python进阶之 ——模块与包
一、模块
1.什么是模块:模块就是一系列功能的集合体
模块的四个通用类别
- I.使用python编写的.py文件(自定义模块包括第三方模块)
- II.已被编译为共享库或DLL的C或C++扩展
- III.把一系列模块组织到一起的文件夹(注:文件夹下有一个__init__.py文件,该文件夹称之为包)
- IV.使用C编写并链接到python解释器的内置模块
2.为什么用模块
- I. 使用内置的或者第三方的模块的好处是:拿来主义,极大提升开发效率
- II. 使用自定义的模块的好吃是:将程序各部分组件共用的功能提取取出放到一个模块里,其他的组件通过导入的方式使用该模块,该模块即自定义的模块,好处是可以减少代码冗余
3.如何用模块
将模块导入到执行文件run.py中查看
4.首次导入模块会发生三件事
- I.会产生一个模块的名称空间
- II.执行spam.py文件的内容,将产生的名字丢到模块的名称空间里
- III. 在当前执行文件中拿到一个名字spam,该名字指向模块的名称空间
若为from 模块名 import ...则拿到一个spam中的定义的函数的名字如read1,其指向模块的名称空间中的read1
当模块名过长时,可用缩写代替,其格式为 import 模块名 as 缩写
需注意,模块名为纯小写加下划线
import
优点:指名道姓地问某一个名称空间要名字,不会与当前执行文件名称空间中的名字冲突
缺点:引用模块中的名字必须加前缀(模块名.),使用不够简洁
from...import
优点:引用模块中的名字不用加前缀(模块名.),使用更为简洁
缺点:容易与当前执行文件名称空间中的名字冲突
如果把一个功能拿到文件外单独当作一个模块,而且使用时不能改变它的调用方式,或者追求简洁,使用from...import 的导用方式,但是要注意有无名称冲突
或者run文件在根目录,src在子文件夹core内,不改变环境变量,就需要使用from core import src 导入src模块,再用src.func1() 的方式调用功能。
二、模块的搜索路径
一个py文件就是一个模块,在导入时必须从某一个文件夹下找到该py文件,模块的搜索路径指的就是在导入模块时需要检索的文件夹们
查找模块路径的优先级
- 1.内存
- 2.内置模块
- 3.sys.path(是以执行文件为准的)其第一个路径为执行文件所在文件夹
若所找的文件所在文件夹与执行文件所在文件夹同属一个根目录(即它们为同级时),用 import sys sys.path.append(r'所找文件所在地址/目录')
注意:若写的程序,只有一个执行文件,其它的文件虽然也可能导入模块,但是参照的环境变量是以执行文件为参照
三、区分python文件的两种用途__name__
1.用途
- I.直接右键运行,当作执行文件
- II.当作模块被导入
2.区分
- I.当文件被当作执行文件时,__name__的值为__main__
- II.当文件被当作模块导入时,__name__的值为模块名
四、软件开发的目录规范
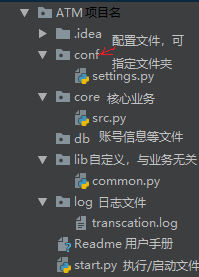


#-------------start.py(其在根目录下时无需添加项目根目录所在绝对路径) from core import src src.run() #--------------setting.py import os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) LOG_PATH=r'%s\log\transcation.log' %BASE_DIR #---------------src.py from lib import common def register(): print('注册。。。') def login(): print('登陆。。。') def shopping(): print('购物。。。') def withdraw(): print('提现。。。') # 调用日志功能 common.logger('买包花了7K') func_dic={ '1':register, '2':login, '3':shopping, '4':withdraw } def run(): while True: print(""" 退出 注册 登陆 购物 提现 """) choice=input('请输入指令>>>: ').strip() if choice == '0':break if choice in func_dic: func_dic[choice]() else: print('请重新输入指令。。。') #-----------------------common import time from conf import settings def logger(msg): with open(r'%s' %settings.LOG_PATH,mode='at',encoding='utf-8') as f: f.write('%s %s\n' %(time.strftime('%Y-%m-%d %H:%M:%S'),msg)) #--------------transcation,log 2018-12-05 15:55:17 买包花了7K
五、包
1、循环导入:A引用B,B引用A
模块循环/嵌套导入抛出异常的根本原因是由于在python中模块被导入一次之后,就不会重新导入,只会在第一次导入时执行模块内代码。项目中应该尽量避免出现循环/嵌套导入,如果出现多个模块都需要共享的数据,可以将共享的数据集中存放到某一个地方
解决循环导入的两种方案
- 1.数据被导入过了,不会重新导入。再次导入模块时,数据没有存在模块中。此时须将导入语句放到最后。
- 2.执行文件并不等于导入文件。此时须将导入语句放到函数中
2、包:含有__init__.py的文件夹,其也是模块
1.创建包的目的:被导入使用。包的作用:从文件夹级别管理代码
随着功能增多,我们需要用模块去组织功能,而随着模块越来越多,我们需要用包将模块文件组织起来,来提高程序的结构性和可维护性
2.注意:
- 1)关于包相关的导入语句也分为import和from...import...,无论在什么位置,在导入时都必须遵守一个原则:凡是在导入时带点的,左边都必须是一个包(即包名. )否则非法。如item,subitem,subsubitem,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
- 2)import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
- 3)包A和包B下有同名模块也不会冲突
__init__.py文件的作用:初始化包,导入包中的模块内容。一个包通常包含多个py文件,为了使用方便,可以在__init__中导入需要使用的内容
3.绝对导入和相对导入
绝对导入:以执行文件的sys.path为起点开始导入
优:执行文件与被导入的模块中都可以使用
缺:所有导入都是以sys.path为起点,导入麻烦
相对导入:参照当前文件所在的文件夹为起始开始查找
优:导入更简单
缺:只能在导入包中模块时才能使用
.代表当前所在文件的文件夹,..代表上一级文件夹,...代表上一级的上一级文件夹
注意:
- 1.相对导入只能用于包内部模块之间的相互导入,导入者与被导入者都必须存在于一个包中,不能超过顶层包
- 2.attempted relative import beyond top-level package # 试图在顶级包之外使用相对导入是错误的,即必须在顶级包内使用相对导入,每增加一个.代表跳到上一级文件夹,而上一级不应该超出顶级包
