

【转载】基于 Redis 的分布式锁到底安全吗?
转载自原文地址 https://juejin.cn/post/6844903465181773831
一篇非常非常棒的关于redis分布式锁细节的思考和总结文章
【完整版】
网上有关Redis分布式锁的文章可谓多如牛毛了,不信的话你可以拿关键词“Redis 分布式锁”随便到哪个搜索引擎上去搜索一下就知道了。这些文章的思路大体相近,给出的实现算法也看似合乎逻辑,但当我们着手去实现它们的时候,却发现如果你越是仔细推敲,疑虑也就越来越多。
实际上,大概在一年以前,关于Redis分布式锁的安全性问题,在分布式系统专家Martin Kleppmann和Redis的作者antirez之间就发生过一场争论。由于对这个问题一直以来比较关注,所以我前些日子仔细阅读了与这场争论相关的资料。这场争论的大概过程是这样的:为了规范各家对基于Redis的分布式锁的实现,Redis的作者提出了一个更安全的实现,叫做Redlock。有一天,Martin Kleppmann写了一篇blog,分析了Redlock在安全性上存在的一些问题。然后Redis的作者立即写了一篇blog来反驳Martin的分析。但Martin表示仍然坚持原来的观点。随后,这个问题在Twitter和Hacker News上引发了激烈的讨论,很多分布式系统的专家都参与其中。
对于那些对分布式系统感兴趣的人来说,这个事件非常值得关注。不管你是刚接触分布式系统的新手,还是有着多年分布式开发经验的老手,读完这些分析和评论之后,大概都会有所收获。要知道,亲手实现过Redis Cluster这样一个复杂系统的antirez,足以算得上分布式领域的一名专家了。但对于由分布式锁引发的一系列问题的分析中,不同的专家却能得出迥异的结论,从中我们可以窥见分布式系统相关的问题具有何等的复杂性。实际上,在分布式系统的设计中经常发生的事情是:许多想法初看起来毫无破绽,而一旦详加考量,却发现不是那么天衣无缝。
下面,我们就从头至尾把这场争论过程中各方的观点进行一下回顾和分析。在这个过程中,我们把影响分布式锁的安全性的那些技术细节展开进行讨论,这将是一件很有意思的事情。这也是一个比较长的故事。当然,其中也免不了包含一些小“八卦”。
Redlock算法
就像本文开头所讲的,借助Redis来实现一个分布式锁(Distributed Lock)的做法,已经有很多人尝试过。人们构建这样的分布式锁的目的,是为了对一些共享资源进行互斥访问。
但是,这些实现虽然思路大体相近,但实现细节上各不相同,它们能提供的安全性和可用性也不尽相同。所以,Redis的作者antirez给出了一个更好的实现,称为Redlock,算是Redis官方对于实现分布式锁的指导规范。Redlock的算法描述就放在Redis的官网上:
在Redlock之前,很多人对于分布式锁的实现都是基于单个Redis节点的。而Redlock是基于多个Redis节点(都是Master)的一种实现。为了能理解Redlock,我们首先需要把简单的基于单Redis节点的算法描述清楚,因为它是Redlock的基础。
基于单Redis节点的分布式锁
首先,Redis客户端为了获取锁,向Redis节点发送如下命令:
SET resource_name my_random_value NX PX 30000
上面的命令如果执行成功,则客户端成功获取到了锁,接下来就可以访问共享资源了;而如果上面的命令执行失败,则说明获取锁失败。
注意,在上面的SET命令中:
my_random_value是由客户端生成的一个随机字符串,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的。NX表示只有当resource_name对应的key值不存在的时候才能SET成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁。PX 30000表示这个锁有一个30秒的自动过期时间。当然,这里30秒只是一个例子,客户端可以选择合适的过期时间。
最后,当客户端完成了对共享资源的操作之后,执行下面的Redis Lua脚本来释放锁:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这段Lua脚本在执行的时候要把前面的my_random_value作为ARGV[1]的值传进去,把resource_name作为KEYS[1]的值传进去。
至此,基于单Redis节点的分布式锁的算法就描述完了。这里面有好几个问题需要重点分析一下。
首先第一个问题,这个锁必须要设置一个过期时间。否则的话,当一个客户端获取锁成功之后,假如它崩溃了,或者由于发生了网络分割(network partition)导致它再也无法和Redis节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了。antirez在后面的分析中也特别强调了这一点,而且把这个过期时间称为锁的有效时间(lock validity time)。获得锁的客户端必须在这个时间之内完成对共享资源的访问。
第二个问题,第一步获取锁的操作,网上不少文章把它实现成了两个Redis命令:
SETNX resource_name my_random_value
EXPIRE resource_name 30
虽然这两个命令和前面算法描述中的一个SET命令执行效果相同,但却不是原子的。如果客户端在执行完SETNX后崩溃了,那么就没有机会执行EXPIRE了,导致它一直持有这个锁。
第三个问题,也是antirez指出的,设置一个随机字符串my_random_value是很有必要的,它保证了一个客户端释放的锁必须是自己持有的那个锁。假如获取锁时SET的不是一个随机字符串,而是一个固定值,那么可能会发生下面的执行序列:
- 客户端1获取锁成功。
- 客户端1在某个操作上阻塞了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,释放掉了客户端2持有的锁。
之后,客户端2在访问共享资源的时候,就没有锁为它提供保护了。
第四个问题,释放锁的操作必须使用Lua脚本来实现。释放锁其实包含三步操作:'GET'、判断和'DEL',用Lua脚本来实现能保证这三步的原子性。否则,如果把这三步操作放到客户端逻辑中去执行的话,就有可能发生与前面第三个问题类似的执行序列:
- 客户端1获取锁成功。
- 客户端1访问共享资源。
- 客户端1为了释放锁,先执行'GET'操作获取随机字符串的值。
- 客户端1判断随机字符串的值,与预期的值相等。
- 客户端1由于某个原因阻塞住了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,执行
DEL操纵,释放掉了客户端2持有的锁。
实际上,在上述第三个问题和第四个问题的分析中,如果不是客户端阻塞住了,而是出现了大的网络延迟,也有可能导致类似的执行序列发生。
前面的四个问题,只要实现分布式锁的时候加以注意,就都能够被正确处理。但除此之外,antirez还指出了一个问题,是由failover引起的,却是基于单Redis节点的分布式锁无法解决的。正是这个问题催生了Redlock的出现。
这个问题是这样的。假如Redis节点宕机了,那么所有客户端就都无法获得锁了,服务变得不可用。为了提高可用性,我们可以给这个Redis节点挂一个Slave,当Master节点不可用的时候,系统自动切到Slave上(failover)。但由于Redis的主从复制(replication)是异步的,这可能导致在failover过程中丧失锁的安全性。考虑下面的执行序列:
- 客户端1从Master获取了锁。
- Master宕机了,存储锁的key还没有来得及同步到Slave上。
- Slave升级为Master。
- 客户端2从新的Master获取到了对应同一个资源的锁。
于是,客户端1和客户端2同时持有了同一个资源的锁。锁的安全性被打破。针对这个问题,antirez设计了Redlock算法,我们接下来会讨论。
【其它疑问】
前面这个算法中出现的锁的有效时间(lock validity time),设置成多少合适呢?如果设置太短的话,锁就有可能在客户端完成对于共享资源的访问之前过期,从而失去保护;如果设置太长的话,一旦某个持有锁的客户端释放锁失败,那么就会导致所有其它客户端都无法获取锁,从而长时间内无法正常工作。看来真是个两难的问题。
而且,在前面对于随机字符串my_random_value的分析中,antirez也在文章中承认的确应该考虑客户端长期阻塞导致锁过期的情况。如果真的发生了这种情况,那么共享资源是不是已经失去了保护呢?antirez重新设计的Redlock是否能解决这些问题呢?
分布式锁Redlock
由于前面介绍的基于单Redis节点的分布式锁在failover的时候会产生解决不了的安全性问题,因此antirez提出了新的分布式锁的算法Redlock,它基于N个完全独立的Redis节点(通常情况下N可以设置成5)。
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁的操作:
- 获取当前时间(毫秒数)。
- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串
my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。 - 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
当然,上面描述的只是获取锁的过程,而释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
由于N个Redis节点中的大多数能正常工作就能保证Redlock正常工作,因此理论上它的可用性更高。我们前面讨论的单Redis节点的分布式锁在failover的时候锁失效的问题,在Redlock中不存在了,但如果有节点发生崩溃重启,还是会对锁的安全性有影响的。具体的影响程度跟Redis对数据的持久化程度有关。
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- 客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
- 节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
在默认情况下,Redis的AOF持久化方式是每秒写一次磁盘(即执行fsync),因此最坏情况下可能丢失1秒的数据。为了尽可能不丢数据,Redis允许设置成每次修改数据都进行fsync,但这会降低性能。当然,即使执行了fsync也仍然有可能丢失数据(这取决于系统而不是Redis的实现)。所以,上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,antirez又提出了延迟重启(delayed restarts)的概念。也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
关于Redlock还有一点细节值得拿出来分析一下:在最后释放锁的时候,antirez在算法描述中特别强调,客户端应该向所有Redis节点发起释放锁的操作。也就是说,即使当时向某个节点获取锁没有成功,在释放锁的时候也不应该漏掉这个节点。这是为什么呢?设想这样一种情况,客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
【其它疑问】
前面在讨论单Redis节点的分布式锁的时候,最后我们提出了一个疑问,如果客户端长期阻塞导致锁过期,那么它接下来访问共享资源就不安全了(没有了锁的保护)。这个问题在Redlock中是否有所改善呢?显然,这样的问题在Redlock中是依然存在的。
另外,在算法第4步成功获取了锁之后,如果由于获取锁的过程消耗了较长时间,重新计算出来的剩余的锁有效时间很短了,那么我们还来得及去完成共享资源访问吗?如果我们认为太短,是不是应该立即进行锁的释放操作?那到底多短才算呢?又是一个选择难题。
Martin的分析
Martin Kleppmann在2016-02-08这一天发表了一篇blog,名字叫"How to do distributed locking
",地址如下:
Martin在这篇文章中谈及了分布式系统的很多基础性的问题(特别是分布式计算的异步模型),对分布式系统的从业者来说非常值得一读。这篇文章大体可以分为两大部分:
- 前半部分,与Redlock无关。Martin指出,即使我们拥有一个完美实现的分布式锁(带自动过期功能),在没有共享资源参与进来提供某种fencing机制的前提下,我们仍然不可能获得足够的安全性。
- 后半部分,是对Redlock本身的批评。Martin指出,由于Redlock本质上是建立在一个同步模型之上,对系统的记时假设(timing assumption)有很强的要求,因此本身的安全性是不够的。
首先我们讨论一下前半部分的关键点。Martin给出了下面这样一份时序图:
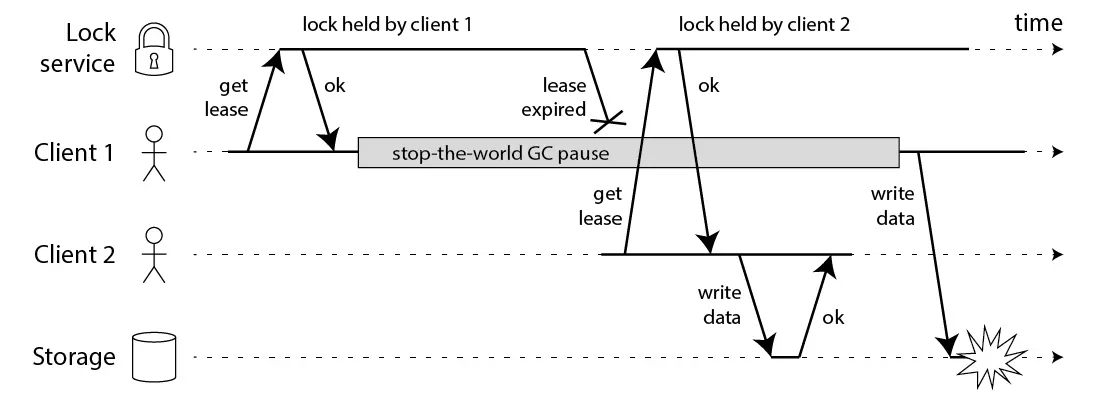
在上面的时序图中,假设锁服务本身是没有问题的,它总是能保证任一时刻最多只有一个客户端获得锁。上图中出现的lease这个词可以暂且认为就等同于一个带有自动过期功能的锁。客户端1在获得锁之后发生了很长时间的GC pause,在此期间,它获得的锁过期了,而客户端2获得了锁。当客户端1从GC pause中恢复过来的时候,它不知道自己持有的锁已经过期了,它依然向共享资源(上图中是一个存储服务)发起了写数据请求,而这时锁实际上被客户端2持有,因此两个客户端的写请求就有可能冲突(锁的互斥作用失效了)。
初看上去,有人可能会说,既然客户端1从GC pause中恢复过来以后不知道自己持有的锁已经过期了,那么它可以在访问共享资源之前先判断一下锁是否过期。但仔细想想,这丝毫也没有帮助。因为GC pause可能发生在任意时刻,也许恰好在判断完之后。
也有人会说,如果客户端使用没有GC的语言来实现,是不是就没有这个问题呢?Martin指出,系统环境太复杂,仍然有很多原因导致进程的pause,比如虚存造成的缺页故障(page fault),再比如CPU资源的竞争。即使不考虑进程pause的情况,网络延迟也仍然会造成类似的结果。
总结起来就是说,即使锁服务本身是没有问题的,而仅仅是客户端有长时间的pause或网络延迟,仍然会造成两个客户端同时访问共享资源的冲突情况发生。而这种情况其实就是我们在前面已经提出来的“客户端长期阻塞导致锁过期”的那个疑问。
那怎么解决这个问题呢?Martin给出了一种方法,称为fencing token。fencing token是一个单调递增的数字,当客户端成功获取锁的时候它随同锁一起返回给客户端。而客户端访问共享资源的时候带着这个fencing token,这样提供共享资源的服务就能根据它进行检查,拒绝掉延迟到来的访问请求(避免了冲突)。如下图:
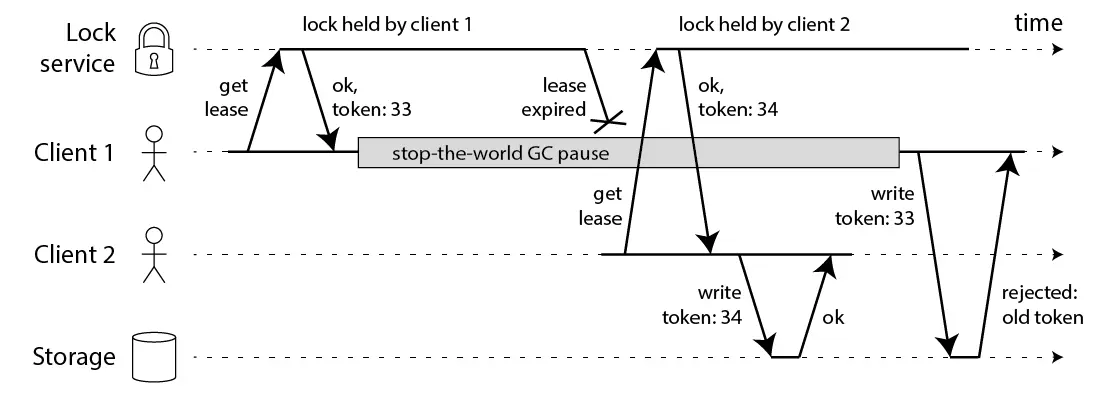
在上图中,客户端1先获取到的锁,因此有一个较小的fencing token,等于33,而客户端2后获取到的锁,有一个较大的fencing token,等于34。客户端1从GC pause中恢复过来之后,依然是向存储服务发送访问请求,但是带了fencing token = 33。存储服务发现它之前已经处理过34的请求,所以会拒绝掉这次33的请求。这样就避免了冲突。
现在我们再讨论一下Martin的文章的后半部分。
Martin在文中构造了一些事件序列,能够让Redlock失效(两个客户端同时持有锁)。为了说明Redlock对系统记时(timing)的过分依赖,他首先给出了下面的一个例子(还是假设有5个Redis节点A, B, C, D, E):
- 客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
- 节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- 客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
- 客户端1和客户端2现在都认为自己持有了锁。
上面这种情况之所以有可能发生,本质上是因为Redlock的安全性(safety property)对系统的时钟有比较强的依赖,一旦系统的时钟变得不准确,算法的安全性也就保证不了了。Martin在这里其实是要指出分布式算法研究中的一些基础性问题,或者说一些常识问题,即好的分布式算法应该基于异步模型(asynchronous model),算法的安全性不应该依赖于任何记时假设(timing assumption)。在异步模型中:进程可能pause任意长的时间,消息可能在网络中延迟任意长的时间,甚至丢失,系统时钟也可能以任意方式出错。一个好的分布式算法,这些因素不应该影响它的安全性(safety property),只可能影响到它的活性(liveness property),也就是说,即使在非常极端的情况下(比如系统时钟严重错误),算法顶多是不能在有限的时间内给出结果而已,而不应该给出错误的结果。这样的算法在现实中是存在的,像比较著名的Paxos,或Raft。但显然按这个标准的话,Redlock的安全性级别是达不到的。
随后,Martin觉得前面这个时钟跳跃的例子还不够,又给出了一个由客户端GC pause引发Redlock失效的例子。如下:
- 客户端1向Redis节点A, B, C, D, E发起锁请求。
- 各个Redis节点已经把请求结果返回给了客户端1,但客户端1在收到请求结果之前进入了长时间的GC pause。
- 在所有的Redis节点上,锁过期了。
- 客户端2在A, B, C, D, E上获取到了锁。
- 客户端1从GC pause从恢复,收到了前面第2步来自各个Redis节点的请求结果。客户端1认为自己成功获取到了锁。
- 客户端1和客户端2现在都认为自己持有了锁。
Martin给出的这个例子其实有点小问题。在Redlock算法中,客户端在完成向各个Redis节点的获取锁的请求之后,会计算这个过程消耗的时间,然后检查是不是超过了锁的有效时间(lock validity time)。也就是上面的例子中第5步,客户端1从GC pause中恢复过来以后,它会通过这个检查发现锁已经过期了,不会再认为自己成功获取到锁了。随后antirez在他的反驳文章中就指出来了这个问题,但Martin认为这个细节对Redlock整体的安全性没有本质的影响。
抛开这个细节,我们可以分析一下Martin举这个例子的意图在哪。初看起来,这个例子跟文章前半部分分析通用的分布式锁时给出的GC pause的时序图是基本一样的,只不过那里的GC pause发生在客户端1获得了锁之后,而这里的GC pause发生在客户端1获得锁之前。但两个例子的侧重点不太一样。Martin构造这里的这个例子,是为了强调在一个分布式的异步环境下,长时间的GC pause或消息延迟(上面这个例子中,把GC pause换成Redis节点和客户端1之间的消息延迟,逻辑不变),会让客户端获得一个已经过期的锁。从客户端1的角度看,Redlock的安全性被打破了,因为客户端1收到锁的时候,这个锁已经失效了,而Redlock同时还把这个锁分配给了客户端2。换句话说,Redis服务器在把锁分发给客户端的途中,锁就过期了,但又没有有效的机制让客户端明确知道这个问题。而在之前的那个例子中,客户端1收到锁的时候锁还是有效的,锁服务本身的安全性可以认为没有被打破,后面虽然也出了问题,但问题是出在客户端1和共享资源服务器之间的交互上。
在Martin的这篇文章中,还有一个很有见地的观点,就是对锁的用途的区分。他把锁的用途分为两种:
- 为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的email。
- 为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,或者其它严重的问题。
最后,Martin得出了如下的结论:
- 如果是为了效率(efficiency)而使用分布式锁,允许锁的偶尔失效,那么使用单Redis节点的锁方案就足够了,简单而且效率高。Redlock则是个过重的实现(heavyweight)。
- 如果是为了正确性(correctness)在很严肃的场合使用分布式锁,那么不要使用Redlock。它不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分(对于timing)。而且,它没有一个机制能够提供fencing token。那应该使用什么技术呢?Martin认为,应该考虑类似Zookeeper的方案,或者支持事务的数据库。
Martin对Redlock算法的形容是:
neither fish nor fowl (非驴非马)
【其它疑问】
- Martin提出的fencing token的方案,需要对提供共享资源的服务进行修改,这在现实中可行吗?
- 根据Martin的说法,看起来,如果资源服务器实现了fencing token,它在分布式锁失效的情况下也仍然能保持资源的互斥访问。这是不是意味着分布式锁根本没有存在的意义了?
- 资源服务器需要检查fencing token的大小,如果提供资源访问的服务也是包含多个节点的(分布式的),那么这里怎么检查才能保证fencing token在多个节点上是递增的呢?
- Martin对于fencing token的举例中,两个fencing token到达资源服务器的顺序颠倒了(小的fencing token后到了),这时资源服务器检查出了这一问题。如果客户端1和客户端2都发生了GC pause,两个fencing token都延迟了,它们几乎同时到达了资源服务器,但保持了顺序,那么资源服务器是不是就检查不出问题了?这时对于资源的访问是不是就发生冲突了?
- 分布式锁+fencing的方案是绝对正确的吗?能证明吗?
(以上是上部)
自从我写完这个话题的上半部分之后,就感觉头脑中出现了许多细小的声音,久久挥之不去。它们就像是在为了一些鸡毛蒜皮的小事而相互争吵个不停。的确,有关分布式的话题就是这样,琐碎异常,而且每个人说的话听起来似乎都有道理。
今天,我们就继续探讨这个话题的后半部分。本文中,我们将从antirez反驳Martin Kleppmann的观点开始讲起,然后会涉及到Hacker News上出现的一些讨论内容,接下来我们还会讨论到基于Zookeeper和Chubby的分布式锁是怎样的,并和Redlock进行一些对比。最后,我们会提到Martin对于这一事件的总结。
antirez的反驳
Martin在发表了那篇分析分布式锁的blog (How to do distributed locking)之后,该文章在Twitter和Hacker News上引发了广泛的讨论。但人们更想听到的是Redlock的作者antirez对此会发表什么样的看法。
Martin的那篇文章是在2016-02-08这一天发表的,但据Martin说,他在公开发表文章的一星期之前就把草稿发给了antirez进行review,而且他们之间通过email进行了讨论。不知道Martin有没有意料到,antirez对于此事的反应很快,就在Martin的文章发表出来的第二天,antirez就在他的博客上贴出了他对于此事的反驳文章,名字叫"Is Redlock safe?",地址如下:
这是高手之间的过招。antirez这篇文章也条例非常清晰,并且中间涉及到大量的细节。antirez认为,Martin的文章对于Redlock的批评可以概括为两个方面(与Martin文章的前后两部分对应):
- 带有自动过期功能的分布式锁,必须提供某种fencing机制来保证对共享资源的真正的互斥保护。Redlock提供不了这样一种机制。
- Redlock构建在一个不够安全的系统模型之上。它对于系统的记时假设(timing assumption)有比较强的要求,而这些要求在现实的系统中是无法保证的。
antirez对这两方面分别进行了反驳。
首先,关于fencing机制。antirez对于Martin的这种论证方式提出了质疑:既然在锁失效的情况下已经存在一种fencing机制能继续保持资源的互斥访问了,那为什么还要使用一个分布式锁并且还要求它提供那么强的安全性保证呢?即使退一步讲,Redlock虽然提供不了Martin所讲的递增的fencing token,但利用Redlock产生的随机字符串(my_random_value)可以达到同样的效果。这个随机字符串虽然不是递增的,但却是唯一的,可以称之为unique token。antirez举了个例子,比如,你可以用它来实现“Check and Set”操作,原话是:
When starting to work with a shared resource, we set its state to “
<token>”, then we operate the read-modify-write only if the token is still the same when we write.
(译文:当开始和共享资源交互的时候,我们将它的状态设置成“<token>”,然后仅在token没改变的情况下我们才执行“读取-修改-写回”操作。)
第一遍看到这个描述的时候,我个人是感觉没太看懂的。“Check and Set”应该就是我们平常听到过的CAS操作了,但它如何在这个场景下工作,antirez并没有展开说(在后面讲到Hacker News上的讨论的时候,我们还会提到)。
然后,antirez的反驳就集中在第二个方面上:关于算法在记时(timing)方面的模型假设。在我们前面分析Martin的文章时也提到过,Martin认为Redlock会失效的情况主要有三种:
- 时钟发生跳跃。
- 长时间的GC pause。
- 长时间的网络延迟。
antirez肯定意识到了这三种情况对Redlock最致命的其实是第一点:时钟发生跳跃。这种情况一旦发生,Redlock是没法正常工作的。而对于后两种情况来说,Redlock在当初设计的时候已经考虑到了,对它们引起的后果有一定的免疫力。所以,antirez接下来集中精力来说明通过恰当的运维,完全可以避免时钟发生大的跳动,而Redlock对于时钟的要求在现实系统中是完全可以满足的。
Martin在提到时钟跳跃的时候,举了两个可能造成时钟跳跃的具体例子:
- 系统管理员手动修改了时钟。
- 从NTP服务收到了一个大的时钟更新事件。
antirez反驳说:
- 手动修改时钟这种人为原因,不要那么做就是了。否则的话,如果有人手动修改Raft协议的持久化日志,那么就算是Raft协议它也没法正常工作了。
- 使用一个不会进行“跳跃”式调整系统时钟的ntpd程序(可能是通过恰当的配置),对于时钟的修改通过多次微小的调整来完成。
而Redlock对时钟的要求,并不需要完全精确,它只需要时钟差不多精确就可以了。比如,要记时5秒,但可能实际记了4.5秒,然后又记了5.5秒,有一定的误差。不过只要误差不超过一定范围,这对Redlock不会产生影响。antirez认为呢,像这样对时钟精度并不是很高的要求,在实际环境中是完全合理的。
好了,到此为止,如果你相信antirez这里关于时钟的论断,那么接下来antirez的分析就基本上顺理成章了。
关于Martin提到的能使Redlock失效的后两种情况,Martin在分析的时候恰好犯了一个错误(在本文上半部分已经提到过)。在Martin给出的那个由客户端GC pause引发Redlock失效的例子中,这个GC pause引发的后果相当于在锁服务器和客户端之间发生了长时间的消息延迟。Redlock对于这个情况是能处理的。回想一下Redlock算法的具体过程,它使用起来的过程大体可以分成5步:
- 获取当前时间。
- 完成获取锁的整个过程(与N个Redis节点交互)。
- 再次获取当前时间。
- 把两个时间相减,计算获取锁的过程是否消耗了太长时间,导致锁已经过期了。如果没过期,
- 客户端持有锁去访问共享资源。
在Martin举的例子中,GC pause或网络延迟,实际发生在上述第1步和第3步之间。而不管在第1步和第3步之间由于什么原因(进程停顿或网络延迟等)导致了大的延迟出现,在第4步都能被检查出来,不会让客户端拿到一个它认为有效而实际却已经过期的锁。当然,这个检查依赖系统时钟没有大的跳跃。这也就是为什么antirez在前面要对时钟条件进行辩护的原因。
有人会说,在第3步之后,仍然可能会发生延迟啊。没错,antirez承认这一点,他对此有一段很有意思的论证,原话如下:
The delay can only happen after steps 3, resulting into the lock to be considered ok while actually expired, that is, we are back at the first problem Martin identified of distributed locks where the client fails to stop working to the shared resource before the lock validity expires. Let me tell again how this problem is common with all the distributed locks implementations, and how the token as a solution is both unrealistic and can be used with Redlock as well.
(译文:延迟只能发生在第3步之后,这导致锁被认为是有效的而实际上已经过期了,也就是说,我们回到了Martin指出的第一个问题上,客户端没能够在锁的有效性过期之前完成与共享资源的交互。让我再次申明一下,这个问题对于所有的分布式锁的实现是普遍存在的,而且基于token的这种解决方案是不切实际的,但也能和Redlock一起用。)
这里antirez所说的“Martin指出的第一个问题”具体是什么呢?在本文上半部分我们提到过,Martin的文章分为两大部分,其中前半部分与Redlock没有直接关系,而是指出了任何一种带自动过期功能的分布式锁在没有提供fencing机制的前提下都有可能失效。这里antirez所说的就是指的Martin的文章的前半部分。换句话说,对于大延迟给Redlock带来的影响,恰好与Martin在文章的前半部分针对所有的分布式锁所做的分析是一致的,而这种影响不单单针对Redlock。Redlock的实现已经保证了它是和其它任何分布式锁的安全性是一样的。当然,与其它“更完美”的分布式锁相比,Redlock似乎提供不了Martin提出的那种递增的token,但antirez在前面已经分析过了,关于token的这种论证方式本身就是“不切实际”的,或者退一步讲,Redlock能提供的unique token也能够提供完全一样的效果。
另外,关于大延迟对Redlock的影响,antirez和Martin在Twitter上有下面的对话:
antirez:
@martinkl so I wonder if after my reply, we can at least agree about unbound messages delay to don’t cause any harm.Martin:
@antirez Agree about message delay between app and lock server. Delay between app and resource being accessed is still problematic.(译文:
antirez问:我想知道,在我发文回复之后,我们能否在一点上达成一致,就是大的消息延迟不会给Redlock的运行造成损害。
Martin答:对于客户端和锁服务器之间的消息延迟,我同意你的观点。但客户端和被访问资源之间的延迟还是有问题的。)
通过这段对话可以看出,对于Redlock在第4步所做的锁有效性的检查,Martin是予以肯定的。但他认为客户端和资源服务器之间的延迟还是会带来问题的。Martin在这里说的有点模糊。就像antirez前面分析的,客户端和资源服务器之间的延迟,对所有的分布式锁的实现都会带来影响,这不单单是Redlock的问题了。
以上就是antirez在blog中所说的主要内容。有一些点值得我们注意一下:
- antirez是同意大的系统时钟跳跃会造成Redlock失效的。在这一点上,他与Martin的观点的不同在于,他认为在实际系统中是可以避免大的时钟跳跃的。当然,这取决于基础设施和运维方式。
- antirez在设计Redlock的时候,是充分考虑了网络延迟和程序停顿所带来的影响的。但是,对于客户端和资源服务器之间的延迟(即发生在算法第3步之后的延迟),antirez是承认所有的分布式锁的实现,包括Redlock,是没有什么好办法来应对的。
讨论进行到这,Martin和antirez之间谁对谁错其实并不是那么重要了。只要我们能够对Redlock(或者其它分布式锁)所能提供的安全性的程度有充分的了解,那么我们就能做出自己的选择了。
Hacker News上的一些讨论
针对Martin和antirez的两篇blog,很多技术人员在Hacker News上展开了激烈的讨论。这些讨论所在地址如下:
- 针对Martin的blog的讨论:news.ycombinator.com/item?id=110…
- 针对antirez的blog的讨论:news.ycombinator.com/item?id=110…
在Hacker News上,antirez积极参与了讨论,而Martin则始终置身事外。
下面我把这些讨论中一些有意思的点拿出来与大家一起分享一下(集中在对于fencing token机制的讨论上)。
关于antirez提出的“Check and Set”操作,他在blog里并没有详加说明。果然,在Hacker News上就有人出来问了。antirez给出的答复如下:
You want to modify locked resource X. You set X.currlock = token. Then you read, do whatever you want, and when you write, you "write-if-currlock == token". If another client did X.currlock = somethingelse, the transaction fails.
翻译一下可以这样理解:假设你要修改资源X,那么遵循下面的伪码所定义的步骤。
- 先设置X.currlock = token。
- 读出资源X(包括它的值和附带的X.currlock)。
- 按照"write-if-currlock == token"的逻辑,修改资源X的值。意思是说,如果对X进行修改的时候,X.currlock仍然和当初设置进去的token相等,那么才进行修改;如果这时X.currlock已经是其它值了,那么说明有另外一方也在试图进行修改操作,那么放弃当前的修改,从而避免冲突。
随后Hacker News上一位叫viraptor的用户提出了异议,它给出了这样一个执行序列:
- A: X.currlock = Token_ID_A
- A: resource read
- A: is X.currlock still Token_ID_A? yes
- B: X.currlock = Token_ID_B
- B: resource read
- B: is X.currlock still Token_ID_B? yes
- B: resource write
- A: resource write
到了最后两步,两个客户端A和B同时进行写操作,冲突了。不过,这位用户应该是理解错了antirez给出的修改过程了。按照antirez的意思,判断X.currlock是否修改过和对资源的写操作,应该是一个原子操作。只有这样理解才能合乎逻辑,否则的话,这个过程就有严重的破绽。这也是为什么antirez之前会对fencing机制产生质疑:既然资源服务器本身都能提供互斥的原子操作了,为什么还需要一个分布式锁呢?因此,antirez认为这种fencing机制是很累赘的,他之所以还是提出了这种“Check and Set”操作,只是为了证明在提供fencing token这一点上,Redlock也能做到。但是,这里仍然有一些不明确的地方,如果将"write-if-currlock == token"看做是原子操作的话,这个逻辑势必要在资源服务器上执行,那么第二步为什么还要“读出资源X”呢?除非这个“读出资源X”的操作也是在资源服务器上执行,它包含在“判断-写回”这个原子操作里面。而假如不这样理解的话,“读取-判断-写回”这三个操作都放在客户端执行,那么看不出它们如何才能实现原子性操作。在下面的讨论中,我们暂时忽略“读出资源X”这一步。
这个基于random token的“Check and Set”操作,如果与Martin提出的递增的fencing token对比一下的话,至少有两点不同:
- “Check and Set”对于写操作要分成两步来完成(设置token、判断-写回),而递增的fencing token机制只需要一步(带着token向资源服务器发起写请求)。
- 递增的fencing token机制能保证最终操作共享资源的顺序,那些延迟时间太长的操作就无法操作共享资源了。但是基于random token的“Check and Set”操作不会保证这个顺序,那些延迟时间太长的操作如果后到达了,它仍然有可能操作共享资源(当然是以互斥的方式)。
对于前一点不同,我们在后面的分析中会看到,如果资源服务器也是分布式的,那么使用递增的fencing token也要变成两步。
而对于后一点操作顺序上的不同,antirez认为这个顺序没有意义,关键是能互斥访问就行了。他写下了下面的话:
So the goal is, when race conditions happen, to avoid them in some way.
......
Note also that when it happens that, because of delays, the clients are accessing concurrently, the lock ID has little to do with the order in which the operations were indented to happen.
(译文: 我们的目标是,当竞争条件出现的时候,能够以某种方式避免。
......
还需要注意的是,当那种竞争条件出现的时候,比如由于延迟,客户端是同时来访问的,锁的ID的大小顺序跟那些操作真正想执行的顺序,是没有什么关系的。)
这里的lock ID,跟Martin说的递增的token是一回事。
随后,antirez举了一个“将名字加入列表”的操作的例子:
- T0: Client A receives new name to add from web.
- T0: Client B is idle
- T1: Client A is experiencing pauses.
- T1: Client B receives new name to add from web.
- T2: Client A is experiencing pauses.
- T2: Client B receives a lock with ID 1
- T3: Client A receives a lock with ID 2
你看,两个客户端(其实是Web服务器)执行“添加名字”的操作,A本来是排在B前面的,但获得锁的顺序却是B排在A前面。因此,antirez说,锁的ID的大小顺序跟那些操作真正想执行的顺序,是没有什么关系的。关键是能排出一个顺序来,能互斥访问就行了。那么,至于锁的ID是递增的,还是一个random token,自然就不那么重要了。
Martin提出的fencing token机制,给人留下了无尽的疑惑。这主要是因为他对于这一机制的描述缺少太多的技术细节。从上面的讨论可以看出,antirez对于这一机制的看法是,它跟一个random token没有什么区别,而且,它需要资源服务器本身提供某种互斥机制,这几乎让分布式锁本身的存在失去了意义。围绕fencing token的问题,还有两点是比较引人注目的,Hacker News上也有人提出了相关的疑问:
- (1)关于资源服务器本身的架构细节。
- (2)资源服务器对于fencing token进行检查的实现细节,比如是否需要提供一种原子操作。
关于上述问题(1),Hacker News上有一位叫dwenzek的用户发表了下面的评论:
...... the issue around the usage of fencing tokens to reject any late usage of a lock is unclear just because the protected resource and its access are themselves unspecified. Is the resource distributed or not? If distributed, does the resource has a mean to ensure that tokens are increasing over all the nodes? Does the resource have a mean to rollback any effects done by a client which session is interrupted by a timeout?
(译文:...... 关于使用fencing token拒绝掉延迟请求的相关议题,是不够清晰的,因为受保护的资源以及对它的访问方式本身是没有被明确定义过的。资源服务是不是分布式的呢?如果是,资源服务有没有一种方式能确保token在所有节点上递增呢?对于客户端的Session由于过期而被中断的情况,资源服务有办法将它的影响回滚吗?)
这些疑问在Hacker News上并没有人给出解答。而关于分布式的资源服务器架构如何处理fencing token,另外一名分布式系统的专家Flavio Junqueira在他的一篇blog中有所提及(我们后面会再提到)。
关于上述问题(2),Hacker News上有一位叫reza_n的用户发表了下面的疑问:
I understand how a fencing token can prevent out of order writes when 2 clients get the same lock. But what happens when those writes happen to arrive in order and you are doing a value modification? Don't you still need to rely on some kind of value versioning or optimistic locking? Wouldn't this make the use of a distributed lock unnecessary?
(译文: 我理解当两个客户端同时获得锁的时候fencing token是如何防止乱序的。但是如果两个写操作恰好按序到达了,而且它们在对同一个值进行修改,那会发生什么呢?难道不会仍然是依赖某种数据版本号或者乐观锁的机制?这不会让分布式锁变得没有必要了吗?)
一位叫Terr_的Hacker News用户答:
I believe the "first" write fails, because the token being passed in is no longer "the lastest", which indicates their lock was already released or expired.
(译文: 我认为“第一个”写请求会失败,因为它传入的token不再是“最新的”了,这意味着锁已经释放或者过期了。)
Terr_的回答到底对不对呢?这不好说,取决于资源服务器对于fencing token进行检查的实现细节。让我们来简单分析一下。
为了简单起见,我们假设有一台(先不考虑分布式的情况)通过RPC进行远程访问文件服务器,它无法提供对于文件的互斥访问(否则我们就不需要分布式锁了)。现在我们按照Martin给出的说法,加入fencing token的检查逻辑。由于Martin没有描述具体细节,我们猜测至少有两种可能。
第一种可能,我们修改了文件服务器的代码,让它能多接受一个fencing token的参数,并在进行所有处理之前加入了一个简单的判断逻辑,保证只有当前接收到的fencing token大于之前的值才允许进行后边的访问。而一旦通过了这个判断,后面的处理不变。
现在想象reza_n描述的场景,客户端1和客户端2都发生了GC pause,两个fencing token都延迟了,它们几乎同时到达了文件服务器,而且保持了顺序。那么,我们新加入的判断逻辑,应该对两个请求都会放过,而放过之后它们几乎同时在操作文件,还是冲突了。既然Martin宣称fencing token能保证分布式锁的正确性,那么上面这种可能的猜测也许是我们理解错了。
当然,还有第二种可能,就是我们对文件服务器确实做了比较大的改动,让这里判断token的逻辑和随后对文件的处理放在一个原子操作里了。这可能更接近antirez的理解。这样的话,前面reza_n描述的场景中,两个写操作都应该成功。
基于ZooKeeper的分布式锁更安全吗?
很多人(也包括Martin在内)都认为,如果你想构建一个更安全的分布式锁,那么应该使用ZooKeeper,而不是Redis。那么,为了对比的目的,让我们先暂时脱离开本文的题目,讨论一下基于ZooKeeper的分布式锁能提供绝对的安全吗?它需要fencing token机制的保护吗?
我们不得不提一下分布式专家Flavio Junqueira所写的一篇blog,题目叫“Note on fencing and distributed locks”,地址如下:
Flavio Junqueira是ZooKeeper的作者之一,他的这篇blog就写在Martin和antirez发生争论的那几天。他在文中给出了一个基于ZooKeeper构建分布式锁的描述(当然这不是唯一的方式):
- 客户端尝试创建一个znode节点,比如
/lock。那么第一个客户端就创建成功了,相当于拿到了锁;而其它的客户端会创建失败(znode已存在),获取锁失败。 - 持有锁的客户端访问共享资源完成后,将znode删掉,这样其它客户端接下来就能来获取锁了。
- znode应该被创建成ephemeral的。这是znode的一个特性,它保证如果创建znode的那个客户端崩溃了,那么相应的znode会被自动删除。这保证了锁一定会被释放。
看起来这个锁相当完美,没有Redlock过期时间的问题,而且能在需要的时候让锁自动释放。但仔细考察的话,并不尽然。
ZooKeeper是怎么检测出某个客户端已经崩溃了呢?实际上,每个客户端都与ZooKeeper的某台服务器维护着一个Session,这个Session依赖定期的心跳(heartbeat)来维持。如果ZooKeeper长时间收不到客户端的心跳(这个时间称为Sesion的过期时间),那么它就认为Session过期了,通过这个Session所创建的所有的ephemeral类型的znode节点都会被自动删除。
设想如下的执行序列:
- 客户端1创建了znode节点
/lock,获得了锁。 - 客户端1进入了长时间的GC pause。
- 客户端1连接到ZooKeeper的Session过期了。znode节点
/lock被自动删除。 - 客户端2创建了znode节点
/lock,从而获得了锁。 - 客户端1从GC pause中恢复过来,它仍然认为自己持有锁。
最后,客户端1和客户端2都认为自己持有了锁,冲突了。这与之前Martin在文章中描述的由于GC pause导致的分布式锁失效的情况类似。
看起来,用ZooKeeper实现的分布式锁也不一定就是安全的。该有的问题它还是有。但是,ZooKeeper作为一个专门为分布式应用提供方案的框架,它提供了一些非常好的特性,是Redis之类的方案所没有的。像前面提到的ephemeral类型的znode自动删除的功能就是一个例子。
还有一个很有用的特性是ZooKeeper的watch机制。这个机制可以这样来使用,比如当客户端试图创建/lock的时候,发现它已经存在了,这时候创建失败,但客户端不一定就此对外宣告获取锁失败。客户端可以进入一种等待状态,等待当/lock节点被删除的时候,ZooKeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。这样的特性Redlock就无法实现。
小结一下,基于ZooKeeper的锁和基于Redis的锁相比在实现特性上有两个不同:
- 在正常情况下,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。这避免了基于Redis的锁对于有效时间(lock validity time)到底设置多长的两难问题。实际上,基于ZooKeeper的锁是依靠Session(心跳)来维持锁的持有状态的,而Redis不支持Sesion。
- 基于ZooKeeper的锁支持在获取锁失败之后等待锁重新释放的事件。这让客户端对锁的使用更加灵活。
顺便提一下,如上所述的基于ZooKeeper的分布式锁的实现,并不是最优的。它会引发“herd effect”(羊群效应),降低获取锁的性能。一个更好的实现参见下面链接:
我们重新回到Flavio Junqueira对于fencing token的分析。Flavio Junqueira指出,fencing token机制本质上是要求客户端在每次访问一个共享资源的时候,在执行任何操作之前,先对资源进行某种形式的“标记”(mark)操作,这个“标记”能保证持有旧的锁的客户端请求(如果延迟到达了)无法操作资源。这种标记操作可以是很多形式,fencing token是其中比较典型的一个。
随后Flavio Junqueira提到用递增的epoch number(相当于Martin的fencing token)来保护共享资源。而对于分布式的资源,为了方便讨论,假设分布式资源是一个小型的多备份的数据存储(a small replicated data store),执行写操作的时候需要向所有节点上写数据。最简单的做标记的方式,就是在对资源进行任何操作之前,先把epoch number标记到各个资源节点上去。这样,各个节点就保证了旧的(也就是小的)epoch number无法操作数据。
当然,这里再展开讨论下去可能就涉及到了这个数据存储服务的实现细节了。比如在实际系统中,可能为了容错,只要上面讲的标记和写入操作在多数节点上完成就算成功完成了(Flavio Junqueira并没有展开去讲)。在这里我们能看到的,最重要的,是这种标记操作如何起作用的方式。这有点类似于Paxos协议(Paxos协议要求每个proposal对应一个递增的数字,执行accept请求之前先执行prepare请求)。antirez提出的random token的方式显然不符合Flavio Junqueira对于“标记”操作的定义,因为它无法区分新的token和旧的token。只有递增的数字才能确保最终收敛到最新的操作结果上。
在这个分布式数据存储服务(共享资源)的例子中,客户端在标记完成之后执行写入操作的时候,存储服务的节点需要判断epoch number是不是最新,然后确定能不能执行写入操作。如果按照上一节我们的分析思路,这里的epoch判断和接下来的写入操作,是不是在一个原子操作里呢?根据Flavio Junqueira的相关描述,我们相信,应该是原子的。那么既然资源本身可以提供原子互斥操作了,那么分布式锁还有存在的意义吗?应该说有。客户端可以利用分布式锁有效地避免冲突,等待写入机会,这对于包含多个节点的分布式资源尤其有用(当然,是出于效率的原因)。
Chubby的分布式锁是怎样做fencing的?
提到分布式锁,就不能不提Google的Chubby。
Chubby是Google内部使用的分布式锁服务,有点类似于ZooKeeper,但也存在很多差异。Chubby对外公开的资料,主要是一篇论文,叫做“The Chubby lock service for loosely-coupled distributed systems”,下载地址如下:
另外,YouTube上有一个的讲Chubby的talk,也很不错,播放地址:
Chubby自然也考虑到了延迟造成的锁失效的问题。论文里有一段描述如下:
a process holding a lock L may issue a request R, but then fail. Another process may ac- quire L and perform some action before R arrives at its destination. If R later arrives, it may be acted on without the protection of L, and potentially on inconsistent data.
(译文: 一个进程持有锁L,发起了请求R,但是请求失败了。另一个进程获得了锁L并在请求R到达目的方之前执行了一些动作。如果后来请求R到达了,它就有可能在没有锁L保护的情况下进行操作,带来数据不一致的潜在风险。)
这跟Martin的分析大同小异。
Chubby给出的用于解决(缓解)这一问题的机制称为sequencer,类似于fencing token机制。锁的持有者可以随时请求一个sequencer,这是一个字节串,它由三部分组成:
- 锁的名字。
- 锁的获取模式(排他锁还是共享锁)。
- lock generation number(一个64bit的单调递增数字)。作用相当于fencing token或epoch number。
客户端拿到sequencer之后,在操作资源的时候把它传给资源服务器。然后,资源服务器负责对sequencer的有效性进行检查。检查可以有两种方式:
- 调用Chubby提供的API,CheckSequencer(),将整个sequencer传进去进行检查。这个检查是为了保证客户端持有的锁在进行资源访问的时候仍然有效。
- 将客户端传来的sequencer与资源服务器当前观察到的最新的sequencer进行对比检查。可以理解为与Martin描述的对于fencing token的检查类似。
当然,如果由于兼容的原因,资源服务本身不容易修改,那么Chubby还提供了一种机制:
- lock-delay。Chubby允许客户端为持有的锁指定一个lock-delay的时间值(默认是1分钟)。当Chubby发现客户端被动失去联系的时候,并不会立即释放锁,而是会在lock-delay指定的时间内阻止其它客户端获得这个锁。这是为了在把锁分配给新的客户端之前,让之前持有锁的客户端有充分的时间把请求队列排空(draining the queue),尽量防止出现延迟到达的未处理请求。
可见,为了应对锁失效问题,Chubby提供的三种处理方式:CheckSequencer()检查、与上次最新的sequencer对比、lock-delay,它们对于安全性的保证是从强到弱的。而且,这些处理方式本身都没有保证提供绝对的正确性(correctness)。但是,Chubby确实提供了单调递增的lock generation number,这就允许资源服务器在需要的时候,利用它提供更强的安全性保障。
关于时钟
在Martin与antirez的这场争论中,冲突最为严重的就是对于系统时钟的假设是不是合理的问题。Martin认为系统时钟难免会发生跳跃(这与分布式算法的异步模型相符),而antirez认为在实际中系统时钟可以保证不发生大的跳跃。
Martin对于这一分歧发表了如下看法(原话):
So, fundamentally, this discussion boils down to whether it is reasonable to make timing assumptions for ensuring safety properties. I say no, Salvatore says yes — but that's ok. Engineering discussions rarely have one right answer.
(译文:
从根本上来说,这场讨论最后归结到了一个问题上:为了确保安全性而做出的记时假设到底是否合理。我认为不合理,而antirez认为合理 —— 但是这也没关系。工程问题的讨论很少只有一个正确答案。)
那么,在实际系统中,时钟到底是否可信呢?对此,Julia Evans专门写了一篇文章,“TIL: clock skew exists”,总结了很多跟时钟偏移有关的实际资料,并进行了分析。这篇文章地址:
Julia Evans在文章最后得出的结论是:
clock skew is real
(时钟偏移在现实中是存在的)
Martin的事后总结
我们前面提到过,当各方的争论在激烈进行的时候,Martin几乎始终置身事外。但是Martin在这件事过去之后,把这个事件的前后经过总结成了一个很长的故事线。如果你想最全面地了解这个事件发生的前后经过,那么建议去读读Martin的这个总结:
在这个故事总结的最后,Martin写下了很多感性的评论:
For me, this is the most important point: I don't care who is right or wrong in this debate — I care about learning from others' work, so that we can avoid repeating old mistakes, and make things better in future. So much great work has already been done for us: by standing on the shoulders of giants, we can build better software.
......
By all means, test ideas by arguing them and checking whether they stand up to scrutiny by others. That's part of the learning process. But the goal should be to learn, not to convince others that you are right. Sometimes that just means to stop and think for a while.(译文:
对我来说最重要的一点在于:我并不在乎在这场辩论中谁对谁错 —— 我只关心从其他人的工作中学到的东西,以便我们能够避免重蹈覆辙,并让未来更加美好。前人已经为我们创造出了许多伟大的成果:站在巨人的肩膀上,我们得以构建更棒的软件。
......
对于任何想法,务必要详加检验,通过论证以及检查它们是否经得住别人的详细审查。那是学习过程的一部分。但目标应该是为了获得知识,而不应该是为了说服别人相信你自己是对的。有时候,那只不过意味着停下来,好好地想一想。)
关于分布式锁的这场争论,我们已经完整地做了回顾和分析。
按照锁的两种用途,如果仅是为了效率(efficiency),那么你可以自己选择你喜欢的一种分布式锁的实现。当然,你需要清楚地知道它在安全性上有哪些不足,以及它会带来什么后果。而如果你是为了正确性(correctness),那么请慎之又慎。在本文的讨论中,我们在分布式锁的正确性上走得最远的地方,要数对于ZooKeeper分布式锁、单调递增的epoch number以及对分布式资源进行标记的分析了。请仔细审查相关的论证。
Martin为我们留下了不少疑问,尤其是他提出的fencing token机制。他在blog中提到,会在他的新书《Designing Data-Intensive Applications》的第8章和第9章再详加论述。目前,这本书尚在预售当中。我感觉,这会是一本值得一读的书,它不同于为了出名或赚钱而出版的那种短平快的书籍。可以看出作者在这本书上投入了巨大的精力。
最后,我相信,这个讨论还远没有结束。分布式锁(Distributed Locks)和相应的fencing方案,可以作为一个长期的课题,随着我们对分布式系统的认识逐渐增加,可以再来慢慢地思考它。思考它更深层的本质,以及它在理论上的证明。
(完)
感谢:
由衷地感谢几位朋友花了宝贵的时间对本文草稿所做的review:CacheCloud的作者付磊,快手的李伟博,阿里的李波。当然,文中如果还有错漏,由我本人负责^-^。
链接:https://juejin.cn/post/6844903465181773831
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)