01-Hadoop
一、hadoop简介
1、优势
- 高可靠性:底层维护多个数据副本,所以即使hadoop某个计算元素或存储出现故障也不会导致数据丢失。
- 高扩展性:在集群间分配任务数据,可方便扩展很多节点
- 高效性:在MapRedurce的思想下,Hadoop是并行工作的,以加快任务的处理。
- 高容错性:能够自动将失败的任务重新分配
2、hadoop中的组件
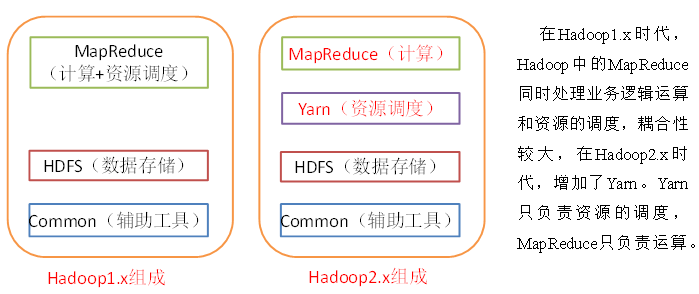
在hadoop不久之后,由于MR的低效性,出现了许多更为高效的计算框架!
例如: Tez,Storm,Spark,Flink
3、HDFS
必须进程:
①Namenode(1个): 负责文件,名称等元数据(属性信息)的存储!
文件名,大小,文件切分了多少块(block),创建和修改时间等!
职责: 接受客户端的请求!
接受DN的请求!
向DN分配任务!
②Datanode(N个): 负责文件中数据的存储!
职责: 负责接受NM分配的任务!
负责数据块(block)的管理(读,写)!
可选进程:
①SecondaryNamenode(N个): 负责辅助NameNode工作!
4、MapReduce
① MapReduce是一个编程模型!这个模型由两个阶段组成,一个称为Map阶段,另一个称为Reduce阶段!
在Map阶段和Reduce阶段分别启动若干进程负责运算!这些进程称为Task!
② 在Map阶段启动的Task称为MapTask!
在Reduce阶段启动的Task称为ReduceTask!
③ 将一个MapReduce程序称为一个Job,一个Job中会启动若干个Task!
④ 在Job启动时,Job会先创建一个MRAppMaster进程,由这个进程和RM进行通信,为Job中的每个Task申请计算所需要的资源!
⑤ Task的请求,会被RM缓存到一个调度队列中,由NM领取Task,领取后NM会根据Task要求,提供计算资源!
提供后,为了避免计算资源在当前Task使用时被其他的task抢占,NM会将资源封装到一个Container中!
⑥ Container可以对计算资源进行隔离!
5、YARN
YARN负责集群中所有计算资源的管理和调度!
核心进程:
① ResourceManager(1个): 负责整个集群所有资源的管理!
职责: 负责接受客户端的提交Job的请求!
负责向NM分配任务!
负责接受NM上报的信息!
② NodeManager(N个): 负责单台计算机所有资源的管理!
职责: 负责和RM进行通信,上报本机中的可用资源!
负责领取RM分配的任务!
负责为Job中的每个Task分配计算资源!
概念:
Container(容器): NodeManager为Job的某个Task分配了2个CPU和2G内存的计算资源。为了防止当前Task在使用这些资源期间,被其他的task抢占资源。将计算资源,封装到一个Container中,在Container中的资源,会被暂时隔离,无法被其他进程所抢占。当前Task运行结束后,当前Container中的资源会被释放!允许其他task来使用。
二、hadoop安装
1、环境要求
必须保证已经安装了JDK,有JAVA_HOME环境变量!
2、安装
解压在linux下编译的Hadoop!
3、建议将HADOOP_HOME提升为全局变量
后续的HADOOP体系中的所有的框架,都通过HADOOP_HOME找到hadoop的安装目录!
将bin,sbin目录配置到PATH中!
4、目录结构
bin: 常用的工具hadoop所在的目录
sbin: 提供对集群的管理功能,例如启动和停止进程!
etc: 默认的配置文件目录
三、hadoop的使用
1、配置文件
hadoop有4个默认我配置文件,这4个文件会随着Hadoop启动时,自动加载。如果希望对这4个文件加载的默认属性进行覆盖!用户需要自定义配置文件!
文件格式:
core-site.xml----->core-default.xml
hdfs-site.xml----->hdfs-default.xml
yarn-site.xml----->yarn-default.xml
mapred-site.xml----->mapred-default.xml
默认配置文件目录: $HADOOP_HOME/etc/hadoop
2、HDFS的运行模式
① 本地模式: 使用当前计算机的文件系统作为HDFS的文件系统!
fs.defaultFS=file:///(默认)
② 分布式文件系统: 通过运行NN,DN等进程,由这些进程组成一个分布式的系统,进行文件的读写!
fs.defaultFS=hdfs://NN所在的主机名:9000
3、启动一个分布式文件系统
① 在$HADOOP_HOME/etc/hadoop,配置core-site.xml
fs.defaultFS=hdfs://NN所在的主机名:9000
② 配置Hadoop默认的工作目录,在$HADOOP_HOME/etc/hadoop,配置core-site.xml
hadoop.tmp.dir=配置一个当前用户有写权限的非tmp目录
③ 格式化NN
hadoop namenode -format
目的: 1)生成NN的工作目录
2)在工作目录下生成NN所要使用的特殊的文件,例如VERSION,fsiamge000000
注意: 一个集群搭建完成后,只需要格式化一次!
④ 启动
hadoop-daemon.sh start namenode|datanode
⑤ 查看
jps
http://NN所运行的主机名:50070
4、MR的运行模式
本地模式: 在本机使用多线程的方式模拟多个Task的运行!
mapreduce.framework.name=local(默认)
分布式模式: 在YARN上运行!
mapreduce.framework.name=yarn(默认)
5、配置MR在yarn上运行
① 在$HADOOP_HOME/etc/hadoop,配置mapred-site.xml
mapreduce.framework.name=yarn
②配置YARN
在$HADOOP_HOME/etc/hadoop,配置yarn-site.xml
配置yarn.resourcemanager.hostname=RM运行的主机名
yarn.xxxx-auxservice=mapreduce_shuffle
③启动YARN
yarn-daemon.sh start resourcemanager | nodemanager
④查看
jps
http://rm所运行的主机名:8088
⑤提交作业
hadoop jar xxx.jar 主类名 输入目录.. 输出目录
要求: 输出目录必须不存在,输入目录中必须全部是文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号