动态网络中时间链路预测的一个高级的深度生成框架
An Advanced Deep Generative Framework for Temporal Link Prediction in Dynamic Networks
摘要:时间链路预测的主要挑战是捕捉动态网络的时空模式和高度非线性。受图像生成成功的启发,我们将动态网络转换为静态图像序列,并将时间链接预测表述为条件图像生成问题。为了有效地解决具有挑战性的时间链接预测问题,我们提出了一种新的深度生成框架NetworkGAN,它通过深度学习技术同时对动态网络中的空间和时间特征进行建模。提出的NetworkGAN算法继承了图卷积网络(GCN)、时间矩阵分解(TMF)、长短期记忆网络(LSTM)和生成对抗网络(GAN)的优点。具体来说,一个attentive GCN首先被设计成自动学习动态网络的空间特征。其次,我们提出了一个TMF增强的attentive LSTM (TMF-LSTM)来捕捉动态网络的时间依赖性和演化模式,它基于在先前时间戳观察到的网络快照来预测下一时间戳的网络快照。此外,我们使用了一个GAN框架来进一步改进时间链接预测的性能,通过使用一个鉴别模型来指导在一个对抗过程中的深度生成模型(即TMFLSTM)的训练。为了验证模型的有效性,我们在五个真实数据集上进行了大量的实验。实验结果表明,与其他强有力的竞争对手相比,该网络具有显著的优势。
关键词:深度生成模型、生成对抗网络、时间链接预测 (Deep generative model, generative adversarial network (GAN), temporal link prediction.)
1、介绍
通过最先进的时间链路预测方法存在以下(缺点 提出缺点是为了进行改进)改进的地方:
(1)、因此,非常希望探索动态网络的多个非线性变换的组合,以提高时间链路预测的性能。(以往的许多方法都是基于典型的线性模型,无法应对动态网络的高度非线性和复杂性。)
(2)、因此,充分利用空间和时间特征,从动态网络的角度预测链路是至关重要的(通过深度信念网络(DBN) [11]在每个时间戳探索静态网络的空间特征,或者通过递归神经网络(RNN)在时变动态网络上建模网络演化模式)
(3)、因此,它促使我们提出了一个联合模型,该模型利用了动态网络的全局和局部特征,同时受益于基于矩阵分解的方法和基于深度学习的方法(大多数基于深度学习的方法[例如,长期短期记忆网络(LSTM)]不能学习整个动态轮廓,而仅仅是捕捉动态网络的短期依赖性。)
(4)、因此,时间链路预测方法不仅要预测链路的存在,还要考虑链路权重,这是一个更具挑战性的问题(基于深度学习的方法仅适用于未加权的网络,但是权重非常重要)
为了缓解上述局限性,我们提出了一种先进的深度生成框架(NetworkGAN),用于动态网络中的时间链路预测,该框架通过深度学习技术同时捕捉动态网络中的非线性时空特征。NetworkGAN结合了深度生成网络和TMF模型的优势,以增强网络表示学习,并在下一个时间戳生成高质量的网络拓扑。(首先,为了从每个时间戳的网络快照中捕获空间特征,我们利用了注意力图卷积网络(GCN),该网络已被证明是一种建模网络中节点的深层非线性特征的强大技术,以编码每个时间戳的网络的结构特征。每个时间戳的网络。其次,我们采用了TMF增强的注意力LSTM (TMF-LSTM)模型,该模型采用了注意力GCN学习的一系列网络表示,并预测下一个时间戳中的网络快照,以捕捉具有多个连续时间间隔的时变网络的时间特征和演化模式。第三,由于在生成过程中很难利用线性单元的优势,生成对抗网络(GAN) [14]被应用于通过使用区分模型来指导在对抗过程中深度生成模型(即TMFLSTM)的训练来细化时间链接预测的性能。在对抗式学习中,生成模型G被训练为通过TMF-LSTM网络基于先前观察到的顺序网络快照来预测下一个时间戳中的网络拓扑。同时,还训练了一个判别模型D来判别生成的网络快照和训练数据中的真实网络快照。生成器和鉴别器通过一个极小极大两人游戏进行了优化。因此,这种对抗过程最终可以调整G以产生高质量的网络拓扑。)
本文主要贡献概括如下:
- 1)我们引入了GCN、TMF和LSTM相结合的时间链预测框架,该框架综合考虑了动态网络的空间相关性和时间相关性。动态网络的特点,如大量的数据和非线性的时空相关性,将使神经网络成为一种很有前途的时间链路预测方法。
- 2)我们提出了一个整合TMF和LSTM的TMF-LSTM网络,它既能捕捉整个动态轮廓,又能捕捉动态网络的短期时间相关性。
- 3)为了评价该方法的有效性,我们在五个网络数据集上进行了大量的实验。实验结果表明,在动态网络中,时间链路预测的性能始终优于现有技术。
2、相关工作
A、传统时间链路预测方法
这些方法严重依赖繁琐且容易出错的手工特征,导致它们不能从动态网络中自动提取和组织动态且有区别的特征。此外,它们无法捕捉复杂的非线性时空特征。
B、链路预测的深度学习
然而,以前大多数基于深度学习的方法只能用于预测某一对节点之间是否存在链接。它们不适用于具有挑战性的加权动态网络。由于问题设置和网络数据的格式,我们的方法不同于那些方法。我们利用GCN、TMF和LSTM组合的GAN框架来处理加权动态网络中具有挑战性的链路预测任务。
C、图像生成的生成性对抗网络
另一方面,本文是我们前期工作的延伸[37]。本文与我们的前期工作[37]的主要区别可以概括为以下三个方面:
- 1)我们提出了一个Attentive GCN模型来编码网络结构。与GCN相反,Attentive GCN允许给每个顶点的相邻顶点分配不同的重要性,这保持了网络的一阶邻近性。
- 2)我们结合TMF和LSTM (TMF-LSTM)来捕捉整个动态轮廓和动态网络的短期时间依赖性。TMF-LSTM可以根据以前时间戳的可见网络快照预测未来的网络连接。
- 3)我们从不同角度对五个现实生活数据集进行了广泛的实验。实验结果表明,对于动态网络中的时间链路预测,我们的模型始终优于现有的方法。
3、问题定义
我们将动态网络定义为一系列网络快照G = {G1,G2,...,GT},其中Gt= (Vt,Et,Wt)表示时间戳t (t ∈ {1,2,...,T})和{1,2,...,T}是时间点的有限集合。我们假设G中的网络快照共享同一个顶点集,即Gt= (V,Et,Wt)。第t个网络快照包含一组表示对象的顶点集V,一组边集Et表示两个对象之间关系的边,以及一个相应的权重集Wt。我们用一个邻接矩阵At∈ RN×N来描述它的静态拓扑结构,其中N = |V|是动态网络中顶点的个数(不变)。对于加权网络,矩阵A具有随时间演变的任意边权重,而对于未加权网络,矩阵A的值是二进制的。具体来说,当节iI和j之间存在边时,即(i,j) ∈ Et,对于边权重(Wt)ij,我们有(At)ij =(Wt)ij;否则(At)ij= 0。时间链路预测旨在预测时间戳t+1处的网络快照At+1,给定之前观察到的l个网络快照A(t -l+1:t)= { At -l+1,At -l+2,...,At}。这里,l是一个超参数,表示训练期间上下文窗口的大小。
4、我们的方法
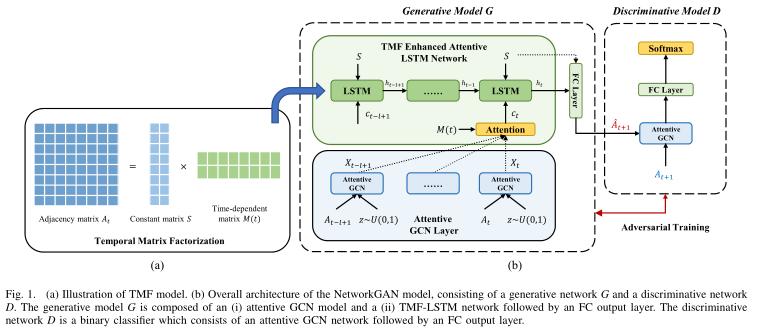
A、我们模型的架构
我们的模型,如图1所示,包含三个主要部分:1)一个Attentive GCN;2)TMF-LSTM网络;和3)GAN。首先,我们提出了一个attentive GCN来学习每个单个网络快照的拓扑结构信息,它通过关注机制来考虑k步相邻顶点的信息。然后,由专心的GCN模型给出的综合网络表示被馈送到TMF-LSTM模型,以学习动态网络的演化模式,并基于先前观察到的网络快照来预测未来的网络快照。此外,我们应用GAN框架来改进时间链路预测的性能,并通过使用判别模型来引导深度生成模型(即TMF-LSTM)在对抗过程中的训练来生成高质量的网络快照。接下来,我们将详细介绍我们模型的这三个主要部分。
B、Attentive Graph Convolutional Network(Attentive GAN 注意力图卷积网络)
受[38]的启发,我们提出了一个Attentive GCN模型来建模动态网络中每个网络快照的局部拓扑结构。GCN是GNNs的变体,它可以直接操作图。与GCN相反,我们的模型允许为每个顶点的相邻顶点分配不同的权重,这保持了网络的一阶邻近性。
1) Self-Attention Layer: 网络快照的拓扑结构和节点属性可以分别用邻接矩阵A ∈ RN×N和特征矩阵Z ∈ RN×M表示,其中Z的第i行表示节点i的特征向量。我们的模型首先将特征矩阵Z作为输入,并产生一组新的节点特征Z' ∈ RN×F(F为输出特征数)作为注意层的输出。形式上,作为初始步骤,由权重矩阵Wα∈ RF×M参数化的共享线性变换被应用于每个节点。然后,我们在节点上使用自我关注,并计算关注系数如下:
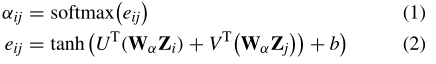
所学习的注意力系数被用来计算相应特征的线性组合,用作每个节点的最终输出特征
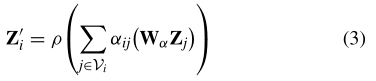
其中ρ是一个非线性tanh函数,Vi指的是节点i的相邻顶点。
2) Graph Convolutional Network Layer: 一个典型的GCN层把学习的特征 Z‘ 作为输入并且使用局部一阶近似基于邻接矩阵执行谱图卷积运算。在形式上,我们将一个GCN单位的运作定义为:

C、Temporal Matrix Factorization Enhanced Attentive LSTM Network(时变矩阵分解增强Attentive LSTM网络)
1)标准LSTM网络: 以前观察到的由Attentive GCN学习的综合网络表示{ Xt-l+1,Xt-l+2,...,Xt} ,被馈送到LSTM网络,以预测时间戳t+1的网络快照At+1。LSTM网络具有强大的能力来学习顺序数据的长期依赖性,并捕捉动态网络的演变模式。
LSTM结构可以被描述为具有几个乘法门单元的封装单元。在形式上,在时间戳t,每个LSTM单元将当前输入向量Xt作为输入,前一个时间戳的隐藏状态向量ht-1,和在当前时间戳隐藏状态向量ht,该向量的计算公式为:
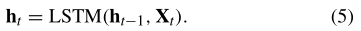
因此,给定输入网络快照{ Xt-l+1,Xt-l+2,...,Xt},我们可以得到相应的隐藏状态{ ht-l+1,ht-l+2,...,ht}。
2)时间矩阵分解:TMF [9]学习底层邻接矩阵的低秩表示,它随时间参数化。TMF基于过去或未来的网络快照在任何给定时刻t重建网络快照的邻接结构。在任何给定时刻t重建网络拓扑结构的能力使用户能够进行一般预测。此外,TMF不仅可以了解当前时间步长的网络表示,还可以了解动态网络的长期概况。具体来说,在TMF,矩阵At被分解为

其中S和M(t)都是N × ι矩阵。显然,(6)可以推广到无向网络,因为无向网络可以看作有向网络的一个特例。S和M(t)的主要区别在于,S是一个不变的矩阵,而M(t)是时间相关的。M(t)的一个典型选择是多项式函数,可定义如下:

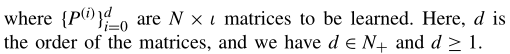
通常将矩阵分解视为最小二乘优化问题。矩阵分解的标准方法是建立一个最小二乘优化问题,使矩阵A(t)和SM(t)T尽可能匹配。这就可能被实现,通过最小化矩阵A(t)-SM(t)T的Frobenius范数的时间衰减和
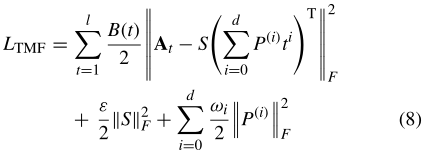
其中ε和ω是正则化系数。l是上下文窗口的大小。S和P(i)的正则项用于避免过拟合。这里,B(t)是控制当前网络快照相对于过去时间戳的重要性的衰减函数。B(t)的一个可能的解可能是指数衰减函数

 是用户定义的超参数。
是用户定义的超参数。
3) LSTM and TMF Hybrid: 基于矩阵分解和基于深度学习的链路预测方法是相互补充的。具体来说,TMF方法探索了动态网络中的全局潜在特征和不断演变的模式。相反,LSTM方法预测下一个网络的拓扑,考虑本地网络拓扑和短期网络动态。因此,它促使我们提出了一种联合方法,这种方法既受益于TMF方法,也受益于LSTM方法,利用了动态网络的全局和局部特征。
如图1所示,我们通过将(6)中S的潜在特征视为静态上下文表示来扩展LSTM,并将其作为额外的输入馈送到LSTM对动态网络的时间隐藏状态的计算中。在每个时间步长,上下文表示有助于推断LSTM网络的隐藏状态。
此外,提出了一种注意机制,通过利用TMF的时间因素来计算动态网络的每个隐藏状态的权重。时间t的隐藏状态ht可以由下式重新表示
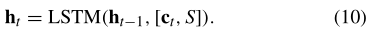
上下文向量ct是计算LSTM隐藏状态的额外输入,这样LSTM可以在每个时间戳获得网络的全部信息(长期信息)。上下文向量ct是时间t的网络快照的相关长期信息的动态表示,计算如下
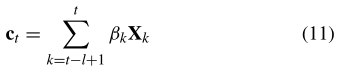
其中通过使用动态潜在特征M(t)作为关注源来计算在时间步长t的关注权重βk

其中σ是前馈神经网络,用于产生实值分数。注意力权重βk决定了应该选择哪些输入网络快照来预测当前网络快照。
最后,最后的隐藏状态ht和S被馈送到输出完全连接(FC)层,以生成下一个时间片的网络快照At+1
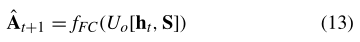
其中Uo为可学习参数,fFC为FC层
D. Generative Adversarial Network(GAN 生成性对抗网络)
在本文中,我们使用GAN [14]来进一步改进生成LSTM网络的性能。特别是,GAN由一个辨别模型D和一个生成模型G组成,前者学会区分输入实例是否真实,后者学会通过生成可信的高质量数据来混淆D。最近,在使用GAN生成逼真图像方面取得了显著进展。具体来说,鉴别器D和生成器模型G玩下面的极小极大游戏:

其中x是来自训练集的真实数据,z是从正态分布采样的噪声变量。
像标准的GAN框架一样,提出的网络GAN用最小最大两人游戏优化了两个神经网络(即生成器G和鉴别器D)。D试图从G生成的网络快照中辨别出训练数据中真实的网络快照,而G则试图最大化D出错的概率。希望这种对抗性的学习过程最终能调整G,生成更多高质量的网络快照。接下来,我们详细阐述了发生器G和鉴别器D。
1)鉴别网络D: 区分模型被实现为二进制分类器。由于地面真实网络快照中的边缘权重可能具有大范围的值(例如,[0,1000]),我们将α的值归一化到[0,1]的范围内。被预测的网络快照A被G定义在[0,1]范围内,可以直接作为D的输入。如图1(右)所示,我们首先利用关注的GCN模型,用(4)学习输入网络快照A 的综合分布表示Z‘。然后,Z‘ 被馈送到FC层,然后是softmax层,以计算输出概率分布
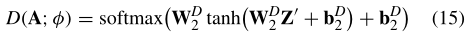
其中φ是判别模型D的参数集;WD 2和WD 2是要学习的权重矩阵;bD2和bD2是偏置项。
在对抗训练中,我们使用区分模型作为奖励函数,通过交替和迭代地更新区分模型和生成模型来进一步提高生成模型的性能。判别模型D的目的是使生成模型G从生成的网络快照中正确判别训练数据中的真实网络快照的概率最大化。通过固定G的参数,我们可以通过最小化以下目标函数来更新判别模型的参数:
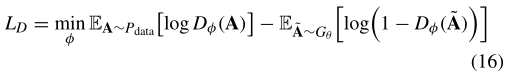
其中,数据表示训练数据;θ和φ分别是生成模型G和判别模型D的参数。
2)生成模型G: 如图1(左)所示,发生器G由GCN层、LSTM层和FC输出层组成。GCN层将网络快照A(t-l+1:t)= { At-l+1,At-l+2,...,At}以及噪声分布z作为输入,并输出分布式网络表示序列{ Xt-l+1,Xt-l+2,...,Xt},然后将其送入LSTM层。类似于判别模型D,每个邻接矩阵A中的值在被馈送到GCN单元之前应该被归一化到[0,1]的范围内。而且,我们让噪声分布z在[0,1][即z~U(0,1)]内遵循均匀分布。
LSTM网络将由Attentive GCN层学习出的网络分布序列{ Xt-l+1,Xt-l+2,...,Xt}作为输入,并把隐藏状态{ ht-l+1,...,ht}作为输出。当输入到LSTM层时,每个矩阵输入应该被重新整形为一个行方向的向量。最后,我们将最后一个隐藏状态ht反馈给FC层,以生成下一个时间片的网络快照At+1。在本文的其余部分,我们利用以下简化符号来表示带有噪声z的生成网络G和网络快照序列At-l+1:t = { At-l+1,...,At}作为输入
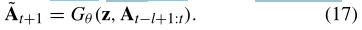
当判别模型D通过执行(16)被优化和固定时,生成模型G可以通过以下方式被优化
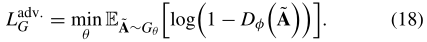
实际上,(18)可能没有分配足够的梯度来学习一个好的生成模型。当G在训练的早期阶段较差时,D可以以高置信度区分输入实例,因为生成的实例明显不同于来自训练集的实例。不是训练G来最小化log(1-Dφ(ˈA)),而是训练G来最大化logDφ(ˈA)。这个目标函数可以导致G和D的动力学的相同不动点,但是在学习的早期给出更强的梯度。
a)重构损失:对抗性训练理论上可以学习G和D,产生一个可以成功忽悠D的高质量网络快照,但是预测的网络快照中的值可能与下一个时间戳的地面真实网络快照中的值不一致。因此,仅对抗损失不能保证学习的生成模型能够基于先前观察到的网络预测下一个网络快照。为了进一步减少可能的生成函数的空间,我们引入了另一个重构损失
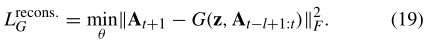
生成模型G试图基于先前的l个网络快照在At-l+1:t重建时间戳t + 1中的网络快照。这样的过程增强了G对动态网络的先前时间特征的建模。
总的来说,生成模型G的全部目标是
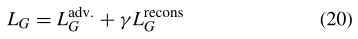
其中γ控制重建损失的影响
请注意,生成的网络快照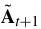 中的元素在[0,1]的范围内。因此,在
中的元素在[0,1]的范围内。因此,在 上归一化的另一个逆过程被应用来将预测值转换成链路权重的真实范围。遗传神经网络框架的总体训练程序总结在算法1中。在训练阶段,分别通过(16)和(20)以对抗的方式交替训练辨别模型和生成模型。
上归一化的另一个逆过程被应用来将预测值转换成链路权重的真实范围。遗传神经网络框架的总体训练程序总结在算法1中。在训练阶段,分别通过(16)和(20)以对抗的方式交替训练辨别模型和生成模型。

6、总结
在未来,我们首先计划通过将其扩展到可以端到端学习的统一模型来进一步提高NetworkGAN的性能。特别是,我们希望将TMF无缝集成到LSTM,以使整个框架端到端可培训。此外,我们可以致力于探索社区检测技术[50],以增强动态网络中的时间链接预测,因为社区检测可以提供对网络结构的洞察。链接预测技术反过来也可以改进社区检测,因为链路信息(拓扑结构)对于根据观察到的网络快照预测未来社区是至关重要的。因此,将社区检测和链接预测结合到一个联合模型中可以相互增强这两项任务。最后,我们将概括所提出的框架来处理二分网络中的时间链接预测。例如,我们可以应用二分网络嵌入算法来学习二分网络的网络嵌入(特征矩阵)。

