

消息中间件面试题之kafka
Kafka的特性
1.消息持久化
2.高吞吐量
3.扩展性
4.多客户端支持
5.Kafka Streams
注意:当你不会说的时候,就围绕着kafka你知道的kafka的功能来说,比方说消息的持久化机制。
说一说Kafka你熟悉的参数?
创建生产者对象时有三个属性必须指定
bootstrap.servers:说白了就是指定都有哪些节点
key.serializer:键的序列化器
value:serializer: 值的序列化器
acks:指定了必须要有多少个分区副本收到消息,生产者才会认为写入消息是成功的,这个参数对消息丢失的可能性有重大影响。
acks=0:⽣产者不等待broker对消息的确认,只要将消息放到缓冲区,就认为消息已经发送完成。
acks=1: 表示消息只需要写到主分区即可,然后就相应客户端,而不等待副本分区的确认。
acks=all: 表示消息需要写到主分区,并且会等待所有的ISR副本分区确认记录。
retries:重试次数,当消息返送出现错误的时候,系统会重发消息。根客户端收到错误时,重发一样。
compression.type:指定消息的压缩类型。
max.request.size:控制生产者发送请求的最大大小。
request.timeout.ms:客户端等待请求响应的最大值。说白了就是一个超时时间。
batch.size:当多个消息被发送同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次内存被填满后,批次里的所有消息会被发送出去。
kafka中,可以不用zookeeper么?
在新版本的kafka中可以不使用zookeeper。但是kafka本身是自带zookeeper的。但是为了安全考虑,我们通常会外接我们自己的zookeeper。现在的新版本可以使用Kafka with Kraft,就可以完全抛弃zookeeper。
为什么Kafka不支持读写分离?
1、数据一致性问题:数据从主节点转到从节点,必然会有一个延时的时间窗口,这个时间窗口会导致主从节点之间的数据不一致。
2、延时问题:Kafka追求高性能,如果走主从复制,延时严重
Kafka中是怎么做到消息顺序性的
一个 topic,一个 partition,一个 consumer,内部单线程消费,最傻瓜式的一种做法。
构建ProducerRecord消息的时候,我们可以通过构造方法指定要发送到哪个分区。
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) {
}
Kafka为什么那么快?
- 利用 Partition 实现并行处理
- 顺序写磁盘
- 充分利用 Page Cache
- 零拷贝技术
- 批处理
- 数据压缩
kafka怎样做消息广播(面试的时候有被问到)
这里需要问面试官一下,你是想要实现消息的广播发送还是消息的广播消费。
消息的广播发送:
Kafka 本身不提供直接的“广播”机制,但可以通过创建多个主题(topics)并将消息发送到每个主题来实现广播效果。每个订阅者只能看到他所订阅的主题中的消息。
消息的广播消费:
总所周知,我们每一个消费组中只有一个消费者能消费到某个主题下的那一条消息。这个时候我们可以通过在每个消费者分组上加上UUID,这样就能保证每个项目启动的消费者的分组是不同的。这样就能够达到广播消费的目的了。
kafka中的消息粒度,partition下面还有一个消息存储的粒度,叫什么(面试的时候有被问到)
Kafka中的partition下面存储的是LogSegment。每个partition在物理上被分割成多个大小相等的LogSegment,每个LogSegment由一个数据文件(.log)和一个索引文件(.index)组成。数据文件存储实际的消息数据,而索引文件存储消息的索引信息,包括消息的物理偏移地址等元数据。
如果我配置了7天,那么我消费的时候如果指定的是earlist的话,那么有没有可能消费到7天之外的数据。(面试的时候有被问到)
有可能
https://blog.csdn.net/weixin_42305433/article/details/109731388
kafka消息删除的粒度,是消息级别的删除吗(面试有被问到)
Kafka的删除策略以segment为单位,而非单条消息。
kafka的消息是以主题为单位进行归类的,各个主题之间彼此是独立的,互不影响。
每个主题又可以分为一个或多个分区。
每个分区各自存在一个记录消息数据的日志文件。
分区日志文件中包含很多的LogSegment(也就是说日志分段),默认情况下一个LogSegment是1G。
kafka一共有两种消息删除策略,一种是消息删除,一种是消息压缩。
消息删除:在Kafka中,消息一旦被写入到分区中,就不可以被直接删除。这是因为Kafka的设计目标是实现高性能的消息持久化存储,而不是作为一个传统的队列,所以不支持直接删除消息。
然而,Kafka提供了消息的过期策略来间接删除消息。具体来说,可以通过设置消息的过期时间(TTL)来控制消息的生命周期。一旦消息的时间戳超过了设定的过期时间,Kafka会将其标记为过期,并在后续的清理过程中删除这些过期的消息。
Kafka的清理过程由消费者组中的消费者来执行。消费者消费主题中的消息,并将消费的进度提交到Kafka。一旦消息被提交,Kafka就可以安全地删除这些消息。
另一方面,如果需要从Kafka中完全删除消息,可以通过设置合适的保留策略来实现。Kafka支持两种保留策略:基于时间和基于大小。基于时间的保留策略会根据消息的时间戳来删除旧的消息,而基于大小的保留策略会根据分区的大小来删除旧的消息。可以根据业务需求选择适合的保留策略。
需要注意的是,删除消息并不会立即释放磁盘空间。删除的消息只是被标记为删除,并在后续的清理过程中才会真正释放磁盘空间。因此,即使消息被删除,磁盘空间也不会立即释放,而是会在清理过程中逐渐释放。
消息压缩会将所有key相同的消息进行合并。这个一般使用在大数据领域。
kafka为什么这么快?(面试有被问到)
kafka对于大数据是支持的,比如说Hadoop
主要有以下这么四点:
磁盘顺序
读写页缓存:直接使用操作系统的页缓存特性提高处理速度,进而避免了JVM GC带来的性能损耗。
零拷贝
批量操作:kafka也支持消息压缩和批量发送数据
kafka文件删除有两种方式,一种是基于时间,一种是基于分区文件的大小
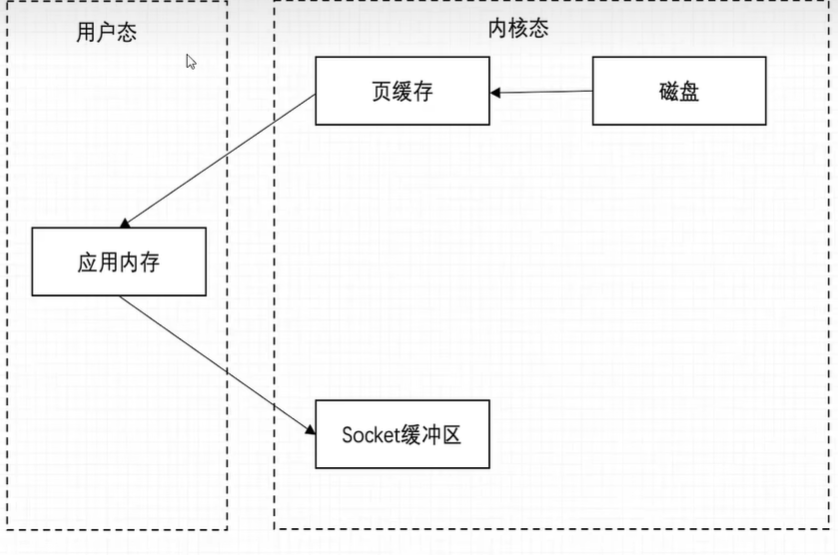
kafka几个核心点(面试有被问到)
acks:
该选项控制着已发送消息的持久性。
acks=0 :⽣产者不等待broker的任何消息确认。只要将消息放到了socket的缓冲区,就认为消息 已发送。不能保证服务器是否收到该消息, retries 设置也不起作⽤,因为客户端不关⼼消息是 否发送失败。客户端收到的消息偏移量永远是-1。
acks=1 :leader将记录写到它本地⽇志,就响应客户端确认消息,⽽不等待follower副本的确 认。如果leader确认了消息就宕机,则可能会丢失消息,因为follower副本可能还没来得及同步该 消息。
acks=all :leader等待所有同步的副本确认该消息。保证了只要有⼀个同步副本存在,消息就不 会丢失。这是最强的可⽤性保证。等价于 acks=-1 。默认值为1,字符串。可选值:[all, -1, 0, 1]
retries
设置该属性为⼀个⼤于1的值,将在消息发送失败的时候重新发送消息。该重试与客户端收到异常 重新发送并⽆⼆⾄。允许重试但是不设置 max.in.flight.requests.per.connection 为1,存 在消息乱序的可能,因为如果两个批次发送到同⼀个分区,第⼀个失败了重试,第⼆个成功了,则 第⼀个消息批在第⼆个消息批后。int类型的值,默认:0,可选值:[0,...,2147483647]
kafka消费消息的时候,我们可以使用同步提交offset也可以异步提交offset。
kafka怎样保证消息不丢失(面试有被问到)
在生产者端,我们可以设置acks的值,来保证消息不丢失
在broker端,我们可以设置分区和副本的机制来保证消息的不丢失。
在消费者端,我们可以使用在消息被正确消费之后手动提交偏移量的方式来保证。
也可以在消息投递之前,添加一张日志表(采用顺序写的方式)来保证。
kafka生产者都干了哪些事情?(面试有被问到)
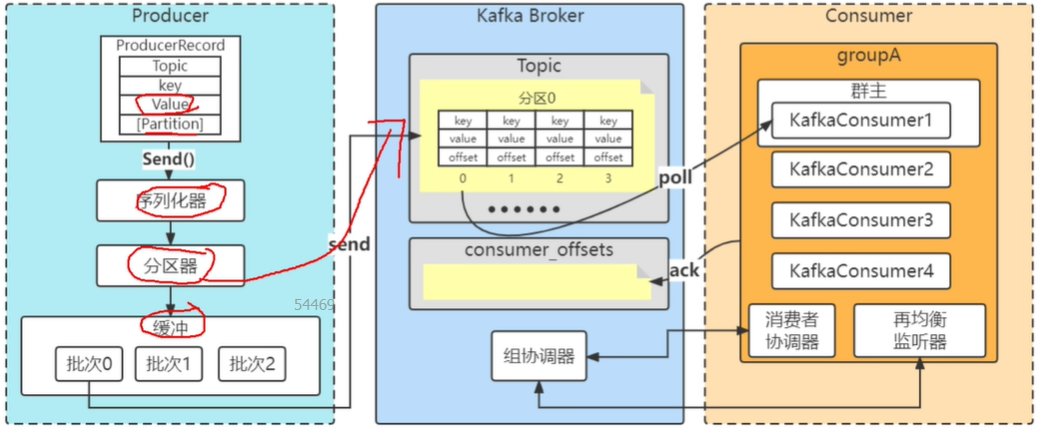
为什么kafka在客户端发送的时候需要做一个缓存区?
1.为了减少IO的开销(单个 -> 批次)
2.减少GC
缓存发送:主要是这两个参数控制(只要1个满足)
大小:batch.size = 16384(16K)
时间:linger.ms = 0(说白了就是只要有了消息就会进行发送)
序列化器:将消息对象序列化为字节流,以便存储和传输。
分区器:根据配置的分区策略,将消息分配到不同的分区中
kafka生产者是怎样将消息发送到broker上面的?(面试有被问到)
后台是通过一个sender线程使用TCP的方式发送到broker上面的。当然它是自定义的TCP协议。
kafka搭建为什么要使用zookeeper(面试有被问到)
1.每个broker在启动的时候都会向zookeeper中注册自己的信息(ip port),broker创建的节点是临时节点类型,如果broker发生宕机,这个临时节点也会被删除,这个时候就会发生主从切换。
2.每个topic下面可能会有多个分区信息,这个时候topic和对应分区以及broker的关系也会被记录到zookeeper中。
3.生产者的负载均衡,因为每个broker都会注册自己的信息,每个broker上线下线,生产者都能够感知到,这样生产者就能够负载均衡的发送消息了。
4.消费者的负载均衡,每个消费者分组都包含了若干个消费者,每条消息只会发送到组里面的一个消费者中。同上。
5.维系分区和消费者的关系。
6.消息消费的偏移量,也就是每个分区消息的消费进度信息。
搭建kafka集群的时候需要注意什么?(面试有被问到)
我总结有这么以下几点:
需要搭建zookeeper集群
kafka的安装配置,肯定是要改配置文件的。
网络配置:因为是broker集群,我们一定要确保每个节点都能够正常的进行通信,如果不能通信的话,这个时候我们就需要关闭防火墙,或者是开发某个端口。
版本一致性:确保Kafka集群的各个节点使用相同版本的Kafka,以避免兼容性问题。
Topic分区和副本配置:根据需求设置Topic的分区数和副本数,副本数可以保证数据的冗余和可用性1。
Broker ID唯一性:每个Kafka节点的broker.id必须是唯一的,且集群中的每个节点都应该有一个唯一的标识1。
环境准备:包括节点规划、JDK环境配置等,确保每个节点都安装了JDK,因为Kafka需要Java运行环境2。
说一下kafka怎样保证消息的幂等性(面试有被问到)
说白了就是不重复消费
就说redis的setnx
说一下怎样搭建kafka集群(面试有被问到)
要搭建Kafka集群,您需要准备以下条件:
- 至少三台机器(或者在同一台机器上运行多个虚拟实例)。
- 相同的Kafka版本在所有机器上。
- 一个ZooKeeper集群,用于管理Kafka集群状态。
以下是搭建Kafka集群的基本步骤:
- 安装Java。
- 下载并解压Kafka到每台机器上。
- 配置ZooKeeper集群(如果尚未设置)。
- 配置Kafka服务器属性,例如
server.properties。
以下是配置Kafka集群的关键设置示例:
broker.id: 每个Kafka实例的唯一标识。
listeners: 监听的地址和端口。
zookeeper.connect: ZooKeeper集群的地址。
示例server.properties配置:
broker.id=1
listeners=PLAINTEXT://:9092
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
对于其他Kafka实例,您需要更改broker.id来保证唯一性,并相应更改listeners和zookeeper.connect中的配置。
启动Kafka集群通常按以下顺序进行:
- 启动ZooKeeper集群。
- 启动Kafka服务。
启动Kafka服务的命令通常是:
kafka-server-start.sh /path/to/your/kafka/config/server.properties
确保每个Kafka实例的配置文件都已正确配置,并且所有端口都没有被其他服务占用。
什么是 Rebalance 机制
在 Kafka 中,Rebalance(再平衡)是一种机制,用于在消费者组(Consumer Group)内重新分配分区(Partition)的所有权。
当有消费者加入或离开消费者组、或者主题(Topic)的分区数量发生变化时,就会触发 Rebalance。它的目的是确保消费者组内的每个消费者能够公平合理地消费消息,避免某个消费者负担过重或部分消息得不到处理。
kafka自动提交的时候设置的超时时间是多少呀
Kafka 消费者默认的自动提交间隔时间是 5 秒。这个时间是通过auto.commit.interval.ms参数来设置的。这意味着每隔 5 秒,消费者会自动将它所消费到的消息的偏移量提交给 Kafka 集群。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
Properties props = new Properties();
// 设置其他必要的消费者配置参数,如bootstrap.servers等
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS, "3000");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 后续的消费者操作代码
}
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2020-09-13 redis测试100万并发请求 redis-benchmark -h localhost -p 6379 -c 100 -n 10000