
读书笔记--(索引的扫描方式)
索引扫描识别
1、B树索引
组件:
- 根节点:只有一个根节点,位于树最顶端的分支节点。
- 分支节点:存储指针指向索引里其他的分支节点或叶子节点。
- 叶子节点:存储索引条目(包括索引条目头信息、索引键值长度、索引键值、rowid相关信息)直接指向表里的数据行。
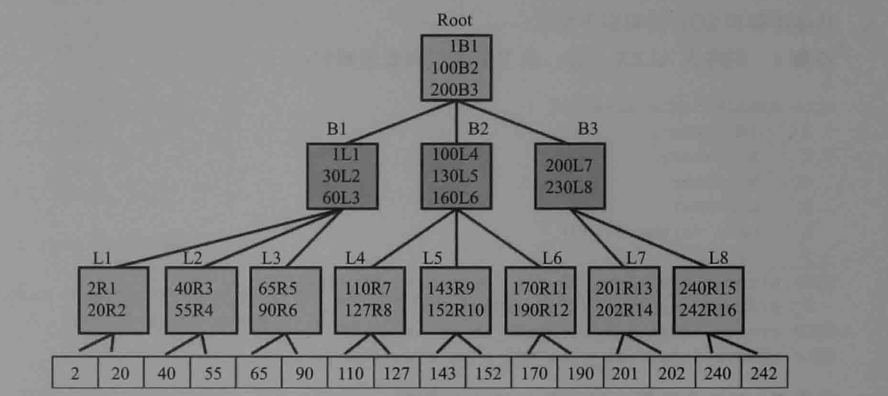
根据图,就分支节点块包含的索引条目都是按顺序排序的,每个索引条目都是由两个字段组成,第一个表示该分支节点块下所指向的叶子节点块的开始键值,第二个字段为指向叶子节点块地址的指针。本例中根节点包含三个指针,分别是(1 B1)、(100 B2)、(200 B3),他们指向三个分支节点块,1、100、200表示开始键值,B1、B2、B3表示指向三个分支节点块的地址。
对于叶子节点块包含的索引条目与分支节点一样,都是按顺序排的,每个索引条目也是2个字段,第一个表示索引的键值,单列索引就是一个值,复合索引就是多个值组合在一起,第二个字段表示该键值所对应的数据行的rowid。
当有新的键值插入时,索引会判断新键值的位置,将其插入,如果对应叶子节点满了,则会分裂出新的叶子节点块,分支节点块满了,同样会分列出新块。
2、全表扫描
全表扫描(FULL TABLE SCAN)就是查询整张表低于高水位的数据块。小表无所谓,大表将会导致很多非必要的数据块读取,造成过多的I/O开销
3、rowid扫描
rowid就是索引的页码,通过rowid查询记录是查询速度最快的方法,比任何索引扫描都快(索引检索的本质就是rowid扫描取数),因为:
索引扫描实质上可以分解为2个动作:
- 索引结构扫描,获取待返回数据行的rowid;
- 根据获取的rowid扫描表,获取对应数据行并返回;
4、索引唯一扫描
索引唯一扫描(INDEX UNIQUE SCAN)只能发生在唯一键索引(主键索引实质就是唯一键索引),通过唯一索引数值返回单个rowid,对应的查询结果也只返回一行。如果唯一索引是由多个列组成的组合索引,至少组合索引的前导列参与查询,sql语句只返回一行也属于索引唯一扫描。
索引唯一扫描是最高效的索引扫描方式,其只对唯一键上的等值查询有效。
--强制走索引 select /*+ index(table_name index_name)*/ * from table_name where ...
5、索引范围扫描
索引范围扫描(INDEX RANGE SCAN)是使用索引取多行数据,可以发生在唯一键上,也可以发生在非唯一键索引上。
索引范围扫描发生情况:
- 在唯一索引列上使用了范围操作符(>、<、<>、>=、<=、between,即不等值查询)
- 对非唯一索引列上进行查询。
--强制走索引 select /*+ index_rs(table_name index_name)*/ * from table_name where ...
当发生索引范围扫描时,对索引列有一个自动排序的操作,默认是正序操作。
例如:select * from table where name='100';等价于 select * from table where name='100' order by name desc;
索引范围扫描是一种最常见的扫描方式,做优化时尽可能使用的一种方式。
6、索引全扫描
对表来说有全表扫描,同样也存在索引全扫描(INDEX FULL SCAN),它将扫描索引全部节点和条目,再选择对应数据进行排序输出,索引全扫描只在CBO下有效。CBO根据统计数值得知进行索引全扫描比进行全表扫描更有效,才进行索引全扫描,而且此时查询出的数据必须从索引中直接得到。
索引全扫描情况:
- 表和表进行排序合并联立(Sort-Merge Join)查询时,排序的列必须是存在于索引中的;
- 查询中有order by 和group by子句的时候,子句中所有的列是必须存在于索引中的。
简单例子:select * from table order by id;--id列有主键,会走索引全扫描
--强制走索引 select /*+ index_fs(table_name index_name)*/ * from table_name where ...
与全表扫描相比,索引全扫描优势:
- 全表扫描不进行排序,必须将数据全部取出后,再进行排序输出,其扫描目标表高水位下所有数据块,包括没有必要的空块。
- 因为索引的本身结构就是个有序结构,索引全扫描在遍历索引的同时就已经完成了排序操作,输出结果时不需要排序,再者通过rowid获取行数据,避免了空块读取。
索引全扫描过程是单块读取其不支持多块并行的读取,其输出结果是有序排列的。
7、索引快速全扫描
索引快速全扫描(Index Fast Full Scan)和索引全扫描很相似,主要区别是,索引快速全扫描不需要排序,数据不是已排序方式返回。这种存取方法中,可以使用并行查询,以获得最大吞吐量并缩短执行时间。
例如:当取count(*)时不关心排序,只需要统计叶子节点上的索引条目数量就可以返回结果。索引快速全扫描就是非常好的选择。
--强制走索引 select /*+ index_ffs(table_name index_name)*/ * from table_name where ...
索引全扫描和快速全扫描区别:
| 扫描方式 | 输出排序 | 取数效率 |
| 索引全扫描 | 有序输出,无需额外排序 | 单块读,不支持并行 |
| 索引快速扫描 | 无序输出,需要额外排序 | 支持并行多块读 |
索引快速全扫描是一种比较高效的扫描方式,在优化过程中可以尽量使用。
8、索引跳跃扫描
索引跳跃扫描(index skip scan) 是oracle 9i引进的新特性,发生在符合索引上,如果where子句只包含索引中的部分列,且这些列不是索引的第一列,就可能发生index skip scan。如果查询时第一列没有被指定就跳过他。
index skip scan 需要CBO,并且对表进行分析后,还需要保证第一列的distinct值非常小。oracle 会对复合索引进行逻辑划分,分为多个子索引,可以理解为索引从逻辑上被划分为第一列distinct值数量的子索引,每次对一个子索引进行扫描。
如果复合索引的首列distinct值很多,那么复合索引拆分逻辑子索引的本身动作就很大的开销,查询过程会扫描子索引,也会增加开销,相比之下CBO会选择全表扫描
--强制走索引 select /*+ index_ss(table_name index_name)*/ * from table_name where ...
在复合索引的设计中,尽可能选择区分度较大的列作为前导列,如果为了使用index skip scan这个索引扫描方式而选择区分度极低的列作前导列,就是本末倒置了。
8、索引组合扫描(index_combine)
9、索引联立扫描(index_join)
严格意义上讲,index_combine和index_join都不能算是一种独立的扫描方式他们是对五种扫描方式的优化和补充,使其获得更好的性能优势。
应用技巧:如果索引的结构设计比较合理,则能在索引扫描过程中完成取数操作,尽量在索引扫描过程中完成,避免回表取数的开销,这个技巧叫做索引覆盖应用(index covering),它覆盖了查询的所有字段(select ,where,order by ,group by ),用来提高查询效率。
如果统计信息和直方图收集的准确的话,是不需要我们使用hint 优化的CBO计算的更准。如果不能确定统计信息准确性就考虑实际情况,业务场景,实际执行时间等优化方案。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步