

【驱动】块设备驱动(二)-通用块层
前言
通用块层是一个内核组件,处理来自系统其他组件发出的块设备请求。换句话说,通用块层包含了块设备操作的一些通用函数和数据结构,如通用磁盘结构gendisk,请求队列结构request_queue、请求结构request、块设备I/O操作结构bio和块设备操作结构block_device_operations等。
关键数据结构
buffer_head
内存中一个page所包含的磁盘块在物理上不一定是相邻的。那么page中不同的磁盘块怎么管理呢?这里就涉及到了buffer_head结构。每个buffer_head管理的单元是内存页page中对应的一个物理块(对于block大小为1k的情况下,一个page对应磁盘上的4个block,而每个buffer_head对应1个磁盘block),也就是说buffer_head管理单元是 “页”的一个子集。
struct buffer_head { unsigned long b_state; /* buffer state bitmap (see above) */ struct buffer_head *b_this_page;/* circular list of page's buffers */ struct page *b_page; /* the page this bh is mapped to */ sector_t b_blocknr; /* start block number */ size_t b_size; /* size of mapping */ char *b_data; /* pointer to data within the page */ struct block_device *b_bdev; bh_end_io_t *b_end_io; /* I/O completion */ void *b_private; /* reserved for b_end_io */ struct list_head b_assoc_buffers; /* associated with another mapping */ struct address_space *b_assoc_map; /* mapping this buffer is associated with */ atomic_t b_count; /* users using this buffer_head */ };
unsigned long b_state:位图,用于表示缓冲区的状态信息。例如是否是脏数据、是否已经写回磁盘等。
struct buffer_head *b_this_page:用于构建一个循环链表,将同一页(page)上的多个缓冲区头连接在一起。通过该指针,可以遍历同一页上的所有缓冲区。
struct page *b_page:指向映射到的页(page)的指针。缓冲区头与页相关联,表示该缓冲区头所属的页。
sector_t b_blocknr:起始块号(block number),表示缓冲区映射的起始位置。
size_t b_size:表示映射大小(mapping size)的变量,用于表示缓冲区映射的大小。
char *b_data:指向页中数据的指针。它指向页中存储的缓冲区数据的起始位置。
struct block_device *b_bdev:指向块设备(block device)的指针,表示缓冲区头所属的块设备。
bh_end_io_t *b_end_io:一个指向I/O完成回调函数的指针。当与缓冲区头相关联的I/O操作完成时,内核将调用此回调函数。
void *b_private:保留字段,用于存储与缓冲区头相关的私有数据。通常在与回调函数(b_end_io)一起使用,用于传递额外的参数或上下文信息。
struct list_head b_assoc_buffers:链表头,当前缓冲区头与其他映射相关联的缓冲区头连接在一起。通过该链表,可以遍历与当前缓冲区头相关联的其他缓冲区头。
struct address_space *b_assoc_map:指向地址空间的指针,表示当前缓冲区头所属的地址空间。地址空间用于管理文件系统中的缓冲区。
atomic_t b_count:一个原子变量,表示当前正在使用该缓冲区头的用户数。在多线程环境下,通过原子操作可以对该计数进行增减操作,用于跟踪缓冲区头的使用情况。
ll_rw_block
通用块层提供了 ll_rw_block() 函数对逻辑块进行读写操作,根据给定的读写操作类型和缓冲区的状态,它会对指定的缓冲区执行相应的I/O操作,并处理相关的完成动作。
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[]) { int i; for (i = 0; i < nr; i++) { struct buffer_head *bh = bhs[i]; if (!trylock_buffer(bh)) continue; if (rw == WRITE) { if (test_clear_buffer_dirty(bh)) { bh->b_end_io = end_buffer_write_sync; get_bh(bh); submit_bh(WRITE, bh); continue; } } else { if (!buffer_uptodate(bh)) { bh->b_end_io = end_buffer_read_sync; get_bh(bh); submit_bh(rw, bh); continue; } } unlock_buffer(bh); } }
ll_rw_block接受三个参数: rw表示读写操作类型(READ、WRITE或READA),nr表示传入的struct buffer_head指针数组的长度,bhs是一个指向struct buffer_head指针数组的指针。
函数的作用是对传入的struct buffer_head数组进行I/O操作,可以是读取(READ)或写入(WRITE)。第三个操作类型READA在ll_rw_block函数中调用了generic_make_request()函数。
在执行操作之前,该函数会丢弃那些无法获取锁定(BH_Lock状态位)的缓冲区,对于写请求,丢弃那些看起来已经是干净的缓冲区;对于读请求,丢弃那些看起来已经是最新的缓冲区。此外,对于被处理为写请求的缓冲区,该函数会标记为已经干净(缓冲区在解锁之前不会被缓冲区缓存认为是干净的)。
ll_rw_block函数将b_end_io设置为简单的完成处理程序,该处理程序会将缓冲区标记为最新(如果适用),解锁缓冲区并唤醒任何等待的进程。
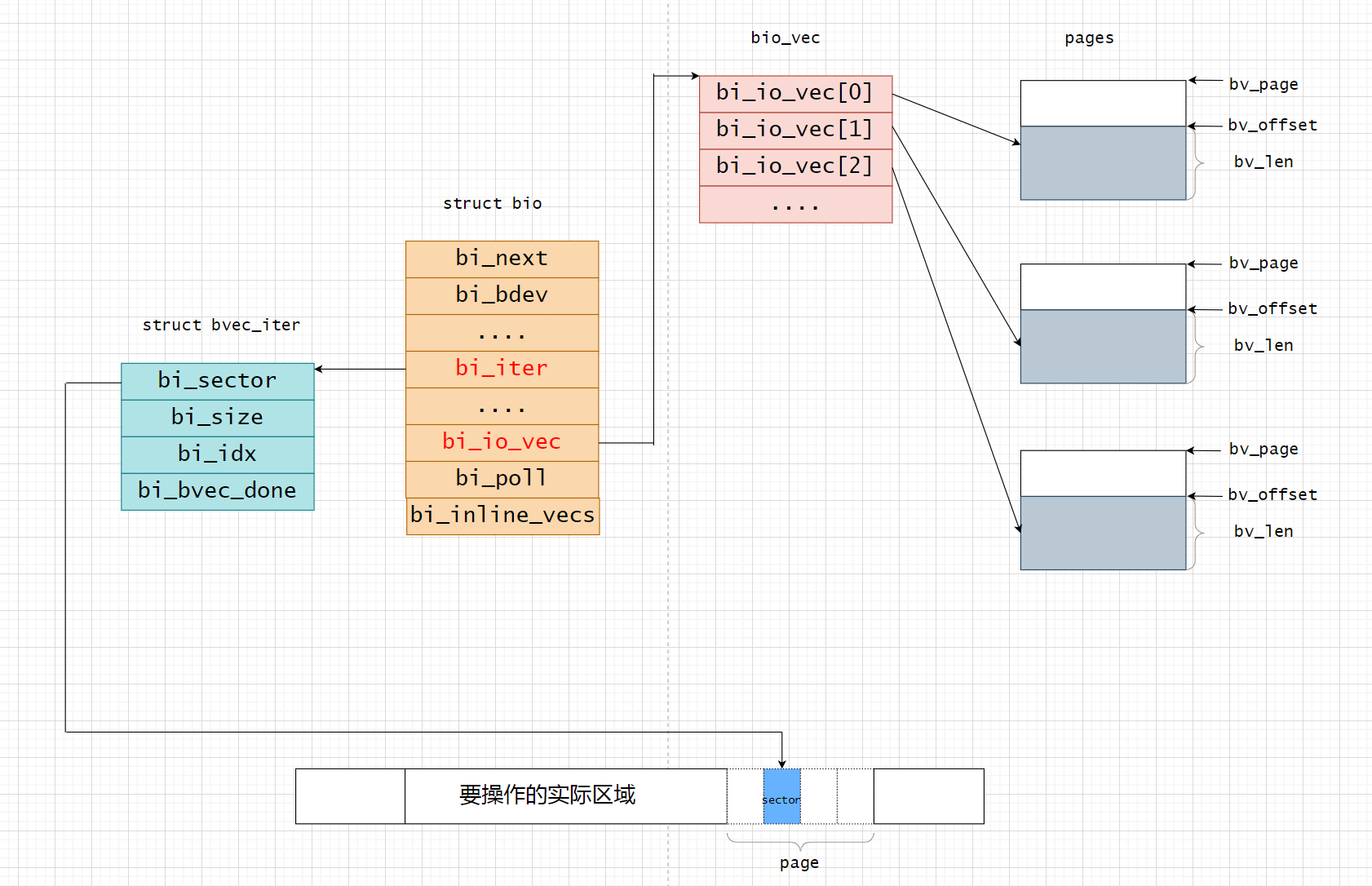
struct bio
通用块层的核心数据结构是struct bio,它描述了块设备的IO操作。
struct bio { struct bio *bi_next; /* request queue link */ struct block_device *bi_bdev; unsigned int bi_flags; /* status, command, etc */ unsigned short bi_write_hint; int bi_error; unsigned long bi_rw; /* bottom bits READ/WRITE, * top bits priority */ struct bvec_iter bi_iter; /* Number of segments in this BIO after * physical address coalescing is performed. */ unsigned int bi_phys_segments; /* * To keep track of the max segment size, we account for the * sizes of the first and last mergeable segments in this bio. */ unsigned int bi_seg_front_size; unsigned int bi_seg_back_size; atomic_t __bi_remaining; bio_end_io_t *bi_end_io; void *bi_private; #ifdef CONFIG_BLK_CGROUP /* * Optional ioc and css associated with this bio. Put on bio * release. Read comment on top of bio_associate_current(). */ struct io_context *bi_ioc; struct cgroup_subsys_state *bi_css; #endif union { #if defined(CONFIG_BLK_DEV_INTEGRITY) struct bio_integrity_payload *bi_integrity; /* data integrity */ #endif }; unsigned short bi_vcnt; /* how many bio_vec's */ /* * Everything starting with bi_max_vecs will be preserved by bio_reset() */ unsigned short bi_max_vecs; /* max bvl_vecs we can hold */ atomic_t __bi_cnt; /* pin count */ struct bio_vec *bi_io_vec; /* the actual vec list */ struct bio_set *bi_pool; /* * We can inline a number of vecs at the end of the bio, to avoid * double allocations for a small number of bio_vecs. This member * MUST obviously be kept at the very end of the bio. */ struct bio_vec bi_inline_vecs[0]; };
bi_next: 指向下一个bio结构体的指针,用于构建请求队列。bi_bdev: 指向块设备的指针,表示该bio请求所涉及的块设备。bi_flags: 用于存储bio的状态、命令等标志位。bi_write_hint: 提示bio是写操作的提示标志位。bi_error: 存储bio操作过程中的错误代码。bi_rw: 存储bio的读写操作类型,低位表示 READ/WRITE,高位表示优先级。bi_iter: 用于迭代bio的bio_vec结构体的迭代器。bi_phys_segments: 在物理地址合并后,bio中的段(segment)数量。bi_seg_front_size和bi_seg_back_size: 用于跟踪合并后的第一个和最后一个可合并段的大小。__bi_remaining: 原子计数器,表示剩余未处理的bio数量。bi_end_io: 指向bio结束时调用的回调函数的指针。bi_private: 指向bio的私有数据的指针。bi_ioc和bi_css: 可选的io_context和cgroup_subsys_state,用于关联bio。bi_integrity: 如果启用了数据完整性检查,指向bio_integrity_payload结构体的指针。bi_vcnt:bio_vec的数量,表示bio中的向量个数。bi_max_vecs:bio可以容纳的最大bio_vec的数量。__bi_cnt: 原子计数器,表示对bio的引用计数。bi_io_vec: 实际的bio_vec列表。bi_pool: 指向bio_set结构体的指针,表示与该bio相关的资源池。bi_inline_vecs: 在bio的末尾可以内联一些向量,以避免为少量bio_vec进行双重分配。
bio_vec
struct bio_vec { struct page *bv_page; unsigned int bv_len; unsigned int bv_offset; };
bv_page:指向段的页框中页描述符的指针bv_len; 段的长度,以字节为单位bv_offset:页框中段数据的偏移量
顾名思义,bio_vec 就是一个 bio 的数据容器,专门用来保存 bio 的数据,当然他是这个 bio 大集体的一个最小项,刚刚说了 bio 是通用块层的最小集,而这个 bio_vec 则是组成 bio 数据的最小单位,他包含了一块数据所在的页,这块数据所在的页内偏移以及长度,通过这些信息就可以很清晰的描述数据具体位于什么位置,通过对这些数据的整合,可以将他们添加到 SGL(散列表) 中直接发送给后端硬件设备。
bvec_iter
寻遍整个 bio 发现居然没有携带需要下盘的扇区编号以及当前 bio 的大小,这个很尴尬,但确实如此,相当于 bio 作为一辆汽车,他携带了货物但是没告诉他目的地这不是完蛋了吗?不是,真正的目的地保存在这个 bvec_iter 中,作为一个迭代器,自然他的使命就是用来遍历 bvec,也就是 bio 数据区。那么他好比就是这辆 bio 汽车的货物分拣员,自然我的目的地不必贴到车上,直接告诉分拣员也是可以的,因为后面的事情可不是这辆汽车再做,而是分拣员需要逐个卸货的时候用。一起来看看迭代器长什么样?
struct bvec_iter { sector_t bi_sector; /* device address in 512 byte sectors */ unsigned int bi_size; /* residual I/O count */ unsigned int bi_idx; /* current index into bvl_vec */ unsigned int bi_bvec_done; /* number of bytes completed in current bvec */ };
有几个重点:
-
一个BIO所请求的数据在块设备中是连续的,对于不连续的数据块需要放到多个BIO中。
-
一个BIO所携带的数据大小是有上限的,该上限值由
bi_max_vecs间接指定,超过上限的数据块必须放到多个BIO中。 -
使用
bio_for_each_segment来遍历 bio_vec
BIO、bi_io_vec、page之间的关系
bio_alloc
bio_alloc函数用于分配bio结构,并返回指向分配的bio结构的指针。bio_alloc 最终会调用到bio_alloc_bioset函数。我们直接分析bio_alloc_bioset。
struct bio *bio_alloc_bioset(gfp_t gfp_mask, int nr_iovecs, struct bio_set *bs) { gfp_t saved_gfp = gfp_mask; unsigned front_pad; unsigned inline_vecs; unsigned long idx = BIO_POOL_NONE; struct bio_vec *bvl = NULL; struct bio *bio; void *p; if (!bs) { if (nr_iovecs > UIO_MAXIOV) return NULL; p = kmalloc(sizeof(struct bio) + nr_iovecs * sizeof(struct bio_vec), gfp_mask); front_pad = 0; inline_vecs = nr_iovecs; } else { /* should not use nobvec bioset for nr_iovecs > 0 */ if (WARN_ON_ONCE(!bs->bvec_pool && nr_iovecs > 0)) return NULL; /* * generic_make_request() converts recursion to iteration; this * means if we're running beneath it, any bios we allocate and * submit will not be submitted (and thus freed) until after we * return. * * This exposes us to a potential deadlock if we allocate * multiple bios from the same bio_set() while running * underneath generic_make_request(). If we were to allocate * multiple bios (say a stacking block driver that was splitting * bios), we would deadlock if we exhausted the mempool's * reserve. * * We solve this, and guarantee forward progress, with a rescuer * workqueue per bio_set. If we go to allocate and there are * bios on current->bio_list, we first try the allocation * without __GFP_DIRECT_RECLAIM; if that fails, we punt those * bios we would be blocking to the rescuer workqueue before * we retry with the original gfp_flags. */ if (current->bio_list && (!bio_list_empty(¤t->bio_list[0]) || !bio_list_empty(¤t->bio_list[1]))) gfp_mask &= ~__GFP_DIRECT_RECLAIM; p = mempool_alloc(bs->bio_pool, gfp_mask); if (!p && gfp_mask != saved_gfp) { punt_bios_to_rescuer(bs); gfp_mask = saved_gfp; p = mempool_alloc(bs->bio_pool, gfp_mask); } front_pad = bs->front_pad; inline_vecs = BIO_INLINE_VECS; } if (unlikely(!p)) return NULL; bio = p + front_pad; bio_init(bio); if (nr_iovecs > inline_vecs) { bvl = bvec_alloc(gfp_mask, nr_iovecs, &idx, bs->bvec_pool); if (!bvl && gfp_mask != saved_gfp) { punt_bios_to_rescuer(bs); gfp_mask = saved_gfp; bvl = bvec_alloc(gfp_mask, nr_iovecs, &idx, bs->bvec_pool); } if (unlikely(!bvl)) goto err_free; bio_set_flag(bio, BIO_OWNS_VEC); } else if (nr_iovecs) { bvl = bio->bi_inline_vecs; } bio->bi_pool = bs; bio->bi_flags |= idx << BIO_POOL_OFFSET; bio->bi_max_vecs = nr_iovecs; bio->bi_io_vec = bvl; return bio; err_free: mempool_free(p, bs->bio_pool); return NULL; } static inline struct bio *bio_alloc(gfp_t gfp_mask, unsigned int nr_iovecs) { return bio_alloc_bioset(gfp_mask, nr_iovecs, fs_bio_set); }
首先,函数接受三个参数:gfp_mask表示内存分配的标志,nr_iovecs表示iovec的数量,bs是一个指向bio_set结构的指针,用于指定分配bio的bio_set。
根据bs是否为NULL进行不同的分配方式。如果bs为NULL,则通过kmalloc函数分配一块内存,大小为sizeof(struct bio) + nr_iovecs * sizeof(struct bio_vec)。然后,设置front_pad为0,inline_vecs为nr_iovecs的值。
如果bs不为NULL,则执行另一段代码。首先,检查bs->bvec_pool是否为NULL并且nr_iovecs是否大于0。如果满足条件,则返回NULL,表示分配失败。接下来,检查当前进程的bio_list是否存在未完成的bio请求,如果存在,则将gfp_mask中的__GFP_DIRECT_RECLAIM标志位清除,以避免在分配期间触发直接回收内存的行为。然后,使用mempool_alloc函数从bs->bio_pool中分配一块内存。如果分配失败,并且gfp_mask与保存的gfp_mask不相同,说明之前尝试分配时可能未释放内存,此时调用punt_bios_to_rescuer函数将之前的bio请求提交给救援工作队列,然后重新使用保存的gfp_mask再次尝试分配内存。
接下来,根据分配的内存地址计算bio的指针,并调用bio_init函数对bio进行初始化。
然后,根据nr_iovecs的值进行不同的处理。如果nr_iovecs大于inline_vecs,则调用bvec_alloc函数从bs->bvec_pool中分配一块内存作为bio_vec数组,并将分配的bio_vec数组赋值给bvl。如果分配失败,并且gfp_mask与保存的gfp_mask不相同,说明之前尝试分配时可能未释放内存,此时调用punt_bios_to_rescuer函数将之前的bio请求提交给救援工作队列,然后重新使用保存的gfp_mask再次尝试分配内存。如果分配成功,则将bio的BIO_OWNS_VEC标志位置位,表示bio拥有分配的bio_vec数组。如果nr_iovecs不为0,将分配的bio_vec数组赋值给bio的bi_io_vec字段。
如果nr_iovecs小于等于inline_vecs且不为0,则将bio的bi_inline_vecs指针赋值给bvl。
最后,设置bio的一些字段,如bi_pool、bi_flags和bi_max_vecs,然后返回指向分配的bio结构的指针。
submit_bio
submit_bio将bio请求到磁盘request请求的转换(请求的合并和IO优化),并将request请求挂入到磁盘请求的队列中,然后进行处理。
blk_qc_t submit_bio(int rw, struct bio *bio) { bio->bi_rw |= rw; /* * If it's a regular read/write or a barrier with data attached, * go through the normal accounting stuff before submission. */ if (bio_has_data(bio)) { unsigned int count; if (unlikely(rw & REQ_WRITE_SAME)) count = bdev_logical_block_size(bio->bi_bdev) >> 9; else count = bio_sectors(bio); if (rw & WRITE) { count_vm_events(PGPGOUT, count); } else { task_io_account_read(bio->bi_iter.bi_size); count_vm_events(PGPGIN, count); } if (unlikely(block_dump)) { char b[BDEVNAME_SIZE]; printk(KERN_DEBUG "%s(%d): %s block %Lu on %s (%u sectors)\n", current->comm, task_pid_nr(current), (rw & WRITE) ? "WRITE" : "READ", (unsigned long long)bio->bi_iter.bi_sector, bdevname(bio->bi_bdev, b), count); } } return generic_make_request(bio); }
-
bio->bi_rw |= rw;将传入的读/写标志rw合并到bio结构体的bi_rw字段中。这是为了将读写标志与bio中已有的标志进行合并。 -
if (bio_has_data(bio))条件判断检查bio结构体中是否有数据。如果有数据,则执行下面的代码块。 -
根据不同的条件,计算数据块的数量
count。-
如果
rw参数包含REQ_WRITE_SAME标志位,表示写入相同数据的请求,则将count设置为块设备逻辑块大小(通过bdev_logical_block_size函数获取)除以 512 的结果。 -
否则,将
count设置为bio结构体中的扇区数(通过bio_sectors函数获取)。
-
-
根据读写类型进行统计和日志记录:
-
如果
rw参数包含WRITE标志位,表示写操作,则调用count_vm_events函数统计页面输出(PGPGOUT)事件的发生次数,并使用数据块的数量count进行计数。 -
否则,调用
task_io_account_read函数将读取操作的字节数记录到当前任务的 I/O 统计中,并调用count_vm_events函数统计页面输入(PGPGIN)事件的发生次数,并使用数据块的数量count进行计数。
-
-
如果启用了块转储(
block_dump)功能,则通过printk函数在内核日志中打印有关当前进程、进程ID、读写类型、扇区号、块设备名称和数据块数量等信息。 -
最后,调用
generic_make_request函数将bio提交给块设备层处理,执行实际的 I/O 操作。
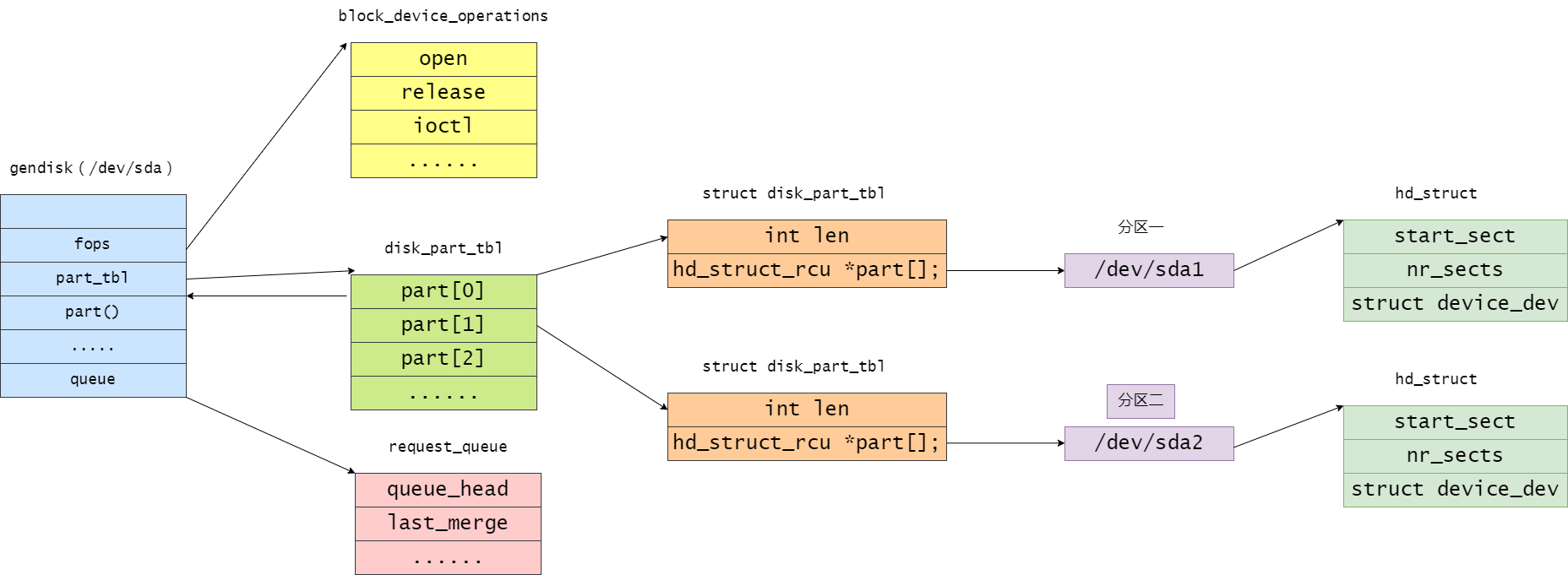
struct gendisk
linux 内核使用 gendisk 结构体来描述一个磁盘设备,定义在 include/linux/genhd.h 中
struct gendisk { /* major, first_minor and minors are input parameters only, * don't use directly. Use disk_devt() and disk_max_parts(). */ int major; /* major number of driver */ int first_minor; int minors; /* maximum number of minors, =1 for * disks that can't be partitioned. */ char disk_name[DISK_NAME_LEN]; /* name of major driver */ char *(*devnode)(struct gendisk *gd, umode_t *mode); unsigned int events; /* supported events */ unsigned int async_events; /* async events, subset of all */ /* Array of pointers to partitions indexed by partno. * Protected with matching bdev lock but stat and other * non-critical accesses use RCU. Always access through * helpers. */ struct disk_part_tbl __rcu *part_tbl; struct hd_struct part0; const struct block_device_operations *fops; struct request_queue *queue; void *private_data; /* Flag of rockchip specific disk: eMMC/eSD, NVMe, etc. */ bool is_rk_disk; int flags; struct device *driverfs_dev; // FIXME: remove struct kobject *slave_dir; struct timer_rand_state *random; atomic_t sync_io; /* RAID */ struct disk_events *ev; #ifdef CONFIG_BLK_DEV_INTEGRITY struct kobject integrity_kobj; #endif /* CONFIG_BLK_DEV_INTEGRITY */ int node_id; };
major:驱动程序的主设备号。first_minor:磁盘的第一个次设备号。minors:最大的次设备号数量,对于不能分区的磁盘来说,该值通常为1。disk_name:主驱动程序的名称。devnode:函数指针,用于生成磁盘节点的路径名。events:支持的事件类型。async_events:异步事件类型,是所有事件类型的子集。part_tbl:指向分区表的指针数组,通过partno索引访问分区。受匹配的块设备锁保护,但状态和其他非关键访问使用 RCU(Read-Copy Update)访问。应始终通过辅助函数访问。part0:表示磁盘的第一个分区。fops:指向block_device_operations结构体的指针,表示与磁盘相关的块设备操作。queue:指向request_queue结构体的指针,表示与磁盘关联的请求队列。private_data:指向磁盘的私有数据的指针。is_rk_disk:表示是否为 Rockchip 特定的磁盘,如 eMMC/eSD、NVMe 等。flags:磁盘的标志位。driverfs_dev:指向设备的指针,用于 driverfs(一种用于设备驱动程序的虚拟文件系统)。slave_dir:指向从设备目录的指针。random:指向随机定时器状态的指针。sync_io:用于 RAID(冗余磁盘阵列)的同步 I/O。ev:指向磁盘事件的指针。integrity_kobj:用于数据完整性的内核对象。node_id:节点 ID。
hd_struct
如果将一个磁盘分成了几个分区,那么其分区表保存在hd_struct结构的数组中,该数组的地址存放在gendisk对象的part字段中。通过磁盘内分区的相对索引对该数组进行索引。
struct hd_struct { sector_t start_sect; /* * nr_sects is protected by sequence counter. One might extend a * partition while IO is happening to it and update of nr_sects * can be non-atomic on 32bit machines with 64bit sector_t. */ sector_t nr_sects; seqcount_t nr_sects_seq; sector_t alignment_offset; unsigned int discard_alignment; struct device __dev; struct kobject *holder_dir; int policy, partno; struct partition_meta_info *info; #ifdef CONFIG_FAIL_MAKE_REQUEST int make_it_fail; #endif unsigned long stamp; atomic_t in_flight[2]; #ifdef CONFIG_SMP struct disk_stats __percpu *dkstats; #else struct disk_stats dkstats; #endif struct percpu_ref ref; struct rcu_head rcu_head; };
start_sect:分区的起始扇区。nr_sects:分区的扇区数。在 32 位机器上,更新nr_sects可能不是原子操作,因此受到序列计数器的保护。nr_sects_seq:扇区数的序列计数器。alignment_offset:对齐偏移量,用于指示分区的对齐位置。discard_alignment:丢弃对齐的大小。__dev:Linux 设备结构体,表示与分区关联的设备。holder_dir:指向持有者目录的指针。policy:分区策略。partno:分区号。info:指向分区元信息的指针。make_it_fail:用于配置失败的请求。stamp:时间戳。in_flight:用于跟踪处理中的请求的原子计数器数组。dkstats:磁盘统计信息,可能是每 CPU 的结构体或单个结构体。ref:引用计数器和相关的操作。rcu_head:用于 RCU(Read-Copy Update)机制的头部。
alloc_disk
struct gendisk *alloc_disk(int minors) { return alloc_disk_node(minors, NUMA_NO_NODE); } EXPORT_SYMBOL(alloc_disk); struct gendisk *alloc_disk_node(int minors, int node_id) { struct gendisk *disk; disk = kzalloc_node(sizeof(struct gendisk), GFP_KERNEL, node_id); if (disk) { if (!init_part_stats(&disk->part0)) { kfree(disk); return NULL; } disk->node_id = node_id; if (disk_expand_part_tbl(disk, 0)) { free_part_stats(&disk->part0); kfree(disk); return NULL; } disk->part_tbl->part[0] = &disk->part0; /* * set_capacity() and get_capacity() currently don't use * seqcounter to read/update the part0->nr_sects. Still init * the counter as we can read the sectors in IO submission * patch using seqence counters. * * TODO: Ideally set_capacity() and get_capacity() should be * converted to make use of bd_mutex and sequence counters. */ seqcount_init(&disk->part0.nr_sects_seq); if (hd_ref_init(&disk->part0)) { hd_free_part(&disk->part0); kfree(disk); return NULL; } disk->minors = minors; rand_initialize_disk(disk); disk_to_dev(disk)->class = &block_class; disk_to_dev(disk)->type = &disk_type; device_initialize(disk_to_dev(disk)); } return disk; }
函数 alloc_disk() 用于分配一个通用磁盘,并设置其 minors 值为传入的 minors 参数。最终会调用函数 alloc_disk_node(),并将 NUMA_NO_NODE 作为 node_id 参数传递给它。
函数 alloc_disk_node() 接受 minors 和 node_id 作为参数,用于在指定的 NUMA 节点上分配一个通用磁盘结构体。它首先使用 kzalloc_node() 分配了一个大小为 sizeof(struct gendisk) 的内存块,并将其初始化为零。
接下来,它通过调用 disk_expand_part_tbl() 来扩展分区表,并将 disk->part0 分区指针设置为第一个分区。然后,它使用 seqcount_init() 初始化分区的扇区数的序列计数器,并使用 hd_ref_init() 初始化分区的引用计数器。
最后,它设置了其他一些字段的值,如 disk->minors、rand_initialize_disk() 初始化磁盘的随机定时器状态,并将 disk_to_dev(disk)->class 和 disk_to_dev(disk)->type 设置为 block_class 和 disk_type。最后,它使用 device_initialize() 初始化磁盘对应的设备结构体。
add_disk
函数 add_disk() 用于将磁盘添加到系统中,并进行必要的注册和初始化操作,以便系统可以正确识别和使用该磁盘。
void add_disk(struct gendisk *disk) { struct backing_dev_info *bdi; dev_t devt; int retval; /* minors == 0 indicates to use ext devt from part0 and should * be accompanied with EXT_DEVT flag. Make sure all * parameters make sense. */ WARN_ON(disk->minors && !(disk->major || disk->first_minor)); WARN_ON(!disk->minors && !(disk->flags & GENHD_FL_EXT_DEVT)); disk->flags |= GENHD_FL_UP; retval = blk_alloc_devt(&disk->part0, &devt); if (retval) { WARN_ON(1); return; } disk_to_dev(disk)->devt = devt; /* ->major and ->first_minor aren't supposed to be * dereferenced from here on, but set them just in case. */ disk->major = MAJOR(devt); disk->first_minor = MINOR(devt); disk_alloc_events(disk); /* Register BDI before referencing it from bdev */ bdi = &disk->queue->backing_dev_info; bdi_register_owner(bdi, disk_to_dev(disk)); blk_register_region(disk_devt(disk), disk->minors, NULL, exact_match, exact_lock, disk); register_disk(disk); blk_register_queue(disk); /* * Take an extra ref on queue which will be put on disk_release() * so that it sticks around as long as @disk is there. */ WARN_ON_ONCE(!blk_get_queue(disk->queue)); retval = sysfs_create_link(&disk_to_dev(disk)->kobj, &bdi->dev->kobj, "bdi"); WARN_ON(retval); disk_add_events(disk); blk_integrity_add(disk); }
-
函数对传入的磁盘结构体进行一些合法性检查。接下来,函数将
GENHD_FL_UP标志设置为磁盘的flags字段,表示该磁盘已启动。 -
然后,函数调用
blk_alloc_devt()分配一个设备号给磁盘的第一个分区disk->part0。函数将分配的设备号存储在disk_to_dev(disk)->devt中,并将disk->major和disk->first_minor设置为设备号的主设备号和次设备号。接下来,函数调用disk_alloc_events()为磁盘分配事件结构体。 -
函数注册磁盘的
backing_dev_info结构体,以便可以从块设备中引用它。函数调用blk_register_region()注册块设备的区域,以及调用register_disk()注册磁盘。函数调用blk_register_queue()注册磁盘的请求队列。 -
函数通过调用
blk_get_queue()在磁盘的请求队列上获取一个额外的引用计数,该引用计数将在disk_release()函数中释放。这样可以确保请求队列在磁盘存在期间保持有效。函数使用sysfs_create_link()创建一个链接,将磁盘的设备对象与backing_dev_info的设备对象进行关联。函数调用disk_add_events()添加磁盘事件。 -
最后,函数调用
blk_integrity_add()添加磁盘的完整性检查。
块设备磁盘、分区、块设备关系
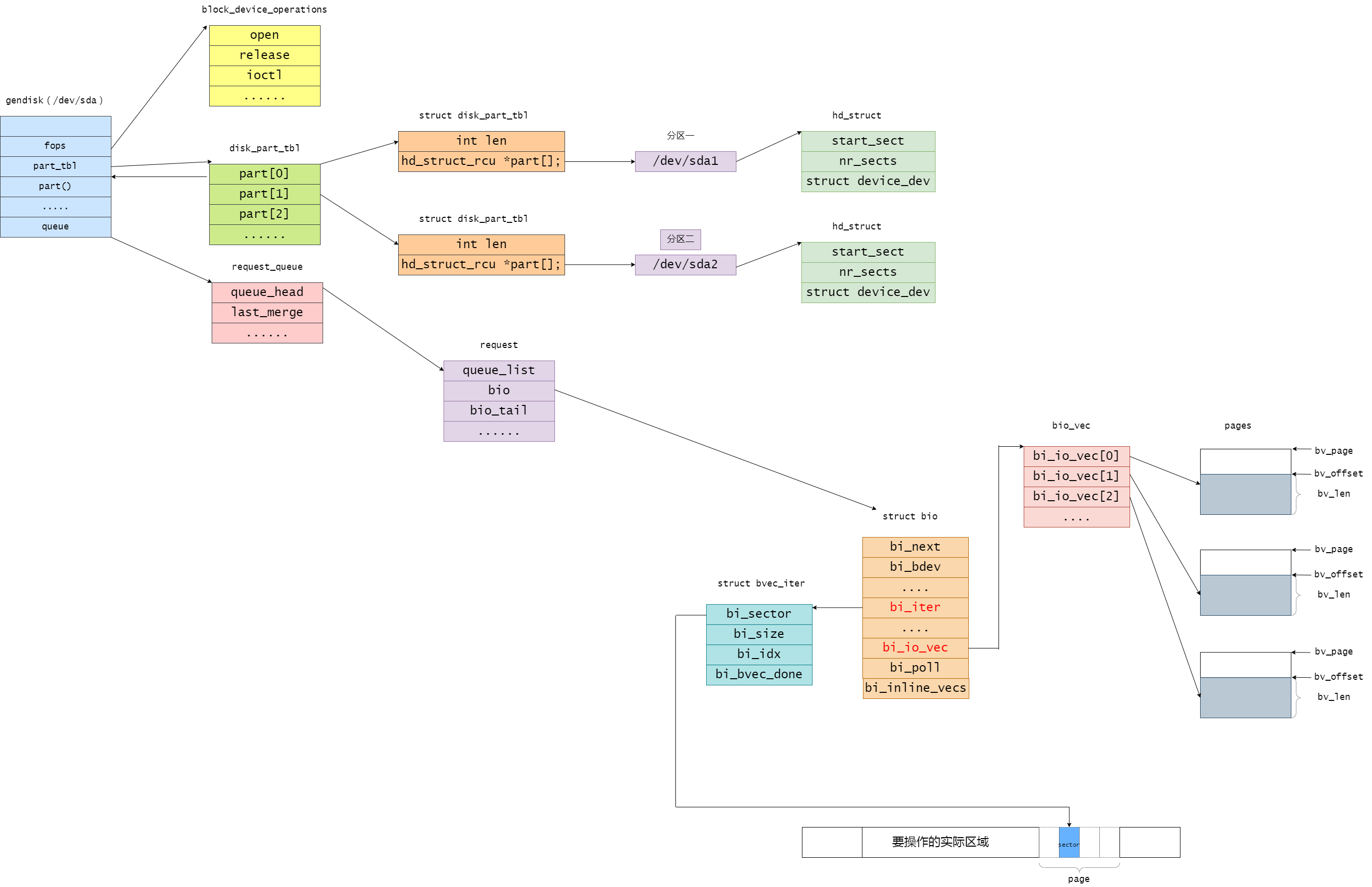
最后再来一张全景图
本文参考
https://blog.csdn.net/weixin_43780260/article/details/88993543
https://blog.csdn.net/morecrazylove/article/details/128712522


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具