E-LSTM-D: 一个动态网络链接预测的深度学习框架
一、介绍
处理动态链路预测的主要问题:非线性问题、分析网络演化的能力
端到端编码器-LSTM-解码器(E-LSTM-D):
- 该模型可以有效地处理高维、非线性、稀疏等问题。
- 编解码器体系结构自动学习网络的表示。
- 堆叠的LSTM模块提高了学习时间特征的能力。
贡献:
- 我们新提出的E-LSTM-D模型能够在性能略有下降的情况下进行长期预测任务;它通过对模型结构进行微调,即改变不同层中的单元数,适合不同尺度的网络;此外,它还可以预测即将出现或消失的链路,而现有的大多数方法只关注前者。
- 我们定义了一种新的度量误差率来度量动态网络链路预测的性能,这是ROC曲线(AUC)下面积的一个很好的补充,使评估更加全面。
二、方法
1 E-LSTM-D 模型
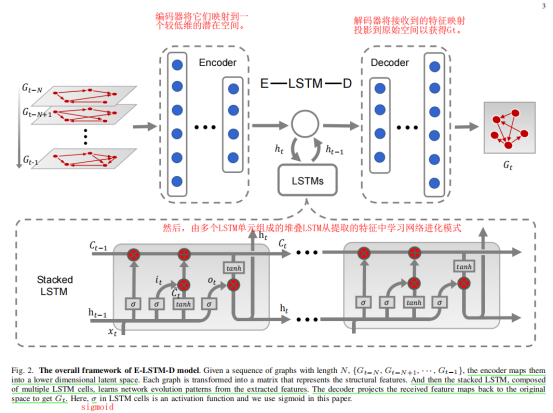
具体而言,编码器被放置在模型的入口处,以学习高度非线性的网络结构,解码器将提取的特征转换回原始空间。这种编解码器结构能够处理空间非线性和稀疏性,而编码器和解码器之间的叠加LSTM可以学习时间依赖关系。

1.1 Encoder-Decoder 结构
自动编码器可以无监督地学习数据的表示,编码器被放置在模型的入口处,以学习高度非线性的网络结构 ,解码器将提取的特征转换回原始空间(固定形状的矩阵)。然而,在这里,整个过程是监督的,这与自动编码器不同,因为我们标记了数据(At)来引导解码器构建能够更好地拟合目标分布的矩阵。 特别是,由多个非线性感知组成的编码器将高维图形数据投影到一个相对较低的维数向量空间中。 因此,得到的向量可以表征网络中顶点的局部结构。 这个过程可以定性为:

Si是表示输入序列S中的第i个图。对于输入序列,每个编码器层分别处理每个项,然后按时间顺序连接所有激活项。用RLU作为激活函数加速编解码器的收敛。
具有编码器镜像结构的解码器接收潜在特征,并在At的监督下将其映射到重建空间中:
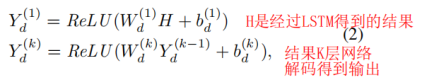
H是由叠加的LSTM生成的,它表示目标快照的特征,而不是编码器中以前使用的所有快照的特征序列。另一个区别是解码器的最后一层,或输出层,使用sigmoid作为激活函数,而不是ReLU。而输出层的单位数总是等于节点数。
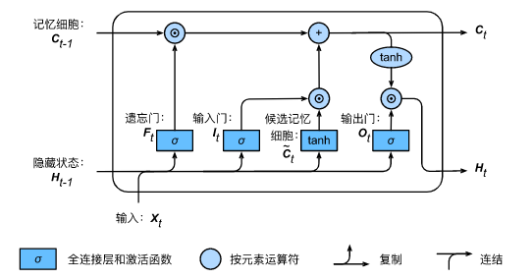
1.2 Stacked LSTM
虽然编码解码器体系结构可以处理高非线性,但它不能捕捉时变特性。LSTM,[33],作为一种特殊的递归神经网络(RNN)[34],[35],可以学习长期的依赖关系,并在这里介绍来解决这个问题。一个LSTM由三个门组成,即一个忘记门、一个输入门和一个输出门。
论文中提的公式:
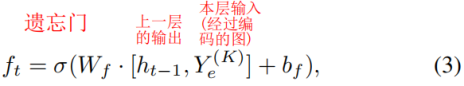
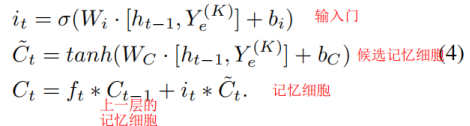
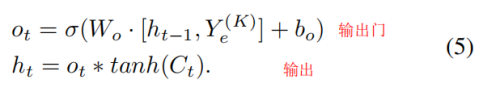
入口处的编码器可以降低每个图的维数,从而保持堆叠LSTM的计算在合理的成本。 而有利于处理时间和顺序数据的叠加LSTM反过来对编码器也是一个补充。
2 平衡训练过程
稀疏性问题:
在At中,零元素比非零元素多得多,使得解码器对重构零元素具有吸引力。为了解决这个稀疏性问题,我们应该更多地关注那些现有的链接,而不是在反向传播中不存在的链接。我们将一个新的损失函数定义为:
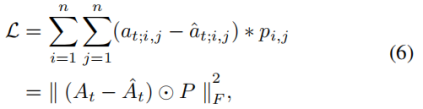
☉代表Hadamard product(哈达玛积(Hadamard product)是矩阵的一类运算,若A=(aij)和B=(bij)是两个同阶矩阵,若cij=aij×bij,则称矩阵C=(cij)为A和B的哈达玛积,或称基本积 [1] 。)矩阵乘法,对每个训练过程,如果at;ij=0,则pij=1,否则的话pij=β>1。这种惩罚矩阵对非零元素施加更多的惩罚,使模型在一定程度上避免了过拟合。
防止过拟合:
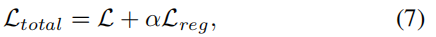
其中Lreg,定义在等式中。(8),是一个L2正则化器,以防止模型过拟合,α是一个权衡参数。
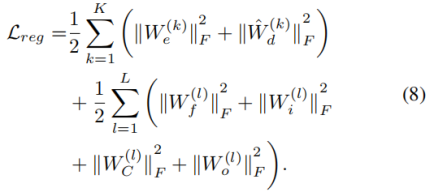
A中的每个元素的值为0或1。然而,输出数据并不是单热编码的。它们是小数,理论上可以向无穷大或向相反的方向移动。为了得到一个有效的邻接矩阵,我们在输出层施加一个sigmoid函数,然后将这些值修改为0和1,以0.5为分界点。也就是aij>0.5代表有链接,否则就是没有。为了优化该模型,我们应首先进行正向传播以获得损失,然后进行反向传播以更新所有参数。特别是,关键操作是计算偏导数。

