

HDFS读写流程
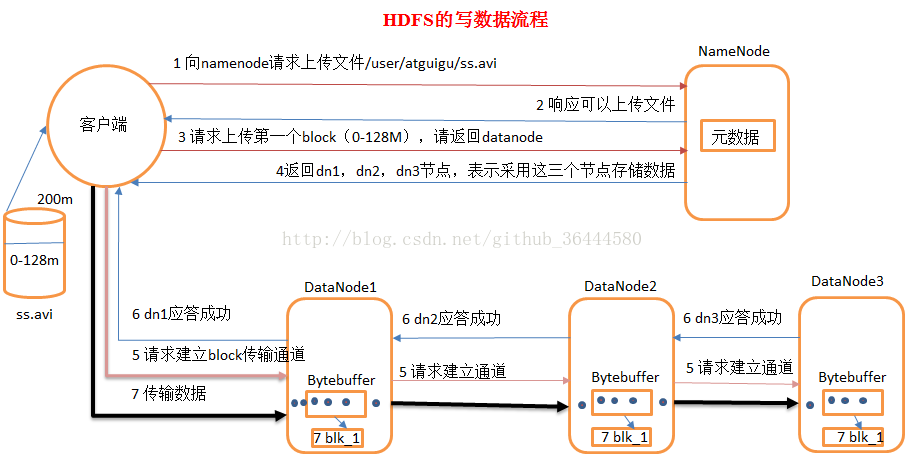
1、HDFS写流程
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本

1)跟NN通信请求上传文件,NN检查目标文件是否存在,父目录是否存在
2)NN返回是否可以上传
3)client会先对文件进行切分,比如一个block块128M,文件300M就会被切分成3个块,两个128M,一个44M。请求第一个block该传输到哪些DN服务器上。
4)NN返回DN的服务器。
5)client请求一个台DN上传数据(RPC调用,建立pipeline),第一个DN收到请求会继续调用第二个DN,然后第二个调用第三个DN,将整个pipeline建立完成,逐级返回客户端。
6)client开始传输block(先从磁盘读取数据存储到一个本地内存缓存),以packet为单位(一个packet为64kb),写入数据的时候datanode会进行数据校验,并不是通过packet为单位校验,而是以chunk为单位校验(512byte),第一个DN收到第一个packet就会传给第二台,第二台传给第三台;第一台每传一个packet就会放入一个应答队列等待应答。
7)当一个block传输完成时,client再次请求NN上传第二个block的服务器。
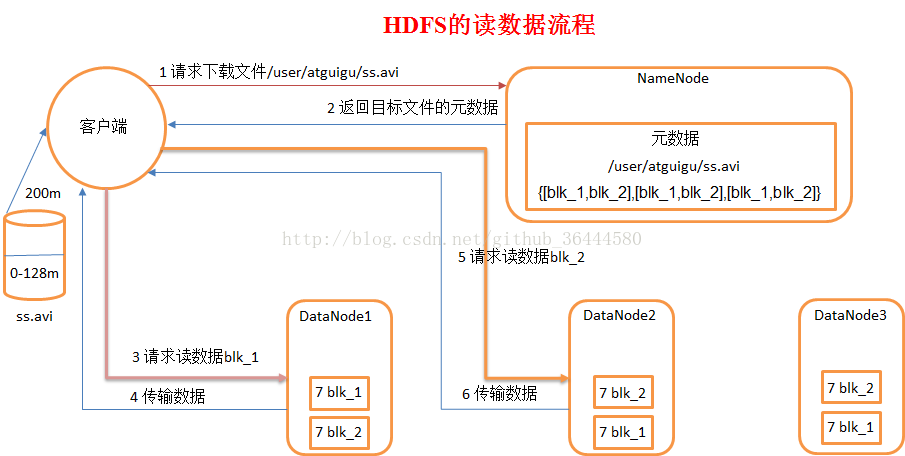
2、HDFS读流程
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件

1)跟NN通信查询元数据(block所在的DN的节点),找到文件块所在的DN的服务器。
2)挑选一台DN(就近原则,然后随机)服务器,请求建立socket流。
3)DN开始发送数据(从磁盘里读取数据放入流,一packet为单位做校验)
4)客户端以packet为单位接收,现在本地缓存,然后写入目标文件中,后面的block块就相当于append到前面的block块,最后合成最终需要的文件。
原文地址:https://www.cnblogs.com/jnba/p/10550394.html
HDFS中的block、packet、chunk
介绍HDFS读写流程上来就直接从文件分块开始,其实,要把读写过程细节搞明白前,了解block、packet与chunk。下面分别讲述。
-
block
这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。 -
packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。 -
chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
例如,在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
原文地址: https://blog.csdn.net/qq_38202756/article/details/82262453
