

【转载】ARM嵌入式系统为什么要做内存对齐
做嵌入式系统软件开发,经常在代码中看到各种各样的对齐,很多时候我们都是知其然不知其所以然,知道要做好各种对齐,但是不明白为什么要对齐,不对齐会有哪些后果,这篇文章大概总结了内存对齐的理由。
CPU体系结构和MMU的要求
- 目前有一些RISC指令集的CPU不支持非对齐的内存变量访问操作,比如 MIPS/PowerPC/某些DSP等等,如果发生非对齐的内存访问,会产生unaligned exception 异常。
- ARM指令集是从ARMv6(ARM11)开始支持非对齐内存访问的,以前老一点的ARM9的CPU也是不支持非对齐访问的。ARM指令集支持的部分特性迭代如下:

- 尽管现代的ARMv7 ARMv8 指令集的Cortex-AXX系列CPU都支持非对齐内存访问,但是考虑到如下图所示现代SOC芯片里面多种异构CPU协调工作的情况,主CPU用于跑Linux/Android操作系统的ARM64可以支持非对齐内存访问,但是SOC里面还有其它不知道体系结构和版本的协CPU(可能是MIPS, ARM7,Cortex-R/M系列, 甚至51单片机核),这些协CPU都和主ARM64主CPU共享物理内存的不同地址段,并且有自己的固件程序在内存上运行,所以在划分地址空间的时候还是要注意内存对齐的问题,尤其是考虑到这些协CPU可能不支持非对齐访问,同样在编写协CPU固件程序的时候,也要清晰认识到该CPU是否支持非对齐内存访问。
- 同样在ARM的MMU虚拟地址管理中,也有内存地址对齐的要求,下图是ARM的MMU的工作原理和多级页表(Translation Tables)的索引关系图

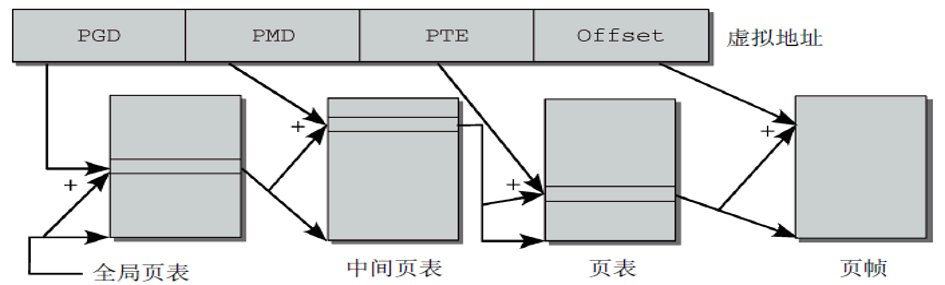
- ARM体系架构的MMU要求
- arm 32位体系结构要求L1第一级页表基地址(The L1 Translation Table Base Addr)对齐到16KB的地址边界,L2第二级页表地址(The L2 Translation Table Add)对齐到1KB的地址边界。
- ARM 64位体系结构要求虚拟地址的第21-28位VA[28:21]对齐到64 KB granule, 第16到20位VA[20:16]对齐到4 KB granule。
- ARM 的Memory ordering特性中的不同Memory types对非对齐内存访问的支持的要求是不同的。
下图是ARM Memory ordering特性中三种不同的Memory types访问规则
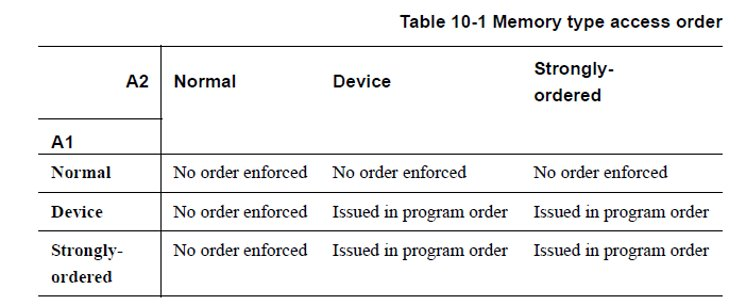
- 只有Normal Memory是支持非对齐内存访问的
- Strongly-ordered 和 Device Memory不支持非对齐内存访问
对原子操作的影响
尽管现代的ARMv7 ARMv8 指令集的ARM CPU支持非对齐内存访问,但是非对齐内存访问是无法保证操作的原子性。
下图分别是一个变量在内存对齐和非对齐的时候的内存布局:
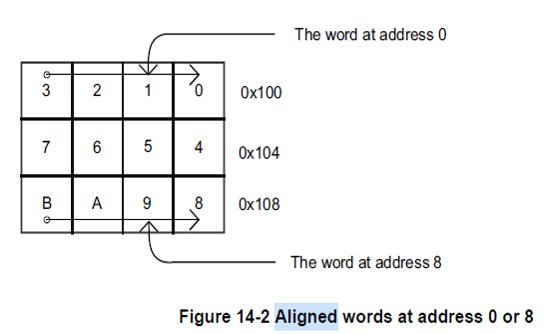
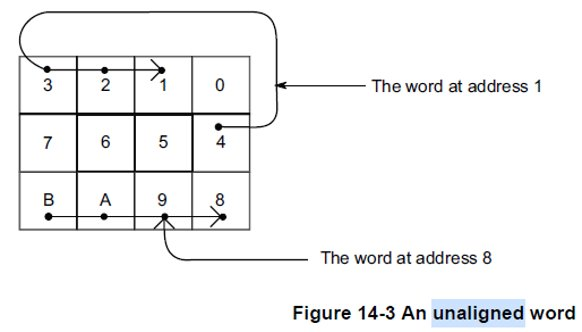
- 内存对齐的变量访问,使用单个通用的CPU寄存器暂存,一个内存对齐的变量的读写操作能保证是单次原子操作.
- 非对齐的变量的内存访问是非原子操作,他们通常情况下访问一个非对齐的内存中的变量需要2次分别的对内存进行访问,因而不能保证原子性,一旦发生2次分别内存访问,2次分别的访问中间就有可能被异步事件打断,造成变量改变,因而不能保证原子性。
ARM NEON的要求
现代ARM CPU一般都有一个NEON的协处理器,一般用在浮点计算中用来做SIMD并行矢量加速计算。下图是NEON SIMD并行矢量计算的基本原理图:
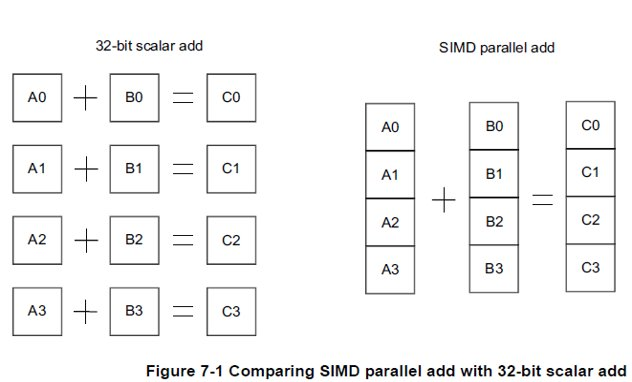
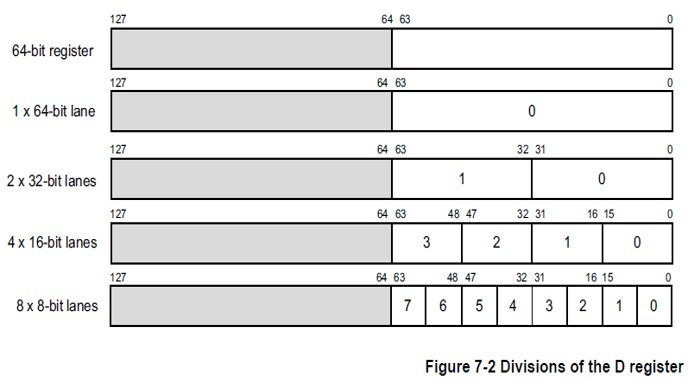
- NEON本身是支持非对齐内存访问的
- 但是NEON访问非对齐的内存一般会有2个指令周期的时间penalty
- 通常情况下,为了灵活应用NEON的并行计算特性,在做SIMD并行矢量加速运算时,我们要根据NEON寄存器的Lane的bits数对齐相应的变量。如果是配置成8-bits的计算,就做8-bits对齐,如果是16-bits计算,就做16-bits对齐,以此类推,NEON的并行矢量计算的lane根据spec手册,有各种灵活配置的方法。
对性能perf的影响
- 通常而言,尽管现代的ARM CPU已经支持非对齐内存的访问,但是ARM访问非对齐的内存地址还是会造成明显的性能下降。因为访问一个非对齐的内存,需要增加多次load/store内存变量次数,进而增加了程序运行的指令周期
- 才有perf工具进行性能分析,能看到非对齐内存访问的性能下降,在perf工具中有一个alignment-faults的事件,可以观察程序访问非对齐内存的事件统计
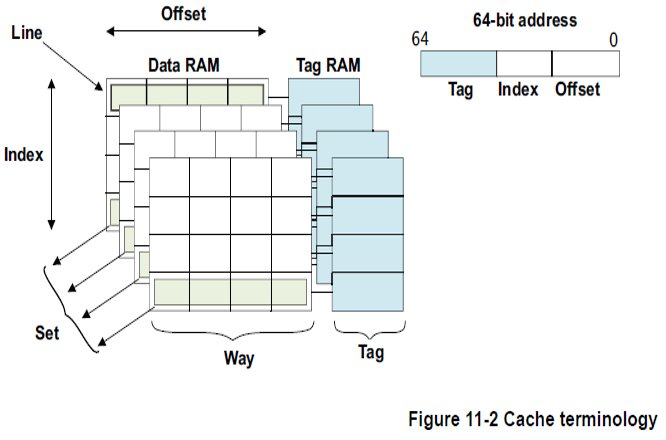
cache line 对齐
除了通常所讲的根据CPU访问内存的地址位数的内存对齐之外,在程序优化的时候,还要考虑到cache存在的情况,根据cache line的长度来对齐你的访问变量。
- cache和cache line的结构原理图如下(其中图2从该文章引用自: cenalulu),cache line是cache和内存进行数据传输的最小单位,一般cache都是以cache line的长度一次读写内存中的映射地址。
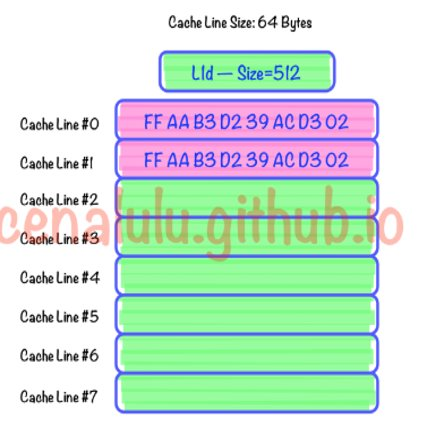
- 在ARM 系列的CPU中,不同型号的ARM CPU的cache line长度是不一样的,因此同样是基于ARM平台的CPU,从A平台移植优化过的程序到B平台时,一定要注意不同CPU的cache line大小是否一致,是否要重新调整cache line对齐优化。下图是ARMv7几款公版CPU的cache line的资料手册,ARMv8 64位的公版CPU(A53, A57, A72, A73)目前的cache line大小都是64 bytes, 但是各家公司基于公版ARM的定制版CPU的cache line大小可能有差异,一定要参考相关TRM手册进行调整、对齐、优化.
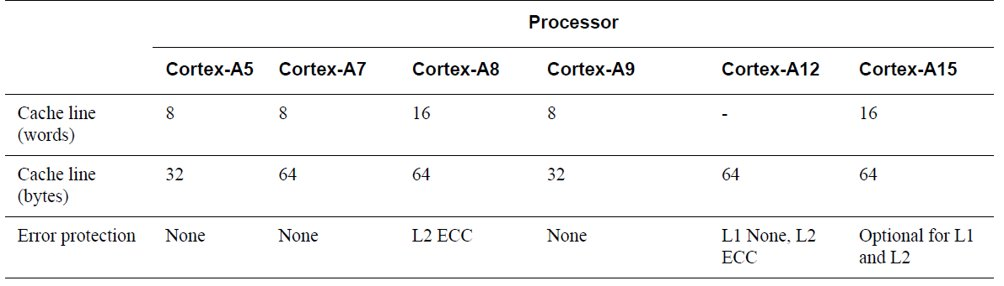
- 下图是一个例子关于未做cache line对齐的情况下,进行内存读写性能抖动的例子,引用自cenalulu.测试代码如下
程序的大意,对不同大小的数组进行1亿次读写操作,统计不同数组size时的读写时间。从测试的结果可以看出,当数组大小小于cache line size时,读写时间基本变化不大,当数组大小刚刚超过cache line size的时候,读写时间发生了剧烈的抖动。
这是因为超过cache line 大小的数组元素可能没有提前预读到cache line中,在访问完cache line中的数组元素之后,要重新从内存读取数据,刷新cache line,因而产生了性能抖动。
通过这个例子告诉我们,充分利用系统cache特性,根据cache line对齐你的数据,保证程序访问的局部数据都在一个cache line中可以提升系统性能。
#include "stdio.h" #include <stdlib.h> #include <sys/time.h> long timediff(clock_t t1, clock_t t2) { long elapsed; elapsed = ((double)t2 - t1) / CLOCKS_PER_SEC * 1000; return elapsed; } int main(int argc, char *argv[]) #******* { int array_size=atoi(argv[1]); int repeat_times = 1000000000; long array[array_size]; for(int i=0; i<array_size; i++){ array[i] = 0; } int j=0; int k=0; int c=0; clock_t start=clock(); while(j++<repeat_times){ if(k==array_size){ k=0; } c = array[k++]; } clock_t end =clock(); printf("%lu\n", timediff(start,end)); return 0; } 1234567891011121314151617181920212223242526272829303132333435
- 没有对齐到同一个cache line中的变量,在多核SMP系统中,cross cache line操作是非原子操作,存在篡改的风险。该例子引用自
kongfy)
测试代码如下,
程序大意是,系统cpu的cache line是64字节,一个68字节的结构体struct data, 其中前面填充60字节的pad[15]数组,最后一个8字节的变量v, 这样结构体大小超过了64字节,最后一个变量v的前后部分可定不在同一个cache line中,整个结构体没法根据cache line对齐。
全局变量value.v初始值是0, 程序开多线程,对全局变量value.v进行多次~位取反操作,直觉上最后结果value.v的位结果不是全0就是全1,但是最后value.v的位结果居然是一半1一半0, 这就是由于cross cache line 操作是非原子性的,导致一个线程对value.v前半部分取反的时候,另外的线程对后半部分在另一个cache line同时取反,然后前一个线程再对另一个cache line的value.v后半部分取反,导致和直觉不一致。
#include <pthread.h> #include <stdlib.h> #include <stdio.h> #include <algorithm> using namespace std; static const int64_t MAX_THREAD_NUM = 128; static int64_t n = 0; static int64_t loop_count = 0; #pragma pack (1) struct data { int32_t pad[15]; int64_t v; }; #pragma pack () static data value __attribute__((aligned(64))); static int64_t counter[MAX_THREAD_NUM]; void worker(int *cnt) { for (int64_t i = 0; i < loop_count; ++i) { const int64_t t = value.v; if (t != 0L && t != ~0L) { *cnt += 1; } value.v = ~t; asm volatile("" ::: "memory"); } } int main(int argc, char *argv[]) { pthread_t threads[MAX_THREAD_NUM]; /* Check arguments to program*/ if(argc != 3) { fprintf(stderr, "USAGE: %s <threads> <loopcount>\n", argv[0]); exit(1); } /* Parse argument */ n = min(atol(argv[1]), MAX_THREAD_NUM); loop_count = atol(argv[2]); /* Don't bother with format checking */ /* Start the threads */ for (int64_t i = 0L; i < n; ++i) { pthread_create(&threads[i], NULL, (void* (*)(void*))worker, &counter[i]); } int64_t count = 0L; for (int64_t i = 0L; i < n; ++i) { pthread_join(threads[i], NULL); count += counter[i]; } printf("data size: %lu\n", sizeof(value)); printf("data addr: %lX\n", (unsigned long)&value.v); printf("final: %016lX\n", value.v); return 0; }
原文链接:https://blog.csdn.net/zhou_chenz/article/details/102610992


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构