

Atomic类和线程同步新机制
一、为什么要使用Atomic类?
看一下下面这个小程序,模拟计数,创建10个线程,共同访问这个int count = 0 ;每个线程给count往上加10000,这个时候你需要加锁,如果不加锁会出现线程安全问题,但是使用AtomicInteger之后就不用再做加锁的操作了,因为AtomicInteger内部使用了CAS操作,直接无锁往上递增,有人会问问什么会出现无锁操作,答案只有一个:那就是快呗;
下面是AtomicInteger的使用方法:
package com.example.demo.threaddemo.juc_008; import java.util.ArrayList; import java.util.List; import java.util.concurrent.atomic.AtomicInteger; /** * @author D-L * @Classname T01_AtomicInteger * @Version 1.0 * @Description 使用AtomicInteger类代替synchronized * @Date 2020/7/22 */ public class T01_AtomicInteger { // int count = 0; AtomicInteger count = new AtomicInteger(0); public /**synchronized*/ void m(){ for (int i = 0; i < 10000; i++) { // count++; count.incrementAndGet(); } } public static void main(String[] args) { T01_AtomicInteger t = new T01_AtomicInteger(); List<Thread> threads = new ArrayList<>(); for (int i = 0; i < 10; i++) { threads.add(new Thread(t::m ,"Thread" + i)); } threads.forEach(o -> o.start()); threads.forEach(o ->{ try { o.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); /* for (int i = 0; i < 10; i++) { new Thread(t::m ,"Thread"+i).start(); } try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }*/ System.out.println(t.count); } }
二、Atomic类,synchronized、LongAdder的效率验证 及 分析
模拟多个线程对一个数进行递增,多线程对一个共享变量进行递增的方法大概有三种;验证一下它们的效率,这里做一些粗糙的测试,基本已经能说明问题,具体情况还要根据实际情况:
- 第一种:使用long count = 0; 加锁来实现;
- 第二种:使用AtomicLong类来实现;
- 第三种:使用LongAdder实现;
package com.example.demo.threaddemo.juc_008; import java.util.concurrent.atomic.AtomicLong; import java.util.concurrent.atomic.LongAdder; /** * @author D-L * @Classname T02_AtomicVsSyncVsLongAdder * @Version 1.0 * @Description 测试Atomic类 synchronized LongAdder效率 * @Date 2020/7/22 */ public class T02_AtomicVsSyncVsLongAdder { static AtomicLong count1 = new AtomicLong(0L); static Long count2 = 0L; static LongAdder count3 = new LongAdder(); public static void main(String[] args) throws InterruptedException { Thread [] threads = new Thread[1000]; /*-----------------------------------Atomic类-----------------------------------*/ for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(() ->{ for (int j = 0; j < 100000; j++) { count1.incrementAndGet(); } }); } long start = System.currentTimeMillis(); for (Thread t : threads) t.start(); for (Thread t : threads) t.join(); long end = System.currentTimeMillis(); System.out.println("Atomic:" + count1.get() +"-----time:" +(end - start)); /*----------------------------------synchronized---------------------------------*/ Object lock = new Object(); for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int j = 0; j < 100000; j++) { synchronized (lock) { count2++; } } } }); } long start2 = System.currentTimeMillis(); for (Thread t : threads) t.start(); for (Thread t : threads) t.join(); long end2 = System.currentTimeMillis(); System.out.println("synchronized:" + count1.get() +"-----time:" +(end2 - start2)); /*-------------------------------------LongAdder----------------------------------*/ for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(() ->{ for (int j = 0; j < 100000; j++) { count3.increment(); } }); } long start3 = System.currentTimeMillis(); for (Thread t : threads) t.start(); for (Thread t : threads) t.join(); long end3 = System.currentTimeMillis(); System.out.println("LongAdder:" + count1.get() +"-----time:" +(end3 - start3)); } }
/*----------------------------------运行结果---------------------------------*/
Atomic:100000000-----time:2096
synchronized:100000000-----time:5765
LongAdder:100000000-----time:515
从以上的结果来看并发量达到一定程度运行效率:LongAdder > AtomicLong > synchronized; 这个还只是一个粗略的测试,具体使用还要根据实际情况。
- 为什么AtomicLong的效率比synchronized的效率高?
AtomicLong的底层使用的是CAS操作(无锁优化),而synchronized虽然底层做了优化但是并发量达到一定层度,存在锁的膨胀,最终会变成重量级锁,需要向操作系统申请锁资源,所以synchronized的效率慢一点合情合理。
- 为什么LongAdder的效率比AtomicLong的效率高?
因为LongAdder使用了分段锁的概念,效率比AtomicLong的效率高。
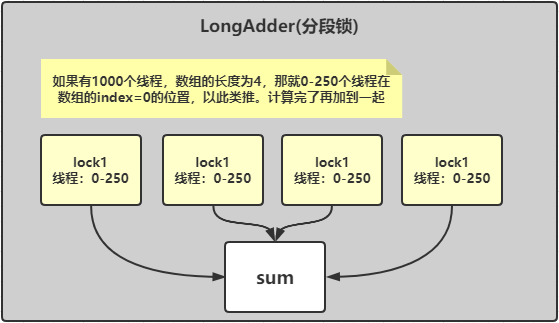
分段锁的意思就是用一个数组把线程分成若干组,然后运行结束后把结果累加起来,例如你有1000个线程,数组的长度为4,那就把0-250个放到数组的第0位,以此类推,然后把四个数组中线程的计算结果累加,这样会很大程度上节省时间,从而提高效率。

