
2(MapReduce)
思想:分而治之
一,执行流程
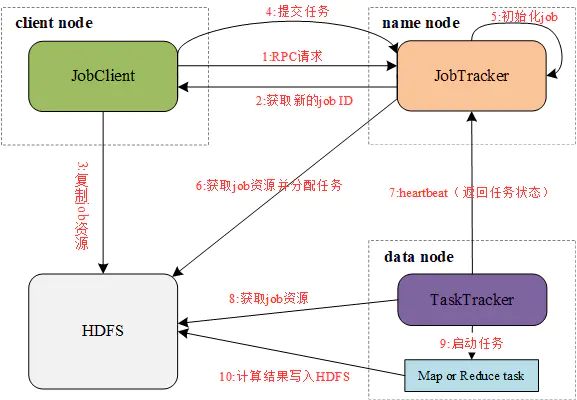
由图我们可以看到, MapReduce存在以下4个独立的实体。
- JobClient:运行于client node,负责将MapReduce程序打成Jar包存储到HDFS,并把Jar包的路径提交到Jobtracker,由Jobtracker进行任务的分配和监控。
- JobTracker:运行于name node,负责接收JobClient提交的Job,调度Job的每一个子task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
- TaskTracker:运行于data node,负责主动与JobTracker通信,接收作业,并直接执行每一个任务。
- HDFS:用来与其它实体间共享作业文件。
各实体间通过以下过程完成一次MapReduce作业:
- JobClient通过RPC协议向JobTracker请求一个新应用的ID,用于MapReduce作业的ID
- JobTracker检查作业的输出说明。例如,如果没有指定输出目录或目录已存在,作业就不提交,错误抛回给JobClient,否则,返回新的作业ID给JobClient
- JobClient将作业所需的资源(包括作业JAR文件、配置文件和计算所得得输入分片)复制到以作业ID命名的HDFS文件夹中
- JobClient通过submitApplication()提交作业
- JobTracker收到调用它的submitApplication()消息后,进行任务初始化
- JobTracker读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个TaskTracker
- TaskTracker通过心跳机制领取任务(任务的描述信息)
- TaskTracker读取HDFS上的作业资源(JAR包、配置文件等)
- TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask)
- TaskTracker将Reduce结果写入到HDFS当中
二,工作原理
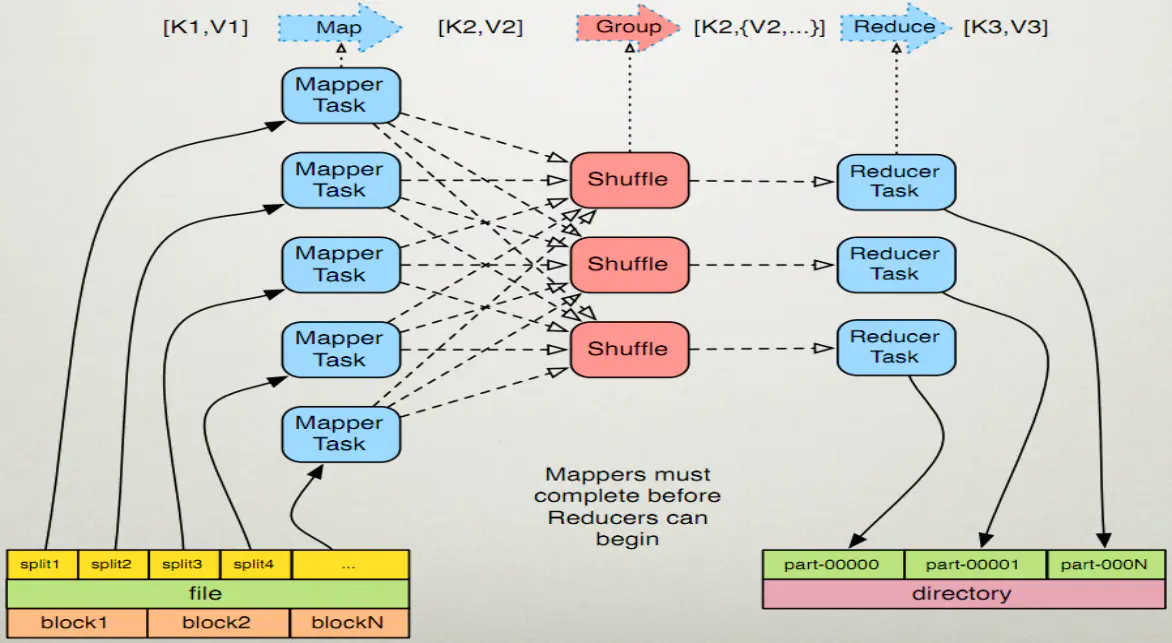
Map任务处理
- 需要对输入文件进行“分片”,也就是把所要输入的文件copy到HDFS中
- 启动job读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数
- 重写map(),对第一步产生的<k,v>进行处理,转换为新的<k,v>输出
- 对输出的key、value进行分区
- 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中
- (可选) 对分组后的数据进行归约
Reduce任务处理
- 进入reduce阶段。相同的key的map输出会到达同一个reducer,reducer对key相同的多个value进行“reduce操作”
- 多个map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点上
- 对多个map的输出进行合并、排序。
- 重写reduce函数实现自己的逻辑,对输入的key、value处理,转换成新的key、value输出
- 把reduce的输出保存到文件中
Map-Reduce框架的运作完全基于<key,value>对,即数据的输入是一批<key,value>对,生成的结果也是一批<key,value>对,只是有时候它们的类型不一样而已。Key和value的类由于需要支持被序列化(serialize)操作,所以它们必须要实现Writable接口,而且key的类还必须实现WritableComparable接口,使得可以让框架对数据集的执行排序操作。
Map:<k1,v1> ->list<k2,v2>
Reduce:<k2,list<v2>> -><k3,v3>
一个Map-Reduce任务的执行过程以及数据输入输出的类型如下所示:
(input)<k1,v1> -> map -> <k2,v2> -> combine -> <k2,v2> -> reduce -> <k3,v3>(output)
原文链接:https://www.jianshu.com/p/ca165beb305b

 浙公网安备 33010602011771号
浙公网安备 33010602011771号