
Redis之AOF重写及其实现原理
AOF 重写
- AOF 持久化是通过保存被执行的写命令来记录数据库状态的,所以AOF文件的大小随着时间的流逝一定会越来越大;影响包括但不限于:对于Redis服务器,计算机的存储压力;AOF还原出数据库状态的时间增加;
- 为了解决AOF文件体积膨胀的问题,Redis提供了AOF重写功能:Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个文件所保存的数据库状态是相同的,但是新的AOF文件不会包含任何浪费空间的冗余命令,通常体积会较旧AOF文件小很多。
AOF 文件重写的实现
- AOF重写并不需要对原有AOF文件进行任何的读取,写入,分析等操作,这个功能是通过读取服务器当前的数据库状态来实现的。
- # 假设服务器对键list执行了以下命令s;
- 127.0.0.1:6379> RPUSH list "A" "B"
- (integer) 2
- 127.0.0.1:6379> RPUSH list "C"
- (integer) 3
- 127.0.0.1:6379> RPUSH list "D" "E"
- (integer) 5
- 127.0.0.1:6379> LPOP list
- "A"
- 127.0.0.1:6379> LPOP list
- "B"
- 127.0.0.1:6379> RPUSH list "F" "G"
- (integer) 5
- 127.0.0.1:6379> LRANGE list 0 -1
- 1) "C"
- 2) "D"
- 3) "E"
- 4) "F"
- 5) "G"
- 127.0.0.1:6379>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 当前列表键list在数据库中的值就为
["C", "D", "E", "F", "G"]。要使用尽量少的命令来记录list键的状态,最简单的方式不是去读取和分析现有AOF文件的内容,,而是直接读取list键在数据库中的当前值,然后用一条RPUSH list "C" "D" "E" "F" "G"代替前面的6条命令。
AOF重写功能的实现原理
- 首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录该键值对的多个命令;
- 伪代码表示如下;
- def AOF_REWRITE(tmp_tile_name):
-
- f = create(tmp_tile_name)
-
- # 遍历所有数据库
- for db in redisServer.db:
-
- # 如果数据库为空,那么跳过这个数据库
- if db.is_empty(): continue
-
- # 写入 SELECT 命令,用于切换数据库
- f.write_command("SELECT " + db.number)
-
- # 遍历所有键
- for key in db:
-
- # 如果键带有过期时间,并且已经过期,那么跳过这个键
- if key.have_expire_time() and key.is_expired(): continue
-
- if key.type == String:
-
- # 用 SET key value 命令来保存字符串键
-
- value = get_value_from_string(key)
-
- f.write_command("SET " + key + value)
-
- elif key.type == List:
-
- # 用 RPUSH key item1 item2 ... itemN 命令来保存列表键
-
- item1, item2, ..., itemN = get_item_from_list(key)
-
- f.write_command("RPUSH " + key + item1 + item2 + ... + itemN)
-
- elif key.type == Set:
-
- # 用 SADD key member1 member2 ... memberN 命令来保存集合键
-
- member1, member2, ..., memberN = get_member_from_set(key)
-
- f.write_command("SADD " + key + member1 + member2 + ... + memberN)
-
- elif key.type == Hash:
-
- # 用 HMSET key field1 value1 field2 value2 ... fieldN valueN 命令来保存哈希键
-
- field1, value1, field2, value2, ..., fieldN, valueN =\
- get_field_and_value_from_hash(key)
-
- f.write_command("HMSET " + key + field1 + value1 + field2 + value2 +\
- ... + fieldN + valueN)
-
- elif key.type == SortedSet:
-
- # 用 ZADD key score1 member1 score2 member2 ... scoreN memberN
- # 命令来保存有序集键
-
- score1, member1, score2, member2, ..., scoreN, memberN = \
- get_score_and_member_from_sorted_set(key)
-
- f.write_command("ZADD " + key + score1 + member1 + score2 + member2 +\
- ... + scoreN + memberN)
-
- else:
-
- raise_type_error()
-
- # 如果键带有过期时间,那么用 EXPIREAT key time 命令来保存键的过期时间
- if key.have_expire_time():
- f.write_command("EXPIREAT " + key + key.expire_time_in_unix_timestamp())
-
- # 关闭文件
- f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 实际为了避免执行命令时造成客户端输入缓冲区溢出,重写程序在处理
list hash set zset时,会检查键所包含的元素的个数,如果元素的数量超过了redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值,那么重写程序会使用多条命令来记录键的值,而不是单使用一条命令。该常量默认值是64– 即每条命令设置的元素的个数 是最多64个,使用多条命令重写实现集合键中元素数量超过64个的键;
AOF后台重写
aof_rewrite函数可以创建新的AOF文件,但是这个函数会进行大量的写入操作,所以调用这个函数的线程将被长时间的阻塞,因为Redis服务器使用单线程来处理命令请求;所以如果直接是服务器进程调用AOF_REWRITE函数的话,那么重写AOF期间,服务器将无法处理客户端发送来的命令请求;- Redis不希望AOF重写会造成服务器无法处理请求,所以Redis决定将AOF重写程序放到子进程(后台)里执行。这样处理的最大好处是:
- 子进程进行AOF重写期间,主进程可以继续处理命令请求;
- 子进程带有主进程的数据副本,使用子进程而不是线程,可以避免在锁的情况下,保证数据的安全性。
使用子进程进行AOF重写的问题
- 子进程在进行AOF重写期间,服务器进程还要继续处理命令请求,而新的命令可能对现有的数据进行修改,这会让当前数据库的数据和重写后的AOF文件中的数据不一致。
如何修正
- 为了解决这种数据不一致的问题,Redis增加了一个AOF重写缓存,这个缓存在fork出子进程之后开始启用,Redis服务器主进程在执行完写命令之后,会同时将这个写命令追加到AOF缓冲区和AOF重写缓冲区
- 即子进程在执行AOF重写时,主进程需要执行以下三个工作:
- 执行client发来的命令请求;
- 将写命令追加到现有的AOF文件中;
- 将写命令追加到AOF重写缓存中。
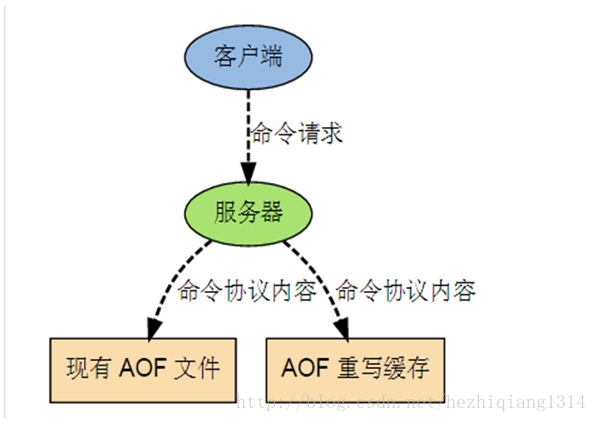
效果
- 可以保证:
- AOF缓冲区的内容会定期被写入和同步到AOF文件中,对现有的AOF文件的处理工作会正常进行
- 从创建子进程开始,服务器执行的所有写操作都会被记录到AOF重写缓冲区中;
完成AOF重写之后
-
当子进程完成对AOF文件重写之后,它会向父进程发送一个完成信号,父进程接到该完成信号之后,会调用一个信号处理函数,该函数完成以下工作:
- 将AOF重写缓存中的内容全部写入到新的AOF文件中;这个时候新的AOF文件所保存的数据库状态和服务器当前的数据库状态一致;
- 对新的AOF文件进行改名,原子的覆盖原有的AOF文件;完成新旧两个AOF文件的替换。
-
当这个信号处理函数执行完毕之后,主进程就可以继续像往常一样接收命令请求了。在整个AOF后台重写过程中,只有最后的“主进程写入命令到AOF缓存”和“对新的AOF文件进行改名,覆盖原有的AOF文件。”这两个步骤(信号处理函数执行期间)会造成主进程阻塞,在其他时候,AOF后台重写都不会对主进程造成阻塞,这将AOF重写对性能造成的影响降到最低。
以上,即AOF后台重写,也就是BGREWRITEAOF命令的工作原理。
触发AOF后台重写的条件
- AOF重写可以由用户通过调用
BGREWRITEAOF手动触发。 -
服务器在AOF功能开启的情况下,会维持以下三个变量:
- 记录当前AOF文件大小的变量
aof_current_size。 - 记录最后一次AOF重写之后,AOF文件大小的变量
aof_rewrite_base_size。 - 增长百分比变量
aof_rewrite_perc。
- 记录当前AOF文件大小的变量
-
每次当
serverCron(服务器周期性操作函数)函数执行时,它会检查以下条件是否全部满足,如果全部满足的话,就触发自动的AOF重写操作:- 没有BGSAVE命令(RDB持久化)/AOF持久化在执行;
- 没有BGREWRITEAOF在进行;
- 当前AOF文件大小要大于
server.aof_rewrite_min_size(默认为1MB),或者在redis.conf配置了auto-aof-rewrite-min-size大小; - 当前AOF文件大小和最后一次重写后的大小之间的比率等于或者等于指定的增长百分比(在配置文件设置了
auto-aof-rewrite-percentage参数,不设置默认为100%)
如果前面三个条件都满足,并且当前AOF文件大小比最后一次AOF重写时的大小要大于指定的百分比,那么触发自动AOF重写。
总结
- AOF重写的目的是为了解决AOF文件体积膨胀的问题,使用更小的体积来保存数据库状态,整个重写过程基本上不影响Redis主进程处理命令请求;
- AOF重写其实是一个有歧义的名字,实际上重写工作是针对数据库的当前状态来进行的,重写过程中不会读写、也不适用原来的AOF文件;
- AOF可以由用户手动触发,也可以由服务器自动触发。
转自:https://blog.csdn.net/hezhiqiang1314/article/details/69396887

 浙公网安备 33010602011771号
浙公网安备 33010602011771号