

Spring cloud alibaba面试题
Spring cloud alibaba面试题
**spring cloud alibaba都有哪些组件 **
如果面试官问你微服务都有哪些组件,可以先说spring cloud Netflix那一套(因为那一套自己是比较擅长的),说完了之后,再捎带着说spring cloud alibaba这一套组件。
服务注册发现以及配置中心:nacos
限流降级熔断:sentinel
分布式事务:seata
服务间通信调用:dubbo
Nacos1.x作为注册中心的原理?
底层基于netty实现。
集群数据同步使用distrio协议。
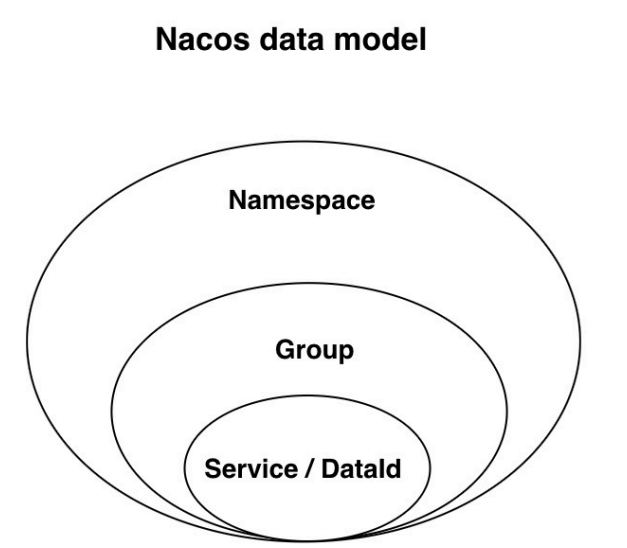
Nacos服务领域模型有哪些?
| 模型名称 | 解释 |
|---|---|
| Namespace | 实现环境隔离,默认值public,比方说DEV、SIT、UAT环境。 |
| Group | 一般用来表示某个项目。不同的service可以组成一个Group,默认值Default-Group, 同⼀个命名空间的不同分组微服务之间也是不能通信的。 如:交易分组:订单服务、支付服务 仓储分组:库存服务、物流服务 |
| Service | 服务名称 |
| DataId | 表示具体的配置文件 |
nacos集群节点数据同步问题
每个节点都维护了全量的数据,节点之间数据同步是基于distrio协议来完成的。
spring cloud config和nacos之间区别
修改了配置之后,config需要重启服务,nacos不需要。nacos有可视化的界面更加易于管理。而config是基于git来做的,没有可视化界面。
为什么Feign第一次调用耗时很长?
ribbon默认是懒加载的,只有第一次调用的时候才会生成ribbon对应的组件,这就会导致首次调用的会很慢的问题。
Feign的性能优化?
Feign底层默认是 JDK自带的HttpURLConnection,它是单线程发送HTTP请求的,不能配置线程池,我们使用Okhttp或者HttpClient来发送http请求,并且它们两个都支持线程池。
Feign怎样实现认证的传递?
实现RequestInterceptor接口重写apply方法,我们就能够对用户名和密码进行认证了。
谈谈Sentienl中使用的限流算法
1.计数器固定窗口算法,会存在临界值问题。
2.计数器滑动窗口算法,上面算法的改进,但是也不是完美的,因为具体将单位时间分为多少个格子不好说。
3.漏桶算法,不能应对突发流量。
4.令牌桶算法,可以应对一定的突发流量。
谈谈Sentienl服务熔断过程
服务熔断一般有三种状态:
熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制。
熔断开启状态(Open)
后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法。
半开状态(Half-Open)
尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预期,则
说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断关闭状态。
在Gateway中怎样实现服务平滑迁移?
使用Weight路由的断言工厂进行服务权重的配置,并将配置放到Nacos配置中心中,这样我们改了配置不用重启服务就能够实时生效。
spring:
cloud:
gateway:
routes:
- id: weight_high
uri: https://weighthigh.org
predicates:
- Weight=group1, 8
- id: weight_low
uri: https://weightlow.org
predicates:
- Weight=group1, 2
以上的配置说明当请求经过gateway网关的时候,会有80%的流量走 https://weighthigh.org,剩下20%的流量走https://weightlow.org。
在灰度发布的时候用的比较多。
Seata支持那些事务模式
Seata 是一款阿里巴巴开源的分布式事务解决方案。
Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
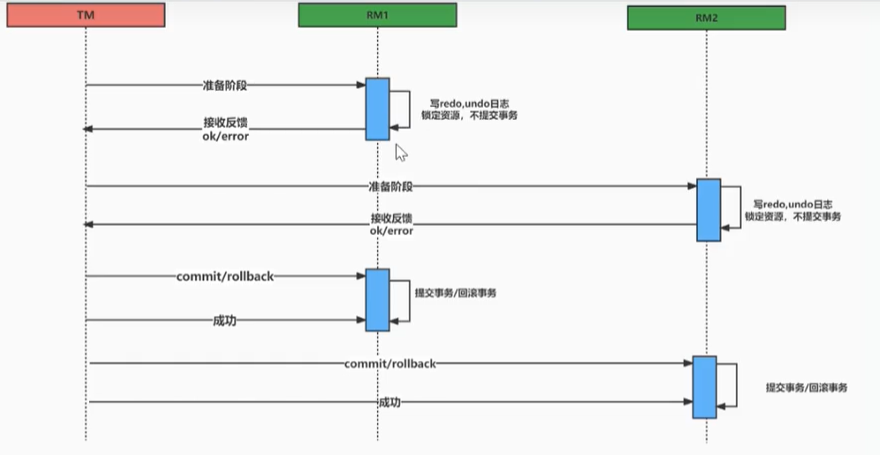
请简述2PC流程以及优缺点
流程:
1.事务协调器先询问各个参与者是否可以正常执行,如果可以,那么各个参与者就执行本地事务,但是不提交。
2.各个参与者将执行结果反馈给事务协调器,如果结果是都没有问题,那么事务协调器就给他们发送commit提交事务的信号。如果有一个参与者有问题,那么事务协调器就发送rollback的请求,让每个分支事务进行回滚。
3.每个分支提交事务,释放资源,并将处理结果再次发送给事务协调器,如果结果是都没有问题,那么事务协调器就给他们发送commit提交事务的信号。如果有一个参与者有问题,那么事务协调器就发送rollback的请求,让每个分支事务进行回滚。
2PC实际项目开发中用的比较多,3PC用的少一点。
XA、TCC、AT、SAGA都是2PC(两阶段提交)
优点: 尽量保证了数据的强一致,实现成本较低,在各大主流数据库都有自己实现,对于MySQL是
从5.5开始支持(XA)。
缺点:
单点问题:事务管理器在整个流程中扮演的角色很关键,如果其宕机,比如在第一阶段已经完
成,在第二阶段正准备提交的时候事务管理器宕机,资源管理器就会一直阻塞,导致数据库无法
使用。
同步阻塞:在准备就绪之后,资源管理器中的资源一直处于阻塞,直到提交完成,释放资源。
数据不一致:两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可
能,比如在第二阶段中,假设协调者发出了事务commit的通知,但是因为网络问题该通知仅被
一部分参与者所收到并执行了commit操作,其余的参与者则因为没有收到通知一直处于阻塞状
态,这时候就产生了数据的不一致性。
Seata中xid怎样通过Feign进行全局传递
全局事务id通过Feign的header进行传递。底层是一个map结构,说白了就是将xid放到了map中去了。
分布式事务应用的典型场景
多服务
多数据源(分库分表)
请说一下CAP和BASE理论
CAP和BASE是分布式必备理论基础
这个定理的内容是指的是在一个分布式系统中、Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。要不是AP,就是CP.
BASE是Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent(最终一致性)三个短语的缩写。BASE理论是基于CAP理论演化而来的。
BASE理论的核心思想是:**即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。****
简述Seata的AT模式两阶段过程
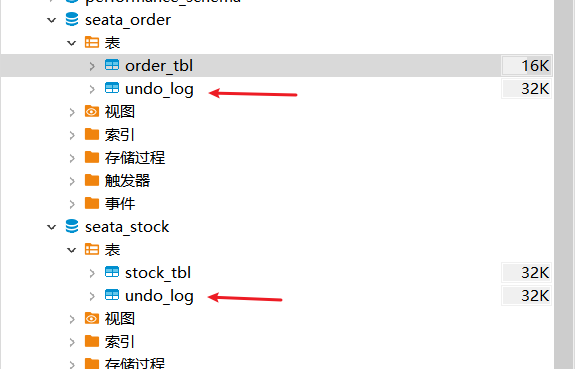
一阶段:开启全局事务、注册分支事务、储存全局锁、业务数据和回滚日志(undoLog)进行提交
二阶段:事务协调者根据所有分支的情况,决定本次全局事务是Commit还是Rollback (二阶段是完全异步删除undolog日志,全局事务、分支事务、储存的全局锁)。
结合代码讲解:
@GlobalTransactional // 开启全局事务,生成xid
@Transactional(rollbackFor = Exception.class) // 分支事务
public void placeOrder(String userId, String commodityCode, Integer count) {
BigDecimal orderMoney = new BigDecimal(count).multiply(new BigDecimal(5));
Order order = new Order().setUserId(userId).setCommodityCode(commodityCode).setCount(count).setMoney(
orderMoney);
orderDAO.insert(order);
stockFeignClient.deduct(commodityCode, count);
}
@Transactional(rollbackFor = Exception.class) // 分支事务
public void deduct(String commodityCode, int count) {
if (commodityCode.equals("product-2")) {
throw new RuntimeException("异常:模拟业务异常:stock branch exception");
}
QueryWrapper<Stock> wrapper = new QueryWrapper<>();
wrapper.setEntity(new Stock().setCommodityCode(commodityCode));
Stock stock = stockDAO.selectOne(wrapper);
stock.setCount(stock.getCount() - count);
stockDAO.updateById(stock);
}
简述Seata的TCC模式两阶段过程
TCC模式也是类似于2PC两阶段提交的。
TCC模式的实现,需要我们实现一个接口,并重写该接口中的三个方法。
一个是try方法,预留业务资源的方法。
一个是confirm方法,确认执行业务操作。
一个是cancel方法,取消预留资源,回退到更改前的状态。
一般像金融类业务,使用tcc模式的比较多。
简述Eureka自我保护机制
Eureka服务端会检查最近15分钟内所有Eureka 实例正常心跳占比,如果低于85%就会触发自我保护机制。触发了保护机制,Eureka将暂时把这些失效的服务保护起来,不让其过期,但这些服务也并不是永远不会过期。Eureka在启动完成后,每隔60秒会检查一次服务健康状态,如果这些被保护起来失效的服务过一段时间后(默认90秒)还是没有恢复,就会把这些服务剔除。如果在此期间服务恢复了并且实例心跳占比高于85%时,就会自动关闭自我保护机制。
这样做的目的是防止由于网络抖动等原因导致的误删健康的服务实例,从而保证了服务的高可用性和稳定性
简述Eureka集群架构
Register(服务注册):把自己的 IP 和端口注册给 Eureka。
Renew(服务续约):发送心跳包,每 30 秒发送一次。告诉 Eureka 自己还活着。
Cancel(服务下线):当 provider 关闭时会向 Eureka 发送消息,把自己从服务列表中删除。防
止 consumer 调用到不存在的服务。
Get Registry(获取服务注册列表):获取其他服务列表。
Make Remote Call(远程调用):完成服务的远程调用。
Replicate(集群中数据同步):eureka 集群中的数据复制与同步。
注意:Eureka集群中每个实例并不保存全量的数据。
从Eureka迁移到Nacos的解决方案
pom文件中添加nacos的依赖。
然后修改yaml配置
最后将启动类上的注解进行修改@EnabledEurekaClient 改为 @EnabledDiscoveryClient.
seata 是如何解决分布式事务问题的。
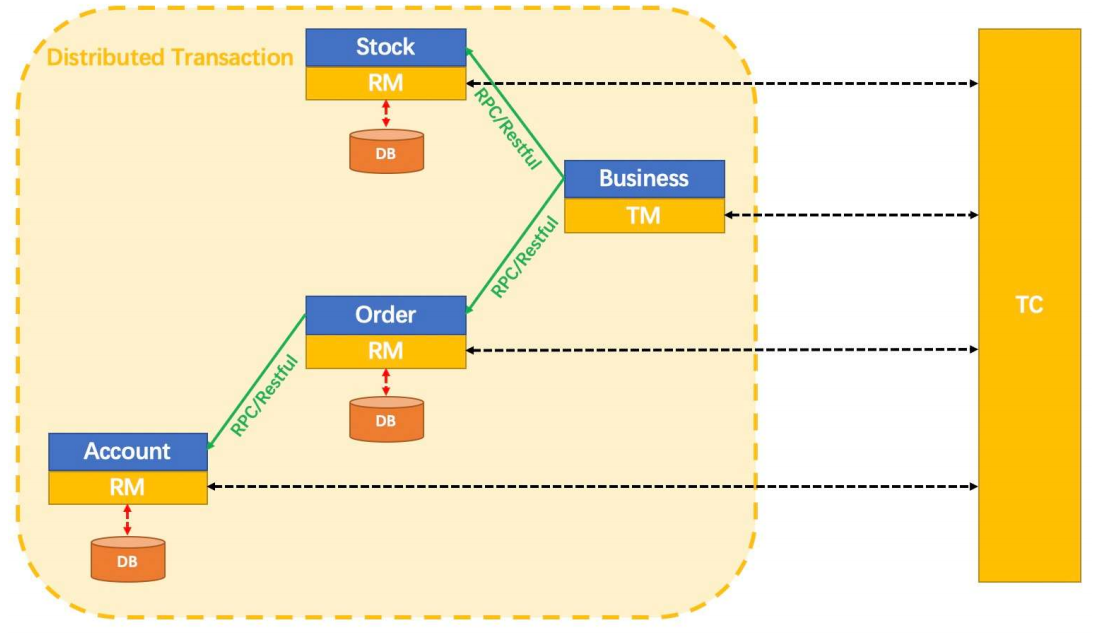
分布式事务是由⼀批分⽀事务组成的全局事务,⽽通常情况下分⽀事务就是本地事务。
其中 TM 和 RM 是作为Seata的客户端与业务系统集成在⼀起,TC作为Seata的服务端独⽴部署。
Transaction Coordinator - 事务协调者(TC):**维护全局和分⽀事务的状态,驱动全局提交或回滚。
Transaction Manager - 事务管理器(TM):定义全局事务的范围:开始⼀个全局事务,提交或回滚⼀个全局事务。
资源管理器 - 资源管理器(RM):管理分⽀事务处理的资源,与 TC 对话以注册分⽀事务和报告分⽀事务的状态,并驱动分⽀事务的提交或回滚。
说一下nacos的底层原理(面试有被问到)
具体的实现大概可以分成这么几个部分:
1.配置信息存储:Nacos默认使用内嵌数据库Derby来存储配置信息,还可以采用MySQL等关系型数据库。
2.注册配置信息:服务启动时,Nacos Client会向Nacos Server注册自己的配置信息,这个注册过程就是把配置信息写入存储,并生成版本号。
3.获取配置信息:服务运行期间,Nacos Client通过API从Nacos Server获取配置信息。Server根据键查找对应的配置信息,并返回给Client。
4.监听配置变化:Nacos Client可以通过注册监听器的方式,实现对配置信息的监听。当配置信息发生变化时,Nacos Server会通知已注册的监听器,并触发相应的回调方法。
nacos底层保存注册信息使用的是一个concurrenthashmap来做的。
你们项目中怎样处理分布式事务的问题?(面试有被问到)
1.如果你是单个数据库下面的多张表操作,我们可以基于@Transactional注解来做,或者是spring提供的编程式事务类TrasanctionTemplate类来做。
2.如果涉及到分库分表的业务场景,这个时候涉及到的分布式事务,我们可以采用XA模式的两阶段提交方式(给面试官讲一下两阶段提交的流程,一定要说上事务协调器,并且说这种方式一般也很少用)。
3.还有就是三阶段提交。
4.采用基于事务补偿的机制来做,您比方说我们XXX平台系统,一个交易通常会调用多个其他系统的接口,这时候,我们会让其他系统再给我们提供对应的回滚接口,以备不时之需。
5.采用基于消息队列的最终一致性方案,就是将消息先发送到mq中,就直接响应客户成功了。
说一下nacos是怎样做到更新配置不重启微服务的
首先nacos采用的是一个长轮询的方式向nacos server端去发起配置更新的请求。
所谓长轮询就是客户端发起一次轮询请求到服务端,当服务器端的配置没有变更的时候,这个连接会一直打开,直到服务端有配置变更或者连接超时之后返回。
nacos client 端需要获取服务端变更的配置,前提是需要有一个比较,也就是说客户端本地的配置信息和服务端的配置信息进行一个比较。一旦发现和服务端的配置有差异。那么表示服务器端的配置有更新。于是需要把更新的配置拉取到本地。
在这个过程中有可能客户端的配置比较多,导致比较的时间比较长。使得配置的同步效率比较低。
于是,nacos针对这个场景做了两个方面的优化。第一:减少网络通信的数据量,客户端把需要更新的配置进行分片。每一个分片的大小是3000,也就是说每次拿3000个配置去nacos server端去进行比较。第二:分阶段进行比较和更新。第1个阶段,客户端把这3000个配置的key以及对应的value值的MD5拼接成一个字符串,然后发送到nacos server端进行判断,服务端会逐个比较这些配置中MD5不同的key,把存在更新的key返回给客户端。第二个阶段,客户端拿到这个变更的key以后,客户端把这3000个配置的key以及对应的value值的MD5拼接成一个字符串,然后发送到nacos server端进行判断,服务端会逐个比较这些配置中MD5不同的key,把存在更新的key返回给客户端。客户端拿到这些变更的key,循环逐个去调用服务端获取这些key的value值。
那么这两个优化的核心目的是去减少网络通信的数据包的一个大小。把一次大的数据包的通信拆分成多个小的数据包的通信。虽然会增加网络通信的一个次数,但是对于整个性能的提升是非常大的,最后再加上采用长轮询的方式,既减少了pull的轮询次数,又利用了长轮询的优势,动态更新配置的一个功能。
以上就是我对这个问题的一个理解。
说一下nacos是怎样做到更新配置不重启微服务的实现方式
方式一:在需要动态刷新的配置类或方法上添加@RefreshScope注解
方式二:通过在配置类上添加@ConfigurationProperties注解
注册中心选型(面试有被问到)
Spring cloud config :这是Netflix推荐的注册中心。
Spring cloud alibaba nacos:这是阿里体系的配置中心,也是注册中心。
Apollo: 是携程框架部门研发的开源配置管理中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性。
数据源:
Spring cloud config :三方仓库github、Gitee、自检gitlab。
nacos:MySQL,其他需自研。
appollo:MySQL,其他需自研。
Spring cloud config:适合学习使用。
Nacos:适合需要快速部署和集成,且对资源消耗有严格要求的场景。适用于中小型企业或项目,特别是在资源有限的情况下。
Apollo:适合大型企业级应用,特别是对配置管理有严格要求的环境。适用于金融、电信等行业的复杂业务系统,需要严格的权限划分和配置变更流程。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY