Java-List(有序,可重复,有索引),HashSet(无序,不可重复),TreeSet(有序,不可重复),Map(具有映射关系):HashMap与TreeMap(与Set相类似)
1.集合
- java集合存放于包java.util包中,是一个用来存放对象的容器
- 只能存放对象,例如:存放int是转换成Integer对象
- 集合存放的是多个对象的引用,对象本身还是放在堆内存中
- 集合可以存放不同类型,不限数量的数据类型
1.1 ArrayList
public class Test3 {
public static void main(String[] args) {
//ArrayList可重复,保证存入有序
List<String > list=new ArrayList<>();//接口回调
List<String> link=new LinkedList<>();//基于双向链表
List<String> v=new Vector<>();//操作和arraylist操作相同,但是线程安全些,效率低一点
List<String> stacks=new Stack<>();//基于栈
list.add("456");//追加到末尾
list.add("hello");
list.add("12311");
list.add("12322");
//1.for
for(int i=0;i<list.size();i++){
System.out.println(list.get(i));
}
//2.foreach 加强for循环 for(元素类型 变量 : 遍历的集合){}
for(String s:list){
System.out.println(s);
}
//3.迭代器
System.out.println("=============");
Iterator<String> it = list.iterator();
/*while (true){
boolean b = it.hasNext();
if(!b){
break;
}
System.out.println(it.next());
}*/
while (it.hasNext()){
System.out.println(it.next());
}
}
}
1.2 Set
public class SetDemo{
public static void main(String[] args){
Set<String> set =new HashSet<>();
//不能重复 不能保证元素存储顺序
set.add("111");
set.add("222");
set.add("111");
set.add("555");
set.add("333");
System.out.println(set);
//2.foreach 加强for循环 for(元素类型 变量 : 遍历的集合){}
for(String s:set){
System.out.println(s);
}
//3.迭代器
System.out.println("=============");
Iterator<String> it = set.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}
1.3 Map
public class Main {
public static void main(String[] args) {
Map<String,String> map=new HashMap<>();
//不能保证插入顺序,键不能重复,键可以为null
map.put("007","hello");
map.put("002","hello2");
map.put("003","hello3");
map.put("004","hello4");
map.put("005","hello5");
Set<String> keys = map.keySet();
for(String key:keys){
System.out.println("key:"+key+",value:"+map.get(key));
}
Iterator<String> iterator = keys.iterator();
while (iterator.hasNext()){
String key=iterator.next();
System.out.println(key+":"+map.get(key));
}
}
}
1.4 案例:斗地主洗牌发牌
package pm;
import java.util.*;
public class Tset3 {
public static void main(String[] args) {
//斗地主发牌
//先把牌弄出来,2个集合,一个集合装花色,一个集合装数字
List<String> type=new ArrayList<>();
type.add("♥");
type.add("♠");
type.add("♦");
type.add("♣");
List<String> typecount=new ArrayList<>();
for(int i=3;i<=10;i++){
typecount.add(""+i);
}
//把非数字牌添加进来
typecount.add("J");
typecount.add("Q");
typecount.add("K");
typecount.add("A");
typecount.add("2");
//创建牌的map,每张牌都有一个编号,编号从0-53,把每张牌装进去
Map<Integer,String> poke=new HashMap<>();
int index=0;
for(String s:typecount){
for(String sc:type){
poke.put(index,s+sc);
index++;
}
}
poke.put(52,"大王");
poke.put(53,"小王");
System.out.println(poke);
//创建一个牌编号集合,以便洗牌
List<Integer> number=new ArrayList<>();
for(int i=0;i<54;i++){
number.add(i);
}
//洗牌,编号乱了
Collections.shuffle(number);
//需要4个集合来装牌对应的编号,3个玩家,1个底牌
List<Integer> p1=new ArrayList<>();
List<Integer> p2=new ArrayList<>();
List<Integer> p3=new ArrayList<>();
List<Integer> buttonpoke=new ArrayList<>();
//发牌对应的编号
for(int i=0;i<54;i++){
if(i>=51){
buttonpoke.add(number.get(i));
}else{
if(i%3==1){
p1.add(number.get(i));
}else if(i%3==2){
p2.add(number.get(i));
}else if(i%3==0){
p3.add(number.get(i));
}
}
}
//对编号排序
Collections.sort(p1);
Collections.sort(p2);
Collections.sort(p3);
Collections.sort(buttonpoke);
//需要4个集合来装牌
List<String> p11=new ArrayList<>();
List<String> p22=new ArrayList<>();
List<String> p33=new ArrayList<>();
List<String> buttonpoke1=new ArrayList<>();
//根据编号去牌库获取对应的牌
for(Integer i:p1){
p11.add(poke.get(i));
}
for(Integer i:p2){
p22.add(poke.get(i));
}
for(Integer i:p3){
p33.add(poke.get(i));
}
for(Integer i:buttonpoke){
buttonpoke1.add(poke.get(i));
}
System.out.println("玩家1:"+p11);
System.out.println("玩家2:"+p22);
System.out.println("玩家3:"+p33);
System.out.println("底牌:"+buttonpoke1);
}
}
2 HashSet(无序,不可重复)
- HashSet是set接口的典型实现,大多数时候使用Set集合时都使用这个实现类。我们大多数时候说的set集合指的都是HashSet集合
- HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找功能
- Hash具有以下特点:不能保证元素的排列顺序,不可重复,HashSet不是线程安全的,集合元素可以使null
- 当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashcode值,然后根据hashCode值决定该对象在HashSet中的存储位置
- 如果两个元素的equals()方法返回true,但它们的hashCode()返回值不相等,hashSet将会把它们存储在不同的位置,但依然可以添加成功
2.1 代码如下:
package demo;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Test2 {
public static void main(String[] args) {
Set set=new HashSet();
//Set<Object> set=new HashSet<Object>();//与上面的等价
set.add(1);
set.add("a");//添加对象到集合
System.out.println("添加对象到集合:"+set);//添加对象到集合:[1, a]
set.remove(1);//移除对象
System.out.println("移除对象:"+set);//移除对象:[a]
System.out.println("判断是否包含元素1:"+set.contains(1));//判断是否包含元素1:false
System.out.println("判断是否包含元素a:"+set.contains("a"));//判断是否包含元素a:true
set.clear();//清空集合
System.out.println("清空集合:"+set);//清空集合:[]
set.add("a");
set.add("b");
set.add("c");
set.add("d");
//set集合存的值是不重复的
set.add(1);
set.add(true);
set.add(null);
System.out.println(set);//[null, a, 1, b, c, d, true]
//迭代器遍历集合
System.out.println("迭代器遍历集合");
Iterator it=set.iterator();
while(it.hasNext()) {
System.out.print(it.next()+" ");//null a 1 b c d true
}
//for Each迭代集合
System.out.println();
System.out.println("for Each迭代集合");
for(Object obj:set) {//这个意思是说把set的每一个值取出来赋值给obj,直到循环set的所有值
System.out.print(obj+" ");//null a 1 b c d true
}
System.out.println();
System.out.println(set.size());//获取集合的元素个数:7
//如果想要让集合只能存同样类型的对象,怎么做
//使用泛型
Set<String> set1=new HashSet<String>();//比如指定String为集合的泛型,那么这个集合不能存String类型之外的数据
set1.add("abc");
//set1.add(1);这样是不行的
}
}
3.TreeSet(有序,不可重复)
- TreeSet可以确保集合元素处于排序状态,TreeSet支持两种排序方法:自然排序和定制排序
3.1 代码如下
package demo;
import java.util.Comparator;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class Test3 {
public static void main(String[] args) {
// TODO 自动生成的方法存根
Set<Integer> set=new TreeSet<Integer>();//TreeSet的自然排序
set.add(5);
set.add(2);
set.add(4);
set.add(3);
set.add(1);
System.out.println("添加对象到集合:"+set);//添加对象到集合:[1, 2, 3, 4, 5]
set.remove(1);//移除对象
System.out.println("移除对象:"+set);//移除对象:[2, 3, 4, 5]
System.out.println("判断是否包含元素1:"+set.contains(1));//判断是否包含元素1:false
//迭代器遍历集合
System.out.println("迭代器遍历集合");
Iterator<Integer> it=set.iterator();
while(it.hasNext()) {
System.out.print(it.next()+" ");//2 3 4 5
}
//for Each迭代集合
System.out.println();
System.out.println("for Each迭代集合");
for(Integer i:set) {//这个意思是说把set的每一个值取出来赋值给obj,直到循环set的所有值
System.out.print(i+" ");//2 3 4 5
}
System.out.println();
System.out.println(set.size());//获取集合的元素个数:4
set.clear();//清空集合
System.out.println("清空集合:"+set);//清空集合:[]
Person p1=new Person("zhangsan",17);
Person p2=new Person("lisi",23);
Person p3=new Person("wangwu",20);
Person p4=new Person("zhaoliu",29);
Set<Person> set1=new TreeSet<Person>(new Person());//TreeSet的定制排序
set1.add(p2);
set1.add(p4);
set1.add(p3);
set1.add(p1);
System.out.println("for Each迭代集合");
for(Person p:set1) {//这个意思是说把set的每一个值取出来赋值给obj,直到循环set的所有值
System.out.println(p.name+" "+p.age+" ");//zhangsan 17 wangwu 20 lisi 23 zhaoliu 29
}
}
}
//TreeSet定制排序,需要实现Comparator接口
class Person implements Comparator<Person>{ //把Person对象存到TreeSet中并按照年龄排序
int age;
String name;
public Person() {
}
public Person(String name,int age) {
this.name=name;
this.age=age;
}
@Override
public int compare(Person arg0, Person arg1) {
// TODO 自动生成的方法存根
if(arg0.age>arg1.age) {
return 1;
}else if(arg0.age<arg1.age) {
return -1;
}else {
return 1;
}
}
}
4.List(有序,可重复,有索引)
-
5.Map(具有映射关系)
-
Map有两组值,一个是key,一个是value,类型不限,key不允许有重复值,key与value存在单向1对1关系
5.HashMap与TreeMap
package demo;
import java.util.HashMap;
import java.util.Map.Entry;
import java.util.Set;
import java.util.TreeMap;
public class Map {
public static void main(String[] args) {
//前面试接口,后面是实现类
//Map<String,Integer> map=new HashMap;
HashMap<String,Integer> map=new HashMap<String,Integer>();
map.put("b",1);
map.put("c",2);
map.put("a",2);
System.out.println("按默认方式存入数据:"+map);//按默认方式存入数据:{a=2, b=1, c=2}
System.out.println("根据key取值:"+map.get("b"));//根据key取值:1
map.remove("c");
System.out.println("根据key移除键值对:"+map);//根据key移除键值对:{a=2, b=1}
System.out.println("获取集合的元素个数:"+map.size());//获取集合的元素个数:2
System.out.println("判断当前的集合是否存在指定的key:"+map.containsKey("b"));//判断当前的集合是否存在指定的key:true
System.out.println("判断当前的集合是否存在指定的value:"+map.containsValue(1));//判断当前的集合是否存在指定的value:true
System.out.println("获取map集合的key的集合:"+map.keySet());//获取map集合的key的集合:[a, b]
System.out.println("获取map集合的所有value值:"+map.values());//获取map集合的所有value值:[2, 1]
Set<String> keys=map.keySet();
//for Each迭代集合,通过map.keySet()遍历map集合
System.out.println();
System.out.println("for Each迭代集合,通过map.keySet()遍历map集合");
for(String key:keys) {//这个意思是说把set的每一个值取出来赋值给key,直到循环keys的所有值
System.out.println("key:"+key+",value:"+map.get(key));key:a,value:2 key:b,value:1
}
//for Each迭代集合, 通过map.entrySet()遍历map集合
Set<Entry<String,Integer>> entrys=map.entrySet();
System.out.println();
System.out.println("for Each迭代集合,通过map.entrySet()遍历map集合");
for(Entry<String,Integer> en:entrys) {//这个意思是说把set的每一个值取出来赋值给key,直到循环keys的所有值
System.out.println("key:"+en.getKey()+",value:"+en.getValue());//key:a,value:2 key:b,value:1
}
map.clear();//清空集合
System.out.println("清空数据:"+map);//清空数据:{}
//TreeMap自然排序是遵循字典排序,自定义排序与HashSet相类似
TreeMap<Integer,String> map1=new TreeMap<Integer,String>();
map1.put(4, "a");
map1.put(2, "a");
map1.put(3, "a");
map1.put(1, "a");
System.out.println("TreeMap:"+map1);//TreeMap:{1=a, 2=a, 3=a, 4=a}
TreeMap<String,String> map2=new TreeMap<String,String>();
map2.put("b", "b");
map2.put("c", "c");
map2.put("d", "d");
map2.put("a", "a");
map2.put("ab", "ab");
System.out.println("TreeMap:"+map2);//TreeMap:{a=a, ab=ab, b=b, c=c, d=d}
}
}
6.collection
package demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class Collectiontest {
public static void main(String[] args) {
// TODO 自动生成的方法存根
ArrayList<String> list=new ArrayList<String>();
list.add("b");//第一个,索引下标0
list.add("cd");//第二个,索引下标1
list.add("ca");//允许使用重复元素
list.add("a");
list.add("1");
System.out.println("按默认方式存入数据:"+list);//按默认方式存入数据:[b, cd, ca, a, 1]
Collections.reverse(list);
System.out.println("反转List中元素的顺序:"+list);//反转List中元素的顺序:[1, a, ca, cd, b]
Collections.shuffle(list);
System.out.println("对List中元素进行随机排序:"+list);//对List中元素进行随机排序:[a, 1, ca, cd, b]
Collections.sort(list);
System.out.println("List集合字典升序排序:"+list);//List集合字典升序排序:[1, a, b, ca, cd]
System.out.println("输出最大:"+Collections.max(list));//输出最大:cd
System.out.println("输出最小:"+Collections.min(list));//输出最小:1
Collections.swap(list, 0, 4);//
System.out.println("将指定list集合中的i处元素和j处元素进行交换后:"+list);//将指定list集合中的i处元素和j处元素进行交换后:[cd, a, b, ca, 1]
Student s1=new Student(14,"zhangsan");
Student s2=new Student(12,"lisi");
Student s3=new Student(13,"wangwu");
Student s4=new Student(11,"suiliu");
ArrayList<Student> stus=new ArrayList<Student>();//自定义排序
stus.add(s1);
stus.add(s2);
stus.add(s3);
stus.add(s4);
for(Student stu:stus) {
System.out.print(stu.name+","+stu.age+" ");//zhangsan,14 lisi,12 wangwu,13 suiliu,11
}
Collections.sort(stus,new Student());//按照指定方法排序
System.out.println();
for(Student stu:stus) {
System.out.print(stu.name+","+stu.age+" ");//suiliu,11 lisi,12 wangwu,13 zhangsan,14
}
Student ss=Collections.min(stus,new Student());
System.out.println(ss.name+"输出最大:"+ss.age);//suiliu输出最大:11
}
}
class Student implements Comparator<Student>{
int age;
String name;
public Student() {
}
public Student(int age,String name) {
this.name=name;
this.age=age;
}
@Override
public int compare(Student arg0, Student arg1) {//根据年龄升序排列
// TODO 自动生成的方法存根
if(arg0.age>arg1.age) {
return 1;
}else if(arg0.age<arg1.age) {
return -1;
}else {
return 1;
}
}
}
7.Lambda表达式
7.1 Lambda的认识
通过匿名对象创建线程:
public class Demo01ThreadNameless {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("多线程任务执行!");
}
}).start();
s }
}
而实际上,似乎只有方法体才是关键所在。
Lambda表达式写法,代码如下:
public class Demo02LambdaRunnable {
public static void main(String[] args) throws IOException {
new Thread(()->{System.out.println("多线程任务执行!");}).start();
}
}
这段代码和刚才的执行效果是完全一样的。
7.2 Lambda的格式
本质:就是一个接口的实例对象
前提:接口,这个接口只有一个抽象方法
语法:()->{} ——():参数列表;->:语法符号;{}:装方法体
7.3 省略原则
在Lambda标准格式的基础上,使用省略写法的规则为:
- 小括号内参数的类型可以省略;
- 如果小括号内有且仅有一个参,则小括号可以省略;
- 如果大括号内有且仅有一个语句,则无论是否有返回值,都可以省略大括号、return关键字及语句分号。
Runnable接口简化:
() ‐> System.out.println("多线程任务执行!")
Comparator接口简化:
Arrays.sort(array, (a, b) ‐> a.getAge() ‐ b.getAge());
8.Stream流
8.1 引言
在Java 8之前的做法可能为:
public class Demo02NormalFilter {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
List<String> zhangList = new ArrayList<>();
for (String name : list) {
if (name.startsWith("张")) {
zhangList.add(name);
}
}
List<String> shortList = new ArrayList<>();
for (String name : zhangList) {
if (name.length() == 3) {
shortList.add(name);
}
}
for (String name : shortList) {
System.out.println(name);
}
}
}
Stream的写法:
public class Demo03StreamFilter {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.stream().filter(s ‐> s.startsWith("张"))
.filter(s ‐> s.length() == 3)
.forEach(System.out::println);
}
}
8.2 流式思想概述
当需要对多个元素进行操作(特别是多步操作)的时候,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤 方案,然后再按照方案去执行它。
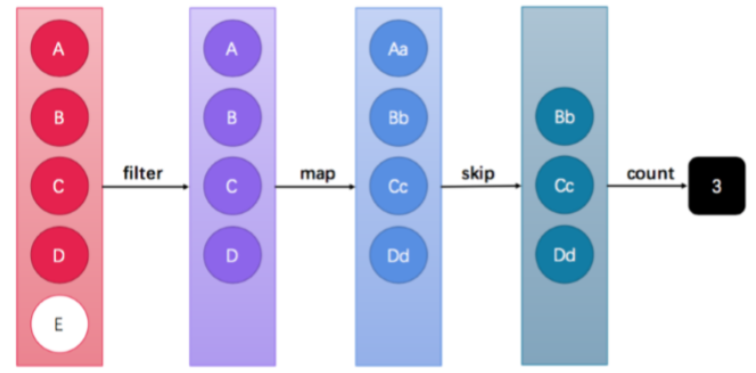
这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模 型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而右侧的数字 3是终结果。
这里的 filter 、 map 、 skip 都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法 count 执行的时候,整个模型才会按照指定策略执行操作。而这得益于Lambda的延迟执行特性。
Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何 元素(或其地址值)。
8.3 获取流方式
获取一个流非常简单,有以下几种常用的方式:
- 所有的 Collection 集合都可以通过 stream 默认方法获取流;
- Stream 接口的静态方法 of 可以获取数组对应的流。
3.3.1 根据Collection获取流
首先, java.util.Collection 接口中加入了default方法 stream 用来获取流,所以其所有实现类均可获取流。
public class Demo04GetStream {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// ...
Stream<String> stream1 = list.stream();
Set<String> set = new HashSet<>();
// ...
Stream<String> stream2 = set.stream();
Vector<String> vector = new Vector<>();
// ...
Stream<String> stream3 = vector.stream();
}
}
3.3.2 根据Map获取流
java.util.Map 接口不是 Collection 的子接口,且其K-V数据结构不符合流元素的单一特征,所以获取对应的流 需要分key、value或entry等情况:
public class Demo05GetStream {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
// ...
Stream<String> keyStream = map.keySet().stream();
Stream<String> valueStream = map.values().stream();
Stream<Map.Entry<String, String>> entryStream = map.entrySet().stream();
}
}
3.3.3 根据数组获取流
如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以 Stream 接口中提供了静态方法 of ,使用很简单:
public class Demo05GetStream {
public static void main(String[] args) {
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);
}
}
8.4 常用方法
流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
- 终结方法:返回值类型不再是 Stream 接口自身类型的方法,因此不再支持类似 StringBuilder 那样的链式调 用。本小节中,终结方法包括 count 和 forEach 方法。
- 非终结方法:返回值类型仍然是 Stream 接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余 方法均为非终结方法。)
8.4.1 forEach : 逐一处理
虽然方法名字叫 forEach ,但是与for循环中的“for-each”不同,该方法并不保证元素的逐一消费动作在流中是被有序执行的。
void forEach(Consumer<? super T> action);
该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理。例如:
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream<String> stream = Stream.of("张无忌", "张三丰", "周芷若");
stream.forEach(System.out::println);
}
}
在这里,方法引用 System.out::println 就是一个 Consumer 函数式接口的示例。
8.4.2 count:统计个数
正如旧集合 Collection 当中的 size 方法一样,流提供 count 方法来数一数其中的元素个数,该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。
基本使用:
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.filter(s ‐> s.startsWith("张"));
System.out.println(result.count()); // 2
}
}
8.4.3 filter:过滤
可以通过 filter 方法将一个流转换成另一个子集流。方法声明:
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
基本使用:
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.filter(s ‐> s.startsWith("张"));
}
}
在这里通过Lambda表达式来指定了筛选的条件:必须姓张。
8.4.4 limit:取用前几个
limit 方法可以对流进行截取,只取用前n个。方法定义:
Stream<T> limit(long maxSize)
参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。
基本使用:
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.limit(2);
System.out.println(result.count()); // 2 }
}
8.4.5 skip:跳过前几个
如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.skip(2);
System.out.println(result.count()); // 1
}
}
8.4.6 map:映射
如果需要将流中的元素映射到另一个流中,可以使用 map 方法。方法签名:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
基本使用:
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream<String> original = Stream.of("10", "12", "18");
Stream<Integer> result = original.map(Integer::parseInt);
}
}
这段代码中, map 方法的参数通过方法引用,将字符串类型转换成为了int类型(并自动装箱为 Integer 类对 象)。
8.4.7 concat:组合
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b
基本使用:
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream<String> streamA = Stream.of("张无忌");
Stream<String> streamB = Stream.of("张翠山");
Stream<String> result = Stream.concat(streamA, streamB);
}
}




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律