


如下内容来之https://time.geekbang.org/column/article/6463 学习笔记:
01 | 架构是什么
模块和组件:
都是系统的组成部分,只是从不同的角度拆分系统而已。
从业务逻辑的角度来拆分系统后,得到的单元就是“模块”;
从物理部署的角度来拆分系统后,得到的单元就是“组件”。
划分模块的主要目的是职责分离;划分组件的主要目的是单元复用。
框架与架构:
框架是一整套开发规范,架构是某一套开发规范下的具体落地方案,包括各个模块之间的组合关系以及它们协同起来完成功能的运作规则。
框架关注的是“规范”,架构关注的是“结构”。框架的英文是 Framework,架构的英文是 Architecture,Spring MVC 的英文文档标题就是“Web MVC framework”

02 | 架构设计的历史背景
软件架构相关的问题,例如:
- 系统规模庞大,内部耦合严重,开发效率低;
- 系统耦合严重,牵一发动全身,后续修改和扩展困难;
- 系统逻辑复杂,容易出问题,出问题后很难排查和修复。
软件架构的出现有其历史必然性。
20 世纪 60 年代第一次软件危机引出了“结构化编程”,创造了“模块”概念;
20 世纪 80 年代第二次软件危机引出了“面向对象编程”,创造了“对象”概念;
到了 20 世纪 90 年代“软件架构”开始流行,创造了“组件”概念。
我们可以看到,“模块”“对象”“组件”本质上都是对达到一定规模的软件进行拆分,差别只是在于随着软件的复杂度不断增加,拆分的粒度越来越粗,拆分的层次越来越高。
03 | 为什么要做架构设计
不做架构设计系统就跑不起来么?
架构设计的主要目的是为了解决软件系统复杂度带来的问题。
首先,遵循这条准则能够让“新手”架构师心中有数,而不是一头雾水。
其次,遵循这条准则能够让“老鸟”架构师有的放矢,而不是贪大求全。
04 | 复杂度来源:高性能
软件系统中高性能带来的复杂度主要体现在两方面,一方面是单台计算机内部为了高性能带来的复杂度;另一方面是多台计算机集群为了高性能带来的复杂度。
软件系统中高性能带来的复杂度主要体现在两方面,一方面是单台计算机内部为了高性能带来的复杂度;另一方面是多台计算机集群为了高性能带来的复杂度。
操作系统和性能最相关的就是进程和线程 需要考虑如多进程、多线程、进程间通信、多线程并发等技术点,而且这些技术并不是最新的就是最好的,也不是非此即彼的选择。
举一个最简单的例子:Nginx 可以用多进程也可以用多线程,JBoss 采用的是多线程;Redis 采用的是单进程,Memcache 采用的是多线程
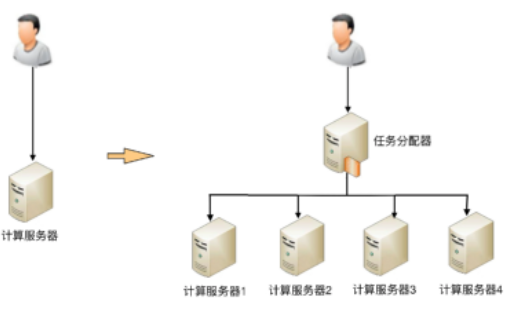
1. 任务分配
任务分配的意思是指每台机器都可以处理完整的业务任务,不同的任务分配到不同的机器上执行
1 台服务器演变为 2 台服务器后,架构上明显要复杂多了,
主要体现在:需要增加一个任务分配器,这个分配器可能是硬件网络设备(例如,F5、交换机等),可能是软件网络设备(例如,LVS),也可能是负载均衡软件(例如,Nginx、HAProxy),还可能是自己开发的系统。选择合适的任务分配器也是一件复杂的事情,需要综合考虑性能、成本、可维护性、可用性等各方面的因素。
任务分配器和真正的业务服务器之间有连接和交互(即图中任务分配器到业务服务器的连接线),需要选择合适的连接方式,并且对连接进行管理。例如,连接建立、连接检测、连接中断后如何处理等。
任务分配器需要增加分配算法。例如,是采用轮询算法,还是按权重分配,又或者按照负载进行分配。如果按照服务器的负载进行分配,则业务服务器还要能够上报自己的状态给任务分配器。
2. 任务分解
通过任务分配的方式,我们能够突破单台机器处理性能的瓶颈,通过增加更多的机器来满足业务的性能需求,但如果业务本身也越来越复杂,单纯只通过任务分配的方式来扩展性能,收益会越来越低。例如,业务简单的时候 1 台机器扩展到 10 台机器,性能能够提升 8 倍(需要扣除机器群带来的部分性能损耗,因此无法达到理论上的 10 倍那么高),但如果业务越来越复杂,1 台机器扩展到 10 台,性能可能只能提升 5 倍。造成这种现象的主要原因是业务越来越复杂,单台机器处理的性能会越来越低。为了能够继续提升性能,我们需要采取第二种方式:任务分解。
05 | 复杂度来源:高可用
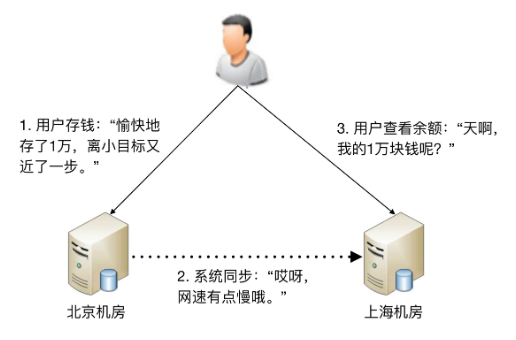
高可用状态决策无论是计算高可用还是存储高可用,其基础都是“状态决策”,即系统需要能够判断当前的状态是正常还是异常,如果出现了异常就要采取行动来保证高可用。如果状态决策本身都是有错误或者有偏差的,那么后续的任何行动和处理无论多么完美也都没有意义和价值。但在具体实践的过程中,恰好存在一个本质的矛盾:通过冗余来实现的高可用系统,状态决策本质上就不可能做到完全正确。下面我基于几种常见的决策方式进行详细分析。
1. 独裁式 当决策者本身故障时,整个系统就无法实现准确的状态决策。如果决策者本身又做一套状态决策,那就陷入一个递归的死循环了
2. 协商式 最常用的协商式决策就是主备决策。 应该以哪个连接为准?实际上这也是一个无解的答案,无论以哪个连接为准,在特定场景下都可能存在问题
3. 民主式 民主式决策指的是多个独立的个体通过投票的方式来进行状态决策。例如,ZooKeeper 集群在选举 leader 时就是采用这种方式 民主式决策和协商式决策比较类似,其基础都是独立的个体之间交换信息,每个个体做出自己的决策,然后按照“多数取胜”的规则来确定最终的状态。不同点在于民主式决策比协商式决策要复杂得多,ZooKeeper 的选举算法 ZAB,绝大部分人都看得云里雾里,更不用说用代码来实现这套算法了。
06 | 复杂度来源:可扩展性
预测变化的复杂性在于:不能每个设计点都考虑可扩展性。不能完全不考虑可扩展性。所有的预测都存在出错的可能性。对于架构师来说,如何把握预测的程度和提升预测结果的准确性,是一件很复杂的事情,而且没有通用的标准可以简单套上去,更多是靠自己的经验、直觉。所以架构设计评审的时候,经常会出现两个设计师对某个判断争得面红耳赤的情况,原因就在于没有明确标准,不同的人理解和判断有偏差,而最终又只能选择其中一个判断
2 年法则 : 只预测 2 年内的可能变化,不要试图预测 5 年甚至 10 年后的变化
应对变化:
方案一:提炼出“变化层”和“稳定层”第一种应对变化的常见方案是:将不变的部分封装在一个独立的“稳定层”,将“变化”封装在一个“变化层”(也叫“适配层”)。这种方案的核心思想是通过变化层来隔离变化。
方案二:提炼出“抽象层”和“实现层” 提炼出一个“抽象层”和一个“实现层”。如果说方案一的核心思想是通过变化层来隔离变化,那么方案二的核心思想就是通过实现层来封装变化
规则引擎和设计模式类似,都是通过灵活的设计来达到可扩展的目的,但“灵活的设计”本身就是一件复杂的事情,不说别的,光是把 23 种设计模式全部理解和备注,都是一件很困难的事情。1 写 2 抄 3 重构原则
举个最简单的例子,假设你们的创新业务要对接第三方钱包,按照这个原则,就可以这样做:
1 写:最开始你们选择了微信钱包对接,此时不需要考虑太多可扩展性,直接快速对照微信支付的 API 对接即可,因为业务是否能做起来还不确定。
2 抄:后来你们发现业务发展不错,决定要接入支付宝,此时还是可以不考虑可扩展,直接把原来微信支付接入的代码拷贝过来,然后对照支付宝的 API,快速修改上线。
3 重构:因为业务发展不错,为了方便更多用户,你们决定接入银联云闪付,此时就需要考虑重构,参考设计模式的模板方法和策略模式将支付对接的功能进行封装
07 | 复杂度来源:低成本、安全、规模
安全:
无论是引入新技术,还是自己创造新技术,都是一件复杂的事情。引入新技术的主要复杂度在于需要去熟悉新技术,并且将新技术与已有技术结合起来;创造新技术的主要复杂度在于需要自己去创造全新的理念和技术,并且新技术跟旧技术相比,需要有质的飞跃。
例如,常见的 XSS 攻击、CSRF 攻击、SQL 注入、Windows 漏洞、密码破解等,本质上是因为系统实现有漏洞,黑客有了可乘之机。黑客会利用各种漏洞潜入系统,这种行为就像小偷一样,黑客和小偷的手法都是利用系统或家中不完善的地方潜入,并进行破坏或者盗取。因此形象地说,功能安全其实就是“防小偷”
如果说功能安全是“防小偷”,那么架构安全就是“防强盗”
规模带来复杂度的主要原因就是“量变引起质变” 最近几年火热的“大数据”就是在这种背景下诞生的
如果因为业务的发展,单表数据达到了 10 亿行,就会产生很多问题,例如:添加索引会很慢,可能需要几个小时,这几个小时内数据库表是无法插入数据的,相当于业务停机了。修改表结构和添加索引存在类似的问题,耗时可能会很长。即使有索引,索引的性能也可能会很低,因为数据量太大。数据库备份耗时很长。……
因此,当 MySQL 单表数据量太大时,我们必须考虑将单表拆分为多表,这个拆分过程也会引入更多复杂性,例如:拆表的规则是什么?以用户表为例:是按照用户 id 拆分表,还是按照用户注册时间拆表?拆完表后查询如何处理?以用户表为例:假设按照用户 id 拆表,当业务需要查询学历为“本科”以上的用户时,要去很多表查询才能得到最终结果,怎么保证性能?
本文来自博客园,作者:董锡振,转载请注明原文链接:https://www.cnblogs.com/dongxizhen/p/16207751.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能