

1(HDFS)
一,HDFS特点
优点:
(1)高容错性:数据自动保存多个副本;副本丢失后,自动恢复;
(2)适合批处理:移动计算而非数据;数据位置暴露给计算框架(Block偏移量);
(3)适合大数据处理:GB 、TB 、甚至PB 级数据;百万规模以上的文件数量;10K+ 节点;
(4)可构建在廉价机器上:通过多副本提高可靠性;提供了容错和恢复机制;
缺点:
(1)低延迟数据访问:反应慢
(2)小文件存取:占用NameNode 大量内存;寻道时间超过读取时间
(3)并发写入、文件随机修改:一个文件只能有一个写者;仅支持append
二,存储模型
(1)文件被线性切割成块Block,每个块都有它的偏移量offset(byte),Block分散存储在集群节点中。
(2)单一文件的Block大小一致,文件与文件的Block大小可以不一致。
(3)Block可以设置副本数,副本分散在不同节点中。副本不能超过节点数量。
(4)已上传的文件的Block副本数可以调整,大小不变。block默认128M,最小1M。
(5)只支持一次写入多次读取,但是可以用append追加数据。
三,架构模型
(1)主从架构
(2)NameNode节点保存文件的元数据(单节点),DateNode保存文件Block数据(多节点)
元数据:文件描述信息
(3)DateNode与NameNode保持心跳,提交Block列表(datanode主动汇报)
(4)HdfsClient与NameNode交互元数据信息,获取元数据信息,找到数据所在datanode,客户端直接去和datanode交互
(5)HdfsClient与DateNode交互文件Block数据(防止namenode单节点瓶颈)
(6)(大数据相关的都是C/S架构,web开发B/S架构)
四,角色
NameNode(NN)
(1)基于内存存储
- 不会和磁盘发生交换
- 只存在内存中
- 持久化(单向)
内存掉电易失,通过快照(fsimage)+日志文件(edits)实现持久化。快照只能是定时记录,容易丢失部分数据,所以要结合日志文件。掉电后,上电时先把快照加载到 内存,然后增量执行日志
(2)NameNode主要功能
- 接受客户端的读写服务
- 收集DateNode汇报的Block列表信息
(3)NameNode保存的metadata(元数据)信息
- 文件overship和permissions
- 文件大小、时间
- Block列表:Block偏移量
Block每个副本的位置(由DateNode上报,NameNode不保存)
DateNode(DN)
(1)本地磁盘目录存储数据(Block),文件形式。同时存储块的md5(校验文件完整性)
(2)启动DN时会向NN汇报Block信息
(3)通过向NN发送心跳保持与其联系(3s一次),如果NN10分钟没有收到DN心跳,则认为其已经lost,并copy其上的Block到其他DN
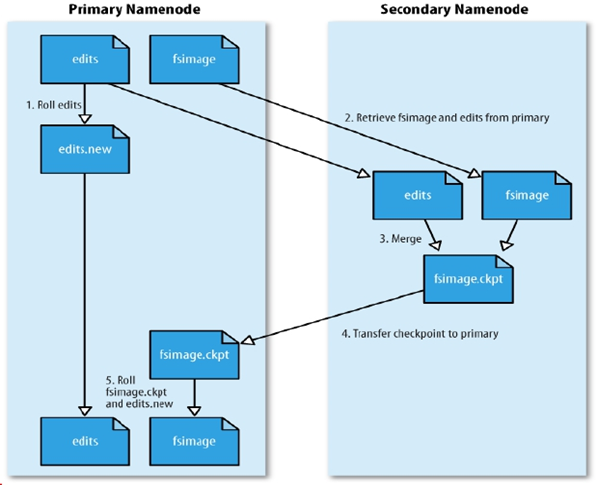
SecondaryNameNode(SNN)(1.x版本)
(1)它不是NN的备份(但可以做备份),它的主要工作是帮助NN合并edits log,减少NN启动时间。
(2)SNN在不停的做执行合并操作,只要满足以下下条件
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
- 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB
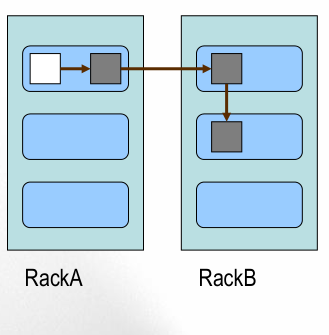
五,放置策略
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的 机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点
六,hadoop读、写流程
HDFS写流程
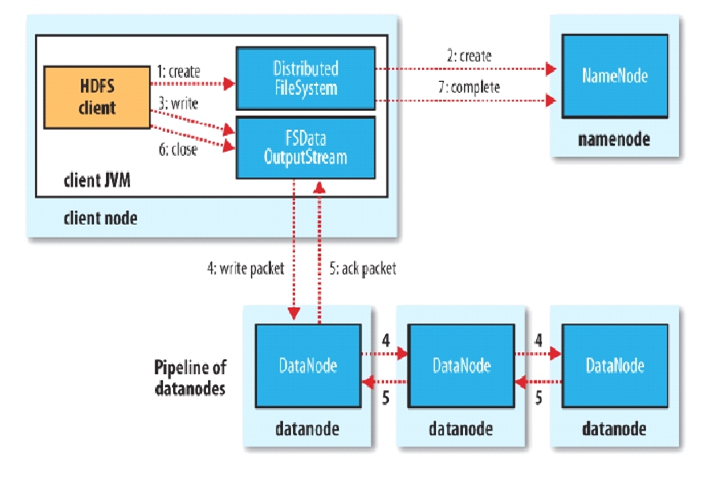
(1)客户端和NameNode请求块的3个位置
(2)NameNode根据副本存放规则返回3个位置
(3)客户端根据3个位置做pipeline,以更小的包做流式传输
更小的包:把一个块切分成更小的块逐个传输
流式:第一个小块传输到DN1后,第二个小块继续向DN1传输的同时,DN1上一个小块就可以同步进行副本传输到DN2,实现了时间上的并行传输
(4)第一个块传完后线性处理第二个块
(5)节点各自心跳汇报,时间也重叠,块的副本数对客户端透明,传输时间约等于一个文件的传输时间,不会因为副本数增加
HDFS读流程
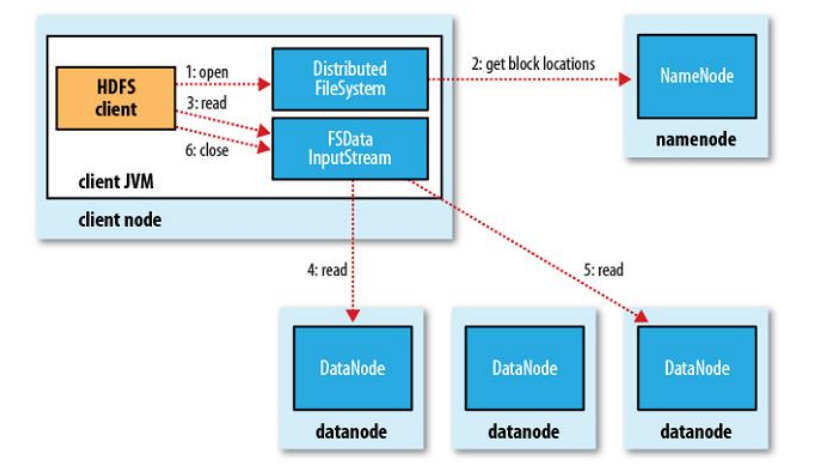
(1)和NN获取一部分Block副本位置列表
(2)线性和DN获取Block,最终合并为一个文件
(3)在Block副本列表中按距离择优选取
(4)MD5验证数据完整性
七,HDFS高可用
HDFS 2.x
1、解决HDFS 1.0中单点故障和内存受限问题。
2、解决单点故障
- HDFS HA:通过主备NameNode解决
- 如果主NameNode发生故障,则切换到备NameNode上
3、解决内存受限问题
- HDFS Federation(联邦)
- 水平扩展,支持多个NameNode;
- (2)每个NameNode分管一部分目录;
- (1)所有NameNode共享所有DataNode存储资源
4、2.x仅是架构上发生了变化,使用方式不变
5、对HDFS使用者透明
6、HDFS 1.x中的命令和API仍可以使用
HDFS 2.x HA
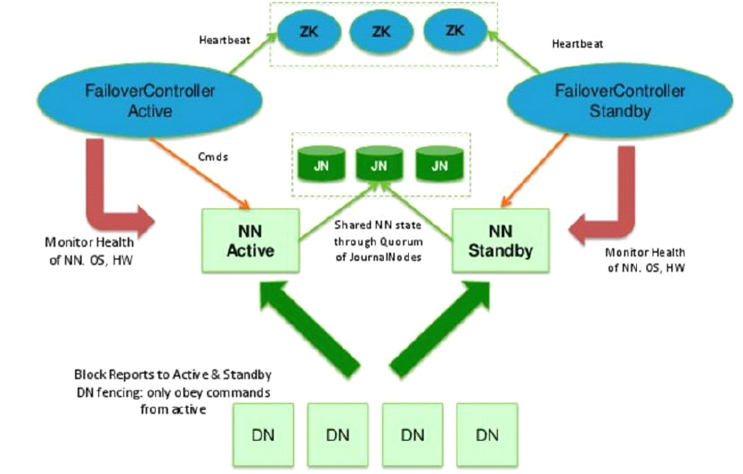
1、主备NameNode
2、解决单点故障(属性,位置)
- 主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
- 所有DataNode同时向两个NameNode汇报数据块信息(位置)
- JNN:集群(属性)
当Active Namenode执行了修改操作时,它会定期将执行的操作记录在editlog中,并写入JNN的多数节点中。而Standby Namenode会一直监听JNN上editlog的变化,如果发现editlog有改动,Standby Namenode就会读取editlog并与当前的合并。当发生了错误切换时,Standby节点会保证已经从JNN上读取了所有editlog并与之合并,然后才会从Standby状态切换为Active状态。通过这种机制,保证了Active Namenode与Standby Namenode之间命名空间状态的一致性,也就是第一关系链的一致性
- standby:备,完成了edits.log文件的合并产生新的image,推送回ANN
3、两种切换选择
- 手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
- 自动切换:基于Zookeeper实现
4、基于Zookeeper自动切换方案
- ZooKeeper Failover Controller:监控NameNode健康状态,进程分别在两个namenode所在的机器上
- 并向Zookeeper注册NameNode
- NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active
脑裂:在HA架构中有一个非常重非要的问题,就是需要保证同一时刻只有一个处于Active状态的Namenode,否则机会出现两个Namenode同时修改命名空间的问,也就是脑裂(Split-brain)。脑裂的HDFS集群很可能造成数据块的丢失,以及向Datanode下发错误的指令等异常情况。
