
并发编程之进程
并发编程
并发指多个任务同时被执行,在之前的TCP通信中,服务器在建立连接后需要一个循环来与客户端循环的收发数据


import socket # 服务器的地址 addr = ("127.0.0.1", 8888) c = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, 0) while True: msg = input(">:").strip() c.sendto(msg.encode("utf-8"), addr) data, s_addr = c.recvfrom(1024) print(data.decode("utf-8"))
UDP多人聊天 服务端但服务器并不知道客户端什么时候会发来数据,导致没有数时服务器进入了一个等待状态;此时其他客户端也无法链接服务器, 当客户端发送消息,必须另一个客户端发送消息后才能再次发送,不能连续发送给多条消息,就是因为在发送完之后,客户端处于等待接受状态,很明显这是不合理的,学习并发编程就是要找到一种方案,让一个程序中的的多个任务可以同时被处理
了解并发编程
并发编程是为了提高CPU工作效率而催生出的一项技术.单核CPU在同一时间只能执行同一个程序中的指令,当这个程序处于I/O (输入和输出)状态或者sleep状态,是不使用CPU的,如果I/O 三秒钟,CPU的主频通常能达到 MHz或者GHz为单位,也就是每秒钟有上百万乃至上亿次的时钟周期,而CPU完成一条指令通常只耗费个位数时钟周期,所以CPU执行指令的速度是很快的,每秒钟上百万至上亿次,没空闲一秒钟就有大量的性能浪费.
并发编程依赖多道技术,包括时间复用和空间复用来让CPU减少空闲
时间复用:
操作系统可以控制硬件和应用程序,当一个CPU正在执行程序,遇到 I/O 时,操作系统会记录下当前程序的一些状态,然后切换到另一个程序让CPU执行, (或者说是程序在抢夺CPU的使用权) 再次遇到 I/O 时 ,又会切换到另一个程序... ... 这样能保证CPU能高效率运算,并且当一个程序使用CPU时间过长,操作系统也会记录下运行状态,切换到另一个程序运行,而由于CPU执行速度很快,一般来切换速度也会比较快,给用户造成了一种,当前有多个程序同时运行的现象...原理就是小学数学中的"统筹算法",正在运行的程序,又叫做进程
空间复用:
内存中同时存放多个程序(注意是程序的数据而不是进程),这样同一时间,内存中就有多个程序,减少了对硬盘的I/O,而对硬盘的操作是很慢的,从而减少了时间,这种技术需要依赖硬件上的实现:内存必须从硬件上就分成多个空间,不然一个程序可以使用另一个程序的数据,安全性就无从可言,比如你的qq程序可以访问操作系统的内存,这意味着你的qq可以拿到操作系统的所有权限。再次就是稳定性,某个进程崩溃之后可能会导致其他进程资源的回收,造成混乱.
多道技术
存在的缺陷是: 如果一个程序是纯计算型,很少需要I/O,多道技术反而会降低它的执行效率!
进程:正在运行的程序
进程是正在执行的一个过程,是对正在运行程序的抽象,也是操作系统在调度和进行资源分配的基本单位。
进程概念起源于操作系统,so,了解进程之前要了解操作系统,前人有云,不再赘述
一 操作系统的作用: 1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口 2:管理、调度进程,并且将多个进程对硬件的竞争变得有序 二 多道技术: 1.产生背景:针对单核,实现并发 现在的主机一般是多核,那么每个核都会利用多道技术 有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个cpu中的任意一个,具体由操作系统调度算法决定。 2.空间上的复用:如内存中同时有多道程序 3.时间上的复用:复用一个cpu的时间片 强调:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,这样才能保证下次切换回来时,能基于上次切走的位置继续运行
进程与程序
进程是正在运行的程序,程序是程序员编写的一堆代码,也就是一堆字符,当这堆代码被系统加载到内存中并执行时,就有了进程。
一个程序是可以产生多个进程的,比如QQ多开,pycharm中同时运行多个py文件,这些py文件都是python程序的子进程,可以通过DOS 命令行tasklist 来查看进程。
from multiprocessing import Process def task(): print("task run") # windows创建子进程时,子进程会将父进程的代码加载一遍,导致重新加载所有的代码造成递归 # 所以将创建子进程的代码放到main下 if __name__=="__main__": p=Process(target=task,name="子进程") # 创建一个表示进程的对象 # print(p) # <Process(子进程, initial)>,python解释器无法创建进程,只有操作系统可以 p.start() # task run,给操作系统发送通知,要求其开启进程
系统会给每个进程分配一个进程编号 PID,在python中可以使用os模块下 os.getpid() 获取pid,在命令行可以使用 tasklist /f /pid xxx 来结束指定的进程。
当一个进程a开启了另一个进程b时,a称为b的父进程,可通过os模块获取父进程的PID(用PPID)。
python中开启子进程的两种方式(此处属于进程中实现并发)
import os from multiprocessing import Process def task(): print("task run") print("self",os.getpid()) print("parent",os.getppid()) # windows创建子进程时,子进程会将父进程的代码加载一遍,导致重复创建子进程 # 所以将创建子进程的代码放到main下 if __name__ == "__main__": p = Process(target=task, name="子进程") print("self",os.getpid()) print("parent",os.getppid()) p.start() # task run,给操作系统发送通知,要求其开启进程 # self 17088 # parent 9324 # task run # self 13368 # parent 17088
# 创建进程的第二种方式,继承Process,覆盖run方法,在子进程启动之后自动执行run方法 from multiprocessing import Process class MyProcesses(Process): def run(self): print("run") if __name__=="__main__": p=MyProcesses() p.start() # run
# 可以自定义进程的属性和行为,来完成一些额外任务 from multiprocessing import Process class MyProcesses(Process): def __init__(self,url): self.url=url super().__init__() # 子类中的方法只有run会自动执行 def run(self): print("下载文件",self.url) def task(self): pass if __name__ == "__main__": p = MyProcesses("www.baidu.com/xx.mp4") p.start() # 下载文件 www.baidu.com/xx.mp4
并发与并行
并发:其是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
并行:同时运行,只有具备多个cpu才能实现并行。指同一个时间有多个进程,比如双核CPU就可以实现双并发,一个核运行一个程序。
同步\异步and阻塞\非阻塞(重点)
同步就是当一个进程发起一个函数(任务)调用的时候,一直等到函数(任务)完成,而进程继续处于激活状态。
在发出一个功能调用时,在没有得到结果之前,该调用就不会返回。按照这个定义,其实绝大多数函数都是同步调用。但是一般而言,我们在说同步、异步的时候,特指那些需要其他部件协作或者需要一定时间完成的任务。 举例: 1. multiprocessing.Pool下的apply #发起同步调用后,就在原地等着任务结束,根本不考虑任务是在计算还是在io阻塞,总之就是一股脑地等任务结束 2. concurrent.futures.ProcessPoolExecutor().submit(func,).result() 3. concurrent.futures.ThreadPoolExecutor().submit(func,).result()
异步情况下是当一个进程发起一个函数(任务)调用的时候,不会等函数返回,而是继续往下执行当,函数返回的时候通过状态、通知、事件等方式通知进程任务完成。
异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立刻得到结果。当该异步功能完成后,通过状态、通知或回调来通知调用者。如果异步功能用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低(有些初学多线程编程的人,总喜欢用一个循环去检查某个变量的值,这其实是一 种很严重的错误)。如果是使用通知的方式,效率则很高,因为异步功能几乎不需要做额外的操作。至于回调函数,其实和通知没太多区别。 举例: 1. multiprocessing.Pool().apply_async() #发起异步调用后,并不会等待任务结束才返回,相反,会立即获取一个临时结果(并不是最终的结果,可能是封装好的一个对象)。 2. concurrent.futures.ProcessPoolExecutor(3).submit(func,) 3. concurrent.futures.ThreadPoolExecutor(3).submit(func,)
阻塞调用是指调用结果返回之前,当前线程会被挂起(如遇到io操作)。函数只有在得到结果之后才会将阻塞的线程激活。有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。 举例: 1. 同步调用:apply一个累计1亿次的任务,该调用会一直等待,直到任务返回结果为止,但并未阻塞住(即便是被抢走cpu的执行权限,那也是处于就绪态); 2. 阻塞调用:当socket工作在阻塞模式的时候,如果没有数据的情况下调用recv函数,则当前线程就会被挂起,直到有数据为止。
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程。
1. 同步与异步针对的是函数/任务的调用方式:同步就是当一个进程发起一个函数(任务)调用的时候,一直等到函数(任务)完成,而进程继续处于激活状态。而异步情况下是当一个进程发起一个函数(任务)调用的时候,不会等函数返回,而是继续往下执行当,函数返回的时候通过状态、通知、事件等方式通知进程任务完成。
2. 阻塞与非阻塞针对的是进程或线程:阻塞是当请求不能满足的时候就将进程挂起,而非阻塞则不会阻塞当前进程
进程的三种状态:
就绪 、运行 和 阻塞
就绪:当进程被CPU"切走",别的程序使用CPU,而自身I/O操作已经执行完,需要CPU来自行的状态
运行:程序自身代码正在被CPU执行
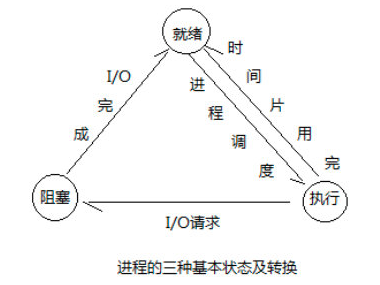
多道技术会在进程执行时间过长或遇到IO时自动切换其他进程,意味着IO操作与,进程被剥夺CPU执行权都会造成进程阻塞
进程的创建
但凡是硬件,都需要有操作系统去管理,只要有操作系统,就有进程的概念,就需要有创建进程的方式,一些操作系统只为一个应用程序设计,比如微波炉中的控制器,一旦启动微波炉,进程就已经存在。
而对于通用系统(跑很多应用程序),需要有系统运行过程中创建或撤销进程的能力,主要分为4种形式创建新的进程
-
系统初始化(查看进程linux中用ps命令,windows中用任务管理器,前台进程负责与用户交互,后台运行的进程与用户无关,运行在后台并且只在需要时才唤醒的进程,称为守护进程,如电子邮件、web页面、新闻、打印)
-
一个进程在运行过程中开启了子进程(如nginx开启多进程,os.fork,subprocess.Popen等)
-
用户的交互式请求,而创建一个新进程(如用户双击暴风影音)
-
一个批处理作业的初始化(只在大型机的批处理系统中应用)
无论哪一种,新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的:
-
在UNIX中该系统调用是:fork,fork会创建一个与父进程一模一样的副本,二者有相同的存储映像、同样的环境字符串和同样的打开文件(在shell解释器进程中,执行一个命令就会创建一个子进程)
-
在windows中该系统调用是:CreateProcess,CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
关于创建的子进程,UNIX和windows
1.相同的是:进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离),任何一个进程的在其地址空间中的修改都不会影响到另外一个进程。
2.不同的是:在UNIX中,子进程的初始地址空间是父进程的一个副本,提示:子进程和父进程是可以有只读的共享内存区的。但是对于windows系统来说,从一开始父进程与子进程的地址空间就是不同的。
进程的终止/
1. 正常退出(自愿,如用户点击交互式页面的叉号,或程序执行完毕调用发起系统调用正常退出,在linux中用exit,在windows中用ExitProcess)
2. 出错退出(自愿,python a.py中a.py不存在)
3. 严重错误(非自愿,执行非法指令,如引用不存在的内存,1/0等,可以捕捉异常,try...except...)
4. 被其他进程杀死(非自愿,如kill -9)
进程的层次结构
无论UNIX还是windows,进程只有一个父进程,不同的是:
1. 在UNIX中所有的进程,都是以init进程为根,组成树形结构。父子进程共同组成一个进程组,这样,当从键盘发出一个信号时,该信号被送给当前与键盘相关的进程组中的所有成员。
2. 在windows中,没有进程层次的概念,所有的进程都是地位相同的,唯一类似于进程层次的暗示,是在创建进程时,父进程得到一个特别的令牌(称为句柄),该句柄可以用来控制子进程,但是父进程有权把该句柄传给其他子进程,这样就没有层次了。
进程并发的实现
两种方式
from multiprocessing import Process import time def test(b): print("子进程执行...") global a a = 10000 print(a) time.sleep(1) if __name__ == '__main__': # windows中 创建子进程会将当前代码执行一遍,如果不写在 这个条件下,会报错,因为子父进程会互相创建、启动 a = 10 p = Process(target=test, args=(a,)) # 创建子进程的对象 p.start() # 向操作系统发送请求,操作系统会申请内存空间,然后把父进程的数据拷贝给子进程,作为子进程的初始状态 在这一步是创建和启动子进程 print(a) # 正是因为 CPU执行速度比创建子进程速度快,所以这行代码先于print("子进程执行...")执行 time.sleep(2) print(a) # 仍然为10 所以子进程中的数据更改不会影响到父进程 即 内存是相互独立的
from multiprocessing import Process class MyProcess(Process):# 继承Process def __init__(self, url):# 必须 覆盖__init__方法 self.url = url super().__init__() def run(self):# 覆盖run方法 这个方法在p.start()后自发运行 print("下载器") print("hello,world!") if __name__ == '__main__': p = MyProcess("www.baidu.com/a.mp4") p.start()
Process 里面具有以下方法和属性
from multiprocessing import Process a=100 def task(): global a a=0 print("子进程的",a) if __name__=="__main__": p=Process(target=task) p.start() print("自己的",a) # 自己的 100 # 子进程的 0 # 子进程里改变的数据不会影响父进程,先打印自己的是因为子进程创建需要时间
from multiprocessing import Process import time def task(): print("上传文件") time.sleep(2) print("上传结束") if __name__=="__main__": p=Process(target=task) p.start() p.join() # 提高子进程优先级,使其比父进程高,当CPU切换时,优先切子进程。故不用 p.wait()。 print("上传成功")
from multiprocessing import Process import time def task(num): print("现在是%s号"%num) time.sleep(2) # print("上传结束") if __name__ == "__main__": start_time=time.time() for i in range(5): p = Process(target=task,args=(i,)) p.start() # p.join() # 并不会并发,逐个执行 p.join() # 并不会并发,只有最后一个才会等,统计的是最后一个的时间 print(time.time()-start_time) print("over")
from multiprocessing import Process import time def task(num): print("现在是%s号"%num) time.sleep(2) # print("上传结束") if __name__ == "__main__": start_time=time.time() ps=[] for i in range(5): p = Process(target=task,args=(i,)) p.start() ps.append(p) for p in ps: p.join() print(time.time()-start_time) print("over")

