
海量数据和高并发解决方案
ps :读书笔记
海量数据解决方案
缓存和页面静态化
缓存就是把从数据库中的数据暂时存起来,下次使用时无需在查询数据库。缓存分为程序直接保存到内存和框架框架2种。程序缓存一般使用currentHashMap直接保存到内存。框架缓存的话有redis,memcache等。
ps:空数据值问题。
缓存创建的时候把没有数据的缓存用特定的符号来表示。因为这种模式下如果从缓存中获取不到数据,就会查询数据库,但是其本身就没有数据的话。那么每次都要查询一次数据库,不合理。
页面静态化:是将程序生成的页面保存起来。这样下次调用直接就使用。连程序这一关也过了。更加快速。可以在程序中使用velocity等技术来生成静态页面,也可以通过上层缓存Nginx来生成。
数据库优化
1.表结构优化:设计合理的符合规范的表。
2.sql优化:根据日志以及其他工具分析那条sql语句最耗时,在针对性的有的放矢的优化,要统筹好,不能只针对一条语句,优化时要考虑到表上的其他语句综合考虑。
3.分区:一个表中数据量太大时,那么分区就可以使用了。分区是将数据按照一定规则把数据分到不同区来保存,这样子操作数据时,数据量更少。查询数据时只在一定区间进行。且这种操作时对程序透明的。程序无需修改。
4.分表:分表就是把表横向切分为几个表。第一种方式就是为了减少数据,比如一张表里面某个字段是分类。可以更具这个分类来分为多个表。以此来减少每个表的数据量。第二种方式是由于某个表某些字段经常被查,但是不修改,某些字段需要进场修改,那么分表是个不错的选择,因为对于mysql之类的表来说,增删改操作时要加锁的,无论是什么隔离级别。,这样子加锁范围就减少了。对于mysql来说不是问题,但是对于其他数据库来说就不知道了。对于mysql来说可以照样读取数据,对于某些数据库或者se隔离级别的mysql,这条记录也是不可读的。需要等待数据库释放这条记录的锁。
5.索引优化:对于mysql的innodb来说,我上篇博客已经说过了。这里简单说下,最左匹配原则,综合所有查询语句,找出,最佳的索引创建原则和最佳的查询语句,比如,你有联合索引(a,b,c)。你的查询语句为b=1 and c=1 那么要么调整查询语句让其条件多个a=?要么联合索引(a,b,c)调整为(b,c,a)。其次对于mysql来说。一条语句有且只用一个表有且只用一条索引。至于多表查询时连表的语句也会加入到索引里面。
6.存储过程:对于复杂的sql来说来说,直接使用存储过程来调用,可以有效提高效率。
活跃数据分离
一个数据量很大的表,只有一小部分数据是活跃数据,经常被查询,更多的数据则是惰性数据,偶尔被调用一下。那么我们可以用2个表来保存,第一个表是活跃数据保存,第二个表是惰性数据保存。这样子可以有效提高效率。至于是否活跃数据,怎么分配就要看自己方业务逻辑怎么实现的了。
批量读取和延迟修改
1.批量读取:故名思议,把一堆查询结合成一条查询,比如。有的业务是要查询一次做个操作,那么可以把这些查询放在一个in()语句里面。又或者高并发下,把几秒的异步请求统一查询处理。
2.延迟修改:就是把一些频繁修改的数据放到一个缓存里面去,然后定时把缓存的数据刷到数据库里面,这个缓存和普通缓存不一样,这个缓存的数据库不是完整的。程序查询时同时读取数据库和缓存的数据,综合读取之。
读写分离
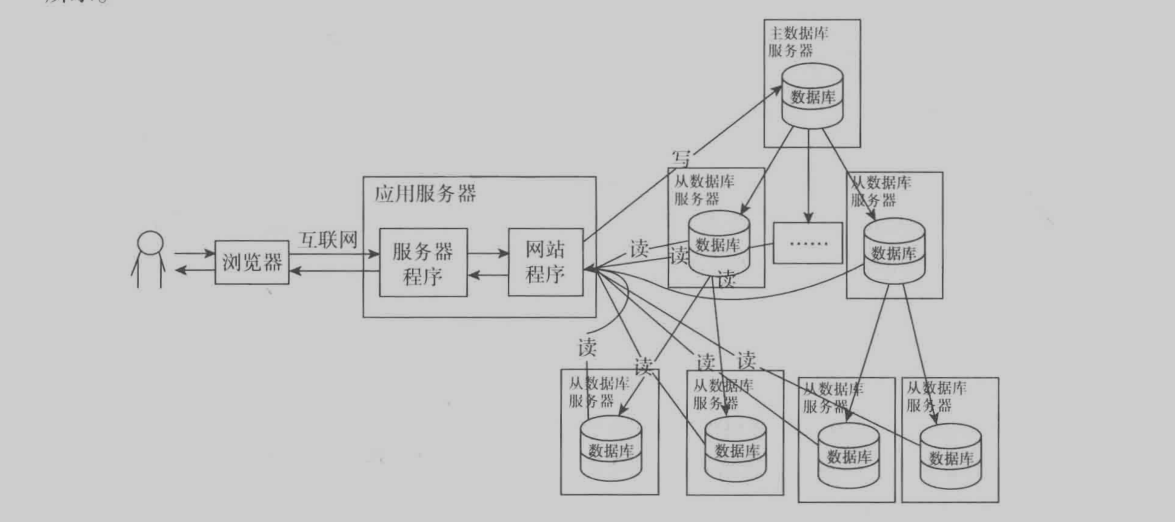
先上一张图,这个图是书里面的,说起来很简单就是把读取数据和增删改数据分离到不同数据库里面。增删改放到主数据库里面,读取数据则是放到从数据库里面。主数据的数据通过底层同步到从数据库里面。
分布式数据库
分布式数据库是将不同的表放到不同的数据库里面,然后再放到不同的服务器里面,这样子查询时可以使用多台服务器来运行,可以有效提高效率,主要用于超复杂耗时的查询。这个可以和读写分离一起使用,搭配使用。另一种情况是不同业务的表放在不同数据库里面,可以起到分流的作用
NoSql和Hadoop
NoSql和sql比起来就是非结构化的,就是没有定义好的字段,类型啊之类的,但是NOsql是通过多个块存储数据,因此效率速度很快,被广泛应用于大数据
Hadoop:Hadoop是针对大数据处理的一套框架。
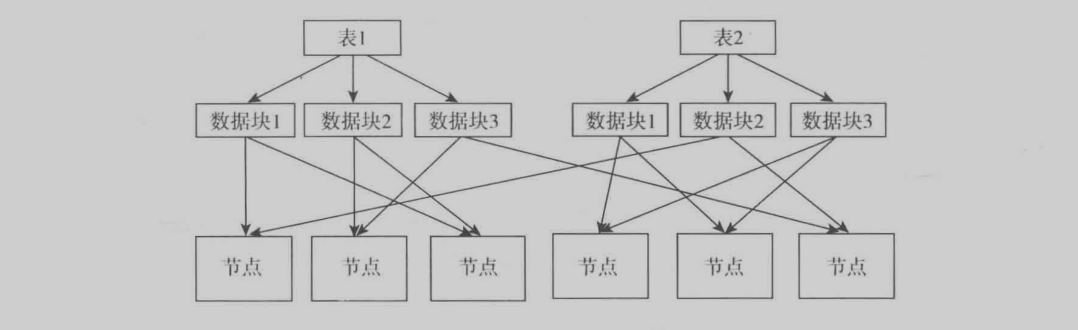
这个是Hadoop存储图,就是把表的数据块分为多个节点保存。这样子可以并发处理并且可以保存数据的稳定性。Hadoop是对每一个数据块找到的节点并处理,然后在统一处理,得到最终结果(这块不熟)
高并发处理方案
静态资源分离
就是将图片,视频,css,等文件保存到另外一个服务器中,使用2级域名,通过不同域名,可以让浏览器迅速获取到资源而不用访问应用服务器。
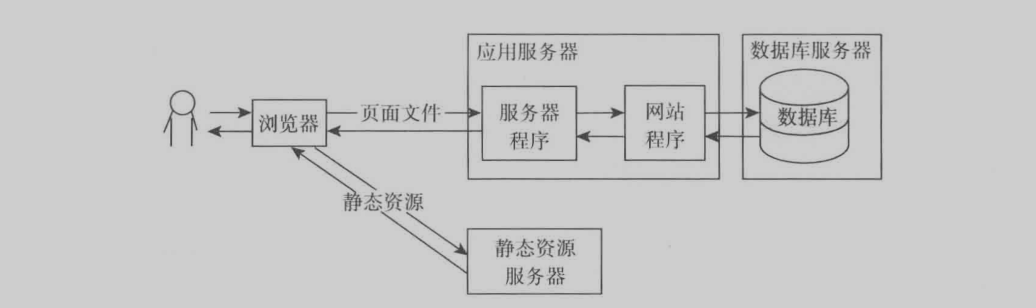
页面缓存
就是将程序生成的页面缓存保存下来,下次访问时就不用再用cpu来生成数据了。浪费其资源。可以使用Nginx服务器自带的缓存机制,也可以使用专门的squid来处理。(ps:对于一些页面某些数据经常变化,但是整体不变,那么我们可以使用ajax来请求重新获取数据来更新界面)
集群和分布式
集群就是相同的程序放到多个服务器里面,主要起到分流的作用。分布式就是更具业务逻辑将程序拆分到不同服务器上。这2个可以一起使用。(至于集群导致的session和token问题,下一章会有篇关于session和token)。不用业务之间的联系可以通过RPC来处理,我们这边业务较为复杂,将大量的程序拆分成一个个的微服务。每个微服务之间通过dubbo来传递消息。
反向代理
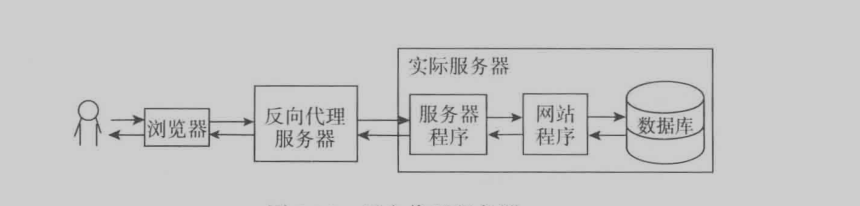
反向代理:就是客户端访问的服务器不直接提供资源,该服务器从别的服务器获取资源并返回给用户主要由3个作用
1.可以负载均衡
2.可以转发请求
3.可以作为前端服务器和实际请求服务器集成。
ps:反向代理和代理服务器不一样。反向代理是用户不知道这个事,一切都是透明的。代理服务器则是用于代替用户获取资源在返回给用户,需要用户手动设置。
CDN
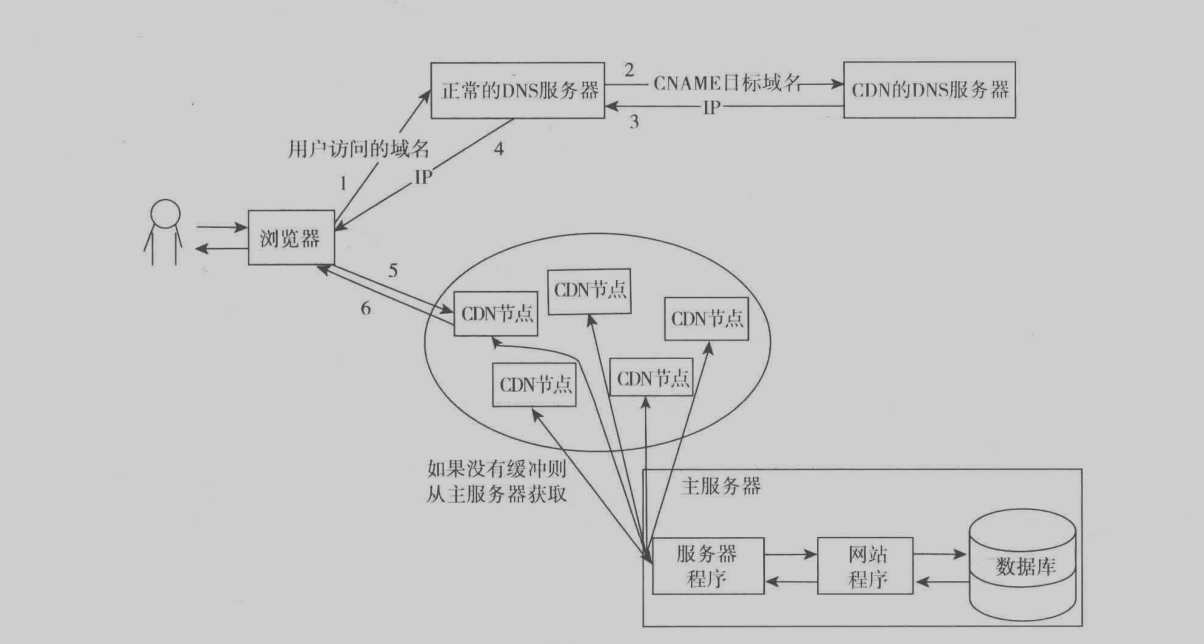
CDN是个特殊的页面缓存服务器,和普通的服务器相比,CDN服务器遍布全国各地,当接受到用户请求时,会将其分配到对应的最合适节点,根据地域等信息来分配,如图所示为其中一个实现方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号