
c++ primer plus 第6版
源代码 ---编译器---目标代码---连接程序(启动代码--库代码)---可执行代码
源代码扩展名:c cc cxx C cpp c++
编译和链接:unix CC **.c ------》**.o -----》a.out
linux g++ **.cxx 需要链接库时的命令:g++ **.cxx -lg++;多个文件的编译 g++ 1.cxx 2.cxx中如果修改了1.cxx则编译时需要的命令
g++ 1.cxx 2.o 将重新编译的1.o与2.o重新链接。
参照linux或unix 中man帮助 编译器的命令手册
当ide中执行完程序后马上 关闭窗口,可以在程序源代码的后面加上
cin.get();\\加入状态 读取下一次键击 等待 直到按下enter按键
cin.get();
return 0;
第2章
1.区分大小写
2. #include <iostream> 添加的预处理的文件
using namespace std;
cout<< endl; 开始一个新行
3.在return 之前 加上cin.get(); 一致开着窗口不关闭
4.预处理器编译指令#include
5.编译指令 using namespace
6.函数头部 c++使用 int mian (void)这种用法 void 指出不接受任何参数
7.注释 //单行 多行用/* */
8.预编译 将#后面的命令 预编译 例如iostream 将ioistream的内容编译后替换#后面的内容 与编写大代码文件组合成一个复合文件。
9.上面iostream 如果在c中需要有.h的后缀 但是在c++ 中如果使用c中的老式头文件 仍然可以使用.h的扩展名 但是有些文件都去掉了.h扩展名 并且在文件名称的前面加上前缀c 表示来自c语言的头文件库。例如c++中使用math.h为cmath 这种变化对包含命名空间有用。
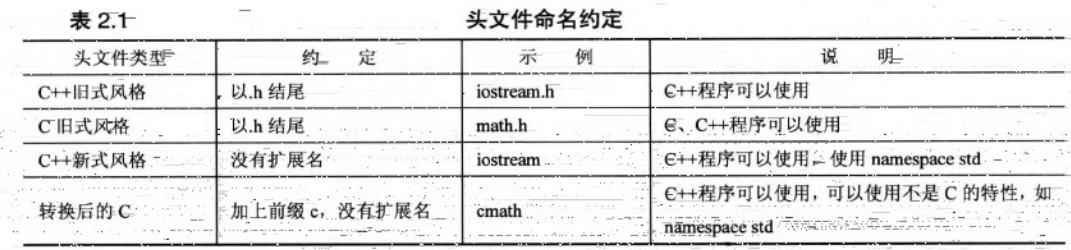
10名称空间
如果使用iostream 而不是iostream.h 则应该使用命名空间编译指令来使用iostream中的定义对程序可用 using namespace std;
这叫using编译指令 名称空间主要用来在大程序中将多个厂商的现有代码组合时,来组织程序。
大概的意思就是 a公司的代码 wo()函数 和b公司的代码中的wo() 函数,这两个函数同时封装到一个叫做名称空间的单元中,此时a公司的wo()函数在空间中被标记为a::wo() 而b公司的代码为b::wo(); 以此来区分不同的函数或者版本
仅仅当头文件中没有.h的时候 才是上面的情况
按照c++的标准组件,他们都被放置到名称空间std中。 所以调用的时候通常是std::cout std::endl
可以省略掉using
即 std:: cout<<*******
std::cout<<std::endl;
这样用起来比较繁琐 所以使用using namespace std 即可 ,而不必使用std::前缀
using编译指令使得std 名称空间中的所有名称都可用。
当然严谨一些 只使用所需的名称即可。用using声明来实现
using std::cout 仅仅使用cout即可 而不必使用std::cout
using std::endl
using std::cin
11. cout 的输出
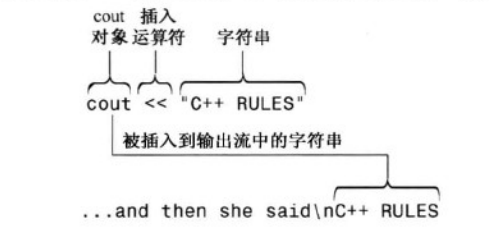
<< 表示将后面的双引号中的字符串发送给cout函数
cout对象表示输出流 (程序中流出的一些列字符),其属性是在iostream文件中的定义的。cout的对象属性包括一个插入运算符 << ,它可以将其右侧的信息插入到流中。
例如 cout<<"fuck"; 理解为将字符串fuck 插入到输出流中。
12.运算符的重载
以上面的<<为例 在c中 此符为左移运算符 << 在c++中则是左移运算符 此为运算符重载 导致的不同的运算符有不同的含义。
c本身也有运算符重载的情况 &即表示地址运算符 也表示按位and的运算符
*既表示乘法 有表示指针解除引用 编译器如何判断意义呢:答案就是根据上下文的含义来确定。
1.endl 重启一行 导致屏幕的光标移动到下一行的开头。
例如endl的一些对于cout来说有特殊含义的特殊符号被称为控制符。 在iostream中定义 且位于名称空间std中
如果没有换行符 则下一个cout的字符串的输出会紧跟在上一个cout的输出的末尾。
2.换行符
c中的旧式 换行符号 \n
cout<<"*****\n"; 此为换行符
\n和endl的区别:endl 可以确保程序继续运行前刷新输出 即在屏幕上立即显示
\n则不能如此
有时候 在有些系统中 在您输入信息后才会出现提示
13 c++ 源代码的格式化
以分号分割每一条语句 而不是回车符或其他符号
1.代码中的标记和空白
一行代码中不可分割的元素叫做标记 多个标记用空格 制表符或回车分开,这些都称为空白
括号和逗号等不需要空白分开。
14.c++语句
c++程序是一组函数 每个函数又是一组语句。
声明语句创建变量
赋值语句给该变量提供一个值。
1.声明语句和变量
指出信息的存储位置和所需要的内存空间 使用声明语句来指出存储类型并提供位置标签。
int carrots;
指出空间为一个整数的存储空间 和编译器负责分配一个整数大小的内存空间给变量carrots这个变量并标记。
c++可以在首次使用变量之前声明 ,不必非在程序的开始部分声明,当然在开始位置声明更好。
2.赋值语句
将数值赋值给内存单元
c++的特性和c不同的地方 可以连续使用赋值运算符 例如 : a=b=c=3;
赋值从右向左进行。首先3给c c给b b的值再给a
3.cout的新花样
cout <<a; 如果a的值为1 则 输出值为1
做了两步 1.cout先将a的值替换为当前的值1 2.将数值1转换为何时的字符输出
cout 可以用于数值和字符串
如果定义字符串“25” 则字符串存储的是书写该数字时使用的字符。即字符3和8 程序的内部存储的是字符3和字符8的编码 如果要打印字符串,则cout仅仅打印各个字符即可。
如果定义的数值是整数25 则将25转换为二进制数存储在内存单元中。 打印之前cout需要将整数形式的数字转换为字符形式的数字再打印 例如itoa()函数的功能 atoi()的功能是将asc码转换为对应的数字。
cout 后面的<<插入运算符将根据其后的数据类型相应地调整其行为。运算符重载。
cout 可以扩展 extensible 用户可以自定义<<的运算符,,使其能够识别和显示所开发的新的数据类型。
15.其他的c++语句
cin 与cout对应的 要求输入的对象
cin>>a;
将键盘输入的值赋值为a
如果程序中要求添加cin.get() 则需要添加两条这样的语句 cin.get();
第一条获取数值 第二条让程序停止 直到输入enter键
cout<<"now you have"<<a<<"adsjfo0uo"<<endl;
组合输出
15.1 使用cin
将键盘上的值赋给变量a
cin>>a;
信息从cin流向a c++将输入看做是流入程序的字符流。
iostream 文件将cin定义为一个表示这种流的对象。输入时,cin使用>>运算符从输入流中抽取字符,通常需要在运算符右侧提供一个变量,以接受 抽取的信息(符号<<和》》被选择用来指示信息流的方向。)
cin也是智能对象 如果a 为整形变量 则输入的就被cin转换为计算机用来存储整数的数字形式。
15.2 cout进行拼接 cout<<a<<b<<c; 拼接 输出
也可以cout <<a;
<<b;
<<c;
15.3类简介
类为用户定义的一种数据类型 oop对象编程。
cout 和cin 是一个ostream类对象 此类(iostream文件的另一个成员)描述了ostream对象表示的数据以及可以对它执行的操作,如将数字或字符串插入到输出流中。同样cin是一个istream类的对象,在iostream中定义。
像函数来自于函数库 类也可以来自类库 ostream和istream类就属于这种情况。这些类并没有内置到c++语言中,而是语言标准指定的类。这些类定义位于iostream文件中。没有被内置到编译器中。多数实现都在软件包中提供了其他类的定义。事实上 c++的优势就是由于存在大量支持 unix winodws 和mac编程的类库。
要对特定对象执行这些允许的操作,需要给该对象发送一条消息,例如告诉cout对象 要显示一个字符串
传递消息的方式:1是使用类方法 实际上就是函数调用 2是重新定义运算符。
cout<<"fuck"; 就是使用了第2种方法。
16 函数
函数分两种 有返回值 和无返回值
1.有返回值
使用函数之前 编译器需要知道函数的参数类型和返回值得类型
c++ 程序应当为程序中使用的每个函数提供原型
函数原型对于函数 就像变量声明对于变量 指出涉及的类型 仅仅描述函数接口 并非函数定义(描述函数的实现的代码)
例如 函数sqrt函数定义为可能带小数部分的数字 并返回一个相同类型的数字,c++将这种类型称为double
原型为 double sqrt(double);
第一个double 指出返回值的类型 括号中的指出参数的类型 上面带有分号 所以说明是一个原型 而不是函数头
如果是函数头 没有分号 则编译器就会将其解释为一个函数头 并要求提供定义该函数的函数体。
使用sqrt()时 需要提供原型
两种方法: 在源代码文件中输入函数原型
包含头文件 cmath (即c中的math.h) 其中定义了函数的原型 推荐此方法
库文件包含函数的编译代码 而头文件中包含了原型
如果是老式的编译器 需要使用math.h 而不是cmath
库函数的使用
c++库函数存储在库文件中 使用时 需要在库文件中搜索您使用的函数 如果提示一个没有定义的外部函数 则有可能是编译器不能自动搜索函数所在的库。
如果出现这种情况 在unix中 则需要使用-lm选项 以搜索 CC sqrt.C -lm
在linux中 g++ sqrt.C -lm
只包含头文件 仅可提供原型,但是不一定会导致编译器搜索正确的库文件
type-name variable-name;
double类型使得变量area和side能够存储带小数的值
函数变体
多个参数 answer=pow(5.0,8.0);
无参数 myguess=rand();rand 不接受任何参数
无返回值 void bucks(double); 所有此函数不能用于赋值语句的右侧 或其他表达式中
用户定义的函数
函数原型放到main函数之前 源代码放在main函数的后面
函数的格式
type functionname(argumentlist) 此为函数头
{
statements 此为函数体
}

用户定义的有返回值的函数

通常在一个简单敞亮的地方 都可以使用一个返回值类型与该常亮相同的函数
例如int aunt=stonetolb(10);
int aounts=aunt+stonetolb(10);
cout<<"adsfasdf"<<stonetolb(16)<<"adsf"<<endl;
总结 函数原型描述了函数的接口,即函数如何与程序的其他部分交互
参数列表指出何种信息被传递给函数
函数类型 指出返回值的类型
见上图。
程序案例
#include <iostream>
int stonetolb(int);
int main()
{
using namespace std;
int stone;
cout<<"adsfasdf";
cin>>stone;
int pounds=stonetolb(stone);
cout<<stone<<"stone=";
cout<<pounds<<"pounds."<<endl;
return 0;
}
int stonetolib(int sts)
{
return 14*sts;
/*
int pounds=14*sts;
return pounds;
*/
}
stonetolb() 包含全部的函数特性
有函数头和函数体
接受一个参数
返回一个值
需要一个原型
在多函数程序中使用using编译指令
using namespace std
因为每个函数都使用cout 所以需要能够访问位于名称空间std中的cout定义
using编译指令可以位于函数的外部 也可以位于函数的内部
例如 1. 所有函数都需要访问std 空间
所以using编译指令需要在所有函数的外面
#include <iostream>
using namespace std; //编译指令
void A(int);//A函数的原型
int B(int);//B函数的原型
int main()
{ cout<<"adsfasdf"; //使用std命名空间中的cout
}
void A(int n){ cout<<"adsflkajsljll!";} A函数头和函数体
INT B(int n){ cout <<"adsfadsf";}
2.将using namespace std;放在特定的函数定义中,让该函数能够使用名称空间std中的所有元素
3.在特定的函数中使用类似using std::cout;这样的编译指令 ,而不是using namespace std; 让该函数能够使用指定的元素,如cout
4.完全不适用编译指令suing 而在需要使用名称空间std中的元素时,使用前缀std:: 如下所示 std::cout<<"asdfasdf"<<std::endl;
17.命名约定
Myfucntion () myfunction() myFunction() my_function() my_funct() 等等根据开发团队 品味和喜好 尽量在全部源代码中保持一致。
18 总结
c++语句包括下述6种
声明语句
赋值语句
消息语句 将消息发送给对象 激发某种行为
函数调用 执行函数 被调用的函数执行完毕后,程序返回到函数调用语句后面的语句
函数原型 生命函数的返回类型 函数接受的参数数量和类型
返回语句 将值从被调用的函数哪里返回到调用函数中
第三章 处理数据
一.oop的本质 是设计并扩展自己的数据类型。设计自己的数据类型就是让类型与数据匹配
创建自己的类之前 必须了解并理解c++的类型 因为这些类型是创建自己类型的基本组件
内置c++类型分为两组:基本类型和符合类型
基本类型:整数和浮点数
复合类型:数组 字符串 指针 结构
2.变量 int var=5; var为变量名 标识内存地址 检索var的内存地址 &var
不能以数字开头 区分大小写 不能将c++ 关键字用作名称 只能使用字母字符、数字和下划线。
两个下划线或下划线和大写字母开头的被保留 一个下划线开头的被保留给实现 全局标识符
3.整型
没有小数部分的数字
c++基本类型 按宽度递增 char short int long long long (双long c++11新增)
c++提供了灵活的标准 确保最小长度
short 最少16位 ;int至少和short一样长;long至少32位,且至少与int一样长;long long至少64位,且至少与long一样长
当前很多系统都是用最小长度 short为16位 long为32位
这仍然为int提供了多种选择,其宽度可以是16位,24位或32位。
以上四种均为符号类型
a.运算符sizeof和头文件limits
sizeof 运算符返回类型和变量的长度 单位为字节;climits定义了符号常量来表示类型的限制 例如INT_MAX表示类型int能够存储的最大值
字节的含义依赖于实现 所以在不同的系统中,某个数据类型的长度有可能不同。在climits 头文件中 包含了限制信息 例如INT_MAX为int的最大取值;CHAR_BIT为字节的位数。
符号常量----预处理方式
#define INT_MAX 32767 此语句位于climits文件中
与#include一样 将#define 也是一个预处理编译指令
c++编译过程,首先将源代码传递给预处理器。该编译指令的意思是在程序中查找INT_MAX 将所有的INT_MAX都替换为32767. 在所有的都被替换后,再编译。预处理器查找独立的标记 即单词跳过嵌入型的单词, 所以对PINT_MAXTM 这样的并不替换
c++中更好的创建符号常量的方法是使用关键字const 但是有些头文件 尤其是用于c和c++中的头文件,必须使用#define
b.初始化
在使用变量a或者表达式b 进行初始化其他变量时,需要a和b在此语句之前已经被声明定义过。否则是非法的
c++独有的初始化语法:int a(43) 将a的值赋为43
c.c++11初始化的方式
此方式用于数组和结构 在c++98中可用于单值变量
int a={24} a为24
将大括号初始化器 用于单值变量不多,但是c++11使得这种情况多了,首先此种方式可以使用= 也可以不用。
int a{7};或者int a={7}
其次大括号可以不包含任何东西
int a={} int b{} 变量将被初始化为0
d,无符号类型
前面的4中整形都有一种不能存储负数值的无符号变体, 可以增大变量能够存储的最大值
short为-32767---+32768 无符号为:0-65535 仅当数值不会为负时才应该使用无符号类型 使用关键字 unsigned 此为本身是unsigned int的缩写
例如 unsigned short a;
short b;
1. a=0 b=0;
a-1 a为65535 溢出
b-1 b为-1 不溢出
2. a=32767
b=35767
a+1 32768 不溢出
b+1 -32768 溢出

e 选择整形类型
int为设置为对目标计算机而言最为自然的长度 自然长度指处理起来效率最高的长度。
如果仅仅使用一个字节 则可以使用char
在使用大型的数组时 常使用short 节省内存
f.整形字面量值
显示的书写的常量 十进制 八进制 16进制 仅仅显示不同而已,在内存中实际是二进制存储
0x(1-f) 代表16进制 0(1-7)表示8进制 1-9 十进制
hex octal decimal
默认情况下 cout以十进制格式显示
cout中有显示的控制字符 hex dec oct 分别对应16 10 8进制的显示方式,默认显示十进制
int a=42;
cout<<hex; 控制符hex实际上是一条消息 告诉cout采取何种行为 hex位于名称空间std中,程序使用了该名称空间 所以不能使用hex为变量名
cout<<"十六进制的数值为:"<<a;
g.c++确定常量的类型
cout<<"year="<<1492<<"\n";
程序将1492存储为int long还是其他整型呢?答案是,除非有理由存储为其他类型(如使用了特殊的后缀来表示特定的类型,或者值太大,不能存储为int),否则c++默认为将整型常量存储为int类型。
后缀:放在数字常量后面的字母,用于表示类型。整数后面的l或者L后缀表示该整数long常量,u或者U后缀表示unsigned int 常量 ul表示unsinged long常量。
22022L 被存储为long 占32位。
ull Ull uLL ULL 等等都用于表示类型 unsigned long long
长度:对于不带后缀的十进制整数,将使用下面几种类型中能够存储该数的最小类型来表示:int long 或者long long
十进制:int为16位,long为32位的计算机系统上:20000被表示为int类型 40000被表示为long类型 3000000000 表示为long long类型。
十六进制或八进制:使用下面的几种类型中的能够存储该数的最小类型来表示:
int 、 unsinged int long、unsigned long 、long long或者unsinged long long.
在将40000表示为long的计算机系统中 十六进制数0x9c40 将被表示为unsigned int
h.char类型:字符和小整数
可以看做比short更小的整型 所有的字母 数字和标点符号
例如:
char ch;
cin>>ch;
cout<<ch;
输入M 对应的字符编码为77 输出的是M 不是77;内存中的数值为77 由此可以证明 cin将键盘输入转化为77 cout将内存中的77转化为M
cin和cout都由变量类型引导。
例2
char ch='M';
int i=ch;
cout<<ch<<i; 输出M i为77
ch=ch+1;
i=ch;
cout<<ch<<i; 输出N i为78
cout.put(ch); 输出为N
cout.put('!'); 输出为字符常量 !
说明 'M'表示M的数值编码 i为编码的数值 77
char ch; cin>>ch; 键盘输入的数字被视为字符
如果按键盘上的数字5 则被视为‘5’字符 转换为ascii编码为53存储到ch代表的单元中。
cout.put() 为成员函数 句点. 为成员运算符 通过类的对象cout(实例)来调用类iostream中的成员函数put()
出现它的原因是 早期的c++版本将字符常量存储为int类型 ‘M’编码77被存储的int类型的内存单元中
char ch='M'; 对于cout来说 'M'和ch有很大的区别 虽然值相同 但是前者占用int类型的空间 char仅占用8位的空间
上面的语句从常量'M'中复制8位(左边的8位)到变量ch中
cout<<'$'; 打印$的ascii码 而不是字符
cout.put('$'); 打印$
release 2.0之后,c++将字符常量存储为char类型 而不是int类型 此时cout可以正确的处理字符常量了
源代码如下
#include <iostream>
int main()
{
std::cout<<'$';
std::cout<<std::endl;
std::cout.put('$');
return 0;
}
char 字面值
单引号 括起的常规字符 表示字符常量 代表字符的数值编码
一些字符无法从键盘输入 则需要转义的方法
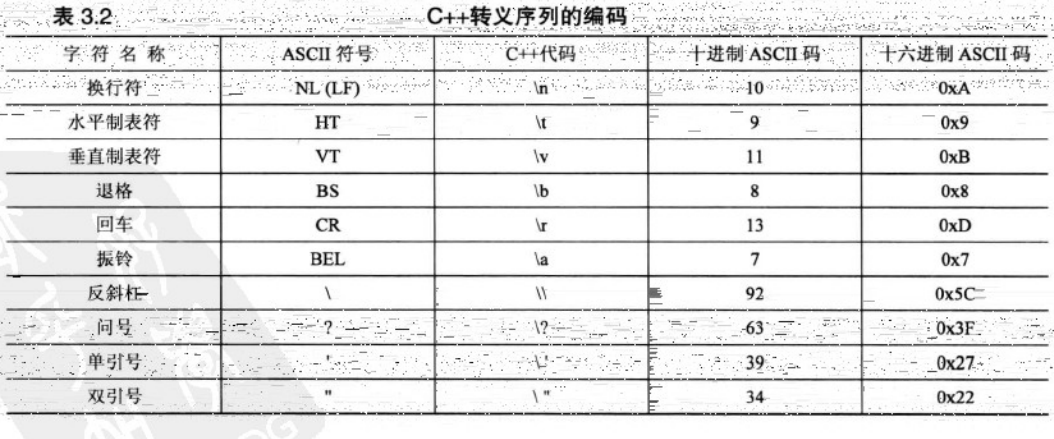
当这些转义字符用作字符常量的时候 ,应该用单引号括起;将他们放在字符串中时,不要使用单引号
'\n' "akjsdhflkh\"aldsfjljl\"\n"
也可以基于字符的八进制和十六进制编码来使用转义序列。例如ctrl+z的ascii码为26 对应的八进制为032 十六进制为0x1a 所以可以用转义字符\032 或 \x1a表示
通用字符名
一个基本的源字符集 可用来编写源代码的字符集;
一个基本的执行字符集 包括程序执行期间可处理的字符
允许实现提供扩展源字符集合扩展执行字符集
unicode和iso 10646 ascii码为unicode的子集
signed char 和unsigned char
与int 不同的是,char在默认情况下既不是没有符号,也不是有符号,可以显示的设置
unsigned char 表达的范围为0-255
char 表达的范围为-128-127
wchar_t 宽字符类型 表示扩展字符集
当需要处理的字符集无法用一个8位的字节表示时,c++处理的方式有两种:大型字符集作为基本字符集,可将char定义为16位的字节或更长的字节,容量够大
另一种是可以同时支持一个小型基本字符集和一个较大的扩展字符集。8位char表示基本字符集,另一类型wchar_t表示扩展字符集,有足够的空间
cin 和cout将输入输出看做char流。不用来处理wchar_t的类型。iostream头文件新版提供wcin和wcout来处理wchar_t流。
wchar_t bob=L'P' 使用L前缀只是宽字符常量和宽字符串
wcout<<L"tall"<<endl; 输出一个宽字符串
新增类型 unicode不够用时出现了
char16_t 和char32_t 均为无符号
u前缀表示char16_t字符常量和字符串常量
u'C'和u"be good"
U前缀表示char32_t常量 如U'R'和U"dirty rat"
例如 char16_t ch1=u'g';
char32_t ch2=U'\U0000222B';
与wchar_t一样 上面的两个也都有底层的类型 一种内置的整型 随系统变化
bool类型
逻辑赋值语句 int a=true 1 字面值提升转换为int类型
b=false 0
bool a=-100 true 非0值转换为true 0为false
bool b=0 false
二 const 限定符
使用const替代#define
const int months=12;
用以区分常量和变量。可以将名称的首字母大写;另一种方式是将整个名称大写,使用#define创建常量时通常使用此约定 ;第三种是以字母k开头 例如kmonths
通用格式
const type name = value;
如果声明常量时没有提供值,则该常量的值讲是不确定的,且无法修改
const比define要好 所以在c++中要用const 而不用#define
能明确指定类型
使用c++的作用域规则将定义限制在特定的函数或文件中(作用于规则描述了名称在各种模块中的可知成都)
可以将congst用于更复杂的类型
三 浮点数
c++的第二组基本类型 带小数的数字 两部分存储 一部分表示值,另一部分用于对值进行放大或者缩小。
例如数字34.1245 和34124.5 除了小数点的位置不同外 其他都相同 第一个数表示为0.341245基准值和100 缩放因子
而第2个数表示为0.341245基准值和10000 (缩放因子更大)
缩放因子的作用是移动小数点的位置,术语浮点因此而得名。
c++内部表示浮点数的额方法与此相同。但是基于二进制 所以缩放因子是2的幂 而不是10的幂
重要的是浮点数能够表示小数值、非常大和非常小的值,它们内部表示方法与整数有天壤之别。
1.书写浮点数
常规写法 12.34
浮点数写法 e表示法
3.45E6 表示3.45与1000000相乘
E6指的是10的6次方 即1后面6个0
3.45E6表示的是3450000 6被称为指数 3.45被称为尾数
2.52e+8 7e5 8.33-4
e 数字以浮点存储 没有小数点 既可以使用E也可以使用e 指数可以是正数也可以是负数。 然而数字中不能有空格
负数是除以10的乘方,而不是乘以10的乘方。

2.浮点类型
float double和long double
按照有效数位和允许的指数最小范围来描述
有效位 是数字中有意义的位。 山脉高度实际14179 但是携程14000 所以有效为2位 其余三位仅仅是占位符
也可以写成14.162千英尺 同样有5个有效位
c++对有效位的要求:float为32位 double至少48位 且不少于flat,long double至少和double一样多。
通常f 32位 double 64位 ldouble 80、96或者128位。
这三种类型的指数范围至少是-37到37.可以从头文件cfloat或float.h中找到系统的限制。

源代码如下
#include <iostream>
int main()
{
using namespace std;
cout.setf(ios_base::fixed,ios_base::floatfield); cout.setf()调用迫使输出使用定点表示法,一遍更好地了解精度, 防止程序切换到e表示法 并使程序显示小数点后6位
括号中的参数通过包含iostream来提供的常量
float tub=10.0/3.0; 实际数值应该是3.33333333333..... 但是仅显示6位小数
double mint=10.0/3.0;
const float million=1.0e6;
cout<<"tub="<<tub<<endl;
cout<<"a million tubs="<<million*tub<<" ";
cout<<"\nand ten million tubs=";
cout<<10*million*tub<<endl;
cout<<"mint="<<mint<<" "<<"and a million mints=";
cout<<million*mint<<endl;
return 0;
}
程序说明
1.cout会删除结尾的0 所以讲333.250000显示为333.25 但是cout.setf()会显示所有的数值。
float 6位 double 15位 精度不同 10.0/3.0的结果为3.333333.... 本身没有问题,如果乘以百万就会出现误差,tub在7位有效位上是精确的,在第7个3之后就与正确的值有了误差。
double类型的变量显示了13个3,因此它至少有13位是精确的。系统确保有效位为15位
cout所属的ostream类有一个类成员函数,能够精确地控制输出的格式----字段宽度 小数位数 采用小数格式还是e格式等等
tips:源文件开头的包含编译指令 常用,且最好的方式就是打开被包含的文件 进行阅读 这些文本文件
2.浮点常量
程序使用默认的浮点类型为double,如果想常量为float类型 请使用F或者f后缀 ;l或L后缀 定义long double类型
例如:1.24f 2.45F 2.2L 注意编译器的支持 如果不支持 请去掉后缀
3.浮点数的优缺点
程序示例
#include <iostream>
int main()
{
using namespace std;
float a=2.34E+22f;
float b=a+1.0f;
cout<<"a="<<a<<endl;
cout<<"b-a="<<b-a<<endl;
return 0;
}
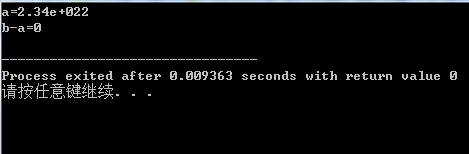
2.34E+22是一个小数点左边有23位的数字。加上1,就是第23位加1 float类型仅能表示数字中的前6位或7位 ,所以修改第23位的值对这个值不会有任何影响。
#include <iostream>
int main()
{
using namespace std;
double a=2.35E+10; 类型改为double 22改为10
double b=a+1.0;
cout<<"a="<<a<<endl;
cout<<"b="<<b<<endl;
cout<<"b-a="<<b-a<<endl;
return 0;
}
程序运行的结果就是b-a=1 则说明double类型能够表示足够的位数大于11位
tips:类型的分类
对基本类型的分类: 分为若干个族
singed char short int long统称为符号整形;他们的无符号版本统称为无符号整形;
c++11新增 long long
bool char wchar_t 符号整数和无符号整数统称为整型;
c++11新增char16_t 和char32_t
float double long double统称为浮点型。
整数和浮点型统称算数 arithmetic 类型
三 c++算术运算符
+ - * / %
加 减 乘 除 取模(余数)
1.运算符优先级和结合性
先看优先级 如果优先级相同且无括号 则看操作数的结合性是从左到右还是从右到左。
注意优先级和结合性规则仅当两个运算符用于同一个操作数时,才有效
所以 int a=20*5+21*3 中是先算20*5 还是先算21*3呢?能否根据结合性 表明先左侧的乘法 再右侧的乘法呢? 答案是都不可以
两个*运算符并没有用于同一个操作数,所以上面的结合性并不适用,根据事先来解决 让c++lai决定在系统中的最佳顺序
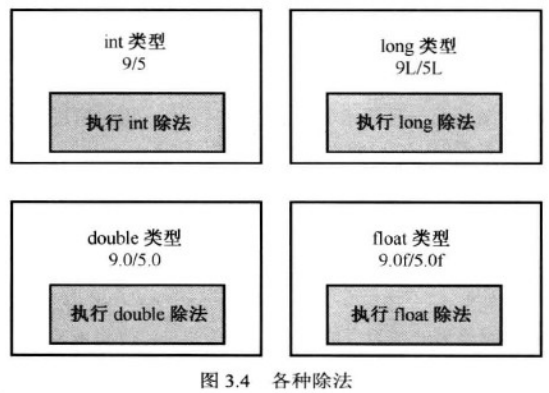
2.除法分支
/取决于操作数的类型。如果操作数都是整数 则进行整数的除法,小数部分被丢弃;如果两个都是浮点数,则小数部分被保留
示例源代码
#include <iostream>
int main()
{
using namespace std;
cout.setf(ios_base::fixed,ios_base::floatfield);
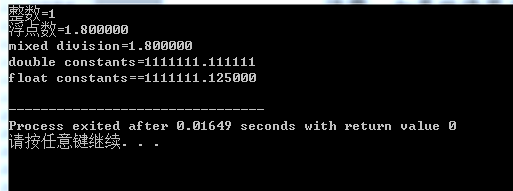
cout<<"整数="<<9/5<<endl; 整数 去掉小数点
cout<<"浮点数="<<9.0/5.0<<endl; 浮点数 f 保留小数点后6位
cout<<"mixed division="<<9.0/5<<endl; 当两数不同类型时, c++自动转换为同一类型,在这里转换为浮点类型 再计算
cout<<"double constants="<<1.e7/9.0<<endl; 浮点常量在默认下为double类型 有效位13 如果都为double类型 则结果为double类型;float同样为float类型
cout<<"float constants=="<<1.e7f/9.0f<<endl; 在此为浮点类型 结果显示出 后两行不同的精度对结果的影响 有效位8 小数点后都是6位
return 0;
}
tips:如果编译器不识别setf()中的ios_base 请使用ios
如果编译器不支持浮点常量的后缀f,则可以使用(float)1.e7/(float)9.0 代替 1.e7f/9.0f ; 有些事先会删除结尾的0
运算符重载简介
上例中表示3种不同的运算:int 除法 float double
c++根据上下文(操作数类型) 来确定运算符的含义。使用相同的符号进行多种操作叫做运算符重载(operator overloading)。
c++有一些内置的重载示例。c++还允许扩展运算符重载 由用户来定义类,这是oop的重要属性
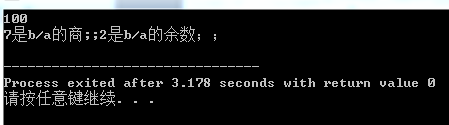
3.求模运算符
返回整数除法的余数 尤其适用于解决要求将一个量分成不同的整数单元的问题:例如将英寸转换为英尺或英寸
#include <iostream>
int main()
{
using namespace std;
const int a=14;
int b;
cin>>b;
int c=b/a;
int d=b%a;
cout<<c<<"是b/a的商;;"<<d<<"是b/a的余数;;"<<endl;
return 0;
}
4.类型转换
11种整型和3种浮点类型 很多时候需要转换
c++自动执行很多类型转换:
将一种算术类型的值赋给另一种算术类型的变量时,c++对值进行转换
表达式中包含不同的类型时,转换
参数传递给函数时,转换
1.初始化和赋值进行的转换
将一种类型的值赋给另一种类型的变量,此时值将被转换为接收变量的类型
假设 so_long 的类型为long,thirty的类型为short
so_long=thirty; 将short的值赋给long
赋值时,将thirty的值 16位 扩展为long型的值 为32位
上例为将小值赋值给大类型仅仅是空间增大而已,数值不变
如果将大类型赋值给小类型 会造成麻烦
0赋值给bool变量时,将被转换为false;而非0值将被转换为true
#include <iostream>
int main()
{
using namespace std;
cout.setf(ios_base::fixed,ios_base::floatfield);
float tree=3;
int guess(3.9832);
int debt=7.2e12;
cout<<"tree="<<tree<<endl;
cout<<"guess="<<guess<<endl;
cout<<"debt="<<debt<<endl;
return 0;
}
2.以{ }方式初始化时进行的转换 c++11
c++11将使用大括号的初始化称为列表初始化 list-initialization; 常用于给复杂的数据类型提供值列表。对类型转换的要求更加严格
列表初始化不允许缩窄 narrowing,即变量的类型可能无法表示赋给它的值。例如不允许将浮点型转换为整型
编译器知道目标变量能够正确地存储赋给它的值。long可以初始化为int值,因为long总是至少与int一样长;相反方向的转换也可能被允许,只要int变量能够存储赋给它的long常量。
例如 char c1 {31325} 缩窄 不允许
char c2 {66} 允许
char c3 ={x} 不允许 x不是一个常量
3.表达式中的转换
出现时就自动转换和与其他类型同时出现在表达式中时被转换。
1.计算表达式时,bool char unsigned char、signed char、short值被转换为int ture被转化为1 flase转为0 ;这些转换被称为整型提升 integral promotion
例如:short a=10,b=20;
short c=a+b;
此时,计算a+b时,c++取得10和20并将它们转换为int类型。然后程序将计算的int型的结果再转换为short类型
通常默认将int类型作为计算机的最自然的类型 因为此类型最快
还有其他的提升:如果short比int短,则unsigned short类型被转换为int;如果两种类型的长度相同,则unsigned short被转为unsigned int类型,此种规则确保提升时不会损失数据。
同样wchar_t被提升为第一个宽度足够存储whcar_t取值范围的类型:int unsigned int long unsigned long类型
总之 提升的过程为由小到大的过程
a 如果一个是long double 则另一个操作数转为long double
b 否则如果一个是double 则另一个被转换为double
c 否则如果一个是float 则另一个转换为float
d 否则 说明操作数都是整型,因此执行整型的提升
e 如果两个数都是有符号或无符号的 且一个比另一个的级别低,则转为高等级的类型
f 否则无符号级别比有符号的级别高,就转换为无符号
g 否则如果有符号能表示无符号的所有可能取值,则将无符号转为有符号的值
h 否则将两个操作数都转为有符号类型的无符号类型的版本
总结:有符号整数级别由高到低依次为long long 、long、int、short、signed char.
无符号整型的排列顺序与有符号整型相同
char、signed char、unsigned char的级别相同
· 类型bool的级别最低
wchar_t char16_t char32_t 的级别与其底层类型相同。
4.传递参数
传递参数的类型转换通常为c++函数原型控制,也可以取消原型对参数传递的控制;
此时会对char和short类型包括有无符号应用整型提升
在将参数传递给取消原型对参数传递控制的函数时,c++将float参数提升为double
5.强制类型转换
通过强制类型转换机制显式地进行类型转换
两种:
a (typename) value 来自于c语言
b typename (value) c++独有的格式的想法是,要让强制类型转换就像是函数调用。这样对内置类型的强制类型转换就像是为用户定义的类设计的类型转换。
强制类型转换不会修改变量本身,而是创建一个新的、指定类型的值,可以在表达式中使用这个值
例如:
int a;
(long) a;
long(a);
强制类型转换运算符 有4个 15章介绍
6.c++11中的auto声明
编译器能够根据初始值的类型推断变量的类型。 重新定义了auto的含义
处理复杂类型,如标准模块库 STL中的类型时,自动类型推断的有时才能显现出来。
第四章 复合类型
此章包括数组 字符串 string类 结构 共用体 枚举 指针和自由存储空间 指针、数组和指针算术 类型组合几个部分
一数组
数组声明注意
每个元素的的值得类型
数组名
数组中的元素个数
例如 short months[12]
typename arrayName[arraySize]
作为复合类型的数组:因为它是使用其它类型来创建的。
最后一个元素的索引比数组长度小1.编译器不会检查使用的下标是否有效。所以应确保程序使用有效的下标值。
1.数组的初始化规则
只有在定义数组时才能使用初始化,也不能将一个数组赋值给另一个数组
可以使用下标分别给数组中的元素赋值
将一个数组初始化为0 long a[10]={0}; 将第一个元素设为0
[]内为空 则编译器将计算元素个数 例如 short a[]={1,2,3,4}; 此数组包含4个元素
2.c++数组初始化方法
使用大括号的初始化 列表初始化 作为一种通用初始化方式,可用于所有类型。
int a[4] {1,2,3,4};
清0的操作:int a[4]{};或者int a[4]={}
列表初始化进制缩窄转换
long a[]={1,2,3.0} 不允许 3.0为浮点型 不允许去掉小数点、 将浮点数转换为整型是缩窄
char b[4] {'h','i',1122011,'\0'} 不允许 1122011 超出值 会缩窄
char c[4] {'h','i',112,'\0'} 允许 112未超过数组元素类型的范围
c++中的标准模板库STL提供了一种数组替代品 模板类 vector 而c++新增了模板类 array。这些替代品比内置复合类型数组更复杂、更灵活
二 字符串
内存中连续字节中的一系列字符
c++处理字符串的方式有两种 第一种为c语言的风格字符串 另一种基于string类库的方法
第一种方式 连续的内存单元 意味着可以存储在char类型的数组中,以空字符串 \0结尾 ascii码为0
char a[2]={'s','t'}; 不是字符串 cout输出为st 并接着将内存中随后的各个字节解释为要打印的字符,直到遇到空字符为止。实际上空字符为0在内存中很常见所以会很快停止。
char a[3]={'s','t','\0'}; 是字符串 因为以\0结尾 cout输出也为st 但是看到\0停止
此种方式需要单引号太多
第二种方式为 使用引号将字符串括起即可,这种字符串被称为字符串常量string constrant 或字符串字面值 string literal
char bird[11]="mr.cheeps";
char fish[]="bubbles"; 此种方式的双引号已经隐式地包括结尾的空字符,因此不用显示的包括'\0'.
输入时,使用键盘输入,将字符读入char数组时,会自动加上结尾的空字符。
注意字符串常量 使用双引号和字符常量 使用单引号 不可以互换。字符常量如's'是字符串编码的简写表示 代表83
但是“s”不是字符常量 它表示两个字符 s和\0 但是实际上"s"表示的是字符串所在的内存地址。
char shirt_size="s"; 这是非法的语句 试图将一个内存地址赋给shirt_size
char shirt_size='s' 这是合法的语句 字符常量赋值给字符变量
1.拼接字符串常量
有时,字符串很长,无法放在一行中。c++允许拼接字符串字面值,即将两个用引号扩起的字符串合并为一个。任何两个由空白(空格、制表符、换行符)分隔的字符串常量都将自动拼接成一个。
2.数组中使用字符串
将字符串存储到数组中 两种方法:将数组初始化为字符串常量,将键盘或文件输入读入到数组中 。使用cin将一个输入字符串放到另一个数组中
#include <iostream>
#include <cstring>
int main()
{
using namespace std;
const int Size=15;
char name1[Size];
char name2[Size]="C++owboy";
cout<<"Howdy! I'm "<<name2;
cout<<"! What's your name?\n";
cin>>name1;
cout<<" Well. "<<name1<<" your name has ";
cout<<strlen(name1)<<" letters and is stored\n";
cout<<" in an array of "<<sizeof(name1)<<" bytes.\n";
cout<<" your initial is "<<name1[0]<<".\n";
name2[3]='\0'; 将name2[3]中的内容设置为结尾符 则输出时到此结束
cout<<" here are the first 3 characters of my name: ";
cout<<name2<<endl;
return 0;
}
程序说明:

程序说明:
sizeof 运算符指出整个数组的长度 15字节
strlen()函数返回的是存储在数组中的字符串的长度,而不是数组本身的长度。只计算可见的字符,而不把空字符计算在内。
例如字符串为 cosmic 则要存储该字符串,数组的长度不能短于strlen(cosmic)+1; 数组中需要加入'\0' 结尾符号
符号常量指定数组的长度。
3.字符串输入
#include <iostream>
int main()
{
using namespace std;
const int ArSize=20;
char name[ArSize];
char dessert[ArSize];
cout<<"Enter your name:\n";
cin>>name;
cout<<"Enter your favorite dessert:\n";
cin>>dessert;
cout<<"I have some delicious "<<dessert;
cout<<" for you,"<<name<<".\n";
return 0;
}
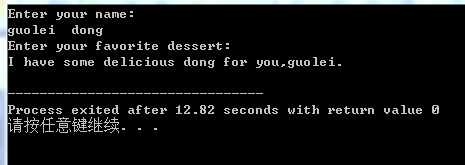
这里可以看到 第一个输入完成后 第二个输入并没有输入的情况下就已经打印输出了
所以这里提示 cin的处理机制:cin使用空白(空格、制表符和换行符)来确定字符串的结束位置,意味着cin在获取字符数组输入时只读取一个单词。读取该单词后,cin将该字符串放到数组中,并自动在结尾添加空字符。
这个例子的实际结果是 cin把guolei 作为第一个字符串,并将它放到name数组中。并把dong留在了输入的队列中。当cin在输入队列中搜索用户喜欢的甜点时,发现了输入队列中的dong字符串 因此读取dong 并将它放到dessert数组中。
另一个问题是 输入字符串可能比目标数组长,不能防止30个字符的字符串放到20个字符的数组中的情况发生
在第17章介绍cin的高级特性
4.每次读取一行字符串输入
需要采用面向行而不是面向单词的方法。 istrem中类cin提供了一些面向行的类成员函数 :getline()和get() 这两个函数都读取一行输入,直到到达换行符。
getline()将丢弃换行符,而get()将换行符保留在输入序列中。
a 面向行的输入getline()
读取整行 通过回车键输入的换行符来确定输入结尾。
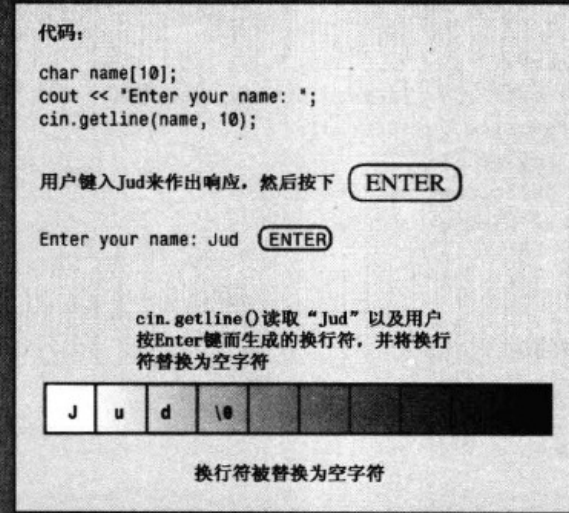
调用方法:cin.getline() 两个参数 第一个参数用来存储输入行的数组的名称,第二个参数是要读取的字符数。如果字符数为20,则函数最多读19个字符,余下的空间用于存储结尾添加的空字符。
getline()成员函数在读取指定数目的字符或遇到换行符时停止读取
例如 将姓名读入到包含20个元素的name数组中,可以使用这样的函数
cin.getline(name,20);
这会将一行读入到name数组中,如果这行包含的字符不超过19个。getline()成员函数还可以接受第三个可选参数。
#include <iostream>
int main()
{
using namespace std;
const int ArSize=20;
char name[ArSize];
char dessert[ArSize];
cout<<"Enter your name:\n";
cin.getline(name,ArSize);
cout<<"Enter your favorite dessert:\n";
cin.getline(dessert,ArSize);
cout<<"I have some delicious "<<dessert;
cout<<" for you,"<<name<<".\n";
return 0;
}
程序显示如下:
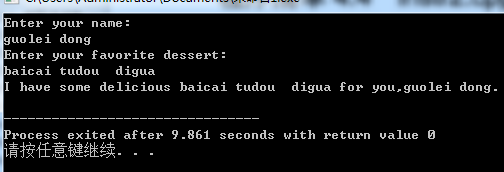
getline()函数每次读取一行,通过换行符来确定行尾,但是不保存换行符;相反,在存储字符串时,用空字符来替换换行符
b.面向行的输入
istream类有另一个get()成员函数 该函数有几种变体。其中一种变体的工作方式与getline()类似,接收的参数 解释参数 都读到行尾 均相同
不同点是它不再读取并丢弃换行符 而是将其留在输入队列中
例如
cin.get(name,size); 没问题
cin.get(name2,size); 有问题 数组中为空
原因是当第一次调用后,换行符会留在输入队列中,所以第二次调用时看到的第一个字符便是换行符。因此get()认为已经到达行尾,而没有发现任何可以读取的内容。
所以name2中的内容为空。
get()的另一种变体,使用不带任何参数的cin.get()调用可读取下一个字符 (即使是换行符),所以可以用来处理换行符,为读取下一行输入做准备。
上面的例子可以改为
cin.get(name,size); 没问题 读入第一行
cin.get(); 跳过换行符
cin.get(name2,size); 没问题 读入第二行
另一种使用get()的方式是将两个类成员函数拼接起来(合并),如下所示:
cin.get(name,ArSize).get()
cin.get(name,ArSize)会返回一个cin对象,该对象随后将被用来调用get()函数。
所以可以使用下面的输入中连续的两行分别读入到数组name1和name2中,其效果与两次调用cin.getline()相同
cin.getline(name1,ArSize).getline(name2,ArSize); 读入连续的两行。
案例:
#include <iostream>
int main()
{
using namespace std;
const int ArSize=30;
char name[ArSize];
char dessert[ArSize];
cout<<"Enter your name:\n";
cin.get(name,ArSize).get();
cout<<"Enter your favorite dessert:\n";
cin.get(dessert,ArSize).get();
cout<<"I have some delicious "<<dessert;
cout<<" for you,"<<name<<".\n";
return 0;
}
c++中允许函数有多个版本,这些版本的参数列表不同是多版本的条件。
例如cin.get(name,size) 编译器就知道是要读取一个字符串放入数组
cin.get() 编译器就知道要读取一个字符 这就是不同之处
get和getline的工作方式
老式的实现没有getline()
get()的方式更加的仔细,假设用get()将一行读入数组中,查看下一个输入字符,如果是换行符,则说明读取了整行,否则说明该行还有其他输入。
c.空行和其他的问题
当遇到空行时的读取方式:
下一条输入语句将在前一条getline()或get()结束读取的位置开始读取;但是当前的做法是 当get()读取空行后将设置失效位(failbit)。意味着接下来的输入将被阻断,但是可以用下面的命令来恢复输入:cin.clear();
另一个问题是,输入字符串可能比分配的空间长。如果输入行包含的字符数比指定的多,则getline()和get()将把余下的字符留在输入队列中,而getline()还会设置失效位,并关闭后面的输入。
5.混合输入字符串和数字
混合输入数字和面向行的字符串会导致问题。
#include <iostream>
int main()
{
using namespace std;
cout<<"what year was your house built?\n";
int year;
cin>>year;
cout<<"what is its street address?\n";
char address[80];
cin.getline(address,80);
cout<<"year built:"<<year<<endl;
cout<<"address:"<<address<<endl;
cout<<"Done!\n";
return 0;
}
上例中的运行结果
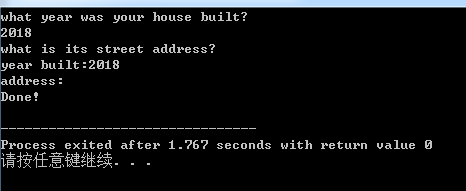
输入年后,回车,用户没有输入的机会,程序就输出了:原因就是当cin读取年份后,将回车键生成的换行符留在了输入队列中,后面的cin.getline()看到了换行符后,将认为是一个空行,并将一个空字符串赋给了address数组
解决的办法就是在cin>>year;的后面接上一个cin.get();或者cin.get(ch);语句跳过换行符或者使用连接的方式(cin>>year).get()的拼接方式。(cin>>year).get(ch);
三.string类介绍
c++98标准通过string类来扩展c++库,因此现在可以string类型的变量而不是字符数组来存储字符串。string类提供了将字符串作为一种数据类型的表示方法
头文件string 并且string类要位于名称空间std中。且string类隐藏了字符串的数组的性质。
实例:
#include <iostream>
#include <string>
int main()
{
using namespace std;
char c1[20];
char c2[20]="dongugolei";
string s1;
string s2="123456";
cout<<"enter a kind of feline:";
cin>>c1;
cout<<"enter another kind of feline:";
cin>>s1;
cout<<"here are some felines:\n";
cout<<c1<<" "<<c2<<" "<<s1<<" "<<s2<<endl;
cout<<"the third letter in "<<c2<<" is "<<c2[2]<<endl;
cout<<"the third letter in "<<s2<<" is "<<s2[2]<<endl; 注意这里要用数组的下标形式
return 0;
}
在很多方面,使用string对象的方式与使用字符数组相同
可使用c风格字符串来初始化string对象
使用cin来将键盘输入存储到string对象中
使用cout来显示string对象
使用数组表示法来访问存储在string对象中的字符
string和数组之间的主要区别是,可以将string对象声明为简单变量,而不是数组:
string s1; 创建一个空的字符串对象
string s2=“panther”; 创建一个已经初始化的字符串对象
假设定义对象时,string类的对象的长度为0,但是当cin对此对象进行输入时,可以根据输入的字符串大小来自动调整此对象的长度。
可以将char数组视为一组用于存储一个字符串的char存储的安远,而string类变量是一个表示字符串的实体。
1.c++11字符串初始化
允许列表初始化用于c风格字符串和string对象
char first_data[]={"dong guo lei"}; 数组初始化
char second_data[]={"dong guo lei"};
string third_data={"dong guo lei"}; 类对象的初始化
string fourth_data {"dong guo lei"};
2.赋值、拼接和附加
不能将一个数组赋给另一个数组,但可以将一个string对象赋给另一个string对象:
char c1[20];
char c2[20]="dongguolei";
string s1;
string s2="fuck";
c1=c2; 无效,数组不能赋给数组
s1=s2; 有效,对象可以赋给对象
string类简化了字符串的合并操作。可以使用运算符+将两个string对象合并起来,还可以使用运算符+=将字符串附加到string对象的末尾。
string s3;
s3=s1+s2; 对象的连接
s1+=s2; 对象的附加
s1+="asdfljljlk" 字符串追加到字符串对象的末尾
源代码
#include <iostream>
#include <string>
int main()
{
using namespace std;
string s1="dongugolei";
string s2,s3;
cout<<"you can assign one string object to another: s2 = s1 \n";
s2=s1; //字符串对象赋值
cout<<"s1:"<<s1<<" ,s2: "<<s2<<endl;
cout<<"you can assign C-style string to a string object.\n";
cout<<"s2=\"buzzard\"\n";
s2="buzzard";
cout<<"s2: "<<s2<<endl;
cout<<"you can concatenate strings: s3 = s1 + s2 \n";
s3=s1+s2; //字符串对象连接
cout<<"s3: "<<s3<<endl;
cout<<"you can append strings.\n";
s1+=s2; //字符串对象的附加
cout<<"s1 += s2 yields s1= "<<s1<<endl;
s2 +=" for a day "; //字符串追加到字符串对象
cout<<"s2+=\" for day\" yields s2 = "<<s2<<endl;
return 0;
}
3.string类的其他操作
添加string类之前,需要完成的给字符串赋值,使用string.h头文件 cstring 提供了这些函数
strcpy()来将字符串赋值到字符数组中,使用函数strcat()将字符串附加到字符数组末尾。
源代码:
#include <iostream>
#include <string>
#include <cstring>
int main()
{
using namespace std;
char c1[20];
char c2[20]="goudan"; //定义数组 并赋值
string s1;
string s2="lvfenqiu"; //定义字符串对象,并赋值
s1=s2; //字符串对象赋值
strcpy(c1,c2); // 字符数组的赋值需要用strcpy函数
s1+=" is lvfenqiu "; // += 运算符来连接字符串对象
strcat(c1," is goudan "); // 字符数组的连接用函数strcat函数
int len1=s1.size(); //字符串对象的成员函数 获取长度
int len2=strlen(c1); //获取字符数组的长度函数strlen
cout<<" the string "<<s1<<" contains "<<len1<<" characters. \n";
cout<<" the string "<<c1<<" contains "<<len2<<" characters. \n";
return 0;
}

函数strcat()试图将全部12个字符赋值到数组site中,将覆盖相邻的内存。 程序被破坏。
但是string类具有自动调整大小的功能,能够避免这种问题的发生。c函数库确实提供了与strcat()和strcpy()类似的函数----strncat()和strncpy() 它们接受指出目标数组最大允许长度的第三个参数
strlen()是常规的函数 接受一个c风格字符串作为参数,并返回该字符串包含的字符数。函数size()的功能基本相同
s1不是函数参数 s1.size()为一个对象的成员函数
4.string类 I/O 输入输出
cin和运算符>>来将输入存储到string对象中,使用cout和运算符<<来显示string对象。处理与c风格字符串相同,但是每次读取一行,而不是一个单词。
#include <iostream>
#include <string>
#include <cstring>
int main()
{
using namespace std;
char c1[20];
string str;
cout<<" length of string in charr before input: "<<strlen(c1)<<endl; //输出的值不一定 因为数组内容未定义 从数组第一个单元开始计算字节数,知道遇到空字符
cout<<" length of string in str before input: "<<str.size()<<endl; //长度为0 因为未被初始化的string对象的长度被自动设置为0
cout<<" enter a line of text: \n";
cin.getline(c1,20);//getline 获取一行的输入 指出一个最大的长度 在这里 getline()前面有句点 说明是一个类方法
cout<<" you entered: "<<c1<<endl;
cout<<" enter another line of text: \n";
getline(cin,str); // 前面没有句点运算符 说明这不是一个类方法
cout<<" you entered: "<<str<<endl;
cout<<" Length of string in c1 after input: "<<strlen(c1)<<endl;
cout<<" length of string in str after input: "<<str.size()<<endl;
return 0;
}
getline()是istream的类方法,在引入string类之前很久,c++就有istream类。因此istream的设计考虑到了诸如double int等基本的c++数据类型,但是没有考虑string的类型。所以istream类中有处理double和int等基本类型的类方法,没有string类的对象的类方法
但可以使用下面的代码:cin>>str; 读取一个词到一个string类的对象中使用了istream类的一个成员函数 友元函数
5.其他形式的字符串字面值
除了char外还有wchar_t的类型,新增类型为char16_t char32_t。可以创建这些类型的数组和这些类型的字符串字面值。
分别用L u 和U表示
例如:wchar_t title[]=L"Chief Astrogator"; //w_char string 类型
char16_t name[]=u"Felonia Ripova";//char_16 string类型
c++11也支持unicode字符编码方案UTF-8 根据编码的数字值,可能存储为1-4个八位组 使用前缀u8来表示此种类型的字符串字面值
c++11新增另一种类型时原始raw字符串。 在原始字符串中,字符表示的就是自己。例如 \n不表示换行符,而表示两个常规字符斜杠和n 所以在屏幕上显示的就是斜杠和n
例如:cout<<R"(uses"\n" instead of endl)"<<'\n'
输出 uses \n instead of endl
使用标准字符串字面值 则编码如下
cout<<"uses \"\\n\" instead of endl";
使用了\\来显示\ 单个的\表示转义
注意在输入原始字符串时,回车键不会移到下一行,还将在原始字符串中添加回车字符
如果要在原始字符串中包含)" 当编译器见到第一个)"时会认为字符串到此会结束,但是原始字符串语法允许表示字符串开头的"和(之间添加其他的字符,所以在字符串结尾的"和)之间也必须包含这些字符
例如: R“+*( 标识原始字符串的开头时, 也必须使用)+*" 表示原始字符串的结尾
实例: cout<<R"+*("123456789")*+"<<endl;
输出为 "123456789" 输出括号中的内容
总之 "+*( 替代了默认的"( 定界符。 但是空格 左右括号 斜杠和控制字符(制表符和换行符)除外。
可见前缀R与其他字符串前缀结合使用,以标识wchar_t等类型的原始字符串。可将R放在前面,也可将其放在后面,如Ru UR等
四 结构
可以存储不同类型的数据 与数组(只能存储相同类型)不同
也可以有结构数组
结构是用户定义的类型 声明定义了类型的数据属性
1.定义结构描述 描述并标记了能够存储在结构中的各种数据类型。然后按描述创建结构变量 结构数据对象
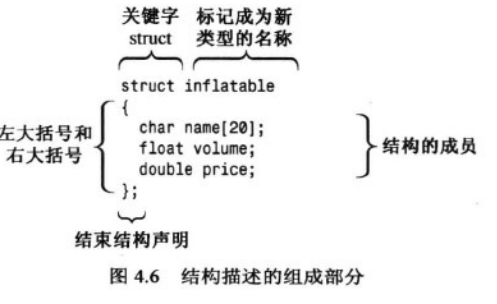
定义之后就可以 创建这种类型的变量了
inflatable hat c++中的格式 强调这是一种新类型
结构类型 变量名
struct inflatable hat c中的格式 区别 差了一个struct
使用.来访问各个成员 hat.price
访问类的成员函数 例如cin.getline()的方式是从访问结构成员变量 如hat.price 的方式衍生而来的。
1.程序中使用结构
结构声明的位置 在main函数之前或者main之内紧挨着括号
函数外部的变量由所有的函数共享 类似于全局 c++不提倡外部变量 但是提倡外部结构声明。
用逗号分隔列表,并将这些值用花括号括起。将每个结构成员看做是相应类型的变量。hat.price是一个double的变量,pal.name是一个char数组 可以初始化为一个字符串。
2.c++11结构初始化
支持结构列表初始化
inflatable duck{"daphne",0.12,9.98};
大括号内无值,则成员被设置为0 不匀许缩窄转换
3.结构可以将string类作为成员
#include <string>
struct inflatable 结构体定义
{
std::string name;
float volume;
double price;
}
编译器支持以string对象作为成员的结构进行初始化;让结构定义能够访问名称空间std,所以可以将编译指令using移到结构定义之前或std::string
4.其他结构属性
c++使用户定义的类型与内置类型尽可能相似。
a 可以将结构作为参数传递给函数
b 可以让函数返回一个结构
c 可以使用=将一个结构赋值给另一个同类型的结构,这样每个成员与另个结构中的相应成员值相同 即使成员是结构体或者数组 此为成员赋值 memberwise assignment
//assgn_st.cpp
#include <iostream>
struct inflatable
{
char name[20];
float volume;
double price;
};
int main(){
using namespace std;
inflatable bouquet={"sunflowers",0.20,12.49};
inflatable choice;
cout<<"bouquet:"<<bouquet.name<<" for $";
cout<<bouquet.price<<endl;
choice=bouquet;
cout<<"choice:"<<choice.name<<" for $";
cout<<choice.price<<endl;
return 0;
}
从中可以看出 成员赋值有效。因为choice的结构的成员值与b结构中的成员值相同
同时进行结构的定义和创建结构的变量
struct perks
{
int key_number;
char car[12]; 定义
} mr_smith,ms_jones; 两个perks类型的变量 将变量名放在结束括号的后面即可
struct perkes
{
int key_number;
char car[12];
} mr_glitz={7,"packard"} 紧跟在大括号后面并且直接赋值 初始化 但是不建议
结构体类型定义和变量的声明分开 更加利于程序的阅读
也可以如此定义
struct {
int x;int y;
} position; 定义了一个结构变量,可以使用成员运算符来访问它的成员 position.x 此方法没有类型的名称 所以在其他的地方无法创建这种类型的变量
c++11结构的特性 主要是与c结构的区别
a c++除了成员变量外,还有成员函数 通常被用于类中,而不是结构中
5.结构数组
结构中可以包含数组 也可以创建元素为结构的数组
inflatable gifts[100]; 结构类型的数组
cin>>gifts[0].volume; 访问结构数组中的元素结构中的成员
初始化
inflatable guests[2]={
{"bambi",0.5,21.99}, 初始化数组元素guests[0]
{"godzilla",2000,565.99} guests[1]
};
6.结构中的位字段
struct torgle_register{
unsigned int SN:4; 4bits for SN value
unsigned int :4; 未使用的4bit 留空
bool googIn:1; 有效的输入 占用1位
bool goodTorgle:1; 有效的torgling 占用1位
};
初始化
torgle_register tr={14,ture,false}; 其中未使用的4位并未赋值
if(tr.goodIn) //statment
通常用于低级变成中,一般用按位运算符来代替此种方式。
五共用体
一种数据格式 类似于结构体 区别只能存储int long 或者double 并且同时只能存储其中的一种格式
而结构体能以同时存储多种格式的数据类型
union a
{
int int_val;
long long_val;
double double_val;
}
使用a类型的变量来存储int 、long、double 但是要注意要在不同的时间点进行
a pail;
pail.int_val=15;
pail.double_val=1.38;
共用体每次只能存储一个值,因此它必须有足够的空间来存储最大的成员,所以,共用体的长度为其最大成员的长度。
共用体的用途之一是:当数据项使用两种或更多种格式,但是不会同时使用,可以节省空间
例如小商品的目录 有些小商品是整数 有些小商品id是字符串
struct widget{
char brand[20];
int type;
union id {
long id_num;
char id_char[20];
} id_val;
};
...
widget prize;
...
if(prize.type==1) cin>>prize.id_val.id_num;
else cin>>prize.id_val.id_char;
匿名共用体 没有名称 其成员将成为位于相同地址处的变量,显然 每次只有一个成员是当前的成员。
例如 struct widget{
...
union{
long id_num;
char id_char[20];
}; 匿名共用体
};
widget prize;
if(prize.type==1)
..
else
cin>>prize.id_num 此处使用匿名共用体中的成员
由于共用体是匿名的 所以id_num和id_char被视为prize的两个成员 他们的地址是相同的,所以不需要中间标识符id_val.
共用体常用语系统数据结构后者硬件数据结构
六 枚举
除了const 另一种创建符号常量的方式就是枚举 ,它还允许定义新类型 限制严格
enum spectrum{red,orange,yellow,green,blue,violet,indigo,ultraviolet}
完成的两个工作:
1.spectrum成为新类型的名字;spectrum被成为枚举 enumeration 就像struct变量被称为结构一样
2.将red、orange、yellow等作为符号常量 它们对应整数值0-7 这些常量叫做枚举量enumerator
默认情况下,将证书值赋给枚举量,第一个枚举量的值为0,第二个枚举量的值为1,依次类推,可以通过显示地制定整数值来覆盖默认值
用枚举名来声明这种变量 案例
enum spectrum{red,orange,yellow,green,blue,violet,indigo,ultraviolet} 枚举的声明
spectrum band; band为枚举变量
band=blue; 只能将定义枚举时使用的枚举量赋值给这种枚举的变量
band=2000; 不成立 只能将枚举的常量赋值给变量 2000不是 只能有8个可能的值
++band; 只为枚举定义了赋值运算符 没有定义算数运算符 所以此式子是无效的 (分实现 有些可能,但是为了移植性考虑 应该采用严格的限制)
band=orange+red;错误的式子
int color=blue; 枚举量是整型,可被提升为int型 有效
band=3; 整型数值不能转换为枚举类型 并赋值 无效 ;3对应green 但将3赋值给band将导致类型错误 将green赋值为band可以
color=3+red; 有效 3+red不是枚举量定义,但是red被转换为int型 因此结果的类型也是int 这种情况下是枚举类型被转换为int类型。
所以可以在算数表达式中同时使用枚举和常规整数。
band=orange+red; 非法 没有为枚举定义运算符+ 尽管orange+red被转换为1+0 表达式合法,但是其类型为int 不能将其赋值给类型为spectrum的变量band
band=spectrum(3); 类型转换 如果int值有效 通过强制转换为枚举类型 并将其赋值给枚举变量 green 对应3 有效
band=specrum(40003); 无效 整数无对应的值
1.设置枚举量的值
显式:
enum bits{one=1,two=2,four=4};
早期c++版本制定的值必须是整数,现在可以是long或long long
隐式:
enum bigstep{first,second=100,third}; first默认为0 third为101
后面的比前面大1
enum {zero,null=0,one,numero_uno=1};
zero null都为0 one比null大1 所以为1
2.枚举的取值范围
c++ 通过强制类型转换,增加了可赋值给枚举变量的合法值。每个枚举都有取值范围 range
上限和下限
上限 枚举两中的最大值,比这个最大值大的最小的2的幂 再减去1 就是上限:例如枚举中的最大值为101 则比101最大的2的幂中最小的是2的7次幂 为128,再减去1得到127 就是范围 如果枚举量中没有负数,则最小值就是0 则范围为0-127
下限上限一样,最后再加上负号 例如最小的枚举量为-6则 比-6小的最小的幂中最大的就是-8 再用8-1=7 最后再加上负号 -7就是取值范围
选择存储枚举类型的空间大小由编译器来决定 对于取值范围较小的枚举,使用一个字节或更少的空间;而对于包含long类型值的枚举 则使用4个字节
c++扩展枚举 增加了作用域内的枚举, 第10张 类作用域将介绍
七 指针和自由存储空间
指针存储数据所在内存单元的地址,获取变量的地址使用地址运算符 & :例如 home是一个变量,则&home是它的地址。
使用常规变量时,值是指定的量,地址为派生量
指针与c++基本原理
面向对象编程在于 oop强调的是在程序的运行阶段(程序正在运行时) 而不是编译阶段(编译器将程序组合起来时) 进行决策,
运行阶段决策提供了灵活性,根据当时的情况进行调整,例如为数组分配内存的情况,需要制定数组的长度,因此数组长度在程序编译时就设定好了;这就是编译阶段决策。所以程序在大多数情况下浪费了内存,如果oop将这样的决策推迟到运行阶段进行,使得程序更加灵活,在程序运行后,可以告诉它只需要20个元素,而下次告诉它需要205个元素
所以语言必须允许在程序运行时创建数组,所以c++使用的方法是使用关键字new请求正确数量的内存以及使用指针来跟踪新分配的内存的位置。
处理存储数据的策略相反,将地址视为指定的量,而将值视为派生量。
特殊类型的变量--指针用于存储值得地址,所以指针名表示的是地址 , *运算符被称为间接值indirect velue或者解除引用dereferencing运算符
*指针变量 可以得到该地址处存储的值 (c++根据上下文来确定所指的是乘法还是解除引用)
例如:
int updates=6;
int * p_updates; 指针变量的声明
p_updates=&updates 指针变量的赋值
*p_updates=*p_updates+1; 指向的内存单元的值 加上1
1.声明和初始化指针
计算机需要跟踪指针指向的值得类型。
指针变量本身也需要存储空间, win7 64位 编译器为 gcc 64位4.9.2 sizeof(int *) 和其他的sizeof(double *)都一样 是占用8个字节的空间
注意
c程序员使用格式 int *ptr 用来强调这是一个int类型
c++ 通常用int* ptr 用来强调这是一个指向int的指针
添加空格不影响他们的区别
int * p1,p2 ; 其中p1为指针 p2为int型变量 对每个指针变量都需要使用一个*
可以在声明语句中初始化指针 被初始化的是指针而不是它指向的值
例如 int a=5; int * ptr=&a; ptr存储的是a变量的地址
2.指针的危险
创建指针时,计算机将分配用来存储地址的内存,但是不会分配用来存储指针所指向的数据的内存。为数据提供空间是一个独立的步骤。
int * a; *a=222;
上面中的代码表示a为指针 并且将指针指向的位置存储数值为222;但是不知道存储到哪里
所以一定要咋对指针应用解除引用运算符*之前,将指针初始化为一个确定的适当的地址。
3.指针和数字
计算机通常将地址当做整数处理 但是指针不同于整数
int * ptr;
ptr=0xb8000000; 会提示类型不匹配
如果想通过直接赋值来定义指针变量的值 则需要类型强制转换 如下
ptr=(int *) 0xb8000000; 成功匹配
4.使用new来分配内存
变量是在编译时分配的有名称的内存,而指针只是为可以通过名称直接访问的内存提供了一个别名,真正的用处是,在运行阶段分配未命名的内存以存储值。此时只能通过指针来访问。
c语言用库函数malloc()来分配内存;在c++中仍然可以这样做 但是c++通常用new运算符来创建内存。
int * p1=new int;
语句中 程序员告诉new 需要为int类型分配内存 ,所以new就会找一个长度正确的内存块。 并返回该内存块的地址。
程序员需要将此地址赋给一个指针变量
int b;
int *p2=&b;
两个比较p1和p2都是指针 都指向内存单元 但是 p1指向的内存单元只能通过指针访问,而p2指向的内存单元可以用b来访问
p1指向的内存单元没有名称 我们就说它指向一个数据对象,术语数据对象比变量更通用,它指的是为数据项分配的内存块。因此变量也是数据对象,但是p1指向的内存不是变量。处理数据对象的指针使得在管理内存方面有更大的控制权。
为一个数据对象 可以使结构或其他的基本类型 获得并指定分配内存的通用格式如下:
typename * pointer_name =new typename;
#include <iostream>
int main(){
using namespace std;
cout.setf(ios_base::fixed,ios_base::floatfield);//cout显示时 按原样输出 而不是用e表示的浮点值
int nights=1001;
int * pt=new int;
*pt=1001; //指向的内存单元的值
cout<<"nights value = ";
cout<<nights<<":location "<<&nights<<endl;
cout<<"int:";
cout<<"value = "<<*pt<<":location = "<<pt<<endl;
double * pd=new double;
*pd=10000001.55;
cout<<"double :";
cout<<"value = "<<*pd<<":location = "<<pd <<endl;
cout<<"location of pointer pd: "<<&pd<<endl; //address
cout<<"size of pt = "<<sizeof(pt); //占用的空间大小 指针本身
cout<<": size of *pt = "<<sizeof(*pt)<<endl; // 指针所指变量所占用的空间大小
cout<<"size of pd = "<<sizeof pd;
cout<<":size of *pd = "<<sizeof(*pd)<<endl;
return 0;
}

程序说明:
new 分别为int和double 的数据对象分配内存 在程序运行时进行的。
new分配的内存块通常与常规变量声明分配的内存块不同
变量nights和pd的值都存储在栈(stack)中
而new 从被称为堆(heap)或者自由存储区(free store)的内存区域分配内存
如果没有足够的内存 则new会引发一场
5.使用delete来释放内存
使用new 来请求内存,当使用完成后 需要用delete来释放内存 归还到内存池中。
例如 int * pt=new int;
...
delete pt;
仅仅是释放pt指向的内存,但是不会删除指针pt本身。
new 和delete一定要配对使用 否则会发生内存泄漏 memory leak
不能对已经释放的内存再释放 但是对空指针使用delete是安全的
示例2
int * ps=new int; 分配内存
int * pt=ps; 设置另一个指针指向相同的内存
delete pt; 释放第二个指针
一般情况下,不要创建两个指向同一个内存块的指针,因为这将增加错误地删除同一个内存块两次的可能性,但是对于返回指针的函数 使用另一个指针是有道理的。
6.使用new来创建动态数组
简单的数据对象无需使用new和指针
大型的数据如数组 字符串和结构 可能需要使用new
在编译时给数组分配内存被称为静态联编 static binding 以为这数组时在编译时就被加入到程序中的;但是当使用new时,则在运行阶段需要数组就创建,如果不需要数组就不创建。还可以在程序运行时选择数组的长度 这种被称为动态联编 dynamic binding 这种数组叫做动态数组
所以静态数组需要指定长度 而动态数组可以在运行时确定数组的长度
动态数组的new创建和使用指针访问数组元素
1.new创建动态数组
int * psome=new int[10]
new运算符返回第一个元素的地址,并赋值给psome
释放数组使用的内存使用delete [ ] psome;
总之使用new和delete时应遵循以下规则:
a 不要使用delete来释放不是new分配的内存
b 不要使用delete来释放同一个内存块两次
c 如果new [] 为数组分配内存 则应使用delete [] 来释放
d 如果使用new[]为一个实体分配内存 则使用delete 没有方括号来释放
e 对空指针应使用delete是安全的
psome是指向一个int 的指针 编译器不能对psome是指向数组中的第一个这种情况进行跟踪,所以编写程序时,必须让程序跟踪元素的数目
实际上,程序确实跟踪了分配的内存量,以便以后使用delete[]运算符能正确地释放这些内存,但是信息不公开,例如不能用sizeof运算符来确定动态分配的数组所包含的字节数
通用格式
type_name * pointer_name =new type_name [num_elements];
2.使用动态数组
指针变量当做数组名
psome[0] 代表第一个元素
psome[1] 代表第二个元素
实例4.18
#include <iostream>
int main(){
using namespace std;
double * p3=new double[3];
p3[0]=0.2;
p3[1]=0.5;
p3[2]=0.8;
cout<<"p3[1] is "<<p3[1]<<endl;
p3=p3+1; //指针位置变动为指向数组中的第二个元素
cout<<" Now p3[0] is "<<p3[0]<<"and";
cout<<" p3[1] is "<<p3[1]<<".\n";
p3=p3-1; //将指针位置切换回指向第一个元素 即数组首元素
delete [] p3; //释放数组
return 0;
}
八 指针、数组和指针算术
指针和数组基本等价的原因在于指针算术和c++内部处理数组的方式。
c++数组名解释为地址
示例
#include <iostream>
int main(){
using namespace std;
double wages[3]={10000.0,20000.0,30000.0};
short stacks[3]={3,2,1};
double * pw=wages; // 数组名为地址 赋值给指针
short * ps=&stacks[0]; //&运算符 获取数组地址 并赋值给指针变量
cout<<"pw= "<<pw<<",* pw= "<<* pw<<endl;
pw=pw+1;
cout<<"add 1 to the pw pointer:\n";
cout<<"pw= "<<pw<<",* pw= "<<* pw<<endl<<endl;//指针加1后的输出结果 double类型 每个元素占8个字节
cout<<"ps= "<<ps<<",* ps= "<<* ps<<endl;
ps=ps+1; //指针加1后的输出结果 short类型 每个元素占2个字节
cout<<"add 1 to the ps pointer:\n";
cout<<"ps= "<<ps<<",* ps= "<<* ps<<endl;
cout<<"access two elements with array notation\n";
cout<<"stacks[0]= "<<stacks[0]<<",stacks[1] = "<<stacks[1]<<endl;//short类型 数组的首和第二的元素输出 通过数组名输出
cout<<"access two elements with pointer notation\n";
cout<<"*stacks= "<<*stacks<<",*(stacks+1)= "<<*(stacks +1)<<endl;//通过指针输出 数组首元素 数组第二个元素
cout<<sizeof(wages)<<" = size of wages array\n"; //数组名返回数组大小
cout<<sizeof(pw)<<"= size of pw pointer\n"; //double类型的指针 返回的是指针本身占用的大小
return 0;
}
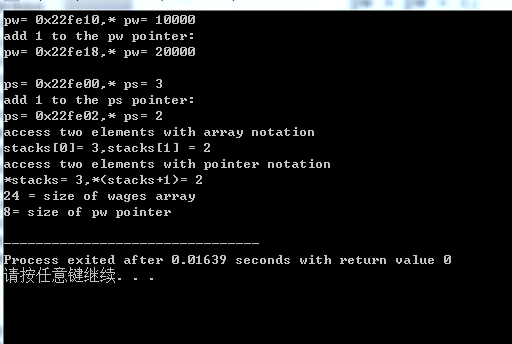
程序说明:
c++将数组名解释为第1个元素的地址,pw声明为指向double类型的指针,然后将它初始化为wages 此数组中第一个元素的地址
所以wages=&wages[0]
将指针变量加1后,其增加的值等于指向的类型占用的字节数
c++编译器将该表达式stacks[1]看作是*(stacks+1)----- 意味着先计算数组第2个元素的地址值,然后找到存储在那里的值。
所以 *(stacks+1) 与stacks[1]是等价的。
arrayname[i] becomes *(arrayname + i)
如果使用的是指针,而不是数组名,则c++也将执行同样的转换:
pointername[i] becomes *(pointername + i)
因此,在很多情况下,可以相同的方式使用指针名和数组名。
多数表达式中,都表示地址,区别是 可以修改指针的值,而数组名是常量
pointername=pointername +1; 有效
arrayname=arrayname+1; 无效 因为数组名是常量
另一个区别:sizeof 数组名 会得到数组的长度 此种情况下编译器不会将数组名解释为地址
sizeof 指针 会得到指针的长度
数组的地址:
对数组取地址时,数组名也不会被解释为其地址。而会被解释为其第一个元素的地址,而对数组名应用地址运算符时,得到的是整个数组地址:
short tell[10];
cout<<tell<<endl; 显示首元素地址
cout<<&tell<<endl; 显示全部数组的地址
&tell[0]是一个2字节内存块的地址
而&tell是一个20字节的内存块的地址 所以表达式tell+1将地址值加2,而表达式&tell+2将地址加20。也就是tell是一个short的指针 而&tell是一个指向20个元素的short数组的指针 short (*) [20]
可以这样声明指针和初始化
short (*pas)[20]=&tell; 括号必不可少。 否则优先级规则将pas 与[20] 结合。导致pas是一个short指针数组,它包含20个元素,且均为指针;另有与pas被设置为&tell,所以*pas被设置为&tell 因此*pas与tell等价 所以(*pas)[0]为tell数组的第一个元素。
总结
1.声明指针
typename * pointername;
double *pn
2.给指针赋值
double * pn;
double * pa;
char * pc;
double bubble=3.2;
pn=&bubble;
pc=new char;
pa=new double[30];
3.对指针解除引用
对指针解除引用意味着获得指针指向的值。对指针引用或间接值运算符* 来解除引用。cout<<*pn;
另一种解除引用的方法是使用数组表示法,例如 pn[0]与*pn是一样的 不要对未初始化的地址的指针解除引用。
4.区分指针和指针所指向的值
int * pt=new int; pt为指针 *pt为int变量
5.数组名
数组名为数组的第一个元素的地址
注意 sizeof 运算符用于数组名时,返回整个数组的长度 单位为字节
6.指针算术
指针和整数相加,结果为原来的地址值加上指向的对象占用的总字节数。 仅当两个指针指向同一个数组时,两个指针相减会得到两个元素的间隔。
7.数组的动态联编和静态联编
使用数组声明来创建数组时,将采用静态联编,即数组的长度在编译时的设置:
int tacos[10];
而使用new [] 运算符创建数组时,将采用动态联编 (动态数组),即将在运行时为数组分配空间,其长度也将在运行时设置。使用完这种数组后,应使用delete[ ]释放其占用的内存:
int size;
cin>>size;
int * pz=new int [size];
delete [] pz;
8.数组表示法和指针表示法
使用方括号数组表示法等同于对指针解除引用
int * pt =new int [10];
* pt=5; 数组首元素为5 即第0个元素
pt[0]=6; 数组首元素为6
pt[9]=44; 数组第9个元素为44
int coats[10];
*(coats+4)=12; 数组第4个元素为12
3.指针和字符串
数组和指针的特殊关系可以扩展到c风格字符串
char flower[10]="rose";
cout<<flower<<"s are red\n";
数组名是第一个元素的地址,因此cout语句中的flower是包含字符r的char元素的地址。
输出时会输出rose 也就是说cout会输出fower指向的char数组中的字符串 直到空字符为止。
在cout和多数c++表达式中,char数组名,char指针以及用引号括起的字符串常量都被解释为字符串的第一个字符的地址,所以以上的情况都会输出字符串,直到遇到空字符
//4.20ptrstr.cpp 不同形式的字符串
#include <iostream>
#include <cstring>
int main(){
using namespace std;
char animal[20]="bear"; //array
const char * bird ="wren"; //pointer 字符串地址保存
char * ps;
cout<<animal<<" and "; //输出animal数组名代表地址处的字符串。
cout<<bird<<"\n"; //输出指针指向的地址中的字符串。
cout<<"enter a kind of animal: ";
cin>>animal; //将输入的数据保存到animal变量中 这里animal是字符串 不是指针
//cout<<animal<<endl;
ps=animal;
cout<<ps<<"!\n"; //ps与animal变量相同
cout<<"before using strcpy():\n";
cout<<animal<<" at "<<(int *) animal<<endl; //将字符串类型 强制转换为整型的指针
cout<<ps<<" at "<<(int *) ps <<endl; //同理ps也一样
ps=new char(strlen(animal)+1); //创建一个字符数组 数组长度为animal字符串的长度加上1 1为空字符 并将此数组的首地址赋值给ps变量
strcpy(ps,animal); // 将animal字符串存储到ps指针指向的地址的内存单元
cout<<"after using strcpy():\n";
cout<<animal<<" at "<<(int *) animal<<endl;
cout<<ps<<" at "<<(int *) ps<<endl; //此时的ps为新申请的地址
delete [] ps; //释放内存中 ps指向的字符数组
return 0;
}
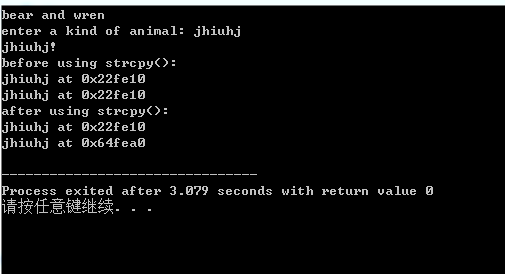
说明:1.“wren”实际表示的是字符串的地址,因此这条语句将wren的地址赋值给了bird指针。一般的编译器在内存中留出一些空间,来存储程序源代码中所有用引号括起来的字符串。并将每个被存储的字符串与其地址关联起来。
2.字符串字面值是常量,这就是为什么用const的原因 ,以这种方式使用const意味着可以用bird来访问字符串,但是不能修改它。
使用数组名animal和指针bird是一样的,cout将显示存储在这两个地址上的两个字符串 bear和wren。
对于输入cin 如果输入的较短 那么可以存储到数组中,则使用数组animal进行输入可行,但是使用bird来进行输入并不合适。
a c++中字符串字面量都被视为常量,但不是所有的编译器都会在修改只读常量 (例如字符串字面量)时,会产生运行阶段错误
b 有些编译器使用字符串字面值的一个副本来表示程序中所有的该字面值。
针对b点:c++不能保证字符串字面值被唯一地存储。如果在程序中多次使用了字符串字面值“wren” 则编译器可能存储该字符串的多个副本,也可能是一个副本。如果为后者,则bird将指向该字符串的唯一副本。
不要使用字符串常量或未初始化的指针接受输入,可以使用std::string对象,而不是数组。
一般情况下 给cout提供一个指针会打印地址,但是如果指针的类型为cha *,则cout将显示指向的字符串。如果要显示的是字符串的地址,则必须将这种指针强制转换为另一种指针类型,如int*(上面的代码就是这样做的),所以ps显示为字符串“fox”,而(int *) ps显示为该字符串的地址。注意将animal赋值给ps并不会赋值字符串,而只是复制地址,首先需要分配内存来存储该字符串,可以通过声明另一个数组或使用new来完成。后一种方法使得能够根据字符串的长度来指定所需要的空间
ps=new char[strlen(animal)+1];
“fox”不能填满整个animal数组,所以这样做浪费了空间,上述代码使用strlen()来确定字符串的长度,并将它加1来获得包含字符时该字符串的长度。随后程序使用new来分配刚好足够存储该字符串的空间。
之后,需要将animal数组中的字符串复制到新分配的空间中,将animal赋值给ps是不可行的,因为这样只能修改存储在ps中的地址,从而失去程序访问新分配内存的唯一途径。需要使用库函数strcpy(): strcpy(ps,animal);
strcpy接受2个参数。第一个是目标地址,第二个是要复制的字符串的地址。需要确定分配了足够的目标空间,使用strlen来确定所需要的空间,并使用new获得可用的内存。
通过使用strcpy()和new,将获得“fox”的两个独立副本:
fox at 0x005462d3
fox at 0x00642841
new在离animal数组很远的地方找到了所需要的内存空间。
经常需要将字符串放到数组中。初始化时,需要使用=运算符;否则应该使用strcpy()或者strncpy()
char food[20]="carrots";
strcpy(food,"flan")
源代码
#include <iostream>
#include <cstring>
int main()
{
using namespace std;
char food[20]="carrots";
cout<<food<<endl; //carrots
strcpy(food,"flan");
cout<<food<<endl; //flan
return 0;
}
注意类似下面这样的代码可能会导致问题 因为food数组比字符串小
strcpy(food,"a pina basket filled with many goodies xxxxxxxxx");
这种情况下,函数会将字符串中剩余的部分复制到数组后面的内存字节中,这可能会覆盖程序正在使用的其他内存,所以请使用strncpy(),此函数还接受第3个参数--要复制的最大字符数。另外要注意:如果该函数在到达字符串结尾之前,目标内存已经用完,则它将不会添加空字符。
strncpy(food,"a pina basket filled with many goodies xxxxxxxxx",19);
food[19]='\0';
这样最多将19个字符复制到数组中,然后将最后一个元素设置成空字符。如果该字符串少于19个字符,则strncpy()将在复制完该字符串后,加上空字符,以标记该字符串的结尾。
如果使用c++的string类型则更为简单,可以不使用strcpy()和strncpy()函数,而使用=运算符
4.使用new创建动态结构
在运行时创建数组优于编译时创建数组,对于结构也是如此。需要在程序运行时为结构分配所需的空间,这也可以使用new运算符来完成。通过使用new,可以创建动态结构
类与结构类似,所以一下方法可用于类
a 创建结构
inflatable * ps= new inflatable;
存储inflatable结构的一块可用内存的地址赋给ps 这种句法和c++内置类型是完全相同的。
b 访问成员 动态的结构由于美国有名称,只知道地址,所以只能使用-->运算符 ps->price 被指向结构的price成员
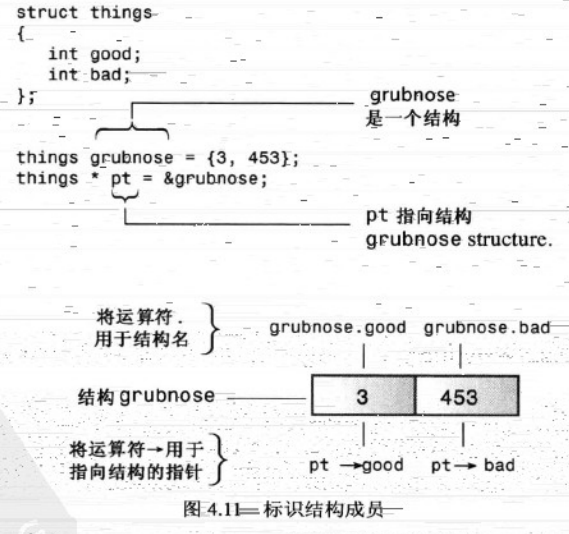
注意指定结构成员时,如果有结构名就是用句点运算符 如果有指针 就使用箭头运算符。
另一种访问结构成员的方法是:如果ps是指向结构的指针 则* ps为结构本身 所以可用 (* ps).price 来访问结构的成员。注意运算符要求要使用括号。
//newstrct.cpp using new with a structure
#include <iostream>
struct inflatable{ //结构定义
char name[20];
float volume;
double price;
};
int main(){
using namespace std;
inflatable * ps =new inflatable; //创建结构空间并ps指向
cout<<"enter name of infaltable item:";
cin.get(ps->name,20); //获得输入最大20个字符 存入ps->name成员数组中
cout<<"enter volume in cubic feet: ";
cin>>(*ps).volume; //获得输入 并存入volume成员
cout<<"enter price:$";
cin>>ps->price; //价格
cout<<"name: "<<(* ps).name<<endl; //输出结构体.运算
cout<<"Volume: "<<ps->volume<<" cubic feet \n"; //
cout<<"price: $"<<ps->price<<endl;
delete ps; //释放申请的内存空间
return 0;
}
//4.22 delete.cpp
#include <iostream>
#include <cstring> //string.h
using namespace std; //命名空间 外置
char * getname(void); //函数原型
int main()
{
char * name; //字符指针
name =getname(); //调用
cout<<name<<" at "<<(int *) name<<"\n";//输出字符串和所在的地址
delete [] name;//释放指针指向的内存
name =getname();//同上
cout<<name<<" at "<<(int *) name<<"\n";
delete [] name;
return 0;
}
char * getname() //函数实现
{
char temp[80];//字符数组
cout<<"enter last name: ";
cin>>temp;// 标准输入存入指定数组
char * pn=new char[strlen(temp)+1];//新申请一个数组长度的空间 并pn指向
strcpy(pn,temp); //复杂字符串 到新申请的空间。
return pn;//返回指针
}
程序说明:
1.getname() 使用cin将输入的单词放到temp数组中,然后使用new分配内存 需要的空间长度为strlen(temp)+1 个字符 包括空字符,之后getname()使用标准库函数strcpy()将temp中的字符串赋值到新的内存块中,该函数并不检查内存块是否能够容纳字符串。但getname()通过使用new请求合适的字节数来完成这样的工作。函数返回pn指针,指向字符串副本的内存块
2.main中 返回值(地址)被赋值给指针name,该指针是在main()中定义的,但它指向getname()函数中分配的内存块,之后, 程序打印该字符串及其地址。
3.在第一次释放name指向的内存后,main再次调用getname c++不保证新释放的内存就是下一次使用new时选择的内存 可能是也可能不是 (是否有地址池?如果有地址池前后两次使用的内存可能是一样的)
4此例子中main中释放内存 getname创建内存 说明分开new和delete是可行的,但是建议不要这样做
5.第9章为c++处理内存的知识
5.自动存储、静态存储、和动态存储
内存分配的方法: c++三种管理数据内存的方式:自动存储 静态存储 动态存储(有时也叫自由存储空间或堆)。
c++11 新增了第四种类型 线程存储
a 自动存储
函数内部定义的常规变量使用自动存储空间,被称为自动变量,
在函数被调用时,此类变量自动产生,在函数结束时,消亡。
上例中的temp数组当getname函数活动时存在,当程序控制权到main时,temp内存又释放。如果genname返回temp地址,则main中的name指针指向的内存将很快得到重新使用。
自动变量为局部变量,作用域为包含它的代码块,一般一个代码块为一个函数,但是以后会看到函数内也可以有其他的代码块 ,
自动变量存储在函数的栈中,执行代码块时,其中的变量将依次加入到栈中。离开时后进先出。
b 静态变量
静态存储是整个程序执行期间都存在的存储方式。使变量成为静态的方式有两种:一种是函数外面定义,另一种是在声明变量时使用关键字static
static double fee=56.50
自动存储和静态存储的关键在于 变量的寿命
变量可能存在于程序的整个生命周期(静态变量),也可能只是在特定函数被执行时存在(自动变量)。
c 动态存储
new 和delete 运算符提供了一种比上面更灵活的方法,他们管理一个内存池,在c++中被称为自由存储空间 free store或者堆 heap。该内存池同用于静态变量和自动变量的内存是分开的。
new和delete可以在同一个函数(代码块)或者不同的代码块中出现,也就是说可以在一个函数中创建内存空间,在另一个函数中释放内存空间,加大了管理的复杂度。
new和delete的相互影响会导致占用的自由存储去不连续。
堆、栈、内存的泄漏
当使用new 创建存储空间给变量后,没有调用delete,可能会发生内存泄漏的情况,即使指向创建的内存的指针由于作用域或对象的生命周期的原因被释放,动态分配的内存块(自由存储空间中)的变量或者结构也将继续存在。实际上,将会无法访问自由存储空间的结构。因为指向的指针已经无效,
为了避免这种情况,需要同时使用new和delete运算符,在自由存储空间上动态分配内存,随后就释放它。
绝对不允许使用未初始化的指针来访问内存或者释放一个指针两次。
9.类型组合
数组 结构 指针,可以互相之间组合
struct date
{
int year;
/*sone really interesting data,etc.*/
}
结构: date s01,s02,s03;
成员运算符:s1.year=1998;
创建结构指针:date * pa=&s2;
使用间接成员运算符来访问成员:pa->year=1999;
创建数组:date a[3]; 三个结构体类型的数组
使用成员运算符来访问元素的成员:a[0].year=2003;
其中a是一个数组,a[0]是一个结构,而a[0].year是该结构的一个成员。由于数组名是一个指针,所以可以使用间接成员运算符
(a+1)->year=2004 等价于 a[1].year=2004;
可创建指针数组: const date *b[3]={&s01,&s02,&s03}; b为指针数组 b[1]为指针 可将间接成员运算符应用于它,以访问成员
std::cout<<b[1]->year<<std::endl;
创建指向上述指针数组的指针:const date * * pb=b;
b是一个数组的名称,因此它是第一个元素的地址。但其第一个元素为指针,因此pb是一个指针,指向一个指向const date 的指针。声明容易出错。
可以使用c++11版本的auto 来避免错误
auto pb=b; c++自动类型检测。
成员的访问:cout<<(*pb)->year<<endl; cout<<(*(pb+1))->year<<endl
pb是一个指向结构指针的指针,因此*pb是一个结构指针 可以用间接成员运算符
pb指向b的第一个元素 所以*pb为指针数组的第一个元素,即&s01。 所以 (*pb)->year为s01的year成员。在第二条语句中,pb+1指向下一个元素b[1],
即&s02 括号必不可少。* pb->year 试图将运算符*应用于pb->year 因为year不是指针 对不是指针的变量采取*运算符(解除引用)会导致错误。
//mixtypes.cpp 4.23
#include <iostream>
struct date{int year;};
int main()
{
using namespace std;
date s01,s02,s03; //定义结构变量
s01.year=1998; //初始化 s01
date * pa=&s02; //pa指针指向s02
pa->year=1999; //初始化s02
date b[3]; //结构数组 定义
b[0].year=2003; //结构体成员访问
cout<<b->year<<endl; //b为数组首元素 首元素成员访问
const date * arp[3]={&s01,&s02,&s03}; //常量指针数组 成员均为指针
cout<<arp[1]->year<<endl; //输出 s02中的year成员
const date * * ppa=arp; //指向指针数组的指针
auto ppb=arp; // 同上 利用c++的auto来自动判断变量的类型 比较安全
cout<<(*ppa)->year<<endl; //ppa指向arp arp为指针数组 所以*ppa代表arp中的首元素 此例代表 &s01->year
cout<<(*(ppb+1))->year<<endl;//同上 *(ppb+1) 代表&s02 此例代表&s02->year
return 0;
}
如果上面的auto编译不能成功,devc++ 中 gcc 4.9.2 编译器中需要在编译选项中加入-std=c++11命令。
10.数组的替代品
模板vector和array是数组的替代品
类似于string类,是一种动态数组。可以在运行阶段设置vector对象的长度 可以再末尾附加新数据, 还可以在中间插入新数据。 他是使用new创建动态数组的替代品。
vector 使用new 和delete来自动管理内存
vector <typeName> vt (n_elem)
其中n_elem可以是整形常量或者变量
注意事项:
头文件 <vector>; vector包含在名称空间std中 可以使用using 编译指令 using声明或者std::vector ; 模板使用不同的语法来指出它存储的数据类型
vector类使用不同的语法来指定元素数
示例:
#include <vector>
...
using namespace std;
vector <int> vi; //创建了一个整形的数组 名为vi
int n;
cin>>n;
vector<double> vd(n);
2. 模板类 array c++11
vector 类安全 功能比数组强大 但是效率低 如果需要长度固定的数组,使用数组时最好的选择,但是不方便,所以有了新增的模板类 array 位于名称空间std中,与数组一样 长度固定。
也使用栈(静态内存分配),而不是自由存储区,因此效率与宿主相同 但是更方便安全。
需要头文件array 创建语法与vector稍有不同 语法:array <typename,n_elem> arr; n_elem不能是变量 名称为arr
#include <array>
...
using namespace std;
array<int,5> ai; //长度5的空数组 组名为ai
array<double, 4> ad={1.2,3.1,3.43,4.3};//长度为4的 double类型的数组 并且初始化
3.比较数组、vector对象和array对象
示例程序
//4.24 choices.cpp
#include <iostream>
#include <vector>
#include <array>
int main()
{
using namespace std;
auto i=1;
double a1[4]={1.2,2.4,3.6,4.8};//c c++
vector<double> a2(4); //vector 创建的数组 c++98
a2[0]=1.0/3.0;
a2[1]=1.0/5.0;
a2[2]=1.0/7.0;
a2[3]=1.0/9.0;
array<double,4> a3={3.14,2.72,1.62,1.41}; //array的方式创建a3 初始化 和a4数组未初始化
array<double,4> a4;
a4=a3;//赋值 可以将一个对象赋值给另一个对象 但是数组就不可以直接赋值,只能单个元素复制
cout<<"a1[2]: "<<a1[2]<<" at "<<&a1[2]<<endl; //输出a1数组中的
cout<<"a2[2]: "<<a2[2]<<" at "<<&a2[2]<<endl;
cout<<"a3[2]: "<<a3[2]<<" at "<<&a3[2]<<endl;
cout<<"a4[2]: "<<a4[2]<<" at "<<&a4[2]<<endl;
a1[-2]=20.2;//此处的a1[-2] 转化为*(a1-2) 表示 找到a1指向的地方,并在向前移动两个double类型的元素 并将20.2存储到此为止。
cout<<"a1[-2]: "<<a1[-2]<<" at "<<&a1[-2]<<endl;
cout<<"a3[2]: "<<a3[2]<<" at "<<&a3[2]<<endl;
cout<<"a4[2]: "<<a4[2]<<" at "<<&a4[2]<<endl;
return 0;
}

程序说明:无论数组 vector还是array对象 都可以使用标准数组表示法来访问各个元素
array对象和数组存储在相同的内存区域(栈)中,vector 对象存储在另一个区域(自由存储区或堆)中。
array对象可以直接复制,数值不能直接复制,只能以元素为单位进行复制
a1[-2]=20.2 等价于*(a1-2)=20.2;
a1指向的地方,向前移动两个double元素,并将20.2存储到目的地。也就是说,将信息存储到数组的外面 已经越界,但是c++并不检查这种错误
所以在使用时这种不安全需要避免
vector和array对象可以禁止这种行为
a2[-2]=0.5; 命令可以执行
但是可以使用另一种选择 成员函数at() 类似于cin对象的成员函数getline()一样,可以使用vector和array对象的成员函数at();
a2.at(1)=2.3
中括号表示法和成员函数at()的区别是
at可以在运行期间捕获非法索引 程序默认会中断。 代价就是时间运行长 这些类还能够降低意外的超界的错误 包含成员函数begin()和end()这两个函数。
