Pandas基础
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据):
- Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
- DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
1.数据的属性
| 属性 | 作用 |
|---|---|
| columns | 返回数据的列名 |
| ndim | 返回int,表示数组的维数 |
| shape | 返回tuple。表述尺寸 |
| size | 返回int,表示元素总数 |
| dtypes | 返回data-type,描述元素的类型 |
| index | 返回RangeIndex(start=0, stop=最后的数值下标值, step=数据步长值) |
| values | 返回全部数据元素值 |
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_table('meal_order_detail1',con=engin)
#数据索引
print(data.index) #输出为:RangeIndex(start=0, stop=2779, step=1)
#数据元素
print(data.values)
'''
输出为:
[['2956' '417' '610062' ... 'NA' 'caipu/104001.jpg' '1442']
['2958' '417' '609957' ... 'NA' 'caipu/202003.jpg' '1442']
['2961' '417' '609950' ... 'NA' 'caipu/303001.jpg' '1442']
...
['6756' '774' '609949' ... 'NA' 'caipu/404005.jpg' '1138']
['6763' '774' '610014' ... 'NA' 'caipu/302003.jpg' '1138']
['6764' '774' '610017' ... 'NA' 'caipu/302006.jpg' '1138']]
'''
#数据列名
print(data.columns)
'''
输出为:
Index(['detail_id', 'order_id', 'dishes_id', 'logicprn_name',
'parent_class_name', 'dishes_name', 'itemis_add', 'counts', 'amounts',
'cost', 'place_order_time', 'discount_amt', 'discount_reason',
'kick_back', 'add_inprice', 'add_info', 'bar_code', 'picture_file',
'emp_id'],
dtype='object')
'''
#数据类型
print(data.dtypes)
'''
输出为:
detail_id object
order_id object
dishes_id object
logicprn_name object
parent_class_name object
dishes_name object
itemis_add object
counts float64
amounts float64
cost object
place_order_time datetime64[ns]
discount_amt object
discount_reason object
kick_back object
add_inprice object
add_info object
bar_code object
picture_file object
emp_id object
dtype: object
'''
#数据元素个数
print(data.size) #输出为:52801
#数据形状
print(data.shape) #输出为:(2779, 19)
#数据维度数
print(data.ndim) #输出为:2
2.索引和切片
2.1 键值索引获取某一列数据
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_table('meal_order_detail1',con=engin)
#数据列名
print(data.columns)
'''
输出为:
Index(['detail_id', 'order_id', 'dishes_id', 'logicprn_name',
'parent_class_name', 'dishes_name', 'itemis_add', 'counts', 'amounts',
'cost', 'place_order_time', 'discount_amt', 'discount_reason',
'kick_back', 'add_inprice', 'add_info', 'bar_code', 'picture_file',
'emp_id'],
dtype='object')
'''
#通过键值对进行索引,获取某一列的数据
print(data['dishes_name'])
'''
输出为:
0 蒜蓉生蚝
1 蒙古烤羊腿
2 大蒜苋菜
3 芝麻烤紫菜
4 蒜香包
...
2774 白饭/大碗
2775 牛尾汤
2776 意文柠檬汁
2777 金玉良缘
2778 酸辣藕丁
Name: dishes_name, Length: 2779, dtype: object
'''
2.2 键值提取基础上使用切片提取
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_table('meal_order_detail1',con=engin)
#数据列名
print(data.columns)
'''
输出为:
Index(['detail_id', 'order_id', 'dishes_id', 'logicprn_name',
'parent_class_name', 'dishes_name', 'itemis_add', 'counts', 'amounts',
'cost', 'place_order_time', 'discount_amt', 'discount_reason',
'kick_back', 'add_inprice', 'add_info', 'bar_code', 'picture_file',
'emp_id'],
dtype='object')
'''
#使用切片提取数据
print(data['dishes_name'][:5])
'''
0 蒜蓉生蚝
1 蒙古烤羊腿
2 大蒜苋菜
3 芝麻烤紫菜
4 蒜香包
Name: dishes_name, dtype: object
'''
print(data['dishes_id'][:5][2]) #输出为:609950
2.3 iloc使用切片索引
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_table('meal_order_detail1',con=engin)
#查看第三行第三列的数据值
print(data.iloc[2,2]) #输出为:609950
#查看第三行到第五行的第三列数据
print(data.iloc[2:5,2])
'''
输出为:
2 609950
3 610038
4 610003
Name: dishes_id, dtype: object
'''
2.4 loc使用切片或字符索引
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_table('meal_order_detail1',con=engin)
#查看第三行dishes_id的数据
print(data.loc[2,'dishes_id']) #输出为:609950
#查看第3行到第六行dishes_id的数据值
print(data.loc[2:5,'dishes_id'])
'''
输出为:
2 609950
3 610038
4 610003
5 610019
Name: dishes_id, dtype: object
'''
3.数据的增、改、删
3.1 增加数据
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_table('meal_order_detail1',con=engin)
#提取
data2=data.loc[data['order_id']=='458',:]
#增加数据
data2['total_price']=data2['counts']*data2['amounts']
#展示前三行
print(data2.head(3))
'''
输出为:
detail_id order_id dishes_id ... picture_file emp_id total_price
145 3411 458 610063 ... caipu/104002.jpg 1455 45.0
146 3413 458 609943 ... caipu/103004.jpg 1455 55.0
147 3418 458 609954 ... caipu/304001.jpg 1455 29.0
'''
3.2 删除数据
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_table('meal_order_detail1',con=engin)
data2=data.loc[data['order_id']=='458',:]
data2['total_price']=data2['counts']*data2['amounts']
print(data2.head(3))
'''
输出为:
detail_id order_id dishes_id ... picture_file emp_id total_price
145 3411 458 610063 ... caipu/104002.jpg 1455 45.0
146 3413 458 609943 ... caipu/103004.jpg 1455 55.0
147 3418 458 609954 ... caipu/304001.jpg 1455 29.0
'''
#删除数据
data2.drop(labels='total_price',axis=1,inplace=True)
print(data2.columns)
'''
输出为:
Index(['detail_id', 'order_id', 'dishes_id', 'logicprn_name',
'parent_class_name', 'dishes_name', 'itemis_add', 'counts', 'amounts',
'cost', 'place_order_time', 'discount_amt', 'discount_reason',
'kick_back', 'add_inprice', 'add_info', 'bar_code', 'picture_file',
'emp_id'],
dtype='object')
'''
print(data2.head(3))
'''
输出为:
detail_id order_id dishes_id ... bar_code picture_file emp_id
145 3411 458 610063 ... NA caipu/104002.jpg 1455
146 3413 458 609943 ... NA caipu/103004.jpg 1455
147 3418 458 609954 ... NA caipu/304001.jpg 1455
'''
3.3 修改数据
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_table('meal_order_detail1',con=engin)
#提取
data2=data.loc[data['order_id']=='458',:]
#修改
data2['order_id']='45800'
4.数据读取与保存
4.1 数据库文件
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
#测试是否成功
print(engin)
#读取数据库某表格数据,不能查询
data=pd.read_sql_table('meal_order_detail1',con=engin)
#可以使用sql查询语句
data=pd.read_sql_query('select * from meal_order_detail1',con=engin)
#上面两种都可以用
data=pd.read_sql('select * from meal_order_detail1',con=engin)
data=pd.read_sql('meal_order_detail1',con=engin)
#数据存储到数据库
data.to_sql('temp',con=engin,if_exists='replace')
4.2 csv文件
import pandas as pd
#读取csv数据
data=pd.read_table('./data/meal_order_info.csv',encoding='gbk',sep=',')
#读取csv数据
data=pd.read_table('./data/meal_order_info.csv',encoding='gbk')
#存储数据
data.to_csv('./tmp/temp.csv',index=False)
4.3 excel文件
import pandas as pd
# 读取excel文件
data=pd.read_excel('./data/meal_order_detail.xlsx')
#保存数据到excel,工作表为a
data.to_excel('./tmp/temp.xlsx',sheet_name='a')
#保存数据到excel,工作表为b
data.to_excel('./tmp/temp.xlsx',sheet_name='b')
#写入方式二
with pd.ExcelWriter('./tmp/temp.xlsx') as w:
data.to_excel(w,sheet_name='a')
data.to_excel(w,sheet_name='b')
5.时间类型数据处理
5.1 转换为datatime数据
import pandas as pd
data=pd.read_csv('./data/meal_order_info.csv',encoding='gbk')
print(data['lock_time'].head())
'''
输出为:
0 2016/8/1 11:11:46
1 2016/8/1 11:31:55
2 2016/8/1 12:54:37
3 2016/8/1 13:08:20
4 2016/8/1 13:07:16
Name: lock_time, dtype: object
'''
#转数据为datetime类
pd.to_datetime(data['lock_time'])
#赋值回去作为修改
data['lock_time']=pd.to_datetime(data['lock_time'])
print(data['lock_time'].head())
'''
输出为:
0 2016-08-01 11:11:46
1 2016-08-01 11:31:55
2 2016-08-01 12:54:37
3 2016-08-01 13:08:20
4 2016-08-01 13:07:16
Name: lock_time, dtype: datetime64[ns]
'''
5.2 特定时间戳
import pandas as pd
#时间戳最小值
print(pd.Timestamp.min) #输出为:1677-09-21 00:12:43.145224193
#时间戳最大值
print(pd.Timestamp.max) #输出为:2262-04-11 23:47:16.854775807
5.3 设置时间作为索引
.to_datetime仅转换格式,.DatetimeIndex还能设置为索引
import pandas as pd
data=pd.read_csv('./data/meal_order_info.csv',encoding='gbk')
print(data['lock_time'].head())
'''
输出为:
0 2016/8/1 11:11:46
1 2016/8/1 11:31:55
2 2016/8/1 12:54:37
3 2016/8/1 13:08:20
4 2016/8/1 13:07:16
Name: lock_time, dtype: object
'''
#转换时间
datatime=pd.DatetimeIndex(data['lock_time'][0:5])
print(datatime)
'''
输出为:
DatetimeIndex(['2016-08-01 11:11:46', '2016-08-01 11:31:55',
'2016-08-01 12:54:37', '2016-08-01 13:08:20',
'2016-08-01 13:07:16'],
dtype='datetime64[ns]', name='lock_time', freq=None)
'''
6.数据合并
6.1 横向合并
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
#因为data是dataframe类型的数据,所以要用iloc
#因为数据量太大,所以用形状代替效果
a=data.iloc[:,:10]
print(a.shape) #输出为:(2779, 10)
b=data.iloc[:,10:]
print(b.shape) #输出为:(2779, 9)
#横向合并操作
print(pd.concat([a,b],axis=1).shape) #输出为:(2779, 19)
6.2 纵向合并
表名一致的纵向合并
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
#因为data是dataframe类型的数据,所以要用iloc
#因为数据量太大,所以用形状代替效果
a=data.iloc[:100,:]
print(a.shape) #输出为:(100, 19)
b=data.iloc[100:,:]
print(b.shape) #输出为:(2679, 19)
#纵向堆叠
#两张表列名一致的纵向堆叠
print(a.append(b).shape) #输出为:(2779, 19)
表名不一致的纵向合并
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
#因为data是dataframe类型的数据,所以要用iloc
#因为数据量太大,所以用形状代替效果
a=data.iloc[:100,:]
print(a.shape) #输出为:(100, 19)
b=data.iloc[100:,:]
print(b.shape) #输出为:(2679, 19)
#纵向堆叠
#两张表列名不一致的纵向堆叠,当然也可以用于一致的
print(pd.concat([a,b]).shape) #输出为:(2779, 19)
6.3 根据主键合并
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
order=pd.read_csv('./data/meal_order_info.csv',encoding='gbk')
#属性和值不一致,所以让属性和值一致
order['info_id']=data['order_id'].astype(str)
#主键合并
pd.merge(order,data,left_on='info_id',right_on='order_id')
print(order.shape) #输出为:(945, 21)
print(data.shape) #输出为:(2779, 19)
print(pd.merge(order,data,left_on='info_id',right_on='order_id').shape) #输出为:(10741, 40)
6.4 重叠合并
相同值会不变,空缺值会对应填齐
import pandas as pd
import numpy as np
dis1={'id':list(range(1,10)),
'cpu':['i7','i5',np.nan,'i7','i7','i5',np.nan,np.nan,'i5']}
a=pd.DataFrame(dis1)
dis2={'id':list(range(1,10)),
'cpu':['i7','i5','i5',np.nan,'i7','i5','i5',np.nan,'i5']}
b=pd.DataFrame(dis2)
print(a)
'''
输出为:
id cpu
0 1 i7
1 2 i5
2 3 NaN
3 4 i7
4 5 i7
5 6 i5
6 7 NaN
7 8 NaN
8 9 i5
'''
print(b)
'''
输出为:
id cpu
0 1 i7
1 2 i5
2 3 i5
3 4 NaN
4 5 i7
5 6 i5
6 7 i5
7 8 NaN
8 9 i5
'''
#重叠合并
print(a.combine_first(b))
'''
输出为:
id cpu
0 1 i7
1 2 i5
2 3 i5
3 4 i7
4 5 i7
5 6 i5
6 7 i5
7 8 NaN
8 9 i5
'''
8.构造透视表
可以进行某些计算,如求和与计数等,根据一个或多个键对数据进行聚合
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
print(data.head())
'''
输出为:
detail_id order_id dishes_id ... bar_code picture_file emp_id
0 2956 417 610062 ... NA caipu/104001.jpg 1442
1 2958 417 609957 ... NA caipu/202003.jpg 1442
2 2961 417 609950 ... NA caipu/303001.jpg 1442
3 2966 417 610038 ... NA caipu/105002.jpg 1442
4 2968 417 610003 ... NA caipu/503002.jpg 1442
'''
#创建透视表
#选取三列进行根据order_id
print(pd.pivot_table(data[['order_id','counts','amounts']],index='order_id',aggfunc=np.mean).head())
'''
输出为:
amounts counts
order_id
1002 32.000 1.0000
1003 30.125 1.2500
1004 43.875 1.0625
1008 63.000 1.0000
1011 57.700 1.0000
'''
print(pd.pivot_table(data[['order_id','counts','amounts','dishes_name']],index=['order_id','dishes_name'],aggfunc=np.mean).head())
'''
输出为:
amounts counts
order_id dishes_name
1002 凉拌菠菜 27.0 1.0
南瓜枸杞小饼干 19.0 1.0
焖猪手 58.0 1.0
独家薄荷鲜虾牛肉卷 45.0 1.0
白胡椒胡萝卜羊肉汤 35.0 1.0
'''
9.构造交叉表
计算分组频率的特殊透视表
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
print(data.head())
'''
输出为:
detail_id order_id dishes_id ... bar_code picture_file emp_id
0 2956 417 610062 ... NA caipu/104001.jpg 1442
1 2958 417 609957 ... NA caipu/202003.jpg 1442
2 2961 417 609950 ... NA caipu/303001.jpg 1442
3 2966 417 610038 ... NA caipu/105002.jpg 1442
4 2968 417 610003 ... NA caipu/503002.jpg 1442
'''
#创建透视表
#选取三列进行根据order_id
print(pd.crosstab(index=data['order_id'],columns=['dishes_name'],values=data['counts'],
dropna=True,margins=True,aggfunc=np.sum).fillna(0).head())
'''
输出为:
col_0 dishes_name All
order_id
1002 7.0 7.0
1003 10.0 10.0
1004 17.0 17.0
1008 5.0 5.0
1011 10.0 10.0
'''
10.数据去重
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
# 我们用数据的条数来显示数据去重效果
#数据去重前
print(data['dishes_name'])
'''
输出为:
0 蒜蓉生蚝
1 蒙古烤羊腿
2 大蒜苋菜
3 芝麻烤紫菜
4 蒜香包
...
2774 白饭/大碗
2775 牛尾汤
2776 意文柠檬汁
2777 金玉良缘
2778 酸辣藕丁
Name: dishes_name, Length: 2779, dtype: object
'''
print(data['dishes_name'].count()) #去重前数据数量:2779
#数据去重操作
print(data['dishes_name'].drop_duplicates())
'''
输出为:
0 蒜蓉生蚝
1 蒙古烤羊腿
2 大蒜苋菜
3 芝麻烤紫菜
4 蒜香包
...
1024 海带结豆腐汤
1169 冰镇花螺
1411 冬瓜炒苦瓜
1659 超人气广式肠粉
2438 百里香奶油烤紅酒牛肉
Name: dishes_name, Length: 145, dtype: object
'''
#数据去重后
print(data['dishes_name'].drop_duplicates().count()) #去重后数据数量:145
11.数据相似度计算
11.1 调用corr方法计算
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
#求相似度
print(data[['counts','amounts']].corr())
'''
输出为:
counts amounts
counts 1.000000 -0.174648
amounts -0.174648 1.000000
'''
#使用corr()求相似度的弊端,需要选择数值型特征数据,如果是类别型数据corr()会自动忽略
print(data[['counts','amounts','dishes_name']].corr())
'''
输出为:
counts amounts
counts 1.000000 -0.174648
amounts -0.174648 1.000000
'''
11.2 利用循环实现
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
#利用循环判断两两之间的相似度关系
#新建DataFrame类型数据
sim_dis=pd.DataFrame([],index=['counts','amounts','dishes_name'],
columns=['counts','amounts','dishes_name'])
#开始双层循环
for i in ['counts','amounts','dishes_name']:
for j in ['counts','amounts','dishes_name']:
sim_dis.loc[i,j]=data[i].equals(data[j])
print(sim_dis)
'''
输出为:
counts amounts dishes_name
counts True False False
amounts False True False
dishes_name False False True
'''
12.缺失值检测和处理
12.1 检测缺失值
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
#检测数据是否有缺少值
print(data.isnull().sum())
'''
输出为:
detail_id 0
order_id 0
dishes_id 0
logicprn_name 0
parent_class_name 0
dishes_name 0
itemis_add 0
counts 0
amounts 0
cost 0
place_order_time 0
discount_amt 0
discount_reason 0
kick_back 0
add_inprice 0
add_info 0
bar_code 0
picture_file 0
emp_id 0
dtype: int64
'''
print(data.notnull().sum())
'''
输出为:
detail_id 2779
order_id 2779
dishes_id 2779
logicprn_name 2779
parent_class_name 2779
dishes_name 2779
itemis_add 2779
counts 2779
amounts 2779
cost 2779
place_order_time 2779
discount_amt 2779
discount_reason 2779
kick_back 2779
add_inprice 2779
add_info 2779
bar_code 2779
picture_file 2779
emp_id 2779
dtype: int64
'''
12.2 多种删除缺失值方式
import pandas as pd
import numpy as np
#删除缺失值的操作
dis1={'id':list(range(1,10)),
'cpu':['i7','i7',np.nan,'i7','i7','i5',np.nan,np.nan,'i5']}
a=pd.DataFrame(dis1)
#检测是否有缺失值
print(a.isnull())
'''
输出为:
id cpu
0 False False
1 False False
2 False True
3 False False
4 False False
5 False False
6 False True
7 False True
8 False False
'''
#删除含有缺失值的数据
print(a.dropna())
'''
输出为:
id cpu
0 1 i7
1 2 i7
3 4 i7
4 5 i7
5 6 i5
8 9 i5
'''
#选定某一列其中有缺失值我们才进行剔除
print(a.dropna(subset=['id']))
'''
输出为:
id cpu
0 1 i7
1 2 i7
2 3 NaN
3 4 i7
4 5 i7
5 6 i5
6 7 NaN
7 8 NaN
8 9 i5
'''
#删除含有缺失值的整个特征
print(a.dropna(axis=1))
'''
输出为:
id
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
'''
12.3 缺失值填充
均值填充,与数据量大的元素填充
import pandas as pd
import numpy as np
#删除缺失值的操作
dis1={'id':list(range(1,10)),
'cpu':['i7','i7',np.nan,'i7','i7','i5',np.nan,np.nan,'i5']}
a=pd.DataFrame(dis1)
print(a)
'''
输出为:
id cpu
0 1 i7
1 2 i7
2 3 NaN
3 4 i7
4 5 i7
5 6 i5
6 7 NaN
7 8 NaN
8 9 i5
'''
#看值的数量统计
#cpu这一列的i7与i5的个数统计,从大到小排列
a['cpu'].value_counts()
#进行元素替换,填充i7
print(a['cpu'].fillna(a['cpu'].value_counts().index[0]))
'''
输出为:
0 i7
1 i7
2 i7
3 i7
4 i7
5 i5
6 i7
7 i7
8 i5
Name: cpu, dtype: object
'''
dis2={'id':list(range(1,10)),
'cpu':[7,7,np.nan,7,6,5,np.nan,np.nan,5]}
b=pd.DataFrame(dis2)
print(b)
'''
输出为:
id cpu
0 1 7.0
1 2 7.0
2 3 NaN
3 4 7.0
4 5 6.0
5 6 5.0
6 7 NaN
7 8 NaN
8 9 5.0
'''
#采用均值替换元素
print(b['cpu'].fillna(b['cpu'].mean()))
'''
输出为:
0 7.000000
1 7.000000
2 6.166667
3 7.000000
4 6.000000
5 5.000000
6 6.166667
7 6.166667
8 5.000000
Name: cpu, dtype: float64
'''
13.异常值检测与处理
13.1 利用箱线图检测
import pandas as pd
from sqlalchemy import create_engine
import matplotlib.pyplot as plt
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
#使用箱型图判断异常值
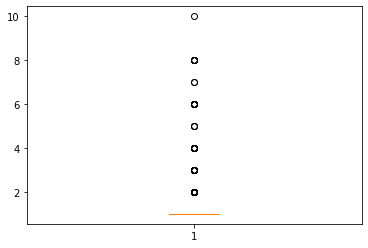
p=plt.boxplot(data['counts'])
plt.show()
#获取异常值数据
print(p['fliers'][0].get_ydata())
'''
输出为:
[ 2. 2. 2. 2. 5. 2. 2. 2. 2. 2. 3. 2. 2. 2. 2. 4. 2. 4.
4. 4. 2. 4. 10. 4. 6. 2. 6. 6. 8. 2. 2. 2. 6. 6. 4. 3.
4. 6. 2. 6. 6. 2. 8. 3. 2. 2. 2. 4. 2. 2. 2. 2. 3. 6.
8. 2. 2. 2. 2. 5. 2. 2. 5. 3. 4. 2. 3. 2. 2. 4. 8. 2.
2. 3. 3. 2. 2. 2. 4. 4. 2. 2. 2. 4. 6. 2. 3. 3. 3. 2.
2. 2. 2. 2. 2. 3. 2. 3. 3. 2. 3. 2. 4. 6. 2. 2. 2. 2.
2. 2. 2. 2. 2. 2. 4. 7. 2. 2. 4. 8. 8. 4. 3. 3. 3. 2.
2. 2. 2. 2. 2. 3. 4. 6. 7. 2. 2. 2. 2. 2. 2.]
'''
13.2 利用循环检测
import pandas as pd
from sqlalchemy import create_engine
import matplotlib.pyplot as plt
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
#使用3setae判断异常值
u=data['counts'].mean()
o=data['counts'].std()
#求出在这个范围外的值,apply函数主要用于对DataFrame中的行或者列进行特定的函数计算。
ind=data['counts'].apply(lambda x:x>u+3*o or x<u-3*o)
print(ind)
'''
输出为:
0 False
1 False
2 False
3 False
4 False
...
2774 False
2775 False
2776 False
2777 False
2778 False
Name: counts, Length: 2779, dtype: bool
'''
#定位这些元素出来
print(data.loc[ind,'counts'])
'''
输出为:
94 5.0
176 3.0
238 4.0
270 4.0
346 4.0
...
2370 3.0
2458 3.0
2459 4.0
2461 6.0
2501 7.0
Name: counts, Length: 62, dtype: float64
'''
14.数据标准化与离散化
14.1 离差标准化
import pandas as pd
data=pd.read_csv('./data/detail.csv',encoding='gbk')
print(data[['counts','amounts']].head())
'''
输出为:
counts amounts
0 1 49
1 1 48
2 1 30
3 1 25
4 1 13
'''
#设计离差标准化函数
def MinMaxScale(data):
return ((data-data.min())/(data.max()-data.min()))
a=MinMaxScale(data['counts'])
b=MinMaxScale(data['amounts'])
print(pd.concat([a,b],axis=1).head())
'''
counts amounts
0 0.0 0.271186
1 0.0 0.265537
2 0.0 0.163842
3 0.0 0.135593
4 0.0 0.067797
'''
14.2 标准差标准化
import pandas as pd
data=pd.read_csv('./data/detail.csv',encoding='gbk')
print(data[['counts','amounts']].head())
'''
输出为:
counts amounts
0 1 49
1 1 48
2 1 30
3 1 25
4 1 13
'''
#设计标准差标准化函数
def StandScale(data):
return (data-data.mean())/data.std()
a=StandScale(data['counts'])
b=StandScale(data['amounts'])
print(pd.concat([a,b],axis=1).head())
'''
输出为:
counts amounts
0 -0.177571 0.116671
1 -0.177571 0.088751
2 -0.177571 -0.413826
3 -0.177571 -0.553431
4 -0.177571 -0.888482
'''
14.3 小数定标准化
import pandas as pd
import numpy as np
data=pd.read_csv('./data/detail.csv',encoding='gbk')
print(data[['counts','amounts']].head())
'''
输出为:
counts amounts
0 1 49
1 1 48
2 1 30
3 1 25
4 1 13
'''
#设计小数定标标准化函数
def DecimalScale(data):
return data/10**(np.ceil(np.log10(data.abs().max())))
a=DecimalScale(data['counts'])
b=DecimalScale(data['amounts'])
print(pd.concat([a,b],axis=1).head())
'''
输出为:
counts amounts
0 0.1 0.049
1 0.1 0.048
2 0.1 0.030
3 0.1 0.025
4 0.1 0.013
'''
14.4 调用cut方法离散化
import pandas as pd
import numpy as np
data=pd.read_csv('./data/detail.csv',encoding='gbk')
print(data['amounts'].head())
'''
0 49
1 48
2 30
3 25
4 13
'''
print(data['amounts'].value_counts().head())
'''
输出为:
35 935
48 516
58 460
10 414
29 408
'''
#使用等宽法进行离散化处理
print(pd.cut(data['amounts'],bins=5).head())
'''
输出为:
0 (36.4, 71.8]
1 (36.4, 71.8]
2 (0.823, 36.4]
3 (0.823, 36.4]
4 (0.823, 36.4]
Name: amounts, dtype: category
Categories (5, interval[float64, right]): [(0.823, 36.4] < (36.4, 71.8] < (71.8, 107.2] <
(107.2, 142.6] < (142.6, 178.0]]
'''
#展示效果
print(pd.cut(data['amounts'],bins=5).value_counts().head())
'''
输出为:
(0.823, 36.4] 5461
(36.4, 71.8] 3157
(71.8, 107.2] 839
(142.6, 178.0] 426
(107.2, 142.6] 154
'''
14.5 使用自定义函数离散化
import pandas as pd
import numpy as np
data=pd.read_csv('./data/detail.csv',encoding='gbk')
print(data['amounts'].head())
'''
0 49
1 48
2 30
3 25
4 13
'''
#使用等频法进行离散化处理
def samefreq(data,k):
w=data.quantile(np.arange(0,1+1/k,1/k))
return pd.cut(data,w)
print(samefreq(data['amounts'],k=5))
'''
输出为:
0 (39.0, 58.0]
1 (39.0, 58.0]
2 (18.0, 32.0]
3 (18.0, 32.0]
4 (1.0, 18.0]
...
10032 (32.0, 39.0]
10033 (32.0, 39.0]
10034 (32.0, 39.0]
10035 (1.0, 18.0]
10036 (18.0, 32.0]
Name: amounts, Length: 10037, dtype: category
Categories (5, interval[float64, right]): [(1.0, 18.0] < (18.0, 32.0] < (32.0, 39.0] <
(39.0, 58.0] < (58.0, 178.0]]
'''
print(samefreq(data['amounts'],k=5).value_counts())
'''
输出为:
(18.0, 32.0] 2107
(39.0, 58.0] 2080
(32.0, 39.0] 1910
(1.0, 18.0] 1891
(58.0, 178.0] 1863
Name: amounts, dtype: int64
'''
15.数据的计算
import pandas as pd
from sqlalchemy import create_engine
engin=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql_query('select * from meal_order_detail1',con=engin)
data2=data.loc[data['order_id']=='458',:]
#求平均值
print(data2.mean())
'''
输出为:
detail_id 2.436672e+54
order_id 3.274703e+40
dishes_id 4.357597e+82
itemis_add 0.000000e+00
counts 1.000000e+00
amounts 5.000000e+01
add_inprice 0.000000e+00
emp_id 1.039390e+54
dtype: float64
'''
#求最小值
print(data2.min())
'''
输出为:
detail_id 3411
order_id 458
dishes_id 609939
logicprn_name NA
parent_class_name NA
dishes_name 五香酱驴肉
itemis_add 0
counts 1.0
amounts 10.0
cost NA
place_order_time 2016-08-01 19:27:00
discount_amt NA
discount_reason NA
kick_back NA
add_inprice 0
add_info NA
bar_code NA
picture_file caipu/102004.jpg
emp_id 1455
dtype: object
'''
#返回所有数值计算结果
print(data2.describe())
'''
输出为:
counts amounts
count 14.0 14.000000
mean 1.0 50.000000
std 0.0 36.746533
min 1.0 10.000000
25% 1.0 29.750000
50% 1.0 46.500000
75% 1.0 54.250000
max 1.0 158.000000
'''
#返回类别数据
print(data['dishes_name'].value_counts())
'''
输出为:
白饭/大碗 92
凉拌菠菜 77
谷稻小庄 72
麻辣小龙虾 65
白饭/小碗 60
..
三丝鳝鱼 2
咖啡奶香面包 2
铁板牛肉 2
冰镇花螺 1
百里香奶油烤紅酒牛肉 1
Name: dishes_name, Length: 145, dtype: int64
'''
16.数据分组聚合
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
data=pd.read_sql('meal_order_detail1',con=engine)
print(data)
'''
输出为:
detail_id order_id dishes_id ... bar_code picture_file emp_id
0 2956 417 610062 ... NA caipu/104001.jpg 1442
1 2958 417 609957 ... NA caipu/202003.jpg 1442
2 2961 417 609950 ... NA caipu/303001.jpg 1442
...............................................................
2777 6763 774 610014 ... NA caipu/302003.jpg 1138
2778 6764 774 610017 ... NA caipu/302006.jpg 1138
[2779 rows x 19 columns]
'''
#根据order_id进行聚合
print(data.groupby(by='order_id').head())
'''
输出为:
detail_id order_id dishes_id ... bar_code picture_file emp_id
0 2956 417 610062 ... NA caipu/104001.jpg 1442
1 2958 417 609957 ... NA caipu/202003.jpg 1442
2 2961 417 609950 ... NA caipu/303001.jpg 1442
...............................................................
2774 6750 774 610011 ... NA caipu/601005.jpg 1138
2775 6742 774 609996 ... NA caipu/201006.jpg 1138
[1355 rows x 19 columns]
'''
#提取三列数据根据order_id进行聚合
print(data[['order_id','counts','amounts']].groupby(by='order_id').head())
'''
输出为:
order_id counts amounts
0 417 1.0 49.0
1 417 1.0 48.0
2 417 1.0 30.0
.....................
2774 774 1.0 10.0
2775 774 1.0 40.0
[1355 rows x 3 columns]
'''
17.参考文章
[Pandas数据合并与拼接的5种方法 - 云+社区 - 腾讯云](https://cloud.tencent.com/developer/article/1640799#:~:text=Pandas数据合并与拼接的5种方法 1 一、DataFrame.... 2 二、DataFrame.merge:类似 vlookup 3,三、DataFrame.join:主要用于索引上的合并 4 四、Series.append:纵向追加Series 5 五、DataFrame.... 6 总结)
[pandas文件读取与存储_IT之一小佬的博客-CSDN博客 ](https://blog.csdn.net/weixin_44799217/article/details/113954597#:~:text=pandas文件读取与存储,我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。 注:最常用的HDF5和CSV文件)
使用pandas模块实现数据的标准化_一个回和的博客-CSDN ...
【创作不易,望点赞收藏,若有疑问,请留言,谢谢】




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!