图神经网络七日打卡营
1、图与图学习
1)图的两个基本元素是点和边,是一种统一描述复杂事务的语言,常见的图有社交网络、推荐系统、化学分子结构。
2)图学习: Graph Learning。深度学习中的一个子领域,强调处理的数据对象为图;与一般深度学习的区别:能够方便地处理不规则数据(树、图),同时也可以处理规则数据(如图像)。
3)图学习的应用:
- 节点级别任务:金融诈骗检测(典型的节点分类)、自动驾驶中的3D点云目标检测
- 边级别任务:推荐系统(典型的边预测)
- 图级别任务:气味识别(典型的图分类)、发现“宇宙”
4)图学习是怎么做的:
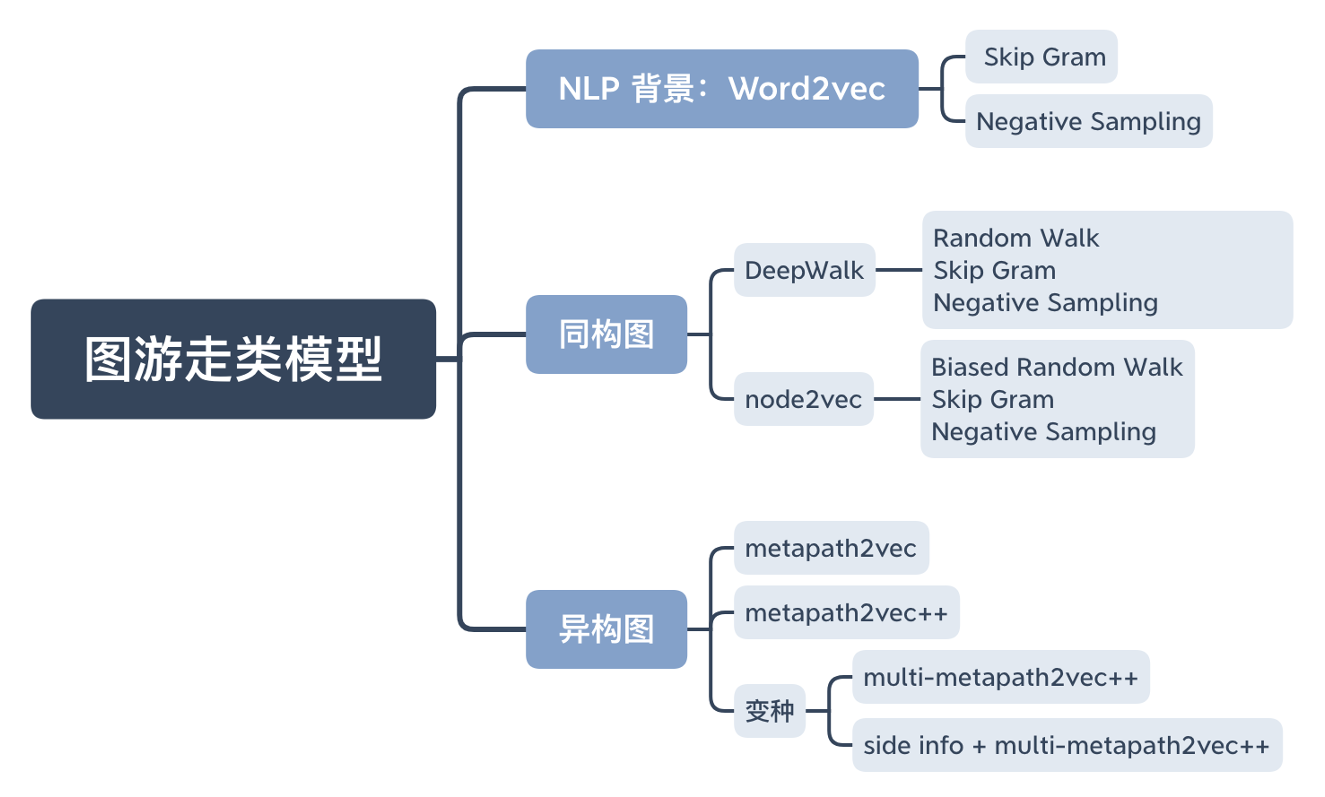
- 图游走类算法:通过在图上的游走,获得多个节点序列,再利用 Skip Gram 模型训练得到节点表示(下节课内容)
- 图神经网络算法:端到端模型,利用消息传递机制实现。
- 知识图谱嵌入算法:专门用于知识图谱的相关算法。
2、图游走类模型(得到节点表示(Node Embedding)用于下游任务)
1)DeepWalk采样算法

class UserDefGraph(Graph): def random_walk(self, nodes, walk_len): """ 输入:nodes - 当前节点id list (batch_size,) walk_len - 最大路径长度 int 输出:以当前节点为起点得到的路径 list (batch_size, walk_len) 用到的函数 1. self.successor(nodes) 描述:获取当前节点的下一个相邻节点id列表 输入:nodes - list (batch_size,) 输出:succ_nodes - list of list ((num_successors_i,) for i in range(batch_size)) 2. self.outdegree(nodes) 描述:获取当前节点的出度 输入:nodes - list (batch_size,) 输出:out_degrees - list (batch_size,) """ walks = [[node] for node in nodes] # 保存游走路径? walks_ids = np.arange(0, len(nodes)) # 有多少起始节点 cur_nodes = np.array(nodes) # 所有的起始节点 for l in range(walk_len): """选取有下一个节点的路径继续采样,否则结束""" outdegree = self.outdegree(cur_nodes) # 当前节点出度 walk_mask = (outdegree != 0) if not np.any(walk_mask): break cur_nodes = cur_nodes[walk_mask] walks_ids = walks_ids[walk_mask] outdegree = outdegree[walk_mask] ###################################### # 请在此补充代码采样出下一个节点 succ_nodes = self.successor(cur_nodes) sample_index = np.floor( np.random.rand(outdegree.shape[0]) * outdegree).astype("int64") next_nodes = [] for s, ind, walk_id in zip(succ_nodes, sample_index, walks_ids): walks[walk_id].append(s[ind]) next_nodes.append(s[ind]) ###################################### cur_nodes = np.array(next_nodes) return walks
2)Node2vec采样算法(DeepWalk的改进)


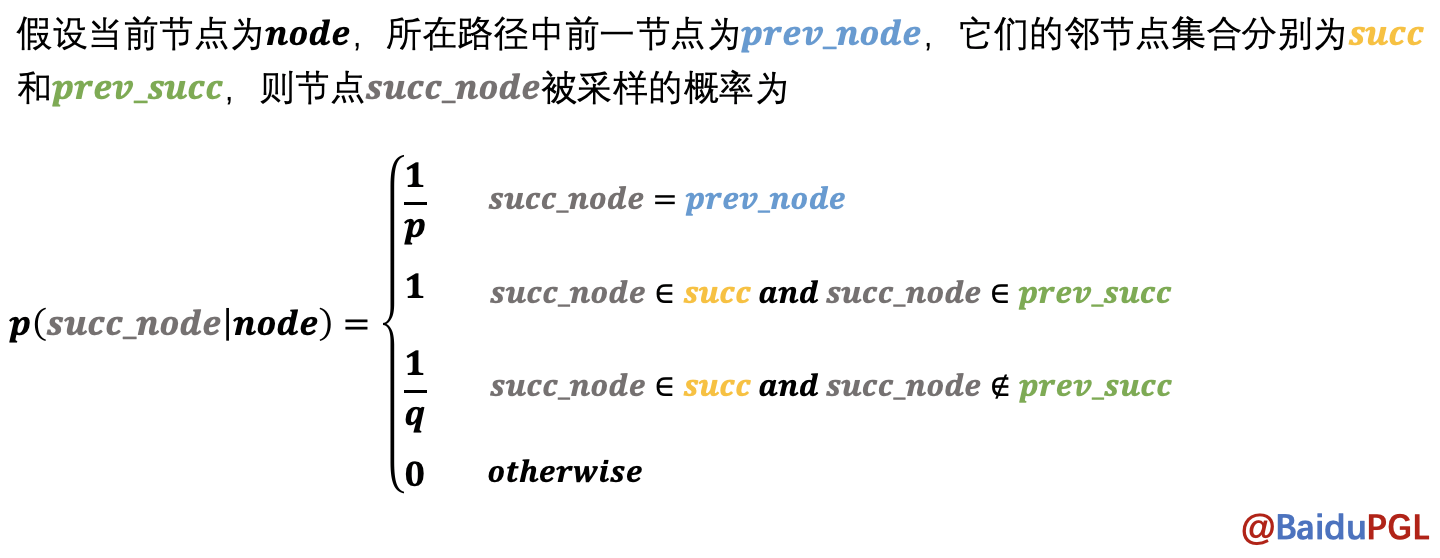
def node2vec_sample(succ, prev_succ, prev_node, p, q): """ 输入:succ - 当前节点的下一个相邻节点id列表 list (num_neighbors,) prev_succ - 前一个节点的下一个相邻节点id列表 list (num_neighbors,) prev_node - 前一个节点id int p - 控制回到上一节点的概率 float q - 控制偏向DFS还是BFS float 输出:下一个节点id int """ ################################## # 请在此实现node2vec的节点采样函数 succ_len = len(succ) prev_succ_len = len(prev_succ) probs=[] prob_sum = 0 prob = 0 prev_succ_set = np.asarray([]) for i in range(prev_succ_len): prev_succ_set= np.append(prev_succ_set, prev_succ[i]) for i in range(succ_len): if succ[i] == prev_node: prob = 1. / p elif np.where(prev_succ_set==succ[i]): prob = 1. elif np.where(prev_succ_set!=succ[i]): prob = 1. / q else: prob=0 probs.append(prob) prob_sum += prob RAND_MAX = 65535 rand_num = float(np.random.randint(0, RAND_MAX+1))/RAND_MAX*prob_sum sample_succ = 0 for i in range(succ_len): rand_num -= probs[i] if rand_num <= 0: sample_succ = succ[i] return sample_succ ################################## return sampled_succ
3、图神经网络算法(一)
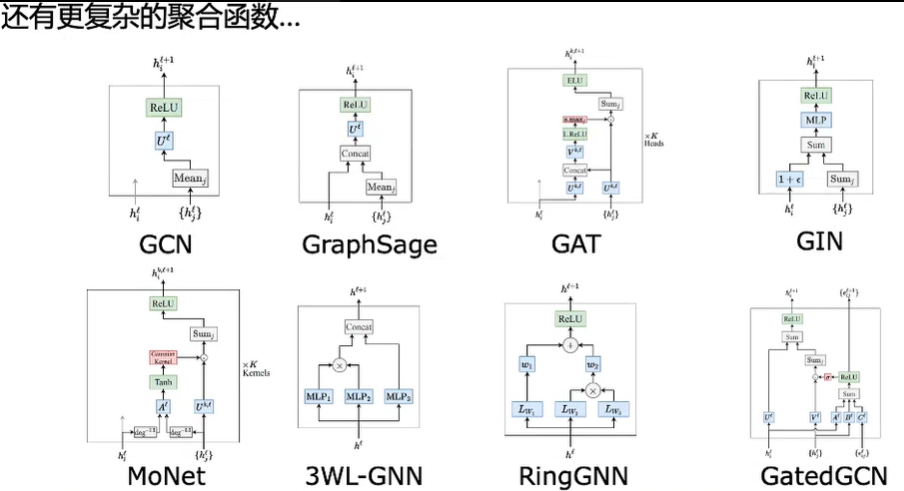
1)GCN



%%writefile userdef_gcn.py import paddle.fluid as fluid def gcn_layer(gw, feature, hidden_size, activation, name, norm=None): # send函数 def send_func(src_feat, dst_feat, edge_feat): ''' 请完成填空 提示: src_feat 为源节点特征 src_feat { "h": Tensor形状为 [边数目, hidden_size] } dst_feat 为目标节点特征 dst_feat { "h": Tensor形状为 [边数目, hidden_size] } 由于本题目没有边特征,edge_feat为 None ''' # 问题1:下列两个feature,我们选择哪个 ans1 = "A" # "A" or "B" if ans1 == "A": feat = src_feat["h"] elif ans1 == "B": feat = dst_feat["h"] return feat # recv函数 def recv_func(msg): ''' 请完成填空 提示: 1. 使用到的函数:fluid.layers.sequence_pool(x, pool_type) 2. 接受到的消息是一个变长Tensor,在Paddle里被称为LodTensor 例如: msg = [ [1, 2], # 节点0 接受的特征 [1], # 节点1 接受的特征 [2, 3, 4] # 节点2 接受的特征 ] 对于不定长Tensor,我们可以使用一系列的sequence操作。例如sequence_pool 例如: 对上述msg进行sequence_pool求和的操作, 我们会得到 msg = [ [3], # 节点0 接受的特征 [1], # 节点1 接受的特征 [9] # 节点2 接受的特征 ] ''' # 问题2:在 GCN里面,我们的 Recv 函数是 ans = "A" # "A" or "B" or "C" if ans == "A": return fluid.layers.sequence_pool(msg, "sum") elif ans == "B": return fluid.layers.sequence_pool(msg, "average") elif ans == "C": return fluid.layers.sequence_pool(msg, "max") # 消息传递机制执行过程 msg = gw.send(send_func, nfeat_list=[("h", feature)]) output = gw.recv(msg, recv_func) # 通过以activation为激活函数的全连接输出层 output = fluid.layers.fc(output, size=hidden_size, bias_attr=False, act=activation, name=name) return output
2)GAT


%%writefile demo_gat.py from pgl.utils import paddle_helper import paddle.fluid as fluid def single_head_gat(graph_wrapper, node_feature, hidden_size, name): # 实现单头GAT def send_func(src_feat, dst_feat, edge_feat): ################################## # 按照提示一步步理解代码吧,你只需要填###的地方 # 1. 将源节点特征与目标节点特征concat 起来,对应公式当中的 concat 符号,可能用到的 API: fluid.layers.concat Wh = fluid.layers.concat(input=[src_feat["Wh"], dst_feat["Wh"]], axis=-1) # 2. 将上述 Wh 结果通过全连接层,也就对应公式中的a^T alpha = fluid.layers.fc(Wh, size=1, name=name + "_alpha", bias_attr=False) # 3. 将计算好的 alpha 利用 LeakyReLU 函数激活,可能用到的 API: fluid.layers.leaky_relu alpha = fluid.layers.leaky_relu(alpha, 0.2) ################################## return {"alpha": alpha, "Wh": src_feat["Wh"]} def recv_func(msg): ################################## # 按照提示一步步理解代码吧,你只需要填###的地方 # 1. 对接收到的 logits 信息进行 softmax 操作,形成归一化分数,可能用到的 API: paddle_helper.sequence_softmax alpha = msg["alpha"] norm_alpha = paddle_helper.sequence_softmax(alpha) # 2. 对 msg["Wh"],也就是节点特征,用上述结果进行加权 output = norm_alpha * msg["Wh"] # 3. 对加权后的结果进行相加的邻居聚合,可能用到的API: fluid.layers.sequence_pool output = fluid.layers.sequence_pool(output, pool_type="sum") ################################## return output # 这一步,其实对应了求解公式当中的Whi, Whj,相当于对node feature加了一个全连接层 Wh = fluid.layers.fc(node_feature, hidden_size, bias_attr=False, name=name + "_hidden") # 消息传递机制执行过程 message = graph_wrapper.send(send_func, nfeat_list=[("Wh", Wh)]) output = graph_wrapper.recv(message, recv_func) output = fluid.layers.elu(output) return output def gat(graph_wrapper, node_feature, hidden_size): # 完整多头GAT # 这里配置多个头,每个头的输出concat在一起,构成多头GAT heads_output = [] # 可以调整头数 (8 head x 8 hidden_size)的效果较好 n_heads = 8 for head_no in range(n_heads): # 请完成单头的GAT的代码 single_output = single_head_gat(graph_wrapper, node_feature, hidden_size, name="head_%s" % (head_no) ) heads_output.append(single_output) output = fluid.layers.concat(heads_output, -1) return output
4、图神经网络算法二(图采样和邻居聚合)
1)GraphSAGE
使得模型能够以Mini-batch的方式进行训练
- 假设我们要利用中心节点的k阶邻居信息,则在聚合的时候,需要从第k阶邻居传递信息到k-1阶邻居,并依次传递到中心节点。
- 采样的过程刚好与此相反,在构造第t轮训练的Mini-batch时,我们从中心节点出发,在前序节点集合中采样Nt个邻居节点加入采样集合。
- 接着将邻居节点作为新的中心节点继续进行第t-1轮训练的节点采样,以此类推。
- 最后将采样到的节点和边一起构造得到子图。
2)PinSAGE
通过多次随机游走,按游走经过的频率选取邻居
3)邻居聚合
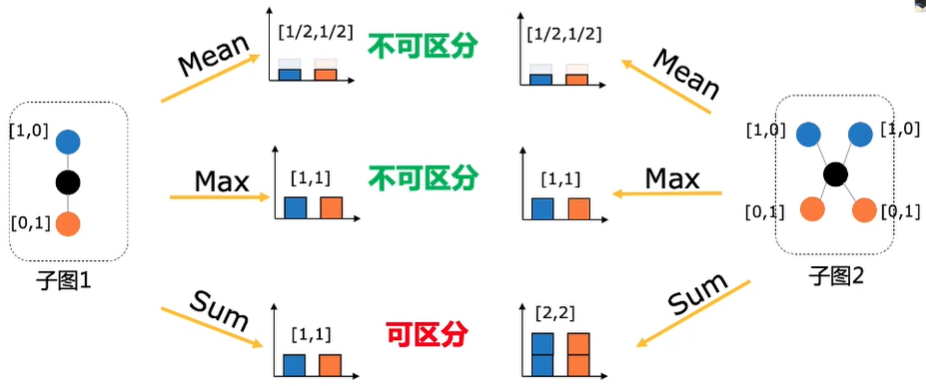
三种经典的聚合函数
- Mean 求平均
- Max 取最大
- Sum 求和
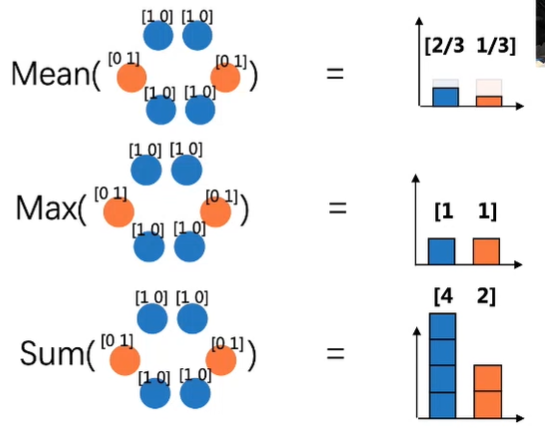
评估聚合表达能力的指标单射(一对一映射)
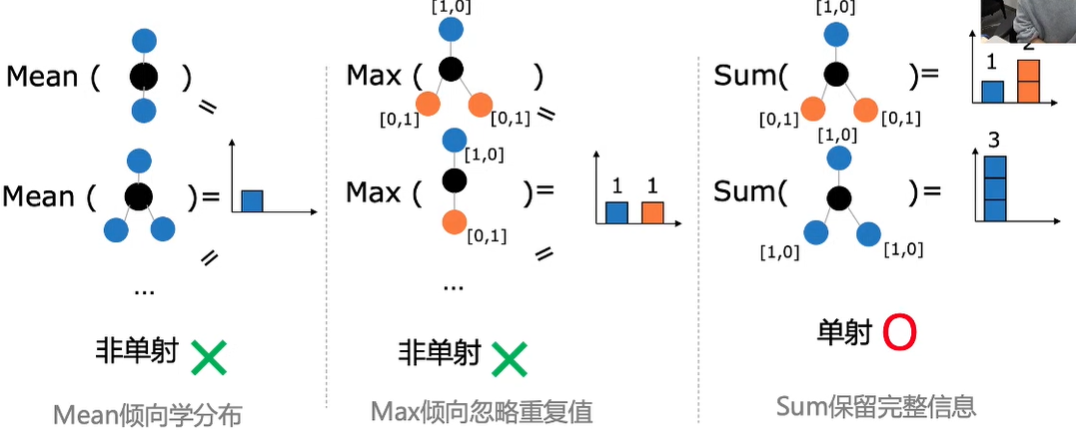
单射可以保证聚合后的结果可区分