Mysql学习总结
表:具有固定列数和任意行数。
数据库:一些关联表的集合。
主键:一个数据表只能包含一个主键,使用主键来查询数据。
外键:用来关联两张表。
索引:快速访问数据库表的特定信息,索引是对数据库表一列和多列的值进行排序的一种数据结构。
DDL:数据定义语言:定义数据库对象:创建库,表,列等。
DML:数据操作语言:用来操作数据库表中的记录。
DQL:数据查询语言:用来查询数据。
DCL:数据控制语言:用来定义访问权限和安全级别。
oracle 创建用户:
grant resource ,connect to 用户名;
mysql数据库分为两类:
系统数据库:
- information_schema:存储数据库对象信息(例如:用户表信息,列信息等里面内容不能动)。
- performance_schema:存储数据库服务器性能参数信息。
- mysql:存储数据库用户权限信息。
- sys:以视图形式将information_schema和performance_schema结合,查询出更容易理解数据。
用户数据库:
用户自己创建的数据库,一个项目一个数据库。
常用数据类型:
double:浮点型(double(5,2)表示最多5位,其中必须有两位小数)。
char:固定长度字符串类型
varchar:可变长度字符串类型
text:字符串类型
blob:二进制类型
data:日期类型(格式为:yyyy-MM-dd)
time:时间类型(格式为:hh:mm:ss)
datatime:日期时间类型(格式为:yyyy-MM-dd hh:mm:ss)
在mysql中字符串类型和日期类型都要用单引号括起来。('mysql','2020-01-01')
-----------------------------------------------------------------------------------------------------------------------------------------------------
命令总结:
DDL:
- 创建数据库:create database 数据库名 character set utf8
- 修改数据库:alter database 数据库名 character set gbk
- 删除数据库:drop database 数据库名
- 查看数据库:show database 数据库名
- 使用数据库:use +数据库名称(之后可以查看数据库当中有多少张表:show tables)
- 创建学生表:
CREATE TABLE student( id BIGINT, name VARCHAR(20), email VARCHAR(20), age INT ); - 添加一列:alter table 表名 add 列名 数据类型
- 查看表字段信息:desc 表名
- 修改一个表的字段类型:alter table 表名 modify 字段名 数据类型
- 删除一列:alter table 表名 drop 字段名
- 修改表名:rename table 原始表名 to 要修改的表名
- 查看表的创建细节:show create table 表名
- 修改表的字符集为gbk:alter table 表名 character set gbk
- 修改表的列名:alter table 表名 change 原始列名 要修改列名 数据类型
- 删除表:drop table 表名
DML:
- 查询表中所有数据:select * from 表名
- 插入数据:insert into 表名(列名1,列名2...)values (列值1,列值2...)
- 批量插入:
INSERT INTO student (id, name, email, age) VALUES (1, 'zs', '123', 5), (2, 'ls', '456', 6); - 更新:update 表名 列名1=列值1,列名2=列值2... where 列名=值
- 删除:
- delete from 表名 (where 列名=值) 不删除表结构,数据可找回
- truncate table 表名 不能找回数据,删除数据快
DQL:
1.条件查询:
- 查询指定列的数据:select 列名1,列名2... from 表名
- where子句中的一些运算符和关键字
- between...and... 例如:select * from student where age between 18 and 20;
- in(set)/not in(set) 例如:select * from student where id in/not in ('1001', '1002', ''1003);
- is null / is not null
- and
- or
- not
2.模糊查询
- 通配符:
- _:任意一个字符
- %:任意0~n个字符
- 例如:查询姓名由五个字母组成,且第五个字母为s学生 select * from student where name like '____s';
- 例如:查询姓名中包含s的学生 select * from student where name like '%s%';
3.字段控制查询
- 去除重复记录:select distinct 列名 from 表名;
- 将查询结果运算并起名: 例如:select *, age+ifnull(score,0) as total from student(as可省略)
- 排序:
- select * from student order by age asc(升序默认)/desc(降序)
- select * from student order by age asc ,id desc 按年龄升序,年龄相同按id降序排列
4.常用聚合函数:
- count()统计指定列不为null的记录行数 例如:select count(*) as total_record from employee
- max(),min()统计指定列的最大值,最小值
- sum()计算指定列的数值和,如果指定列类型不是数值类型,计算结果为0
- avg()计算指定列的平均值,如果指定列类型不是数值类型,计算结果为0
5.分组查询
- group by加group_concat()表示分组后,根据分组结果,使用group_concat()来放置某一组字段的值的集合 例如:select gender, group_concat(name) from employee group by gender

- group by+聚合函数
- 例如 select department,sum(salary),count(*) from employee group by department 查询每个部门的部门名称和每个部门的工资和,人数,
- 例如select department,count(salary) from employee where salary>1500 by department; 查询每个部门的部门名称以及每个部门工资大于1500的人数。
- group by+having having作用和where一样但只能用于group by
- 例如:select depatment,sum(salary) from employee group by department having sum(salary)>9000; 查询工资总和大于9000部门的部门名称和工资和

- 例如:select department,sum(salary) from employee where salary>2000 group by department having sum(salary)>6000 order by sum(salary) desc;查询工资大于2000中,工资总和大于6000的部门名称和工资和按各部门工资总和>6000的降序排列
- 书写顺序:
![]()
- 执行顺序:

- limit:limit 参数1(从哪一行开始查),参数2(一共要查几行),角标是从零开始的 。
- 分页思路: curPage---当前页,pageSize---每页都多少条数据 select * from employee limit (curPage-1)*pageSize,pageSize;
多表查询
1.合并结果集
- union合并时去除重复记录。
- union all 合并时不去除重复记录。
- 被合并的两个结果:列数,列类型必须相同。
- select * from 表1 union (all) select * from 表2;
2. 连接查询
- 内连接:
1.等值连接:select * from stu st inner join score sc on st.id=sc.sid where score>70,

2.非等值连接:连接表的条件不是=,是其他运算符时,例如:select e.ename,e.salary,d.dname,g.grade from emp e, dept d, salgrade g where e.deptno = d.deptno and e.salary >= g.lowSalary and e.salary<=g.highSalary;
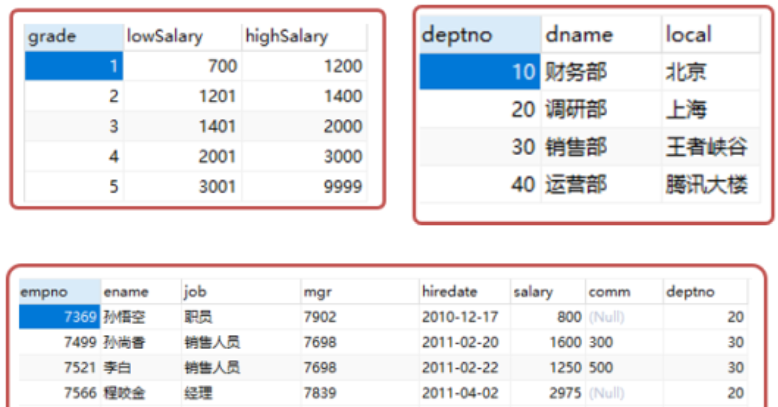
3.多表连接:99连接:select st.name,c.name,sc.score from stu st, score sc, course c where st.id=sc.sid and sc.cid=c.cid;
4.多表连接:内联查询:select st.name,c.name,sc.score from stu st inner join score sc on st.id=sc.sid inner join course c on sc.cid=c.cid;
5.自连接:自己连接自己,起别名:例如:select * from emp e1, empe2 where e1.mgr=e2.empno and e1.empno=1111; 求员工编号为111的员工编号,姓名和经理编号,姓名
- 外连接
1.左外连接:左连接会把左表中的数据全部查出,右表当中只查出满足条件的数据 例如:select st.name, sc.score, sc.km from stu st left outer(可省略) join score sc on st.id=sc.sid;
2.右外连接:同上
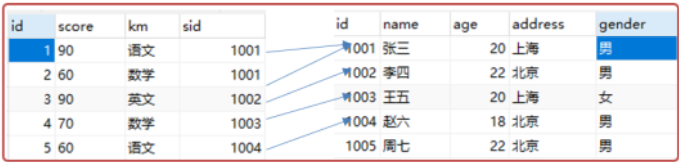
- 自然连接
两张连接的表中列的列名称和类型完全一致的列作为条件,会自动去除相同的列。例如:select * from student natural join score;
3.子查询
- 含义:一个select语句中包含一个或多个select语句.
- 出现位置:where后,把select的查询结果当作另一个select的条件值。from后把查询结果当作一个新表。
数据完整性约束
1.实体完整性
- 作用:标识每一行数据不重复
- 主键约束(primary key):
- 特点:每个表要有一个主键,数据唯一且不能为null。
- 添加方式:建表时:例如:create table 表名(字段1 数据类型 primary key,字段2 数据类型); create table 表名(字段1 数据类型,字段2 数据类型,primary key(主键1,主键2) );修改表时添加:例如:alter table student add constraint primary key(id);
- 唯一约束(unique):
- 特点:指定列的数据不能重复,可以为空值。
- 格式:create table 表名(字段1 数据类型,字段2 数据类型 unique);
- 自动增长列(auto_increment)
- 特点:指定列的数据自动增长,即使数据删除,序号不会重复之前的,继续往下走。
- 指定列的数据自动增长(添加时设置为主键)例如:create table 表名(字段1 数据类型 primary key auto_increment,字段2 数据类型);
2.域完整性
- 域:代表当前单元格。
- 作用:限制此单元格的数据正确,不对照此列的其他单元格进行比较。
- 非空约束(not null):create table 表名(字段1 数据类型 primary key auto_increment,字段2 数据类型 unique not null);
- 默认值约束(default):create table 表名(字段1 数据类型 primary key auto_increment,字段2 数据类型 unique not null default '男');
3.参照完整性
- 什么是参照完整性:表与表之间的一种对应关系。
- 通常情况下可以通过设置两表之间的主键,外键关系,或者编写两表之间的触发器来实现。
- 有对应参照完整性的两张表格,在对它们进行数据插入,更新,删除的过程中,系统都会将被修改的表格与另一张对应表格进行对照,从而阻止一些不正确的操作。
- 注意:数据库的主键和外键类型要一致,两个表必须是InnoDB类型,设置参照完整性后外键中的值必须是主键中的内容。
- 一个表设置当中的字段为主键,设置主键的为主表 create table student(sid int primary key, name varchar(50) not null, sex varchar(10) default '男');
- 创建表时设置外键,设置外键的为子表 create table score(sid int, score double, constraint fk_stu_score_sid foreign key(sid) references students(sid)); 添加外键: alter table score add constraint fk_stu_score_sid foreign key(sid) references student(sid);
事务
- 什么是事务:不可分割的操作,假设一个操作由ABCD四个步骤组成,只有四个步骤全部完成事务才成功,若任意一个失败,则认为事务失败。每条sql语句都是一个事务,事务只对DML语句有效,对DQL无效。
- 事务的ACID:1.原子性:要么全部成功,要么失败全部回滚 2.一致性:让数据保持合理,例如:仓库商品减1,对应用户购物车商品加1。3.隔离性:多个用户并发访问数据库时,一个用户开启的事务不能被其他事务的操作干扰,多个并发事务之间要相互隔离。4.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号