>nul 4 for %%1 in (6 7 8 9 10) do @echo %%1 5 pause>nul
双击执行。结果如下:
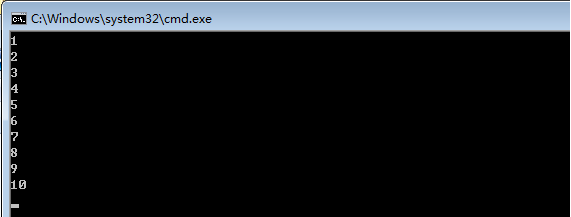
看来一切正常哈。但是,为了便于脚本的维护以及避免两种形式变量同时使用时的隐患(一种比另一种只差个%,常在河边走,哪有不湿鞋的!),建议慎重选择。
哦,原来如此:for命令的变量尽量不要使用数字(即不要随便使用%%0~%%9)。
2. 关于in与do之间括号中的内容。其实,这个括号就相当于一个容器,里面存放了待遍历的所有元素(一个或多个变量或其他类型)。经网询,每个元素之间,可以用空格、跳格、逗号、分号或等号分隔。
各种不同的分隔,验证举例如下:
新建一个文本文件,命名为forItemdemo,修改文件类型为bat,用Notepad++打开编辑内容为:

1 @echo off 2 rem 空格 3 for %%A in (1 2 3) do @echo %%A 4 pause>nul 5 rem 跳格 6 for %%B in (4 5 6) do @echo %%B 7 pause>nul 8 rem 逗号 9 for %%C in (7,8,9) do @echo %%C 10 pause>nul 11 rem 分号 12 for %%D in (10;11;12) do @echo %%D 13 pause>nul 14 rem 等号 15 for %%D in (13=14=15) do @echo %%D 16 pause>nul
执行结果如下:

do之后就是相当于for循环语句的循环体部分,在此不做解释。
【2】for命令使用
(1)for /l
for /l l是指loop,即循环的意思。for语句本身就是一种“循环”,为什么还要这个呢?且看下文分解。
for /l 语句的完整格式:
for /l %variable in (start,step,end) do command [command-parameters]
说明:
[1] start指起始值;step指步间距;end指终止值。
[2] start、step和end都只能取整数(正负皆可)。
[3] 步间距step的值不能为0。
[4] 当步间距step的值为正整数时,终止值end不能小于初始值start。
[5] 当步间距step的值为负整数时,终止值end不能大于初始值start。
具体含义:从start开始计数,以step为步长,直至最接近end的那个整数值为止,这之间有多少个数,do后的语句就执行多少次。
for /l 的简单应用示例如下:
例1:正常语法。新建文本文件,命名为for1.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /l %%i in (1,2,10) do echo %%i 3 pause>nul 4 for /l %%i in (-1,-2,-10) do echo %%i 5 pause>nul
执行结果: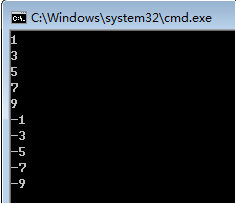
例2:死循环。新建文本文件,命名为for1.2,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 for /l %%i in (1,0,1) do echo abc 2 pause>nul
例3:无效语句。新建文本文件,命名为for1.3,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 for /l %%i in (2,1,1) do echo abc 2 pause>nul
当大家明白了for /l 的具体功能之后,是否会想到了与它有异曲同工之妙的goto循环语句呢? 似乎,for /l 和 goto 循环语句可以相互替换?
一般而言,for /l语句可以换成goto循环,但是,goto循环并不一定能被 for /l 语句替换掉。具体原因,请大家仔细想想。
只是就大家非常关心的一个问题提供一个简洁的答案,那就是:什么时候该用for /l计数循环,而什么时候又该用goto条件循环?
答案非常简单:
当循环次数确定的时候,首选for /l语句,也可使用goto语句但不推荐;
当循环次数不确定的时候,用goto语句将是唯一的选择,因为,这个时候需要用if之类的条件语句来判断何时结束goto跳转。
(2)for /d
/d ,完整的含义是 /directory,即为了处理文件夹。完整语句应该是这样的:
for /d %variable in (元素集合) do command [command-parameters]
[1] 有通配符。当“元素集合”中包含有通配符 ? 或 * 时,它会匹配文件夹。但是,相比 for /r 而言,这个时候的for /d,其作用就小得可怜了。(for /r 待看下文)
它仅能匹配当前目录下的第一级文件夹,或是指定目录位置上的一级文件夹,而不能匹配更深路径下的子文件夹。
例如,新建文本文件,命名为for2.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /d %%i in (f:\test*) do echo %%i 3 pause>nul
这样的语句,会匹配到形如:f:\test、f:\test1、f:\test2 等之类的文件夹,若不存在这样的文件夹,将不会有任何回显。
[2] 无通配符。当“元素集合”中不包含任何的通配符时,它的作用和 "for %%i in (元素集合) do 命令语句集合" 这样的语句无任何区别。
因此,for /d 的角色就变得很微妙,总结一下:
当“元素集合”中包含通配符 ? 或 * 时,它的作用就是匹配文件夹,此时,它仅能匹配当前目录下的第一级文件夹,或是指定目录位置上的文件夹。
在层次深度上不及 for /r,但和 for /r 一样的坏脾气:不能匹配带隐藏属性的文件夹;
在灵活性上不及for /f 和dir的组合;
当“元素集合”中不包含任何通配符的时候,它完全是 "for %%i in (元素集合) do ……" 语句的翻版,但是又稍显复杂。
for /d 的作用是如此有限,使用的次数是如此之少,以至于一度找不到它的用武之地,认为它食之无味,弃之可惜,完全是鸡肋一块。
当某年某月,我在cmd窗口里写下了这样的代码:
for /d %i in (test*) do @echo %i
我的本意是想查看在我的临时目录下,长年累月的测试工作到底创建了多少测试文件夹,以便随后把 echo 换成 rd 删除之。
这个时候,我突然发现这条代码是如此的简洁,是 for /r 或 for 和 dir /ad /b 的组合所无法替代的(echo换成 rd 就可以直接删除掉这些测试目录)。
简洁的代码给我带来的喜悦仅仅持续了短短10几秒的时间,我便开始了迷惘——能用到for /d 的类似情形,貌似少之又少且乏善可陈啊!
[3] for /r /d 是可以一起使用的(在for有限的4个参数中,据我所知只有/r /d可以一起使用)。
例如,新建文本文件,命名为for2.2,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /r /d %%i in (*) do echo %%i 3 pause>nul
效果:显示当前目录下所有的文件夹(包括子文件夹);等价于 "dir /ad /s /b"。
for /r /d 其实是对 /d 参数的扩展,/d参数本身只能处理第一层文件夹,但是加上/r 参数后就可以处理所有的子文件夹; 但是,for /r /d依然不能处理隐藏属性的文件夹。
这里给出使用for /r /d的一般条件:
3.1 要对文件夹进行操作(dir /ad /s /b可以显示,但不能对文件夹进行操作);
3.2 不处理隐藏属性的文件夹(说到底,还是for /f 和 dir 结合的命令更强大些)。
(3)for /r
for /r 语句的完整格式:
for /r [[drive:]path] %%variable in (set) do command [command-parameters]
按照帮助信息里翻译得四不像的说法,for /r 的作用是“递归”,我们换一个通俗一点的,叫“遍历文件夹”。
更详细的解释:像下面的语句中,如果“元素集合”中只是一个点号,那么,这条语句的作用就是:列举“目录”及其之下的所有子目录,对这些文件夹都执行“命令语句集合”中的命令语句。其作用与嵌套进 for /f 复合语句的 "dir /ad /b /s 路径" 功能类似。如果省略了“目录”,将在当前目录下执行前面描述的操作。
那么,再具体一点,for /r具体的语句完整格式为:
for /r 目录 %%i in (元素集合) do 命令语句集合
先来个代码加深一下理解:新建文本文件,命名为for3.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /r f:\test %%i in (.) do echo %%i 3 pause>nul
执行结果如下所示:
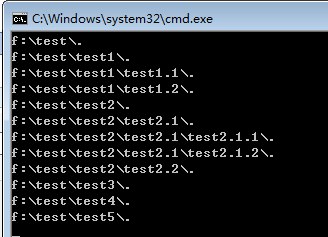
效果就是显示 f:\test 目录及其之下所有子目录的路径。
说到这里,其效果其实与 dir /ad /b /s f:\test 类似,请看执行dir命令的结果:
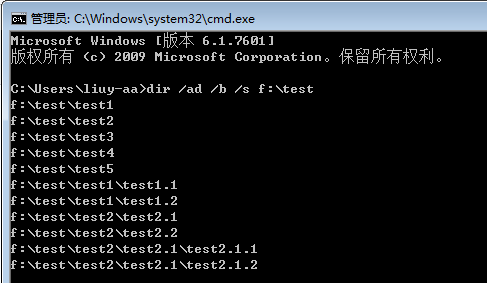
那么,若要论两者的区别,可以归纳出以下3点:
[1] for /r 列举出来的路径最后都带有斜杠和点号(即每个路径末尾的“\.”),而 dir 语句则没有,这就会对获取到的路径进行进一步加工产生影响。
[2] for /r 不能列举带隐藏属性的目录,而 dir 语句则可以通过指定 /a 后面紧跟的参数来获取带指定属性的目录,更加灵活;
[3] 若要对获取到的路径进行进一步处理,则需要把 dir 语句放入 for /f 语句中进行分析,写成如下形式:
1 @echo off
2 for /f %%i in ('dir /ad /b /s') do echo %%i
3 pause>nul
由于 for /r 语句是边列举路径边进行处理,所以,在处理大量路径的时候,过程前期不会感到有停顿;而 for /f 语句则需要等到 dir /ad /b /s 语句把所有路径都列举完之后,再读入内存进行处理,所以,在处理大量路径的时候,前期会感到有明显的停顿。
第[2]点差别很容易被大家忽视,导致用 for /r 列举路径的时候会造成内容遗漏;
第[3]点则会让大家有更直观的感受,很容易感觉到两者之间的差别。
反过来,要是“元素集合”不是点号呢?那又如何?
来看看这个代码:
1 @echo off 2 for /r f:\test %%i in (a b c) do echo %%i 3 pause
运行的结果是:
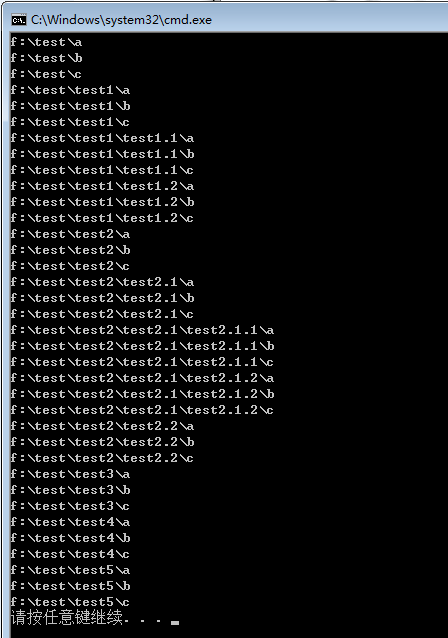
原来,它的含义是:列举 f:\test 及其所有的子目录,对所有的目录路径都分别添加a、b、c之后再显示出来。
再来看一个代码:
1 @echo off 2 for /r f:\test %%i in (*.txt) do echo %%i 3 pause>nul
运行结果是:
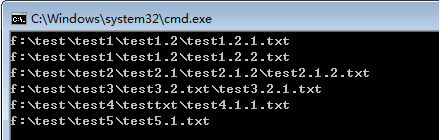
这段代码的含义是:列举 f:\test 及其所有子目录下的txt文本文件(以.txt结尾的文件夹不会被列出来)。
我们再回过头来归纳一下这个语句的作用:
for /r 目录 %%i in (元素集合) do 命令语句集合
上面语句的作用是:
[1] 列举“目录”及该目录路径下所有子目录,并把列举出来的目录路径和元素集合中的每一个元素拼接成形如“目录路径\元素”格式的新字符串,然后,对每一条这样的新字符串执行“命令语句集合”中的每一条命令;
特别需要注意的是:
当“元素集合”带以点号分隔的通配符 ? 或 * 的时候,把“元素集合”视为文件(不视为文件夹即目录),整条语句的作用是匹配“目录”所指文件夹及其所有子文件夹下匹配的文件;
若不以点号分隔,则把“元素集合”视为文件夹(不视为文件);
[2] 当省略掉“目录”时,则默认针对当前目录进行;
[3] 当元素集合中仅仅是一个点号的时候,将只列举目录路径;
(二)for /r 还是 dir /ad /b /s 列举目录时该如何选择?
前面已经说过,当列举目录时,for /r 和 dir /ad /b /s 的效果是非常类似的,这就产生了一个问题:
当我要获取目录路径并进行进一步处理的时候,两者之间,我该如何选择?
这个问题,前面其实已经有过一些讨论,现在我们再来作详细的分析。再来分析一下两者各自的优缺点:
[1] for /r:
1)优点:
① 只通过1条语句就可以同时实现获取目录路径和处理目录路径的操作;
② 遍历文件夹的时候,是边列举边处理的,获取到一条路径就处理一条路径,内存占用小,处理大量路径的时候不会产生停顿感。
2)缺点:
① 不能获取到带隐藏属性的目录,会产生遗漏;
② 不能获取带指定属性的目录。
[2] dir /ad /s:
1)优点:
① 能一次性获取带任意属性的目录,不会产生遗漏;
② 能通过指定不同的参数获取带任意属性的目录,更具灵活性。
2)缺点:
① dir /ad /s 语句仅能获取到目录路径,若要实现进一步的处理,还需要嵌入 for /f 语句中才能实现,写法不够简洁;
② 嵌入 for /f 语句之后,需要写成格式:
for /f "delims=" %%i in ('dir /ad /b /s') do ……
受 for /f 语句运行机制的制约,需要先列举完所有的路径放入内存之后,才能对每一条路径进行进一步的处理,处理大量路径时,内存占用量偏大,并且在前期会产生明显的停顿感,用户体验度不够好;
综合上述分析,可以做出如下选择:
1、若仅仅是为了获取某文件夹及其所有子文件夹的路径的话,请选择 dir /ad /b /s 语句;
2、若需要过滤带隐藏属性的文件夹的话,for /r 和 dir 语句都可以实现,但 for /r 内存占用小,处理速度快,是上上之选;
3、若需要获取所有文件夹,则除了 dir /ad /b /s 外,别无选择,因为 for /r 语句会遗漏带隐藏属性的文件夹;
在实际的使用中,我更喜欢使用 for /f 和 dir 的组合,因为它不会产生遗漏,并能给我带来更灵活的处理方式,唯一需要忍受的,就是它在处理大量路径时前期的停顿感,以及在这背后稍微有点偏高的内存占用;在我追求速度且可以忽略带隐藏属性的目录的时候,我会换用 for /r 的方案,不过这样的情形不多——有谁会愿意为了追求速度而容忍遗漏呢?
备注:关于红色加粗的隐藏属性问题,在win7系统下不复现。即遍历时候,可以罗列到隐藏属性的目录。参考文献是winXP环境,所以关于这点待再确认。
(4)for /f
网询很多资料,大家都说了一句话:for /f 是个十分强大的家伙。
“家伙”不知道什么意思?听说古时候,一天有一个秀才经过一个村庄,遇见一个衣衫褴褛的小孩,穿着棉衣,戴着凉帽,那时估计人生活比较艰难,冬季为了避寒估计也就不考虑那么多。秀才傲慢讥讽的对小孩说:“穿棉衣,戴凉帽,不知春秋。”小孩看了看,一个陌生的人,不慌不忙的回了一首:“东来的,西往的,不是东西。”(注意:《春秋》和《东西》可都是当时的著作名称)
接下来,让我们一起学习一下这个家伙。
如果说,for语句是批处理中最强大的语句的话,那么,for /f 就是精华中的精华(小说的笔法,牛人出场时候,总得渲染一下气氛哈)。
for /f 的强大,和它拥有众多的开关密切相关。因为开关众多,所以用法复杂,本章将分成若干小节,为大家逐一介绍强大的 for /f 语句。
(一) 为解析文本而生:for /f 的基本用法
所有的对象,无论是文件、窗体、还是控件,在所有的非机器语言看来,无外乎都是形如“c:\test.txt”、“CWnd”之类的文本信息;而所有的对象,具体如ini文件中的某条配置信息、注册表中的某个键值、数据库中的某条记录等等……都只能先转化为具有一定格式的文本信息,方可被代码识别、操控。可以说,编程的很大一部分工作,都是在想方设法绞尽脑汁如何提取这些文本信息。
而提取文本信息,则是for /f的拿手好戏:读取文件内容;提取某几行字符;截取某个字符片段;对提取到的内容再切分、打乱、杂糅……只要你所能想到的花样,for /f 都会想方设法帮你办到,因为,for /f 就是被设计成专门用于解析文本的。
光说不练不行,先来看个例子:
新建一个文本文件test.txt,编辑内容如下:
1 本文的目标是:不求最好,但求更好,做最实用的批处理分享。 2 本文地址:http://www.cnblogs.com/Braveliu/p/5081087.html。 3 这里是:顺序选择循环的博客,新手学习提升的福地。
新建文本文件,命名为for4.1.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f %%i in (test.txt) do echo %%i 3 pause>nul
执行结果:
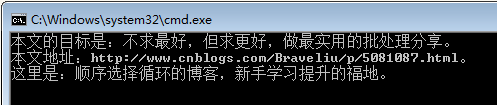
这段代码,主要是让你树立这样一种意识、一种观念:读取文本文件的内容,请使用 for /f 语句!
备注:改为“逐行分析文本文件的内容”,因为读取文本文件内容的方法命令有很多,比如重定向输入,又比如type/more/find/sort等命令。
深入考虑一下,for /f 语句是把整个test.txt一次性显示出来的吗?
在这段代码中,虽然执行结果是把test.txt中的所有内容都显示出来了,貌似 for /f 语句是把整个test.txt内容一次性显示到屏幕上,实际上并非如此。
无论for语句做何种变化,它的执行过程仍然遵循基本的for流程:依次处理每个元素,直到所有的元素都被处理为止。只不过在for /f语句中,这里的元素是指文件中的每一行,也就是说,for /f 语句是以行为单位处理文本文件的,这是一条极为重要的规则。在此强调它的重要性,希望在接下来的学习过程中,你能时刻牢记这一原则,那么,很多问题将会潜意识的迎刃而解。以下是验证这一说法的源代码(在原代码的基础上添加了& pause>nul语句,这样在执行过程中,每个元素即每行处理完成时,会需要按一下键盘的任意键):
1 @echo off 2 for /f %%i in (test.txt) do echo %%i & pause>nul 3 pause>nul
(二) 切分字符串的利器:delims=
也许你对for4.1.1.bat文件这段代码不屑一顾:不就是把test.txt的内容显示出来了么?好像用处不大啊。
好吧!说明你很有进取精神,咱继续往下看,
还用如上test.txt的文本。新建文本文件,命名为for4.2.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=," %%i in (test.txt) do echo %%i 3 pause>nul
执行结果:
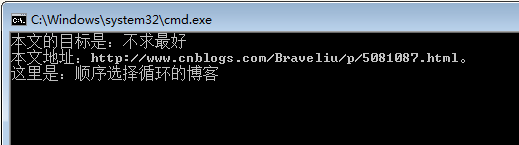
看到了吗?你惊奇地发现,每行第一个逗号之后的所有内容都不见了(如果有不存在逗号的行,则保留原样),也就说,你成功地提取到了每行第一个逗号之前的所有内容!试想一下,这段代码会有什么用呢?
如果别人给了你一个软件清单,每行都是“英文软件名(逗号)中文软件名”的格式,而你却只想保留英文名的时候,这段代码将是多么有用啊!
再假设,有这么一个IP文件,第一列是数字格式的IP地址,第二列是具体的空间地址,列与列之间用逗号分隔,而你想提取其中数字格式的IP,呵呵~~ 我不说你也知道该怎么办了吧?
举一反三,触类旁通。要是文本内容不是以逗号分隔,而是想以其他符号分隔呢?OK,把“delims=,”的逗号换成相应的符号就可以了。
在这里,我们引入了一个新的开关:"delims=,",它的含义是:以逗号作为被处理字符串的分隔符号。
在批处理中,指定分隔符号的方法是:添加一个形如 "delims=符号列表" 的开关,这样,被处理的每行字符串都会被符号列表中罗列出来的符号切分开来。
需要注意的是:如果没有指定"delims=符号列表"这个开关,那么,for /f 语句默认以空格键或跳格键作为分隔符号。
验证一下“注意”。新建一个文本文件test2.txt,内容(把test文件每行内容中间的标点符号都改为空格或跳格)如下:
1 本文的目标是 不求最好 但求更好 做最实用的批处理分享。 2 本文地址 http://www.cnblogs.com/Braveliu/p/5081087.html。 3 这里是 顺序选择循环的博客 新手学习提升的福地。
新建文本文件,命名为for4.2.2,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f %%i in (test2.txt) do echo %%i 3 pause>nul
执行结果:

深入考虑一下,如果我要指定的符号不止一个,该怎么办?
在上面的讲解中,提到了指定分隔符号的方法:添加一个形如“delims=符号列表”的开关。不知道你注意到没有,我的说法是“符号列表”而非“符号”,这是有很大区别的。因为,意味着你可以一次性指定多个分隔符号!
好勒~ 测试一下,还用test.txt文件的内容。
新建文本文件,命名为for4.2.3,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=.," %%i in (test.txt) do echo %%i 3 pause>nul
执行结果:
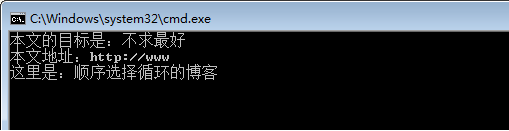
可见,第一个点号或第一个逗号之前的内容都被提取出来了。
for4.2.3 批处理的执行过程是:逐行读取test.txt中的内容,以点号和逗号切分每一行的内容(不存在点号和逗号的行,则不再切分,为了描述的方便,我们把被点号或逗号切分的一个一个的字符串片段,称之为节)。然后,for /f 会提取第一节的内容作为最终结果,显示在屏幕上。需要注意的是,在这里,所有行的字符串被切分成了两个以上的节。但是,for4.2.3的代码只会提取第一个节字符串的内容,因为 for /f 语句默认只提取第一节的字符串。那要想提取其他节呢?继续往下看。
(三) 定点提取:tokens=
上一节在讲解 delims= 的时候,强调 for /f 默认只能提取到第一节的内容。现在我们来思考一个问题:如果我要提取的内容不在第一节上,那怎么办?这回,就该轮到 tokens= 出山了。
tokens= 后面一般跟的是数字,如 tokens=2,也可以跟多个,但是每个数字之间用逗号分隔,如 tokens=3,5,8,它们的含义分别是:提取第2节字符串;提取第3、第5和第8节字符串(注意,这里所说的“节”,是由 delims= 这一开关划分的,它的内容并不是一成不变的)。
下面来看一个例子。新建一个文本文件test3.txt,编辑内容如下:
1 你若盛开,清风自来,如若不来,还有雾霾。
如果,我想提取“如若不来”这四个字,该如何写代码呢?
我们稍微观察一下test3内容就会发现,如果以逗号作为切分符号,就正好可以把“如若不来”化为单独的一个“节”,结合上一节的讲解,我们知道,"delims=," 这个开关是不可缺少的,而要提取的内容在以逗号切分的第3节上,那么,tokens= 后面的数字就应该是3了,最终的代码如下:
新建文本文件,命名为for4.3.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=, tokens=3" %%i in (test3.txt) do echo %%i 3 pause>nul
执行结果:

如果我们现在要提取的不只是一个“节”,而是多个那又怎么办呢?比如,要提取以逗号切分的第3节和第4节字符串,尝试写一个。
新建文本文件,命名为for4.3.2,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=, tokens=3,4" %%i in (test3.txt) do echo %%i 3 pause>nul
执行结果:

卧槽,运行批处理后发现,执行结果还只是显示了第3节的内容。
哦,看来,echo 后面的 %%i 只接收到了 tokens=3,4 中第一个数值3所代表的那个字符串,而第二个数值4所代表的字符串因为没有变量来接收,所以就无法在执行结果中显示出来了。
那么,要如何接收 tokens= 后面多个数值所指代的内容呢?
对,问题就在这里。for /f 语句对这种情况做以下规定:
如果 tokens= 后面指定了多个数字,如果形式变量为%%i。那么,第一个数字指代的内容用第一个形式变量 %%i 来接收,第二个数字指代的内容用第二个形式变量 %%j 来接收,第三个数字指代的内容用第三个形式变量 %%k 来接收……第N个数字指代的内容用第N个形式变量来接收。其中,形式变量遵循字母的排序,第N个形式变量具体是什么符号,由第一个形式变量来决定:如果第一个形式变量是%%i,那么,第二个形式变量就是%%j;如果第一个形式变量用的是%%x,那么,第二个形式变量就是%%y。
现在回头再去看for4.3.2文件内容,应该修改成啥样子呢?
新建文本文件,命名为for4.3.3,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=, tokens=3,4" %%i in (test3.txt) do echo %%i %%j 3 pause>nul
执行结果:

OK,大功告成。那如果有这样一个要求:显示test3中的内容,但是逗号要替换成空格,如何编写代码?
结合上面所学的内容,稍加思索,你可能很快就得出了答案:
新建文本文件,命名为for4.3.4,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=, tokens=1,2,3,4" %%i in (test3.txt) do echo %%i %%j %%k %%l 3 pause>nul
执行结果:

写完之后,你可能意识到这样一个问题:
假如,要提取的“节”数不是4,而是10,或者20,或者更多,难道我也得从1写到10、20或者更多吗?有没有更简洁的写法呢?
答案肯定是有的,那就是:如果要提取的内容是连续的多“节”的话,那么,连续的数字可以只写最小值和最大值,中间用短横连接起来即可,比如 tokens=1,2,3,4 可以简写为 tokens=1-4 。
还可以把这个表达式写得更复杂一点:tokens=1,2-4 tokens=1-3,4……怎么方便就怎么写吧!
另外,大家可能还会看到一种比较怪异的写法:
还用如上test3文件。新建文本文件,命名为for4.3.5,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=, tokens=1,*" %%i in (test3.txt) do echo %%i %%j 3 pause>nul
执行结果:
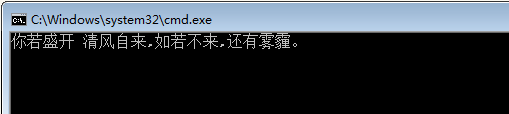
我勒个去!第一个逗号不见了,取代它的是一个空格符号,其余部分保持不变。其中奥妙就在这个星号上面。
tokens=后面所接的星号具备这样的功能:依切分字符,将字符串从左往右切分成紧跟在*之前最大数值所表示的节数之后,字符串的其余部分保持不变,且整体被*所表示的一个变量接收。
理论讲解是比较枯燥的,特别是为了严密起见,还使用了很多限定性的修饰词,导致句子很长,增加了理解的难度,我们还是结合for4.3.5来讲解一下吧。
test3的内容被切分,切分符号为逗号,当切分完第一节之后,切分动作不再继续下去,因为 tokens=1,* 中,星号前面紧跟的是数字1;第一节字符串被切分完之后,其余部分字符串不做任何切分,整体作为第二节字符串,这样,test3就被切分成了两节,分别被变量%%i和变量%%j接收。
以上几种切分方式可以结合在一起使用。不知道下面这段代码的含义你是否能看得懂,如果看不懂的话,那就运行一下代码,然后反复揣摩,你一定会更加深刻地理解本节所讲解的内容的:
新建文本文件,命名为for4.3.6,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=, tokens=2-3,1,*" %%i in (test3.txt) do echo %%i %%j %%k %%l 3 pause>nul
执行结果:
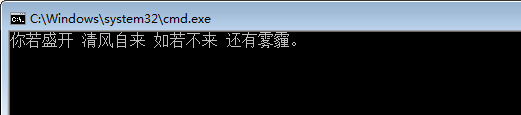
(四) 跳过无关内容,直奔主题:skip = n
很多时候,有用的信息并不是贯穿文本内容的始终,而是位于第N行之后的行内,为了提高文本处理的效率,或者不受多余信息的干扰,for /f 允许你跳过这些无用的行,直接从第N+1行开始处理,这个时候,就需要使用参数 skip = n,其中,n是一个正整数,表示要跳过的行数。例如:
仍使用test文件。新建文本文件,命名为for4.4.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "skip=2" %%i in (test.txt) do echo %%i 3 pause>nul
执行结果:

这段代码将跳过头两行内容,从第3行起显示test.txt中的信息。
(五) 忽略以指定字符打头的行:eol=
在cmd窗口中敲入:for /?,“官方”的解释如下:

1 for /f "eol=; tokens=2,3* delims=, " %i in (myfile.txt) do @echo %i %j %k
会分析 myfile.txt 中的每一行,忽略以分号打头的那些行……
第一条解释狗屁不通,颇为费解:行注释字符的结尾是什么意思?“(就一个)”怎么回事?
结合第二条解释,才知道eol有忽略指定行的功能。
但是,这两条解释是互相矛盾的:到底是忽略以指定字符打头的行,还是忽略以指定字符结尾的行?
实践是检验真理的唯一标准,还是用代码来检验一下eol的作用吧!
新建文本文件,命名为test4。编辑内容如下:
1 ;愿得一人心,白首不相离。 2 衣带渐宽终不悔,为伊消得人憔悴。 3 两情若是久长时,又岂在朝朝暮暮。 4 ;曾经沧海难为水,除却巫山不是云。 5 落红不是无情物,化作春泥更护花。
新建文本文件,命名为for4.5.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "eol=;" %%i in (test4.txt) do echo %%i 3 pause>nul
执行结果:
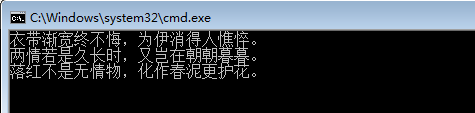
观察结果,总结规律发现:那些以分号打头的行没有显示出来。
由此可见,第二条解释是正确的,eol= 的准确含义是:忽略以指定字符打头的行。而第一条的“结尾”纯属微软在信口开河。
那么,“(就一个)”又作何解释呢?试试这个代码:
新建文本文件,命名为for4.5.2,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "eol=,;" %%i in (test4.txt) do echo %%i 3 pause>nul
执行结果:
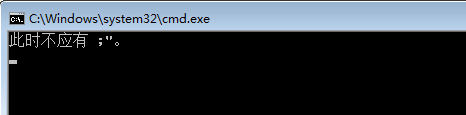
屏幕上出现 此时不应有 ;"。 的报错信息。可见,在指定字符的时候,只能指定1个。
在很多时候,我对这样的设计颇有微词而又无可奈何:为什么只能指定1个而不是多个?要忽略多个还得又是if又是findstr加管道来多次过滤,那效率实在太低下了——能用到的功能基本上都提供,但是却又做不到更好,批处理,你的功能为什么那么弱?
不知道大家注意到没有,如果test4.txt中有以分号打头的行,那么,这些行在代码for4.4.1的执行结果中将凭空消失。
重现一下作为验证。新建文本文件,命名为test4,编辑内容如下:
1 ;愿得一人心,白首不相离。 2 衣带渐宽终不悔,为伊消得人憔悴。 3 两情若是久长时,又岂在朝朝暮暮。 4 ;曾经沧海难为水,除却巫山不是云。 5 落红不是无情物,化作春泥更护花。
新建文本文件,命名为for4.5.3,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "skip=2" %%i in (test4.txt) do echo %%i 3 pause>nul
执行结果:

观察结果,分析总结:原来,for /f 语句是默认忽略以分号打头的行内容的,正如它默认以空格键或跳格键作为字符串的切分字符一样。
但是,备注:eol=; 这种默认设置,在delims=;时变得无效。再验证一下这条:
新建文本文件,命名为test5,编辑内容如下:
1 ;愿得一人心;白首不相离。
新建文本文件,命名为for4.5.4,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f "delims=;" %%i in (test5.txt) do echo %%i 3 pause>nul
执行结果:

很多时候,我们可以充分利用这个特点。比如,在设计即将用for读取配置文件的时候,可以在注释文字的行首加上分号。
如果要取消这个默认设置,可选择的办法是:
1、为eol=指定另外一个字符;
2、使用 for /f "eol=" 语句,也就是说,强制指定字符为空,就像对付 delims= 一样。
(六)如何决定该使用 for /f 的哪种句式?(兼谈usebackq的使用)
for /f %%i in (……) do (……)
for 语句有好几种变形语句,不同之处在于第一个括号里的内容:有的是用单引号括起来;有的是用双引号包住;有的不用任何符号包裹。具体格式为:
[1] for /f %%i in (文件名) do (……)
[2] for /f %%i in ('命令语句') do (……)
[3] for /f %%i in ("字符串") do (……)
看到这里,我想很多人可能已经开始犯了迷糊了:如果要解决一个具体问题,面对这么多的选择,如何决定该使用哪一条呢?
实际上,当我在上面罗列这些语句的时候,已经有所提示了,不知道你是否注意到了。
如果你一时无法参透其中奥妙,那也无妨,请听我一一道来便是。
(1)当你希望读取文本文件中的内容的话,第一个括号中不用任何符号包裹,应该使用的是第[1]条语句。
例如:你想显示test.txt中的内容,那么,就使用
1 @echo off 2 for /f %%i in (test.txt) do echo %%i 3 pause>nul
(2)当你读取的是命令语句执行结果中的内容的话,第一个括号中的命令语句必须使用单引号包裹,应该使用的是第[2]条语句。
例如:你想显示当前目录下所有文件名中含有test字符串的文本文件的时候,应该使用
1 @echo off
2 for /f %%i in ('dir /a-d /b *test*.txt') do echo %%i
3 pause>nul
(3)当你要处理的是一个字符串的时候,第一个括号中的内容必须用双引号括起来,应该是用的是第[3]条语句。
例如:当你想把www.baidu.cn这串字符中的点号换为短横线并显示出来的话,可以使用
1 @echo off
2 for /f "delims=. tokens=1-3" %%i in ("www.baidu.cn") do echo %%i-%%j-%%k
3 pause>nul
很显然,第一个括号里是否需要用符号包裹起来,以及使用什么样的符号包裹,取决于要处理的对象属于什么类型:
- 如果是文件,则无需包裹。
- 如果是命令语句,则用单引号包裹。
- 如果是字符串,则使用双引号括起来。
当然,事情并不是绝对如此,如果细心的你想到了批处理中难缠的特殊字符,你肯定会头大如斗。
或许你头脑中灵光一闪,已经想到了一个十分头痛的问题:在第1条语句中,如果文件名中含有空格 或 &,该怎么办?
照旧吗?尝试一下:
新建文本文件,命名为test 6,编辑内容如下:
1 abcdefghijklmnopqrstuvwxyz.
新建文本文件,命名为for4.6.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 for /f %%i in (test 6.txt) do echo %%i 3 pause>nul
执行结果:
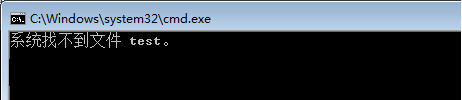
当你兴冲冲地双击批处理,运行后,屏幕上出现了可耻的报错信息:系统找不到文件 test 。
当你把 test 6.txt 换成 test&6.txt 后,更怪异的事情发生了:CMD窗口在你眼前一闪而过,然后,优雅地消失了。
你可能觉得自己的代码写错了某些符号,你再仔细的检查了一次,确认没有笔误,然后,你再次双击批处理,结果问题照旧;你开始怀疑其他程序对它可能有影响,于是关掉其他窗口,再运行了一次,问题依旧;你不服气地连续运行了好几次,还是同样的结果。
真怪哉!
你一拍大腿,猛然想起了一件事:当路径中含有特殊字符的时候,应该使用引号把路径括起来。对,就是它了!
但是,当你把代码写出来之后,你很快就焉了:
1 for /f %%i in ("test 6.txt") do echo %%i
这不就是上面提到的第[3]条 for /f 命令的格式吗?批处理会把 test 6.txt 这个文件名识别字符串啊!
你百无聊赖地在CMD窗口中输入 for /? ,并重重地敲下了回车,漫无目的地在帮助信息中寻找,希望能找到点什么。
结果还真让你到了点什么。
你看到了这样的描述:
usebackq - 指定新语法已在下类情况中使用:在作为命令执行一个后引号的字符串并且一个单引号字符为文字字符串命令并允许在 filenameset中使用双引号扩起文件名称。
但是,通读一遍之后,你却如坠五里雾中,不知所云。
还好,下面有个例子,并配有简单的说明:
1 ::枚举当前环境中的环境变量名称 2 @echo off 3 for /f "usebackq delims==" %%i IN (`set`) do @echo %%i 4 pause>nul
你仔细对比了for /f语句使用usebackq 和 不使用usebackq时在写法上的差别,很快就找到了答案:当使用了usebackq之后,如果第一个括号中是一条命令语句,那么,就要把单引号'改成后引号`(键盘左上角esc键下面的那个按键,与~在同一键位上)。回过头去再看那段关于usebackq的描述,字斟句酌,反复揣摩,终于被你破译了天机:usebackq 是一个增强型参数,当使用了这个参数之后,原来的for语句中第一个括号内的写法要做如下变动:
- 如果第一个括号里的对象是一条命令语句的话,原来的单引号'要改为后引号`;
- 如果第一个括号里的对象是字符串的话,原来的双引号"要改为单引号';
- 如果第一个括号里的对象是文件名的话,要用双引号"括起来。
验证一下,把for4.6.1文件改写成如下代码:
1 @echo off
2 for /f "usebackq" %%i in ("test 6.txt") do echo %%i
3 pause>nul
执行结果:

测试通过!此时,你很可能会仰天长叹:Shit,微软这该死的机器翻译!
至于把代码中的空格换成&后,CMD窗口会直接退出,那是因为&是复合语句的连接符,CMD在预处理的时候,会优先把&前后两部分作为两条语句来解析,而不是大家想象中的一条完整的for语句,从而产生了严重的语法错误。因为牵涉到预处理机制问题,不属于本节要讨论的内容,在此不做详细讲解。
这个时候,我们会吃惊地发现,区区一条for语句,竟然有多达6种句型:
1 rem (1)
2 for /f %%i in (文件名) do (……)
3 rem (2)
4 for /f %%i in ('命令语句') do (……)
5 rem (3)
6 for /f %%i in ("字符串") do (……)
7 rem (4)
8 for /f "usebackq" %%i in ("文件名") do (……)
9 rem (5)
10 for /f "usebackq" %%i in (`命令语句`) do (……)
11 rem (6)
12 for /f "usebackq" %%i in ('字符串') do (……)
其中,4、5、6由1、2、3发展而来,他们有这样的对应关系:1-->4、2-->5、3-->6。
好在后3种情形并不常用,所以,牢牢掌握好前三种句型的适用情形就可以了。否则,要在这么多句型中确定选择哪一条语句来使用,还真有点让人头脑发懵。
至于 for /f 为什么要增加usebacq参数,我只为第4条语句找到了合理的解释:为了兼容文件名中所带的空格 或 &。它在第5、6条语句中为什么还有存在的必要,我也不是很明白,这有待于各位去慢慢发现。(备注:这种解释虽然有点不靠谱,但也算一种解释,大家将就看看吧。启用usebackq选项的时候,“文件名”取代了“字符串”,那么“字符串”只好改变为“命令语句”,“命令语句”只好用后引号重新表示——简而言之,是“文件名”符号改变引起的蝴蝶效应。言外之意:usebackq 除了在处理带空格的文件名时会用到外,根本就没有其它的出场机会和存在价值。)
(5)延迟变量
关于延迟变量变量延迟在for语句中起着至关重要的作用,不只是在for语句中,在其他的复合语句中,它也在幕后默默地工作着,为了突出它的重要性,本节内容在单独的楼层中发出来,希望引起大家的重视。
对于批处理新手而言,“变量延迟”这个概念很可能闻所未闻,但是,它却像一堵横亘在你前进道路上的无形高墙,你感受不到它的存在,但当你试图往前冲时,它会把你狠狠地弹回来,让你无法逾越、无功而返;而一旦找到了越过它的方法,你就会发现,在for的世界里,前面已经是一片坦途,而你对批处理的理解,又上升到了一个新的境界。
例如,你编写了这样一个代码:
新建文本文件,命名为for5.1,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off 2 set num = 0 && echo %num% 3 pause>nul
执行结果:
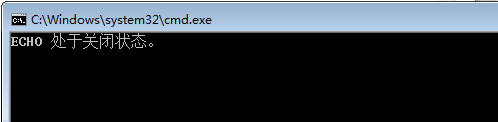
你的本意是想对变量num赋值之后,再把这个值显示出来,结果,显示出来的并不是0,而是显示:ECHO 处于关闭状态。
之所以会出错,是因为“变量延迟”这个家伙在作怪。在讲解变量延迟之前,我们需要了解一下批处理的执行过程,它将有助于我们深入理解变量延迟。
批处理的执行过程是怎样的呢?
“自上而下,逐条执行”,我想,这个经典的说法大家都已经耳熟能详了,没事的时候倒着念,也还别有一番意味。但是,我想问大家的是,大家真的深刻地理解了这句话的含义了吗?“自上而下”,这一条和我们本节的讲解关系不大,暂时略过不说,后一条,“逐条执行”和变量延迟有着莫大的干系,它是我们本节要关注的重点。很多人往往认为一行代码就是一条语句,从而把“逐条执行”与“逐行执行”等同起来,这就大错特错了。莫非“逐条执行”里暗藏着玄机?
正是如此。
“逐条”并不等同于“逐行”。这个“条”,是“一条完整的语句”的意思,并不是指“一行代码”。在批处理中,是不是一条完整的语句,并不是以行来论的,而是要看它的作用范围。什么样的语句才算“一条完整的语句”呢?
[1] 在复合语句中,整个复合语句是一条完整的语句,而无论这个复合语句占用了多少行的位置。常见的复合语句有:for语句、if……else语句、用连接符&、||和&&连接的语句,用管道符号|连接的语句,以及用括号括起来的、由多条语句组合而成的语句块;
[2] 在非复合语句中,如果该语句占据了一行的位置,则该行代码为一条完整的语句。
例如:新建文本文件,命名为for5.2,修改文件类型为bat,用Notepad++打开编辑内容如下:
1 @echo off
2 set num=0
3 for /f %%i in ('dir /a-d /b *.exe') do (
4 set /a num+=1
5 echo num 当前的值是 %num%
6 )
7 echo 当前目录下共有 %num% 个exe文件
8 dir /a-d /b *.txt|findstr "test">nul&&(
9 echo 存在含有 test 字符串的文本本件
10 ) || echo 不存在含有 test 字符串的文本文件
11 if exist test.ini (
12 echo 存在 test.ini 文件
13 ) else echo 不存在 test.ini 文件
14 pause
上面的代码共有14行,但是只有完整的语句只有7条,它们分别是:
第1条:第1行的echo语句;
第2条:第2行的set语句;
第3条:第3、4、5、6行上的for复合语句;
第4条:第7行的echo语句;
第5条:第8、9、10行上用&&和||连接的复合语句;
第6条:第11、12、13行上的if……else复合语句;
第7条:第14行上的pause语句。
在这里,我之所以要花这么长的篇幅来说明一行代码并不见得就是一条语句,是因为批处理的执行特点是“逐条”执行而不是“逐行”执行,澄清了这个误解,将会更加理解批处理的预处理机制。
在代码“逐条”执行的过程中,cmd.exe这个批处理解释器会对每条语句做一些预处理工作,这就是批处理中大名鼎鼎的“预处理机制”。
预处理的大致情形是这样的:首先,把一条完整的语句读入内存中(不管这条语句有多少行,它们都会被一起读入),然后,识别出哪些部分是命令关键字,哪些是开关、哪些是参数,哪些是变量引用……如果代码语法有误,则给出错误提示或退出批处理环境;如果顺利通过,接下来,就把该条语句中所有被引用的变量及变量两边的百分号对,用这条语句被读入内存之就已经赋予该变量的具体值来替换……当所有的预处理工作完成之后,批处理才会执行每条完整语句内部每个命令的原有功能。也就是说,如果命令语句中含有变量引用(变量及紧邻它左右的百分号对),并且某个变量的值在命令的执行过程中被改变了,即使该条语句内部的其他地方也用到了这个变量,也不会用最新的值去替换它们,因为某条语句在被预处理的时候,所有的变量引用都已经被替换成字符串常量了,变量值在复合语句内部被改变,不会影响到语句内部的其他任何地方。
顺便说一下,运行代码 for5.2 之后,将在屏幕上显示当前目录下有多少个exe文件,是否存在含有 test 字符串的文本文件,以及是否存在 test.ini 这个文件等信息。
让很多人百思不得其解的是:如果当前目录下存在exe文件,那么,有多少个exe文件,屏幕上就会提示多少次 "num 当前的值是 0" ,而不是显示1到N(N是exe文件的个数)。
结合上面两个例子,我们再来分析一下,为什么这两段代码的执行结果和我们的期望有一些差距。
在 for5.1 中,set num=0 && echo %num% 是一条复合语句,它的含义是:把0赋予变量num,成功后,显示变量num的值。
虽然是在变量num被赋值成功后才显示变量num的值,但是,因为这是一条复合语句,在预处理的时候,&&后的%num%只能被set语句之前的语句赋予变量num的具体值来替换,而不能被复合语句内部、&&之前的set语句对num所赋予的值来替换,可见,此num非彼num。可是,在这条复合语句之前,我们并没有对变量num赋值,所以,&&之后的%num%是空值,相当于在&&之后只执行了 echo 这一命令,所以,会显示 echo 命令的当前状态,而不是显示变量num的值(虽然该变量的值被set语句改变了)。
在 for5.2 中,for语句的含义是:列举当前目录下的exe文件,每发现一个exe文件,变量num的值就累加1,并显示变量num的值。
看了对 for5.1 的分析之后,再来分析 for5.2 就不再那么困难了:
第3、4、5行上的代码共同构成了一条完整的for语句,而语句"echo num 当前的值是 %num%"与"set /a num+=1"同处复合语句for的内部,那么,第4行上set改变了num的值之后,并不能对第5行上的变量num有任何影响,因为在预处理阶段,第5行上的变量引用%num%已经被在for之前就赋予变量num的具体值替换掉了,它被替换成了0(是被第2行上的set语句赋予的)。
如果想让代码for5.1 的执行结果中显示&&之前赋予num的值,让代码 for5.2 在列举exe文件的时候,从1到N地显示exe文件的数量,那又该怎么办呢?
对代码for5.1,可以把用&&连接复合语句拆分为两条单独的语句,写成:
1 @echo off 2 set num=0 3 echo %num% 4 pause>nul
但是,这不是我们这次想要的结果。
对这两段代码都适用的办法是:使用变量延迟扩展语句,让变量的扩展行为延迟一下,从而获取我们想要的值。
在这里,我们先来充下电,看看“变量扩展”又是怎么一回事。
用CN-DOS里批处理达人willsort的原话,那就是:“在许多可见的官方文档中,均将使用一对百分号闭合环境变量以完成对其值的替换行为称之为“扩展(expansion)”,这其实是一个第一方的概念,是从命令解释器的角度进行称谓的,而从我们使用者的角度来看,则可以将它看作是引用(Reference)、调用(Call)或者获取(Get)。”说得直白一点,所谓的“变量扩展”,实际上就是很简单的这么一件事情:用具体的值去替换被引用的变量及紧贴在它左右的那对百分号。
既然只要延迟变量的扩展行为,就可以获得我们想要的结果,那么,具体的做法又是怎样的呢?
一般说来,延迟变量的扩展行为,可以有如下选择:
[1] 在适当位置使用 setlocal enabledelayedexpansion 语句;
[2] 在适当的位置使用 call 语句。
使用 setlocal enabledelayedexpansion 语句,那么,for5.1 和 for5.2 可以分别修改为:
1 @echo off 2 setlocal enabledelayedexpansion 3 set num=0 && echo !num! 4 pause>nul
1 @echo off
2 set num=0
3 setlocal enabledelayedexpansion
4 for /f %%i in ('dir /a-d /b *.exe') do (
5 set /a num+=1
6 echo num 当前的值是 !num!
7 )
8 echo 当前目录下共有 %num% 个exe文件
9 dir /a-d /b *.txt|findstr "test">nul&&(
10 echo 存在含有 test 字符串的文本本件
11 )||echo 不存在含有 test 字符串的文本文件
12 if exist test.ini (
13 echo 存在 test.ini 文件
14 ) else echo 不存在 test.ini 文件
15 pause>nul
使用第call语句,那么,for5.1 修改为:
1 @echo off 2 set num=0&&call echo %%num%% 3 pause>nul
for5.2 修改为:
1 @echo off
2 set num=0
3 for /f %%i in ('dir /a-d /b *.exe') do (
4 set /a num+=1
5 call echo num 当前的值是 %%num%%
6 )
7 echo 当前目录下共有 %num% 个exe文件
8 dir /a-d /b *.txt|findstr "test">nul&&(
9 echo 存在含有 test 字符串的文本本件
10 )||echo 不存在含有 test 字符串的文本文件
11 if exist test.ini (
12 echo 存在 test.ini 文件
13 ) else 不存在 test.ini 文件
14 pause>nul
由此可见,如果使用 setlocal enabledelayedexpansion 语句来延迟变量,就要把原本使用百分号对闭合的变量引用改为使用感叹号对来闭合;如果使用call语句,就要在原来命令的前部加上 call 命令,并把变量引用的单层百分号对改为双层。 其中,因为call语句使用的是双层百分号对,容易使人犯迷糊,所以用得较少,常用的是使用 setlocal enabledelayedexpansion 语句(set是设置的意思,local是本地的意思,enable是能够的意思,delayed是延迟的意思,expansion是扩展的意思,合起来,就是:让变量成为局部变量,并延迟它的扩展行为)。
通过上面的分析,我们可以知道:
[1] 为什么要使用变量延迟?因为要让复合语句内部的变量实时感知到变量值的变化。
[2] 在哪些场合需要使用变量延迟语句?在复合语句内部,如果某个变量的值发生了改变,并且改变后的值需要在复合语句内部的其他地方被用到,那么,就需要使用变量延迟语句。而复合语句有:for语句、if……else语句、用连接符&、||和&&连接的语句、用管道符号|连接的语句,以及用括号括起来的、由多条语句组合而成的语句块。最常见的场合,则是for语句和if……else语句。
[3] 怎样使用变量延迟?
方法有两种:
① 使用 setlocal enabledelayedexpansion 语句:在获取变化的变量值语句之前使用setlocal enabledelayedexpansion,并把原本使用百分号对闭合的变量引用改为使用感叹号对来闭合;
② 使用 call 语句:在原来命令的前部加上 call 命令,并把变量引用的单层百分号对改为双层。
“变量延迟”是批处理中一个十分重要的机制,它因预处理机制而生,用于复合语句,特别是大量使用于强大的for语句中。只有熟练地使用这一机制,才能在for的世界中如鱼得水,让自己的批处理水平更上一层楼。很多时候,对for的处理机制,我们一直是雾里看花,即使偶有所得,也只是只可意会难以言传。希望大家反复揣摩,多加练习,很多细节上的经验,是只有通过大量的摸索才能得到的。
备注:整理本文的参考文献《批处理for语句从入门到精通》
作者:小德cyj
出处:http://www.cnblogs.com/dongzhuangdian
欢迎转载,希望注明出处

