Spark01-集群配置和代码编写入门
每天进度一总结,月底打满二十天。
Spark的集群配置与启动
在已有的Hadoop集群上安装spark集群,需要注意两者的版本对应问题。本人Hadoop为2.7.7,Spark为2.4.7,Scala为2.11.8,Java为1.8。
将下载好的spark解压到自己指定的目录,然后进行如下配置。
1、修改spark配置文件
进入spark的conf目录下, 这里是spark所有的配置文件目录。
(1)配置spark-env.sh
使用命令,复制并重命名配置文件: cp spark-env.sh.template spark-env.sh
然后修改配置文件信息:vi spark-env.sh
并添加如下信息。
# 指定 JAVA Home export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64 # 指定 Spark Master 地址 export SPARK_MASTER_HOST=bigdata1 export SPARK_MASTER_PORT=7077
(2)配置slaves
使用命令,复制并重命名配置文件: cp slaves.template slaves
然后修改配置文件信息:vi slaves,并添加如下信息。
# 指定bigdata1既是主节点也是从节点,若不想可以删除该行。 bigdata1 bigdata2 bigdata3
(3)其他配置
做完以上两步spark就可以启动了,若想优化性能可作如下配置:
① HistoryServer 的配置
② 高可用配置:利用zookeeper做的高可用
2、集群启动
进入spark 的sbin目录,使用命令 start-all.sh 或 stop-all.sh 启动或关闭集群。
Spark程序执行
1、通过spark shell执行
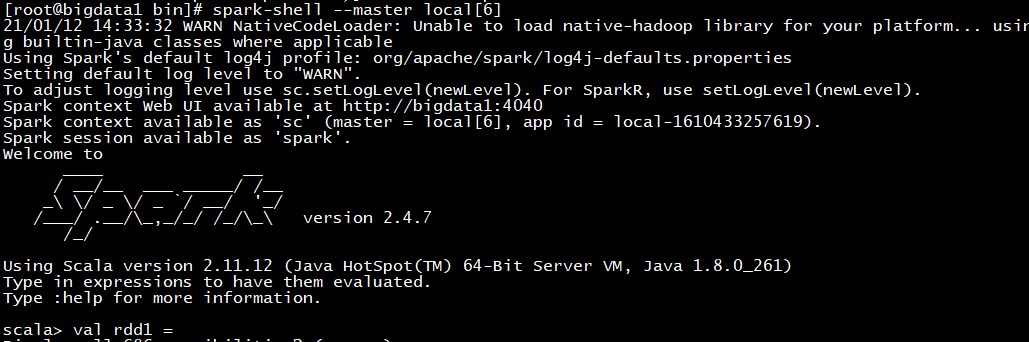
在spark的bin目录下执行 : spark-shell --master local[6]
进入到spark的默认命令行交互模式,即Scala交互。
2、通过独立应用
主要是通过IDEA编写代码然后在spark上运行的。
我们可以在IDEA创建maven工程,添加依赖以支持Scala代码的编写,pom.xml 依赖如下:


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.thorine</groupId> <artifactId>ScalaSparkMavenProject</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <!-- 版本信息 --> <scala.version>2.11.8</scala.version> <spark.version>2.4.7</spark.version> <slf4j.version>1.7.16</slf4j.version> <log4j.version>1.2.17</log4j.version> </properties> <dependencies> <!-- Scala依赖 --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <!-- Spark依赖 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <!-- Hadoop依赖 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.7</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>jcl-over-slf4j</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version> </dependency> </dependencies> <build> <!-- scala代码文件和测试代码文件的依赖,需要手动在项目目录中创建 --> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <!-- scala的依赖插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.0</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.1.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugin.shade.resource.ManifestResourceTransformer"> <mainClass></mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
然后在自己创建的scala代码根目录中创建scala类,实现scala代码编程。
代码演示,单词统计,需要提前创建单词文件,并在代码中修改路径。
package rdd import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { // 1、创建 Spark Context val conf = new SparkConf().setMaster("local[6]").setAppName("word_count1") val sc = new SparkContext(conf) // 2、加载文件 val rdd1 = sc.textFile("dataset/wordcount.txt") // 3、处理 // (1) 把整句话拆分为多个单词 val rdd2 = rdd1.flatMap(item => item.split(" ")) // (2) 把每个单词指定一个词频 1 val rdd3 = rdd2.map(item => (item, 1)) // (3) 聚合 val rdd4 = rdd3.reduceByKey((curr, agg) => curr + agg) // 4、得到结果 val result = rdd4.collect() println("打印结果:" + result) result.foreach( item => println(item)) } }
即可在IDEA中运行。
为了在spark集群上运行,我们将单词文件上传hdfs,然后稍微改动上述代码如下:
package rdd import org.apache.spark.{SparkConf, SparkContext} object WordCount_hdfs { def main(args: Array[String]): Unit = { // 1、创建 Spark Context val conf = new SparkConf().setAppName("word_count1") // 去掉 .setMaster("local[6]") val sc = new SparkContext(conf) // 2、加载文件 val rdd1 = sc.textFile("hdfs://bigdata1:8020/dongao1/wordcount.txt") // 3、处理 // (1) 把整句话拆分为多个单词 val rdd2 = rdd1.flatMap(item => item.split(" ")) // (2) 把每个单词指定一个词频 1 val rdd3 = rdd2.map(item => (item, 1)) // (3) 聚合 val rdd4 = rdd3.reduceByKey((curr, agg) => curr + agg) // 4、得到结果 val result = rdd4.collect() println("打印结果:" + result) result.foreach( item => println(item)) } }
然后利用maven打成jar包,上传至spark目录,然后执行如下命令:
bin/spark-submit --class rdd.WordCount_hdfs --master spark://bigdata1:7077 ScalaSparkMavenProject-1.0-SNAPSHOT.jar
成功。
遇到的错误
1、 Exception in thread "main" java.lang.NoClassDefFoundError: scala/Product$class
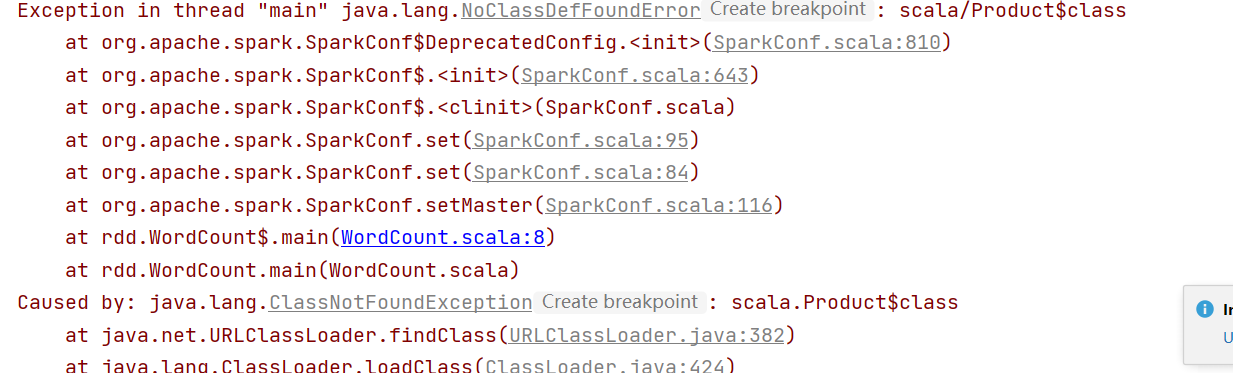
是scala的版本不对,应该使用2.11.x

 浙公网安备 33010602011771号
浙公网安备 33010602011771号