RocketMq的角色组成由 nameserver 、broker、producer、consumer ,当然这些角色都可以以集群的方式存在,因为RocketMQ是站在巨人的肩膀上(kafka)MetaQ的内核,又对其进行了优化让其更满足互联网公司的特点。它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。 RocketMQ目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。下面我们分别来介绍一下这些角色组成。
1、nameserver
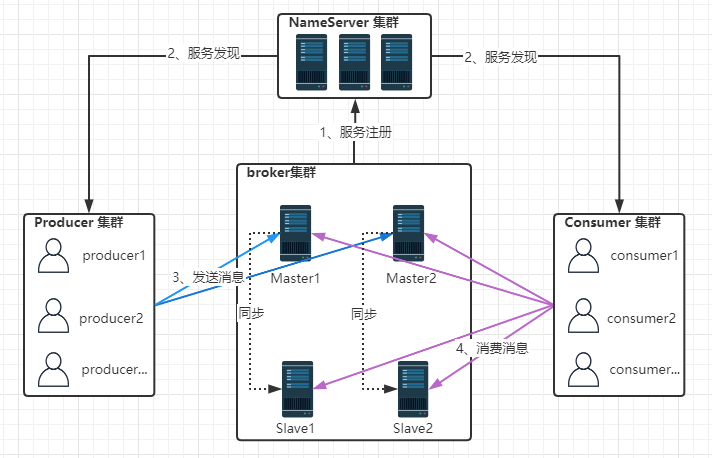
nameserver的底层是由netty实现:提供路由管理、服务注册、服务发现的功能,是一个无状态的节点。
nameserver作为服务的发现者:集群中的各个角色(producer、broker、consumer)都要定时的向nameserver上报自己的状态,以便互相发现彼此,超时不上报会从列表中剔除。
nameserver可以集群化部署:当有多个nameserver存在时,其他角色会同时向他们上报信息,这样可以保证nameserver的高可用性,他们之间互不通信,没有主从的关系。
nameserver是内存式存储:nameserver中的broker、topic默认不会持久化。
有人会说为什么不使用zookeeper?-----------:rocketmq主要是在分布式情况下使用追求性能,因为zookeeper最求最终一致性,所以在性能上会有所折扣。
总结:
NameServer是一个非常简单的Topic路由注册中心,其角色类似Dubbo中的zookeeper,支持Broker的动态注册与发现。主要包括两个功能
Broker管理,NameServer接受Broker集群的注册信息并且保存下来作为路由信息的基本数据。然后提供心跳检测机制,检查Broker是否还存活; 路由信息管理,每个NameServer将保存关于Broker集群的整个路由信息和用于客户端查询的队列信息。然后Producer和Conumser通过NameServer就可以知道整个Broker集群的路由信息,从而进行消息的投递和消费 NameServer通常也是集群的方式部署,各实例间相互不进行信息通讯。Broker是向每一台NameServer注册自己的路由信息,所以每一个NameServer实例上面都保存一份完整的路由信息。当某个NameServer因某种原因下线了,Broker仍然可以向其它NameServer同步其路由信息,Producer,Consumer仍然可以动态感知Broker的路由的信息
NameServer实例时间互不通信,这本身也是其设计亮点之一,即允许不同NameServer之间数据不同步(像Zookeeper那样保证各节点数据强一致性会带来额外的性能消耗)
2、broker
broker面向producer(发送消息)、consumer(接受消息),broker需要向nameserver提交自己的信息,是消息中间件的消息存储器和消息转发器。每个broker在启动的时候都会遍历nameserver的列表,与每一个nameserver建立连接,注册自己的信息,之后定时向每一个nameserver上报。
当然broker也可以集群化,broker的高可用模式下存在主从的关系,Master可读可写,Slave只可读,Master会将写入的数据同步给Slave。Master多机负载,可以部署多个broker,每个broker与nameserver集群中的所有节点建立长连接,定时注册topic信息到nameserver。
3、producer
producer是消息的生产者,通过集群中的任意一个(nameserver)节点(随机选择)建立长连接,获取topic的路由信息【包括Topic下有那些queue,这些queue分布在哪些broker上等等】。接下来向提供topic服务的master(broker)建立长连接,且定时发心跳。
4、consumer
消息的消费者,通过NameServer集群获得Topic的路由信息,连接到对应的Broker上消费消息。【注意】,由于Master和Slave都可以读取消息,因此Consumer会与Master和Slave都建立连接。





