

Redis常见面试题
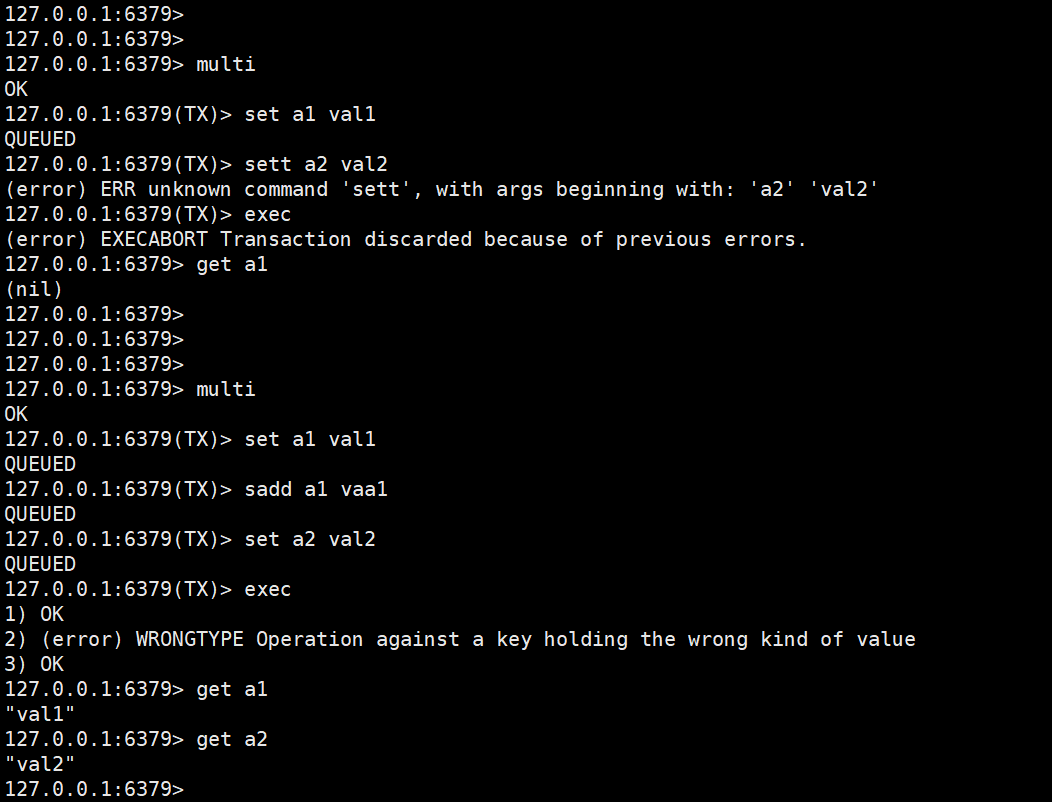
怎么理解Redis中事务?(面试有被问到)
事务表示一组动作要么都执行,要么都不执行。
命令:
multi 开启事务,也就是说会将下面要执行的命令先写入到Redis的队列当中。
exec 提交事务 ,也就是说执行队列当中的命令。
discard 回滚事务
redis中的事务是弱事务,主要体现在事务回滚机制上,Redis只能对基本的语法错误进行判断。它只支持语法错误的检查,也就是说当你的命令中有这种拼写错误的命令的时候,这个时候他是能够进行事务的回滚的。
但是当有运行时错误的时候,已经执行成功的命令他是不能够进行事务回滚的。
为什么要使用pipeline
这玩意是管道的意思,就是说将一组redis命令通过管道发送给redis服务端,执行完成后再一起返回。相较于一条一条的发送执行返回结果,提高了效率。
Redis的过期策略以及内存淘汰机制?
redis的过期策略采用的是定期删除 + 惰性删除。
redis会每100ms进行一次扫描,看看是否有过期的key,有过期key则删除。需要说明的是,redis不是每隔100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。 于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
内存淘汰策略:就是redis在内存快满的时候,根据一定的策略主动删除一些键值对,以释放内存空间并保持系统的稳定性。
1.noeviction(不淘汰策略): 当内存不足以容纳新写入数据时,redis将新写入的命令返回错误。这个策略确保数据的完整性,但会导致写入操作失败。
2.allkeys-lru(最近最少使用): 尝试删除最少使用的键(LRU),使得新添加的数据有空间存放。
3.volatile-lru(最近最少使用): 从设置了过期时间的键中选择最少使用的键进行删除。该策略优先删除最久未被访问的键,保留最常用的键。
4.allkeys-random: 回收随机的键使得新添加的数据有空间存放。
5.volatile-random(随机删除): 从设置了过期时间的key中随机选择一个进行删除。
6.volatile-ttl(根据过期时间优先): 从设置了过期时间的key中选择剩余时间最短的key进行删除。该策略优先删除剩余时间较短的key,以尽量保留剩余时间更长的key.
什么是缓存穿透?如何避免?
缓存穿透:指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。
解决方案:1.查询返回的数据为空,仍把这个空结果进行缓存,但过期时间会比较短;2.布隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对 DB 的查询。
什么是缓存雪崩?如何避免?
缓存雪崩:设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多 key,击穿是某一个key 缓存。
解决方案:将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
Redis如何解决key冲突?
遇到hash冲突采用链表进行处理
Redis持久化方式有哪些?有什么区别?
rdb文件比较小,保存的是一个内存快照,但是容易丢失数据。
aof文件比较大,持久化的速度比较慢。但是不容易丢失数据。
如何保证缓存与数据库双写时的数据一致性
第一种方案:采用延时双删策略
具体的步骤就是:
先删除缓存;
再写数据库;
休眠500毫秒(但是休眠多长时间不好把控);
再次删除缓存。
第二种方案:异步更新缓存(基于订阅binlog的同步机制)
技术整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
Cache Aside Pattern(旁路缓存模式):对于写请求,先更新数据库,再删除缓存。
Redis集群方案什么情况下会导致整个集群不可用?
1.当访问一个 Master 和 Slave 节点都挂了的槽的时候,会报槽无法获取。
2.当集群 Master 节点个数小于 3 个的时候,或者集群可用节点个数为偶数的时候,基于 fail 的这种选举机制的自动主从切换过程可能会不能正常工作,一个是标记 fail 的过程,一个是选举新的 master 的过程,都有可能异常。
什么是缓存击穿?如何避免?
缓存击穿:数据库中有,缓存中没有。缓存击穿实际就是一个并发问题,一般来说查询数据,先查询缓存,有直接返回,没有再查询数据库并放到缓存中之后返回,但这种场景在并发情况下就会有问题,假设同时又100个请求执行上面
逻辑的代码,则可能会出现多个请求都查询数据库,因为大家同时执行,都查到了缓存中没有数据。
解决方案:加锁。如果是单机部署,则可以使用JVM级别的锁,如lock、synchronized。如果是集群部署,则需要使用分布式锁,如基于redis、zookeeper、mysql等实现的分布式锁。
五种基本数据类型的使用场景(面试有被问到)
https://blog.csdn.net/qq_32534855/article/details/105515146
有被问到你们redis中的hash数据类型用来存放什么数据。
答案:Hash类型主要用于存储键值对的数据结构。这种数据结构适用于存储用户信息、商品信息、配置项等具有多个属性的对象。
redis的持久化方式
rdb持久化:在指定的时间间隔内将内存中的数据集快照写入磁盘(以二进制序列化的形式),每次都是从redis中生成一个快照进行数据的全量备份。速度比较快。但是可能会丢失指定时间间隔内的数据。
aof持久化机制:对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在redis重启的时候,可以通过回放aof日志中的写入指令来重新构建整个数据集。效率不如rdb快,但是最多丢失1s内的数据。
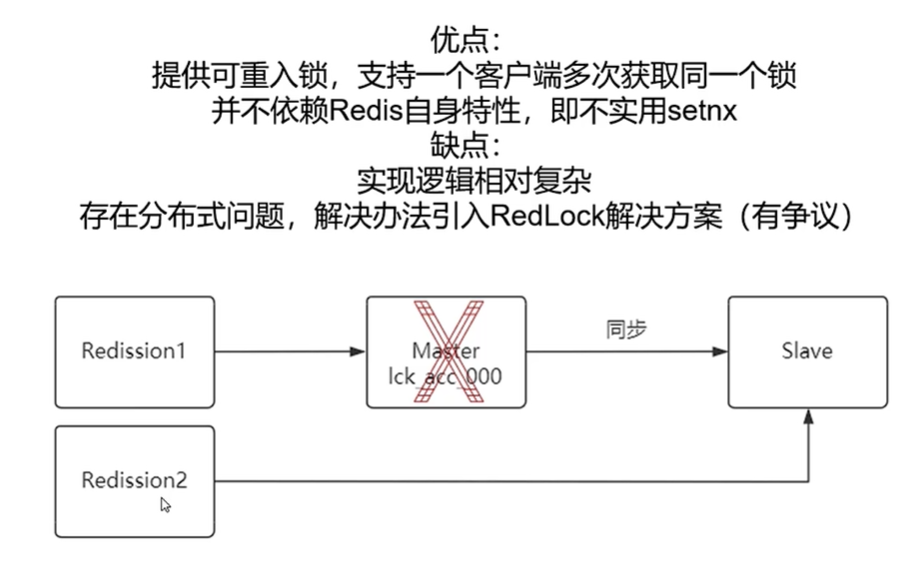
基于Redis、ZooKeeper、数据库实现分布式锁的优缺点
使用分布式锁的目的,是为了保证同一时间只有一个 JVM 进程可以对共享资源进行操作。
基于数据库实现分布式锁:
这种方式实现简单,易于控制,能轻松处理一些容易发生死锁或竞争问题。
但是由于数据库锁会引起严重的性能瓶颈,特别是当锁的数量比较大的时候,会导致系统性能的下降。
基于redis实现分布式锁:
这种方式使用redis提供了高效的获取锁和释放锁的操作,不需要像使用数据库那样频繁的读写数据库,使用起来非常高效。
redisson中有一个看门狗的机制,它会在你获取锁之后,每隔 10 秒帮你把 key 的超时时间设为 30s,就算一直持有锁也不会出现 key 过期了。“看门狗”的逻辑保证了没有死锁发生。
但是,redis获取锁的方式简单粗暴,如果获取不到锁,会不断尝试获取锁,比较消耗性能。redis提供的是基于内存的缓存机制,如果redis服务器负载过重或内存不足,可能会导致获取锁和释放锁的操作变得缓慢,从而影响系统的性能。redis比较适合高并发场景。
基于zookeeper实现分布式锁:
zookeeper天生定位就是分布式协调,强一致性。如果获取不到锁,可以添加一个监听器,不用一直轮询阻塞,性能消耗比较小。
这种方式可以很好的解决数据库锁引起的性能瓶颈问题,因为zookeeper提供了高效的死锁检测和解决机制。
但是zookeeper不适合做大规模的分布式系统,因为它需要维护大量的状态信息。
Cache Aside
首先,先说一下,这是一个老外提出的缓存更新套路,写了一本书《Cache Aside pattern》。其中就指出:
失效:应用程序先从 缓存 中获取数据。如果没有找到,则从数据库中读取数据,然后再放到缓存中。
命中:应用程序从 缓存中 获取到数据,直接返回。
更新:先把数据存到数据库中。成功后,再让缓存失效。
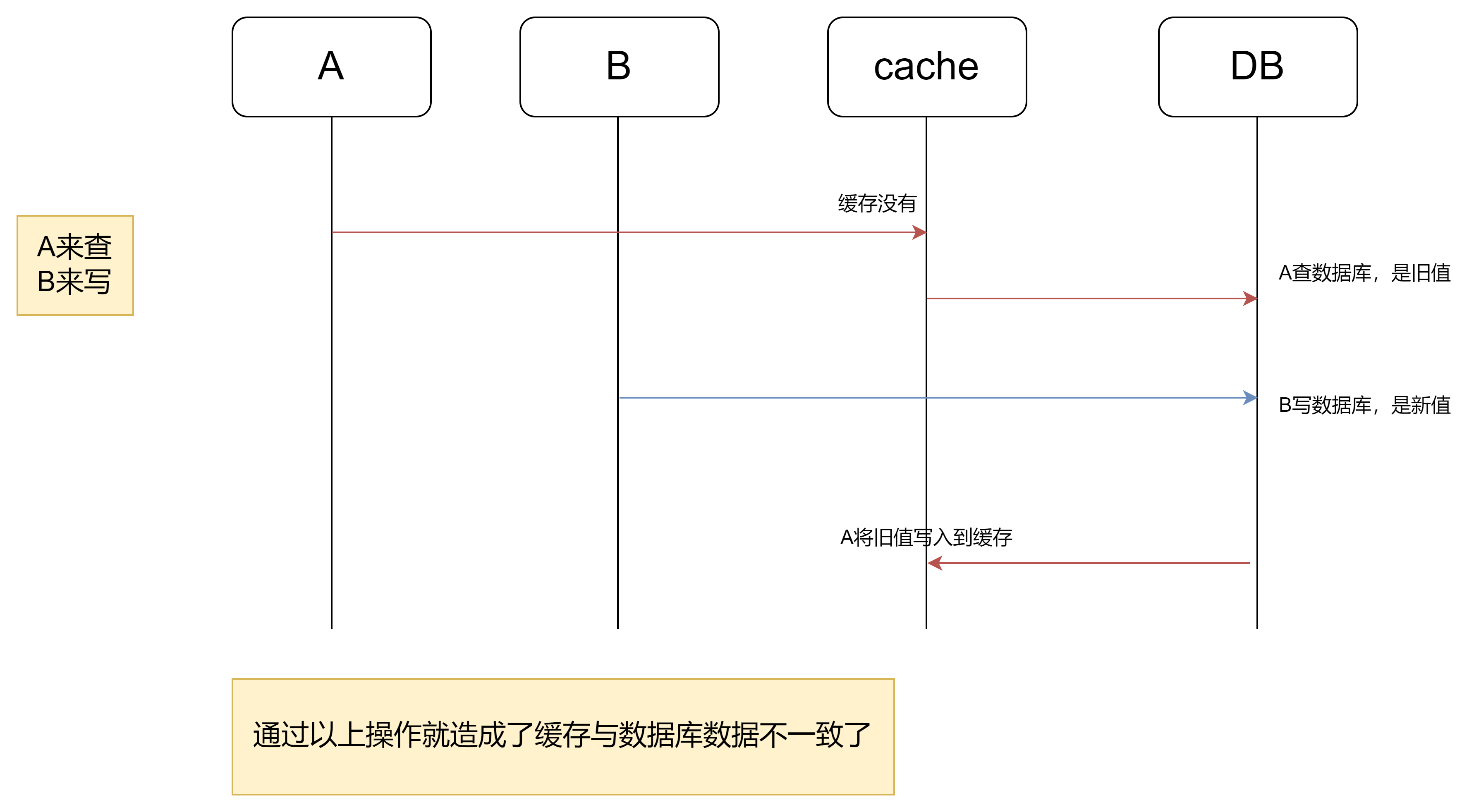
这件事情会发生,那么发生的概率多大呢?
发生上述情况有一个先天性条件:
1.读操作时,缓存中无数据,这样它才会去数据提供方取数据。
2.读操作进行的同时,存在一个写操作。
3.读操作在数据提供方中读取数据的时长大于写操作。这个就很难了。
4.在读写操作并发时,读取到的是旧日值,算是一半一半的概率吧。
就一条,读操作正常情况下,比写操作快很多,所以上述4条同时满足的概率是极低的。
(PS:就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。
可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步(2)更短,这一情形很难出现。
PS:如果真的出现写操作比读操作快的话,那么我们可以采用延迟双删的策略来解决,当然这只能是缓解。
Cache aside 机,制是一种 简单有效的缓存更新机制,应用非常广泛,所以叫做cache aside,缓存在边上。就是说以数据库为主,写完有空再处理边上的 缓存。
Read/Write Through Pattern [读写穿透]
在Cache Aside中,有概率虽然很低出现数据不一致的情况,我们也用了延迟双制,但还是比较复杂。但要想避免缓存不一致的出现也很简单即进行写入操作时,直接将结果写入缓存,而再从缓存同步写入到数据提供广写入数据提供方操作结束后,写入操作才被返回。
这就是Read/Write Through写入机制。
在这种机制下,调用方只需要和缓存打交道,而不需要关心缓存后方的数据提供方。而由缓存来保证自身数据和数据提供方的一致性。
结论:读操作只和缓存打交道,直接读取缓存的结果;写操作的话,调用方写入缓存,再由缓存同步写入数据提供方。(PS:说白了读写只和缓存打交道了)
和Cache-Aside的区别?
在Cache Aside机制中,数据写入缓存的操作,是由调用方的查询结果触发的,
而在Read/write through 机制中,则需要缓存在启动时,自身完成将所有数据从数据提供方读入缓存的过程(在项目启动的时候,其实初始化什么也没有,也没有什么需要读取的,一会有修改,缓存就是新的数据,也不用读)。
比较一下Cache Aside和Read/write through机制。在Cache aside中,缓存只是一个辅助的存在,即使缓存不工作,调用方也可以通过数据提供方完成所有的读写操作,正如其名,缓存在边上,像胯子。
而在Read/write through中,缓存直接对接了调用方,屏蔽了数据提供方,这就意味着缓存系统不可或缺,要求缓存十分可靠。
redis怎样实现分布式锁:
我们可以简单的使用redis的setnx命令来实现分布式锁。
Redisson和Redis的关系是客户端和服务器端的关系。 Redisson是一个基于Redis的Java客户端库,它提供了对Redis的丰富功能的高级封装和抽象,使得Java开发者可以更轻松地与Redis进行交互。
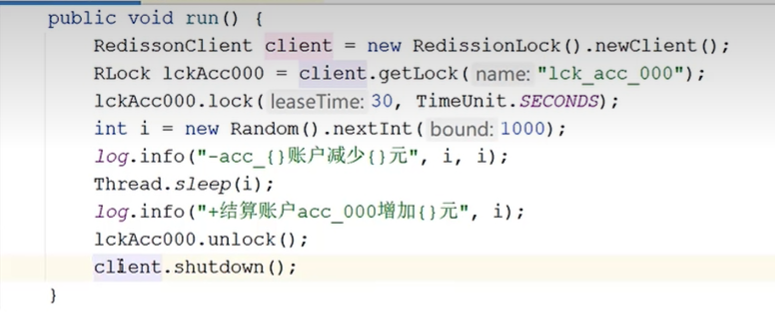
加锁:
redisson底层是基于lua脚本来实现的上锁,锁的默认过期时间是30秒。当然,Redisson底层引入了watch dog(看门狗)机制,每隔10s会来查看我们的任务有没有执行完,如果没有执行完的话,那么会给锁进行续期。
当然,如果我们的任务执行完了之后,我们可以手动调用unlock方法进行锁的释放;还有一种情况就是当我们的应用程序因为某种原因挂掉了,那么这个时候watch dog自然也会失效,这个时候锁会过上个一定时间也会自动释放。
释放锁:
redisson的上锁是支持可重入的,如果我们要实现细粒度的上锁,可以使用。
redisson使用标准的hash类型来进行锁的控制,他是支持重入的。
库存防超卖
商品秒杀巧用redis与lua脚本解决库存防超卖问题
我们可以使用redis加lua脚本的方式来实现库存防超卖。
lua脚本在redis中有什么作用 (面试有被问到)
要想回答好这个问题,我们可以从以下几个方面进行回答。
并发编程的三大特性:原子性、可见性、有序性。
1.什么是原子性?
在 Java 编程中,有两个场景中提到了原子性。一个是数据库事务的 ACID 四大特性中的原子性,它是指"数据库操作要么都成功执行,要么都回滚!";另外一个则是并发编程中的三大特性之一的原子性,它是指"线程的操作,不可被拆分,不可被中断!"
该面试题中的原子性则主要是指并发编程中的原子性!
2.什么是 Lua 脚本?
Lua 脚本是一种使用 C 语言编写的轻量小巧的脚本语言,它设计的目的就是为了嵌入到应用程序中,并为应用程序提供灵活的扩展和定制能力。
从 Redis 2.6.0 版本开始,支持通过内置的 Lua 脚本解释器,使用 EVAL 命令对 Lua 脚本进行操作。
3.为什么 Lua 脚本可以保证原子性?
**最主要的原因有两点:一个是 Redis 命令的执行采用的是单线程模型;另外一个则是 Redis 会把, Lua 脚本作为一个整体单独执行。基于以上两点,Redis 在执行一段 Lua 脚本期间,是不会被其他客户端的请求指令所中断的!只有在该段 Lua 脚本执行结束后,其他被放入到队列中进行排队的客户端的请求指令才会被依次执行,因此 Redis 可以保证这些每个任务的执行都是原子性的!
4.Lua 脚本执行失败会怎么样?
类似于 Redis 的事务机制,如果 Lua 脚本执行期间,发生运行时错误,Lua 脚本也是不会回滚的。但是,两者也有区别,如果Redis 的事务在运行时某个指令发生了错误,该指令的前后指令的执行是不受影响的;而 Lua 脚本则稍微有些不太一样,如果在执行期间某个指令发生错误,该指令前的所有指令是可以正常执行的;但是,该指令后续的脚本将不会被执行!
秒杀的时候lua脚本是怎么写的:
显示判断库存数量是不是大于0,如果大于0,则进行库存的扣减,并将用户的的id放到redis的list列表中
Redis哨兵机制和集群有什么区别
redis集群有这么几种实现方式。
一种是主从集群,一种是redis cluster。
主从集群就是在redis集群中包括一个master节点和多个slave节点。
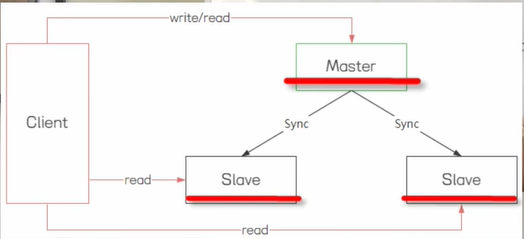
master节点负责数据的写,slave节点负责数据的读取。master节点收到数据的变更会同步到slave节点上面去。通过这样的一个架构可以实现redis的读写分离。可以提升数据的查询效率。 但是redis主从集群不提供容错和恢复的功能。一旦Master节点挂了不会选举出新的master节点。导致后面客户端过来的写请求直接失败。
所以,redis提供了哨兵机制。专门用来监听redis主从集群提供故障的自动恢复能力。哨兵会监控redis主从节点的一个状态。当master节点出现故障的时候,会自动从剩下的slave节点里面去选举出新的master节点。哨兵模式下虽然解决了master选举的一个问题,但是在线扩容的问题还是没有得到解决。
于是就有了第三种集群方式,redis cluster,它实现了redis的分布式存储,也就是说每个节点存储不同的数据,实现数据的分片功能,在redis cluster里面引入了slot槽,来实现数据分片。slot的整体取值范围是0-16383,每个节点会分配一个slot区间,当我们存储key的时候,redis会根据key计算得到一个slot的值,然后找到对应的节点进行数据的读写,在高可用方面,redis cluster 引入了主从复制的一个模式,一个master节点对应一个或者多个slave节点,当master节点出现故障的时候,会自动从slave节点中选举出一个新的master节点继续提供服务。redis cluster 虽然解决了在线扩容以及故障转移的能力。但是同样他也有缺点,比如说客户端在实现上更加复杂,slave节点是一个冷备节点,不提供分担读写操作的一个压力,对redis 里面的批量操作指令会存在限制。
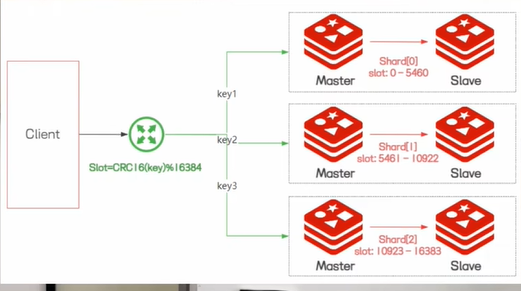
因此,主从模式和cluster模式各有优缺点,我们需要根据实际的场景需求来进行合理的选择。
这么给面试官回答: 面试官你好,我不太清楚你问的是哪一种,是redis 哨兵集群还是redis cluster集群,关于这个问题,我认为可以从三个方面来进行回答。
1.redis哨兵集群是基于主从复制来实现的,所以他可以实现读写分离,分担redis读操作的一个压力,而redis cluster集群中的slave节点只是用来实现冷备的,它只有master节点宕机之后,才会工作。
2.redis哨兵集群无法在线扩容,所以他的并发压力受限于单个服务器资源的配置。redis cluster提供了基于slot槽的数据分片机制,它可以实现在线扩容,去提升提携的一个性能。
3.从集群架构来说,redis 哨兵集群是一主多从,redis cluster是多主多从。
以上就是我的个人理解。
redis集群扩容缩容
https://www.bilibili.com/video/BV1DD4y1G7tC/?p=90&vd_source=273847a809b909b44923e3af1a7ef0b1
扩容
比方说我们生产环境的redis cluster集群部署的是三主三从。现在不够用了,这个时候就需要扩容。现在要变成四主四从。那么应该怎么办?
分为两个步骤,1.我们要将新加进来的一主一从加入到原来的redis cluster集群。2.原有的hash 槽分配要进行重新洗牌。
重新分配槽号的命令:redis-cli-a 111111-cluster reshard 192.168.111.185: 6381
缩容
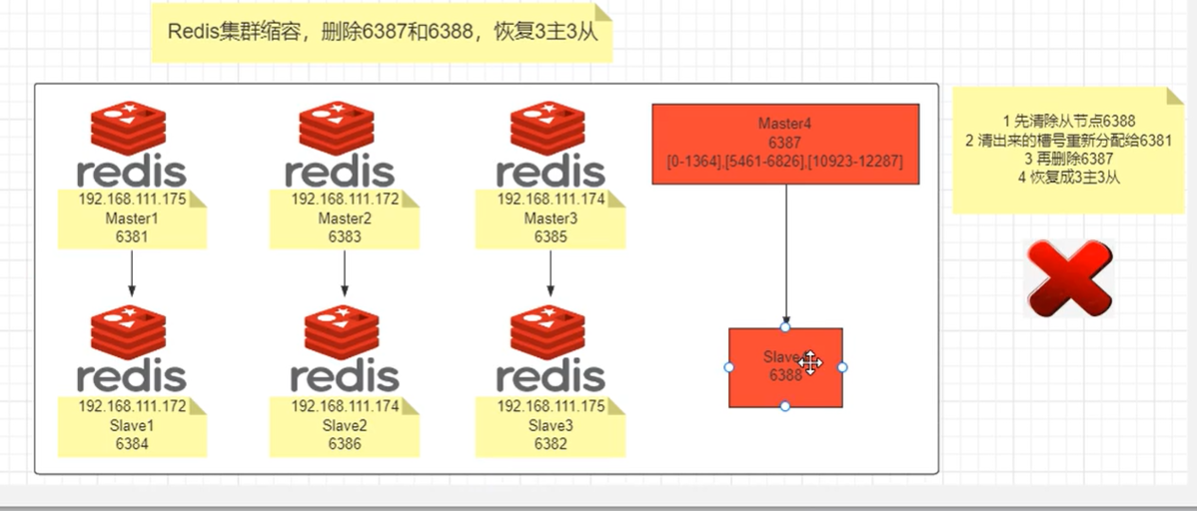
1.先清除从节点 2.清出来的槽号重新分配给原来集群上的一个主节点。3.再删除主节点。
你们redis cluster集群,是怎样进行主从复制的?(面试的时候有被问到)
自己差点被面试官带到沟里面,虽然redis cluster集群中的从节点是一个冷备节点(对外不提供数据的读写操作),但是他是会从主节点上进行数据的同步的,底层是:通过C语言的一个replicaofCommand函数来完成的,会先进行RDB文件的同步,然后进行AOF日志文件的同步。
redis cluster集群环境搭建(面试有被问到)
以三主三从部署环境为例
首先在每个机子上创建一个用户组,用户名,比方说用户组为redis,用户名也为redis,并且设置密码
因为默认是启用了rdb日志的
然后修改六台机子上的redis.conf 的配置文件,内容包括以下组成部分。
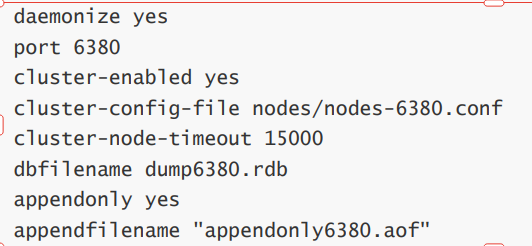
然后将这6个节点都启动起来。
然后通过一条命令指定创建redis集群中有几个主节点几个从节点

Redis数据同步原理(面试有被问到)
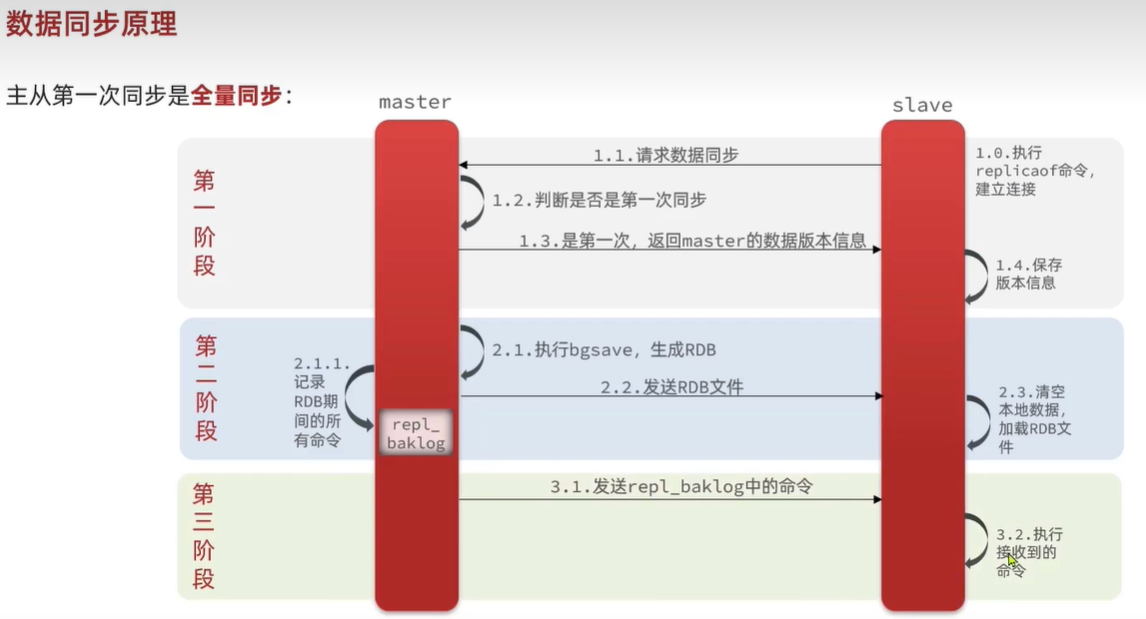
因此slave做数据同步,必须向master声明自己的replicationid 和 offset。
replicationid:如果从节点的replicationid 和 主节点的 replicationid不一致,这个时候就需要进行全量数据的同步。
offset:如果从节点和主节点的offset不一致,则需要进行增量同步。
简述全量同步的流程?
1.slave节点请求增量同步
2.master节点判断replid,发现不一致,拒绝增量同步master将完整内存数据生成RDB,发送RDB到slave
3.slave清空本地数据,加载master的RDB
4.master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
5.slave执行接收到的命令,保持与master之间的同步
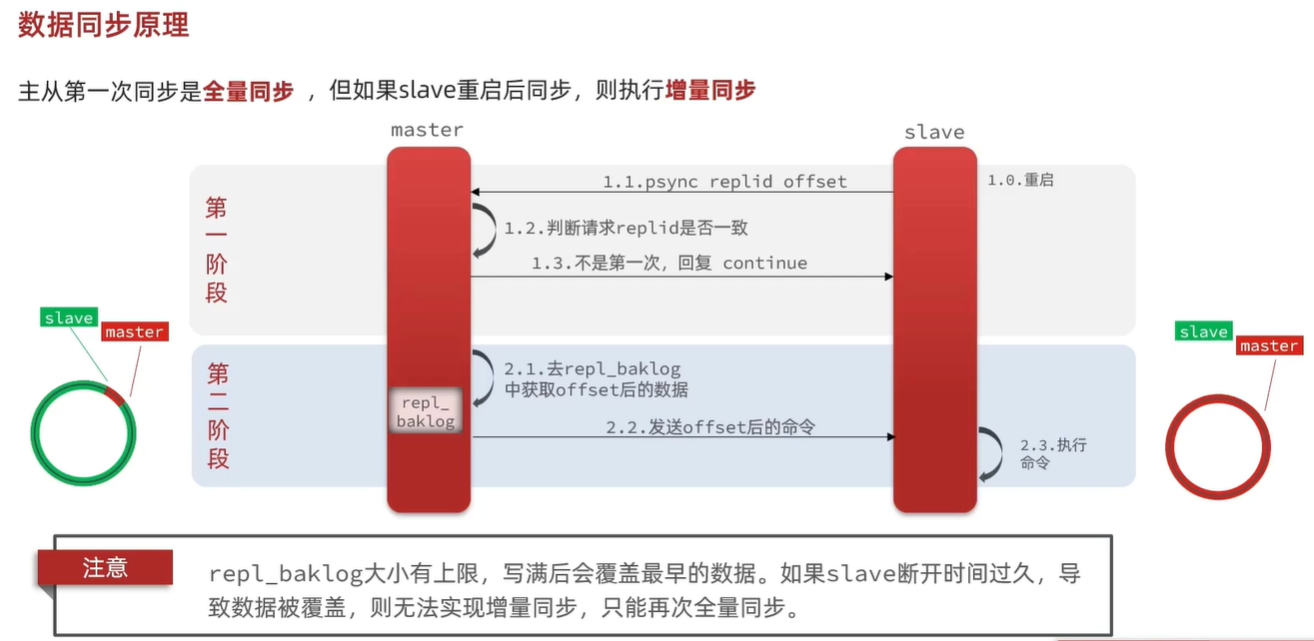
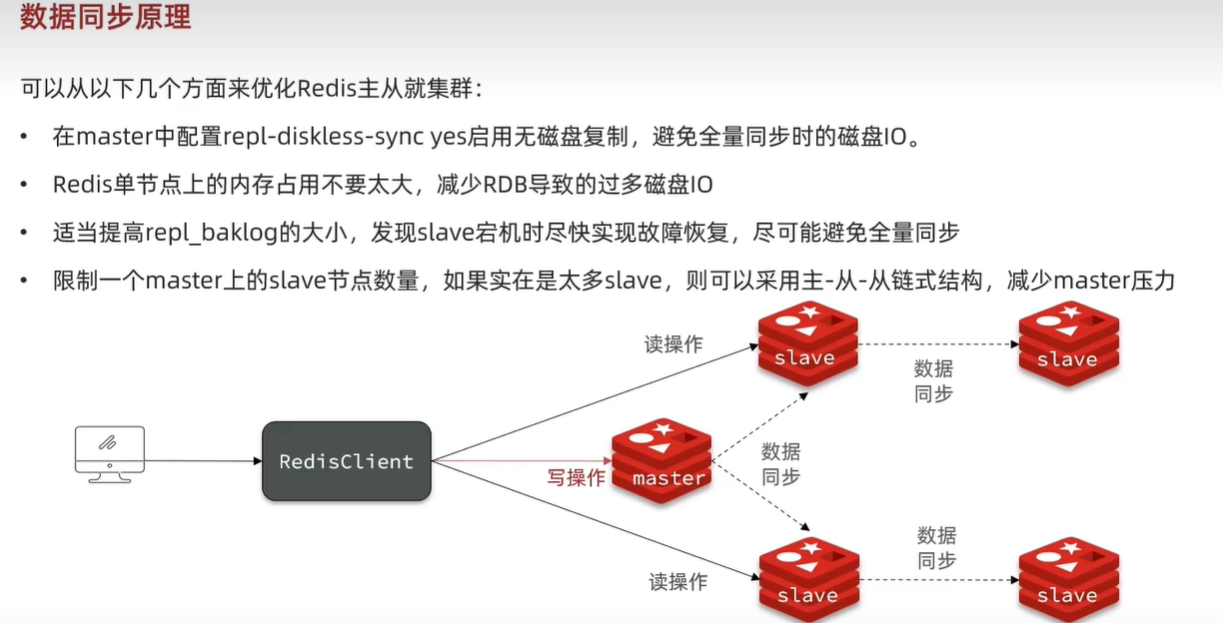
总结:

Redis底层是怎么实现分布式锁的
方式一:使用Redis的setnx命令+expire过期时间
方式二:使用lua脚本
方式三:使用Redisson
等等。。。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2021-09-12 规范化理论-模式分解
2020-09-12 yum install gcc-c++
2019-09-12 接口-httpClient 以及HttpClient与CloseableHttpClient之间的区别