

---恢复内容开始---
c++ primer plus 第6版 部分二 5- 章
第五章
计算机除了存储外 还可以对数据进行分析、合并、重组、抽取、修改、推断、合成、以及其他操作
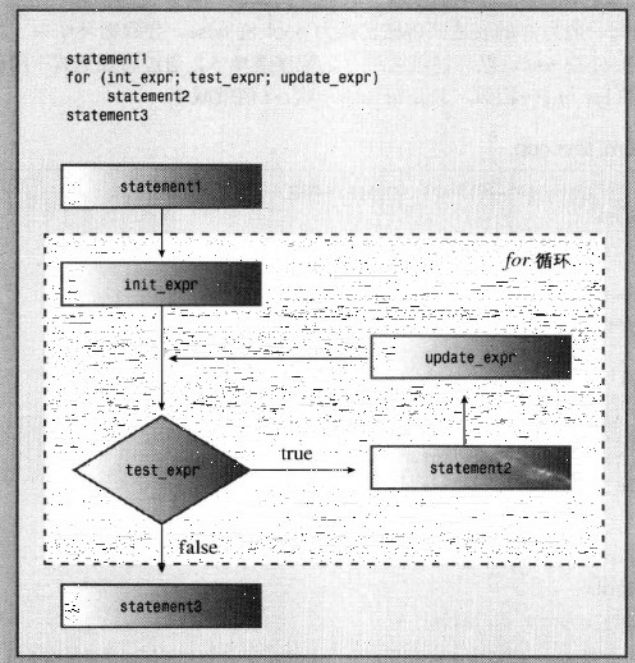
1.for循环的组成部分
a 设置初始值
b 执行测试,看循环时候应当继续进行
c 执行循环操作
d 更新用于测试的值
只要测试表达式为true 循环体就会执行
for (initialization; test-expression; update-expression)
body
test-expression决定循环体是否被执行,通常这个表达式是关系表达式,c++会将此结果强制转换为bool类型。值0的表达式将被转换为bool值false,导致循环结束。
for 后面跟着一对括号 它是一个c++关键字 因此编译器不会将for视为一个函数
1. 表达式和语句
任何值或任何有效的值和运算符的组合都是表达式。c++中每个表达式都有值。通常值是很明显的。
c++将赋值表达式的值定义为左侧成员的值,因此这个表达式的值为20.由于赋值表达式有值,可以编写
maids=(cooks=4)+3; 值为7
赋值表达式从右向左结合
x<y 这样的关系表达式被判定为true或者false
int x;
cout<<(x=100)<<endl; //x=100
cout<<(x<3)<<endl; //0
cout<<(x>3)<<endl; //1
cout.setf(ios_base::boolalpha);//老式的c++实现使用ios:boolalpha 来作为setf()的参数
cout<<(x<3)<<endl; //false
cout在现实bool值之前将他们转换为int 但是cout.setf(ios::boolalpha) 函数调用设置了一个标记,该标记命令cout显示true和false 而不是1和0;
判定表达式的值 改变了内存中数据的值时,表达式有副作用 side effect。
例如x++ 判定赋值表达式 改变了x的值 所以有副作用
有例如x+100 判定赋值表达式 计算出一个新值 未改变x的值 所以没有副作用
表达式到语句的转换非常容易 只需要加上分号即可。
2.非表达式和语句
返回语句 声明语句 和for语句都不满足“语句=表达式+分号”这种模式
int a; 这是一条语句 但是int a并不是表达式 因为它没有值
所以这些代码是非法的:
eggs=int a *1000;
cin>>int a;
不能把for循环赋值给变量
3.修改规则
c++ 在c循环的基础上添加了一些特性 可以对for循环句法做一些调整
for(expression;expression;expression)
statement;
示例:
for(int i=0;i<5;i++) int i=0 叫做生命语句表达式 (不带分号的声明) 此种只能出现在for语句中
其中 int i=0 为声明 不是表达式 这由于上面的语法向矛盾
所以这种调整已经被取消
修改之后的语法:
for (for-init-statement condition;expression)
statement
感觉奇怪,这里只用了一个分号,但是这是允许的因为for-init=statement被视为一条语句,而语句有自己的分号。对于for-init-statement来说,它既可以是表达式语句,也可以是声明。
语句本身有自己的分号,这种句法规则用语句替换了后面跟分号的表达式。在for循环初始化部分中声明和初始化变量。
在for-init-statement中声明变量还有其实用的一面。这种变量只存在于for语句中,当程序离开循环后,这种变量将消失。
for(int i=0;i<5;i++)
较老的c++实现遵循以前的规则,对于前面的循环,将把i视为在循环之前声明 所以在循环结束后,i变量仍然存在。
4.回到for循环
const int arsize=16;// 定义整型的常量 在下方程序中使用 数组长度的定义
for(int i=2;i<arsize;i++) //i<arsize 下标从0到arsize-1 所以数组索引应该在arsize-1的位置停止。也可以使用i<=arsize-1 但是没有前面的表达式好。
5.修改步长
之前的循环计数都是加1或者减1 可以通过修改更新表达式来修改步长。i=i+by
int by;
cin>>by;
for(int i=0;i<100;i=i+by)
注意检测不等号通常要比检测相等要好。上例中如果将i<100改为i==100 则不可行 因为i的取值不会为100
using声明和using编译指令的区别。
6.使用for循环访问字符串
示例:
#include <iostream>
#include <string>
int main(){
using namespace std;
cout<<"enter a word"<<endl;
string word; //定义对象
cin>>word;
for(int i=word.size()-1;i>=0;i--) //word对象的字符串长度 size成员函数
cout<<word[i]; //输出各个字符
cout<<"\n----Bye.\n"<<endl;
return 0;
}
如果所用的实现没有添加新的头文件,则必须使用string.h 而不是cstring
7.递增运算符++ 递减运算符--
都是讲操作数相加或者相减 他们有两种不同的形式 一种为前缀 另一种为后缀 ++x x++
但是他们对操作数的影响的时间是不同的
int a=20 b=20;
cout<<"a++="<<a++<<"++b= "<<++b<<endl;
cout<<"a="<<a<<"b= "<<b<<endl;
a++为使用a的当前值计算表达式 然后将a的值加1 使用后修改
++b是先将b的值加1,然后使用新的值来计算表达式 修改后再使用
8.副作用 和顺序点
side effect 副作用
指的是在计算表达式时对某些东西进行了修改 例如存储在变量中的值
顺序点是程序执行过程中的一个点。c++中 语句中的分号就是一个顺序点 这就意味着程序处理下一条语句之前,赋值运算符、递增运算符和递减运算符执行的所有修改都必须完成。任何完整的表达式末尾都是一个顺序点。
表达式的定义:不是另外一个表达式的子表达式
顺序点有助于阐明后缀递增何时进行
while(guest++<10)
cout<<guests<<endl;
类似于只有测试表达式的for循环。可能会被认为是使用值然后再递增即cout中先使用guests的值 然后再将其值加1。
但是guests++<10 是一个完整的表达式,因为它是while循环的一个测试条件。所以该表达式的末尾是一个顺序点。所以c++确保副作用(将guests+1) 在程序进入cout之前完成,然而使用后缀的格式,可以确保将guests同10进行比较后再将其值加1。
y=(4+x++)+(6+x++);
表达式4+x++不是一个完整的表达式,因此,c++不保证x的值在计算子表达式4+x++后立刻增加1;在这个例子中 红色部分是一个完整的表达式 其中的分号标示了顺序点,因此c++只保证程序执行到下一条语句之前,x的值将被递增两次。c++没有规定是在计算每个子表达式之后将x的值递增,还是在整个表达式计算完毕后才将x的值递增,有鉴于此,应该避免使用这样的表达式。
c++11文档中,不再使用术语“顺序点”了,因为这个概念难以用于讨论多线程执行。相反,使用了术语“顺序”,它表示有些事件在其他事件前发生。这种描述方法并非要改变规则,而旨在更清晰第描述多线程编程。
10.前缀格式和后缀格式
显然,如果变量被用于某些目的(如用作函数参数或给变量赋值),使用前缀格式和后缀格式的结果将是不同的。然而,如果递增表达式的值没有被使用,情况会变得不同例如
x++;
++x;
for(n=lim;n>0;--n)
for(n=lim;n>0;n--)
从逻辑上说,在上述两种情形下,使用前缀格式和后缀格式没有任何区别。表达式的值未被使用,因此只存在副作用。
在上面的例子中使用这些运算符的表达式为完整表达式,因此将x+1和n-1的副作用将在程序进入下一步之前完成,所以前缀与后缀格式的最终效果相同。
前缀与后缀的区别2:它们的执行速度有略微的差别 虽然对程序的行为没有影响
c++允许您针对类定义这些运算符,在这种情况下,用户这样定义前缀函数:将值加1然后返回结果。
后缀版本:首先复制一个副本,将其加1 然后将复制的副本返回
显然前缀的效率要比后缀版本高。
总之,对于内置类型,采用哪种格式不会有差别;但是对于用户定义的类型,如果有用户定义的递增和递减运算符,则前缀格式的效率更高。
11.递增/递减运算符和指针
可以将递增运算符用于指针和基本变量。将递增运算符用于指针时,将把指针的值增加其指向的数据类型占用的字节数,这种规则适用于对指针递增和递减。
double arr[5]={21.1,32.8,23.4,45.2,37.4}
double * pt=arr; //pt points to arr[0],i.e. to 21.1
++pt;//指向arr[1] i.e. to 32.8
也可以结合使用这些运算符来修改指针指向的值。将*和++同时用于指针时提出了这样的问题:
将什么解除引用,将什么递增?
取决于运算符的位置和优先级。
1.前缀递增、后缀递减和解除引用运算符的优先级相同,以从右到左的方式进行结合。
2.后缀递增和后缀递减的优先级相同,但是比前缀运算符的优先级高,这两个运算符以从左到右的方式进行结合。
例如:*++pt的含义 先将++应用于pt 然后再将*应用于递增后的pt pt的指向已经变化
++*pt 先取得pt指向的值,然后再将这个值加1 pt的指向没有变化
(*pt)++ pt指针先解除引用 得到值 然后再加1 原来为32.8 之后的值为32.8+1=33.8 pt的指向未变
x=*pt++; 后缀的运算符++的优先级更高,意味着将运算符用于pt 而不是*pt,因此对指针递增。然后后缀运算符意味着将对原来的地址&arr[2],而不是递增后的新地址解除引用,因此*pt++的值为arr[2],
#include <iostream>
int main(){
using namespace std;
int word[10]={1,2,3,4,5,6,7,8,9,10};//定义数组
int *pt= word; //定义指针指向的数组
int x;
for(int i=0;i<10;i++)
cout<<word[i]<<" , ";
cout<<endl;
cout<<&word<<endl;//输出数组首地址
cout<<pt<<endl; //指针的方式输出数组首地址
for(int i=0;i<10;i++)
{
cout<<"dizhi= "<<&(word[i])<<" "; //输出数组的每个元素的地址
cout<<"*pt++= "<<*pt++<<" "; //输出指针形式的每个元素
cout<<"&pt=="<<pt<<endl; //地址的变化 关键是查看这两行
}
return 0;
}

12.组合赋值运算符
i=i+by 更新循环计数
i+=by
+=运算符将两个操作数相加,并将结果赋值给左边的操作数。这意味着左边的操作数必须能够被赋值,如变量、数组元素、结构成员或者通过对指针解除引用来标识的数据:
示例:
k+=3; 左边可以被赋值 可以k=k+3
int * pa= new int[10]; pa指向数组int
pa[4]=12;
pa+=2; pa指向 pa[4]
34+=10; 非法 34不是一个变量 不可以被赋值

13.复合语句 (语句块)
for循环中的循环体 就是复合语句 由大括号括进
外部语句块中定义的变量在内部语句块中也定义的变量 情况如下:在声明位置到内部语句块结束的范围之内,新变量将隐藏旧变量,然后旧变量再次可见如下
#inlcude <iostream>
{ using namespace std;
int x=20; //原始的变量
{ //代码块开始
cout<<x<<endl; //使用原始的变量 20
int x=100; //定义新的变量
cout<<x<<endl; //使用新的变量 100
}
cout<<x<<endl; //使用旧的变量 20
return 0;
}
14.其他语法技巧----逗号运算符
语句块允许把两条或更多条语句放到按c++句法只能放一条语句的地方。
逗号运算符对表达式完成同样的任务,允许将两个表达式放到c++句法只允许放一个表达式的地方。
例如循环控制部分的更新部分 只允许这里包含一个表达式,但是有i和j两个变量,想同时变化 此时就需要逗号运算符将两个表达式合并成一个
++j,--i 这两个表达式合并成一个
逗号并不总是逗号运算符 例如 声明中的逗号将变量列表中相邻的名称分开:
int i,j;
for(j=0,i=word.size()-1;j<i;--i,++j)
逗号运算符另外的特性:确保先进算第一个表达式,然后计算第二个表达式(逗号运算符是一个顺序点)
i=20,j=2*i
另外逗号表达式的值为上面第二部分的值 上面为40,因为j=2*i的值为40. 逗号的运算符的优先级是最低的。
data=17,24 被解释为(data=17),24 结果为17 24不起作用
data=(17,24) 结果为24 因为括号的优先级最高 从右向左结合 括号中的值为24(逗号右侧的表达式的值) 所以data的值最后为24
15 关系表达式

关系运算符的优先级比算数运算符的低。 注意将bool的值提升为int后,3>y要么是1 或者是0 所以表达式有效
for(x=1;y!=x;++x) 有效
for(cin>>x;x==0;cin>>x)
(x+3)>(y-2) 有效
x+(3>y)-2 有效
16赋值 比较和可能犯的错误
== 和= 是有区别的 前者是判断 关系表达式 后者是赋值表达式
如果用后者则当在for循环中 测试部分将是一个复制表达式 ,而不是一个关系表达式,此时虽然代码仍然有效,但是赋值表达式 为非0 则结果为true 。
示例:测试数组中的分数
for(i=0;scores[i]==20;i++) 测试成绩是否为20 原来的数组值不变
for(i=0;socres[i]=20;i++) 测试成绩是否为20 但是原来的数组值已经都赋值为20了
1.赋值表达式 为非0 则 始终为true 2.实际上修改的数组的元素的数据 3. 表达式一直未true 所以程序再到达数组结尾后,仍然在不断地修改数据
但是代码在语法上是正确的,因此编译器不会将其视为错误
对于c++类,应该设计一种保护数组类型来防止越界的错误。循环需要测试数组的值和索引的值。
17.c风格字符串的比较
数组名代表数组首地址
引号括起来的字符串常量也是其地址
所以word=="mate" 并不是判断两个字符串是否相同,而是查看它们是否存储在相同的地址上 前者为数组 后者为字符串常量 ,所以两个地址一定是不同的,即使word数组中的数据是mate字符串。
由于c++将c风格的字符串视为地址,所以使用关系运算符来比较它们,将不会得到满意的结果。
相反应该使用c风格字符串库中的strcmp()函数来比较。 此函数接收两个字符串地址作为参数,参数可以使指针、字符串常量或者字符数组名,如果两个字符串相同,则函数返回0;如果第一个字符串的字母顺序排在第二个字符串之前,则strcmp()函数将会返回一个负值,相反则返回一个正值。
还有按照“系统排列顺序”比“字母顺序”更加准确,此时意味着字符是针具字符的系统编码来进行比较的ascii码。所有的大写字母的编码都比小写字母要小,所以按顺序排列,大写位于小写之前。
另一个方面 c字符串通过结尾的空值字符定义,而不是数组的长度
所以char big[80]="daffy" 与 char little[10]="daffy" 字符串是相同的
不能用关系运算符来比较字符串,但是可以用来比较字符,因为字符实际上是整型 所以可以用下面的代码显示字母表中的字符
for(ch='a';ch<='z';ch++)
cout<<ch;
示例:
#include <iostream>
#include <cstring>
int main(){
using namespace std;
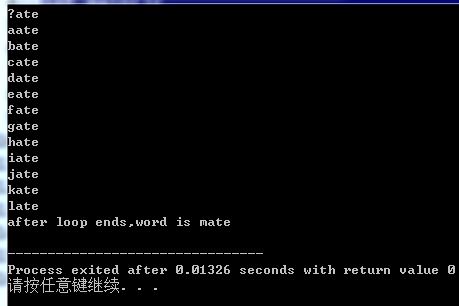
char word[5]="?ate"; //定义字符数组
for(char ch='a';strcmp(word,"mate");ch++)//判断字符数组中的首元素是否为m 为循环的条件 如果不是则返回负值 非0 所以为真,直到 ch=l时 ch++=m strcmp返回0 =false 结束循环
{
cout<<word<<endl;
word[0]=ch;//修改字符数组的首元素为ch
}
cout<<"after loop ends,word is "<<word<<endl;
return 0;
}
检测相等或排列顺序
可以使用strcmp()来测试c风格字符串是否相等 排列顺序,如果str1和str2相等,则下面的表达式为true
strcmp(s1,s2)==0 s1 s2相等 函数返回0 0==0 则为true
strcmp(s1,s2)!=0 s1 s2相等 .. 0!=0 、为false
strcmp(s1,s2) s1 s2相等返回0 为false
strcmp(s1,s2)<0 s1在s2的前面为true s1-s2<0
所以根据测试的条件 strcmp()可以扮演== != <和>运算符的角色
char实际上是整型 修改char 类型的操作实际上是修改存储在变量中的整数的编码 另,使用数组索引可使修改字符串中的字符更为简单
18.比较string类字符串
使用string类的字符串 比使用c风格字符串要简单 类设计可以使用关系运算符进行比较。
原因是因为类函数重载(重新定义)了这些运算符
示例:
#include <iostream>
#include <string> //头文件不同
int main(){
using namespace std;
string word="?ate"; //定义字符串对象
for(char ch='a';word!="mate";ch++)//循环
{
cout<<word<<endl;
word[0]=ch;//修改字符数组的首元素为ch
}
cout<<"after loop ends,word is "<<word<<endl;
return 0;
}
程序说明:
word!="mate" 使用了关系运算符 左边是一个string类的对象,右边是一个c风格的字符串
string类重载运算符!=的方式可以使用的条件:
1.至少有一个操作数为string对象,另一个操作数可以是string对象,也可以是c风格字符串
2.此循环不是计数循环 并不对语句块执行指定的次数,相反 它根据实际的情况来确定是否停止。 此种情况通常使用while循环
二 while循环
while循环是没有初始化和更新部分的for循环 它只有测试条件和循环体
while (test-condition)
body
首先程序计算圆括号内测试条件表达式 如果表达式为true 则执行body 如果表达式维false 则不执行
body代码中必须有完成某种影响测试条件表达式的操作。 例如 循环可以将测试条件中的变量加1或者从键盘输入读取一个新值。
while循环也是一种入口条件循环。因此 测试条件一开始便为false 则程序将不会执行循环体。
while(name[i]!='\0')
测试数组中特定的字符是不是空值字符。
1.for与while
本质上两者是相同的
for(init-expression;test-expression;update-expression)
{ statement(s) }
可以写成如下的形式
init-expression;
while(test-expression)
{
statement(s)
update-expression;
}
同样的
while(test-expression) body
可以写成
for(;test-expression;)
body
for循环需要3个表达式 技术上说,需要1条后面跟两个表达式的语句。不过它们可以是空表达式,只有两个分好是必须的。
另外for循环中 省略测试表达式时 测试结果将是true 因此 for(;;) body 会一直执行下去
差别:
1.for 没有测试条件 则条件为true
2.for中可以使用初始化语句声明一个局部变量 但是while不能这样做
3.如果循环体中包含continue语句 情况将会有所不同。
通常如果将初始值,终止值和更新计数器的、都放在同一个地方,那么要使用for循环格式
当在无法预先知道循环将执行的次数时,程序员常使用while循环
当使用循环时 要注意下面的几条原则
1.指定循环终止的条件
2.在首次测试之前初始化条件
3.在条件被再次测试之前更新条件
错误的标点符号
for循环和while循环都由用括号括起的表达式和后面的循环体(包含一条语句)组成。
语句块 由大括号括起 分号结束语句
2.等待一段时间,编写延时循环
clock()函数 返回程序开始执行后所用的系统时间
#include <iostream>
#include <ctime>//describes clock() function, clock_t loop
int main()
{
using namespace std;
cout<<"enter the delay time,in seconds: ";
float secs;
cin>>secs;
clock_t delay=secs * CLOCKS_PER_SEC;//转化成clock ticks的形式 始终滴答形式
cout<<"starting\a\n";
clock_t start=clock();
while(clock()-start<delay)//等待时间 直到为假时跳出循环
; // 空操作 空语句
cout<<"done \a\n";
return 0;
}
头文件ctime (time.h) 提供了这些问题的解决方案。首先,定义了一个符号常量--CLOCKS_PER_SEC 该常量等于每秒钟包含的系统时间单位数。因此,将系统时间除以这个值,可以得到秒数。或者将秒数乘以CLOCK_PER_SEC 可以得到以系统时间单位为单位的时间。其次,ctime将clock_t作为clock()返回类型的别名 ,这意味着可以将变量声明为clock_t类型 编译器将把它转换为long 、unxigned int 或者适合系统的其他类型。
类型的别名
c++为类型建立别名的方式有两种。
一种是使用预处理器:
#define BYTE char
这样预处理器将在编译程序时用char 替换所有的BYTE,从而使BYTE称为char的别名
第二种是使用c++和c的关键字typedef来创建别名。例如要讲byte作为char的别名,
typedef char byte;
通用格式:typedef typeName aliasName; aliasName为别名
两种比较
示例:
#define FLOAT_POINTER float *
FLOAT_POINTER pa,pb;
预处理器置换将该声明转换为如下的形式
float *pa,pb; 此时 pa为指针 而pb不是指针 只是float类型
typedef 方法不会有这样的问题 它能够处理更加复杂的类型别名 最佳选择,有时候是唯一的选择
不会创建新的类型 仅仅是这种类型的另一个名称
三 do-while循环
前面两种是入口条件的循环 ,而这种事出口条件的循环 意味着这种循环将首先执行循环体,然后再判定测试表达式,决定是否应该继续执行循环。如果条件为false 则循环终止。否则进入新的执行和测试。 此时循环体至少要循环一次。
do
body
while(test-expression);

通常情况下 入口条件循环要比出口条件循环好 因为入口条件循环在循环开始之前对条件进行检查,但是有时候需要do while更加合理 例如请求用户输入时,程序必须先获得输入,然后对它进行测试
//dowhile.cpp
#include <iostream>
int main(){
using namespace std;
int n;
cout<<"enter number in the range 1-10 to find"<<endl;
cout<<"my favorite number\n";
do{
cin>>n;//接收键盘的输入
}
while (n!=7);//当 输入的值不等于7时 判别式为真值 继续循环 等于7就退出循环 进行下面的语句的执行
cout<<"yes,7 is my favorite.\n";
return 0;
}
奇特的for循环
int i=0;
for(;;)
{
i++;
cout<<i<<endl;
if(30>=i) break;
}
或者另外一种变体
int i=0;
for(;;i++)
{
if(30>=i) break;
//do something
}
上述的代码基于这样的一个事实:for循环中的空测试条件被视为true。 不利于阅读 在do while中更好的表达它们的意思
int i=0;
do{
i++;
//do something
}while(30>=i);
第二个例子的转化
while(i<30)
{
//do something;
i++;
}
4.基于范围的for循环(c++11)
c++11新增的一种循环
基于范围 range-based的for循环:对数组(或容器类,如vector和array)的每个元素执行相同的操作
double prices[5]={4.99,10.99,6.87,7.99,8.49};
for(double x:prices)
cout<<x<<std::endl;
其中x最初表示数组prices的第一个元素。显示第一个元素后,不断执行循环,而x依次表示数组的其他元素。因此,上述代码显示全部5个元素,每个元素占据一行。总之,该循环显示数组中的每个值,要修改数组的元素,需要使用不同的循环变量的语法:
for(double &x:prices)
x=x*0.80;
示例1
#include <iostream>
int main(){
using namespace std;
double prices[5]={4.99,10.99,6.87,7.99,8.49};
for(double x:prices) //x最初表示首元素 之后x依次表示数组的其他元素
cout<<x<<endl;
return 0;
}
将上面的代码中的循环更改为for(double &x:prices)
x=x*0.80; //价格变为8折
&表明x是一个引用变量(而不是取地址),这种声明让接下来的代码能够修改数组的内容,而第一种语法不能。
也可以使用基于范围的for循环
for(int x:{3,5,2,8,6})
cout<<x<<" ";
5.循环和文本输入
系统中最常见的 最重要的任务:逐字符地读取来自文件或键盘的文本。
例如想编写一个能够计算输入中的字符数,行数和字数的程序,c++与c在i/o工具不尽相同 cin对象支持3中不同模式的单字符输入,其用户接口各部相同。
1.使用原始的cin进行输入
如果程序要使用循环来读取来自键盘的文本输入,则必须要知道何时停止读取。一种方法就是选择某个字符 作为哨兵字符 将其作为停止标记。
示例:
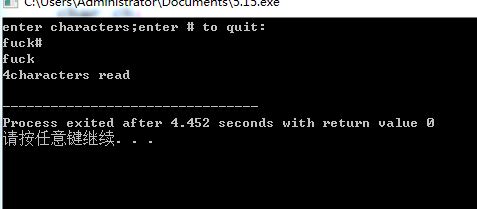
//testin1.cpp
#include <iostream>
int main(){
using namespace std;
char ch;
int count=0;
cout<<"enter characters;enter # to quit:\n";
cin>>ch;
while(ch!='#')//以#字符为终止符 如果输入中不是# 就继续执行循环
{
cout<<ch;
++count;
cin>>ch;//读取下一个字符 很重要 如果没有此条,就会重复处理第一个字符
}
cout<<endl<<count<<"characters read\n";
return 0;
}
程序说明
此循环遵循了前面的循环原则,结束条件为最后读取的字符为#,在循环之前读取一个字符进行初始化,而通过循环体结尾读取下一个字符进行更新。
在输入时 可以输入空格和回车 但是在输出时,cin会将输入的字符中的空格和换行符忽略。所以输入的空格或者回车符没有被回显,也没有被包括在计数内。
更加复杂的是,发送给cin的输入被缓冲,这意味着只有在用户按下回车键后,他输入的内容才会被发送给程序。这就是在运行该程序时,可以在#后面输入字符的原因。按下回车键后,这个字符序列讲被发送给程序,但是程序在遇到#字符后将结束对输入的处理。
2.使用cinget(char)进行补救
通常,逐个字符读取输入的程序需要检查每个字符,包括空格、制表符和换行符。cin所属的istream类(在iostream中定义)中包含一个能够满足这种要求的成员函数。
cin.get(ch)读取输入中的下一个字符(即使它是空格),并将其赋值给变量ch。使用这个函数调用替换cin>>ch,可以修补上面程序的问题
//testin1.cpp
#include <iostream>
int main(){
using namespace std;
char ch;
int count=0;
cout<<"enter characters;enter # to quit:\n";
cin.get(ch); //会显示空格 制表符等其他的字符
while(ch!='#')
{
cout<<ch;
++count;
cin.get(ch);
}
cout<<endl<<count<<"characters read\n";
return 0;
}
程序说明:可能的误解:c语言中 cin.get(ch)调用将一个值放在ch变量中,这意味着将修改该变量的值
c中要修改变量的值,必须将变量的地址传递给函数。
在上例中 cin.get() 传递的是ch 而不是&ch 在c中此代码无效,但是在c++中有效,只要函数将参数声明为引用即可。
引用在c++中对比c新增的一种类型。头文件iostream 将cin.get(ch)的参数声明为引用类型,因此该函数可以修改其参数的值。
3.使用哪一个cin.get()
char name[arsize];
...
cout<<"enter your name:\n";
cin.get(name,arsize).get();//相当于两个函数的调用。 cin.get(name,arsize);cin.get();
cin.get 的一个版本接收两个参数 :数组名 (地址)和arsize (int 类型的整数) 数组名的类型为 char *
cin.get() 不接收任何参数
cin.get(ch) 只有一个ch参数
在c中不可想象 参数数量不够 或过多 会造成函数的出错
但是在c++中,这种被称为函数重载的oop特性 允许重载创建多个同名函数,条件是它们的参数列表不同。如果c++中使用cin.get(name,arsize),则编译器将找到使用char* 和int作为参数的cin.get()版本。 如果没有参数,则使用无参的版本。
4.文件尾条件
如果正常的文本中#正常的字符 那么用#来用作结尾符不会合适
如果输入来自于文件,可以使用一种功能更加强大的技术 EOF 检测文件尾。
c++输入工具和操作系统协同工作,来检测文件尾并将这种信息告知程序。
cin和键盘输入 相关的地方是重定向 < 或者 >符号
操作系统允许通过键盘来模拟文件尾条件。
在unix中 可以在行首按下CTRL+D来实现。
在windows命令提示符下,可以在任意位置按CTRL+Z和enter
很多的pc编程环境都讲CTRL+z视为模拟的EOF
检测EOF的方法原理:
检测EOF后,cin将两位(eofbit和failbit)都设置为1;
查看eofbit是否被设置 使用成员eof()函数
如果检测到EOF,则cin.eof()将返回bool值true,否则返回false。
同样,如果eofbit或者fialbit被设置为1,则fail()成员函数返回true,否则返回false。
eof()和fial()方法报告最近的读取结果。因此应将cin.eof() 或者cn.fail()测试放在读取后
#include <iostream>
int main()
{
using namespace std;
char ch;
int count=0;
cin.get(ch);
while(cin.fail()==false)//判断cin.fail()的值 是否被设置,如果ctrl+z 和enter 已经按下 则返回true 条件不符合,跳出循环
{
cout<<ch;
++count;
cin.get(ch);
}
cout<<endl<<count<<"characters read\n";
return 0;
}
程序说明:windows 7系统上运行该程序,因此可以按下ctrl+z和回车键来模拟EOF条件,在unix和类unix(包括linux)等系统张,用户可以按ctrl+z组合键将程序挂起,而命令fg恢复程序的执行。
通过使用重定向,可以用此程序来显示文本文件。并报告它包含的字符数 主要在unix中测似乎
1.EOF结束输入
cin方法检测到EOF时,将设置cin对象中一个指示EOF条件的标记。设置这个标记后,cin将不读取输入,再次调用cin也不管用。
上面的情况 是对文件的输入有道理,因为程序不应该读取超出文件尾的内容
对于键盘的输入,有可能使用模拟EOF来结束循环,但是稍后还要读取其他输入。
cin.clear()方法用来清除EOF标记,使输入继续进行。
在有些系统中CTRL+Z实际上会结束输入和输出。 而cin.clear()将无法恢复输入和输出。
2.常见的字符输入做法
每次读取一个字符,直到遇到EOF的输入循环的基本设计如下:
cin.get(ch);
while(cin.fail()==false) //这里可以用!逻辑运算符 去掉等号 while(!cin.fail())
{
...
cin.get(ch);
}
方法cin.get(char)的返回值是一个cin对象。然而,istream类提供了一个可将istream对象转换为bool值的函数;
当cin出现在需要bool值的地方(如在while循环的测试条件中)时,该转换函数将被调用。另外,如果最后一次读取成功了,则转换得到的bool值为true;否则为false。
意味着可以改写为
while(cin)//while input is successful
这样比!cin.fail()或者!cin.eof()更通用,因为它可以检测到其他失败的原因,如磁盘故障
最后,由于cin.get(char)的返回值为cin,因此可以将循环精简成这种格式:
while(cin.get(sh))
{
...
}
这样 cin.get(char)只被调用了一次,而不是两次:循环前一次、循环结束后一次。为判断循环测试条件,程序必须首先调用cin.get(ch).如果成功,则将值放入ch中。然后,程序获得函数调用的返回值,即cin。之后对cin进行bool转换,如果输入成功,则结果为true,否则为false。三条指导原则 全部被放在循环条件中。
5.另一个cin.get()版本
旧式的c代码 i/o函数 getchar()和putchar()函数 仍然适用,只要像c语言中那样包含头文件stdio.h或者新的cstdio即可。
也可以使用istream和ostream类中类似功能的成员函数。
cin.get() 不接受任何参数 会返回输入中的下一个字符
ch=cin.get();
与getchar()相似,将字符编码作为int类型返回;
cn.get(ch)则会返回一个对象,而不是读取的字符。
cout.put(ch) 显示字符 此函数类似于c中的putchar() 只不过参数类型为char 而不是int
put()最初只有一个原型 put(char) ,可以传递一个int参数给它,该参数将被强制转换为char。c++标准还要求只有一个原型。然后c++的有些实现都提供了3个原型
参数分别为char signed char unsigned char 。这些实现中如果给put()传递一个int参数将导致错误消息,因为转换int的方式不止一种,如果使用显式强制类型转换的原型(cin.put(char(ch)))可以使用int参数
成功使用cin.get() 需要了解EOF条件。
当函数到达EOF时,将没有可以返回的字符。相反,cin.get()将返回一个用符号常量EOF表示的特殊值。该常量是在头文件iostream中定义的。EOF值必须不同于任何有效的字符值,以便程序不会将EOF于常规字符混淆。通常EOF被定义为值-1,因为没有ascii码为-1的字符,但并不需要知道它实际的值,在程序中使用EOF即可。
示例:
char ch; 替换为 int ch;
cin.get(ch); 替换为 ch=cin.get();
wihile(cin.fail()==false) 替换为ch!=EOF
{
cout<<ch; 替换为:ch.put(ch);
++count;
cin.get(ch); 替换为:ch=cin.get();
}
上面代码的功能是 如果ch是一个字符,则循环将显示它,如果ch为EOF 则循环将结束
需要知道的是 EOF不表示输入中的字符,而是指出没有字符。
//testin4.cpp
#include <iostream>
int main(void)
{
using namespace std;
int ch;
int count=0;
while((ch=cin.get())!=EOF) //获取字符 并将字符的int型的编码赋值给ch 然后再判断与-1(EOF)是否相等
{
cout.put(char(ch)); //将int型编码的ch 强制转换为char类型 并且输出
++count;
}
cout<<endl<<count<<"characters read\n";
return 0;
}
注意,有些系统 如果对EOF不完全支持,如果使用cin.get()来锁住屏幕直到可以阅读它,将不起作用,因为检测EOF时将禁止进一步读取输入。可以使用循环计时来使屏幕停留一段时间。 也可以使用cin.clear来重置输入流。

尽量使用cin.get(char) 这种返回cin对象的方式,get成员函数的主要用途是能够将爱那个stdio.h的getchar()和putchar()函数转换为iostream的cin.get()和cout.put()方法。只要用头文件iostream替换为stdio.h 并用作用相似的方法替换所有的getchar()和putchar()即可。
6.嵌套循环和二维数组
1. int a[4][5]二维数组
a[0] 为二维数组的首元素,而首元素又是包含5个元素的数组
2.for(int row=0;row<4;row++) //行
{
for(int col=0;col<5;++col)//列
cout<<a[row][col]<<"\t";
cout<<endl;
}
3.初始化二维数组
int a[2][3]={
{15,25,35},{17,28,49}
}
也可以 int a[0]={15,25,35}
int a[1]={17,28,49}
4.使用二维数组
//nested.cpp
#include <iostream>
const int Cities=5;
const int years=4;
int main()
{
using namespace std;
const char * cities[Cities]= //指针数组
{
"girbble city","gribbletown","new grebble","san gribble","gribble vista"
};
int maxtemps[years] [Cities]= //二维数组
{
{96,100,87,101,105},{96,98,91,107,104},{97,101,93,108,107},{98,103,95,109,108}
};
cout<<"maximum temperatures for 2008 -2011\n\n";
for(int city=0;city<Cities;++city)
{
cout<<cities[city]<<"\t";
for(int year=0;year<years;++year)
cout<<maxtemps[year][city]<<"\t";
cout<<endl;
}
return 0;
}
在此例中,可以使用char数组的数组,而不是字符串指针数组
char cities[Cities][25]
{
"Gribble City",
"Gribbletown",
"New Gribble",
"San Gribble",
"Gribble Vista"
};
此种方法将全部5个字符串的最大长度限制为24个字符。指针数组存储5个字符串的地址,而使用char数组的数组时,将5个字符串分别赋值到5个包括25个元素的char数组中。因此,从存储空间的角度说,使用指针数组更为经济;但是char数组的数组更容易修改其中的一个字符串。
方法2:
可以使用string对象数组 而不是字符串指针数组
const string cities[Cities]={
"Gribble City",
"Gribbletown",
"New Gribble",
"San Gribble",
"Gribble Vista"
}
如果希望字符串是可修改的,则应该省略限定符const。使用string 对象数组时,初始化列表和用于显示字符串的for循环代码与前两种方法中相同。在希望字符串是可修改的情况下,string类自动调整大小的特性将使这种方法比使用二维数组更为方便。
第六章 分支语句
1.
if(test-condition)
statement
2.
if(test-condition)
statement1
else
statement2
3.格式化if else 语句
if(){}
else{}
或者
if(){} else if(){} else{}
tips:条件运算符和错误防范
variable==value 反转为value==variable
以此来捕获将相等运算符误写为赋值运算符的错误
意思就是 if(3==a) 可以避免写成if(3=a) 编译器会生成错误的信息,因为它以为程序员试图将一个值赋值给一个字面值(3总是等于3,而不是将另一个值赋值给它)
假如省略了其中的一个等号 if(a=3) 就不会出现错误信息 没有 if(3=a) 更好
2.逻辑表达式
a || 或运算符 比关系运算符的优先级要低
此运算符是一个顺序点 sequence point 也就是说 先修改左侧的值,再对右侧的值进行判定c++11侧说法是 运算符左边的子表达式先于右边的子表达式
如果左侧的表达式为true 则c++将不会去判定右侧的表达式
cin>>ch;
if(ch=='y'||ch=='Y')
cout<<"You were warned!\a\a\n";
else if(ch=='n'||ch=='N')
cout<<"A wise choice ... bye\n";
else ....
程序只读取一个字符,所以只读取响应的第一个字符。这意味着用户可以用NO! 而不是N 进行回答,程序将只读取N。然而,如果程序后面再读取输入时,将从O开始读取。
b && 逻辑与表达式 同或运算符一样 也是顺序点 也是左侧确定true后,不看右侧
用&&来设置取值范围
&&运算符还允许建立一系列 if else if else语句,其中每种选择都对应于一个特定的取值范围。
例如
if(age>=85&&age<=100)
else if(age>=70&&age<85)
...
c 逻辑NOT运算符!
取反 优先级高于所有的关系运算符和算数运算符
d 逻辑运算符细节
c++逻辑or和逻辑and运算符的优先级都低于关系运算符。
c++确保程序从左向右进行计算逻辑表达式,并在知道答案后立刻停止
e 其他表示方式
并不是所有的键盘都提供了用作逻辑运算符的符号 所以 c++标准提供了另一种表示方式
就要使用到and or not 等c++保留字 但是不是关键字 如果c语言想将其用作运算符 需要包含头文件iso646.h

3.字符函数库cctype
一个与字符相关的 非常方便的函数软件包 主要用来测试字符类型
头文件 cctype 老式的为ctype。h
cin.get(ch);
if(isalpha(ch)) 判断是否为字母字符

4.?:运算符 三目运算符
5>3?10:12
if(5>3)
return 10;
else
return 12;
示例2:
(i<2)? !i ? x[i] : y : x[1];
嵌套三目运算符
5.switch
swithc(integer expression)//其中括号中的表达式的值为label1 或者label2 或者其他(default)
{
case label1:statement(s);
break; //跳出循环
case label2:
case label3:statement(s);//2和3一样 都会执行后面的语句
default:statement(s)
}
5.1将枚举量用作标签
enum{red,orange,yellow,green,blue};//枚举量
int main()
{
int code;
cin>>code;
switch(code)
{
case red:cout<<"red";
break;
case orange:cout<<"orange";
break;
defalut:....
}
}
5.2 switch 和if else 的区别
if else 更加通用 而且可以处理区间
if(age>17&& age<50)
6.break和continue 语句
continue 是直接跳到循环开始处 开始下一轮循环 不会跳过循环的更新表达式 for循环中 continue语句使程序直接跳到更新表达式处,然后跳到测试表达式处。
但是对于while循环 continue会直接跳到测试表达式处 在while循环中 位于continue之后的更新表达式都将被跳过
break是跳出循环 结束包含它的循环
goto label; 直接将程序跳到label处
7.读取数字的循环
读入数字
int n;
cin>>n;
如果是字符不是数字 会发生如下的情况
n的值不变
不匹配的输入将被留在输入队列中
cin对象中的一个错误标记被设置
对cin方法的调用将返回false 如果被转换为bool类型
方法返回false 意味着可以用非数字输入来结束读取数字的循环。非数字输入设置错误标记意味着必须重置该标记,程序才能继续读取输入。
clear()方法重置错误输入标记,同时也重置文件尾 EOF条件 输入错误和EOF都会导致cin返回false
示例
//cinfish.cpp
#include <iostream>
const int Max=5;
int main()
{
using namespace std;
double fish[Max];
cout<<"please enter the weights of your fish.\n";
cout<<"fish #1: ";
int i=0;
while(i<Max&&cin>>fish[i])// 左侧的表达式为假 则不会判断右侧的表达式,右侧的表达式判断的同时会将结果存储到数组中
{
if(++i<Max) //执行++i i的值会变化
cout<<"fish #"<<i+1<<": ";
}
double total=0.0;
for(int j=0;j<i;j++)
total+=fish[j];
if(i==0)
cout<<"no fish\n";
else
cout<<total/i<<"=average weight of " <<i<<" fish\n";
cout<<"done.\n";
return 0;
}

上面的程序当输入不是数字时,该程序将不在读取输入队列,程序将拒绝输入;如果想继续读取输入,则需要重置输入
当输入错误的内容时:采取的3个步骤
1.重置cin以接受新的输入
2.删除错误输入 (如何删除错误的输入) 程序必须先重置cin 然后才能删除错误输入
3.提示用户再输入
//cingolf.cpp
#include <iostream>
const int Max=5;
int main()
{
using namespace std;
int golf[Max];
cout<<"please enter your golf scores.\n";
cout<<"you must enter "<<Max<<" rounds.\n";
int i;
for(i=0;i<Max;i++)
{
cout<<"round #"<<i+1<<": ";
while(!(cin>>golf[i]))//用户输入数字 则cin表达式将为true 则将后面的值存入到数组中,如果输入的是非数字值,则cin为false 则值不会存入到数组中
{
cin.clear();//如果没有此语句,则程序会拒绝继续读取输入
while(cin.get()!='\n')//读取行尾之前的所有输入,从而删除这一行中的错误输入;另一种方法是读取到下一个空白字符,这样将每次删除一个单词,而不是一次删除整行。
continue;
cout<<"please enter a number: ";
}
}
double total=0.0;
for(int i=0;i<Max;i++)
total+=golf[i];
cout<<total/Max<<"=average scores " <<Max<<" rounds\n";
cout<<"done.\n";
return 0;
}
8.简单文件的输入和输出
1.文本i/o和文本文件
cin输入,会将输入看作一系列的字节,每个字节被解释为字符编码,不管目标的数据类型是什么,都被看作字符数据,然后cin对象负责将文本转换为其他的类型。
输入38.2 15.5
int n;
cin>>n 会不断的读取,直到遇到非数字字符, 38被读取后 句点将成为输入队列中的下一个字符
double x;
cin>>x; 不断的读取 直到遇到不属于浮点数的字符。 38.2将会被读取,空格将成为输入队列中的下一个字符
char word[50];
cin>>word;
不断读取,直到遇到空白字符, 38.5被读取,然后将这4个字符的编码存储到数组word中。并在末尾加上一个空字符。
char word[50];
cin.getline(word,50);
不断读取,直到遇到换行符(示例中少于50个字符),所有字符被存储到word中 包括空格,并在末尾加上一个空字符。换行符被丢弃,输入队列中的下一个字符是下一行中的第一个字符。这里不需要转换。
对于输入 将执行相反的转换。即整数被转换为数字字符序列,浮点数被转换为数字字符和其他字符组成的字符序列 字符数据不需要做任何的转换。
输入一开始都是文本,所以控制台输入的文件版本都是文本文件爱你,即每个字节都存储了一个字符编码的文件。
2.写入到文本文件中 相对应于写入到控制台上(屏幕 对应于cout)
cout用于控制台输出的基本事实
必须包含头文件iostream
头文件iostream定义了一个用处理可输出的ostream类
头文件iostream声明了一个名为cout的ostream变量(对象)
必须指明名称空间std;
结合使用cout和运算符<<来显示各种类型的数据
文件输出与上述相似
必须包含头文件fstream
头文件fstream定义了一个用于处理输出的ofstream类
需要声明一个或多个ofstream变量(对象),并自己命名
指明名称空间std
需要ofstream对象与文件关联起来,为此,方法之一是使用open()方法
使用完文件后,应好似用方法close()将其关闭
可结合使用ofstream对象和运算符<<来输出各种类型的数据
cout为ostream已经定义好的 所以不需要重新定义
而ofstream对象没有已经定义好的对象 所以需要自己声明此脆响 并同文件相关联
ofstream outfile;
ofstream fout; 定义了两个对象 都属于ofstream类
关联文件
outfile.open("fish.txt"); //关联文件 fish.txt
char filename[50];
cin>>filename;
fout.open(filename); //关联文件 filename变量存储的值作为文件名
使用方法:
double wt=125.8;
outfile<<wt; //将wt数据写入到上面关联的文件中 fish.txt
char line[81]="objects are closer than they appear";
fout<<line<<endl; //将line数组中的内容输出到fout对象关联的文件中去
声明一个ofstream对象并将其同文件关联起来后,便可以像使用cout那样使用它。所有可用于cout的操作和方法都可以用于ofstream对象
主要步骤:
1.包含头文件fstream
2.创建一个ofstream对象
3.将该ofstream对象同一个文件关联起来。
4.就像使用cout那样使用该ofstream对象
//outfile.cpp
#include <iostream>
#include <fstream>
int main()
{
using namespace std;
char automobile[50];
int year;
double a_price;
double d_price;
ofstream outfile;
outfile.open("carinfo.txt");//如果在当前目录下没有此文件怎么办呢?自动创建 ;如果已经存咋这个文件,默认情况下会删除原来的内容(将此文件的长度截短为0),写入新的内容。17章可根据参数修改 此默认设置
cout<<"enter the make and model of automobile: ";
cin.getline(automobile,50);//读取到换行符为止
cout<<"enter the model year: ";
cin>>year;
cout<<"enter the original asking price: ";
cin>>a_price ;
d_price=0.913*a_price;
cout<<fixed;
cout.precision(2);
cout.setf(ios_base::showpoint);//显示固定格式
cout<<"make and model: "<<automobile<<endl;
cout<<"year: $"<<year<<endl;
cout<<"was asking $"<<a_price<<endl;
cout<<"now asking $"<<d_price<<endl;
outfile<<fixed;
outfile.precision(2);//格式化方法
outfile.setf(ios_base::showpoint);//格式化方法
outfile<<"make and model: "<<automobile<<endl;
outfile<<"year: "<<year<<endl;
outfile<<"was asking $" <<a_price <<endl;
outfile<<"now asking $"<<d_price <<endl;
outfile.close();//不需要使用文件名作为参数
return 0;
}
所有的cout方法都可以用outfile对象使用
关联文件后,需要关闭此文件的关联
3.读取文本文件 类似于cin 即istream类和ifstream类对应
cin 将控制台(键盘的内容输入) 存入到变量中
ifstream类定义的对象 从文本文件中读取内容到指定的变量中
首先看控制台:
包含iostream头文件
此头文件定义了一个用处理输入的istream类
头文件iostream声明了一个名为cin的istream变量 对象
指明命名空间
结合cin和get方法来读取一个字符 使用cin和getline来读取一行字符
cin 和eof()、fial()方法来判断输入是否成功。
cin本身用作测试条件,如果最后一个读取操作成功,它将转换为bool的值,true或者false
文件的输入与上面的cin类似
头文件fstream
头文件fstream定义了一个用于处理输入的ifstream类
需要声明一个或多个ifstream变量(对象),并以自己喜欢的方式对其进行命名,条件是遵守常用的命名规则。
指明名称空间std
将ifstream对象与文件关联起来。方法之一是使用open方法
使用完文件后,需要使用close()方法将其关闭
ifstream对象和运算符>>来读取各种类型的数据
ifstream和eof() fail()等方法来判断输入是否成功
ifstream对象本身被用作测试条件时,如果最后一个读取操作成功,它将被转换为布尔值bool
示例:
ifstream infile;
ifstream fin;
infile.open("bowling.txt");
char filename[50];
cin>>filename;
fin.open(filename);
double wt
infile>>wt;
char line[81];
fin.getline(line,81);
如果试图打开一个不存在的文件用于输入,则这种错误将导致后面使用ifstream对象进行输入时失败,检查文件是否被成功打开的首先方法是使用is_open(),为此可以使用类似于下面的代码:
infile.open("bowling.txt");
if(!infile.is_open())
{
exit(EXIT_FAILURE);
}
如果文件被成功打开,方法is_open()将返回true;否则返回false
exit()函数的原型是在头文件cstdlib中定义的。在该头文件中,还定义了一个用于同操作系统通信的参数值EXIT_FAILURE 函数exit()终止程序。
如果编译器不支持is_open()函数 可以使用比较老的方法good()来代替。但是此函数在检查问题方面没有新的函数is_open()那么广泛。
示例
//sumafile.cpp
#include <iostream>
#include <fstream>
#include <cstdlib>
const int SIZE=60;
int main()
{
using namespace std;
char filename[SIZE];
ifstream infile;//定义对象
cout<<"enter name of data file: ";
cin.getline(filename,SIZE);//从文件中获取一行数据 60个字符
infile.open(filename);//关联指定的文件
if(!infile.is_open())//判断文件是否存在 如果不存在则提示 并且退出
{
cout<<"could not open the file"<<filename<<endl;
cout<<"program terminating.\n";
exit(EXIT_FAILURE);//根据EXIT_FAILURE的值 退出返回
}
double value;
double sum=0.0;
int count=0;
infile>>value;//从文件获取值 存入变量
while(infile.good())//判断获取的数据是否为double类型
{
++count;
sum+=value;
infile>>value;//获取下一个值
}
if(infile.eof())//判断是否到文件结尾
cout<<"end of file reached.\n";
else if(infile.fail())//判断是否数据匹配
cout<<"input terminated by data mismatch.\n";
else
cout<<"input terminated for unknown reason.\n";
if(count==0)//
cout<<"no data processed.\n";
else//最后输出各个变量的值
{
cout<<"items read: "<<count<<endl;
cout<<"sum: "<<sum<<endl;
cout<<"average: "<<sum/count<<endl;
}
infile.close();
return 0;
}
1.程序说明 设置中文路径名称可用
setlocale(LC_ALL,"Chinese-simplified")
2.注意文件的扩展名
1.txt.txt
3.加入绝对路径
infile.open(“c://source/1.txt”);
4.文件读取循环的正确设计。读取文件时,有几点需要检查,首先,程序读取文件时要超过EOF,如果遇到EOF 则方法eof会返回true;其次类型不匹配 fail返回true;如果最后一次读取文件受损或因噶进故障,bad会返回true 所以不要分别检查这些问题,用good()方法一次性检查就可以了。如果没有任何问题则返回true
注意上面检测的顺序,首先是eof 之后是fail 再之后是bad
同cin相同
cin>>value; //循环之前读入
while(){
...
cin>>value; 循环中读入
}
同上
infile>>value;//循环之前读入
while(infile.good())
{
...
infile>>value;//循环之后读入
}
可以合并为一个判断的表达式
while (infile>>value)
{
statements;
}
第七章 函数 ----c++的编程模块
函数原型 prototype
函数定义 definition
调用函数 calling
1.定义函数
有返回值和无返回值的函数
int functionName(parameterList) 有返回值
{
statements(s)
return value; 必须存在
}
无返回值
void functionname(parameterlist)
{
statements(s);
return; 可有可无 不返回任何值
}
2.函数原型和调用
系统库提供的函数的原型一般包含在include文件中 头文件中。
提供函数原型的原因如下:
a 原型描述了函数到编译器的接口,它将函数返回值的类型以及参数的类型和数量告诉编译器。
double volume=cube(side);
首先,原型告诉编译器,cube有一个double参数 ,如果程序没有提供这样的参数,原型将让编译器能够捕获这种错误。其次,cube函数完成计算后,将把返回值放置在指定的位置--可能是cpu寄存器,也可能是内存中。然后调用函数将从这个位置取得返回值。
因为原型指出了cube的类型为double 因此编译器知道应该检索多少个字节以及如何解释它们。
另一个方面是,如果没有原型,编译器就会在程序中查找,导致效率不高,编译器在搜索文件的剩余部分时将必须停止对main()的编译
另一个问题是,函数可能并不在文件中,c++允许将一个程序放在多个文件中,单独编译这些文件,然后再将他们组合起来。
3.原型的语法
函数原型是一条语句,因此必须以分号结束。
复制函数头部加上分号 就是原型
原型中可以没有变量名,但是必须有类型
4.原型的功能 c++中必须提供函数的原型
编译器正确处理函数的返回值
编译器检查使用的参数数目是否正确
编译器检查使用的参数类型是否正确。如果不正确,则转换为正确的类型
调用函数cube (2) 原型为cube(double)
由于原型中指定了double类型 所以会将整型的2转换为2.0再参加运算
但是如果反过来 cube(int ) 调用时使用cube(2.7854)
原型为int型 转换时会将浮点的类型转换为int 会导致数据的丢失
二 函数参数和按值传递
1.按值传递时,不会改变实参的数值
将实参复制一个副本 成为形参的值,在函数中计算的是形参的数值
2.多个参数
逗号分隔多个参数
和一个参数一样,原型中不必与定义中的变量名相同,而且可以省略
但是在原型中提供变量名使得程序更加容易理解
三函数和数组
示例:int sum_arr(int arr[],int n) 为原型
调用:int sum_arr(int arr[],int n)
也可以使用int sum_arr(int * arr,int n)
1.函数如何使用指针来处理数组
将数组名视为指针
cookies==&cookies[0]
首先,数组声明使用数组名来标记存储位置;其次,对数组名使用sizeof将得到整个数组的长度 以字节为单位ie;第三,将地址运算符&用于数组名时,将返回整个数组的地址
原型:int sum_arr(int * arr,int n) 使用int arr[] 是相同的 但是后者提醒 指针指向数组的第一个元素
调用:int sum_arr(cookies,arsize)
两个恒等式:
arr[i]==*(ar+i)
&arr[i]==ar+i
将指针(包括数组名)加1 实际上加上了一个指针指向的类型的长度 字节为单位ie 对于便利数组而言,使用指针加法和数组下标时等效的
2.将数组作为参数意味着什么?
上例中 实际上传递的是指向数组的指针,而不是整个数组。
当传递常规变量是,使用的是该变量的拷贝;但是传递数组时,函数将使用原来的数组。但是传递数组指针时,使用的是原来的数组,并不是数组的copy
虽然节省了资源,但是同时带来了对原始数据被破坏的风险。
可以使用const的限定符这种解决办法。
cookies和arr指向同一个地址,但是sizeof cookies 的值是32 而sizeof arr为4 这是因为sizeof cookies 是整个数组的长度,而sizeof arr只是指针变量本身的长度。顺便说,这也是必须显式传递数组长度,而不能在sum_arr()中使用sizeof arr的原因 指针并没有指出数组的长度
在原型中不要使用方括号来传递数组的长度
void fillarray(int arr[size])
3.更多数组函数示例
//7.7 arrfun3.cpp
#include <iostream>
const int Max=5;
int fill_array(double ar[],int limit);//原型 fill_array
void show_array(const double ar[],int n);//原型 show_array
void revalue(double r,double ar[],int n);//原型 revalue
int main(){
using namespace std;
double properties[Max];
int size=fill_array(properties,Max);//调用填充函数 注意参数
show_array(properties,size);//调用显示函数
if(size>0)//大于0 说明fill_array函数返回的值是 填充成功的数量
{
cout<<"enter revaluation factor: ";
double factor;
while(!(cin>>factor)) //输入的值各种原因不成功 每次读取一个字符
{
cin.clear();//重置输入
while(cin.get()!='\n') //再次获取输入 如果不等于换行符 则继续读取 一直到换行符之前
continue;
cout<<"bad input,please enter a number: ";
}
revalue(factor,properties,size);//重新赋值
show_array(properties,size);//再次调用显示函数
}
cout<<"donw.\n";
cin.get();
cin.get();//等待 显示
return 0;
}
int fill_array(double ar[],int limit)//填充数组的实现
{
using namespace std;
double temp;
int i;
for(i=0;i<limit;i++)
{
cout<<"enter value #"<<(i+1)<<": ";
cin>>temp;
if(!cin)
{
cin.clear();
while(cin.get()!='\n')
continue;
cout<<"bad input;input process terminated .\n";
break;
}
else if(temp<0)//输入的是赋值则跳出循环
break;
ar[i]=temp;//数组赋值
}
return i;
}
void show_array(const double ar[],int n)//显示数组中各个元素的值 这里的const 用来保证不会修改原始的数组;
{
using namespace std;
for(int i=0;i<n;i++)
{
cout<<"property #"<<(i+1)<<":$";
cout<<ar[i]<<endl;
}
}
void revalue(double r,double ar[],int n)//重新赋值
{
for(int i=0;i<n;i++)
ar[i]*=r;
}
程序说明 关于void show_array(const double ar[],int n);
指针ar不能修改该数据,也就是说可以使用像ar[0]这样的值,但不能修改,注意,这并不意味着原始数组必须是常量,而只是意味着不能在show_array()函数中使用ar来修改这些数据,因此,show_array()将数组视为只读数据。
假设无意间在show_array()函数中执行了下面的操作,从而违反了这种限制:
ar[0]+=10; 会提示错误
c++声明const double ar[] 解释为const double * ar 因此该声明实际上是说 ar指向的是一个常量值。
首先考虑的是通过数据类型和设计适当的函数来处理数据 然后将这些函数组合成一个程序。 叫做自下而上的程序设计
c语言为过程性编程 倾向于从上而下的程序设计
4.使用数组区间的函数
处理数组的c++函数,必须将数组中的数据种类,数组的起始位置和数组中元素数量提交给它;
另一种处理数组的方法,即指定元素区间range 可以通过传递两个指针来完成。一个指针标识数组的开头 另一个指针标识数组的尾部
sum=sum_arr(cookies,cookies+arsize);
sum=sum_arr(cookies,cookies+3);
sum=sum_arr(cookies+4,cookies+8);
//arrfun4.cpp
#include <iostream>
const int arsize=8;
int sum_arr(const int * begin,const int * end);
int main()
{
using namespace std;
int cookies[arsize]={1,2,4,8,16,32,64,128};
int sum=sum_arr(cookies,cookies+arsize);
cout<<"total cookies eaten: "<<sum<<endl;
sum=sum_arr(cookies,cookies+3);
cout<<"first three eaters ate "<<sum<<"cookies.\n";
sum=sum_arr(cookies+4,cookies+8);
cout<<"last four eaters ate "<<sum<<" cookies.\n";
return 0;
}
int sum_arr(const int * begin,const int * end)
{
const int * pt;
int total=0;
for(pt=begin;pt!=end;pt++)
total=total+*pt;
return total;
}
pt设置为指向要处理的第一个元素 begin指向的元素的指针,并将*pt 加入到total中,然后循环通过递增操作来更新pt。使之指向下一个元素。只要pt不等于end 这个过程就会继续。
end-begin为整数值 等于数组的元素数目
5.指针和const
两种不同的方式将const关键字用于指针。
第一是让指针指向一个常量对象,这样可以防止使用该指针来修改所指向的值
第二是将指针本身声明为常量,可以防止改变指针指向的位置
int age=39;
const int * pt=&age;
pt指向一个const int的值,所以不能用pt来修改这个值, 换句话说就是* pt的值为const 不能被修改;
*pt+=1; 错误的语句
cin>>*pt;
pt的声明并不意味着它指向的值实际上是一个常量,而只是说对pt而言,这个值是常量。例如pt指向age 而age不是const 可以直接通过age变量来修改age的值
*pt=20; 错误
age=20 正确
将常规变量的地址赋给常规指针 可行
将const变量的地址赋给指向const的指针 可行 变量和指针都不能修改原值
将const的地址赋给常规指针 不可行 (原因是常规指针可能会改变指向的const的值 会引发错误)
例2:一级指针 一级间接关系 将非const指针赋给const指针是可以的
int age=39; //age++ 有效
int * pd=&age; //*pd=41 有效
const int * pt=pd; //*pt=42 无效
二级关系
const int **pp2; //二级指针
int * p1;
const int n=13; //常量 变量
pp2=&p1; // 错误 将非const地址 赋给const指针 pp2 因此可以使用p1来修改const数据,
*pp2=&n; //常量变量的地址赋给一级指针 有效 两个都是常量
*p1=10; //
如果数据类型本身并不是指针,则可以将const数据或非const数据的地址赋给指向const的指针,但只能将非const数据的地址赋给非const指针。
二级指针不允许赋值
禁止将常量数组的地址赋给非常量指针将意味这不能将数组名作为参数传递给使用非常量形参的函数
const int months[12]={31,28,31,30,31,30,31,31,30,31,30,31};
int sum(int arr[],int n);
int j=sum(months,12);
试图将const指针赋给非const指针arr 编译器将禁止这种函数调用
尽可能使用const
TIPS:将指针参数声明为指向常量数据的指针有两条理由:
避免无意间修改数据而导致的编程错误
使用const使得函数能够处理const和非const实参,否则将只能接受非const数据
int age=39;
const int * pt=&age;
上面的声明中的const只能防止修改pt指向的值(39),而不能防止修改pt的值。也就是说,可以将一个新的地址赋值给pt:
int sage=80;
pt=&sage; 不能使用pt来修改sage的值 但是可以修改pt本身的值 (地址值)
使用const的方式使得无法修改指针的值
int sloth=3;
const int * ps=&sloth;//指针指向一个整型的常量数值 ----1
int * const finger=&sloth;// 一个常量指针 指向整型-----2
1 不能通过指针 改变指向的常量的值,但是可以改变指针本身的地址值 const的位置在最前方 可以不指向sloth
2 不能改变指针本身的地址值,但是可以通过此指针修改指向变量的值 const的位置在后方 执政指向sloth
总结 finger和*ps都是const;而*finger和ps不是const
double trouble=2.0e30;
const double * const stick=&trouble;
stick 只能指向trouble stick不能用来修改trouble的值, stick和*stick都是const
通常 将指针作为函数参数来传递时,可以使用指向const的指针来保护数据。
四 函数和二维数组
为编写将二维数组作为参数的函数 数组名是地址 ,相应的形参就是一个指针 数组名代表数组组中的第一个元素的地址 &数组名则代表全部数组的地址
int data[3][4]={{1,2,3,4},{9,8,7,6},{2,4,6,8}};
int total=sum(data,3);
data是一个数组名,该数组有3个元素,第一个元素本身是一个数组,有4个int值组成,因此data的类型是指向4个int组成的数组的指针。
data指向二维数组中的第一个元素,代表{1,2,3,4}这个元素的地址
所以正确的原型如下:
int sum(int (*ar2)[4],int size); 可读性差一些
ar2 接收的就是一个包含4个int型元素的数组的地址值 (指针)
而与上面同样的原型则为
int sum(int ar2[][4],int size) 可读性更好
ar2是指针而不是数组,指针类型指出,由4个int组成的数组,因此,指针类型指定了列数,这就是没有将列数作为独立的函数参数进行传递的原因。
示例:
int a[100][4];
int b[6][4];
int total1=sum(a,100);
int total2=sum(b,6);
示例2:
int sum(int ar2[][4],int size)
{
int total=0;
for(int r=0;r<size;r++) //双层循环
for(int c=0;c<4;c++)
total+=ar2[r][c];
return total;
}
ar2+r指向编号为r的元素,因此ar2[r]是编号为r的元素,由于该元素本身是一个4个int组成的数组,因此ar2[r]是由4个int组成的数组的名称。
将下标用于数组名将得到一个数组元素,因此ar2[r][c]是由4个int组成的数组中的一个元素,是一个int值。必须对指针ar2执行两次解除引用
最好的方法是两次方括号 ar2[r][c]
也可以使用运算符*两次
ar2[r][c]==*(*(ar2+r)+c)
ar2 指向二维数组的第一行
ar2+r 指向二维数组中的第r行
*(ar2+r) 指向二维数组中的第r行中的首元素
*(ar2+r)+c 指向二维数组中的第r行中的标签为c的元素
*(*(ar2+r)+c) 代表二维数组中的第r行中的标签为c的元素的数值
sum()的代码在声明参数ar2时,没有使用const 因为这种技术只能用于指向基本类型的指针,而ar2是指向指针的指针。
五 函数和c风格字符串
c风格字符串 一些列字符组成,以空值字符结尾。
将字符串作为参数时意味着传递的是地址,但是可以使用const来禁止对字符串参数进行修改。
1.将c字符串作为函数的参数
char数组
用引号括起的字符串常量 也称字符串字面量
被设置为字符串的地址的char指针
上面的三个都是char *
示例:char gohst[15]="asdfasdf";
char * str="adsfasdf";
int n1=strlen(ghost); ghost代表&ghost[0]
int n2=strlen(str); 指向char的指针
int n3=strlen(“adsfasdf”);括号中字符串的地址
所以 将字符串作为参数来传递,但实际传递的是字符串第一个字符的地址 字符串函数原型应将其表示字符串的形参声明为char * 类型
c风格字符串与常规char数组的一个重要区别是 字符串有内置的结束字符 但不以空值字符结尾的char数组只是数组,而不是字符串。
长度可以不用传递给函数 因为 函数可以检测字符串中的每个字符 如果遇到空值字符 就是停止。
示例:
#include <iostream>
unsigned int c_in_str(const char * str,char ch)
int main()
{
using namespace std;
char mmm[15]="minimum";
char * wail="ululate";
unsigned int ms=c_in_str(mmm,'m');
unsigned int us=c_in_str(wail,'u');
cout<<ms<<"m characters in"<<mmm<<endl;
cout<<us<<"u characters in"<<wail<<endl;
return 0;
}
unsined int c_in_str(const char * str,char ch)
{
unsigned int count=0;
while(*str)
{
if(*str==ch)
count++;
str++;
}
return count;
}
同样可行的方式:unsigned int c_in_str(const char str[],char ch)
函数本身演示了处理字符串中字符的标准方式
while(* str)
{
statements
str++;
}
其中*str表示的是第一个字符
当str指向空值字符时,*str等于0 表示空值字符的数字编码为0 则循环结束
函数无法返回一个字符串,但是可以返回一个字符串的地址,而且效率更高
示例2 strgback.cpp
#include <iostream>
char * buildstr(char c,int n); 原型
int main()
{
using namespace std;
int times;
char ch;
cout<<"enter a character: ";
cin>>ch; \\一个字符
cout<<"enter an integer: ";
cin>>times; \\一个整数
char *ps=buildstr(ch,times); \\返回地址
cout<<ps<<endl;
delete [] ps; \\清除ps指向的内存空间 数组
ps=buildstr('+',20);\\调用函数
cout<<ps<<"-done-"<<ps<<endl;
delete [] ps;
return 0;
}
char * buildstr(char c,int n)
{
char * pstr=new char[n+1];\\申请空间 数组存放 pstr为指向的指针
pstr[n]='\0'; \\下标为n的数组值为空值字符
while(n-->0) \\循环赋值
pstr[n]=c;
return pstr; \\返回字符数组的指针
}
创建包含n个字符的字符串,需要能够存储n+1个字符的空间,以便能够存储空值字符。
注意用new 申请的内存空间 必须记住用delete来释放
6 函数和结构
结构和数组不同 结构变量更接近于基本的单值变量,将其数据组合成单个实体或数据对象,该实体被视为一个整体。
可以将一个结构赋给另外一个结构。也可以按值传递结构,就像普通变量那样。
结构传递副本 函数也可返回结构
结构名不是地址,仅仅是结构的名称 如果想要得到结构的地址,必须使用地址运算符&
c++还是用该运算符来表示引用变量 &
1.传递和返回结构
适合结构比较小的情况
struct travel_time{ \\结构定义
int hours;
int mins;
}
travel_time sum(travel_time t1,travel_time t2); \\ 原型
travel_time day1={5,45};
travel_time day2={4,55};
travel_time trip=sum(day1,day2);\\调用
travel_time sum(travel_time t1,travel_time t2) \\被调用函数的实现
{
travel_time total;
statement;
return total; \\返回一个结构体变量
}
2.处理结构的示例
有关函数和c++结构的大部分知识都可以用于c++类中
示例:
\\strctfun.cpp
#include <iostream>
#include <cmath>
struct ploar \\用距离和角度来表示一个点
{
double distance;
double angle;
}
struct rect \\x和y的坐标表示点的位置
{
double x;
double y;
}
ploar rect_to_polar(rect xypos);\\原型声明
void show_polar(polar dapos);\\原型声明
int main()
{
using namespace std;
rect rplace;\\结构类型声明
ploar pplace;\\结构类型声明
cout<<"enter the x and y values: ";
while(cin>>rplace.x>>rplace.y)\\注意这里的cin>>rplace.x 返回cin类型 接着调用cin>>rplace.y
{
pplace=rect_to_polar(rplace);\\调用函数
show_polar(pplace);\\调用函数
cout<<"next two numbers (q to quit): ";
}
cout<<"done.\n";
return 0;
} \\end of main
ploar rect_to_polar(rect xypos) \\接受 rect结构体 返回ploar结构体
{
using namesapce std;
ploar answer;
answer.distance=sqrt(xypos.x*xypos.x+xypos.y*xypos.y); \\计算距离
answer.angle=atan2(xypos.y,xypos.x);\\计算角度
return answer;
}
void show_ploar(polar dapos)
{
using namespace std;
const double rad_to_deg=57.29577951;
cout<<"distance= "<<dapos.distance;
cout<<",angle="<<dapos.angle * rad_to_deg;\\角度转换
cout<<"* degrees\n";
}
2.传递结构的地址
传递结构的地址而不是整个结构以节省时间和空间,使用指向结构的指针。
调用函数,将结构的地址 &pplace而不是结构本身pplace传递给它;
将形参声明为指向polar的指针,即ploar* 类型。由于函数不应该修改结构,因此使用了const修饰符;
形参是指针而不是接哦股,因此应间接成员运算符-> 而不是成员运算符 句点。
修改后的代码如下 show_polar(const ploar *pda)和rect_to_polar()
\\strctfun.cpp
#include <iostream>
#include <cmath>
struct ploar \\用距离和角度来表示一个点
{
double distance;
double angle;
}
struct rect \\x和y的坐标表示点的位置
{
double x;
double y;
}
\\ploar rect_to_polar(rect xypos);\\原型声明
void rect_to_polar(const rect * pxy,ploar * pda);\\原型声明
void show_polar(const polar * pda);\\原型声明
int main( )
{
using namespace std;
rect rplace;\\结构类型声明
ploar pplace;\\结构类型声明
cout<<"enter the x and y values: ";
while(cin>>rplace.x>>rplace.y)\\注意这里的cin>>rplace.x 返回cin类型 接着调用cin>>rplace.y
{
\\pplace=rect_to_polar(rplace);\\调用函数
rect_to_polar(&rplace,&pplace);\\传递地址
show_polar(&pplace);\\调用函数 \\传递地址
cout<<"next two numbers (q to quit): ";
}
cout<<"done.\n";
return 0;
} \\end of main
ploar rect_to_polar(const rect * pxy,ploar * pda) \\接受 rect结构体 返回ploar结构体
{
using namesapce std;
pda->distance=sqrt(pxy->x*pxy->x+pxy->y*pxy->y); \\计算距离
pda->angle=atan2(pxy->y,pxy->x);\\计算角度
}
void show_ploar(const polar * pda)
{
using namespace std;
const double rad_to_deg=57.29577951;
cout<<"distance= "<<pda->distance;
cout<<",angle="<<pda->angle * rad_to_deg;\\角度转换
cout<<"* degrees\n";
}
上例使用了指针 函数能够对原始的机构进行操作;而上上例使用的是结构副本。
7.函数和string对象
c风格字符串和string对象的用途类似,但与数组相比,string对象与结构更相似。
结构可以赋值给结构,对象可以赋值给对象。
如果需要多个字符串,可以声明一个string对象的数组,而不是二维char数组,操作会更加灵活。
//topfive.cpp
#include <iostream>
#include <string>
using namespace std;
const int SIZE=5;
void display(const string sa[],int n);\\原型
int main()
{
string list[SIZE]; \\string对象数组
cout<<"enter your "<<SIZE<<" favorite astronomical sights: \n ";
for(int i=0;i<SIZE;i++)
{
cout<<i+1<<": ";
getline(cin,list[i]);\\初始化数组中的元素
}
cout<<" your list: \n ";
display(list,SIZE); \\传递过去指向string对象数组的指针 (即地址值 =数组名)
return 0;
}
void display(const string sa[],int n)
{
for(int i=0;i<n;i++)
cout<<i+1<<" : "<<sa[i]<<endl;
}
8.函数与array对象
c++中 类对象基于结构
所以:可以按值将对像传递给函数, 函数处理的是原始对象的副本。
可以传递对象的指针 函数内部直接操作原始的对象 通过指针
使用array对象来存储一年四个季度的开支:
std::array<double,4> expenses; 需要包含头文件array,而名称array位于名称空间std中。
函数show(expenses) 不能修改expenses
函数fill(&expenses) 可以修改expenses 传递进来的是指针
则函数的原型为:
void show(std::array<double,4> da);
void fill(std::array<double,4> * pa); \\pa指向array对象的指针
可以用符号常量来替换4
const int seasons=4;
const std::array<std::string,seasons> snames={"spring","summer","fall","winter"};
模板array并非只能存储基本数据类型,还可以存储类对象
//arrobj.cpp
#include <iostream>
#include <array>
#include <string>
const int seasons=4;
const std::array<std::string,seasons> snames={"spring","summer","fall","winter"}; //数组的声明
void fill(std::array<double,seasons> * pa);//原型定义 接收一个array的对象的指针
void show(std::array<double,seasons> da);//原型定义 接收一个array的对象
int main()
{
std::array<double,seasons> expenses; //定义
fill(&expenses);//填充 指针指向的array对象定义的double数组
show(expenses);//传值 并且显示 数组中的内容
return 0;
}
void fill(std::array<double,seasons> * pa) //接收指向数组的指针
{
using namespace std;
for(int i=0;i<seasons;i++)
{
cout<<"enter "<<snames[i]<<" expenses: ";
cin>>(*pa)[i]; //填充 数组元素
}
}
void show(std::array<double,seasons> da)
{
using namespace std;
double total=0.0;
cout<<" \n EXPENSES \n ";
for(int i=0;i<seasons;i++)
{
cout<<snames[i]<<" :$ "<<da[i]<<endl;//输出 个元素的值
total+=da[i];//相加各个元素的值
}
cout<<"total expenses: $ " <<total<<endl;
}
fill和show两个函数都有缺点。函数show()存在的问题是,expenses存储了四个double值,而创建一个新对象并将expenses的值赋值到其中的效率太低。
7.9递归
1.包含一个递归调用的递归
如果递归函数调用自己,则被调用的函数也将调用自己,这将无限循环下去,所以必须有终止调用链的内容。
void recurs(argumentlist)
{
statements1
if(test)
recurs(arguments)
statements2
}
示例:
recur.cpp
#include <iostream>
void countdown(int n)
int main()
{
countdown(4);
return 0;
}
void countdown(int n)
{
using namespace std;
cout<<"counting down ..."<<endl;
if(n>0)
countdown(n-1);
cout<<n<<":kaboom\n";
}
输出:
counting down ...4
counting down ...3
......
counting down ...0
0:kaboom!
1:kaboom!
......
4:kaboom!
7.9.2包含多个递归调用的递归
将一项工作不断分为两项或多项较小的工作时,递归会非常有用。
示例:绘制标尺 分而治之的策略
标出两端,找到重点并将其标出 然后将同样的操作用于标尺的左半部分和右半部分
//ruler.cpp
#include <iostream>
const int len=66;
const int divs=6;
void subdivide(char ar[],int low,int high,int level);//prototype
int main()
{
char ruler[len];//数组
int i;
for(i=1;i<len-2;i++)
ruler[i]=' ';//初始化数组中的值均为空格
ruler[len-1]='\0';//数组中最后一个元素的值为空值
int max=len-2;//数组下标范围设置
int min=0;
ruler[min]=ruler[max]='|';//初始化数组首尾两个元素的值为‘|’
std::cout<<ruler<<std::endl;//输出数组各项的值
for(i=1;i<=divs;i++)//6次循环 分别设置数组中的值 利用递归调用
{
subdivide(ruler,min,max,i);//当level=0时会从调用函数中返回
std::cout<<ruler<<std::endl;//输出数组中个元素的值 分次
for(int j=1;j<len-2;j++)
ruler[j]=' ';
}
return 0;
}
void subdivide(char ar[],int low,int high,int level)//递归函数设置数组值
{
if(level==0)
return;
int mid=(high+low)/2;
ar[mid]='|';
subdivide(ar,low,mid,level-1);//左边的数组 注意level的值是一直变化的
subdivide(ar,mid,high,level-1);//右边的数组
}
使用level来控制递归层,函数调用自身时,将把level减1,当level为0时,该函数将不再调用自己。 最初的中点被用作一次调用的右端点和另一次调用的左端点。
调用次数呈几何级增长,调用一次导致两个调用然后导致4个,然后8个 最后64个调用。
7.10函数指针
函数地址是存储机器语言代码的内存的开始地址
A.基础知识
一个函数以另一个函数作为参数 此时就会需要函数的地址
获取函数的地址
声明一个函数指针
使用函数指针来调用该函数
1.获取函数的地址
函数名即为函数的地址
有think()函数
例如:process(think) 传递函数的地址 作为参数
process(think()) 传递函数think()的返回值做为参数
2.声明函数指针
声明指针必须指定指针的类型。指向函数,也必须指定指针指向的函数的类型
声明需要指定函数的返回类型以及函数的参数列表
首先声明被传递的函数的原型
double pam(int);//prototype
double (*pf)(int); pf为指向函数的指针
提示:通常 用*pf替换原来函数原型中的函数名 就会得到函数的指针
上例中为*pf替换了pam
注意运算符号的优先级:
double (*pf)(int) 指向函数的指针
double *pf(int ) pf是一个返回指针的函数
正确的声明之后, 就可以将函数的地址赋给指针
pf=pam 注意声明中指针与原来的函数原型返回值和参数列表必须完全一致
作为参数传递
void estimate(int lines,double(*pf)(int)); 函数原型
estimate(50,pam); 调用
3.使用指针来调用函数
因为*pf等同于pam 所以直接使用*pf作为函数名即可
double x=pam(4); 用原函数调用
double y=(*pf)(5); 用指针调用
double y=pf(5); 此种方式也可以 仅仅在c++11 中
B 函数指针示例
//7.18 fun_prt.cpp
#include <iostream>
double betsy(int);//prototype
double pam(int);
void estimate(int lines,double (*pf)(int));
int main()
{
using namespace std;
int code;
cout<<"how many lines of code do you need?";
cin>>code;
cout<<"here's betsy's estimate:\n";
estimate(code,betsy);// 调用betsy函数
cout<<"here's pam's estimate:\n";
estimate(code,pam);//调用pam函数
return 0;
}
double betsy(int lns)
{
return 0.05*lns;
}
double pam(int lns)
{
return 0.03*lns+0.0004*lns*lns;
}
void estimate(int lines,double(*pf)(int))
{
using namespace std;
cout<<lines<<"lines will take";
cout<<(*pf)(lines)<<"hour(s)\n";
}
C 深入探讨函数指针
一下的声明完全相同
const double * f1(const double ar[],int n);//以数组的方式声明 ar[] 与指针*ar 作为参数时一样都是指针
const double *f2(const double [],int );省略标识符
const double *f4(const double *ar,int n);
const double *f3(const double *,int);指针形式
假设要声明一个指针,指向函数,如果指针名为pa 则只需将目标函数原型中的函数名替换为(*pa)即可
const double *(*pa)(const double *,int); pa=f3;
const double *(*pa)(const double *,int)=f3 同时初始化 等同与上一句
auto pa2=f1;使用c++11中的auto 自动类型推断功能 简化声明
示例:
cout<<(*pa)(av,3)<<":"<<*(*pa)(av,3)<<endl;
cout<<pa(av,3)<<":"<<*pa(av,3)<<endl;
f3返回值的类型为const double * 所以前面的输出都为函数的返回值 指向const double的指针 即地址值
而后面的输出均加上了* 解引用运算符 所以实际输出为指针指向的double值
D 函数指针数组
---恢复内容结束---
c++ primer plus 第6版 部分二 5- 章
第五章
计算机除了存储外 还可以对数据进行分析、合并、重组、抽取、修改、推断、合成、以及其他操作
1.for循环的组成部分
a 设置初始值
b 执行测试,看循环时候应当继续进行
c 执行循环操作
d 更新用于测试的值
只要测试表达式为true 循环体就会执行
for (initialization; test-expression; update-expression)
body
test-expression决定循环体是否被执行,通常这个表达式是关系表达式,c++会将此结果强制转换为bool类型。值0的表达式将被转换为bool值false,导致循环结束。
for 后面跟着一对括号 它是一个c++关键字 因此编译器不会将for视为一个函数
1. 表达式和语句
任何值或任何有效的值和运算符的组合都是表达式。c++中每个表达式都有值。通常值是很明显的。
c++将赋值表达式的值定义为左侧成员的值,因此这个表达式的值为20.由于赋值表达式有值,可以编写
maids=(cooks=4)+3; 值为7
赋值表达式从右向左结合
x<y 这样的关系表达式被判定为true或者false
int x;
cout<<(x=100)<<endl; //x=100
cout<<(x<3)<<endl; //0
cout<<(x>3)<<endl; //1
cout.setf(ios_base::boolalpha);//老式的c++实现使用ios:boolalpha 来作为setf()的参数
cout<<(x<3)<<endl; //false
cout在现实bool值之前将他们转换为int 但是cout.setf(ios::boolalpha) 函数调用设置了一个标记,该标记命令cout显示true和false 而不是1和0;
判定表达式的值 改变了内存中数据的值时,表达式有副作用 side effect。
例如x++ 判定赋值表达式 改变了x的值 所以有副作用
有例如x+100 判定赋值表达式 计算出一个新值 未改变x的值 所以没有副作用
表达式到语句的转换非常容易 只需要加上分号即可。
2.非表达式和语句
返回语句 声明语句 和for语句都不满足“语句=表达式+分号”这种模式
int a; 这是一条语句 但是int a并不是表达式 因为它没有值
所以这些代码是非法的:
eggs=int a *1000;
cin>>int a;
不能把for循环赋值给变量
3.修改规则
c++ 在c循环的基础上添加了一些特性 可以对for循环句法做一些调整
for(expression;expression;expression)
statement;
示例:
for(int i=0;i<5;i++) int i=0 叫做生命语句表达式 (不带分号的声明) 此种只能出现在for语句中
其中 int i=0 为声明 不是表达式 这由于上面的语法向矛盾
所以这种调整已经被取消
修改之后的语法:
for (for-init-statement condition;expression)
statement
感觉奇怪,这里只用了一个分号,但是这是允许的因为for-init=statement被视为一条语句,而语句有自己的分号。对于for-init-statement来说,它既可以是表达式语句,也可以是声明。
语句本身有自己的分号,这种句法规则用语句替换了后面跟分号的表达式。在for循环初始化部分中声明和初始化变量。
在for-init-statement中声明变量还有其实用的一面。这种变量只存在于for语句中,当程序离开循环后,这种变量将消失。
for(int i=0;i<5;i++)
较老的c++实现遵循以前的规则,对于前面的循环,将把i视为在循环之前声明 所以在循环结束后,i变量仍然存在。
4.回到for循环
const int arsize=16;// 定义整型的常量 在下方程序中使用 数组长度的定义
for(int i=2;i<arsize;i++) //i<arsize 下标从0到arsize-1 所以数组索引应该在arsize-1的位置停止。也可以使用i<=arsize-1 但是没有前面的表达式好。
5.修改步长
之前的循环计数都是加1或者减1 可以通过修改更新表达式来修改步长。i=i+by
int by;
cin>>by;
for(int i=0;i<100;i=i+by)
注意检测不等号通常要比检测相等要好。上例中如果将i<100改为i==100 则不可行 因为i的取值不会为100
using声明和using编译指令的区别。
6.使用for循环访问字符串
示例:
#include <iostream>
#include <string>
int main(){
using namespace std;
cout<<"enter a word"<<endl;
string word; //定义对象
cin>>word;
for(int i=word.size()-1;i>=0;i--) //word对象的字符串长度 size成员函数
cout<<word[i]; //输出各个字符
cout<<"\n----Bye.\n"<<endl;
return 0;
}
如果所用的实现没有添加新的头文件,则必须使用string.h 而不是cstring
7.递增运算符++ 递减运算符--
都是讲操作数相加或者相减 他们有两种不同的形式 一种为前缀 另一种为后缀 ++x x++
但是他们对操作数的影响的时间是不同的
int a=20 b=20;
cout<<"a++="<<a++<<"++b= "<<++b<<endl;
cout<<"a="<<a<<"b= "<<b<<endl;
a++为使用a的当前值计算表达式 然后将a的值加1 使用后修改
++b是先将b的值加1,然后使用新的值来计算表达式 修改后再使用
8.副作用 和顺序点
side effect 副作用
指的是在计算表达式时对某些东西进行了修改 例如存储在变量中的值
顺序点是程序执行过程中的一个点。c++中 语句中的分号就是一个顺序点 这就意味着程序处理下一条语句之前,赋值运算符、递增运算符和递减运算符执行的所有修改都必须完成。任何完整的表达式末尾都是一个顺序点。
表达式的定义:不是另外一个表达式的子表达式
顺序点有助于阐明后缀递增何时进行
while(guest++<10)
cout<<guests<<endl;
类似于只有测试表达式的for循环。可能会被认为是使用值然后再递增即cout中先使用guests的值 然后再将其值加1。
但是guests++<10 是一个完整的表达式,因为它是while循环的一个测试条件。所以该表达式的末尾是一个顺序点。所以c++确保副作用(将guests+1) 在程序进入cout之前完成,然而使用后缀的格式,可以确保将guests同10进行比较后再将其值加1。
y=(4+x++)+(6+x++);
表达式4+x++不是一个完整的表达式,因此,c++不保证x的值在计算子表达式4+x++后立刻增加1;在这个例子中 红色部分是一个完整的表达式 其中的分号标示了顺序点,因此c++只保证程序执行到下一条语句之前,x的值将被递增两次。c++没有规定是在计算每个子表达式之后将x的值递增,还是在整个表达式计算完毕后才将x的值递增,有鉴于此,应该避免使用这样的表达式。
c++11文档中,不再使用术语“顺序点”了,因为这个概念难以用于讨论多线程执行。相反,使用了术语“顺序”,它表示有些事件在其他事件前发生。这种描述方法并非要改变规则,而旨在更清晰第描述多线程编程。
10.前缀格式和后缀格式
显然,如果变量被用于某些目的(如用作函数参数或给变量赋值),使用前缀格式和后缀格式的结果将是不同的。然而,如果递增表达式的值没有被使用,情况会变得不同例如
x++;
++x;
for(n=lim;n>0;--n)
for(n=lim;n>0;n--)
从逻辑上说,在上述两种情形下,使用前缀格式和后缀格式没有任何区别。表达式的值未被使用,因此只存在副作用。
在上面的例子中使用这些运算符的表达式为完整表达式,因此将x+1和n-1的副作用将在程序进入下一步之前完成,所以前缀与后缀格式的最终效果相同。
前缀与后缀的区别2:它们的执行速度有略微的差别 虽然对程序的行为没有影响
c++允许您针对类定义这些运算符,在这种情况下,用户这样定义前缀函数:将值加1然后返回结果。
后缀版本:首先复制一个副本,将其加1 然后将复制的副本返回
显然前缀的效率要比后缀版本高。
总之,对于内置类型,采用哪种格式不会有差别;但是对于用户定义的类型,如果有用户定义的递增和递减运算符,则前缀格式的效率更高。
11.递增/递减运算符和指针
可以将递增运算符用于指针和基本变量。将递增运算符用于指针时,将把指针的值增加其指向的数据类型占用的字节数,这种规则适用于对指针递增和递减。
double arr[5]={21.1,32.8,23.4,45.2,37.4}
double * pt=arr; //pt points to arr[0],i.e. to 21.1
++pt;//指向arr[1] i.e. to 32.8
也可以结合使用这些运算符来修改指针指向的值。将*和++同时用于指针时提出了这样的问题:
将什么解除引用,将什么递增?
取决于运算符的位置和优先级。
1.前缀递增、后缀递减和解除引用运算符的优先级相同,以从右到左的方式进行结合。
2.后缀递增和后缀递减的优先级相同,但是比前缀运算符的优先级高,这两个运算符以从左到右的方式进行结合。
例如:*++pt的含义 先将++应用于pt 然后再将*应用于递增后的pt pt的指向已经变化
++*pt 先取得pt指向的值,然后再将这个值加1 pt的指向没有变化
(*pt)++ pt指针先解除引用 得到值 然后再加1 原来为32.8 之后的值为32.8+1=33.8 pt的指向未变
x=*pt++; 后缀的运算符++的优先级更高,意味着将运算符用于pt 而不是*pt,因此对指针递增。然后后缀运算符意味着将对原来的地址&arr[2],而不是递增后的新地址解除引用,因此*pt++的值为arr[2],
#include <iostream>
int main(){
using namespace std;
int word[10]={1,2,3,4,5,6,7,8,9,10};//定义数组
int *pt= word; //定义指针指向的数组
int x;
for(int i=0;i<10;i++)
cout<<word[i]<<" , ";
cout<<endl;
cout<<&word<<endl;//输出数组首地址
cout<<pt<<endl; //指针的方式输出数组首地址
for(int i=0;i<10;i++)
{
cout<<"dizhi= "<<&(word[i])<<" "; //输出数组的每个元素的地址
cout<<"*pt++= "<<*pt++<<" "; //输出指针形式的每个元素
cout<<"&pt=="<<pt<<endl; //地址的变化 关键是查看这两行
}
return 0;
}
12.组合赋值运算符
i=i+by 更新循环计数
i+=by
+=运算符将两个操作数相加,并将结果赋值给左边的操作数。这意味着左边的操作数必须能够被赋值,如变量、数组元素、结构成员或者通过对指针解除引用来标识的数据:
示例:
k+=3; 左边可以被赋值 可以k=k+3
int * pa= new int[10]; pa指向数组int
pa[4]=12;
pa+=2; pa指向 pa[4]
34+=10; 非法 34不是一个变量 不可以被赋值
13.复合语句 (语句块)
for循环中的循环体 就是复合语句 由大括号括进
外部语句块中定义的变量在内部语句块中也定义的变量 情况如下:在声明位置到内部语句块结束的范围之内,新变量将隐藏旧变量,然后旧变量再次可见如下
#inlcude <iostream>
{ using namespace std;
int x=20; //原始的变量
{ //代码块开始
cout<<x<<endl; //使用原始的变量 20
int x=100; //定义新的变量
cout<<x<<endl; //使用新的变量 100
}
cout<<x<<endl; //使用旧的变量 20
return 0;
}
14.其他语法技巧----逗号运算符
语句块允许把两条或更多条语句放到按c++句法只能放一条语句的地方。
逗号运算符对表达式完成同样的任务,允许将两个表达式放到c++句法只允许放一个表达式的地方。
例如循环控制部分的更新部分 只允许这里包含一个表达式,但是有i和j两个变量,想同时变化 此时就需要逗号运算符将两个表达式合并成一个
++j,--i 这两个表达式合并成一个
逗号并不总是逗号运算符 例如 声明中的逗号将变量列表中相邻的名称分开:
int i,j;
for(j=0,i=word.size()-1;j<i;--i,++j)
逗号运算符另外的特性:确保先进算第一个表达式,然后计算第二个表达式(逗号运算符是一个顺序点)
i=20,j=2*i
另外逗号表达式的值为上面第二部分的值 上面为40,因为j=2*i的值为40. 逗号的运算符的优先级是最低的。
data=17,24 被解释为(data=17),24 结果为17 24不起作用
data=(17,24) 结果为24 因为括号的优先级最高 从右向左结合 括号中的值为24(逗号右侧的表达式的值) 所以data的值最后为24
15 关系表达式
关系运算符的优先级比算数运算符的低。 注意将bool的值提升为int后,3>y要么是1 或者是0 所以表达式有效
for(x=1;y!=x;++x) 有效
for(cin>>x;x==0;cin>>x)
(x+3)>(y-2) 有效
x+(3>y)-2 有效
16赋值 比较和可能犯的错误
== 和= 是有区别的 前者是判断 关系表达式 后者是赋值表达式
如果用后者则当在for循环中 测试部分将是一个复制表达式 ,而不是一个关系表达式,此时虽然代码仍然有效,但是赋值表达式 为非0 则结果为true 。
示例:测试数组中的分数
for(i=0;scores[i]==20;i++) 测试成绩是否为20 原来的数组值不变
for(i=0;socres[i]=20;i++) 测试成绩是否为20 但是原来的数组值已经都赋值为20了
1.赋值表达式 为非0 则 始终为true 2.实际上修改的数组的元素的数据 3. 表达式一直未true 所以程序再到达数组结尾后,仍然在不断地修改数据
但是代码在语法上是正确的,因此编译器不会将其视为错误
对于c++类,应该设计一种保护数组类型来防止越界的错误。循环需要测试数组的值和索引的值。
17.c风格字符串的比较
数组名代表数组首地址
引号括起来的字符串常量也是其地址
所以word=="mate" 并不是判断两个字符串是否相同,而是查看它们是否存储在相同的地址上 前者为数组 后者为字符串常量 ,所以两个地址一定是不同的,即使word数组中的数据是mate字符串。
由于c++将c风格的字符串视为地址,所以使用关系运算符来比较它们,将不会得到满意的结果。
相反应该使用c风格字符串库中的strcmp()函数来比较。 此函数接收两个字符串地址作为参数,参数可以使指针、字符串常量或者字符数组名,如果两个字符串相同,则函数返回0;如果第一个字符串的字母顺序排在第二个字符串之前,则strcmp()函数将会返回一个负值,相反则返回一个正值。
还有按照“系统排列顺序”比“字母顺序”更加准确,此时意味着字符是针具字符的系统编码来进行比较的ascii码。所有的大写字母的编码都比小写字母要小,所以按顺序排列,大写位于小写之前。
另一个方面 c字符串通过结尾的空值字符定义,而不是数组的长度
所以char big[80]="daffy" 与 char little[10]="daffy" 字符串是相同的
不能用关系运算符来比较字符串,但是可以用来比较字符,因为字符实际上是整型 所以可以用下面的代码显示字母表中的字符
for(ch='a';ch<='z';ch++)
cout<<ch;
示例:
#include <iostream>
#include <cstring>
int main(){
using namespace std;
char word[5]="?ate"; //定义字符数组
for(char ch='a';strcmp(word,"mate");ch++)//判断字符数组中的首元素是否为m 为循环的条件 如果不是则返回负值 非0 所以为真,直到 ch=l时 ch++=m strcmp返回0 =false 结束循环
{
cout<<word<<endl;
word[0]=ch;//修改字符数组的首元素为ch
}
cout<<"after loop ends,word is "<<word<<endl;
return 0;
}
检测相等或排列顺序
可以使用strcmp()来测试c风格字符串是否相等 排列顺序,如果str1和str2相等,则下面的表达式为true
strcmp(s1,s2)==0 s1 s2相等 函数返回0 0==0 则为true
strcmp(s1,s2)!=0 s1 s2相等 .. 0!=0 、为false
strcmp(s1,s2) s1 s2相等返回0 为false
strcmp(s1,s2)<0 s1在s2的前面为true s1-s2<0
所以根据测试的条件 strcmp()可以扮演== != <和>运算符的角色
char实际上是整型 修改char 类型的操作实际上是修改存储在变量中的整数的编码 另,使用数组索引可使修改字符串中的字符更为简单
18.比较string类字符串
使用string类的字符串 比使用c风格字符串要简单 类设计可以使用关系运算符进行比较。
原因是因为类函数重载(重新定义)了这些运算符
示例:
#include <iostream>
#include <string> //头文件不同
int main(){
using namespace std;
string word="?ate"; //定义字符串对象
for(char ch='a';word!="mate";ch++)//循环
{
cout<<word<<endl;
word[0]=ch;//修改字符数组的首元素为ch
}
cout<<"after loop ends,word is "<<word<<endl;
return 0;
}
程序说明:
word!="mate" 使用了关系运算符 左边是一个string类的对象,右边是一个c风格的字符串
string类重载运算符!=的方式可以使用的条件:
1.至少有一个操作数为string对象,另一个操作数可以是string对象,也可以是c风格字符串
2.此循环不是计数循环 并不对语句块执行指定的次数,相反 它根据实际的情况来确定是否停止。 此种情况通常使用while循环
二 while循环
while循环是没有初始化和更新部分的for循环 它只有测试条件和循环体
while (test-condition)
body
首先程序计算圆括号内测试条件表达式 如果表达式为true 则执行body 如果表达式维false 则不执行
body代码中必须有完成某种影响测试条件表达式的操作。 例如 循环可以将测试条件中的变量加1或者从键盘输入读取一个新值。
while循环也是一种入口条件循环。因此 测试条件一开始便为false 则程序将不会执行循环体。
while(name[i]!='\0')
测试数组中特定的字符是不是空值字符。
1.for与while
本质上两者是相同的
for(init-expression;test-expression;update-expression)
{ statement(s) }
可以写成如下的形式
init-expression;
while(test-expression)
{
statement(s)
update-expression;
}
同样的
while(test-expression) body
可以写成
for(;test-expression;)
body
for循环需要3个表达式 技术上说,需要1条后面跟两个表达式的语句。不过它们可以是空表达式,只有两个分好是必须的。
另外for循环中 省略测试表达式时 测试结果将是true 因此 for(;;) body 会一直执行下去
差别:
1.for 没有测试条件 则条件为true
2.for中可以使用初始化语句声明一个局部变量 但是while不能这样做
3.如果循环体中包含continue语句 情况将会有所不同。
通常如果将初始值,终止值和更新计数器的、都放在同一个地方,那么要使用for循环格式
当在无法预先知道循环将执行的次数时,程序员常使用while循环
当使用循环时 要注意下面的几条原则
1.指定循环终止的条件
2.在首次测试之前初始化条件
3.在条件被再次测试之前更新条件
错误的标点符号
for循环和while循环都由用括号括起的表达式和后面的循环体(包含一条语句)组成。
语句块 由大括号括起 分号结束语句
2.等待一段时间,编写延时循环
clock()函数 返回程序开始执行后所用的系统时间
#include <iostream>
#include <ctime>//describes clock() function, clock_t loop
int main()
{
using namespace std;
cout<<"enter the delay time,in seconds: ";
float secs;
cin>>secs;
clock_t delay=secs * CLOCKS_PER_SEC;//转化成clock ticks的形式 始终滴答形式
cout<<"starting\a\n";
clock_t start=clock();
while(clock()-start<delay)//等待时间 直到为假时跳出循环
; // 空操作 空语句
cout<<"done \a\n";
return 0;
}
头文件ctime (time.h) 提供了这些问题的解决方案。首先,定义了一个符号常量--CLOCKS_PER_SEC 该常量等于每秒钟包含的系统时间单位数。因此,将系统时间除以这个值,可以得到秒数。或者将秒数乘以CLOCK_PER_SEC 可以得到以系统时间单位为单位的时间。其次,ctime将clock_t作为clock()返回类型的别名 ,这意味着可以将变量声明为clock_t类型 编译器将把它转换为long 、unxigned int 或者适合系统的其他类型。
类型的别名
c++为类型建立别名的方式有两种。
一种是使用预处理器:
#define BYTE char
这样预处理器将在编译程序时用char 替换所有的BYTE,从而使BYTE称为char的别名
第二种是使用c++和c的关键字typedef来创建别名。例如要讲byte作为char的别名,
typedef char byte;
通用格式:typedef typeName aliasName; aliasName为别名
两种比较
示例:
#define FLOAT_POINTER float *
FLOAT_POINTER pa,pb;
预处理器置换将该声明转换为如下的形式
float *pa,pb; 此时 pa为指针 而pb不是指针 只是float类型
typedef 方法不会有这样的问题 它能够处理更加复杂的类型别名 最佳选择,有时候是唯一的选择
不会创建新的类型 仅仅是这种类型的另一个名称
三 do-while循环
前面两种是入口条件的循环 ,而这种事出口条件的循环 意味着这种循环将首先执行循环体,然后再判定测试表达式,决定是否应该继续执行循环。如果条件为false 则循环终止。否则进入新的执行和测试。 此时循环体至少要循环一次。
do
body
while(test-expression);
通常情况下 入口条件循环要比出口条件循环好 因为入口条件循环在循环开始之前对条件进行检查,但是有时候需要do while更加合理 例如请求用户输入时,程序必须先获得输入,然后对它进行测试
//dowhile.cpp
#include <iostream>
int main(){
using namespace std;
int n;
cout<<"enter number in the range 1-10 to find"<<endl;
cout<<"my favorite number\n";
do{
cin>>n;//接收键盘的输入
}
while (n!=7);//当 输入的值不等于7时 判别式为真值 继续循环 等于7就退出循环 进行下面的语句的执行
cout<<"yes,7 is my favorite.\n";
return 0;
}
奇特的for循环
int i=0;
for(;;)
{
i++;
cout<<i<<endl;
if(30>=i) break;
}
或者另外一种变体
int i=0;
for(;;i++)
{
if(30>=i) break;
//do something
}
上述的代码基于这样的一个事实:for循环中的空测试条件被视为true。 不利于阅读 在do while中更好的表达它们的意思
int i=0;
do{
i++;
//do something
}while(30>=i);
第二个例子的转化
while(i<30)
{
//do something;
i++;
}
4.基于范围的for循环(c++11)
c++11新增的一种循环
基于范围 range-based的for循环:对数组(或容器类,如vector和array)的每个元素执行相同的操作
double prices[5]={4.99,10.99,6.87,7.99,8.49};
for(double x:prices)
cout<<x<<std::endl;
其中x最初表示数组prices的第一个元素。显示第一个元素后,不断执行循环,而x依次表示数组的其他元素。因此,上述代码显示全部5个元素,每个元素占据一行。总之,该循环显示数组中的每个值,要修改数组的元素,需要使用不同的循环变量的语法:
for(double &x:prices)
x=x*0.80;
示例1
#include <iostream>
int main(){
using namespace std;
double prices[5]={4.99,10.99,6.87,7.99,8.49};
for(double x:prices) //x最初表示首元素 之后x依次表示数组的其他元素
cout<<x<<endl;
return 0;
}
将上面的代码中的循环更改为for(double &x:prices)
x=x*0.80; //价格变为8折
&表明x是一个引用变量(而不是取地址),这种声明让接下来的代码能够修改数组的内容,而第一种语法不能。
也可以使用基于范围的for循环
for(int x:{3,5,2,8,6})
cout<<x<<" ";
5.循环和文本输入
系统中最常见的 最重要的任务:逐字符地读取来自文件或键盘的文本。
例如想编写一个能够计算输入中的字符数,行数和字数的程序,c++与c在i/o工具不尽相同 cin对象支持3中不同模式的单字符输入,其用户接口各部相同。
1.使用原始的cin进行输入
如果程序要使用循环来读取来自键盘的文本输入,则必须要知道何时停止读取。一种方法就是选择某个字符 作为哨兵字符 将其作为停止标记。
示例:
//testin1.cpp
#include <iostream>
int main(){
using namespace std;
char ch;
int count=0;
cout<<"enter characters;enter # to quit:\n";
cin>>ch;
while(ch!='#')//以#字符为终止符 如果输入中不是# 就继续执行循环
{
cout<<ch;
++count;
cin>>ch;//读取下一个字符 很重要 如果没有此条,就会重复处理第一个字符
}
cout<<endl<<count<<"characters read\n";
return 0;
}
程序说明
此循环遵循了前面的循环原则,结束条件为最后读取的字符为#,在循环之前读取一个字符进行初始化,而通过循环体结尾读取下一个字符进行更新。
在输入时 可以输入空格和回车 但是在输出时,cin会将输入的字符中的空格和换行符忽略。所以输入的空格或者回车符没有被回显,也没有被包括在计数内。
更加复杂的是,发送给cin的输入被缓冲,这意味着只有在用户按下回车键后,他输入的内容才会被发送给程序。这就是在运行该程序时,可以在#后面输入字符的原因。按下回车键后,这个字符序列讲被发送给程序,但是程序在遇到#字符后将结束对输入的处理。
2.使用cinget(char)进行补救
通常,逐个字符读取输入的程序需要检查每个字符,包括空格、制表符和换行符。cin所属的istream类(在iostream中定义)中包含一个能够满足这种要求的成员函数。
cin.get(ch)读取输入中的下一个字符(即使它是空格),并将其赋值给变量ch。使用这个函数调用替换cin>>ch,可以修补上面程序的问题
//testin1.cpp
#include <iostream>
int main(){
using namespace std;
char ch;
int count=0;
cout<<"enter characters;enter # to quit:\n";
cin.get(ch); //会显示空格 制表符等其他的字符
while(ch!='#')
{
cout<<ch;
++count;
cin.get(ch);
}
cout<<endl<<count<<"characters read\n";
return 0;
}
程序说明:可能的误解:c语言中 cin.get(ch)调用将一个值放在ch变量中,这意味着将修改该变量的值
c中要修改变量的值,必须将变量的地址传递给函数。
在上例中 cin.get() 传递的是ch 而不是&ch 在c中此代码无效,但是在c++中有效,只要函数将参数声明为引用即可。
引用在c++中对比c新增的一种类型。头文件iostream 将cin.get(ch)的参数声明为引用类型,因此该函数可以修改其参数的值。
3.使用哪一个cin.get()
char name[arsize];
...
cout<<"enter your name:\n";
cin.get(name,arsize).get();//相当于两个函数的调用。 cin.get(name,arsize);cin.get();
cin.get 的一个版本接收两个参数 :数组名 (地址)和arsize (int 类型的整数) 数组名的类型为 char *
cin.get() 不接收任何参数
cin.get(ch) 只有一个ch参数
在c中不可想象 参数数量不够 或过多 会造成函数的出错
但是在c++中,这种被称为函数重载的oop特性 允许重载创建多个同名函数,条件是它们的参数列表不同。如果c++中使用cin.get(name,arsize),则编译器将找到使用char* 和int作为参数的cin.get()版本。 如果没有参数,则使用无参的版本。
4.文件尾条件
如果正常的文本中#正常的字符 那么用#来用作结尾符不会合适
如果输入来自于文件,可以使用一种功能更加强大的技术 EOF 检测文件尾。
c++输入工具和操作系统协同工作,来检测文件尾并将这种信息告知程序。
cin和键盘输入 相关的地方是重定向 < 或者 >符号
操作系统允许通过键盘来模拟文件尾条件。
在unix中 可以在行首按下CTRL+D来实现。
在windows命令提示符下,可以在任意位置按CTRL+Z和enter
很多的pc编程环境都讲CTRL+z视为模拟的EOF
检测EOF的方法原理:
检测EOF后,cin将两位(eofbit和failbit)都设置为1;
查看eofbit是否被设置 使用成员eof()函数
如果检测到EOF,则cin.eof()将返回bool值true,否则返回false。
同样,如果eofbit或者fialbit被设置为1,则fail()成员函数返回true,否则返回false。
eof()和fial()方法报告最近的读取结果。因此应将cin.eof() 或者cn.fail()测试放在读取后
#include <iostream>
int main()
{
using namespace std;
char ch;
int count=0;
cin.get(ch);
while(cin.fail()==false)//判断cin.fail()的值 是否被设置,如果ctrl+z 和enter 已经按下 则返回true 条件不符合,跳出循环
{
cout<<ch;
++count;
cin.get(ch);
}
cout<<endl<<count<<"characters read\n";
return 0;
}
程序说明:windows 7系统上运行该程序,因此可以按下ctrl+z和回车键来模拟EOF条件,在unix和类unix(包括linux)等系统张,用户可以按ctrl+z组合键将程序挂起,而命令fg恢复程序的执行。
通过使用重定向,可以用此程序来显示文本文件。并报告它包含的字符数 主要在unix中测似乎
1.EOF结束输入
cin方法检测到EOF时,将设置cin对象中一个指示EOF条件的标记。设置这个标记后,cin将不读取输入,再次调用cin也不管用。
上面的情况 是对文件的输入有道理,因为程序不应该读取超出文件尾的内容
对于键盘的输入,有可能使用模拟EOF来结束循环,但是稍后还要读取其他输入。
cin.clear()方法用来清除EOF标记,使输入继续进行。
在有些系统中CTRL+Z实际上会结束输入和输出。 而cin.clear()将无法恢复输入和输出。
2.常见的字符输入做法
每次读取一个字符,直到遇到EOF的输入循环的基本设计如下:
cin.get(ch);
while(cin.fail()==false) //这里可以用!逻辑运算符 去掉等号 while(!cin.fail())
{
...
cin.get(ch);
}
方法cin.get(char)的返回值是一个cin对象。然而,istream类提供了一个可将istream对象转换为bool值的函数;
当cin出现在需要bool值的地方(如在while循环的测试条件中)时,该转换函数将被调用。另外,如果最后一次读取成功了,则转换得到的bool值为true;否则为false。
意味着可以改写为
while(cin)//while input is successful
这样比!cin.fail()或者!cin.eof()更通用,因为它可以检测到其他失败的原因,如磁盘故障
最后,由于cin.get(char)的返回值为cin,因此可以将循环精简成这种格式:
while(cin.get(sh))
{
...
}
这样 cin.get(char)只被调用了一次,而不是两次:循环前一次、循环结束后一次。为判断循环测试条件,程序必须首先调用cin.get(ch).如果成功,则将值放入ch中。然后,程序获得函数调用的返回值,即cin。之后对cin进行bool转换,如果输入成功,则结果为true,否则为false。三条指导原则 全部被放在循环条件中。
5.另一个cin.get()版本
旧式的c代码 i/o函数 getchar()和putchar()函数 仍然适用,只要像c语言中那样包含头文件stdio.h或者新的cstdio即可。
也可以使用istream和ostream类中类似功能的成员函数。
cin.get() 不接受任何参数 会返回输入中的下一个字符
ch=cin.get();
与getchar()相似,将字符编码作为int类型返回;
cn.get(ch)则会返回一个对象,而不是读取的字符。
cout.put(ch) 显示字符 此函数类似于c中的putchar() 只不过参数类型为char 而不是int
put()最初只有一个原型 put(char) ,可以传递一个int参数给它,该参数将被强制转换为char。c++标准还要求只有一个原型。然后c++的有些实现都提供了3个原型
参数分别为char signed char unsigned char 。这些实现中如果给put()传递一个int参数将导致错误消息,因为转换int的方式不止一种,如果使用显式强制类型转换的原型(cin.put(char(ch)))可以使用int参数
成功使用cin.get() 需要了解EOF条件。
当函数到达EOF时,将没有可以返回的字符。相反,cin.get()将返回一个用符号常量EOF表示的特殊值。该常量是在头文件iostream中定义的。EOF值必须不同于任何有效的字符值,以便程序不会将EOF于常规字符混淆。通常EOF被定义为值-1,因为没有ascii码为-1的字符,但并不需要知道它实际的值,在程序中使用EOF即可。
示例:
char ch; 替换为 int ch;
cin.get(ch); 替换为 ch=cin.get();
wihile(cin.fail()==false) 替换为ch!=EOF
{
cout<<ch; 替换为:ch.put(ch);
++count;
cin.get(ch); 替换为:ch=cin.get();
}
上面代码的功能是 如果ch是一个字符,则循环将显示它,如果ch为EOF 则循环将结束
需要知道的是 EOF不表示输入中的字符,而是指出没有字符。
//testin4.cpp
#include <iostream>
int main(void)
{
using namespace std;
int ch;
int count=0;
while((ch=cin.get())!=EOF) //获取字符 并将字符的int型的编码赋值给ch 然后再判断与-1(EOF)是否相等
{
cout.put(char(ch)); //将int型编码的ch 强制转换为char类型 并且输出
++count;
}
cout<<endl<<count<<"characters read\n";
return 0;
}
注意,有些系统 如果对EOF不完全支持,如果使用cin.get()来锁住屏幕直到可以阅读它,将不起作用,因为检测EOF时将禁止进一步读取输入。可以使用循环计时来使屏幕停留一段时间。 也可以使用cin.clear来重置输入流。
尽量使用cin.get(char) 这种返回cin对象的方式,get成员函数的主要用途是能够将爱那个stdio.h的getchar()和putchar()函数转换为iostream的cin.get()和cout.put()方法。只要用头文件iostream替换为stdio.h 并用作用相似的方法替换所有的getchar()和putchar()即可。
6.嵌套循环和二维数组
1. int a[4][5]二维数组
a[0] 为二维数组的首元素,而首元素又是包含5个元素的数组
2.for(int row=0;row<4;row++) //行
{
for(int col=0;col<5;++col)//列
cout<<a[row][col]<<"\t";
cout<<endl;
}
3.初始化二维数组
int a[2][3]={
{15,25,35},{17,28,49}
}
也可以 int a[0]={15,25,35}
int a[1]={17,28,49}
4.使用二维数组
//nested.cpp
#include <iostream>
const int Cities=5;
const int years=4;
int main()
{
using namespace std;
const char * cities[Cities]= //指针数组
{
"girbble city","gribbletown","new grebble","san gribble","gribble vista"
};
int maxtemps[years] [Cities]= //二维数组
{
{96,100,87,101,105},{96,98,91,107,104},{97,101,93,108,107},{98,103,95,109,108}
};
cout<<"maximum temperatures for 2008 -2011\n\n";
for(int city=0;city<Cities;++city)
{
cout<<cities[city]<<"\t";
for(int year=0;year<years;++year)
cout<<maxtemps[year][city]<<"\t";
cout<<endl;
}
return 0;
}
在此例中,可以使用char数组的数组,而不是字符串指针数组
char cities[Cities][25]
{
"Gribble City",
"Gribbletown",
"New Gribble",
"San Gribble",
"Gribble Vista"
};
此种方法将全部5个字符串的最大长度限制为24个字符。指针数组存储5个字符串的地址,而使用char数组的数组时,将5个字符串分别赋值到5个包括25个元素的char数组中。因此,从存储空间的角度说,使用指针数组更为经济;但是char数组的数组更容易修改其中的一个字符串。
方法2:
可以使用string对象数组 而不是字符串指针数组
const string cities[Cities]={
"Gribble City",
"Gribbletown",
"New Gribble",
"San Gribble",
"Gribble Vista"
}
如果希望字符串是可修改的,则应该省略限定符const。使用string 对象数组时,初始化列表和用于显示字符串的for循环代码与前两种方法中相同。在希望字符串是可修改的情况下,string类自动调整大小的特性将使这种方法比使用二维数组更为方便。
第六章 分支语句
1.
if(test-condition)
statement
2.
if(test-condition)
statement1
else
statement2
3.格式化if else 语句
if(){}
else{}
或者
if(){} else if(){} else{}
tips:条件运算符和错误防范
variable==value 反转为value==variable
以此来捕获将相等运算符误写为赋值运算符的错误
意思就是 if(3==a) 可以避免写成if(3=a) 编译器会生成错误的信息,因为它以为程序员试图将一个值赋值给一个字面值(3总是等于3,而不是将另一个值赋值给它)
假如省略了其中的一个等号 if(a=3) 就不会出现错误信息 没有 if(3=a) 更好
2.逻辑表达式
a || 或运算符 比关系运算符的优先级要低
此运算符是一个顺序点 sequence point 也就是说 先修改左侧的值,再对右侧的值进行判定c++11侧说法是 运算符左边的子表达式先于右边的子表达式
如果左侧的表达式为true 则c++将不会去判定右侧的表达式
cin>>ch;
if(ch=='y'||ch=='Y')
cout<<"You were warned!\a\a\n";
else if(ch=='n'||ch=='N')
cout<<"A wise choice ... bye\n";
else ....
程序只读取一个字符,所以只读取响应的第一个字符。这意味着用户可以用NO! 而不是N 进行回答,程序将只读取N。然而,如果程序后面再读取输入时,将从O开始读取。
b && 逻辑与表达式 同或运算符一样 也是顺序点 也是左侧确定true后,不看右侧
用&&来设置取值范围
&&运算符还允许建立一系列 if else if else语句,其中每种选择都对应于一个特定的取值范围。
例如
if(age>=85&&age<=100)
else if(age>=70&&age<85)
...
c 逻辑NOT运算符!
取反 优先级高于所有的关系运算符和算数运算符
d 逻辑运算符细节
c++逻辑or和逻辑and运算符的优先级都低于关系运算符。
c++确保程序从左向右进行计算逻辑表达式,并在知道答案后立刻停止
e 其他表示方式
并不是所有的键盘都提供了用作逻辑运算符的符号 所以 c++标准提供了另一种表示方式
就要使用到and or not 等c++保留字 但是不是关键字 如果c语言想将其用作运算符 需要包含头文件iso646.h
3.字符函数库cctype
一个与字符相关的 非常方便的函数软件包 主要用来测试字符类型
头文件 cctype 老式的为ctype。h
cin.get(ch);
if(isalpha(ch)) 判断是否为字母字符
4.?:运算符 三目运算符
5>3?10:12
if(5>3)
return 10;
else
return 12;
示例2:
(i<2)? !i ? x[i] : y : x[1];
嵌套三目运算符
5.switch
swithc(integer expression)//其中括号中的表达式的值为label1 或者label2 或者其他(default)
{
case label1:statement(s);
break; //跳出循环
case label2:
case label3:statement(s);//2和3一样 都会执行后面的语句
default:statement(s)
}
5.1将枚举量用作标签
enum{red,orange,yellow,green,blue};//枚举量
int main()
{
int code;
cin>>code;
switch(code)
{
case red:cout<<"red";
break;
case orange:cout<<"orange";
break;
defalut:....
}
}
5.2 switch 和if else 的区别
if else 更加通用 而且可以处理区间
if(age>17&& age<50)
6.break和continue 语句
continue 是直接跳到循环开始处 开始下一轮循环 不会跳过循环的更新表达式 for循环中 continue语句使程序直接跳到更新表达式处,然后跳到测试表达式处。
但是对于while循环 continue会直接跳到测试表达式处 在while循环中 位于continue之后的更新表达式都将被跳过
break是跳出循环 结束包含它的循环
goto label; 直接将程序跳到label处
7.读取数字的循环
读入数字
int n;
cin>>n;
如果是字符不是数字 会发生如下的情况
n的值不变
不匹配的输入将被留在输入队列中
cin对象中的一个错误标记被设置
对cin方法的调用将返回false 如果被转换为bool类型
方法返回false 意味着可以用非数字输入来结束读取数字的循环。非数字输入设置错误标记意味着必须重置该标记,程序才能继续读取输入。
clear()方法重置错误输入标记,同时也重置文件尾 EOF条件 输入错误和EOF都会导致cin返回false
示例
//cinfish.cpp
#include <iostream>
const int Max=5;
int main()
{
using namespace std;
double fish[Max];
cout<<"please enter the weights of your fish.\n";
cout<<"fish #1: ";
int i=0;
while(i<Max&&cin>>fish[i])// 左侧的表达式为假 则不会判断右侧的表达式,右侧的表达式判断的同时会将结果存储到数组中
{
if(++i<Max) //执行++i i的值会变化
cout<<"fish #"<<i+1<<": ";
}
double total=0.0;
for(int j=0;j<i;j++)
total+=fish[j];
if(i==0)
cout<<"no fish\n";
else
cout<<total/i<<"=average weight of " <<i<<" fish\n";
cout<<"done.\n";
return 0;
}
上面的程序当输入不是数字时,该程序将不在读取输入队列,程序将拒绝输入;如果想继续读取输入,则需要重置输入
当输入错误的内容时:采取的3个步骤
1.重置cin以接受新的输入
2.删除错误输入 (如何删除错误的输入) 程序必须先重置cin 然后才能删除错误输入
3.提示用户再输入
//cingolf.cpp
#include <iostream>
const int Max=5;
int main()
{
using namespace std;
int golf[Max];
cout<<"please enter your golf scores.\n";
cout<<"you must enter "<<Max<<" rounds.\n";
int i;
for(i=0;i<Max;i++)
{
cout<<"round #"<<i+1<<": ";
while(!(cin>>golf[i]))//用户输入数字 则cin表达式将为true 则将后面的值存入到数组中,如果输入的是非数字值,则cin为false 则值不会存入到数组中
{
cin.clear();//如果没有此语句,则程序会拒绝继续读取输入
while(cin.get()!='\n')//读取行尾之前的所有输入,从而删除这一行中的错误输入;另一种方法是读取到下一个空白字符,这样将每次删除一个单词,而不是一次删除整行。
continue;
cout<<"please enter a number: ";
}
}
double total=0.0;
for(int i=0;i<Max;i++)
total+=golf[i];
cout<<total/Max<<"=average scores " <<Max<<" rounds\n";
cout<<"done.\n";
return 0;
}
8.简单文件的输入和输出
1.文本i/o和文本文件
cin输入,会将输入看作一系列的字节,每个字节被解释为字符编码,不管目标的数据类型是什么,都被看作字符数据,然后cin对象负责将文本转换为其他的类型。
输入38.2 15.5
int n;
cin>>n 会不断的读取,直到遇到非数字字符, 38被读取后 句点将成为输入队列中的下一个字符
double x;
cin>>x; 不断的读取 直到遇到不属于浮点数的字符。 38.2将会被读取,空格将成为输入队列中的下一个字符
char word[50];
cin>>word;
不断读取,直到遇到空白字符, 38.5被读取,然后将这4个字符的编码存储到数组word中。并在末尾加上一个空字符。
char word[50];
cin.getline(word,50);
不断读取,直到遇到换行符(示例中少于50个字符),所有字符被存储到word中 包括空格,并在末尾加上一个空字符。换行符被丢弃,输入队列中的下一个字符是下一行中的第一个字符。这里不需要转换。
对于输入 将执行相反的转换。即整数被转换为数字字符序列,浮点数被转换为数字字符和其他字符组成的字符序列 字符数据不需要做任何的转换。
输入一开始都是文本,所以控制台输入的文件版本都是文本文件爱你,即每个字节都存储了一个字符编码的文件。
2.写入到文本文件中 相对应于写入到控制台上(屏幕 对应于cout)
cout用于控制台输出的基本事实
必须包含头文件iostream
头文件iostream定义了一个用处理可输出的ostream类
头文件iostream声明了一个名为cout的ostream变量(对象)
必须指明名称空间std;
结合使用cout和运算符<<来显示各种类型的数据
文件输出与上述相似
必须包含头文件fstream
头文件fstream定义了一个用于处理输出的ofstream类
需要声明一个或多个ofstream变量(对象),并自己命名
指明名称空间std
需要ofstream对象与文件关联起来,为此,方法之一是使用open()方法
使用完文件后,应好似用方法close()将其关闭
可结合使用ofstream对象和运算符<<来输出各种类型的数据
cout为ostream已经定义好的 所以不需要重新定义
而ofstream对象没有已经定义好的对象 所以需要自己声明此脆响 并同文件相关联
ofstream outfile;
ofstream fout; 定义了两个对象 都属于ofstream类
关联文件
outfile.open("fish.txt"); //关联文件 fish.txt
char filename[50];
cin>>filename;
fout.open(filename); //关联文件 filename变量存储的值作为文件名
使用方法:
double wt=125.8;
outfile<<wt; //将wt数据写入到上面关联的文件中 fish.txt
char line[81]="objects are closer than they appear";
fout<<line<<endl; //将line数组中的内容输出到fout对象关联的文件中去
声明一个ofstream对象并将其同文件关联起来后,便可以像使用cout那样使用它。所有可用于cout的操作和方法都可以用于ofstream对象
主要步骤:
1.包含头文件fstream
2.创建一个ofstream对象
3.将该ofstream对象同一个文件关联起来。
4.就像使用cout那样使用该ofstream对象
//outfile.cpp
#include <iostream>
#include <fstream>
int main()
{
using namespace std;
char automobile[50];
int year;
double a_price;
double d_price;
ofstream outfile;
outfile.open("carinfo.txt");//如果在当前目录下没有此文件怎么办呢?自动创建 ;如果已经存咋这个文件,默认情况下会删除原来的内容(将此文件的长度截短为0),写入新的内容。17章可根据参数修改 此默认设置
cout<<"enter the make and model of automobile: ";
cin.getline(automobile,50);//读取到换行符为止
cout<<"enter the model year: ";
cin>>year;
cout<<"enter the original asking price: ";
cin>>a_price ;
d_price=0.913*a_price;
cout<<fixed;
cout.precision(2);
cout.setf(ios_base::showpoint);//显示固定格式
cout<<"make and model: "<<automobile<<endl;
cout<<"year: $"<<year<<endl;
cout<<"was asking $"<<a_price<<endl;
cout<<"now asking $"<<d_price<<endl;
outfile<<fixed;
outfile.precision(2);//格式化方法
outfile.setf(ios_base::showpoint);//格式化方法
outfile<<"make and model: "<<automobile<<endl;
outfile<<"year: "<<year<<endl;
outfile<<"was asking $" <<a_price <<endl;
outfile<<"now asking $"<<d_price <<endl;
outfile.close();//不需要使用文件名作为参数
return 0;
}
所有的cout方法都可以用outfile对象使用
关联文件后,需要关闭此文件的关联
3.读取文本文件 类似于cin 即istream类和ifstream类对应
cin 将控制台(键盘的内容输入) 存入到变量中
ifstream类定义的对象 从文本文件中读取内容到指定的变量中
首先看控制台:
包含iostream头文件
此头文件定义了一个用处理输入的istream类
头文件iostream声明了一个名为cin的istream变量 对象
指明命名空间
结合cin和get方法来读取一个字符 使用cin和getline来读取一行字符
cin 和eof()、fial()方法来判断输入是否成功。
cin本身用作测试条件,如果最后一个读取操作成功,它将转换为bool的值,true或者false
文件的输入与上面的cin类似
头文件fstream
头文件fstream定义了一个用于处理输入的ifstream类
需要声明一个或多个ifstream变量(对象),并以自己喜欢的方式对其进行命名,条件是遵守常用的命名规则。
指明名称空间std
将ifstream对象与文件关联起来。方法之一是使用open方法
使用完文件后,需要使用close()方法将其关闭
ifstream对象和运算符>>来读取各种类型的数据
ifstream和eof() fail()等方法来判断输入是否成功
ifstream对象本身被用作测试条件时,如果最后一个读取操作成功,它将被转换为布尔值bool
示例:
ifstream infile;
ifstream fin;
infile.open("bowling.txt");
char filename[50];
cin>>filename;
fin.open(filename);
double wt
infile>>wt;
char line[81];
fin.getline(line,81);
如果试图打开一个不存在的文件用于输入,则这种错误将导致后面使用ifstream对象进行输入时失败,检查文件是否被成功打开的首先方法是使用is_open(),为此可以使用类似于下面的代码:
infile.open("bowling.txt");
if(!infile.is_open())
{
exit(EXIT_FAILURE);
}
如果文件被成功打开,方法is_open()将返回true;否则返回false
exit()函数的原型是在头文件cstdlib中定义的。在该头文件中,还定义了一个用于同操作系统通信的参数值EXIT_FAILURE 函数exit()终止程序。
如果编译器不支持is_open()函数 可以使用比较老的方法good()来代替。但是此函数在检查问题方面没有新的函数is_open()那么广泛。
示例
//sumafile.cpp
#include <iostream>
#include <fstream>
#include <cstdlib>
const int SIZE=60;
int main()
{
using namespace std;
char filename[SIZE];
ifstream infile;//定义对象
cout<<"enter name of data file: ";
cin.getline(filename,SIZE);//从文件中获取一行数据 60个字符
infile.open(filename);//关联指定的文件
if(!infile.is_open())//判断文件是否存在 如果不存在则提示 并且退出
{
cout<<"could not open the file"<<filename<<endl;
cout<<"program terminating.\n";
exit(EXIT_FAILURE);//根据EXIT_FAILURE的值 退出返回
}
double value;
double sum=0.0;
int count=0;
infile>>value;//从文件获取值 存入变量
while(infile.good())//判断获取的数据是否为double类型
{
++count;
sum+=value;
infile>>value;//获取下一个值
}
if(infile.eof())//判断是否到文件结尾
cout<<"end of file reached.\n";
else if(infile.fail())//判断是否数据匹配
cout<<"input terminated by data mismatch.\n";
else
cout<<"input terminated for unknown reason.\n";
if(count==0)//
cout<<"no data processed.\n";
else//最后输出各个变量的值
{
cout<<"items read: "<<count<<endl;
cout<<"sum: "<<sum<<endl;
cout<<"average: "<<sum/count<<endl;
}
infile.close();
return 0;
}
1.程序说明 设置中文路径名称可用
setlocale(LC_ALL,"Chinese-simplified")
2.注意文件的扩展名
1.txt.txt
3.加入绝对路径
infile.open(“c://source/1.txt”);
4.文件读取循环的正确设计。读取文件时,有几点需要检查,首先,程序读取文件时要超过EOF,如果遇到EOF 则方法eof会返回true;其次类型不匹配 fail返回true;如果最后一次读取文件受损或因噶进故障,bad会返回true 所以不要分别检查这些问题,用good()方法一次性检查就可以了。如果没有任何问题则返回true
注意上面检测的顺序,首先是eof 之后是fail 再之后是bad
同cin相同
cin>>value; //循环之前读入
while(){
...
cin>>value; 循环中读入
}
同上
infile>>value;//循环之前读入
while(infile.good())
{
...
infile>>value;//循环之后读入
}
可以合并为一个判断的表达式
while (infile>>value)
{
statements;
}
第七章 函数 ----c++的编程模块
函数原型 prototype
函数定义 definition
调用函数 calling
1.定义函数
有返回值和无返回值的函数
int functionName(parameterList) 有返回值
{
statements(s)
return value; 必须存在
}
无返回值
void functionname(parameterlist)
{
statements(s);
return; 可有可无 不返回任何值
}
2.函数原型和调用
系统库提供的函数的原型一般包含在include文件中 头文件中。
提供函数原型的原因如下:
a 原型描述了函数到编译器的接口,它将函数返回值的类型以及参数的类型和数量告诉编译器。
double volume=cube(side);
首先,原型告诉编译器,cube有一个double参数 ,如果程序没有提供这样的参数,原型将让编译器能够捕获这种错误。其次,cube函数完成计算后,将把返回值放置在指定的位置--可能是cpu寄存器,也可能是内存中。然后调用函数将从这个位置取得返回值。
因为原型指出了cube的类型为double 因此编译器知道应该检索多少个字节以及如何解释它们。
另一个方面是,如果没有原型,编译器就会在程序中查找,导致效率不高,编译器在搜索文件的剩余部分时将必须停止对main()的编译
另一个问题是,函数可能并不在文件中,c++允许将一个程序放在多个文件中,单独编译这些文件,然后再将他们组合起来。
3.原型的语法
函数原型是一条语句,因此必须以分号结束。
复制函数头部加上分号 就是原型
原型中可以没有变量名,但是必须有类型
4.原型的功能 c++中必须提供函数的原型
编译器正确处理函数的返回值
编译器检查使用的参数数目是否正确
编译器检查使用的参数类型是否正确。如果不正确,则转换为正确的类型
调用函数cube (2) 原型为cube(double)
由于原型中指定了double类型 所以会将整型的2转换为2.0再参加运算
但是如果反过来 cube(int ) 调用时使用cube(2.7854)
原型为int型 转换时会将浮点的类型转换为int 会导致数据的丢失
二 函数参数和按值传递
1.按值传递时,不会改变实参的数值
将实参复制一个副本 成为形参的值,在函数中计算的是形参的数值
2.多个参数
逗号分隔多个参数
和一个参数一样,原型中不必与定义中的变量名相同,而且可以省略
但是在原型中提供变量名使得程序更加容易理解
三函数和数组
示例:int sum_arr(int arr[],int n) 为原型
调用:int sum_arr(int arr[],int n)
也可以使用int sum_arr(int * arr,int n)
1.函数如何使用指针来处理数组
将数组名视为指针
cookies==&cookies[0]
首先,数组声明使用数组名来标记存储位置;其次,对数组名使用sizeof将得到整个数组的长度 以字节为单位ie;第三,将地址运算符&用于数组名时,将返回整个数组的地址
原型:int sum_arr(int * arr,int n) 使用int arr[] 是相同的 但是后者提醒 指针指向数组的第一个元素
调用:int sum_arr(cookies,arsize)
两个恒等式:
arr[i]==*(ar+i)
&arr[i]==ar+i
将指针(包括数组名)加1 实际上加上了一个指针指向的类型的长度 字节为单位ie 对于便利数组而言,使用指针加法和数组下标时等效的
2.将数组作为参数意味着什么?
上例中 实际上传递的是指向数组的指针,而不是整个数组。
当传递常规变量是,使用的是该变量的拷贝;但是传递数组时,函数将使用原来的数组。但是传递数组指针时,使用的是原来的数组,并不是数组的copy
虽然节省了资源,但是同时带来了对原始数据被破坏的风险。
可以使用const的限定符这种解决办法。
cookies和arr指向同一个地址,但是sizeof cookies 的值是32 而sizeof arr为4 这是因为sizeof cookies 是整个数组的长度,而sizeof arr只是指针变量本身的长度。顺便说,这也是必须显式传递数组长度,而不能在sum_arr()中使用sizeof arr的原因 指针并没有指出数组的长度
在原型中不要使用方括号来传递数组的长度
void fillarray(int arr[size])
3.更多数组函数示例
//7.7 arrfun3.cpp
#include <iostream>
const int Max=5;
int fill_array(double ar[],int limit);//原型 fill_array
void show_array(const double ar[],int n);//原型 show_array
void revalue(double r,double ar[],int n);//原型 revalue
int main(){
using namespace std;
double properties[Max];
int size=fill_array(properties,Max);//调用填充函数 注意参数
show_array(properties,size);//调用显示函数
if(size>0)//大于0 说明fill_array函数返回的值是 填充成功的数量
{
cout<<"enter revaluation factor: ";
double factor;
while(!(cin>>factor)) //输入的值各种原因不成功 每次读取一个字符
{
cin.clear();//重置输入
while(cin.get()!='\n') //再次获取输入 如果不等于换行符 则继续读取 一直到换行符之前
continue;
cout<<"bad input,please enter a number: ";
}
revalue(factor,properties,size);//重新赋值
show_array(properties,size);//再次调用显示函数
}
cout<<"donw.\n";
cin.get();
cin.get();//等待 显示
return 0;
}
int fill_array(double ar[],int limit)//填充数组的实现
{
using namespace std;
double temp;
int i;
for(i=0;i<limit;i++)
{
cout<<"enter value #"<<(i+1)<<": ";
cin>>temp;
if(!cin)
{
cin.clear();
while(cin.get()!='\n')
continue;
cout<<"bad input;input process terminated .\n";
break;
}
else if(temp<0)//输入的是赋值则跳出循环
break;
ar[i]=temp;//数组赋值
}
return i;
}
void show_array(const double ar[],int n)//显示数组中各个元素的值 这里的const 用来保证不会修改原始的数组;
{
using namespace std;
for(int i=0;i<n;i++)
{
cout<<"property #"<<(i+1)<<":$";
cout<<ar[i]<<endl;
}
}
void revalue(double r,double ar[],int n)//重新赋值
{
for(int i=0;i<n;i++)
ar[i]*=r;
}
程序说明 关于void show_array(const double ar[],int n);
指针ar不能修改该数据,也就是说可以使用像ar[0]这样的值,但不能修改,注意,这并不意味着原始数组必须是常量,而只是意味着不能在show_array()函数中使用ar来修改这些数据,因此,show_array()将数组视为只读数据。
假设无意间在show_array()函数中执行了下面的操作,从而违反了这种限制:
ar[0]+=10; 会提示错误
c++声明const double ar[] 解释为const double * ar 因此该声明实际上是说 ar指向的是一个常量值。
首先考虑的是通过数据类型和设计适当的函数来处理数据 然后将这些函数组合成一个程序。 叫做自下而上的程序设计
c语言为过程性编程 倾向于从上而下的程序设计
4.使用数组区间的函数
处理数组的c++函数,必须将数组中的数据种类,数组的起始位置和数组中元素数量提交给它;
另一种处理数组的方法,即指定元素区间range 可以通过传递两个指针来完成。一个指针标识数组的开头 另一个指针标识数组的尾部
sum=sum_arr(cookies,cookies+arsize);
sum=sum_arr(cookies,cookies+3);
sum=sum_arr(cookies+4,cookies+8);
//arrfun4.cpp
#include <iostream>
const int arsize=8;
int sum_arr(const int * begin,const int * end);
int main()
{
using namespace std;
int cookies[arsize]={1,2,4,8,16,32,64,128};
int sum=sum_arr(cookies,cookies+arsize);
cout<<"total cookies eaten: "<<sum<<endl;
sum=sum_arr(cookies,cookies+3);
cout<<"first three eaters ate "<<sum<<"cookies.\n";
sum=sum_arr(cookies+4,cookies+8);
cout<<"last four eaters ate "<<sum<<" cookies.\n";
return 0;
}
int sum_arr(const int * begin,const int * end)
{
const int * pt;
int total=0;
for(pt=begin;pt!=end;pt++)
total=total+*pt;
return total;
}
pt设置为指向要处理的第一个元素 begin指向的元素的指针,并将*pt 加入到total中,然后循环通过递增操作来更新pt。使之指向下一个元素。只要pt不等于end 这个过程就会继续。
end-begin为整数值 等于数组的元素数目
5.指针和const
两种不同的方式将const关键字用于指针。
第一是让指针指向一个常量对象,这样可以防止使用该指针来修改所指向的值
第二是将指针本身声明为常量,可以防止改变指针指向的位置
int age=39;
const int * pt=&age;
pt指向一个const int的值,所以不能用pt来修改这个值, 换句话说就是* pt的值为const 不能被修改;
*pt+=1; 错误的语句
cin>>*pt;
pt的声明并不意味着它指向的值实际上是一个常量,而只是说对pt而言,这个值是常量。例如pt指向age 而age不是const 可以直接通过age变量来修改age的值
*pt=20; 错误
age=20 正确
将常规变量的地址赋给常规指针 可行
将const变量的地址赋给指向const的指针 可行 变量和指针都不能修改原值
将const的地址赋给常规指针 不可行 (原因是常规指针可能会改变指向的const的值 会引发错误)
例2:一级指针 一级间接关系 将非const指针赋给const指针是可以的
int age=39; //age++ 有效
int * pd=&age; //*pd=41 有效
const int * pt=pd; //*pt=42 无效
二级关系
const int **pp2; //二级指针
int * p1;
const int n=13; //常量 变量
pp2=&p1; // 错误 将非const地址 赋给const指针 pp2 因此可以使用p1来修改const数据,
*pp2=&n; //常量变量的地址赋给一级指针 有效 两个都是常量
*p1=10; //
如果数据类型本身并不是指针,则可以将const数据或非const数据的地址赋给指向const的指针,但只能将非const数据的地址赋给非const指针。
二级指针不允许赋值
禁止将常量数组的地址赋给非常量指针将意味这不能将数组名作为参数传递给使用非常量形参的函数
const int months[12]={31,28,31,30,31,30,31,31,30,31,30,31};
int sum(int arr[],int n);
int j=sum(months,12);
试图将const指针赋给非const指针arr 编译器将禁止这种函数调用
尽可能使用const
TIPS:将指针参数声明为指向常量数据的指针有两条理由:
避免无意间修改数据而导致的编程错误
使用const使得函数能够处理const和非const实参,否则将只能接受非const数据
int age=39;
const int * pt=&age;
上面的声明中的const只能防止修改pt指向的值(39),而不能防止修改pt的值。也就是说,可以将一个新的地址赋值给pt:
int sage=80;
pt=&sage; 不能使用pt来修改sage的值 但是可以修改pt本身的值 (地址值)
使用const的方式使得无法修改指针的值
int sloth=3;
const int * ps=&sloth;//指针指向一个整型的常量数值 ----1
int * const finger=&sloth;// 一个常量指针 指向整型-----2
1 不能通过指针 改变指向的常量的值,但是可以改变指针本身的地址值 const的位置在最前方 可以不指向sloth
2 不能改变指针本身的地址值,但是可以通过此指针修改指向变量的值 const的位置在后方 执政指向sloth
总结 finger和*ps都是const;而*finger和ps不是const
double trouble=2.0e30;
const double * const stick=&trouble;
stick 只能指向trouble stick不能用来修改trouble的值, stick和*stick都是const
通常 将指针作为函数参数来传递时,可以使用指向const的指针来保护数据。
四 函数和二维数组
为编写将二维数组作为参数的函数 数组名是地址 ,相应的形参就是一个指针 数组名代表数组组中的第一个元素的地址 &数组名则代表全部数组的地址
int data[3][4]={{1,2,3,4},{9,8,7,6},{2,4,6,8}};
int total=sum(data,3);
data是一个数组名,该数组有3个元素,第一个元素本身是一个数组,有4个int值组成,因此data的类型是指向4个int组成的数组的指针。
data指向二维数组中的第一个元素,代表{1,2,3,4}这个元素的地址
所以正确的原型如下:
int sum(int (*ar2)[4],int size); 可读性差一些
ar2 接收的就是一个包含4个int型元素的数组的地址值 (指针)
而与上面同样的原型则为
int sum(int ar2[][4],int size) 可读性更好
ar2是指针而不是数组,指针类型指出,由4个int组成的数组,因此,指针类型指定了列数,这就是没有将列数作为独立的函数参数进行传递的原因。
示例:
int a[100][4];
int b[6][4];
int total1=sum(a,100);
int total2=sum(b,6);
示例2:
int sum(int ar2[][4],int size)
{
int total=0;
for(int r=0;r<size;r++) //双层循环
for(int c=0;c<4;c++)
total+=ar2[r][c];
return total;
}
ar2+r指向编号为r的元素,因此ar2[r]是编号为r的元素,由于该元素本身是一个4个int组成的数组,因此ar2[r]是由4个int组成的数组的名称。
将下标用于数组名将得到一个数组元素,因此ar2[r][c]是由4个int组成的数组中的一个元素,是一个int值。必须对指针ar2执行两次解除引用
最好的方法是两次方括号 ar2[r][c]
也可以使用运算符*两次
ar2[r][c]==*(*(ar2+r)+c)
ar2 指向二维数组的第一行
ar2+r 指向二维数组中的第r行
*(ar2+r) 指向二维数组中的第r行中的首元素
*(ar2+r)+c 指向二维数组中的第r行中的标签为c的元素
*(*(ar2+r)+c) 代表二维数组中的第r行中的标签为c的元素的数值
sum()的代码在声明参数ar2时,没有使用const 因为这种技术只能用于指向基本类型的指针,而ar2是指向指针的指针。
五 函数和c风格字符串
c风格字符串 一些列字符组成,以空值字符结尾。
将字符串作为参数时意味着传递的是地址,但是可以使用const来禁止对字符串参数进行修改。
1.将c字符串作为函数的参数
char数组
用引号括起的字符串常量 也称字符串字面量
被设置为字符串的地址的char指针
上面的三个都是char *
示例:char gohst[15]="asdfasdf";
char * str="adsfasdf";
int n1=strlen(ghost); ghost代表&ghost[0]
int n2=strlen(str); 指向char的指针
int n3=strlen(“adsfasdf”);括号中字符串的地址
所以 将字符串作为参数来传递,但实际传递的是字符串第一个字符的地址 字符串函数原型应将其表示字符串的形参声明为char * 类型
c风格字符串与常规char数组的一个重要区别是 字符串有内置的结束字符 但不以空值字符结尾的char数组只是数组,而不是字符串。
长度可以不用传递给函数 因为 函数可以检测字符串中的每个字符 如果遇到空值字符 就是停止。
示例:
#include <iostream>
unsigned int c_in_str(const char * str,char ch)
int main()
{
using namespace std;
char mmm[15]="minimum";
char * wail="ululate";
unsigned int ms=c_in_str(mmm,'m');
unsigned int us=c_in_str(wail,'u');
cout<<ms<<"m characters in"<<mmm<<endl;
cout<<us<<"u characters in"<<wail<<endl;
return 0;
}
unsined int c_in_str(const char * str,char ch)
{
unsigned int count=0;
while(*str)
{
if(*str==ch)
count++;
str++;
}
return count;
}
同样可行的方式:unsigned int c_in_str(const char str[],char ch)
函数本身演示了处理字符串中字符的标准方式
while(* str)
{
statements
str++;
}
其中*str表示的是第一个字符
当str指向空值字符时,*str等于0 表示空值字符的数字编码为0 则循环结束
函数无法返回一个字符串,但是可以返回一个字符串的地址,而且效率更高
示例2 strgback.cpp
#include <iostream>
char * buildstr(char c,int n); 原型
int main()
{
using namespace std;
int times;
char ch;
cout<<"enter a character: ";
cin>>ch; \\一个字符
cout<<"enter an integer: ";
cin>>times; \\一个整数
char *ps=buildstr(ch,times); \\返回地址
cout<<ps<<endl;
delete [] ps; \\清除ps指向的内存空间 数组
ps=buildstr('+',20);\\调用函数
cout<<ps<<"-done-"<<ps<<endl;
delete [] ps;
return 0;
}
char * buildstr(char c,int n)
{
char * pstr=new char[n+1];\\申请空间 数组存放 pstr为指向的指针
pstr[n]='\0'; \\下标为n的数组值为空值字符
while(n-->0) \\循环赋值
pstr[n]=c;
return pstr; \\返回字符数组的指针
}
创建包含n个字符的字符串,需要能够存储n+1个字符的空间,以便能够存储空值字符。
注意用new 申请的内存空间 必须记住用delete来释放
6 函数和结构
结构和数组不同 结构变量更接近于基本的单值变量,将其数据组合成单个实体或数据对象,该实体被视为一个整体。
可以将一个结构赋给另外一个结构。也可以按值传递结构,就像普通变量那样。
结构传递副本 函数也可返回结构
结构名不是地址,仅仅是结构的名称 如果想要得到结构的地址,必须使用地址运算符&
c++还是用该运算符来表示引用变量 &
1.传递和返回结构
适合结构比较小的情况
struct travel_time{ \\结构定义
int hours;
int mins;
}
travel_time sum(travel_time t1,travel_time t2); \\ 原型
travel_time day1={5,45};
travel_time day2={4,55};
travel_time trip=sum(day1,day2);\\调用
travel_time sum(travel_time t1,travel_time t2) \\被调用函数的实现
{
travel_time total;
statement;
return total; \\返回一个结构体变量
}
2.处理结构的示例
有关函数和c++结构的大部分知识都可以用于c++类中
示例:
\\strctfun.cpp
#include <iostream>
#include <cmath>
struct ploar \\用距离和角度来表示一个点
{
double distance;
double angle;
}
struct rect \\x和y的坐标表示点的位置
{
double x;
double y;
}
ploar rect_to_polar(rect xypos);\\原型声明
void show_polar(polar dapos);\\原型声明
int main()
{
using namespace std;
rect rplace;\\结构类型声明
ploar pplace;\\结构类型声明
cout<<"enter the x and y values: ";
while(cin>>rplace.x>>rplace.y)\\注意这里的cin>>rplace.x 返回cin类型 接着调用cin>>rplace.y
{
pplace=rect_to_polar(rplace);\\调用函数
show_polar(pplace);\\调用函数
cout<<"next two numbers (q to quit): ";
}
cout<<"done.\n";
return 0;
} \\end of main
ploar rect_to_polar(rect xypos) \\接受 rect结构体 返回ploar结构体
{
using namesapce std;
ploar answer;
answer.distance=sqrt(xypos.x*xypos.x+xypos.y*xypos.y); \\计算距离
answer.angle=atan2(xypos.y,xypos.x);\\计算角度
return answer;
}
void show_ploar(polar dapos)
{
using namespace std;
const double rad_to_deg=57.29577951;
cout<<"distance= "<<dapos.distance;
cout<<",angle="<<dapos.angle * rad_to_deg;\\角度转换
cout<<"* degrees\n";
}
2.传递结构的地址
传递结构的地址而不是整个结构以节省时间和空间,使用指向结构的指针。
调用函数,将结构的地址 &pplace而不是结构本身pplace传递给它;
将形参声明为指向polar的指针,即ploar* 类型。由于函数不应该修改结构,因此使用了const修饰符;
形参是指针而不是接哦股,因此应间接成员运算符-> 而不是成员运算符 句点。
修改后的代码如下 show_polar(const ploar *pda)和rect_to_polar()
\\strctfun.cpp
#include <iostream>
#include <cmath>
struct ploar \\用距离和角度来表示一个点
{
double distance;
double angle;
}
struct rect \\x和y的坐标表示点的位置
{
double x;
double y;
}
\\ploar rect_to_polar(rect xypos);\\原型声明
void rect_to_polar(const rect * pxy,ploar * pda);\\原型声明
void show_polar(const polar * pda);\\原型声明
int main( )
{
using namespace std;
rect rplace;\\结构类型声明
ploar pplace;\\结构类型声明
cout<<"enter the x and y values: ";
while(cin>>rplace.x>>rplace.y)\\注意这里的cin>>rplace.x 返回cin类型 接着调用cin>>rplace.y
{
\\pplace=rect_to_polar(rplace);\\调用函数
rect_to_polar(&rplace,&pplace);\\传递地址
show_polar(&pplace);\\调用函数 \\传递地址
cout<<"next two numbers (q to quit): ";
}
cout<<"done.\n";
return 0;
} \\end of main
ploar rect_to_polar(const rect * pxy,ploar * pda) \\接受 rect结构体 返回ploar结构体
{
using namesapce std;
pda->distance=sqrt(pxy->x*pxy->x+pxy->y*pxy->y); \\计算距离
pda->angle=atan2(pxy->y,pxy->x);\\计算角度
}
void show_ploar(const polar * pda)
{
using namespace std;
const double rad_to_deg=57.29577951;
cout<<"distance= "<<pda->distance;
cout<<",angle="<<pda->angle * rad_to_deg;\\角度转换
cout<<"* degrees\n";
}
上例使用了指针 函数能够对原始的机构进行操作;而上上例使用的是结构副本。
7.函数和string对象
c风格字符串和string对象的用途类似,但与数组相比,string对象与结构更相似。
结构可以赋值给结构,对象可以赋值给对象。
如果需要多个字符串,可以声明一个string对象的数组,而不是二维char数组,操作会更加灵活。
//topfive.cpp
#include <iostream>
#include <string>
using namespace std;
const int SIZE=5;
void display(const string sa[],int n);\\原型
int main()
{
string list[SIZE]; \\string对象数组
cout<<"enter your "<<SIZE<<" favorite astronomical sights: \n ";
for(int i=0;i<SIZE;i++)
{
cout<<i+1<<": ";
getline(cin,list[i]);\\初始化数组中的元素
}
cout<<" your list: \n ";
display(list,SIZE); \\传递过去指向string对象数组的指针 (即地址值 =数组名)
return 0;
}
void display(const string sa[],int n)
{
for(int i=0;i<n;i++)
cout<<i+1<<" : "<<sa[i]<<endl;
}
8.函数与array对象
c++中 类对象基于结构
所以:可以按值将对像传递给函数, 函数处理的是原始对象的副本。
可以传递对象的指针 函数内部直接操作原始的对象 通过指针
使用array对象来存储一年四个季度的开支:
std::array<double,4> expenses; 需要包含头文件array,而名称array位于名称空间std中。
函数show(expenses) 不能修改expenses
函数fill(&expenses) 可以修改expenses 传递进来的是指针
则函数的原型为:
void show(std::array<double,4> da);
void fill(std::array<double,4> * pa); \\pa指向array对象的指针
可以用符号常量来替换4
const int seasons=4;
const std::array<std::string,seasons> snames={"spring","summer","fall","winter"};
模板array并非只能存储基本数据类型,还可以存储类对象
//arrobj.cpp
#include <iostream>
#include <array>
#include <string>
const int seasons=4;
const std::array<std::string,seasons> snames={"spring","summer","fall","winter"}; //数组的声明
void fill(std::array<double,seasons> * pa);//原型定义 接收一个array的对象的指针
void show(std::array<double,seasons> da);//原型定义 接收一个array的对象
int main()
{
std::array<double,seasons> expenses; //定义
fill(&expenses);//填充 指针指向的array对象定义的double数组
show(expenses);//传值 并且显示 数组中的内容
return 0;
}
void fill(std::array<double,seasons> * pa) //接收指向数组的指针
{
using namespace std;
for(int i=0;i<seasons;i++)
{
cout<<"enter "<<snames[i]<<" expenses: ";
cin>>(*pa)[i]; //填充 数组元素
}
}
void show(std::array<double,seasons> da)
{
using namespace std;
double total=0.0;
cout<<" \n EXPENSES \n ";
for(int i=0;i<seasons;i++)
{
cout<<snames[i]<<" :$ "<<da[i]<<endl;//输出 个元素的值
total+=da[i];//相加各个元素的值
}
cout<<"total expenses: $ " <<total<<endl;
}
fill和show两个函数都有缺点。函数show()存在的问题是,expenses存储了四个double值,而创建一个新对象并将expenses的值赋值到其中的效率太低。
7.9递归
1.包含一个递归调用的递归
如果递归函数调用自己,则被调用的函数也将调用自己,这将无限循环下去,所以必须有终止调用链的内容。
void recurs(argumentlist)
{
statements1
if(test)
recurs(arguments)
statements2
}
示例:
recur.cpp
#include <iostream>
void countdown(int n)
int main()
{
countdown(4);
return 0;
}
void countdown(int n)
{
using namespace std;
cout<<"counting down ..."<<endl;
if(n>0)
countdown(n-1);
cout<<n<<":kaboom\n";
}
输出:
counting down ...4
counting down ...3
......
counting down ...0
0:kaboom!
1:kaboom!
......
4:kaboom!
7.9.2包含多个递归调用的递归
将一项工作不断分为两项或多项较小的工作时,递归会非常有用。
示例:绘制标尺 分而治之的策略
标出两端,找到重点并将其标出 然后将同样的操作用于标尺的左半部分和右半部分
//ruler.cpp
#include <iostream>
const int len=66;
const int divs=6;
void subdivide(char ar[],int low,int high,int level);//prototype
int main()
{
char ruler[len];//数组
int i;
for(i=1;i<len-2;i++)
ruler[i]=' ';//初始化数组中的值均为空格
ruler[len-1]='\0';//数组中最后一个元素的值为空值
int max=len-2;//数组下标范围设置
int min=0;
ruler[min]=ruler[max]='|';//初始化数组首尾两个元素的值为‘|’
std::cout<<ruler<<std::endl;//输出数组各项的值
for(i=1;i<=divs;i++)//6次循环 分别设置数组中的值 利用递归调用
{
subdivide(ruler,min,max,i);//当level=0时会从调用函数中返回
std::cout<<ruler<<std::endl;//输出数组中个元素的值 分次
for(int j=1;j<len-2;j++)
ruler[j]=' ';
}
return 0;
}
void subdivide(char ar[],int low,int high,int level)//递归函数设置数组值
{
if(level==0)
return;
int mid=(high+low)/2;
ar[mid]='|';
subdivide(ar,low,mid,level-1);//左边的数组 注意level的值是一直变化的
subdivide(ar,mid,high,level-1);//右边的数组
}
使用level来控制递归层,函数调用自身时,将把level减1,当level为0时,该函数将不再调用自己。 最初的中点被用作一次调用的右端点和另一次调用的左端点。
调用次数呈几何级增长,调用一次导致两个调用然后导致4个,然后8个 最后64个调用。
7.10函数指针
函数地址是存储机器语言代码的内存的开始地址
A.基础知识
一个函数以另一个函数作为参数 此时就会需要函数的地址
获取函数的地址
声明一个函数指针
使用函数指针来调用该函数
1.获取函数的地址
函数名即为函数的地址
有think()函数
例如:process(think) 传递函数的地址 作为参数
process(think()) 传递函数think()的返回值做为参数
2.声明函数指针
声明指针必须指定指针的类型。指向函数,也必须指定指针指向的函数的类型
声明需要指定函数的返回类型以及函数的参数列表
首先声明被传递的函数的原型
double pam(int);//prototype
double (*pf)(int); pf为指向函数的指针
提示:通常 用*pf替换原来函数原型中的函数名 就会得到函数的指针
上例中为*pf替换了pam
注意运算符号的优先级:
double (*pf)(int) 指向函数的指针
double *pf(int ) pf是一个返回指针的函数
正确的声明之后, 就可以将函数的地址赋给指针
pf=pam 注意声明中指针与原来的函数原型返回值和参数列表必须完全一致
作为参数传递
void estimate(int lines,double(*pf)(int)); 函数原型
estimate(50,pam); 调用
3.使用指针来调用函数
因为*pf等同于pam 所以直接使用*pf作为函数名即可
double x=pam(4); 用原函数调用
double y=(*pf)(5); 用指针调用
double y=pf(5); 此种方式也可以 仅仅在c++11 中
B 函数指针示例
//7.18 fun_prt.cpp
#include <iostream>
double betsy(int);//prototype
double pam(int);
void estimate(int lines,double (*pf)(int));
int main()
{
using namespace std;
int code;
cout<<"how many lines of code do you need?";
cin>>code;
cout<<"here's betsy's estimate:\n";
estimate(code,betsy);// 调用betsy函数
cout<<"here's pam's estimate:\n";
estimate(code,pam);//调用pam函数
return 0;
}
double betsy(int lns)
{
return 0.05*lns;
}
double pam(int lns)
{
return 0.03*lns+0.0004*lns*lns;
}
void estimate(int lines,double(*pf)(int))
{
using namespace std;
cout<<lines<<"lines will take";
cout<<(*pf)(lines)<<"hour(s)\n";
}
C 深入探讨函数指针
一下的声明完全相同
const double * f1(const double ar[],int n);//以数组的方式声明 ar[] 与指针*ar 作为参数时一样都是指针
const double *f2(const double [],int );省略标识符
const double *f4(const double *ar,int n);
const double *f3(const double *,int);指针形式
假设要声明一个指针,指向函数,如果指针名为pa 则只需将目标函数原型中的函数名替换为(*pa)即可
const double *(*pa)(const double *,int); pa=f3;
const double *(*pa)(const double *,int)=f3 同时初始化 等同与上一句
auto pa2=f1;使用c++11中的auto 自动类型推断功能 简化声明
示例:
cout<<(*pa)(av,3)<<":"<<*(*pa)(av,3)<<endl;
cout<<pa(av,3)<<":"<<*pa(av,3)<<endl;
f3返回值的类型为const double * 所以前面的输出都为函数的返回值 指向const double的指针 即地址值
而后面的输出均加上了* 解引用运算符 所以实际输出为指针指向的double值
D 函数指针数组
const doubel * (*pa[3])(const double *,int)={f1,f2,f3};
括号外为 一个函数类型
(*pa[3])括号内部分表示一个包含3个指针元素的数组
综合到一起就是3个指针指向3个不同的函数
pa是一个数组
这里能否使用auto呢?答案是不能,自动类型推断只能用于单值初始化,而不能用于初始化列表;但是声明数组pa后,再声明同样类型的数组就可以用auto了
auto pb=pa;
数组名为指向数组中的一个元素的指针,所以pa和pb都是指向函数指针的指针
pa[i]表示数组中的元素即指针元素,
const double * px=pa[0](av,3); 等同于f1(av,3) 即函数返回值
const double * py=(*pb[1])(av,3); 等同于f2(av,3)
如果想得到指向的double的值 则需要再加上解引用运算符
const double * px=*pa[0](av,3);
const double * py=*(*pb[1])(av,3);
创建指向整个数组的指针,数组名pa表示指向函数指针(数组元素)的指针,所以指向数组的指针就是指向指针的指针,可以对其进行初始化,因为这是单个值。所以可以使用auto
auto pc=&pa;
也可以自己声明 需要再某个位置再加上* 操作符
用*pd来替换原型中的pa
const double *(*(* pd)[3])(const double*,int)=&pa;
pd指向数组,*pd就是数组,而(*pd)[i]是数组中的元素,即函数指针。
所以可以使用 (*pd)[i](av,3)来调用函数。前面加上*为指针指向的double的值
注意pa和&pa的区别,前者指向数组中的的一个元素,即&pa[0],仅仅是单个指针(元素)的地址;后者&pa是整个数组的地址
虽然数值都相同,但是类型是不同的。
**(&pa)==pa[0] *pa==pa[0]
//arfupt.cpp
#include <iostream>
const double * f1(const double ar[],int n);
const double * f2(const double [],int n);
const double * f3(const double *,int n);
int main()
{
using namespace std;
double av[3]={111.1,222.2,333.3};
//定义指向函数的指针
const double * (*p1)(const double *,int )=f1;//p1=f1;
auto p2=f2;//自动推断 c++中
//const double * (*p2)(const double [],int)=f2 等同于上句
cout<<"using pointers to functions:\n";
cout<<"address value\n";
cout<<(*p1)(av,3)<<":"<<*(*p1)(av,3)<<endl;//调用f1 现实double值
cout<<p2(av,3)<<":"<<*p2(av,3)<<endl;
const double *(*pa[3])(const double *,int)={f1,f2,f3}; //指向3个指针的数组 数组名为pa
auto pb=pa; //pb指向数组中的第一个元素
cout<<"\nusing an array of pointers to functions:\n";
cout<<"address value\n";
for(int i=0;i<3;i++)//循环调用指针数组中的各个函数 并且输出地址和指向的double值 利用数组名来调用
cout<<pa[i](av,3)<<":"<<*pa[i](av,3)<<endl; //函数指针数组
for(int i=0;i<3;i++)
cout<<pb[i](av,3)<<":"<<*pb[i](av,3)<<endl;//指向一个函数指针的指针 也即是指向一个指针数组中元素的指针
cout<<"\nusing pointers to an array of pointers:\n";
cout<<"address value\n";
auto pc=&pa;//指向指针数组的指针
//等价于const double *(*(*pc)[3] )(const double *,int)=&pa;
cout<<(*pc)[0](av,3)<<":"<<*(*pc)[0](av,3)<<endl;
//自己声明pd
const double *(*(*pd)[3])(const double *,int)=&pa;
const double *pdb=(*pd)[1](av,3);
cout<<pdb<<":"<<*pdb<<endl;//输出地址和指向的double的值
cout<<(*(*pd)[2])(av,3)<<":"<<*(*(*pd)[2])(av,3)<<endl;//注意*的位置的不同输出的值也不同,前者为地址,后者为double值
return 0;
}
const double *f1(const double * ar,int n)
{
return ar;
}
const double *f2(const double ar[],int n)
{
return ar+1;
}
const double *f3(const double ar[],int n)
{
return ar+2;
}
类的虚方法实现通常都采用了这种技术 :指向函数指针数组的指针
7.10.4 使用typedef进行简化
除了auto外 关键字typedef可以创建类型别名
typedef double real; real为double的别名
示例:
typedef const double *(*p_fun)(const double *,int); //p_fun now a type name 类型为const double * (const double *,int)函数类型
p_fun p1=f1;//p1 points to the f1() function
再利用这个别名来简化代码
p_fun pa[3]={f1,f2,f3}; pa为数组 数组中元素类型为 p_fun
p_fun (*pd)[3]=&pa; pd为一个指向包含3个元素的数组的指针 此数组元素的类型为p_fun
第八章 函数探幽
一.内联函数
不同与普通的函数调用 ,内联函数类似于c语言中的宏 在调用的位置展开函数的代码
是否使用内联函数需要对程序运算效率和资源占用率进行评估,如果普通调用的时间长,且不在乎内存的占用,可以使用内联函数;而如果在乎内存的占用率,不在意运行时间,则仅仅用普通的函数调用;
普通调用需要cpu跳到内存中存储函数的位置执行语句;而内联函数仅仅是在相应的调用函数位置替换成函数的实现代码,仅仅在内存空间上会增大,而不会进行cpu执行指令的跳跃。
声明的方法 需要在函数的原型中进行声明 并且在函数定义前也要加上inline
通常的做法是将整个函数的定义替换函数的原型
示例:
inline double square(double x) {return x*x;}
内联函数和常规函数一样 也可以按值来传递参数 如果参数为表达式,则计算表达式的值,再传递
内联与宏的区别
c 中的宏:#define SQUARE(X) X*X 通过文本替换来实现
b=SQUARE(4.5+7.5); 被替换为 b=4.5+7.5*4.5+7.5 结果不正确
内联就不会出现这样的问题 先计算值 再传递
二 引用变量
为另一个变量的别名 类似与指针 但是实际上是指针的另一个接口 与指针又不完全相同
1.创建
int a;
int &b=a;
b=1;
结果b=1 a=1
int a=101;
int & b=a;
int *c=&a;
表达式b和*c 与a可以互换,而表达式&b 和c与&a可以互换,前者为值,后者为地址
注意引用必须在声明时初始化 而指针可以先声明,再赋值
int & b;
b=a;这种做法是错误的
在这一点上,引用与const 指针 是类似的,一旦与某个变量关联起来 就一直是他,不可改变
int & b=a;实际上是int * const c=&a;的伪装表示
示例:
int a=1;
int &b=a;
int c=2;
b=c;
实际上 b仍然是a的引用,但是b=c执行的是a=c=2,因为b是a的引用,所以b的值也是2
2.2将引用作为函数的参数
引用传递参数可以允许被调用函数能够访问调用函数中的变量 类似与指针的操作。
void swapr(int &a,int &b) 按引用 改变的是调用函数中的变量
void swapv(int a,int b) 按值传递 生成临时变量,不改变原值
2.3 引用的属性和特别之处
如果程序员想使用调用函数中的变量,但是又不想修改
则需要加入const 限定符
double refcube(const double &ra);
当程序试图改变ra的值时, 编译器将生成错误消息
按值传递的函数,可以使用多种类型的实参:
double z=cube(x+2.0) 是合法的
但是引用限制比较严格 引用为变量名的引用 :
double z=refcube(x+3.0); 不合法 因为不能存在这样的表达式:x+3.0=5.0
临时变量 引用参数和const
如果实参与引用参数不匹配,c++将生成临时变量。
仅当参数为const引用时,才会生成临时变量。
创建临时变量的时间
A 实参的类型正确,但不是左值
B 实参的类型不正确,但是可以转换成正确的类型
左值是可以被引用的数据对象 实际上就是代表内存空间 包括const和非const两种左值 可变和不可变
非左值包括字面常量和包含多项的表达式
示例:
double refcube(const double &ra)
{
return ra*ra*ra;
}
double side=3.0;
double * pd=&side;
double & rd=side;
long edge=5L;
double lens[4]={2.0,5.0,10.0,12.0};
double c1=refcube(side); ra is side
double c2=refcube(lens[2]); ra is 10.0
double c3=refcube(rd); ra is rd is side
double c4=refcube(*pd); ra is * pd is side
double c5=refcube(edge); ra is edge 类型不同 但是可以转换成double 所以产生临时变量
double c6=refcube(7.0); 产生临时变量 类型正确 但是不是左值
double c7=refcube(side+10.0); 产生临时变量 类型正确 但是不是左值
生成的临时匿名变量 让ra指向它,这些临时变量只在函数调用期间存在,此后编译器便可以随意将其删除
尽可能使用const
使用const 可以避免无意中修改数据的编程错误;
使用const使函数能够处理const和非const实参,否则将只能接受非const数据
使用const引用使函数能够正确生成并使用临时变量
c++11新增加的右值引用 使用&&来声明
double && rref=std::sqrt(36.00) 用来指向右值
double && jref=2.0*j+18.5;
& 为左值引用 &&为右值引用
将引用用于结构
struct free_throws
{
std::string name;
int made;
int attempts;
float percent;
}
原型的写法:void set_pc(free_throws & ft); 在函数中将指向该结构的引用作为参数
如果不希望函数修改传入的结构,可使用const
void display(const free_throws & ft);
8.3
//strc_ref.cpp
#include <iostream>
#include <string>
struct free_throws
{
std::string name;
int made;
int attempts;
float percent;
};
//prototype
void display(const free_throws & ft); //const 引用
void set_pc(free_throws & ft); //非const 引用 结构
free_throws & accumulate(free_throws & target,const free_throws & source); // 返回指向结构的引用
int main()
{
free_throws one={"ifelsa branch",13,14};//初始化结构体
free_throws two={"andor knott",10,16};
free_throws three={"minnie max",7,9};
free_throws four={"whily looper",5,9};
free_throws five={"long long",6,14};
free_throws team={"throwgoods",0,0};//临时
free_throws dup;//临时2
set_pc(one);
display(one);
accumulate(team,one); //返回指向结构的引用
display(team);//显示指向结构的引用
display(accumulate(team,two));//显示 accumulate函数返回的结构的引用作为参数
accumulate(accumulate(team,three),four);//嵌套函数 参数为函数返回的结构的引用 team可写
display(team);
dup=accumulate(team,five);//函数返回作为右值
std::cout<<"Displaying team:\n";
display(team);
std::cout<<"displaying dup after assignment:\n";
display(dup);
set_pc(four);
accumulate(dup,five)=four;//函数返回值作为左值 函数返回 为一个结构体的引用
std::cout<<"displaying dup after ill-advised assignment:\n";
display(dup);
return 0;
}
void display(const free_throws & ft)
{
using std::cout;
cout<<"name:"<<ft.name<<'\n';
cout<<"made:"<<ft.made<<'\n';
cout<<"attempts:"<<ft.attempts<<'\n';
cout<<"percent:"<<ft.percent<<'\n';
}
void set_pc(free_throws & ft)
{
if(ft.attempts!=0)
ft.percent=100.0f*float(ft.made)/float(ft.attempts);
else
ft.percent=0;
}
free_throws & accumulate(free_throws & target,const free_throws & source)//返回引用 指向结构
{
target.attempts+=source.attempts;
target.made+=source.made;
set_pc(target);
return target;
}
程序说明:
set_pcp(&one); 指针的方式调用 传递的是地址
void set_pcp(free_throws * pt) { pt->attempts=...} 实现 需要使用指针作为参数来接传过来的地址
以上两句的搭配同样可以实现引用的功能,即修改传过来的实参
display(accumulate(team,two));
与下面等效:accumulate(team,two);display(team);
为何要返回引用
传统返回机制与按值传递函数的参数类似
计算return 后面的表达式,并将结果返回给调用函数,但是过程是,计算的结果会被复制到一个临时的位置,而调用程序将使用这个值。
double m=sqrt(16.0); 将4.0复制到一个临时的位置 再被赋值给m
cout<<sqrt(25.0); 5.0被复制到一个临时的位置, 再传递给cout
dup=accumulate(team,five); 如果accumulate()返回一个结构,而不是指向结构的引用,将把整个结构复制到一个临时的位置,再将这个拷贝复制给dup
但是返回值作为引用时,将把team复制到dup 效率更加高效
返回引用时需要注意的问题
避免返回函数终止时不再存在的内存单元的引用
案例:
const a & fun(a & ft)
{
a newguy; //函数内部的变量
newguy=ft;
return newguy;
}
该函数返回一个指向临时变量 newguy的引用,函数运行完毕后将不再存在。同样的也应该避免返回指向临时变量的指针
解决办法1:返回一个指向实参的引用,因为实参不在函数内部定义,因此,可以返回 实参变量不消失
办法2:使用new来分配新的存储空间,使用new为字符串分配内存空间,并返回指向该内存空间的指针。
案例:
const free_throws & clone(free_throws & ft)
{
free_throws * pt;
*pt=ft;
return * pt;
}
为何将const用于引用返回类型
accumulate(dup,five)=four; accumulate 返回类型为非const类型 此语句有效
将five的数据存储到dup中,再使用four的内容覆盖dup的内容。 左侧为必须可修改的左值。左边的子表达式必须标识一个可修改的内存块。
常规(非引用)返回类型是右值-不能通过地址访问的值。这种表达式可以出现在赋值语句的右边,但不能出现在左边。例如 10.0 或者向x+y表达式 都是右值,获取10.0的地址没有意义,常规函数返回值是右值的原因就是这种返回值位于临时内存单元中,运行到下一跳语句时,他们就不再存在了。
如果将accumulate声明为const free_throws & accumulate();则accumulate(dup,five)=four 此语句不成立 因为等号右边为不可修改的左值
将引用用于类对象
将类对象传递给函数时,通常使用引用,例如可以通过使用引用,让函数将类string 、 ostream、istream、ofstream和ifstream 等类的对象作为参数。
示例:
#include <iostream>
#include <string>
using namespace std;
string version1(const string & s1,const string & s2);
const string & version2(string & s1,const string & s2);
const string & version3(string & s1,const string & s2);
int main()
{
string input;
string copy;
string result;
cout<<"enter a string : ";
getline(cin,input);\\input接收string对象的字符串
copy=input;\\string赋值
result=version1(input,"****");
result=version2(input,"####");
result=version3(input,"@@@");
return 0;
}
string version1(const string & s1,const string & s2)
{
string temp;
temp=s2+s1+s2;//连接字符串
reurn temp;//按值返回 程序正常 temp在函数结束后,不存在,所以返回前 会将temp变量的内容复制到一个临时的存储的单元中,然后再将此值赋值给result
}
cosnt string & version2(string & s1,const string & s2)
{
s1=s2+s1+s2;
return s1;//按引用返回 程序正常
}
cosnt string & version3(string & s1,const string & s2) //程序崩溃的原因为试图引用已经释放的内存
{
string temp;
temp=s2+s1+s2;
return temp;//返回函数内部的临时变量的引用 程序崩溃 因temp在函数执行完后 它所代表的内存区域被取消
}
将c风格字符串用作string对象引用参数
对于函数version1 形参为const string & ,实参分别为string和const char * 由于input的类型为string,s1指向input是没有问题的。但是const string & 引用的类型接收了实参为char * 的字符指针类型 第2个参数
解释:一定具有转换的功能 可以使用c风格字符串来初始化string对象。涉及到形参为const引用时的规则 产生临时变量。与实参的类型不匹配但是可以正确转换。
同样也可以将实参char * 或者const char *传递给形参const string &。
这种属性的结果是:如果形参类型为const string & ,在调用函数时,使用的实参可以是string对象或c风格字符串。例如引号括起来的字符串字面量、以空字符结尾的char数组或者指向char 的指针变量 都是可行的
对象 、继承和引用
ostream是基类 (控制台输入出) ofstream是派生类 (文件输入出)
派生类继承了基类的方法 意味着ofstream对象可以使用基类的特性,如格式化方法 precision()和sett()
基类引用可以指向派生类对象 而无需进行强制类型转换
导致的结果就是形参为基类引用 实参可以是基类对象,也可以是派生类对象
ostream & 为形参,可以接受ostream对象或者自己声明的ofstream对象作为参数
示例:可以通过同一个函数 (只有函数调用参数不同) 将数据写入文件和显示到屏幕上来说明
#include <iostream>
#include <fstream>
#include <cstdlib>
void file_it(ostream & os,double fo,cosnt double fe[],int n); //文件 prototype
const int LIMIT=5;
int main()
{
osftream fout;//对象
const char * fn="ep-data.txt";//指定文件
fout.open(fn);//关联文件
if(!fout.is_open())//判断文件是否关联成功
{
cout<<"can't open"<<fn<<".bye.\n";
exit(EXIT_FAILURE);
}
double objective;
cout<<".....";
double eps[LIMIT];
for(int i=0;i<LIMIT;I++)
{
cout<<"asdfasdf";
cin>>eps[i];
}
file_it(fout,objective,eps,LIMIT);//输出到文件
file_it(cout,objective,eps,LIMIT);//输出到标准输出
cout<<"done\n";
return 0;
}
//实现
void file_it(ostream & os, double fo, const double fe[], int n)//其中os可以指向ostream对象 (cout) 也可以指向ofstream对象 (fout)
{
ios_base::fmtflags initial;
initial=os.setf(ios_base::fixed);//备份
os.precision(0); 点后0位
os<<"asdfasdf"<<fo<<"mm\n";
os.setf(ios::showpoint);
os.precision(1); 点后1位
os.width(12);//设置字符宽度
os<<"f.l. eyepiece";
os.width(15);
os<<"magnification"<<endl;
for(int i=0;i<n;i++)
{
os.width(12);
os<<fe[i];
os.width(15);
os<<int(fo/fe[i]+0.5)<<endl;
}
os.setf(initial); //还原默认显示格式
}
每个对象都存储了自己的格式化设置 设置完成之后再恢复为默认的设置
何时使用引用参数:
使用引用参数的主要原因:
程序员能够修改调用函数中的数据对象(传递过来的实参)
提高程序运行的速度
实参不做修改:
数据对象小,内置类型 按值传递
数据对象是数组,使用指针,指针声明为指向const的指针
大结构 使用const指针或const 引用
类对象 const引用
实参需要修改:
内置类型 使用指针
数组 只能使用指针
结构 指针或者引用
类对象 引用
默认参数
将默认真赋值给原型中的参数
char * left(const char *str,int n=1); 原型 中从右向左开始按顺序赋初值 不允许跳跃
char harpo(int n,int m=4,int j=5);成立
调用:
left(sample,4); 不使用默认值
或者 left(sample); 使用默认值
空值字符的编码为0,循环将结束。
函数重载
也叫函数多态,让您能够使用多个同名的函数
函数名相同,但是参数列表不同 也叫函数特征标不同,
什么叫做函数特征标相同:两个函数的参数数目 和 类型相同,同时参数的 排列顺序也相同,则它们的特征标相同。与变量名是无关的
示例:
原型:
void print(const char * str,int width); #1
void print(double d,int width); #2
void print(long l,int width); #3
void print(const char * str); #4
调用:
print("pancakes",15); 对应#1
print("syrup"); 对应#4
print(year,6); 没有匹配,但是并不会自动停止使用其中的某个函数,因为c++尝试使用标准类型转换强制进行匹配。如果原型仅#2 则c++会强制转换为#2,但是如果有多个原型符合,例如#2 和#3都适合 则就会发生错误 编译器不知道转换到那个函数
参数如果为类型的引用和类型 则编译器将视为是一个特征标
即double cube(double x); 和 double cube(double & x); 不是重载函数
另一个:const和非const变量
示例:
void dribble(char * bits); #1 重载
void dribble(const char * cbits); #2 重载
void dabble(char *bits); #3
void drivel(const char * bits); #4
const char p1[20]="how's the weather?";
char p2[20]="how's business?";
dribble(p1); 2
dribble(p2); 1
dabble(p1); 没有匹配的 const类型 没有匹配的
dabble(p2); 3
drivel(p1); 4
drivel(p2); 4 可以 将非const 传递给const形参
将非const值赋值给const变量是合法的,但反之则是非法的。
参数列表 特征标 而不是函数类型使得可以对函数进行重载。
long gronk(int n,float m); //这两个函数不是重载的函数
double gronk(int n,float m); 所以声明两次是不允许的
函数名相同但是参数列表不同 返回类型可以不同
重载引用函数 类设计和STL经常使用引用参数
void sink(double & r1); //参数为可修改的左值
void sank(const double & r2); //参数为可修改或不可修改的左值 或者右值
void sunk(double && r3); //右值
假设 重载使用这三种参数的哦函数,结果需要调用最匹配的函数
void staff(double & rs); 可修改左值 1
void staff(const double & rcs); 右值 或者常量左值 2
void stove(double & r1); 可修改左值 3
void stove(const double & r2); 常量左值 4
void stove(double && r3); 右值 5
调用:
double x=55.5;
const double y=32.0;
stove(x); 3
stove(y); 4
stove(x+y); 5 如果5没有定义,则stove(x+y) 将调用函数stove(const double &)
案例:
8.10 leftover.cpp
略
8.4.2 何时使用函数重载
函数重载仅当函数基本上执行相同的任务,但使用不同形式的数据时,才应采用函数重载。
注意默认参数的函数和函数重载之间的区别,如果需要使用不同类型的参数,则默认参数便不能使用了 必须要用到函数重载。
小贴士: 名称修饰
概念:也叫名称矫正 给重载函数指定秘密的身份
功能:用于c++的跟踪 每个重载函数
原理:编译器根据函数原型中指定的形参类型对每个函数名进行加密 以进行跟踪
例子: 源代码
long My FunctionFoo(int ,float);
转变为:?MyFunctionFooYAXH 此行根据函数的特征标不同而不同 用于编译器跟踪
函数模板
函数模板为通用的函数描述,使用泛型来定义函数 其中的泛型可以使用具体的类型来替换
通过类型作为参数传递给模板,可使编译器生成该类型的函数。
示例:
template <typename AnyType> 红色部分为必需的部分,可以用class(c++98标准)代替typename 必须使用尖括号 AnyType为类型名
void Swap(AnyType &a,AnyType &b)
{
AnyType temp;
temp=a;
a=b;
b=temp;
}
通常用T来代替AnyType
案例:
#include <iostream>
template <typename T>
void Swap(T &a,T &b)
int main()
{
using namespace std;
int i,j;
...
Swap(i,j); //此时会生成int版本的函数代码
double x,y;
Swap(x,y); //此时生成double版本的函数代码
return 0;
}
template <typename T>
void Swap(T &a,T &b)
{
T temp;
temp=a;
a=b;
b=temp;
}
重载的模板
需要多个对不同类型使用同一种算法的函数时,可使用模板。
并非所有的类型都使用相同的算法。 此时就需要针对不同的函数特征标,来定义不同的模板函数 即 重载模板 参数列表不同
案例:
#include <iostream>
template <typename T> # 1
void Swap(T &a,T &b)
template <typename T> # 2
void Swap(T *a,T *b,int n);//注意此时最后一个参数是int类型的, 而不是泛型, 所以说并非所有的模板参数都必须是模板参数类型
int main() //模板的重载
{
int i,j;
...
Swap(i,j);// 调用1
int d1[8]={0,7,0,4,1,7,7,6};
int d2[8]={0,7,2,0,1,9,6,9};
show(d1);
show(d2);
Swap(d1,d2,8);// 调用2
return 0;
}
template <typename T> #1
void Swap(T &a,T &b)
{
T temp;
temp=a;
a=b;
b=temp;
}
template <typename T> # 2
void Swap(T a[ ],T b[ ],int n)
{
T temp;
for(int i=0;i<n;i++)
{
temp=a[i];
a[i]=b[i];
b[i]=temp;
}
}
void show(){ }
模板的局限性
template <class T>
void f(T a,T b)
{
a=b; //此时如果T为数组 此语句不能执行
if(a>b) //此时如果T为结构体 则>和< 运算符不能执行
T c=a*b //此时如果T为数组、指针或者结构 此语句也不能执行
}
因此通过上例可以看出 模板函数有时无法处理特殊的类型 一方面需要通用化,另一方面又需要为特定类型提供具体化的模板定义。
显示具体化
概念:提供的一个具体化的函数定义--称为显示具体化 其中包含所需的代码。当编译器找到与函数调用匹配的具体化定义时,将使用该定义,而不再寻找模板。
示例:
struct job
{
char name[40];
double salary;
int floor;
}
模板函数 swap() {} 的功能是交换两个job结构中的三个成员值 使其互换
但是如果仅仅想交换salary和floor两个成员变量的值时,模板函数无法提供相应的功能,此时就需要显示具体化的函数定义
1.第三代具体化 iso/ansi c++标准
分类:给定的函数名 可以有非模板函数、模板函数和显示具体化模板函数以及它们的重载版本
显示具体化的原型和定义应该以 template < > 开头 ,并通过名称来指出类型
具体化优先于常规模板,而非模板函数优先于具体化和常规模板 也就是优先级 = 非模板 > 显示具体化函数 > 常规模板函数
函数原型的定义示例:
void swap(job &,job &); 常规函数 即非模板函数 #1
template <typename T> 模板函数 #2
void swap(T &,T &);
template < > void swap <job> (job & ,job &); 显示具体化函数 #3
//template <> 函数名 <函数类型>(参数列表);
template <class T> 模板函数
void swap(T &,T &);
template <> void swap<job>(job &,job &); 显示具体化 其中<job> 中的job是可选的,因为函数的参数类型表明 这是job的一个具体化 (括号中已经指明了是job类型的参数) 所以也可以这样写template <> void swap(job &,job &); 这种简单的格式
int main()
{
double u,v;
...
swap(u,v); 使用模板函数
job a,b;
...
swap(a,b);使用显示具体化
}
显示具体化示例:
//twoswap.cpp
#include <iostream>
template <typename T>//函数模板
void Swap(T &a,T &b);
struct job
{
char name[40];
double salary;
int floor;
};
template <> void Swap<job>(job &j1,job &j2);//显示具体化
void show(job &a);
int main()
{
using namespace std;
cout.precision(2);
cout.setf(ios::fixed,ios::floatfield); //格式化设置
int i=10;
int j=20;
cout<<"i,j="<<i<<","<<j<<".\n";
cout<<"using compiler-generated int swapper:\n";
Swap(i,j); //此时调用模板
cout<<"now i,j="<<i<<","<<j<<".\n";
//下面为结构体
job sue={"susan yaffee",73000.60,7};
job sidney={"sidney taffee",78060.72,9};
cout<<"before job swapping:\n";
show(sue);
show(sidney);
Swap(sue,sidney);//此时调用具体化
cout<<"after job swapping:\n";
show(sue);
show(sidney);
return 0;
}
template <typename T> //模板实现
void Swap(T &a,T &b)
{
T temp;
temp=a;
a=b;
b=temp;
}
template <> void Swap<job>(job &j1,job &j2) //具体化实现
{
double t1;
int t2;
t1=j1.salary;
j1.salary=j2.salary;
j2.salary=t1;
t2=j1.floor;
j1.floor=j2.floor;
j2.floor=t2;
}
void show(job &j)
{
using namespace std;
cout<<j.name<<":$"<<j.salary<<"on floor"<<j.floor<<endl;
}
注意上例中的Swap中的S如果替换为小写的s 会出现call of overload is ambiguous 调用重载函数不明确 原因就是在std名称空间中还有一个swap函数 重复定义 所以解决办法为函数名不同或者在swap()前加上::
即 ::swap( )
实例化和具体化
实例化与类和对象类似 模板相当于类 函数调用时相当于实例化 的对象
1.函数模板不是函数定义 仅仅是生成函数定义的方案
2.编译器使用模板为特定类型生成函数定义,得到函数实例化 例如 int i,j; swap(i,j); 得到一个swap函数的实例。此实例使用int类型
3.模板不是函数定义,但是使用int类型的模板的实例就是一个函数定义
以上是隐式实例化的例子 编译器通过程序中给swap模板函数提供了int类型 编译器才知道如何实例,并且进行定义。
隐式实例化时编译器自动运行生成的实例
而c++ 编译器可以允许显式的实例化 也就是可以直接用命令 使得编译器创建特定的实例,例如swap<int> ( )
语法为:声明所需的类型 用<>符号指示类型 并在声明前加上关键字 template
template void swap<int>(int ,int); 这是显式的实例化
template <> void swap<int>(int &,int &); 这是显式具体化1 声明
tmeplate <> void swap(int &,int &); 显式具体化2 声明
具体化1和具体化2是等价的
具体化12声明的意思是:不要使用swap()模板来生成函数定义,而应使用专门为int类型显式地定义的函数定义(使用具体化的定义)
注意实例化和具体化的区别是:在template后,具体化声明有<>,而实例化没有<>;
试图在同一个文件(或转换单元)中使用同一种类型的显式实例和显式具体化将出错
显式实例化案例:
template <class T> //普通模板
T Add(T a,T b)
{
return a+b;
}
...
int m=6;
double x=10.2;
cout<<Add<double>(x,m)<<endl; 显式实例化 直接用命令调用编译器通过模板来实例化函数
x和m 不匹配,因为该模板要求两个函数参数的类型相同。但是显示实例化中的命令Add<double>(x,m) 可以强制为double类型实例化,并将参数m强制转换为double类型,以匹配模板函数
如果将swap函数也显式实例化的命令 swap<double> (m,x) 这些代码无用,因为第一个形参的类型为double & ,不能指向int变量m 无法强制转换
隐式实例化(编译器默认行为)、显示实例化和显式具体化统称为具体化。
相同之处: 表示的都是使用具体类型的函数定义,而不是通用描述(通用模板)
显式具体化和显式实例化的语法是不同的 template后面受否跟着<>
示例:
template <class T>
void swap(T &,T &); //通用模板 1
template <> void swap<job>(job &,job &); //显式具体化 声明 2
int main(void)
{
template void swap<char>(char &,char &); //显式实例化 for char类型 编译器看到后就会使用模板定义来生成swap的char版本 3
short a,b;
swap(a,b); 调用通用模板 生成short版本的函数 1
job n,m;
swap(n,m); 调用显式具体化 生成job版本的函数 2
char g,h;
swap(g,h); 调用显式实例化生成的模板具体化的函数定义 3
}
编译器选择使用哪个函数版本 */**********
对于函数重载、函数模板和函数模板重载等,c++编译器需要有一个良好的策略来决定函数实现时应该调用哪一个函数的定义,尤其是有多个参数。
上面的过程叫做重载解析。
大致的过程:
1.创建候选函数列表,其中包含与被调用函数的名称相同的函数和模板函数
2.使用候选函数列表创建可行函数列表。
这些都是参数数目正确的函数,为此有一个隐式转换序列,其中包括实参类型与相应的形参类型完全匹配的情况。
例如 使用float参数的函数调用可以将该参数转换为double 从而与double形参匹配,而模板可以为float生成一个实例。
3.确定是否有最佳的可行函数。如果有,则使用它,否则该函数调用出错
案例:
函数:may('B'); 参数的类型是一个字符类型 函数调用
首先编译器找候选者,即名称为may()的函数和函数模板。
再次寻找一个参数的函数
下面的函数:
void may(int); #1 不需要转换
float may(float,float=3); #2 默认参数可行
void may(char); #3 隐式转换为char
char * may(const char *); #4 整数不能被隐式地转换为指针类型 所以此函数不可能被调用
char may(const char &); #5 常量引用 可以接收整型的变量
template <class T> void may(const T &); #6 常量引用
template <class T> void may(T *); #7 整数不能被隐式地转换为指针类型 所以此函数不可能被调用
注意只考虑特征标,而不考虑返回类型。其中的两个候选窜函数#4和#7不可行,因为整数类型不能被隐式地转换为指针类型。剩余的一个模板可用来生成具体化,其中T被替换为char类型。
#1---#7中 4和7不能被调用。
然后编译器需要确定哪个可行函数是最佳的。 它查看为使函数调用参数与可行的候选函数的参数匹配所需要进行的转换。通常优先级如下:
1.完全匹配 常规函数优先于模板函数
2.提升转换 例如 char和shorts 自动转换为int ;float自动转换为double
3.标准转换 例如int转换为char long转换为double
4.用户定义的转换,如类声明中定义的转换
#1优于#2 char到int的转换时提升 char到float是标准转换
# 3 5 6 都优于#1 2 因为它们完全匹配
#3 和#5优于#6 因为6是函数模板
剩下3和5 如何区分呢?
对完全匹配有如下的讨论
1.完全匹配和最佳匹配
完全匹配时,c++允许某些 无关紧要的转换

type可以是常规的类型 也可以是类似char &的类型
type 意味着用作实参的函数名与用作形参的函数指针只要返回类型和参数列表相同,就是匹配的。
struct blot{int a ;char b[10];};
blot ink={25,"spots"};
recyle(ink);
下列的原型都是完全匹配的: 实 形参
void recycle(blot); blot-to-blot
void recycle(const blot); blot-to-(const blot)
void recycle(blot &); blot-to-(blot &)
void recycle(const blot &); blot-to-(const blot &)
如果有多个匹配的原型 则编译器无法解析过程;如果没有最佳的可行函数,则编译器将生成一条错误消息,该消息可能会使用诸如“ambiguous(二义性)”这样的词语。
即使两个函数完全匹配 也可以完成重载解析的情况:
指向非const数据的指针和引用优先与非const指针和引用参数匹配。
略
