

接口实战项目总结上
1. 前程贷业务分析
1.1 平台介绍
前程贷是一个网贷信息服务平台,p2p模式,主要业务流程:借款人发布借款项目,经管理员审核,进入竞标状态后,投资人选择可投资项目进行投资。用户可以同时为借款人和投资人。
用户模块:注册、登录、充值、提现、更新昵称、投资、用户信息,共7个接口
项目模块:新增项目、审核项目、分页获取项目列表,共3个接口
实现5个接口的自动化测试:注册、登录、充值、新增项目、投资
1.2 数据库
数据流记录,5张表
会员表member,保存平台会员数据。用户名、密码(加密)、手机号、用户类型、可用余额、注册时间
项目表loan,保存平台项目数据。借款人id,标题,借款金额,年利率,借款期限、借款期限类型、竞标天数、创建时间、竞标开始时间、结束时间、项目状态
投资表invest,保存平台投资记录数据,用户投资后就会在表.;里新增一条投资数据。投资人id、标id、投资金额、创建时间、是否有效55
回款计划表repayment,满标后,每份投资会生成一条或多条回款计划记录。
平台会员资金流水记录表,只要会员可用余额有变动,就会在这个表新增一条记录。
1.3 接口信息
-
接口地址、请求方法、请求头、请求参数
-
响应体、接口鉴权等
小结:需求分析中,理解业务逻辑,以及数据流在数据库中的映射关系,明确每个接口的信息,包括地址、请求方法、类型、请求参数等
2. 测试用例编写
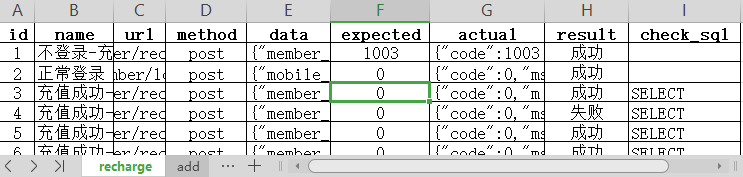
excel编写,一个表单代表一个测试模块,用例内容包括:用例编号、名称、接口地址、请求方法、请求参数(json格式)、预期结果、实际结果、是否通过
测试用例的设计方法:等价类划分、边界值分析、错误推测法(全角字符串、超长混合字符串、数字0、单引号)
总共写了100多条测试用例。
3. 冒烟测试
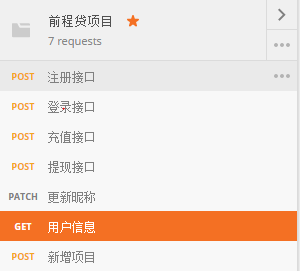
使用postman对程序的主要功能进行验证。
4.分层设计理念+数据驱动思想搭建测试框架
- 结构清晰:测试用例层(业务层)、配置文件层、数据层、日志层、报告层、脚本层
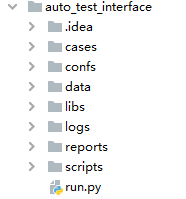
- 减少代码冗余:数据驱动思想,测试数据与用例执行逻辑分离,一个测试用例脚本可以对数据进行批量处理
python + unittest + ddt + requests
import unittest
@ddt.ddt # 装饰器,该类范围内会自动创建多个实例方法
class TestRegister(unittest.TestCase): # 新建一个测试类,并继承unittest.TestCase父类
@classmethod
def setUpClass(cls): # 初始化所有用例的公共操作,创建请求对象,构造请求参数等
pass
@classmethod
def tearDownClass(cls): # 用于所有用例的公共资源释放,例如关闭接口请求会话对象
pass
@ddt.data(*testdatas) # 对序列类型拆包,参数传递
def test_register(self, testcase): # 测试用例:访问接口、传参、获取响应值、断言操作
pass
if __name__ == '__main__':
unittest.main() # 依据ACSICC值的顺序执行
# 调整执行顺序TestSuit套件,调用addTest方法,TextTestRunner执行套件
5. 接口自动化测试框架的技术点
请求处理、excel用例读取、配置信息的处理、日志记录处理、参数化&正则表达式、数据校验pymysql、接口依赖处理、unittest单元测试框架、ddt数据驱动、Jenkins单元持续集成等
6.封装—requests接口请求
import json
import requests
class HttpRequest:
def __init__(self):
# 创建会话对象,自动化维护cookie信息
self.session = requests.Session()
# 发起请求
def send(self, method, url, **kwargs): # 关键字参数包括headers、json、cookies等
method = method.upper() # 请求方法大写
kwargs["json"] = self.handle_param("json", kwargs)
kwargs["data"] = self.handle_param("data", kwargs)
return self.session.request(method, url, **kwargs)
# 请求参数处理
@staticmethod
def handle_param(param_name, param_dict):
# 不管输入的是json格式的字符串,还是字典字符串,或者是字典,都能转为字典输出
if param_name in param_dict:
data = param_dict.get(param_name)
if isinstance(data, str):
try:
data = json.loads(data) # 将json字符串(python中格式为‘{}’)转换成字典
except Exception:
data = eval(data) # 直接将字符串最外层的引号拿掉,字典形式
return data
# 添加请求头,公共请求头更新
def add_headers(self, one_dict): # 请求头参数,字典类型
self.session.headers.update(one_dict)
# 关闭会话,释放资源
def close(self):
self.session.close()
7. 封装—excel数据读写
import os
from openpyxl import load_workbook
class Testcase: # 通过创建不同的对象保存每一条测试用例,用例数据通过创建实例属性来保存,具有全局通用的作用
pass
class HandleExcel:
def __init__(self, filename, sheetname=None):
self.filename = os.path.join(DATA_PATH, filename)
self.sheetname = sheetname
def read_data(self):
wb = load_workbook(self.filename) # 加载excel文件
if self.sheetname == None:
ws = wb.active # 默认读取第一个表单
else:
ws = wb[self.sheetname] # 获取指定表单对象
testcases_list = [] # 存放数据
headers_list = [] # 存放表头信息
for row in range(1, ws.max_row + 1):
one_testcase = Testcase() # 创建对象,通过动态创建实例属性的方法存放每一行用例
for column in range(1, ws.max_column + 1):
one_cell = ws.cell(row, column) # 创建单元格对象
one_cell_value = one_cell.value
if row == 1:
headers_list.append(one_cell_value)
else:
key = headers_list[column - 1]
setattr(one_testcase, str(key), one_cell_value) # 设置当前用例所对应的表头属性
if key == "actual":
setattr(one_testcase, "actual_column", column) # 设置存放实际响应报文所在列的列号属性
elif key == "result":
setattr(one_testcase, "result_column", column) # 设置存放用例执行结果所在列的列号属性
if row != 1:
setattr(one_testcase, "row", row) # 设置当前用例所在的行号属性
testcases_list.append(one_testcase)
return testcases_list # 列表的元素是对象
def write_data(self, one_testcase, actual_value, result_value):
wb = load_workbook(self.filename) # 加载指定excel文件
if self.sheetname == None:
ws = wb.active
else:
ws = wb[self.sheetname] # 访问表单
ws.cell(one_testcase.row, one_testcase.actual_column, value=actual_value) # 访问指定单元格并写入数据
ws.cell(one_testcase.row, one_testcase.result_column, value=result_value) # 写入状态时,一定要将excel文件关闭
wb.save(self.filename) # 对excel文件修改后,一定要保存
8. 封装—数据库处理
import random
import pymysql
from scripts.handle_yaml import do_yaml
class HandleMysql:
def __init__(self):
# 1.创建连接对象
self.conn = pymysql.connect(host=do_yaml.get_data('mysql', 'host'),
user=do_yaml.get_data('mysql', 'user'),
password=do_yaml.get_data('mysql', 'password'),
port=do_yaml.get_data('mysql', 'port'),
database=do_yaml.get_data('mysql', 'database'),
charset="utf8", # 注意这里不能写成utf-8
cursorclass=pymysql.cursors.DictCursor)
self.cursor = self.conn.cursor() # 2.创建游标对象
# 3.获取一条数据,字典类型
def get_one_value(self, sql, args=None):
self.cursor.execute(sql, args=args)
self.conn.commit()
return self.cursor.fetchone()
# 4.获取多条数据,嵌套字典的列表类型
def get_values(self, sql, args=None):
self.cursor.execute(sql, args=args)
self.conn.commit()
return self.cursor.fetchall()
# 5.关闭游标,再关闭连接
def close(self):
self.cursor.close()
self.conn.close()
@staticmethod
def generate_telephone():
"""
随机生成手机号
手机号规则:前3位—网络识别号;第4-7位—地区编码;第8-11位—用户号码
第1位:1;
第2位:3,4,5,7,8
第3位:3:【0,9】, 4:【5,7】, 5:【0,9】, 7:【6,7,8】, 8:【0-9】
:return:返回一个手机号码
"""
# 前三位
second = random.choice([3, 4, 5, 7, 8])
third = str({
3: random.randint(0, 9),
4: random.choice([5, 7]),
5: random.randint(0, 9),
7: random.choice([6, 7, 8]),
8: random.randint(0, 9)
}[second])
# 后八位
eight = ''.join(random.sample('0123456789', 8))
return '1' + str(second) + third + eight
# 在数据库中查询随机生成的手机号是否存在
def check_telephone(self, telephone):
sql = do_yaml.get_data('mysql', 'select_user_sql')
if self.get_one_value(sql, args=[telephone]):
return True
else:
return False
# 得到一个在数据库中不存在的手机号
def get_new_telephone(self):
while True:
one_mobile = self.generate_telephone()
if not self.check_telephone(one_mobile):
break
return one_mobile
def get_not_existed_user_id(self):
# 从yaml配置文件中获取查询最大用户id的sql语句
sql = do_yaml.get_data('mysql', 'select_max_user_id_sql')
# # 获取最大的用户id + 1
not_existed_id = self.get_one_value(sql).get('max(id)') + 1
return not_existed_id
def get_not_existed_loan_id(self):
sql = do_yaml.get_data('mysql', 'select_max_loan_id_sql')
# # 获取最大的用户id + 1
not_existed_id = self.get_one_value(sql).get('max(id)') + 1
return not_existed_id

