
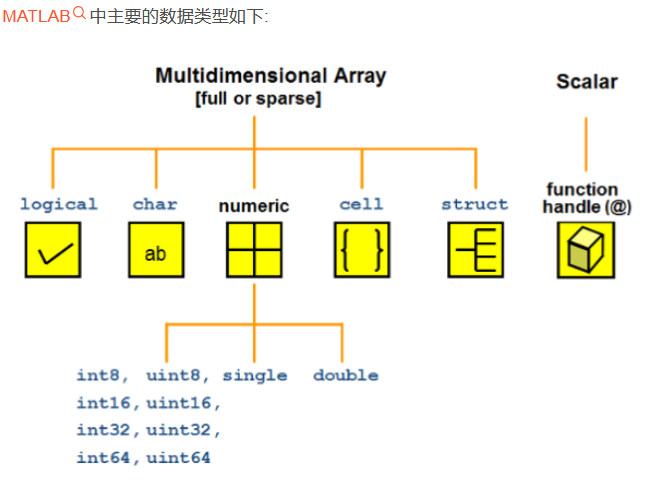
数值类型 numeric
默认为double类型 也可以使用类型转换将其转换为其他类型
n=3; class(n) %得到double类型 n=int8(30); class(n) %得到int8 类型
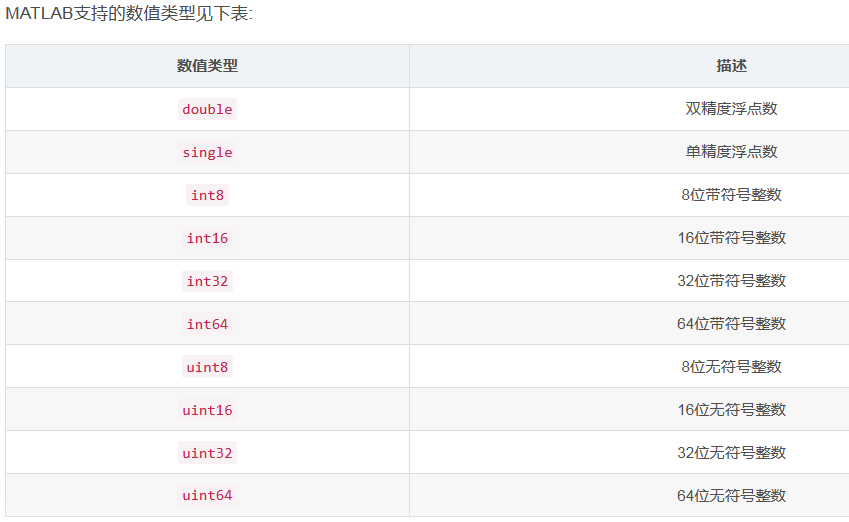
字符类型(char)
%% s1='h' %char类型 显示占2个字节 a=uint8(s1) %强制将s1的char类型转换为numric类型 显示占1个字节 显示104 ascii码表 whos %% s2='H' %同上 b=uint16(s2) % 同上但是占用2个字节 16位无符号整数 显示72 大写字母和小写字母 相差32 (10进制) whos
字符串类型 string
s1='Example'; s2='String'; whos s3=[s1 s2] % 显示 ExampleString 两个字符串串联在一起 s4=[s1;s2]; %加; 组成行列式 失败 两个字符串 的维度不同 前者7列 后者6列

s5=[s1;s1] %两个字符串长度要一致 显示 s5 = Example Example
拓展:
A1=['str1' 'str2']; A2=['str3' 'str4']; A3=['str5' 'str6']; C=vertcat(A1,A2,A3) 输出 C = str1str2 str3str4 str5str6
等价于C=[A1;A2;A3]
逻辑操作与赋值
str='aardvark'; 'a'==str %得到11000100 遍历str中的每个元素和a进行比较 如果%相同则返回1 不同返回0 str(str=='a')='Z' %先执行括号内语句 得到11000100 逻辑运算结果, %再将结果作为索引位置的开关 当该索引位置的值为1时替换为Z 如果为0 %则不替换 所以此时输出 ZZrdvZrk
字符串比较
strcmp 函数
s1='exmaple'; s2='string'; strcmp(s1,s2) %比较s1和s2 得到0 strcmp(s1,s1) %比较s1和s1 得到1
比较函数还有eq ne regexp regexpi sort strcmpi strfind strncmp strncmpi
练习:
s1='i like the letter E' s2=s1(length(s1):-1:1) %翻转字符串 s3=s1(size(s1,2):-1:1) %翻转字符串 s4=reverse(s1) %翻转字符串 输出 s4 = 'E rettel eht ekil i'
t="Hello, world"; whos t % 为何是160 q="Something ""quoted"" and something else." % 显示双引号 需要再用引号修饰 f=71; c=(f-32)/1.8; temptext="temperature is"+c+" °C" % 用+ 连接两个字符串 Name Size Bytes Class Attributes t 1x1 160 string q = "Something "quoted" and something else." temptext = "temperature is21.6667 °C"
%字符串数组
A=["a","bb","ccc";"dddd","eeeee","ffffff"] strlength(A) A = 2x3 string 数组 "a" "bb" "ccc" "dddd" "eeeee" "ffffff" ans = 1 2 3 4 5 6
结构体类型 structure
一种存储异构数据的方法 结构包含成为字段的数组
1.创建结构体
student.name='john doe'; student.id='jdo2@sfu.ca'; student.number=301073268; student.grade=[100,75,73;... 95,91,85.5;... 100,98,72]; student 输出为 student = 包含以下字段的 struct: name: 'john doe' id: 'jdo2@sfu.ca' number: 301073268 grade: [3x3 double]
向结构中添加信息 例如加入另一名同学的记录
student(2).name='ann lane'; %默认结构体中第一个记录的索引为1 所以此处再添加索引为2 student(2).id='aln4@sfu.ca'; student(2).number=301073269; student(2).grade=[95 100 90;... 95,82 97;... 100,85 100]; student %显示当前结构体中所有的记录 student(1).grade(2,3)=30; %修改行列式中某个位置的值 student %结果如下 第2行第3列的元素已经修改成功
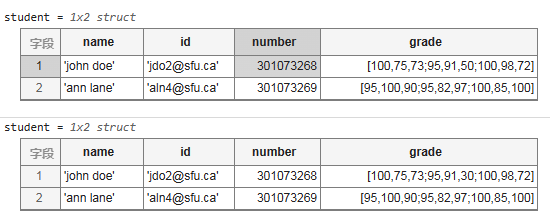
显示结构体中的某个值
student(1).grade(7) %以列为索引方向 student(2).name
rmfield 举例
fieldnames(student) ans = 4x1 cell 数组 {'name' } {'id' } {'number'} {'grade' } >> student student = 包含以下字段的 1x2 struct 数组: name id number grade >> rmfield(student,'id') %只是存储在临时变量ans中 而不改变原结构体中的数据 ans = 包含以下字段的 1x2 struct 数组: name number grade
嵌套结构
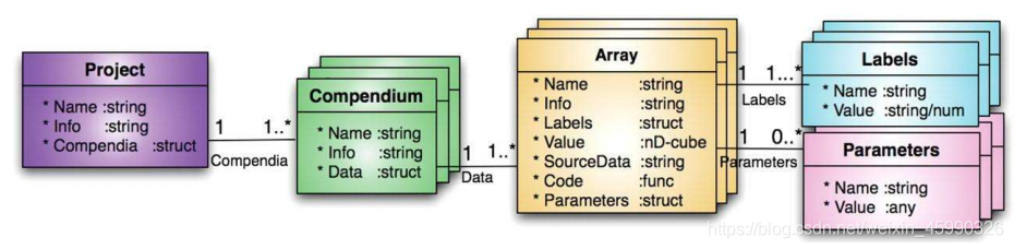
结构体中包含结构体
A=struct('data',[3 4 7;8 9 1],'nest',struct('testnum','test1','xdata',[4 2 8],'ydata',[7 1 6]));
A = %同A(1) 包含以下字段的 struct: data: [2x3 double] nest: [1x1 struct] >> A.nest %同A(1).nest ans = 包含以下字段的 struct: testnum: 'test1' xdata: [4 2 8] ydata: [7 1 6]
元胞数组 cell
用于存储异构数据 ;类似矩阵 但每个条目包含不同类型的数据;通过将索引括在括号内() 中可以引用元胞集,使用花括号 { }进行索引来访问元胞的内容 ;个人理解 可以包含任何类型的元素 类似二维数组
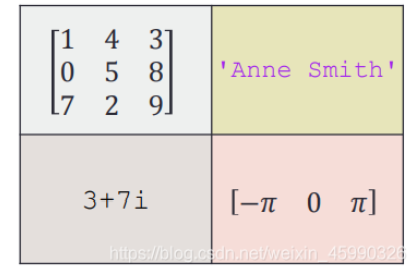
A(1,1)={'This is the firest cell'}; A(1,2)={[5+j*6 4+j*5]}; A(2,1)={[1 2 3;4 5 6;7 8 9]}; A(2,2)={["Tim","Chris"]}; >> A A = 2x2 cell 数组 {'This is the firest cell'} {[5.0000 + 6.0000i 4.0000 + 5.0000i]} {3x3 double } {["Tim" "Chris" ]}
1.创建对象和访问
{ } 用于创建 或者在前 或者在后
A(1,1)={[1 4 3;0 5 8;7 2 9]}; %A{1,1}=[1 4 3;0 5 8;7 2 9] 也可
A(1,2)={'Anne smith'}; %A{1,2}='Anne smith';
A(2,1)={3+7i}; %A{2,1}=3+7i
A(2,2)={-pi:pi:pi}; %A{2,2}=-pi:pi:pi
%以下为输出 A{1,1}(2) ans = 0 A{1,1}(2,2) ans = 5
创建空的=0*0元胞数组
B={ } 此时B为空的元胞数组
原理:单元格数组中的每个条目都持有一个指向数据结构的指针,同一单元阵列的不同单元可以指向不同类型的数据结构
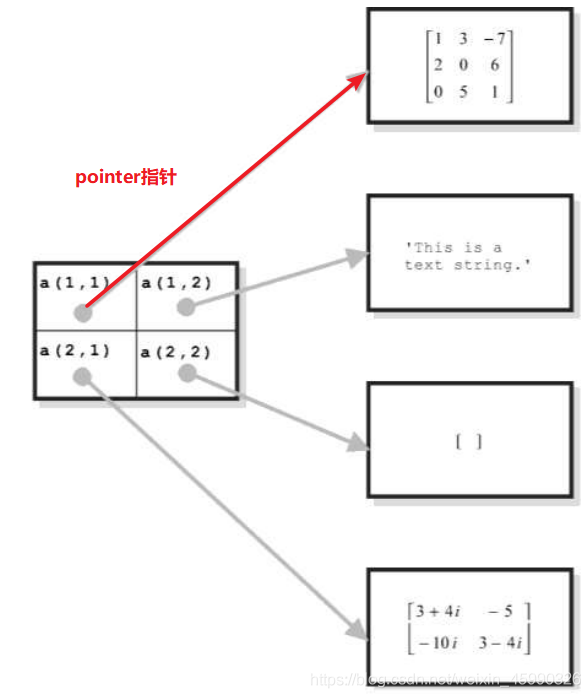
访问单元阵列
>>A(1,1) % 查看指针 本身指向的内容类型 注意用( ) ans = 1x1 cell 数组 {3x3 double} >> A{1,1}(3) %查看指针指向内存单元的实际内容 用{ } ans = 7 >> A{1,1}(3,2) ans = 2
A = 2x2 cell 数组 {'This is the firest cell'} {[5.0000 + 6.0000i 4.0000 + 5.0000i]} {3x3 double } {["Tim" "Chris" ]} >> A(1,1) % 显示指针本身内容 指向内容的数据烈性 ( ) ans = 1x1 cell 数组 {'This is the firest cell'} >> A{1,1} %显示指针指向的内容 具体数据 { } ans = 'This is the firest cell'
元胞数组函数
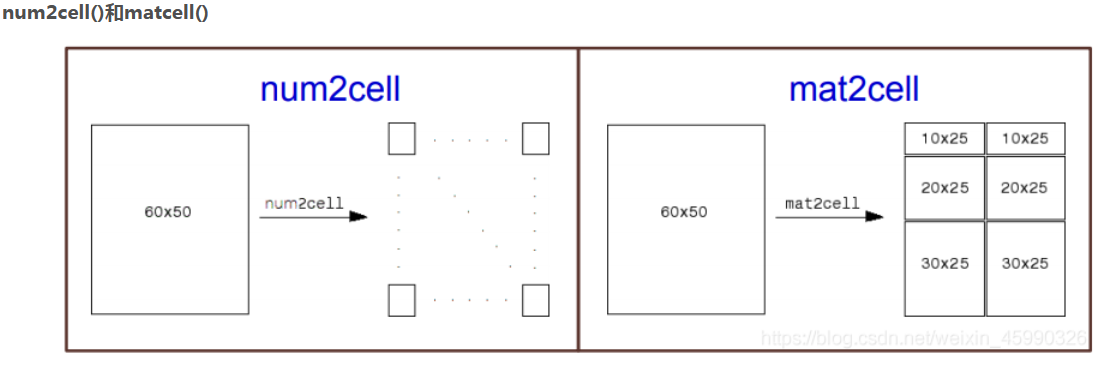
>> a=magic(3) b=num2cell(a) a = 8 1 6 3 5 7 4 9 2 b = 3x3 cell 数组 {[8]} {[1]} {[6]} {[3]} {[5]} {[7]} {[4]} {[9]} {[2]} %此时 b变为了元胞数组
3x1 cell 数组
{[8 1 6]}
{[3 5 7]}
{[4 9 2]}
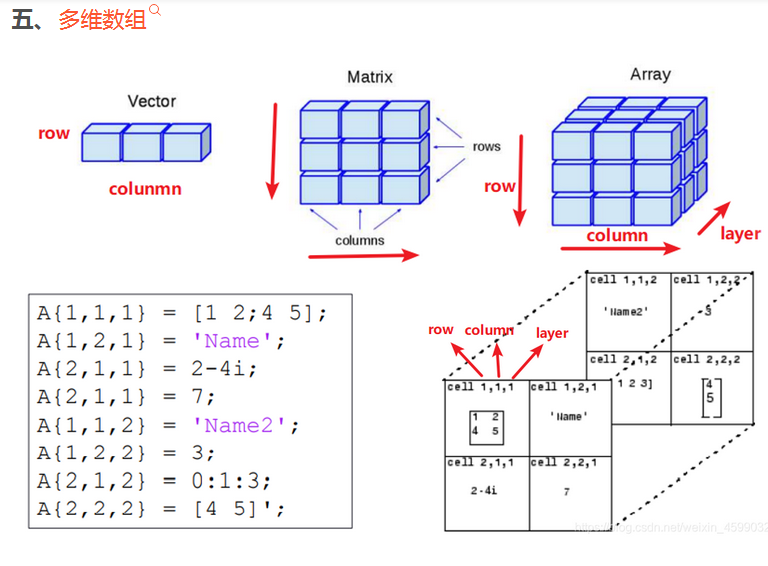
多维数组
array concatenation
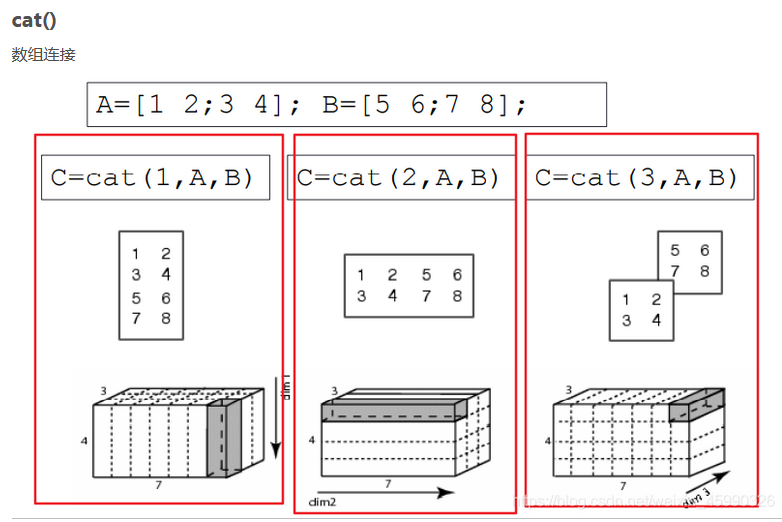
cat(1,A,B) 第一个参数表示三维中的第几维 1为row 2为column 3为layer
A=[1 2;3 4] B=[5 6;7 8] C=cat(1,A,B) >>C = 1 2 3 4 5 6 7 8 >> C=cat(2,A,B) C = 1 2 5 6 3 4 7 8 >> C=cat(3,A,B) %layer 为3 C(:,:,1) = % 1代表第一layer 1 2 3 4 C(:,:,2) = %代表第二layer 5 6 7 8
reshape() 将原来的矩阵行数和列数 改变 变成一个新的矩阵 r1*c1=r2*c2 行数1*列数1=行数2*列数2
returns a new array with assigned rows and columns
A={'james bond',[1 2;3 4;5 6];pi,magic(5)};
C=reshape(A,1,4);
>> A
A =
2x2 cell 数组
{'james bond'} {3x2 double}
{[ 3.1416]} {5x5 double}
>> A{2,2}
ans =
17 24 1 8 15
23 5 7 14 16
4 6 13 20 22
10 12 19 21 3
11 18 25 2 9
>> C
C =
1x4 cell 数组
{'james bond'} {[3.1416]} {3x2 double} {5x5 double}
1 A=[1:3;4:6]; 2 3 >> A 4 A = 5 6 1 2 3 7 4 5 6 8 >> whos A 9 Name Size Bytes Class Attributes 10 11 A 2x3 48 double 12 >> C=reshape(A,3,2) 13 C = 14 1 5 15 4 3 16 2 6 17 >>

文件读写 FILE ACCESSING 读写matlab格式的数据
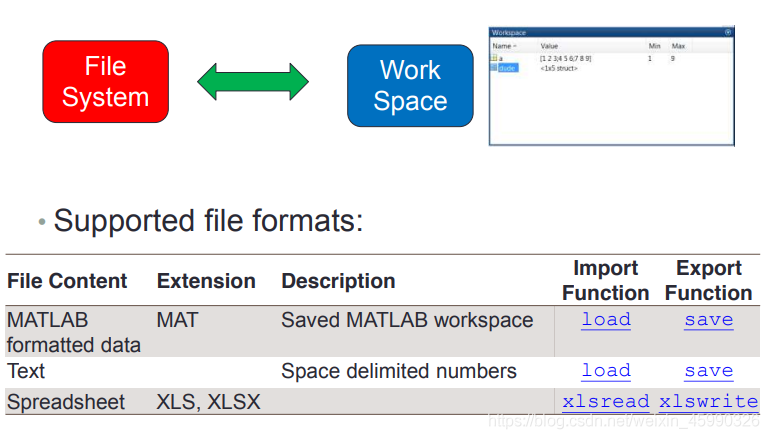

a=magic(4); save testdata.mat; >> clear >> a 函数或变量 'a' 无法识别。 >> load('testdata.mat') >> a a = 16 2 3 13 5 11 10 8 9 7 6 12 4 14 15 1 >>
注意 1. 不加 -ascii码后,生成的mat文件打开会出现乱码
2. 在save文件时有-ascii时,load文件 也要加上相应的参数
读写excel表格 数据
xlsread( ) xlswrite()
score=xlsread('81score.xlsx'); score=xlsread('81score.xlsx','B2:D4'); %仅仅读取其中的数值 而不读取文字
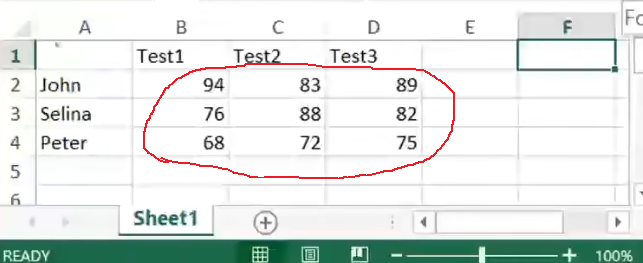
注意表格文件 所存放的目录 matlab能够搜索的路径下
xlswrite() 计算平均值 并写入xls表格中
score=xlsread('s.xls');%将表格中数据保存到score变量中 M=mean(score')' %注意‘’ 的位置? 计算每人的平均值 xlswrite('s.xls',M,1,'E2:E4'); % 文件名 M为三人平均值数值 1为%sheet1 表格 E2:E4为单元格位置 % filename variable sheet location xlswrite('s.xls',{'平均值'},1,'E1'); %将字段名填写到E1位置
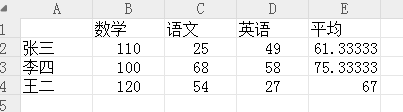
读取数值和字段名称部分
[score header]=xlsread('s.xls');
参数1存储numeric 数值类型的数据 header存储string 数据
>> [score header]=xlsread('s.xls') score = 110.0000 25.0000 49.0000 61.3333 100.0000 68.0000 58.0000 75.3333 120.0000 54.0000 27.0000 67.0000 header = 4×5 cell 数组 '' '数学' '语文' '英语' '平均' '张三' '' '' '' '' '李四' '' '' '' '' '王二' '' '' '' ''
同时也能将两种类型的数据 存储到xls文件当中去 xlswrite() 介绍略
低级文件的输入和输出
在字节或字符级别读取和写入文件
文件ID为fid fileid 利用内建函数确定
文件中的位置由可移动的指针制定
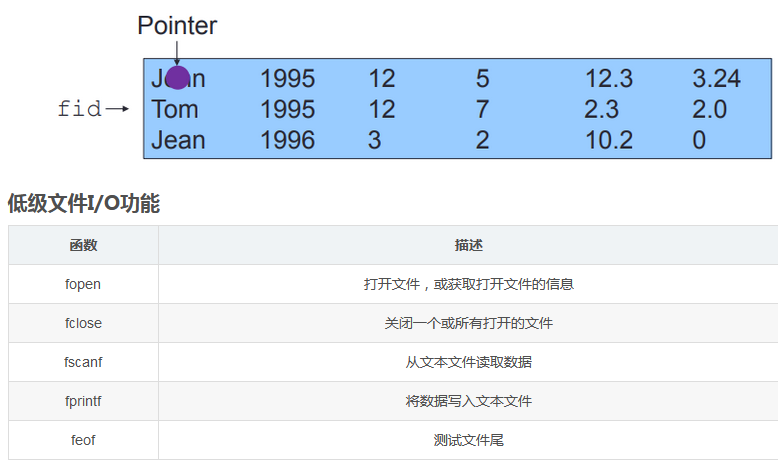
fid=fopen('[filename]','[permission]') 前者为文件名称 可包括路径 后者为权限 可加 可写 可执行
status=fclose(fid); 关闭打开的文件 参考c语言中的文件
