《深入理解计算机系统》读书笔记 —— 第三章 程序的机器级表示
本章主要介绍了计算机中的机器代码——汇编语言。当我们使用高级语言(C、Java等)编程时,代码会屏蔽机器级的细节,我们无法了解到机器级的代码实现。既然有了高级语言,我们为什么还需要学习汇编语言呢?学习程序的机器级实现,可以帮助我们理解编译器的优化能力,可以让我们了解程序是如何运行的,哪些部分是可以优化的;当程序受到攻击(漏洞)时,都会涉及到程序运行时控制信息的细节,很多程序都会利用系统程序中的漏洞信息重写程序,从而获得系统的控制权(蠕虫病毒就是利用了gets函数的漏洞)。特别是作为一名嵌入式软件开发的从业人员,会经常接触到底层的代码实现,比如Bootloader中的时钟初始化,重定位等都是用汇编语言实现的。虽然不要求我们使用汇编语言写复杂的程序,但是要求我们要能够阅读和理解编译器产生的汇编代码。
@
程序编码
计算机的抽象模型
在之前的《深入理解计算机系统》(CSAPP)读书笔记 —— 第一章 计算机系统漫游文章中提到过计算机的抽象模型,计算机利用更简单的抽象模型来隐藏实现的细节。对于机器级编程来说,其中两种抽象尤为重要。第一种是由指令集体系结构或指令集架构( Instruction Set Architecture,ISA)来定义机器级程序的格式和行为,它定义了处理器状态、指令的格式,以及每条指令对状态的影响。大多数ISA,包括x86-64,将程序的行为描述成好像每条指令都是按顺序执行的,一条指令结束后,下一条再开始。处理器的硬件远比描述的精细复杂,它们并发地执行许多指令,但是可以采取措施保证整体行为与ISA指定的顺序执行的行为完全一致。第二种抽象是,机器级程序使用的内存地址是虚拟地址,提供的内存模型看上去是一个非常大的字节数组。存储器系统的实际实现是将多个硬件存储器和操作系统软件组合起来。
汇编代码中的寄存器
程序计数器(通常称为“PC”,在x86-64中用号%rip表示)给出将要执行的下一条指令在内存中的地址。
整数寄存器文件包含16个命名的位置,分别存储64位的值。这些寄存器可以存储地址(对应于C语言的指针)或整数数据。有的寄存器被用来记录某些重要的程序状态,而其他的寄存器用来保存临时数据,例如过程的参数和局部变量,以及函数的返回值。
条件码寄存器保存着最近执行的算术或逻辑指令的状态信息。它们用来实现控制或数据流中的条件变化,比如说用来实现if和 while语句
一组向量寄存器可以存放个或多个整数或浮点数值
关于汇编中常用的寄存器建议看我整理的嵌入式软件开发面试知识点中的ARM部分,里面详细介绍了Arm中常用的寄存器和指令集。
机器代码示例
假如我们有一个main.c文件,使用 gcc -0g -S main.c可以产生一个汇编文件。接着使用gcc -0g -c main.c就可以产生目标代码文件main.o。通常,这个.o文件是二进制格式的,无法直接查看,我们打开编辑器可以调整为十六进制的格式,示例如下所示。
53 48 89 d3 e8 00 00 00 00 48 89 03 5b c3
这就是汇编指令对应的目标代码。从中得到一个重要信息,即机器执行的程序只是一个字节序列,它是对一系列指令的编码。机器对产生这些指令的源代码几乎一无所知。
反汇编简介
要查看机器代码文件的内容,有一类称为反汇编器( disassembler)的程序非常有用。这些程序根据机器代码产生一种类似于汇编代码的格式。在 Linux系统中,使用命令 objdump -d main.o可以产生反汇编文件。示例如下图。

在左边,我们看到按照前面给出的字节顺序排列的14个十六进制字节值,它们分成了若干组,每组有1~5个字节。每组都是一条指令,右边是等价的汇编语言
其中一些关于机器代码和它的反汇编表示的特性值得注意
-
x86-64的指令长度从1到15个字节不等。常用的指令以及操作数较少的指令所需的字节数少,而那些不太常用或操作数较多的指令所需字节数较多
-
设计指令格式的方式是,从某个给定位置开始,可以将字节唯一地解码成机器指令。例如,只有指令 push%rbx是以字节值53开头的
-
反汇编器只是基于机器代码文件中的字节序列来确定汇编代码。它不需要访问该程序的源代码或汇编代码
-
反汇编器使用的指令命名规则与GCC生成的汇编代码使用的有些细微的差别。在我们的示例中,它省略了很多指令结尾的‘q’。这些后缀是大小指示符,在大多数情况中可以省略。相反,反汇编器给ca11和ret指令添加了‘q’后缀,同样,省略这些后缀也没有问题。
数据格式
Intel用术语“字(word)”表示16位数据类型。因此,称32位数为“双字( double words)”,称64位数为“四字( quad words)。下表给出了C语言基本数据类型对应的x86-64表示。
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | 1 | 8 |
访问信息
操作数指示符
整数寄存器
不同位的寄存器名字不同,使用的时候要注意。

三种类型的操作数
1.立即数,用来表示常数值,比如,$0x1f 。不同的指令允许的立即数值范围不同,汇编器会自动选择最紧凑的方式进行数值编码。
2.寄存器,它表示某个寄存器的内容,16个寄存器的低位1字节、2字节、4字节或8字节中的一个作为操作数,这些字节数分别对应于8位、16位、32位或64位。在图3-3中,我们用符号\({r_a}\)来表示任意寄存器a,用引用\(R[{r_a}]\)来表示它的值,这是将寄存器集合看成一个数组R,用寄存器标识符作为索引。
3.内存引用,它会根据计算出来的地址(通常称为有效地址)访问某个内存位置。因为将内存看成一个很大的字节数组,我们用符号\({M_b}[Addr]\)表示对存储在内存中从地址Addr开始的b个字节值的引用。为了简便,我们通常省去下标b。
操作数的格式
看汇编指令的时候,对照下图可以读懂大部分的汇编代码。

数据传送指令
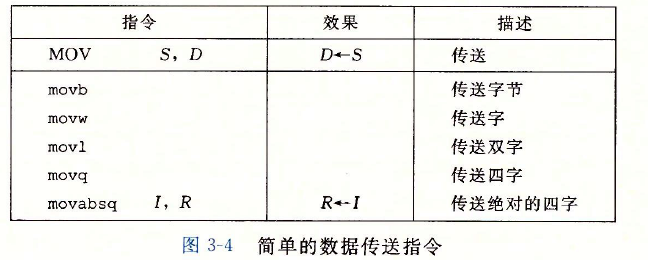
不同后缀的指令主要区别在于它们操作的数据大小不同。
源操作数:寄存器,内存
目的操作数:寄存器,内存。
注意:传送指令的两个操作数不能都指向内存位置。将一个值从一个内存位置复制到另一个内存位置需要两条指令—第一条指令将源值加载到寄存器中,第二条将该寄存器值写入目的位置。
movl $0x4050,%eax Immediate--Register,4 bytes p,1sp move movw %bp,%sp Register--Register, 2 bytes movb (%rdi. %rcx),%al Memory--Register 1 bytes movb $-17,(%rsp) Immediate--Memory 1 bytes movq %rax,-12(%rpb) Register--Memory, 8 bytes
将较小的源值复制到较大的目的时使用如下指令。

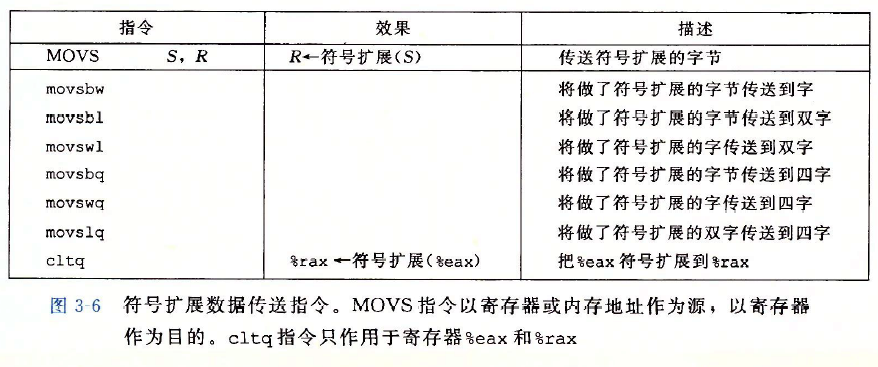
举例

过程参数xp和y分别存储在寄存器%rdi和%rsi中(参数通过寄存器传递给函数)。
第二行:指令movq从内存中读出xp,把它存放到寄存器%rax中(像x这样的局部变量通常是保存在寄存器中,而不是在内存中)。
第三行:指令movq将y写入到寄存器%rdi中的xp指向的内存位置。
第四行:指令ret用寄存器 %rax从这个函数返回一个值。
总结:
间接引用指针就是将该指针放在一个寄存器中,然后在内存引用中使用这个寄存器。
像x这样的局部变量通常是保存在寄存器中,而不是内存中。访问寄存器比访问内存要快得多。
压入和弹出栈数据

pushq指令的功能是把数据压入到栈上,而popq指令是弹出数据。这些指令都只有一个操作数——压入的数据源和弹出的数据目的。
pushq %rbp等价于以下两条指令:
subq $8,%rsp Decrement stack pointer movq %rbp,(%rsp) Store %rbp on stackpopq %rax等价于下面两条指令:
mova (%rsp), %rax Read %rax from stack addq $8,%rsp Increment stack pointer
算数和逻辑操作
加载有效地址
IA32指令集中有这样一条加载有效地址指令leal,用法为leal S, D,效果是将S的地址存入D,是mov指令的变形。可是这条指令往往用在计算乘法上,GCC编译器特别喜欢使用这个指令,比如下面的例子
leal (%eax, %eax, 2), %eax
实现的功能相当于%eax = %eax * 3。括号中是一种比例变址寻址,将第一个数加上第二个数和第三个数的乘积作为地址寻址,leal的效果使源操作数正好是寻址得到的地址,然后将其赋值给%eax寄存器。为什么用这种方式算乘法,而不是用乘法指令imul呢?
这是因为Intel处理器有一个专门的地址运算单元,使得leal的执行不必经过ALU,而且只需要单个时钟周期。相比于imul来说要快得多。因此,对于大部分乘数为小常数的情况,编译器都会使用leal完成乘法操作。
一元和二元操作
| 地址 | 值 |
|---|---|
| 0x100 | 0xFF |
| 0x108 | 0xAB |
| 0x110 | 0x13 |
| 0x118 | 0x11 |
| 寄存器 | 值 |
|---|---|
| %rax | 0x100 |
| %rcx | 0x1 |
| %rdx | 0x3 |
看个例子应该就明白这些指令的含义了,不知道指令意思的,可以看操作数的格式这一节中总结的常见汇编指令的格式。
| 指令 | 目的 | 值 | 解释 |
|---|---|---|---|
| addq %rcx,(%rax) | 0x100 | 0x100 | 将rcx寄存器的值(0x1)加到%rax地址处(0xFF) |
| subq %rdx,8(%rax) | 0x108 | 0xA8 | 从8(%rax)地址处取值(0XAB)并减去%rdx的值(0x3) |
| imulq $16,(%rax,%rdx,8) | 0x118 | 0x110 | (0x100+0x3 * 8) = 118.从118的地址取值并乘以10(16)结果为0x110 |
| incq 16(%rax) | 0x110 | 0x14 | %rax + 16 = 0x100+10 = 0x110。从0x110取值得0x13,结果+1为0x14。 |
| decq %rcx | %rcx | 0x0 | 0x1-1 |
移位操作
左移指令:SAL,SHL
算术右移指令:SAR(填上符号位)
逻辑右移指令:SHR(填上0)
移位操作的目的操作数是一个寄存器或是一个内存位置。169

C语言对应的汇编代码


控制
条件码
条件码的定义:
描述了最近的算术或逻辑操作的属性。可以检测这些寄存器来执行条件分支指令。
常用的条件码
CF:进位标志。最近的操作使最高位产生了进位。可用来检查无符号操作的溢出。
ZF:零标志。最近的操作得出的结果为0。
SF:符号标志。最近的操作得到的结果为负数。
OF:溢出标志。最近的操作导致一个补码溢出—正溢出或负溢出。
改变条件码的指令
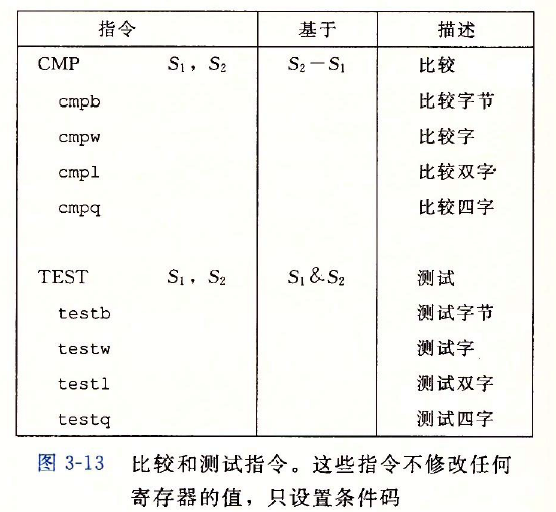
cmp指令根据两个操作数之差来设置条件码,常用来比较两个数,但是不会改变操作数。
test指令用来测试这个数是正数还是负数,是零还是非零。两个操作数相同
test %rax,%rax //检查%rax是负数、零、还是正数(%rax && %rax)
cmp %rax,%rdi //与sub指令类似,%rdi - %rax 。
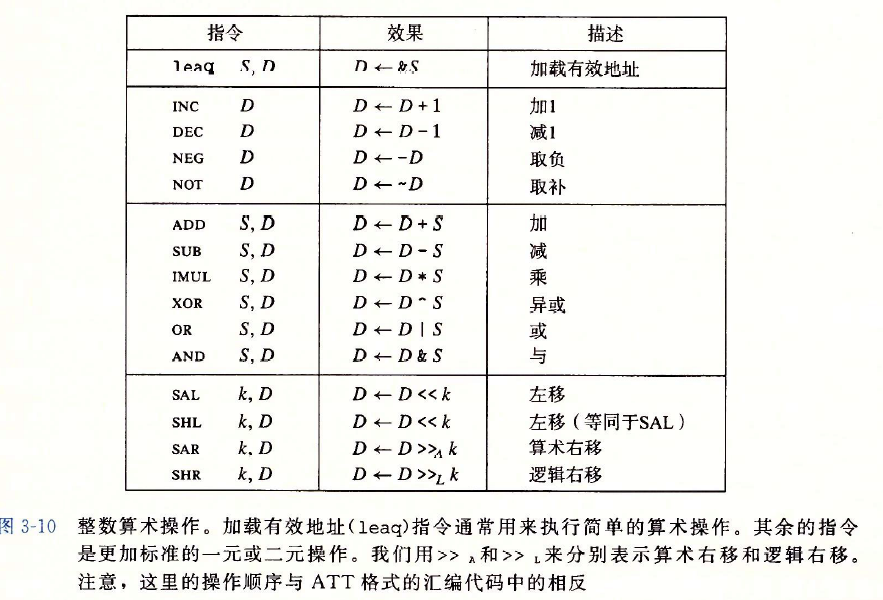
上表中除了leap指令,其他指令都会改变条件码。
ⅩOR,进位标志和溢出标志会设置成0.对于移位操作,进位标志将设置为最后一个被移出的位,而溢出标志设置为0。INC和DEC指令会设置溢出和零标志。
访问条件码
访问条件码的三种方式
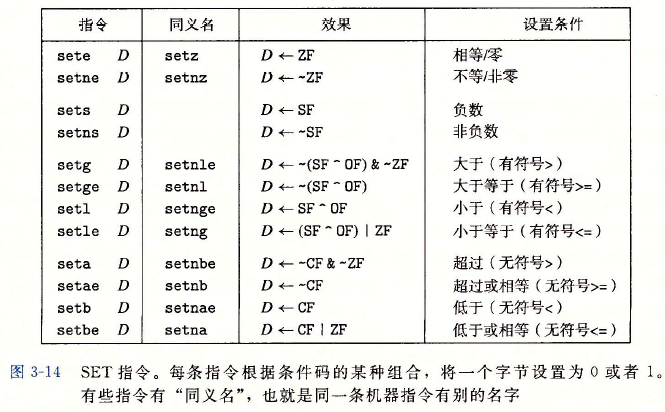
1.可以根据条件码的某种组合,将一个字节设置为0或者1。
2.可以条件跳转到程序的某个其他的部分。
3.可以有条件地传送数据。
对于第一种情况,常使用set指令来设置,set指令如下图所示。
/* 计算a<b的汇编代码 int comp(data_t a,data_t b) a in %rdi,b in %rsi */ comp: cmpq %rsi,%rdi setl %al movzbl %al,%eax retsetl %al 当a<b,设置%eax的低位为0或者1。
跳转指令

上表中的有些指令是带有后缀的,表示条件跳转,下面解释下这些后缀,有助于记忆。
e == equal,ne == not equal,s == signed,ns == not signed,g == greater,ge == greater or equal,l == less,le == less or eauql,a == ahead,ae == ahead or equal,b == below,be == below or equal
直接跳转
jmp .L1 //直接给出标号,跳转到标号处
间接跳转
jmp *%rax //用寄存器%rax中的值作为跳转目标
jmp *(%rax) //以%rax中的值作为读地址,从内存中读出跳转目标
跳转指令的编码
通过看跳转指令的编码格式理解下程序计数器PC是如何实现跳转的。
汇编
movq %rdi, %rax
jmp .L2
.L3:
sarq %rax
.L2:
testq %rax, %rax
jg .L3
rep;ret
反汇编
0:48 89 f8 mov %rdi,%raxrdi,
3:eb 03 jmp 8 <loop+0x8>
5:48 d1 f8 sar %rax
8:48 85 c0 test %rax %rax
b:71 f8 jg 5<loop+0x5>
d: f3 C3 repz rete
右边反汇编器产生的注释中,第2行中跳转指令的跳转目标指明为0x8,第5行中跳转指令的跳转目标是0x5(反汇编器以十六进制格式给出所有的数字)。不过,观察指令的宇节编码,会看到第一条跳转指令的目标编码(在第二个字节中)为0x03.把它加上0×5,也就是下一条指令的地址,就得到跳转目标地址0x8,也就是第4行指令的地址。
类似,第二个跳转指令的目标用单字节、补码表示编码为0xf8(十进制-8)。将这个数加上0xa(十进制13),即第6行指令的地址,我们得到0x5,即第3行指令的地址。
这些例子说明,当执行PC相对寻址时,程序计数器的值是跳转指令后面的那条指令的地址,而不是跳转指令本身的地址。
条件控制实现条件分支

上图分别给出了C语言,goto表示,汇编语言的三种形式。这里使用goto语句,是为了构造描述汇编代码程序控制流的C程序。
汇编代码的实现(图3-16c)首先比较了两个操作数(第2行),设置条件码。如果比较的结果表明x大于或者等于y,那么它就会跳转到第8行,增加全局变量 ge_cnt,计算x-y作为返回值并返回。由此我们可以看到 absdiff_se对应汇编代码的控制流非常类似于gotodiff_ se的goto代码。
C语言中的if-else通用模版如下:

对应的汇编代码如下:

条件传送实现条件分支

GCC为该函数产生的汇编代码如图3-17c所示,它与图3-17b中所示的C函数cmovdiff有相似的形式。研究这个C版本,我们可以看到它既计算了y-x,也计算了x-y,分别命名为rval和eval。然后它再测试x是否大于等于y,如果是,就在函数返回rval前,将eval复制到rval中。图3-17c中的汇编代码有相同的逻辑。关键就在于汇编代码的那条 cmovge指令(第7行)实现了 cmovdiff的条件赋值(第8行)。只有当第6行的cmpq指令表明一个值大于等于另一个值(正如后缀ge表明的那样)时,才会把数据源寄存器传送到目的。
条件控制的汇编模版如下:

实际上,基于条件数据传送的代码会比基于条件控制转移的代码性能要好。主要原因是处理器通过使用流水线来获得高性能,处理器采用非常精密的分支预测逻辑来猜测每条跳转指令是否会执行。只要它的猜测还比较可靠(现代微处理器设计试图达到90%以上的成功率),指令流水线中就会充满着指令。另一方面,错误预测一个跳转,要求处理器丢掉它为该跳转指令后所有指令已做的工作,然后再开始用从正确位置处起始的指令去填充流水线。这样一个错误预测会招致很严重的惩罚,浪费大约15~30个时钟周期,导致程序性能严重下降。
使用条件传送也不总是会提高代码的效率。例如,如果 then expr或者 else expr的求值需要大量的计算,那么当相对应的条件不满足时,这些工作就白费了。编译器必须考虑浪费的计算和由于分支预测错误所造成的性能处罚之间的相对性能。说实话,编译器井不具有足够的信息来做出可靠的决定;例如,它们不知道分支会多好地遵循可预测的模式。我们对GCC的实验表明,只有当两个表达式都很容易计算时,例如表达式分别都只是条加法指令,它才会使用条件传送。根据我们的经验,即使许多分支预测错误的开销会超过更复杂的计算,GCC还是会使用条件控制转移。
所以,总的来说,条件数据传送提供了一种用条件控制转移来实现条件操作的替代策略。它们只能用于非常受限制的情况,但是这些情况还是相当常见的,而且与现代处理器的运行方式更契合。
循环
将循环翻译成汇编主要有两种方法,第一种我们称为跳转到中间,它执行一个无条件跳转跳到循环结尾处的测试,以此来执行初始的测试。第二种方法叫guarded-do,首先用条件分支,如果初始条件不成立就跳过循环,把代码变换为do-whie循环。当使用较髙优化等级编译时,例如使用命令行选项-O1,GCC会采用这种策略。
跳转到中间
如下图所示为while循环写的计算阶乘的代码。可以看到编译器使用了跳转到中间的翻译方法,在第3行用jmp跳转到以标号L5开始的测试,如果n满足要求就执行循环,否则就退出。

guarded-do
下图为使用第二种方法编译的汇编代码,编译时是用的是-O1,GCC就会采用这种方式编译循环。

上面介绍的是while循环和do-while循环的两种编译模式,根据GCC不同的优化结果会得到不同的汇编代码。实际上,for循环产生的汇编代码也是以上两种汇编代码中的一种。for循环的通用形式如下所示。

选择跳转到中间策略会得到如下goto代码:

guarded-do策略会得到如下goto代码:

suitch语句
switch语句可以根据一个整数索引值进行多重分支。它们不仅提高了C代码的可读性而且通过使用跳转表这种数据结构使得实现更加高效。跳转表是一个数组,表项i是一个代码段的地址,这个代码段实现当开关索引值等于i时程序应该采取的动作。
程序代码用开关索引值来执行一个跳转表内的数组引用,确定跳转指令的目标。和使用组很长的if-else语句相比,使用跳转表的优点是执行开关语句的时间与开关情况的数量无关。GCC根据开关情况的数量和开关情况值的稀疏程度来翻译开关语句。当开关情况数量比较多(例如4个以上),并且值的范围跨度比较小时,就会使用跳转表。

原始的C代码有针对值100、102104和106的情况,但是开关变量n可以是任意整数。编译器首先将n减去100,把取值范围移到0和6之间,创建一个新的程序变量,在我们的C版本中称为 index。补码表示的负数会映射成无符号表示的大正数,利用这一事实,将 index看作无符号值,从而进一步简化了分支的可能性。因此可以通过测试 index是否大于6来判定index是否在0~6的范围之外。在C和汇编代码中,根据 index的值,有五个不同的跳转位置:loc_A(.L3),loc_B(.L5),loc_C(.L6),loc_D(.L7)和 loc_def(.L8),最后一个是默认的目的地址。每个标号都标识一个实现某个情况分支的代码块。在C和汇编代码中,程序都是将 index和6做比较,如果大于6就跳转到默认的代码处。

执行 switch语句的关键步骤是通过跳转表来访问代码位置。在C代码中是第16行一条goto语句引用了跳转表jt。GCC支持计算goto,是对C语言的扩展。在我们的汇编代码版本中,类似的操作是在第5行,jmp指令的操作数有前缀‘ * ’,表明这是一个间接跳转,操作数指定一个内存位置,索引由寄存器%rsi给出,这个寄存器保存着 index的值。
C代码将跳转表声明为一个有7个元素的数组,每个元素都是一个指向代码位置的指针。这些元素跨越 index的值0 ~ 6,对应于n的值100~106。可以观察到,跳转表对重复情况的处理就是简单地对表项4和6用同样的代码标号(loc_D),而对于缺失的情况的处理就是对表项1和5使用默认情况的标号(loc_def)。
在汇编代码中,跳转表声明为如下形式

(.rodata段的详细解释在我总结的嵌入式软件开发笔试面试知识点中有详细介绍)
已知switch汇编代码,如何利用汇编语言和跳转表的结构推断出switch的C语言结构?
关于C语言的switch语句,需要重点确定的有跳转表的大小,跳转范围,那些case是缺失的,那些是重复的。下面我们一 一确定。
这些表声明中,从图3-23的汇编第1行可以知道,n的起始计数为100。由第二行可以知道,变量和6进行比较,说明跳转表索引偏移范围为0 ~ 6,对应为100 ~106。从.quad .L3开始,由上到下,依次编号为0,1,2,3,4,5,6。其中由图3-23的ja .L8可知,大于6时就跳转到.L8,那么跳转表中编号为1和5的都是跳转的默认位置。因此,编号为1和5的为缺失的情况,即没有101和105的选项。而编号为4和6的都跳转到了.L7,说明两者是对应于100+4=104,100+6=106。剩下的情况0,2,3依次编号为100,102,103。至此我们就得出了switch的编号情况,一共有6项,100,102,103,104,106,default。剩下的关于每种case的C语言内容就可以根据汇编代码写出来了。
过程
运行时栈
C语言过程调用机制的一个关键特性(大多数其他语言也是如此)在于使用了栈数据结构提供的后进先出的内存管理原则。假如在过程P调用过程Q时,可以看到当Q在执行时,P以及所有在向上追溯到P的调用链中的过程,都是暂时被挂起的。当Q运行时,它只需要为局部变量分配新的存储空间,或者设置到另一个过程的调用。另一方面,当Q返回时,任何它所分配的局部存储空间都可以被释放。因此,程序可以用栈来管理它的过程所需要的存储空间,栈和程序寄存器存放着传递控制和数据、分配内存所需要的信息。当P调用Q时,控制和数据信息添加到栈尾。当P返回时,这些信息会释放掉。
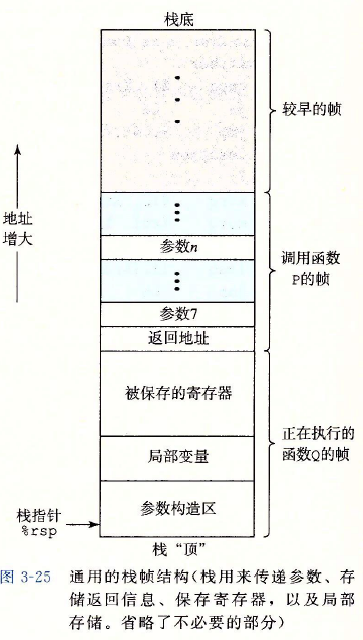
x86-64的栈向低地址方向增长,而栈指针号%rsp指向栈顶元素。可以用 pushq和popq指令将数据存人栈中或是从栈中取出。将栈指针减小一个适当的量可以为没有指定初始值的数据在栈上分配空间。类似地,可以通过增加栈指针来释放空间。
过程P可以传递最多6个整数值(也就是指针和整数),但是如果Q需要更多的参数,P可以在调用Q之前在自己的栈帧(也就是内存)里存储好这些参数。
转移控制
将控制从函数转移到函数Q只需要简单地把程序计数器(PC)设置为Q的代码的起始位置。不过,当稍后从Q返回的时候,处理器必须记录好它需要继续P的执行的代码位置。在x86-64机器中,这个信息是用指令call Q调用过程Q来记录的。该指令会把地址A压入栈中,并将PC设置为Q的起始地址。压入的地址A被称为返回地址,是紧跟在call指令后面的那条指令的地址。对应的指令ret会从栈中弹出地址A,并把PC设置为A。

下面看个例子
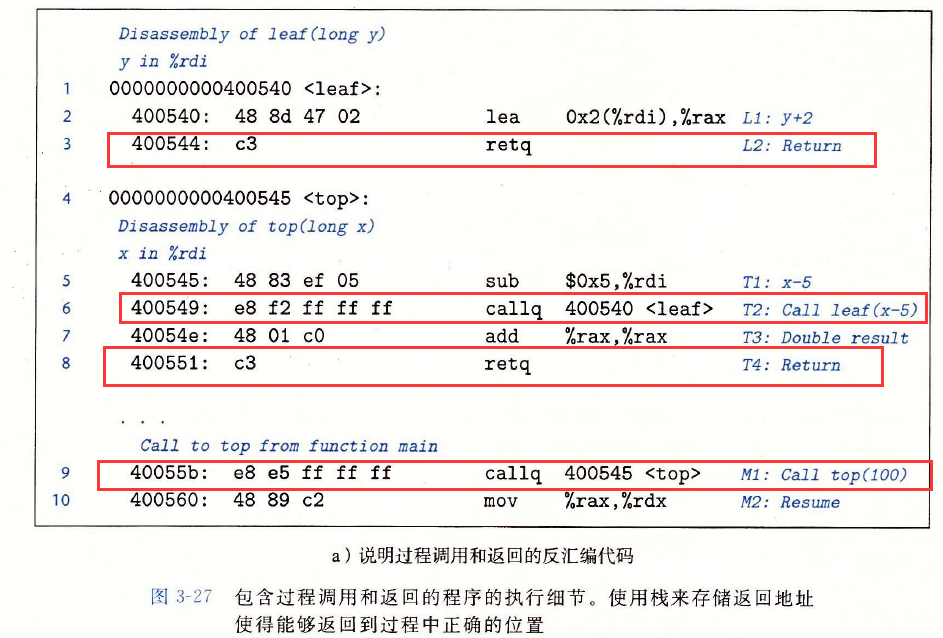
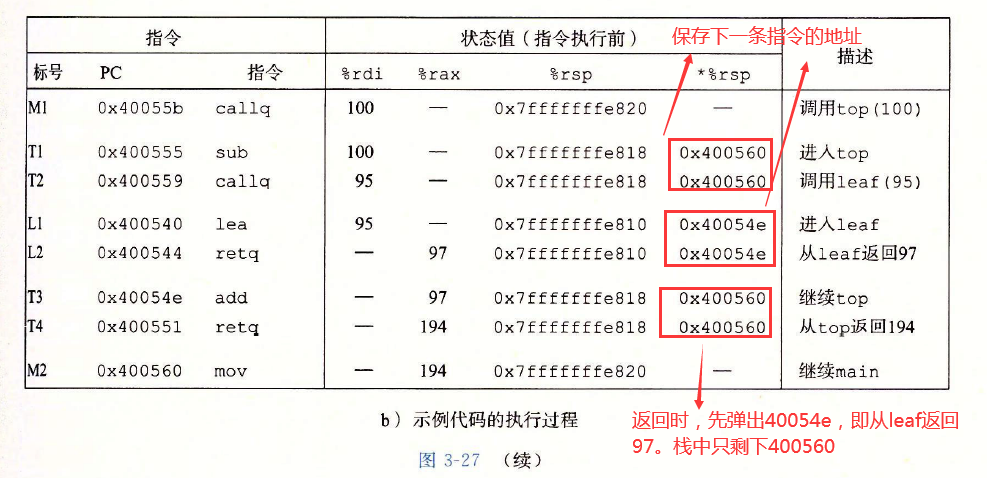
main调用top(100),然后top调用leaf(95)。函数leaf向top返回97,然后top向main返回194.前面三列描述了被执行的指令,包括指令标号、地址和指令类型。后面四列给出了在该指令执行前程序的状态,包括寄存器%rdi、%rax和%rsp的内容,以及位于栈顶的值。
leaf的指令L1将%rax设置为97,也就是要返回的值。然后指令L2返回,它从栈中弹出0×400054e。通过将PC设置为这个弹出的值,控制转移回top的T3指令。程序成功完成对leaf的调用,返回到top。
指令T3将%rax设置为194,也就是要从top返回的值。然后指令T4返回,它从栈中弹出0×4000560,因此将PC设置为main的M2指令。程序成功完成对top的调用,返回到main。可以看到,此时栈指针也恢复成了0x7fffffffe820,即调用top之前的值。
这种把返回地址压入栈的简单的机制能够让函数在稍后返回到程序中正确的点。C语言标准的调用/返回机制刚好与栈提供的后进先出的内存管理方法吻合。
数据传送
X86-64中,可以通过寄存器来传递最多6个参数。寄存器的使用是有特殊顺序的,如下表所示,会根据参数的顺序为其分配寄存器。
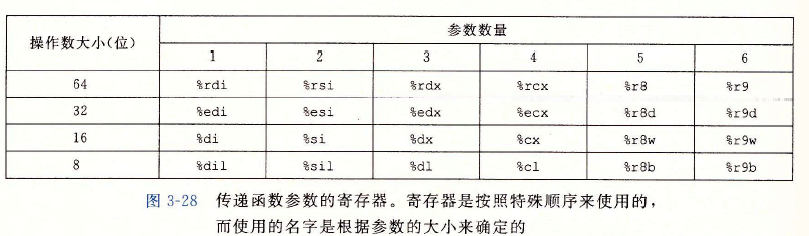
当传递参数超过6个时,会把大于6个的部分放在栈上。
如下图所示的部分,红框内的参数就是存储在栈上的。

栈上的局部存储
通常来说,不需要超出寄存器大小的本地存储区域。不过有些时候,局部数据必须存放在内存中,常见的情况包括:1.寄存器不足够存放所有的本地数据。
2.对一个局部变量使用地址运算符‘&‘,因此必须能够为它产生一个地址。3.某些局部变量是数组或结构,因此必须能够通过数组或结构引用被访问到。
下面看一个例子。


第二行的subq指令将栈指针减去32,实际上就是分配了32个字节的内存空间。在栈指针的基础上,分别+24,+20,+18,+17,用来存放1,2,3,4的值。在第7行中,使用leaq生成到17(%rsp)的指针并赋值给%rax。接着在栈指针基础上+8和+16的位置存放参数7和参数8。而参数1-参数6分别放在6个寄存器中。栈帧的结构如下图所示。
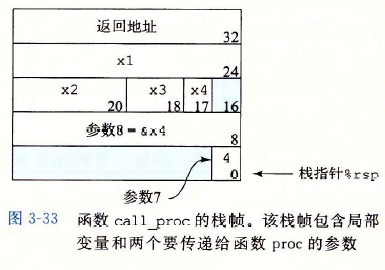
上述汇编中第2-15行都是在为调用proc做准备(为局部变量和函数建立栈帧,将函数加载到寄存器)。当准备工作完成后,就会开始执行proc的代码。当程序返回call_proc时,代码会取出4个局部变量(第17~20行),并执行最终的计算。在程序结束前,把栈指针加32,释放这个栈帧。
寄存器中的局部存储
寄存器组是唯一被所有过程共享的资源。因此,在某些调用过程中,我们要不同过程调用的寄存器不能相互影响。
根据惯例,寄存器%rbx、%rbp和%r12~%r15被划分为被调用者保存寄存器。当过程P调用过程Q时,Q必须保存这些寄存器的值,保证它们的值在Q返回到P时与Q被调用时是一样的。过程Q保存一个寄存器的值不变,要么就是根本不去改变它,要么就是把原始值压入栈中。有了这条惯例,P的代码就能安全地把值存在被调用者保存寄存器中(当然,要先把之前的值保存到栈上),调用Q,然后继续使用寄存器中的值。
下面看个例子。

可以看到GCC生成的代码使用了两个被调用者保存寄存器:%rbp保存x和%rbx保存计算出来的Q(y)的值。在函数的开头,把这两个寄存器的值保存到栈中(第2~3行)。在第一次调用Q之前,把参数ⅹ复制到%rbp(第5行)。在第二次调用Q之前,把这次调用的结果复制到%rbx (第8行)。在函数的结尾,(第13~14行),把它们从栈中弹出,恢复这两个被调用者保存寄器的值。注意它们的弹压入顺序,说明了栈的后进先出规则。
递归过程
根据之前的内容可以知道,多个过程调用在栈中都有自己的私有空间,多个未完成调用的局部变量不会相互影响,递归本质上也是多个过程的相互调用。如下所示为一个计算阶乘的递归调用。

上图给出了递归的阶乘函数的C代码和生成的汇编代码。可以看到汇编代码使用寄存器%rbx来保存参数n,先把已有的值保存在栈上(第2行),随后在返回前恢复该值(第11行)。根据栈的使用特性和寄存器保存规则,可以保证当递归调用 refact(n-1)返回时(第9行),(1)该次调用的结果会保存在寄存器号%rax中,(2)参数n的值仍然在寄存器各%rbx中。把这两个值相乘就能得到期望的结果。
数组分配和访问
基本原则
在机器代码级是没有数组这一更高级的概念的,只是你将其视为字节的集合,这些字节的集合是在连续位置上存储的,结构也是如此,它就是作为字节集合来分配的,然后,C 编译器的工作就是生成适当的代码来分配该内存,从而当你去引用结构或数组的某个元素时,去获取正确的值。
数据类型T和整型常数N,声明一个数组T A[N]。起始位置表示为\({X_A}\).这个声明有两个效果。首先,它在内存中分配一个\(L \bullet N\)字节的连续区域,这里L是数据类型T的大小(单位为字节)。其次,它引入了标识符A,可以用来作A为指向数组开头的指针,这个指针的值就是\({X_A}\)。可以用0~N-1的整数索引来访问该数组元素。数组元素i会被存放在地址为\({X_A} + L \bullet i\)的地方。
char A[12];
char *B[8];
char C[6];
char *D[5];
数组 元素大小 总的大小 起始地址 元素i A 1 12 \({X_A}\) \({X_A}+i\) B 8 64 \({X_B}\) \({X_B}+8i\) C 4 24 \({X_C}\) \({X_C}+4i\) D 8 40 \({X_D}\) \({X_D}+8i\)
指针运算
假设整型数组E的起始地址和整数索引i分别存放在寄存器是%rdx和%rcx中。下面是一些与E有关的表达式。我们还给出了每个表达式的汇编代码实现,结果存放在寄存器号%eax(如果是数据)或寄存器号%rax(如果是指针)中。

二维数组
对于一个声明为T D[R] [C]的二维数组来说,数组D[i] [j]的内存地址为\({X_D} + L(C \bullet i + j)\)。
这里,L是数据类型T以字节为单位的大小。假设\({X_A}\)、i和j分别在寄存器%rdi、%rsi和%rdx中。然后,可以用下面的代码将数组元素A[i] [j]复制到寄存器%eax中:
/*A in %rdi, i in %rsi, and j in %rdx*/
leaq (%rsi,%rsi,2), %rax //Compute 3i
leaq (%rdi,%rax,4),%rax //Compute XA+ 12i
movl (7rax, rdx, 4), %eax //Read from M[XA+ 12i+4j]
异质的数据结构
结构体
C语言的 struct声明创建一个数据类型,将可能不同类型的对象聚合到一个对象中。结构的所有组成部分都存放在内存中一段连续的区域内,而指向结构的指针就是结构第个字节的地址。编译器维护关于每个结构类型的信息,指示每个字段( field)的字节偏移。它以这些偏移作为内存引用指令中的位移,从而产生对结构元素的引用。
结构体在内存中是以偏移的方式存储的,具体可以看这个文章。Linux内核中container_of宏的详细解释。
struct rec {
int i;
int j;
int a[2];
int *p;
};
这个结构包括4个字段:两个4字节int、一个由两个类型为int的元素组成的数组和一个8字节整型指针,总共是24个字节。

看汇编代码也可以看出,结构体成员的访问是基地址加上偏移地址的方式。例如,假设 struct rec*类型的变量r放在寄存器%rdi中。那么下面的代码将元素r->i复制到元素r->j:
/*Registers:r in %rdi,i %rsi */
movl (%rdi), %eax //Get r->i
movl %eax, 4(%rdi) //Store in r-27
leaq 8(%rdi,%rsi,4),//%rax 得到一个指针,8+4*%rsi,&(r->a[i])
数据对齐
关于字节对齐的相关内容见我整理的《嵌入式软件笔试面试知识点总结》里面详细介绍了字节对齐的相关内容。
在机器级程序中将控制和程序结合起来
理解指针
关于指针的几点说明:
1.每个指针都对应一个类型
int *ip;//ip为一个指向int类型对象的指针 char **cpp;//cpp为指向指针的指针,即cpp指向的本身就是一个指向char类型对象的指针 void *p;//p为通用指针,malloc的返回值为通用指针,通过强制类型转换可以转换成我们需要的指针类型
2.每个指针都有一个值。这个值可以是某个指定类型的对象的地址,也可以是一个特殊的NULL(0)。
3.指针用&运算符创建。在汇编代码中,用leaq指令计算内存引用的地址。
int i = 0; int *p = &i;//取i的地址赋值给p指针
4.* 操作符用于间接引用指针。引用的结果是一个具体的数值,它的类型与该指针的类型一致。
5.数组与指针紧密联系,但是又有所区别。
int a[10] ={0};一个数组的名字可以像一个指针变量一样引用(但是不能修改)。数组引用(例如a[5]与指针运算和间接引用(例如*(a+5))有一样的效果。
数组引用和指针运算都需要用对象大小对偏移量进行伸缩。当我们写表达式a+i,这里指针p的值为a,得到的地址计算为a+L * i,这里L是与a相关联的数据类型的大小。
数组名对应的是一块内存地址,不能修改。指针指向的是任意一块内存,其值可以随意修改。
6.将指针从一种类型强制转換成另一种类型,只改变它的类型,而不改变它的值。强制类型转换的一个效果是改变指针运算的伸缩。例如,如果a是一个char * 类型的指针,它的值为a,a+7结果为a+7 * 1,而表达式(int* )p+7结果为p+4 * 7。
内存越界引用
C对于数组引用不进行任何边界检查,而且局部变量和状态信息(例如保存的寄存器值和返回地址)都存放在栈中。这两种情况结合到一起就能导致严重的程序错误,对越界的数组元素的写操作会破坏存储在栈中的状态信息。当程序使用这个被破坏的状态,就会出现很严重的错误,一种特别常见的状态破坏称为缓冲区溢出( buffer overflow)。


上述C代码,buf只分配了8个字节的大小,任何超过7字节的都会使的数组越界。
输入不同数量的字符串会发生不同的错误,具体可以参考下图。

echo函数的栈分布如下图所示。
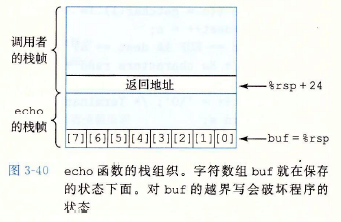
字符串到23个字符之前都没有严重的后果,但是超过以后,返回指针的值以及更多可能的保存状态会被破坏。如果存储的返回地址的值被破坏了,那么ret指令(第8行)会导致程序跳转到一个完全意想不到的位置。如果只看C代码,根本就不可能看出会有上面这些行为。只有通过研究机器代码级别旳程序才能理解像gets这样的函数进行的内存越界写的影响。
浮点代码
计算机中的浮点数可以说是"另类"的存在,每次提到数据相关的内容时,浮点数总是会被单独拿出来说。同样,在汇编中浮点数也是和其他类型的数据有所差别的,我们需要考虑以下几个方面:1.如何存储和访问浮点数值。通常是通过某种寄存器方式来完成2.对浮点数据操作的指令3.向函数传递浮点数参数和从函数返回浮点数结果的规则。4.函数调用过程中保存寄存器的规则—例如,一些寄存器被指定为调用者保存,而其他的被指定为被调用者保存。
X86-64浮点数是基于SSE或AVX的,包括传递过程参数和返回值的规则。在这里,我们讲解的是基于AVX2。在利用GCC进行编译时,加上-mavx2,GCC会生成AVX2代码。
如下图所示,AVX浮点体系结构允许数据存储在16个YMM寄存器中,它们的名字为%ymm0~%ymm15。每个YMM寄存器都是256位(32字节)。当对标量数据操作时,这些寄存器只保存浮点数,而且只使用低32位(对于float)或64位(对于 double)。汇编代码用寄存器的 SSE XMM寄存器名字%xmm0~%xmm15来引用它们,每个XMM寄存器都是对应的YMM寄存器的低128位(16字节)。

其实浮点数的汇编指令和整数的指令都是差不多的,不需要都记住,用到的时候再查询就可以了。
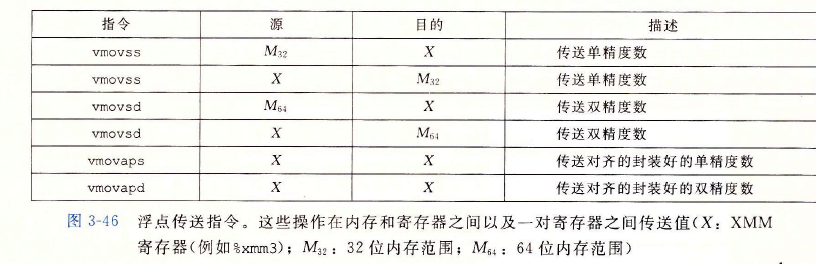
数据传送指令
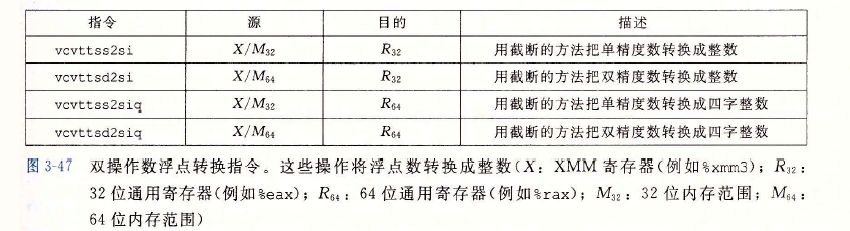
双操作数浮点转换指令
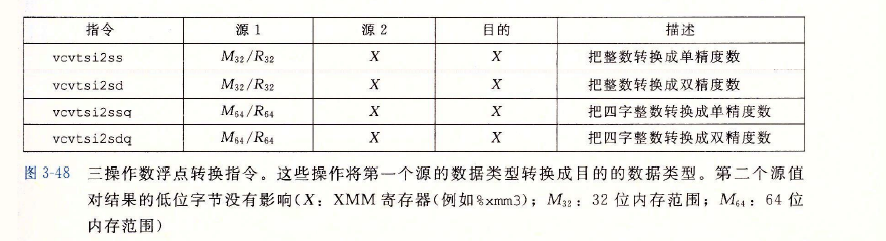
三操作数浮点转换指令
标量浮点算术运算

浮点数的位级操作

比较浮点数值的指令

在本章中,我们了解了C语言提供的抽象层下面的东西。通过让编译器产生机器级程序的汇编代码表示,我们了解了编译器和它的优化能力,以及机器、数据类型和指令集。本章要求我们要能阅读和理解编译器产生的机器级代码,机器指令并不需要都记住,在需要的时候查就可以了。Arm的指令集和X86指令集大同小异,做嵌入式软件开发掌握常用的Arm指令集就可以。嵌入式软件开发知识点详细介绍了常用的Arm指令集及其含义,有需要的可以关注我的公众号领取。
养成习惯,先赞后看!如果觉得写的不错,欢迎关注,点赞,转发,谢谢!
如遇到排版错乱的问题,可以通过以下链接访问我的CSDN。
CSDN:CSDN搜索“嵌入式与Linux那些事”
欢迎欢迎关注我的公众号:嵌入式与Linux那些事,领取秋招笔试面试大礼包(华为小米等大厂面经,嵌入式知识点总结,笔试题目,简历模版等)和2000G学习资料。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号